机器学习——kNN算法解决海伦约会问题
算法的核心思想是,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实例分类到这个类中。经过一番总结,她发现曾交往过三种类型的人:不喜欢的人,魅力一般的人,极具魅力的人。(4)使用算法:首先需要输入样本数据和结构化的输出结果,然后运行k-近邻算法,判定输入数据分别属于哪个分类,最后应用,对计算出的分类执行后续的处理。(3)分析
一、K近邻算法
1、什么是K-近邻算法
K近邻算法是一种基本分类与回归方法。算法的核心思想是,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实例分类到这个类中。K近邻算法通过测量不同特征值之间的距离进行分类。KNN对新样本进行预测的方法是:根据其k个最近邻的训练实例类别,通过多数表决等方式进行预测
2、K-近邻算法的具体流程
(1)收集数据:可以使用任何方法
(2)准备数据:距离计算所需要的数值,最好是结构化的数据格式
(3)分析数据:当拥有了适当的数据量后,通过对数据的分析,根据需要,取得适合的K值
(4)使用算法:首先需要输入样本数据和结构化的输出结果,然后运行k-近邻算法,判定输入数据分别属于哪个分类,最后应用,对计算出的分类执行后续的处理
二、海伦约会问题
海伦一直使用在线约会网站寻找适合自己的约会对象。尽管约会网站会推荐不同的人选,但她并不是喜欢每一个人。经过一番总结,她发现曾交往过三种类型的人:不喜欢的人,魅力一般的人,极具魅力的人
尽管发现了上述规律,但海伦依然无法将约会网站推荐的匹配对象归入恰当的类别。海伦希望分类软件可以更好地帮助她将匹配对象划分到确切的分类中,此外海伦收集了一些约会网站未记录的数据信息,她认为这些数据有助于匹配对象的归类。
数据集: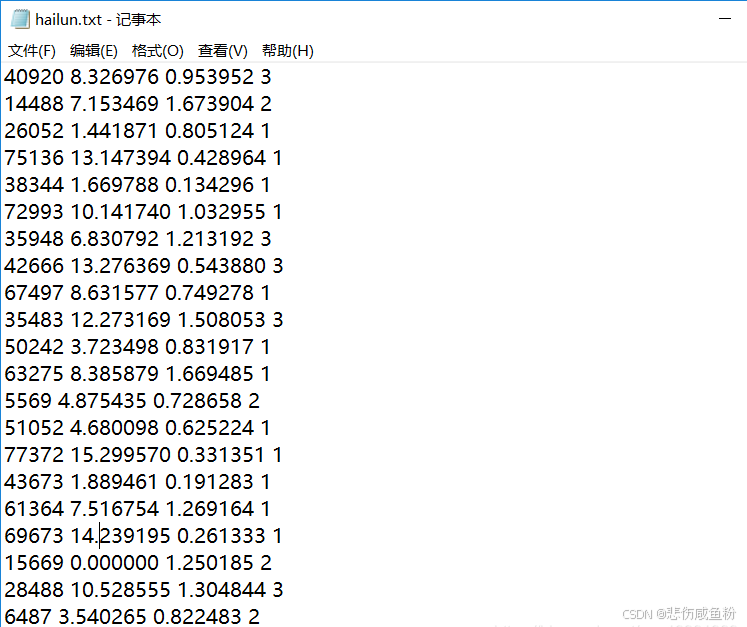
海伦收集的样本数据主要包含以下3种特征:
1.每年获得的飞行常客里程数
2.玩视频游戏所消耗时间百分比
3.每周消费的冰淇淋公升数
2.1数据准备
# 数据准备
datingTest = pd.read_table('datingTestSet.txt', header=None) # 将文件放在代码同一文件夹下
# print(datingTest)
print(datingTest.shape)
print(datingTest.info)2.2分析数据:可视化
# 分析数据
colors = [] # 用颜色将三类人区分出来
'''
range(...)
datingTest.shape[0]表示行数
'''
for i in range(datingTest.shape[0]):
m = datingTest.iloc[i, -1]
if m == 'didntLike':
colors.append('black')
if m == 'smallDoses':
colors.append('orange')
if m == 'largeDoses':
colors.append('red')
# 绘制两两特征之间的散点图
plt.rcParams['font.sans-serif'] = ['Simhei'] # 图中字体设置为黑体
pl = plt.figure(figsize=(12, 8)) # 创建一个图形窗口(宽12英寸,高8英寸)
fig1 = pl.add_subplot(221) # 用aff_subplot函数在图形窗口pl中添加了一个子图
plt.scatter(datingTest.iloc[:, 1], datingTest.iloc[:, 2], marker='.', c=colors)
# plt.scatter(x轴数据,y轴数据,marker=’.‘设置散点图中点的标记类型,c为颜色)函数用于绘制散点图,
plt.xlabel('玩游戏视频所占时间比') # x轴标签
plt.ylabel('每周消费冰淇淋公升数') # y轴标签
fig2 = pl.add_subplot(222)
plt.scatter(datingTest.iloc[:, 0], datingTest.iloc[:, 1], marker='.', c=colors)
plt.xlabel('每年飞行常客里程')
plt.ylabel('玩游戏视频所占时间比')
fig3 = pl.add_subplot(223)
plt.scatter(datingTest.iloc[:, 0], datingTest.iloc[:, 2], marker='.', c=colors)
plt.xlabel('每年飞行常客里程')
plt.ylabel('每周消费冰淇淋公升数')
plt.show()绘制散点图: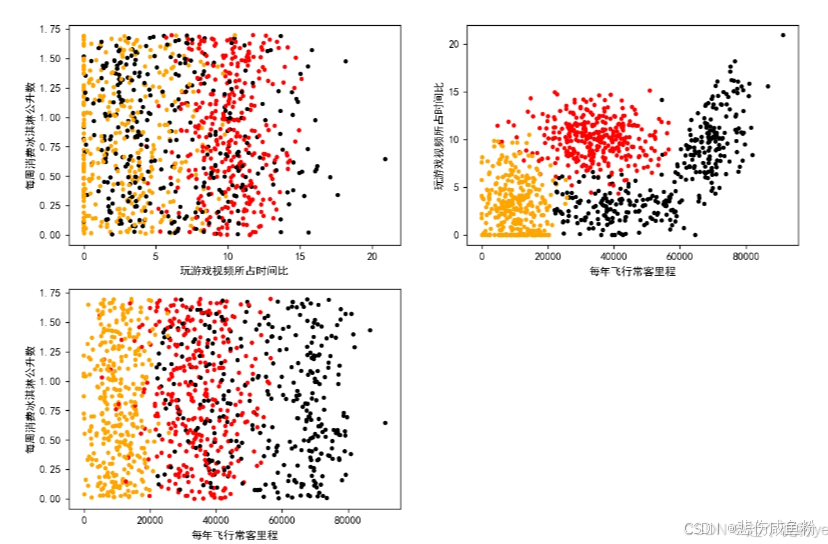
2.3数据归一化
公式: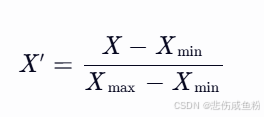
def minmax(data):
mindata = data.min()
maxdata = data.max()
norm = (data-mindata)/(maxdata-mindata)
return norm
# 数据归一化
dating_norm = pd.concat([minmax(datingTest.iloc[:, :3]), datingTest.iloc[:, 3]], axis=1)
dating_norm.head() # 用于返回dataframe的前五航
2.4knn算法实现分类
训练集用来训练模型,测试集用来验证模型得到准确率。
'''
函数功能:切分训练集和测试集
参数说明:
data:原始数据
rate:训练集所占比例
return:切分好的训练集和测试集
'''
def split(data,rate):
n = data.shape[0]
m = int(n*rate)
train = data.iloc[:m,:]
test = data.iloc[m:,:]
test.index = range(test.shape[0])
return train,test
train, test = split(dating_norm, 0.9)构建一个函数,可以利用测试集来测试分类器的准确率。
'''
函数功能:knn分类器实现
参数说明:
train:训练集
test:测试集
k:参数
输出:分类器的准确率
return 测试集
'''
def knnclass(train,test,k):
n = train.shape[1] - 1 #训练集除标签列外的特征列数
m = test.shape[0] #测试集的行数
result =[] #初始化空列表,用于存储预测结果
for i in range(m):
#训练数据与每一条测试数据中样本的距离
dist = list((((train.iloc[:,:n]-test.iloc[i,:n])**2).sum(1))**0.5)#sum(1)是沿着列的方向(横向)对每个样本的差异平方求和
#列表根据距离进行排序
dist_df = pd.DataFrame({'dist':dist,'labels':(train.iloc[:,n])})
#根据距离对DataFrame进行排序,并选择距离最近的K个样本。
dist_k = dist_df.sort_values(by='dist')[:k]
#统计这K个最近邻样本的标签出现的次数。
re = dist_k.loc[:,'labels'].value_counts()
#将出现次数最多的标签(即众数)作为当前测试样本的预测标签,并添加到结果列表中。
result.append(re.index[0])
result = pd.Series(result) #将结果列表转换为Pandas Series对象。
#在测试集DataFrame中添加一列predict,用于存储预测结果。
test['predict'] = result
acc= (test.iloc[:,-1]==test.iloc[:,-2]).mean()
#test.iloc[:,-1] == test.iloc[:,-2])逐一比较,最后返回一个布尔类型的Series,其中的值为True或False
#mean()函数计算上述的平均值,即计算预测正确的样本占总样本的比例,即准确率
print(f'模型预测准确率为{acc}')
return test
print(knnclass(train, test, 5))结果:
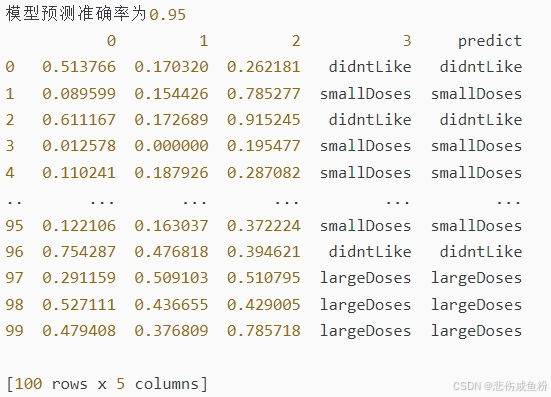
三、实验小结
- K值的选择:KNN算法需要手动选定K值,较小的K值会容易出现过拟合问题;而较大的K值则会容易出现欠拟合问题。一般使用交叉验证等技术来确定最优的K值。
- 距离度量:KNN算法实现的关键在于距离的计算,不同的距离度量方式会影响KNN的分类效果。
-
knn算法的优点与缺点
优点
简单,易于理解,易于实现,无需估计参数。
对数据没有假设,准确度高,对异常点不敏感。
适合对稀有事件进行分类。
适合于多分类问题。
缺点
当特征非常多的时候,计算量太大。
样本不平衡问题(有些类别的样本数量很多,而其它样本的数量很少)。
对训练数据依赖度特别大,对训练数据的容错性太差。对训练数据依赖度特别大,对训练数据的容错性太差。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 25
25 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)