tensorflow学习记录6——构建深度学习神经网络1
Sequential模型的基本组件有5个部分:model.add()、model.compile()、model.fit()、model.evaluate()、model.predict()。将输入层、隐藏层、输出层按需等添加进Sequential容器,Sequential模型的核心操作是添加layers(图层),是简单的线性、从头到尾的顺序结构。tensor:可选参数,若指定,该层将使用这个张量
一、如何构建以上网络的输入层、隐藏层、输出层,使用哪些函数,函数语法规则怎样?
1、输入层:tf.keras.Input()函数
tf.keras.Input( shape=None, batch_size=None, name=None, dtype=None, sparse=False, tensor=None, ragged=False, **kwargs )
参数说明:
shape:输入的形状,不包含批量大小维度。比如 (32, 32, 3) 可用于代表 32x32 像素且有 3 个颜色通道的图像输入。 batch_size:可选参数,指批量大小的整数。一般默认是 None,表示批量大小可变。 name:可选参数,该输入层的名称,为字符串类型。 dtype:输入数据的数据类型,例如 tf.float32。 sparse:布尔值,若为 True,表示输入数据是稀疏张量。 tensor:可选参数,若指定,该层将使用这个张量作为输入,而非创建新的占位符张量。 ragged:布尔值,若为 True,表明输入是不规则张量。
2、隐藏层:用于构建全连接层的函数tf.keras.layers.Dense()函数
tf.keras.layers.Dense(units, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None, **kwargs)
参数说明:
units: 神经元个数; activation: 激活函数; use_bias: 是否使用偏置项。默认为使用; kernel_initializer: 创建层权重核的初始化方案; bias_initializer: 创建层权重偏置的初始化方案; kernel_regularizer: 应用层权重核的正则化方案; bias_regularizer: 应用层权重偏置的正则化方案; activity_regularizer:施加在输出上的正则项,为Regularizer对象; kernel_constraint: 施加在权重上的约束项; bias_constraint: 施加在权重上的约束项。
3、输出层:可以根据实际应用场景,使用tf.keras.layers.Dense()函数灵活构建输出层
输出层会根据解决的任务类型灵活设置。
例 : 构建如下网络+
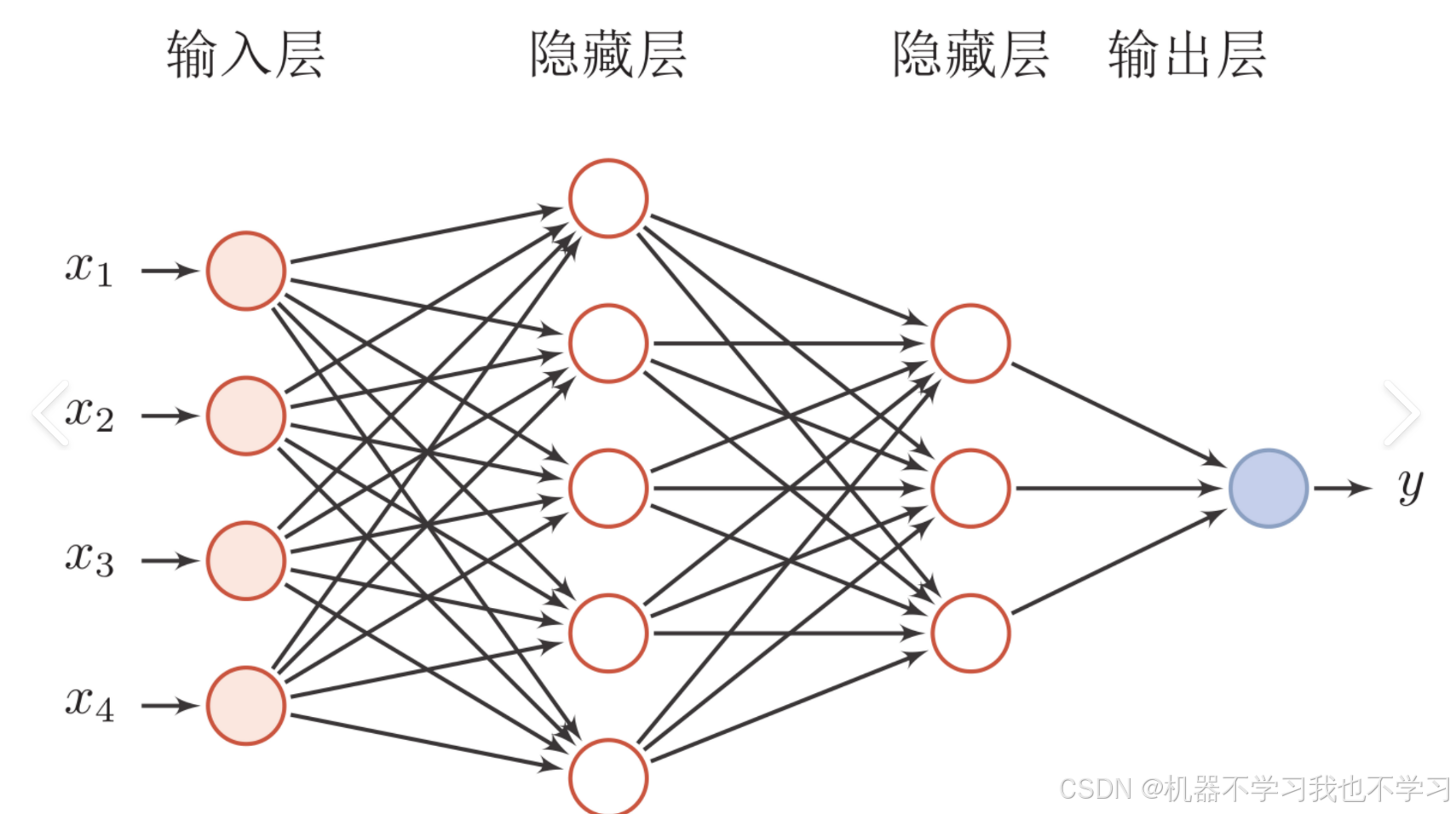
代码如下:
import tensorflow as tf
# 定义输入层,仅接受原始数据,不做函数处理
inputs = tf.keras.Input(shape=(4,))
# 第一个隐藏层,包含5个神经元,使用ReLU激活函数,Dense 表示全连接层
hidden_layer_1 = tf.keras.layers.Dense(5, activation='relu')(inputs)
# 第二个隐藏层,包含3个神经元,使用ReLU激活函数
hidden_layer_2 = tf.keras.layers.Dense(3, activation='relu')(hidden_layer_1)
# 输出层,包含1个神经元,不使用激活函数(适用于回归任务)
outputs = tf.keras.layers.Dense(1)(hidden_layer_2)
# 创建模型,将前面定义的输入层和输出层关联起来,构建完整的神经网络模型
model = tf.keras.Model(inputs=inputs, outputs=outputs)
4、构建Sequential网络
将输入层、隐藏层、输出层按需等添加进Sequential容器,Sequential模型的核心操作是添加layers(图层),是简单的线性、从头到尾的顺序结构。
Sequential模型的基本组件有5个部分:model.add()、model.compile()、model.fit()、model.evaluate()、model.predict()。
如构建以上图片中的网络结构,代码如下:
import tensorflow as tf
# 使用Sequential模型
model = tf.keras.Sequential([
# 输入层,指定输入形状为4
tf.keras.layers.InputLayer(input_shape=(4,)),
# 第一个隐藏层,5个神经元,ReLU激活函数
tf.keras.layers.Dense(5, activation='relu'),
# 第二个隐藏层,3个神经元,ReLU激活函数
tf.keras.layers.Dense(3, activation='relu'),
# 输出层,1个神经元(回归任务无激活函数)
tf.keras.layers.Dense(1)
])
构建Sequential网络过程中可以添加的图层:
卷积层
model.add(Conv2D(64, (3, 3), activation='relu'))
最大池化层
model.add(MaxPooling2D(pool_size=(4, 4)))
全连接层
model.add(Dense(4, activation='relu'))
dropout
model.add(Dropout(0.5))
Flattening layer(展平层)
model.add(Flatten())
参考:
理解keras中的sequential模型-CSDN博客![]() https://blog.csdn.net/mogoweb/article/details/82152174
https://blog.csdn.net/mogoweb/article/details/82152174
二、构建完网络后需编译网络
1、使用model.compile()函数编译网络
model.compile(
optimizer,
loss=None,
metrics=None,
loss_weights=None,
sample_weight_mode=None,
weighted_metrics=None,
target_tensors=None,
distribute=None,
experimental_run_tf_function=True,
steps_per_execution=None
)
主要
参数说明:
optimizer:优化器,用于控制梯度裁剪。必选项 loss:损失函数(或称目标函数、优化评分函数)。必选项 metrics:评价函数用于评估当前训练模型的性能。当模型编译后(compile),评价函数应该作为 metrics 的参数来输入。评价函数和损失函数相似,只不过评价函数的结果不会用于训练过程中。
代码如下:
# 编译模型,指定adam 优化器来更新模型权重、均方误差损失函数 model.compile(optimizer='adam', loss='mse')
2、在编译环节需要设置好 优化器 和 损失函数 等相关参数
1)常见优化器:
SGD:随机梯度下降优化器,随机梯度下降是一种基本的优化算法,通过迭代更新模型参数来最小化损失函数。 # 实例化SGD优化器 sgd = tf.keras.optimizers.SGD(learning_rate=0.1, momentum=0.9, nesterov=True,name='SGD',**kwargs) 主要参数: learning_rate: 学习率,默认为 0.001。 momentum float 超参数 >= 0,加速相关方向的梯度下降并抑制振荡。默认为 0,即普通梯度下降。 nesterov 布尔值。是否应用 Nesterov 动量。默认为 False 。 name 应用渐变时创建的操作的可选名称前缀。默认为 "SGD" 。 **kwargs 关键字参数。允许是 "clipnorm" 或 "clipvalue" 之一。 "clipnorm" (float) 按标准裁剪渐变; "clipvalue" (float) 按值裁剪渐变。 RMSprop:一种自适应学习率的优化算法,通过调整学习率来加速收敛过程。 # 创建 RMSprop 优化器 opt = tf.keras.optimizers.RMSprop(learning_rate=0.1) 主要参数: learning_rate: 学习率,默认为 0.001。 rho: 历史梯度的折扣因子,默认为 0.9。 momentum: 动量,默认为 0.0。 epsilon: 用于数值稳定性的小常数,默认为 1e-7。 centered: 布尔值,是否通过梯度的估计方差对梯度进行归一化,默认为 False。 Adagrad:一种自适应学习率的优化算法,通过调整学习率来加速收敛过程。 # 创建 Adagrad 优化器 adagrad = tf.keras.optimizers.Adagrad(lr=0.01, epsilon=None, decay=0.0) 主要参数: learning_rate: float >= 0. 学习率. epsilon: float >= 0. 若为 None, 默认为 K.epsilon(). decay: float >= 0. 每次参数更新后学习率衰减值. Adam:一种结合了RMSprop和Momentum的优化算法,具有较好的性能和稳定性。 # 创建Adam优化器tf.keras.optimizers.Adam(learning_rate=0.001,beta_1=0.9,beta_2=0.999,epsilon=1e-7,amsgrad=False,name="Adam",**kwargs) 主要参数: learning_rate: 学习率,默认为0.001。 beta_1: 0到1之间,一般接近于1 beta_2: 0到1之间,一般接近于1,和beta_1一样,使用默认的就好 epsilon: 模糊因子,如果为空,默认为k.epsilon() decay: 每次参数更新后学习率的衰减值(每次更新时学习率下降) amsgrad: 布尔型,是否使用AMSGrad变体
2)常见损失函数:
MAE
MSE
二元交叉熵损失函数
稀疏类别交叉熵损失函数
三、传入训练数据对模型进行训练
1、使用model.fit()函数对模型进行训练
model.fit(x, y, batch_size, epochs, verbose, validation_split, validation_data, validation_freq) 主要参数: x: 输入数据。 y: 输出数据。 batch_size: 每个批次的大小,即每次网络训练所使用的样本数量。 epochs: 迭代次数,即所有样本数据将被训练多少次。 verbose: 日志显示模式,0 表示不输出训练过程,1 表示输出进度条,2 表示每个 epoch 输出一行记录。 validation_split: 用于从训练数据中分割出一部分作为验证数据。 validation_data: 指定验证数据集,会覆盖由 validation_split 参数分割出的验证数据。 validation_freq: 指定多少个 epoch 进行一次验证。 callbacks: 回调函数列表,用于在训练的不同阶段执行自定义的操作,如 EarlyStopping。
代码如下:
#训练网络
model.fit(x,y,batch_size=32,epochs=10)
2、在训练环节需要通过设置不同迭代次数、批大小等超参数,优化网络。
超参数的选择通常是一个试错的过程,需要根据经验和领域知识进行调整。
1)迭代次数
迭代次数指传入数据后网络训练的轮次,这个参数不是越大越好,也不是越小越好,大了可能过拟合、可能训练时间长,小了可能模型效果差,可根据实际情况选择合适大小的epochs。
2)批大小
同时处理多个训练数据,称为批训练。在合理范围内,batch_size 越大,训练速度则越快,内存占用更大,而收敛速度变慢,下降方向越准确、引起的训练震荡越小。值特别小则会使训练速度变慢。
四、训练网络结束后,需要选择合适的评估指标对模型进行性能评估
1、模型评估的几个常用指标
AUC、准确率、精度、二进制精度、二进制交叉熵、分类精度、类别交叉熵、余弦相似度、假阴性、平均绝对误差、均方误差等。见课本53页。
可选用一个或多个对模型进行评估。
参考博客:https://blog.csdn.net/m0_49866160/article/details/136691637
2、介绍以下三种方式进行模型评估(以二分类问题准确率为例)
1)方式一:使用metrics模块的函数计算
tf.keras.metrics.BinaryAccuracy(
name='binary_accuracy',
dtype=None,
threshold=0.5
)
参数说明:
name:接收str类型的值。表示度量标准实例的字符串名字。
dtype:接收int、float等数据类型。表示度量标准结果的数据类型。
threshold:用于决定预测值为1或0的阈值。
代码如下:
import tensorflow as tf
y_true=[0, 0, 0, 1, 1, 0]
y_pred=[0.2, 0.3, 0.6, 0.7, 0.8, 0.1]
acc = tf.keras.metrics.BinaryAccuracy(name='accary',dtype=None,threshold=0.5)
acc_calc=acc(y_true,y_pred)
print(acc_calc)
2)方式二:结合compile来使用。
在模型编译函数model.compile()中,有一个参数可以设置评估指标(metrics参数)
代码如下:
model = tf.keras.Sequential()
model.compile(optimizer='adam', loss='mse',metrics=[tf.keras.metrics.BinaryAccuracy()])
3)方式三:使用model.evaluate()函数进行模型评估
代码如下:
model = tf.keras.Sequential()
loss , acc=model.evaluate(test_data,test_labels)

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 37
37 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)