机器学习--实现ROC,PR曲线
在机器学习中,ROC曲线和PR曲线是评估二分类模型性能的重要工具:ROC曲线通过绘制真正例率(TPR)和假正例率(FPR)反映模型对正负类的整体区分能力,其AUC-ROC值越接近1表明模型性能越好,适用于类别均衡的场景;ROC曲线以假阳性率为横轴,真阳性率为纵轴,同样通过改变分类阈值得到一系列点连接而成,越接近左上角表示模型性能越优,适用于评估分类器的整体性能,尤其在类别平衡的数据集中表现较好。两
一、概述
PR曲线和ROC曲线都是用于评估二分类模型性能的工具。PR曲线以精确率为纵轴,召回率为横轴,通过改变分类阈值得到一系列点连接而成,越接近右上角表示模型性能越好,适用于样本不平衡的情况。ROC曲线以假阳性率为横轴,真阳性率为纵轴,同样通过改变分类阈值得到一系列点连接而成,越接近左上角表示模型性能越优,适用于评估分类器的整体性能,尤其在类别平衡的数据集中表现较好。两者在样本平衡的情况下表现相似,但在实际应用中,应根据具体的数据集和评估需求,选择合适的曲线来评估模型的性能。
二、两种曲线的介绍
2.1 ROC曲线
ROC曲线(Receiver Operating Characteristic Curve,受试者工作特征曲线)是评估二分类模型性能的重要工具,尤其在医学诊断、机器学习等领域广泛应用。以下是关于ROC曲线的详细介绍:
1. 核心概念
目的:衡量分类模型在不同阈值下的判别能力,尤其关注模型对正类和负类的区分度。
核心指标:
真正例率(TPR, True Positive Rate):又称灵敏度(Sensitivity),计算公式为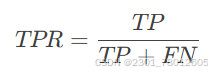
表示实际为正的样本中被模型正确识别的比例。
曲线绘制:通过调整分类阈值(如逻辑回归中的概率阈值),计算不同阈值下的TPR和FPR,在二维坐标系中连接这些点形成曲线。
2. 曲线特性
理想情况:曲线越靠近左上角(TPR=1,FPR=0),模型性能越好。
AUC(Area Under Curve):曲线下面积,取值范围[0, 1],用于量化性能:
AUC=1:完美分类器;
AUC=0.5:等同于随机猜测;
AUC<0.5:可能模型存在反向预测问题。
对角线(AUC=0.5):表示模型无判别能力(如抛硬币)。
3. 应用场景
医学诊断:评估疾病预测模型的准确性。
机器学习:比较不同分类算法(如SVM、随机森林、逻辑回归)的性能。
不平衡数据:当正负样本比例悬殊时,ROC曲线比准确率(Accuracy)更能反映模型真实性能。
4. 优缺点
优点:
不受类别分布影响(对不平衡数据鲁棒);
直观展示模型在所有阈值下的表现。
缺点:
当两类样本分布极不均衡时,可能高估模型性能(此时可结合PR曲线分析)。
2.2PR曲线
PR曲线(Precision-Recall Curve,精确率-召回率曲线)是用于评估二分类模型性能的重要工具,尤其适用于**类别不平衡(Class Imbalance)的场景。与ROC曲线不同,PR曲线更关注模型在正类(少数类)**上的表现,因此在医学诊断、异常检测、信息检索等领域广泛应用。
1. PR曲线的核心概念
PR曲线通过绘制**精确率(Precision)和召回率(Recall)**在不同分类阈值下的变化关系,直观反映模型的分类能力。
关键指标
精确率(Precision)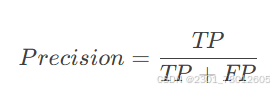
表示预测为正类的样本中,真正为正的比例(即预测的准确性)。
高 Precision 意味着模型预测的正类可信度高(FP少)。
召回率(Recall,即TPR)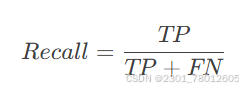
表示实际为正类的样本中,被正确预测的比例(即查全率)。
高 Recall 意味着模型能找出更多的正样本(FN少)。
F1 Score
是 Precision 和 Recall 的调和平均数,用于综合评估模型性能。
PR曲线的特点:
优点:PR曲线对查准率和召回率之间的变化更为敏感,适和用于处理类别不平衡或关注错误分类成本较高的问题。
缺点:当数据集中存在大量负例样本时,PR曲线给出的评估结果太差。
2. PR曲线的绘制方法
调整分类阈值(如逻辑回归中的概率阈值 threshold),计算不同阈值下的 Precision 和 Recall。
以 Recall 为横轴,Precision 为纵轴,绘制所有(Recall, Precision)点并连接成曲线。
曲线越靠近右上角,模型性能越好。
三、实现
3.1 ROC曲线的实现过程
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, roc_auc_score
# 准备一百个数据集
y_true = np.array([0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1,
0, 1, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1,
0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0,
1, 0, 1, 0, 0, 1, 0, 1, 1, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1,
0, 1, 0, 0, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 0])
y_score = np.array([0.21, 0.64, 0.82, 0.47, 0.73, 0.38, 0.91, 0.29, 0.68, 0.43,
0.33, 0.76, 0.79, 0.41, 0.88, 0.69, 0.37, 0.26, 0.48, 0.95,
0.4, 0.66, 0.75, 0.36, 0.84, 0.32, 0.71, 0.44, 0.3, 0.91,
0.95, 0.47, 0.78, 0.87, 0.39, 0.14, 0.21, 0.83, 0.3, 0.79,
0.37, 0.71, 0.26, 0.88, 0.31, 0.48, 0.66, 0.41, 0.24, 0.95,
0.72, 0.45, 0.79, 0.22, 0.92, 0.36, 0.78, 0.47, 0.69, 0.28,
0.81, 0.44, 0.84, 0.29, 0.75, 0.22, 0.89, 0.3, 0.31, 0.91,
0.21, 0.85, 0.33, 0.62, 0.36, 0.38, 0.66, 0.14, 0.79, 0.38,
0.92, 0.45, 0.75, 0.32, 0.67, 0.27, 0.82, 0.31, 0.28, 0.89,
0.33, 0.84, 0.26, 0.72, 0.21, 0.76])
# 计算真正率,假正率和
fpr, tpr, thresholds = roc_curve(y_true, y_score)
auc = roc_auc_score(y_true, y_score)
# 绘制ROC曲线
plt.plot(fpr, tpr, label='ROC curve (AUC = %0.2f)' % auc)
plt.plot([0, 1], [0, 1], 'k--')
# 设置字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 结果
plt.xlabel('假正例率(FPR)')
plt.ylabel('真正例率(TPR)')
plt.title('ROC曲线')
plt.legend(loc='lower right')
plt.show()
结果及分析:
roc曲线越靠近左上角,模型性能越好;曲线越靠近45度对角线,则模型性能越差。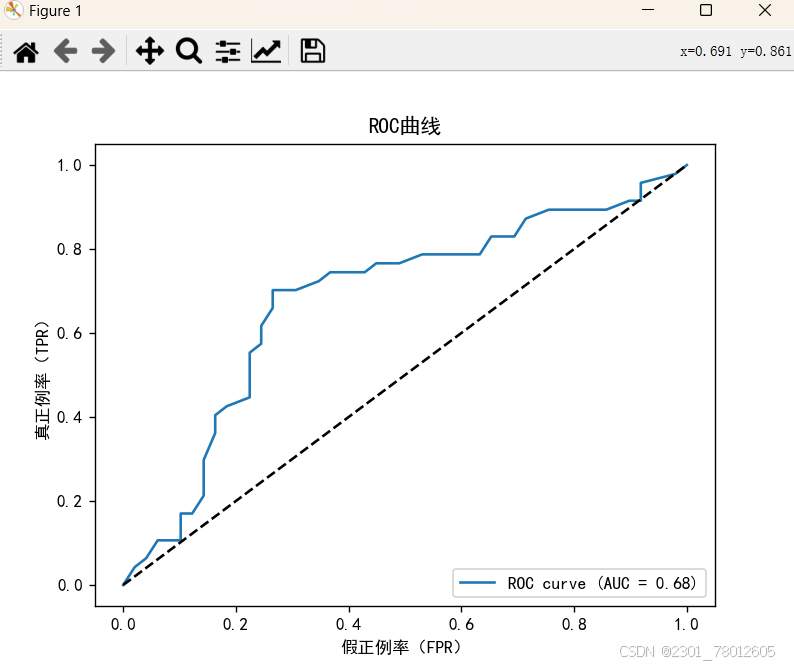
3.2 PR曲线的实现过程
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve, auc
# 准备一百个数据集
y_true = np.array([0, 1, 1, 0, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1,
0, 1, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1,
0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0,
1, 0, 1, 0, 0, 1, 0, 1, 1, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1,
0, 1, 0, 0, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 0])
y_score = np.array([0.21, 0.64, 0.82, 0.47, 0.73, 0.38, 0.91, 0.29, 0.68, 0.43,
0.33, 0.76, 0.79, 0.41, 0.88, 0.69, 0.37, 0.26, 0.48, 0.95,
0.4, 0.66, 0.75, 0.36, 0.84, 0.32, 0.71, 0.44, 0.3, 0.91,
0.95, 0.47, 0.78, 0.87, 0.39, 0.14, 0.21, 0.83, 0.3, 0.79,
0.37, 0.71, 0.26, 0.88, 0.31, 0.48, 0.66, 0.41, 0.24, 0.95,
0.72, 0.45, 0.79, 0.22, 0.92, 0.36, 0.78, 0.47, 0.69, 0.28,
0.81, 0.44, 0.84, 0.29, 0.75, 0.22, 0.89, 0.3, 0.31, 0.91,
0.21, 0.85, 0.33, 0.62, 0.36, 0.38, 0.66, 0.14, 0.79, 0.38,
0.92, 0.45, 0.75, 0.32, 0.67, 0.27, 0.82, 0.31, 0.28, 0.89,
0.33, 0.84, 0.26, 0.72, 0.21, 0.76])
# 计算精确率和召回率
precision, recall, thresholds = precision_recall_curve(y_true, y_score)
# 计算平均准确率
average_precision = auc(recall, precision)
# PR曲线
plt.plot(recall, precision, label='PR curve (AP = %0.2f)' % average_precision)
plt.xlabel('召回率')
plt.ylabel('精度')
plt.title('PR曲线')
plt.legend(loc='lower left')
plt.show()
结果及分析
PR曲线越靠近右上角,模型性能越好;曲线越靠近0纵轴,模型性能越差。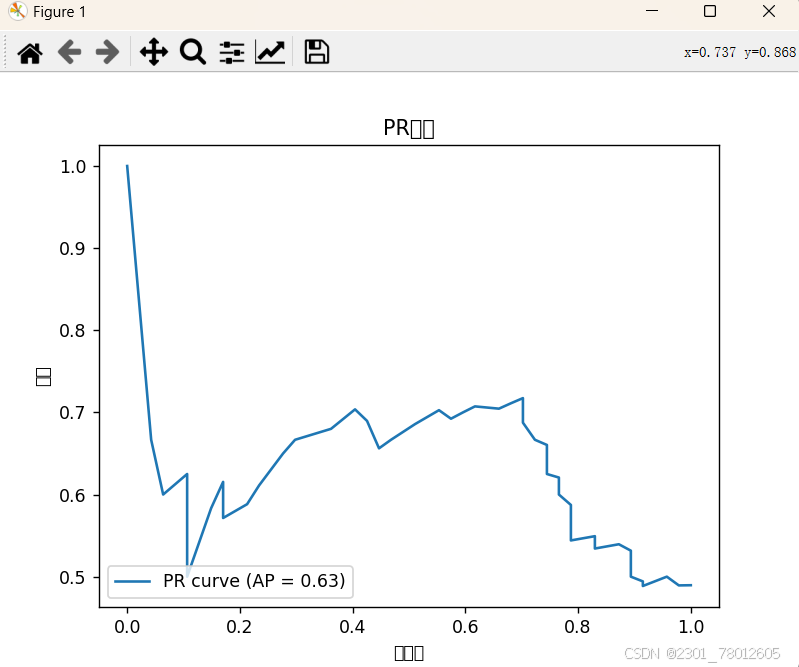
3.3 怎么样选择合适的ROC与PR曲线:
1.选择ROC曲线:
当关注的是模型在不同阈值下的整体分类性能,并且数据集存在类别不平衡或大量负例样本时,ROC曲线是较为合适的选择。
2.选择PR曲线:
当关注的是模型在不同阈值下的查准率和召回率之间的平衡,并且数据集存在类别不平衡或关注错误分类成本较高的情况下,PR曲线是较为合适的选择。
四、结论
在机器学习中,ROC曲线和PR曲线是评估二分类模型性能的重要工具:ROC曲线通过绘制真正例率(TPR)和假正例率(FPR)反映模型对正负类的整体区分能力,其AUC-ROC值越接近1表明模型性能越好,适用于类别均衡的场景;而PR曲线通过精确率(Precision)和召回率(Recall)的权衡关系聚焦正类的预测准确性,其AUC-PR值在类别不平衡(如正样本极少)时更具参考价值,能有效避免因负样本过多导致的评估偏差。实际应用中,ROC曲线更适合全局性能分析,PR曲线则对不平衡数据更敏感,两者结合使用可全面评估模型表现,并根据业务需求(如减少误诊或漏检)选择最佳分类阈值。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 27
27 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)