机器学习的一百个概念(10)假阳性率
深度解析机器学习核心指标假阳性率(FPR),涵盖医疗诊断到金融风控等真实场景应用,提供Python代码实战、阈值优化技巧及业务成本分析方法,独创自适应阈值技术与多模态融合策略,助数据科学家精准平衡模型性能与业务需求。
前言
本文隶属于专栏《机器学习的一百个概念》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见[《机器学习的一百个概念》
ima 知识库
知识库广场搜索:
| 知识库 | 创建人 |
|---|---|
| 机器学习 | @Shockang |
| 机器学习数学基础 | @Shockang |
| 深度学习 | @Shockang |
正文
1. 引言 👋
在机器学习的广阔天地中,模型评估指标是我们理解和优化模型的重要工具。其中,假阳性率(False Positive Rate,FPR)作为一个关键指标,在众多应用场景中扮演着至关重要的角色。无论是医疗诊断、欺诈检测、还是信息安全领域,对FPR的深入理解和有效控制都直接关系到模型的实际应用价值。
本文将从概念定义出发,深入剖析FPR的理论基础、计算方法、应用场景和优化策略,帮助读者全面理解这一重要指标,并能在实际工作中熟练运用。我们不仅会讨论理论知识,还将结合实际案例和代码实现,为读者提供完整的学习路径。
2. 基础概念:什么是假阳性率?🧩
2.1 混淆矩阵回顾
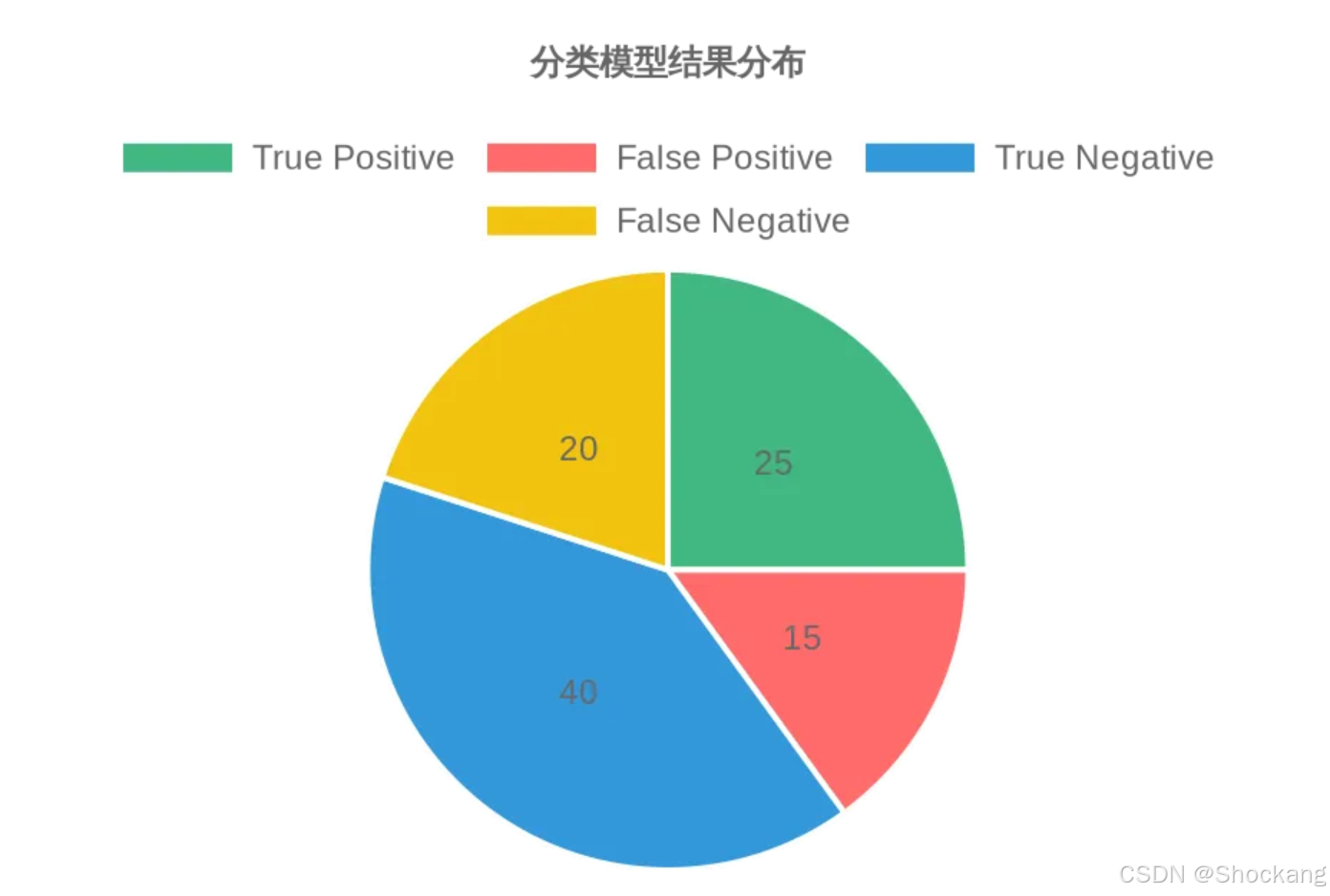
在深入理解假阳性率之前,我们需要先回顾分类问题中的基础概念——混淆矩阵(Confusion Matrix)。在二分类问题中,混淆矩阵包含四个关键元素:
- 真阳性(True Positive, TP): 模型正确地将正类样本预测为正类
- 假阳性(False Positive, FP): 模型错误地将负类样本预测为正类
- 真阴性(True Negative, TN): 模型正确地将负类样本预测为负类
- 假阴性(False Negative, FN): 模型错误地将正类样本预测为负类
这四个元素构成了评估分类模型性能的基础,如下表所示:
| 预测为正类 | 预测为负类 | |
|---|---|---|
| 实际为正类 | TP(真阳性) | FN(假阴性) |
| 实际为负类 | FP(假阳性) | TN(真阴性) |
2.2 假阳性率的定义与计算
假阳性率(False Positive Rate, FPR)是指在所有实际为负类的样本中,被错误地预测为正类的比例。其计算公式为:
FPR=FPFP+TNFPR = \frac{FP}{FP + TN}FPR=FP+TNFP
从直观上理解,FPR表示的是模型将负类误判为正类的概率,也被称为"误报率"或"虚警率"。FPR越低,说明模型对负类的判别能力越强。
2.3 FPR的直观解释
想象一个机场安检系统,其任务是识别危险物品:
- 正类:危险物品
- 负类:安全物品
在这个场景中:
- 假阳性(FP):将安全物品错误地判定为危险物品,导致不必要的检查
- FPR:在所有安全物品中,被错误地标记为危险的比例
如果FPR=0.1,意味着10%的安全物品会被错误地标记为危险,导致不必要的安检流程和旅客延误。
3. 深入理解FPR:理论基础与重要性 🔬
3.1 FPR的统计学意义
从统计学角度看,FPR实际上是第一类错误(Type I Error)的概率,即错误地拒绝原假设的概率。在假设检验中,通常用显著性水平α来表示,它代表了我们愿意接受的假阳性率的上限。
在机器学习中,控制FPR就是在控制模型对负类样本的误判比例,这对许多应用场景至关重要,特别是那些"误报"成本高昂的情境。
3.2 FPR与决策阈值的关系
在大多数分类模型中,最终决策是基于一个阈值(threshold)来确定的。模型会为每个样本生成一个概率或分数,然后与阈值比较来决定最终分类:
- 如果分数 ≥ 阈值,预测为正类
- 如果分数 < 阈值,预测为负类
阈值的选择直接影响FPR:
- 降低阈值:更多样本会被预测为正类,FPR增加(但可能提高真阳性率)
- 提高阈值:更少样本会被预测为正类,FPR降低(但可能降低真阳性率)
这种权衡关系是ROC曲线分析的核心,我们将在后面详细讨论。
3.3 为什么FPR很重要?
FPR之所以重要,主要体现在以下几个方面:
-
成本考量:在许多场景中,假阳性会带来明显的成本或风险。例如,医疗诊断中的假阳性可能导致不必要的治疗和患者焦虑;欺诈检测中的假阳性可能阻碍正常交易。
-
资源分配:每个假阳性都可能消耗有限的资源。例如,安全系统中的假警报会分散安全人员的注意力。
-
用户体验:在产品应用中,高FPR可能严重影响用户体验。例如,垃圾邮件过滤器将正常邮件误判为垃圾邮件。
-
系统可信度:FPR过高会降低系统的整体可信度,导致"狼来了"效应,使用户忽视真正的警报。
4. FPR在不同应用场景中的重要性 🌐
4.1 医疗诊断
在医疗诊断领域,FPR代表将健康患者误诊为患病的比例。控制FPR对医疗系统至关重要,原因包括:
- 心理影响:错误的阳性诊断会给患者带来不必要的焦虑和心理负担
- 医疗资源浪费:后续不必要的检查和治疗会消耗有限的医疗资源
- 治疗风险:不必要的治疗可能带来副作用和并发症风险
例如,在癌症筛查中,高FPR会导致大量健康人接受不必要的活检,这不仅增加医疗成本,还会给患者带来身体和心理伤害。
4.2 欺诈检测
在金融欺诈检测系统中,FPR表示将正常交易误判为欺诈的比例。高FPR会带来严重后果:
- 客户体验受损:正常交易被拒绝会导致客户不满
- 业务损失:频繁的误报会降低交易量,影响收入
- 人工审核成本:每个报警通常需要人工审核,高FPR意味着高昂的人力成本
一个有效的欺诈检测系统需要在降低FPR的同时,保持对真实欺诈的高检出率,这是一个典型的平衡问题。
4.3 网络安全
在入侵检测、恶意软件识别等网络安全应用中,FPR代表将正常行为误判为威胁的比例:
- 警报疲劳:高FPR导致安全分析师面对大量误报,可能忽视真正的威胁
- 系统性能:每次报警通常会触发一系列防御措施,高FPR会降低系统性能
- 可信度降低:频繁的误报会降低安全系统的整体可信度
研究表明,在大型组织中,安全团队每天可能面对数百甚至数千个警报,其中大部分是假阳性。有效控制FPR是安全系统设计的核心挑战。
4.4 信息检索与推荐系统
在搜索引擎、内容过滤和推荐系统中,FPR表示将不相关内容错误地包含在结果中的比例:
- 用户体验:高FPR意味着用户需要筛选大量不相关内容
- 系统效率:推送不相关内容会浪费带宽和计算资源
- 用户信任:频繁推送不相关内容会降低用户对系统的信任
例如,在内容推荐系统中,将用户不感兴趣的内容频繁推送给用户,会导致用户参与度下降和流失。
5. FPR与其他评估指标的关系 📊
5.1 FPR与TPR:ROC曲线
真阳性率(True Positive Rate, TPR),也称为灵敏度(Sensitivity)或召回率(Recall),计算公式为:
TPR=TPTP+FNTPR = \frac{TP}{TP + FN}TPR=TP+FNTP
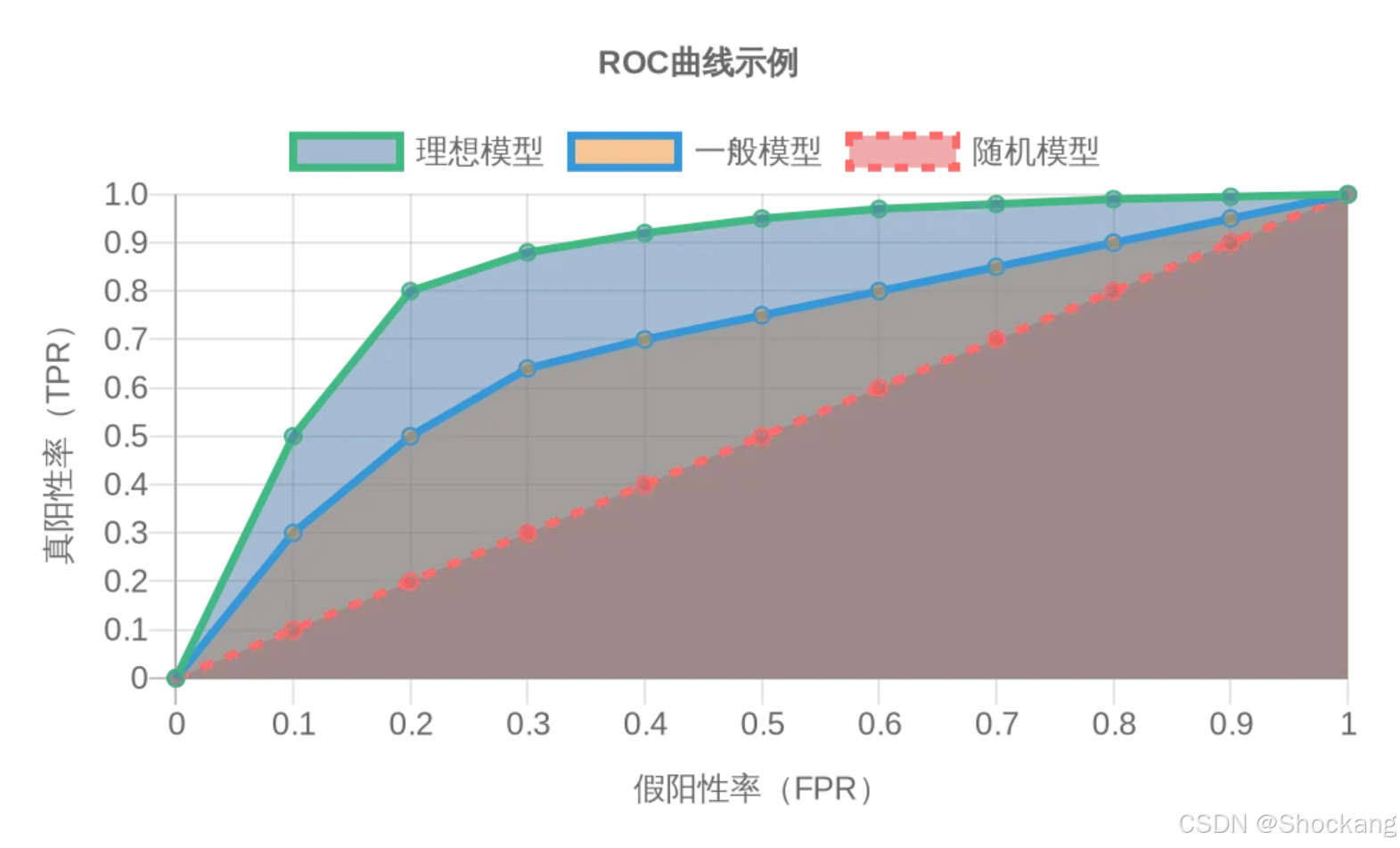
TPR与FPR共同构成了接收者操作特征曲线(Receiver Operating Characteristic Curve, ROC曲线)的两个坐标轴。ROC曲线是通过改变决策阈值,绘制不同阈值下TPR对FPR的曲线。
ROC曲线的特点:
- 曲线越靠近左上角,模型性能越好
- 对角线代表随机猜测的性能
- 曲线下面积(AUC)是模型性能的综合度量
5.2 FPR与精确率
精确率(Precision)表示在所有被预测为正类的样本中,真正属于正类的比例:
Precision=TPTP+FPPrecision = \frac{TP}{TP + FP}Precision=TP+FPTP
精确率与FPR的区别:
- FPR关注的是负类样本中被误判的比例
- 精确率关注的是预测为正类的样本中正确的比例
两者之间存在间接关系:在固定的TP数量下,FP增加会导致FPR增加,同时精确率降低。
5.3 特异性与FPR
特异性(Specificity)是FPR的补集,表示负类样本被正确分类的比例:
Specificity=TNTN+FP=1−FPRSpecificity = \frac{TN}{TN + FP} = 1 - FPRSpecificity=TN+FPTN=1−FPR
特异性高的模型通常FPR低,对负类有良好的识别能力。在某些应用中,特异性被直接作为模型评估指标。
5.4 F1分数与FPR
F1分数是精确率和召回率的调和平均:
F1=2×Precision×RecallPrecision+RecallF1 = \frac{2 \times Precision \times Recall}{Precision + Recall}F1=Precision+Recall2×Precision×Recall
F1分数与FPR没有直接的计算关系,但两者都受到混淆矩阵组成的影响。通常,降低FPR有助于提高精确率,但可能会降低召回率,从而影响F1分数。
6. 实践案例分析:不同领域的FPR应用 🔎
6.1 医疗诊断案例:乳腺癌筛查
在乳腺癌筛查中,医生面临着平衡假阳性和假阴性的挑战:
案例数据:
- 10,000名受检者中,100人实际患有乳腺癌
- 传统筛查方法:TPR=85%,FPR=7%
- 改进筛查方法:TPR=85%,FPR=3%
分析:
- 传统方法:FP = 693人(10,000-100)× 7% = 693人被误判为患病
- 改进方法:FP = 297人(10,000-100)× 3% = 297人被误判为患病
- 改进减少了396人的不必要活检和焦虑
启示:在保持相同检出率的情况下,降低FPR可以显著减少不必要的医疗干预和患者负担。
6.2 欺诈检测案例:信用卡交易
信用卡欺诈检测系统需要在用户体验和风险控制之间取得平衡:
案例数据:
- 某银行每天处理100万笔交易,其中约1,000笔为欺诈交易
- 初始模型:TPR=92%,FPR=2%
- 优化模型:TPR=90%,FPR=0.5%
分析:
- 初始模型:FP = 19,980笔(1,000,000-1,000)× 2% = 19,980笔正常交易被拒绝
- 优化模型:FP = 4,995笔(1,000,000-1,000)× 0.5% = 4,995笔正常交易被拒绝
- 欺诈检出:初始模型检出920笔,优化模型检出900笔
权衡:优化模型虽然漏检了20笔欺诈,但减少了约15,000笔误报,大幅提升了用户体验和运营效率。
6.3 安全检测案例:入侵检测系统
网络入侵检测系统(IDS)需要在安全性和可用性之间寻找平衡点:
案例数据:
- 企业网络每天产生1000万条日志,其中约100条表示真实攻击
- 传统规则型IDS:TPR=95%,FPR=1%
- 机器学习增强IDS:TPR=93%,FPR=0.1%
分析:
- 传统IDS:FP = 99,990条(10,000,000-100)× 1% = 99,990条日志被误报
- 机器学习IDS:FP = 9,999条(10,000,000-100)× 0.1% = 9,999条日志被误报
- 安全事件处理:假设每条警报平均需要5分钟处理,传统IDS需要8,333小时,机器学习IDS需要833小时
影响:降低FPR使得安全团队可以将注意力集中在真正的威胁上,显著提高响应效率。
6.4 推荐系统案例:内容过滤
内容推荐系统需要平衡相关性和多样性:
案例数据:
- 视频平台每天向用户推荐100个视频
- 初始推荐算法:相关内容比例70%,FPR=30%
- 优化推荐算法:相关内容比例80%,FPR=20%
分析:
- 初始算法:每天向用户推送30个不相关视频
- 优化算法:每天向用户推送20个不相关视频
- 用户参与度:实验表明优化算法使观看时长增加15%,用户留存率提高7%
结论:降低FPR(减少不相关内容推送)能显著提升用户体验和平台关键指标。
7. FPR优化策略:实践指南 🛠️
7.1 阈值调整策略
调整决策阈值是控制FPR最直接的方法:
基本原理:
- 提高阈值:降低FPR,但可能降低TPR
- 降低阈值:提高TPR,但可能增加FPR
优化方法:
-
代价敏感学习:根据不同类型错误的成本设置最优阈值
# 示例:根据成本比例调整阈值 def find_optimal_threshold(y_true, y_scores, cost_ratio): """ cost_ratio: FP成本/FN成本的比值 """ fpr, tpr, thresholds = roc_curve(y_true, y_scores) cost = cost_ratio * fpr * (1-prevalence) + (1-tpr) * prevalence return thresholds[np.argmin(cost)] -
分类器校准:使用Platt缩放或等分箱等方法校准概率输出
-
阈值网格搜索:测试不同阈值,选择满足业务FPR要求的最佳阈值
7.2 特征工程优化
优化特征可以从根本上提高模型的区分能力,减少FPR:
有效策略:
- 特征选择:使用方法如递归特征消除(RFE)、LASSO正则化选择最具区分性的特征
- 特征变换:使用变换方法增强特征的表达能力,如对数变换、多项式特征
- 特征交叉:创建交互特征捕捉变量间的非线性关系
- 领域特定特征:基于业务知识设计专用特征
案例:在欺诈检测中,加入交易时间特征(如与用户典型交易时间的偏差)可以显著降低FPR,因为欺诈往往发生在异常时间。
7.3 模型选择与集成学习
不同模型对FPR的控制能力各不相同:
模型选择考量:
- 决策树:可通过调整叶节点纯度参数控制FPR
- SVM:通过核函数和正则化参数优化决策边界
- 概率模型:如逻辑回归,提供良好的概率校准,便于阈值调整
- 深度学习:复杂模型可以捕捉高级特征,但需要特别注意过拟合
集成策略:
- 硬投票:多数投票可降低单个分类器的极端错误
- 软投票:加权概率组合,可设计特定权重控制FPR
- 级联分类器:序列化多个分类器,前面的分类器专注于低FPR
# 示例:使用级联分类器控制FPR
class CascadeClassifier:
def __init__(self, classifiers, thresholds):
self.classifiers = classifiers
self.thresholds = thresholds
def predict(self, X):
# 初始所有样本为负类
predictions = np.zeros(X.shape[0])
# 逐级分类
for clf, threshold in zip(self.classifiers, self.thresholds):
# 仅对当前预测为负的样本进行再次预测
neg_idx = np.where(predictions == 0)[0]
if len(neg_idx) == 0:
break
# 获取概率
probs = clf.predict_proba(X[neg_idx])[:, 1]
# 高于阈值的预测为正
positives = probs >= threshold
predictions[neg_idx[positives]] = 1
return predictions
7.4 类不平衡处理
在类不平衡数据集上,模型往往偏向多数类,影响FPR:
常用方法:
-
重采样技术:
- 欠采样(Undersampling):减少多数类样本
- 过采样(Oversampling):增加少数类样本,如SMOTE算法
- 混合采样:结合两种方法的优势
-
代价敏感学习:
- 为不同类型错误分配不同权重
- 在训练过程中惩罚FP错误
-
调整类权重:
# 示例:调整类权重控制FPR from sklearn.linear_model import LogisticRegression # 假设正类样本较少 # 增加负类权重可以减少FP(减少FPR) clf = LogisticRegression(class_weight={0: 2, 1: 1}) clf.fit(X_train, y_train) -
异常检测方法:
- 一类SVM、隔离森林等专门针对异常检测的算法能更好地控制FPR
- 适用于正类样本极少的场景(如网络安全中的攻击检测)
适当处理类不平衡问题可以显著降低FPR,尤其是在正类样本稀少的场景下(如欺诈检测、疾病诊断等)。
8. 代码实现与实例 💻
8.1 使用Python实现FPR计算与分析
下面是一个完整的Python代码示例,展示如何计算FPR并绘制ROC曲线:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, roc_auc_score, confusion_matrix
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
# 生成示例数据集
X, y = make_classification(n_samples=1000, n_classes=2, weights=[0.9, 0.1],
random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练模型
clf = RandomForestClassifier(random_state=42)
clf.fit(X_train, y_train)
y_scores = clf.predict_proba(X_test)[:, 1]
# 计算ROC曲线
fpr, tpr, thresholds = roc_curve(y_test, y_scores)
auc = roc_auc_score(y_test, y_scores)
# 绘制ROC曲线
plt.figure(figsize=(10, 6))
plt.plot(fpr, tpr, color='blue', label=f'ROC曲线 (AUC = {auc:.3f})')
plt.plot([0, 1], [0, 1], color='red', linestyle='--', label='随机猜测')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('假阳性率 (FPR)')
plt.ylabel('真阳性率 (TPR)')
plt.title('ROC曲线分析')
plt.legend(loc="lower right")
plt.grid(True)
# 查找不同FPR值对应的阈值和TPR
target_fprs = [0.01, 0.05, 0.1]
for target_fpr in target_fprs:
idx = np.argmin(np.abs(fpr - target_fpr))
plt.plot(fpr[idx], tpr[idx], 'ro')
plt.annotate(f'FPR={fpr[idx]:.3f}, TPR={tpr[idx]:.3f}, 阈值={thresholds[idx]:.3f}',
(fpr[idx], tpr[idx]), xytext=(fpr[idx]+0.1, tpr[idx]-0.1),
arrowprops=dict(arrowstyle='->'))
plt.show()
# 计算特定阈值下的混淆矩阵
def calculate_metrics(y_true, y_scores, threshold):
y_pred = (y_scores >= threshold).astype(int)
cm = confusion_matrix(y_true, y_pred)
TN, FP, FN, TP = cm.ravel()
fpr = FP / (FP + TN)
tpr = TP / (TP + FN)
precision = TP / (TP + FP) if (TP + FP) > 0 else 0
return {'阈值': threshold, 'FPR': fpr, 'TPR': tpr, '精确率': precision}
# 分析不同阈值的效果
thresholds_to_try = [0.3, 0.5, 0.7, 0.9]
results = []
for threshold in thresholds_to_try:
results.append(calculate_metrics(y_test, y_scores, threshold))
# 打印结果
print("\n阈值调整对FPR的影响:")
for res in results:
print(f"阈值={res['阈值']:.1f}: FPR={res['FPR']:.3f}, TPR={res['TPR']:.3f}, 精确率={res['精确率']:.3f}")
这段代码展示了:
- 如何生成和预处理数据
- 如何训练模型并获取预测概率
- 如何计算和可视化ROC曲线
- 如何分析不同阈值对FPR的影响
- 如何根据业务需求选择最佳阈值
8.2 FPR优化案例:信用风险评估
以下是一个实际的信用风险评估案例,展示如何优化FPR:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import confusion_matrix, classification_report
# 假设我们已加载信用评估数据集
# X包含特征,y是标签(1表示违约,0表示正常)
# 特征工程
X_engineered = X.copy()
# 添加新特征:收入负债比
X_engineered['income_to_debt'] = X['income'] / (X['debt'] + 1)
# 添加新特征:历史逾期次数/账龄
X_engineered['delinquency_ratio'] = X['delinquency_count'] / (X['account_age_months'] + 1)
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(
X_engineered, y, test_size=0.3, random_state=42, stratify=y)
# 标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 训练基础模型
base_model = GradientBoostingClassifier(random_state=42)
base_model.fit(X_train_scaled, y_train)
base_scores = base_model.predict_proba(X_test_scaled)[:, 1]
# 设定业务目标:FPR不超过5%
target_fpr = 0.05
# 找出满足FPR要求的最佳阈值
fpr, tpr, thresholds = roc_curve(y_test, base_scores)
best_idx = np.argmax(tpr[fpr <= target_fpr])
best_threshold = thresholds[best_idx]
best_fpr = fpr[best_idx]
best_tpr = tpr[best_idx]
print(f"最佳阈值: {best_threshold:.3f}")
print(f"对应FPR: {best_fpr:.3f}")
print(f"对应TPR: {best_tpr:.3f}")
# 使用最佳阈值进行预测
y_pred = (base_scores >= best_threshold).astype(int)
cm = confusion_matrix(y_test, y_pred)
print("\n混淆矩阵:")
print(cm)
print("\n分类报告:")
print(classification_report(y_test, y_pred))
# 计算业务影响
# 假设每个假阳性成本为$1000(拒绝好客户)
# 假设每个假阴性成本为$5000(接受坏客户)
fp_cost = 1000
fn_cost = 5000
TN, FP, FN, TP = cm.ravel()
total_cost = FP * fp_cost + FN * fn_cost
print(f"\n业务成本分析:")
print(f"假阳性数量: {FP}, 成本: ${FP * fp_cost}")
print(f"假阴性数量: {FN}, 成本: ${FN * fn_cost}")
print(f"总成本: ${total_cost}")
# 进一步优化:使用代价敏感学习
sample_weights = np.ones(len(y_train))
# 加大对假阴性的惩罚
sample_weights[y_train == 1] *= (fn_cost / fp_cost)
# 训练代价敏感模型
cost_model = GradientBoostingClassifier(random_state=42)
cost_model.fit(X_train_scaled, y_train, sample_weight=sample_weights)
cost_scores = cost_model.predict_proba(X_test_scaled)[:, 1]
# 分析代价敏感模型
fpr_cost, tpr_cost, thresholds_cost = roc_curve(y_test, cost_scores)
best_idx_cost = np.argmax(tpr_cost[fpr_cost <= target_fpr])
best_threshold_cost = thresholds_cost[best_idx_cost]
y_pred_cost = (cost_scores >= best_threshold_cost).astype(int)
cm_cost = confusion_matrix(y_test, y_pred_cost)
TN_cost, FP_cost, FN_cost, TP_cost = cm_cost.ravel()
total_cost_optimized = FP_cost * fp_cost + FN_cost * fn_cost
print("\n优化后模型表现:")
print(f"假阳性数量: {FP_cost}, 成本: ${FP_cost * fp_cost}")
print(f"假阴性数量: {FN_cost}, 成本: ${FN_cost * fn_cost}")
print(f"总成本: ${total_cost_optimized}")
print(f"成本节约: ${total_cost - total_cost_optimized} ({(total_cost - total_cost_optimized)/total_cost*100:.1f}%)")
这个案例展示了:
- 如何进行针对性的特征工程
- 如何根据业务目标设置FPR阈值
- 如何将FPR与业务成本结合分析
- 如何通过代价敏感学习进一步优化模型
9. 常见问题与解决方案 ❓
9.1 FPR和TPR之间的权衡
问题:在实际应用中,降低FPR通常会导致TPR下降,如何找到最佳平衡点?
解决方案:
- 业务导向阈值选择:基于业务目标设定可接受的FPR范围,在此范围内最大化TPR
- 代价函数:设计综合考虑FP和FN成本的代价函数,寻找总成本最小的点
- 部分AUC优化:专注优化ROC曲线中低FPR区域的性能
- 分段模型:对不同风险等级使用不同模型,高风险区域使用低FPR优先的策略
9.2 类不平衡数据下FPR的计算与解释
问题:在极度不平衡的数据集中(如欺诈检测,正类占比<1%),FPR的解释和优化存在挑战。
解决方案:
- 分层采样验证:确保测试集中包含足够的少数类样本,使FPR计算更可靠
- 基于业务的评估:结合业务指标(如每1000次交易的假警报数)解释FPR
- 置信区间:计算FPR的置信区间,评估其统计稳定性
- 多指标组合:将FPR与其他指标(如精确率-召回率曲线)结合使用
9.3 不同领域FPR的差异化处理
问题:不同应用领域对FPR的需求和处理策略存在显著差异。
解决方案:
| 领域 | FPR关注点 | 优化策略 |
|---|---|---|
| 医疗诊断 | 降低不必要治疗 | 多级诊断流程,结合多模态数据 |
| 欺诈检测 | 平衡用户体验与安全 | 动态阈值,分场景模型 |
| 网络安全 | 减少警报疲劳 | 事件关联分析,上下文感知检测 |
| 内容过滤 | 避免过滤有价值内容 | 个性化阈值,用户反馈学习 |
关键是要根据具体应用场景的特点和业务需求,定制FPR处理策略,而非采用通用解决方案。
9.4 模型部署后FPR的漂移问题
问题:模型部署到生产环境后,随着时间推移和数据分布变化,FPR可能发生漂移。
解决方案:
- 持续监控:建立FPR监控系统,设置警报阈值
- 定期重训练:根据新数据更新模型,适应分布变化
- 模型后校准:使用生产数据重新校准模型阈值
- A/B测试:在生产环境中持续测试不同阈值的效果
- 渐进式部署:新模型逐步替换旧模型,控制风险
# 模型监控示例代码
def monitor_fpr_drift(model, new_data, ground_truth, historical_fpr, alert_threshold=0.02):
"""
监控模型FPR是否发生显著漂移
参数:
model: 已部署的模型
new_data: 新收集的数据
ground_truth: 新数据的真实标签
historical_fpr: 历史FPR值
alert_threshold: FPR变化的警报阈值
返回:
drift_detected: 是否检测到漂移
current_fpr: 当前FPR值
"""
# 获取预测结果
predictions = model.predict(new_data)
# 计算混淆矩阵
cm = confusion_matrix(ground_truth, predictions)
TN, FP, FN, TP = cm.ravel()
# 计算当前FPR
current_fpr = FP / (FP + TN) if (FP + TN) > 0 else 0
# 检测漂移
drift_detected = abs(current_fpr - historical_fpr) > alert_threshold
return drift_detected, current_fpr
10. 未来发展趋势与研究方向 🚀
10.1 自适应阈值技术
传统固定阈值方法难以应对动态环境,未来研究将更多聚焦于自适应阈值技术:
- 在线学习阈值:基于实时反馈调整模型阈值
- 上下文感知阈值:根据不同场景和用户特征动态调整阈值
- 多目标优化阈值:同时考虑多个性能指标的自动阈值调整
这些技术将使模型能够更加智能地平衡FPR和TPR,适应不同环境和需求的变化。
10.2 可解释AI与FPR
随着可解释性在AI中的重要性提升,未来研究将更多关注FPR的可解释性:
- 错误案例分析:系统性地分析和解释假阳性案例的原因
- 特征归因:识别导致高FPR的关键特征及其影响机制
- 可解释的FPR控制:在保持模型可解释性的前提下优化FPR
- 人机协作决策:结合人类专家判断与模型预测,降低系统整体FPR
这些研究将帮助用户更好地理解和信任模型的决策过程,特别是在高风险应用场景中。
10.3 跨域迁移学习与FPR
随着迁移学习的发展,研究人员正在探索如何在不同领域间迁移FPR控制策略:
- 领域适应技术:调整源域模型以适应目标域的FPR要求
- 元学习框架:学习"如何学习"控制FPR的通用策略
- 少样本FPR优化:在目标域数据有限的情况下优化FPR
- 联邦学习中的FPR控制:在保护隐私的前提下协作优化FPR
这些研究将使得在新领域或数据有限的情况下,模型也能快速达到理想的FPR水平。
10.4 多模态融合与FPR
未来的AI系统将越来越多地依赖多模态数据,这为FPR控制带来新的机遇与挑战:
- 模态间协同过滤:利用不同模态数据互补优势降低FPR
- 多级决策流程:结合不同模态的模型构建级联决策系统
- 自动模态选择:智能选择最适合当前场景的数据模态
- 多模态解释框架:跨模态解释假阳性案例,提高系统透明度
多模态方法有望显著提高系统对复杂场景的理解能力,进一步降低FPR。
11. 总结与实践建议 📝
11.1 理论与实践的关键点
假阳性率(FPR)是机器学习中一个至关重要的评估指标,其核心要点包括:
- 定义:FPR = FP / (FP + TN),表示负类被错误预测为正类的比例
- 重要性:在许多应用中,假阳性会带来明显的成本和负面影响
- 权衡:FPR与TPR通常存在权衡关系,需要根据业务目标找到平衡点
- 优化方法:包括阈值调整、特征工程、模型选择和处理类不平衡问题
- 应用场景:不同领域对FPR有不同需求,需要定制化策略
11.2 实践建议清单
基于本文内容,我们总结出以下实践建议:
- 明确业务目标:根据业务需求设定可接受的FPR范围,不盲目追求低FPR
- 合理评估成本:量化假阳性和假阴性的实际成本,指导模型优化
- 多指标综合评价:结合FPR、TPR、精确率等多维度评估模型性能
- 分层阈值策略:对不同风险等级或用户群体采用差异化阈值
- 持续监控与更新:建立FPR监控系统,定期更新模型应对数据漂移
- 人机结合:重要决策结合算法建议和人工判断,降低整体FPR
- 场景化验证:在真实或近似真实的应用场景中验证模型FPR表现
- 文档与沟通:清晰记录FPR相关决策和优化过程,促进团队理解和协作
11.3 结语
假阳性率作为机器学习中的核心评估指标,其重要性不言而喻。随着人工智能技术在各行各业的深入应用,对FPR的精细控制将成为模型成功落地的关键因素之一。希望本文能帮助读者深入理解FPR的理论基础和实践策略,在实际工作中更好地平衡模型性能与业务需求,构建更加高效、可靠的AI系统。
无论是新手还是资深从业者,都应当将FPR控制视为模型开发过程中的核心任务,而非事后的调优手段。只有将FPR纳入整个机器学习流程的各个环节,才能开发出既准确又实用的模型,真正发挥人工智能的价值和潜力。
参考资源
- 机器学习的最佳实践 - GitHub Repository, goodchinas/pyquant.
- 机器学习评估指标的十个常见面试问题 - 知乎专栏.
- 真假阳性问题的模型构建与优化 - CSDN博客, universsky2015.
- 机器学习模型性能的10个指标 - 360doc文档.

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 20
20 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)