带权无向图最小生成树算法
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。提示:以下是本篇文章正文内容,下面案例可供参考提示:这里对文章进行总结:例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
天天开心!!!
文章目录
- 一、无向图有权值的最小生成树怎么实现?
- 二、Prim算法(普利姆算法)
-
- 1.Prim算法的基本过程
- 2.Prim的代码实现
- 三、Kruskal算法(克鲁斯卡尔算法)
-
- 1. Kruskal算法的基本过程
- 2.Kruskal算法代码实现
- 四、结语
一、无向图有权值的最小生成树怎么实现?
前置知识:
1.无向图:无向图是一种由顶点和连接顶点的无方向边构成的图结构,表示实体之间无待定方向的关联关系。
2.有权值:指的是无向图中的边(或称为连接)具有某种数值或权重,也就是边上面带值。
以下就是一个带权图的简单示例: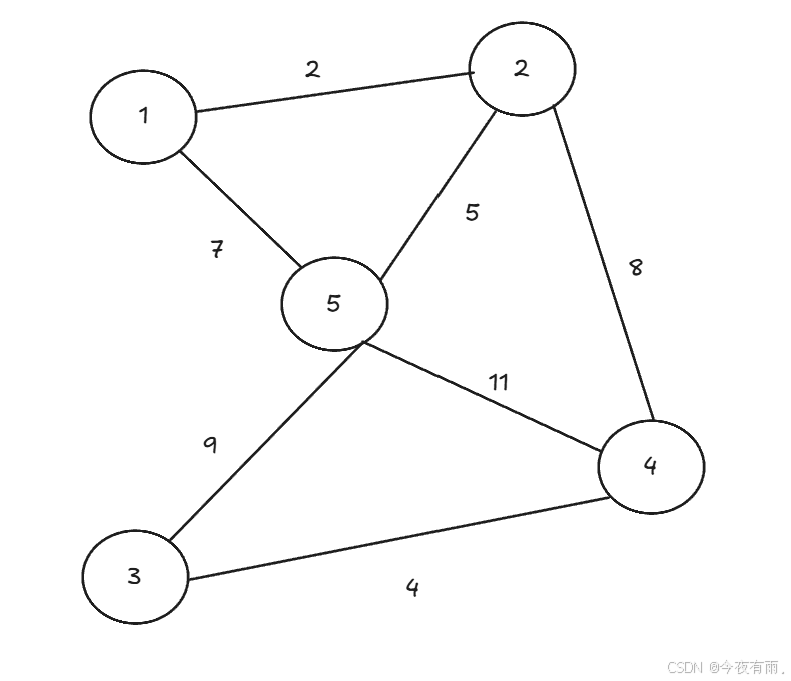
-
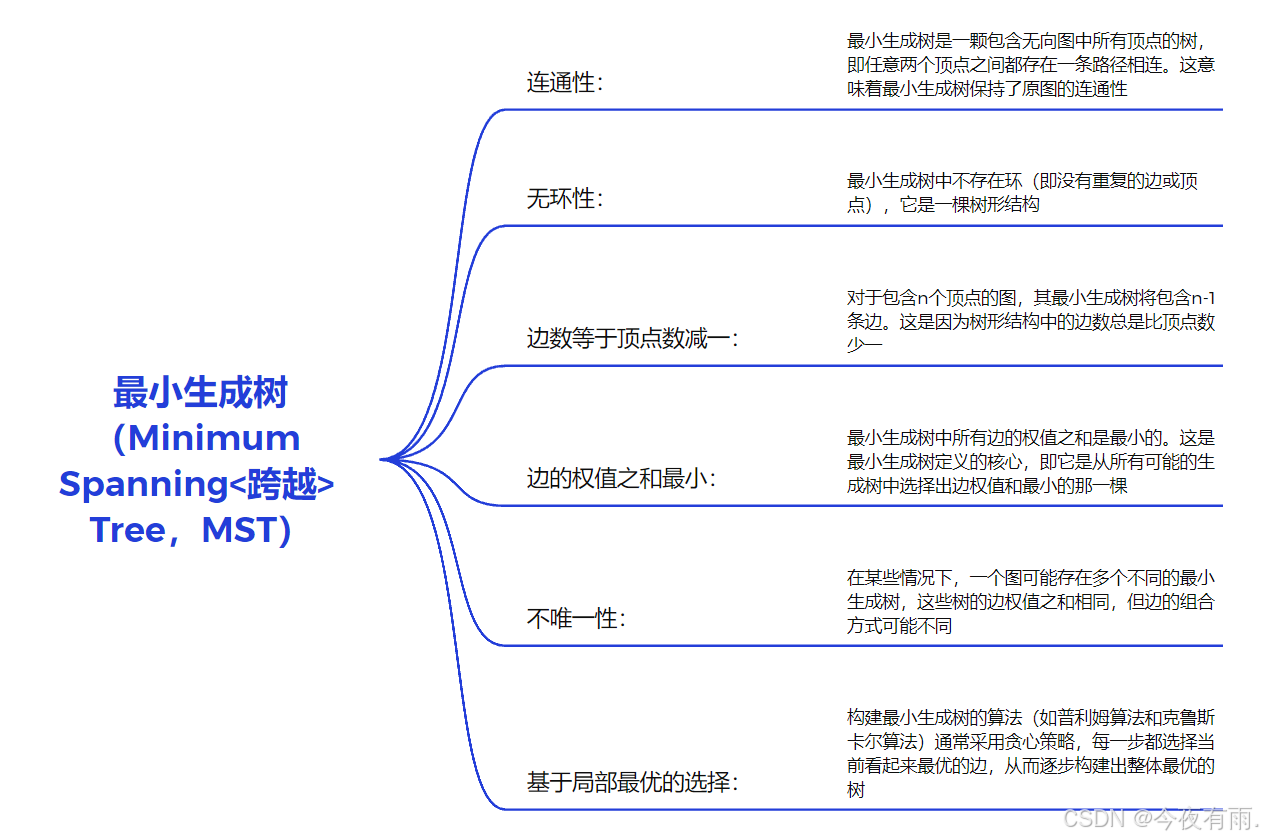
最小生成树(Minimum Spanning<跨越> Tree,MST)是什么样子的?
-
最小生成树的用途
最小生成树在许多实际应用中都有重要作用,如网络设计、电路设计、地图路由规划等。通过找到最小生成树,可以优化资源分配、降低成本或提高效率。 -
生成算法
无向图有权值的最小生成树通常可以通过两种经典的算法来实现:Prim算法和Kruskal算法。这两种算法都是基于贪心策略,但实现方式有所不同
二、Prim算法(普利姆算法)
1.Prim算法的基本过程
Prim算法从图的任意一个顶点开始,每次选择与当前生成树距离最短的顶点加入生成树,直到所有顶点都加入生成树为止
以下是Prim生成树的基本步骤
- 初始化:任意一个顶点加入生成树,并将其标记为已访问
- 选择顶点:在未访问的顶点中,选择距离生成树最近的顶点加入生成树,并将其标记为已访问
- 更新距离:更新所有未访问顶点到生成树的最小距离
- 重复步骤2和3,直到所有顶点都加入生成树为止
在实现时,可以使用一个数组来记录每个顶点到生成树的最小距离,以及一个数组或集合来记录顶点是否已被访问。另外,为了高效地选择距离生成树最近的顶点,可以使用优先队列(如二叉堆)来存储未访问顶点和它们到生成树的距离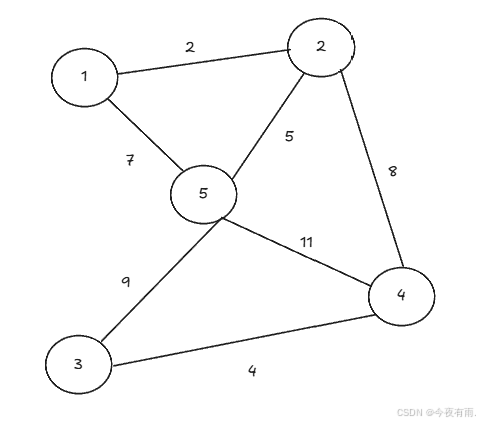
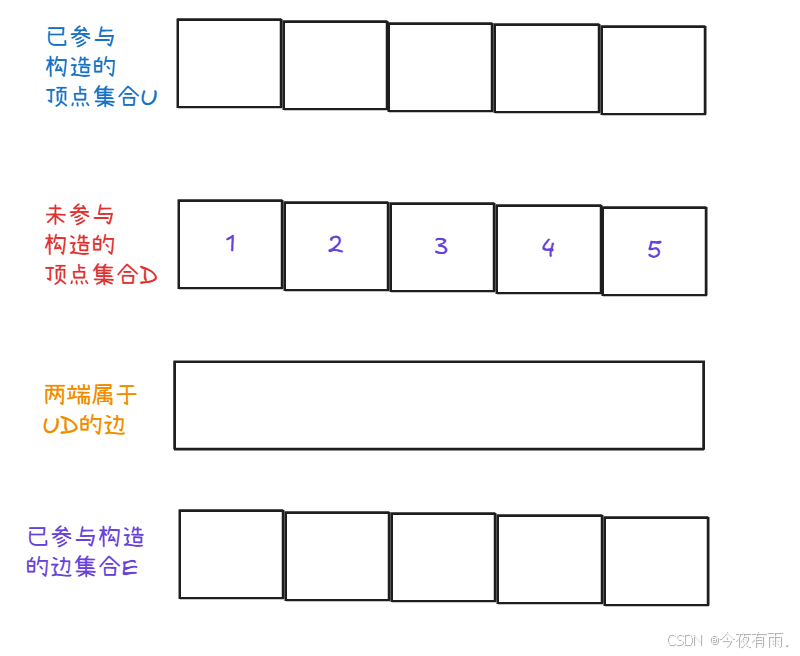
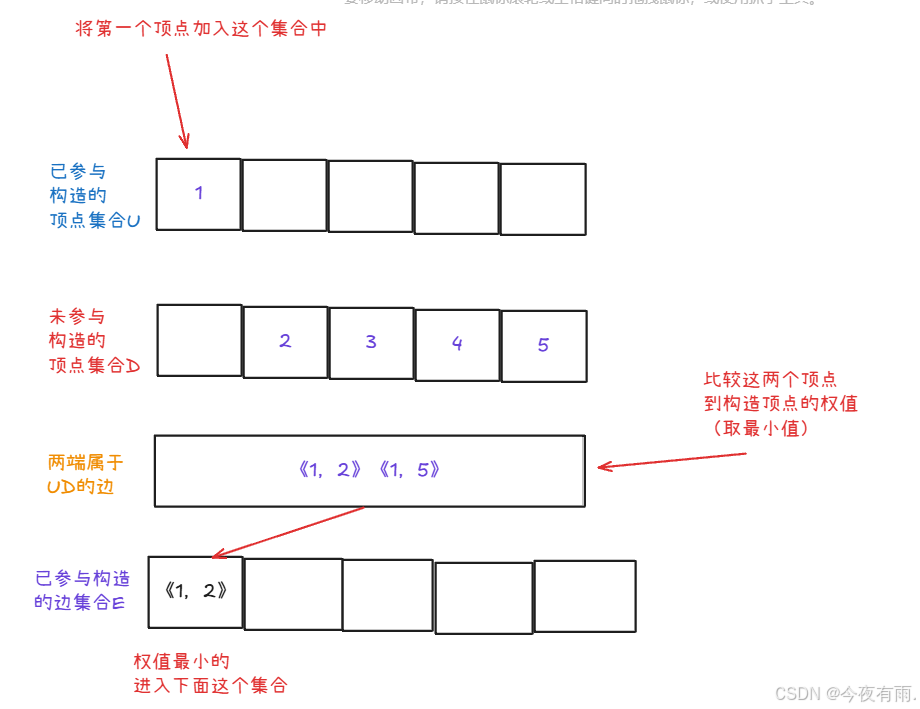
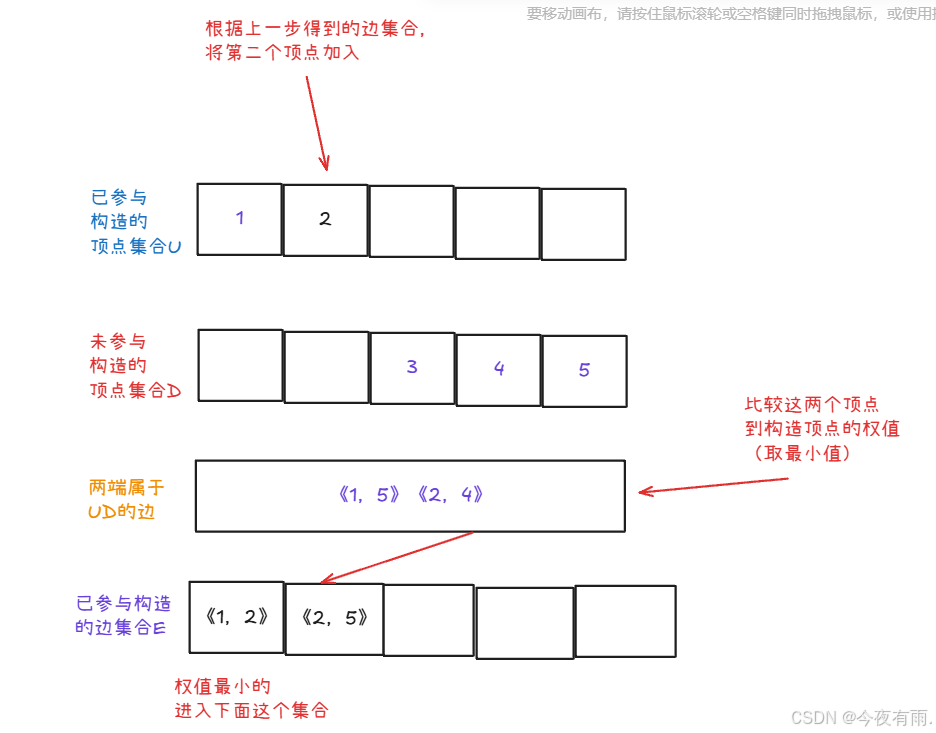
根据以上,我们按照这个逻辑将剩下的顶点加入到集合中
最后得出的的集合如下图所示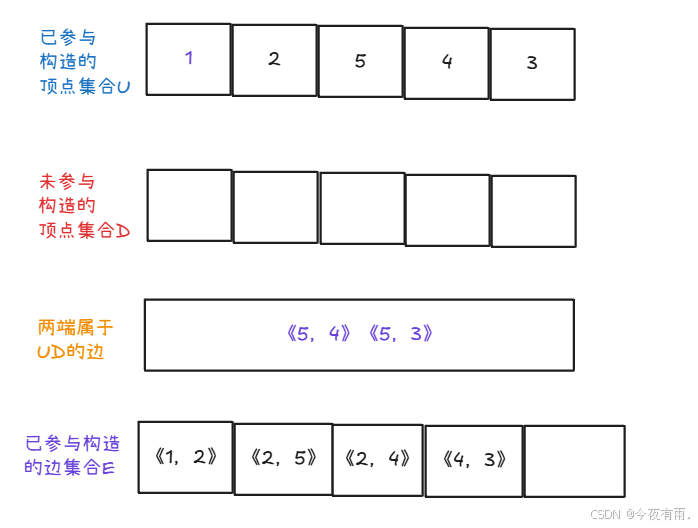
我们根据已参与构造的边集合E来构造带权无向图最小生成树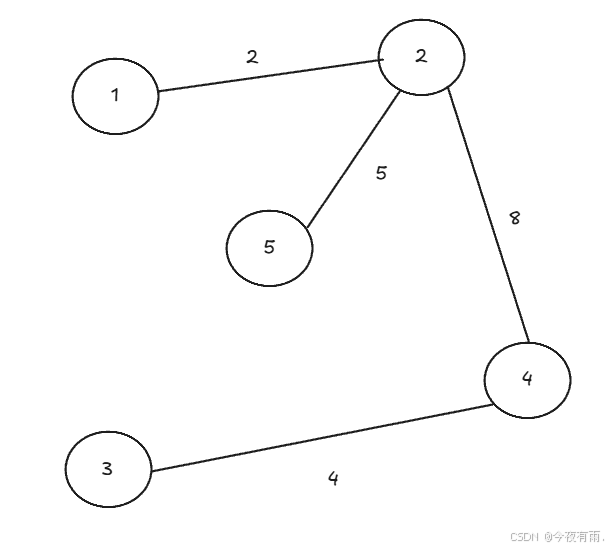
2.Prim的代码实现
以下是一个使用C++实现无向图最小生成树的Prim算法示例,在这个示例中,我们假设图是用邻接矩阵表示的,并且边的权重都是非负的。。
#include <iostream>
#include <vector>
#include <climits>
using namespace std;
//无向图类的定义
class Graph{
int V;//顶点个数
vector<vector<int>> adj;//邻接矩阵
public:
Graph(int V):V(V),adj(V,vector<int>(V,INT_MAX)){}//构造函数
//添加边和权重
void addEdge(int v,int w,int weight)
{
adj[v][w]=weight;
adj[w][v]=weight;//因为是无向图,所以两边都要设置
}
int primMST() {
vector<bool> inMST(V, false);
vector<int> key(V, INT_MAX);
key[0] = 0; // 起始点key设为0
int MSTcost = 0;
// 只需循环V-1次来选择边
for (int count = 0; count < V; count++) { // 循环V次确保所有顶点被处理
int u = -1;
// 选择当前key最小的顶点
for (int v = 0; v < V; v++) {
if (!inMST[v] && (u == -1 || key[v] < key[u])) {
u = v;
}
}
if (u == -1) return -1;
inMST[u] = true;
if (key[u] != INT_MAX) { // 避免起始点的0被累加
MSTcost += key[u];
}
// 更新相邻顶点的key值
for (int v = 0; v < V; v++) {
if (adj[u][v] != INT_MAX && !inMST[v] && adj[u][v] < key[v]) {
key[v] = adj[u][v];
}
}
}
return MSTcost;
}
};
int main()
{
//例子,5个顶点的无向图
int V=5;
Graph g(V);
g.addEdge(0, 1, 2);
g.addEdge(0, 2, 7);
g.addEdge(1, 2, 5);
g.addEdge(1, 3, 8);
g.addEdge(2, 3, 11);
g.addEdge(2, 4, 9);
g.addEdge(3, 4, 4);
//计算最小生成树的权值和
int minCost=g.primMST();
cout<<"最小生成树的权值和为:"<<minCost<<endl;
return 0;
}
三、Kruskal算法(克鲁斯卡尔算法)
1. Kruskal算法的基本过程
Kruskal算法从图的边开始,每次选择一条连接生成树中两个未连接顶点的最小权值边,直到生成树包含所有顶点为止。
以下是Kruskal算法的基本步骤
- 初始化:将图中的所有边按照权值从小到大排序
- 选择边:从排序后的边列表中,选择一条连接生成树中两个未连接顶点的边
- 检查环:检查选择的边是否会形成环。如果形成环,则跳过该边。否则就将其加入生成树
- 重复步骤2和3,直到生成树包含所有顶点或边列表为空为止。
我们还是以下图为例子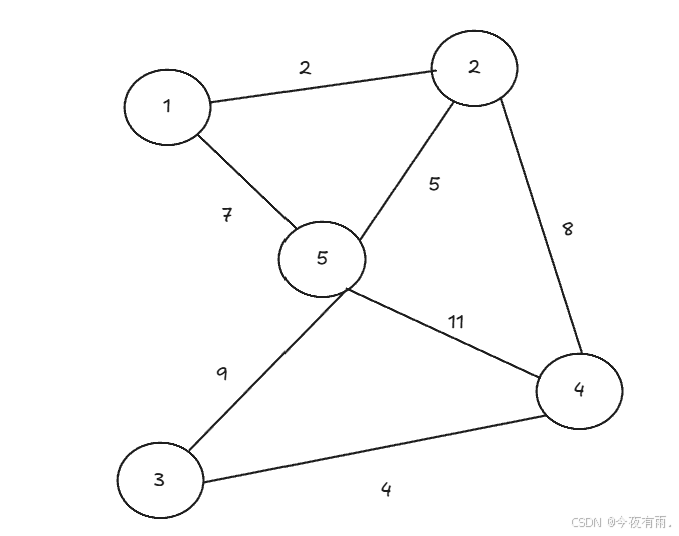
我们将权值进行排序,并放入到集合E中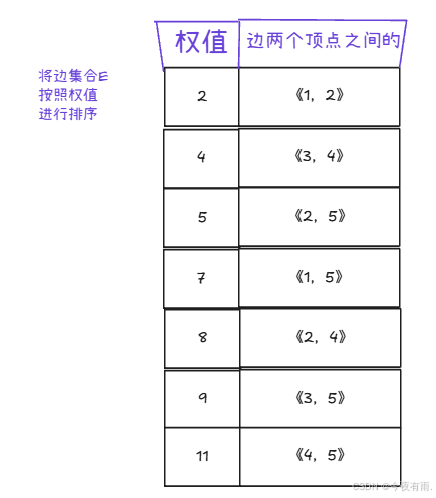
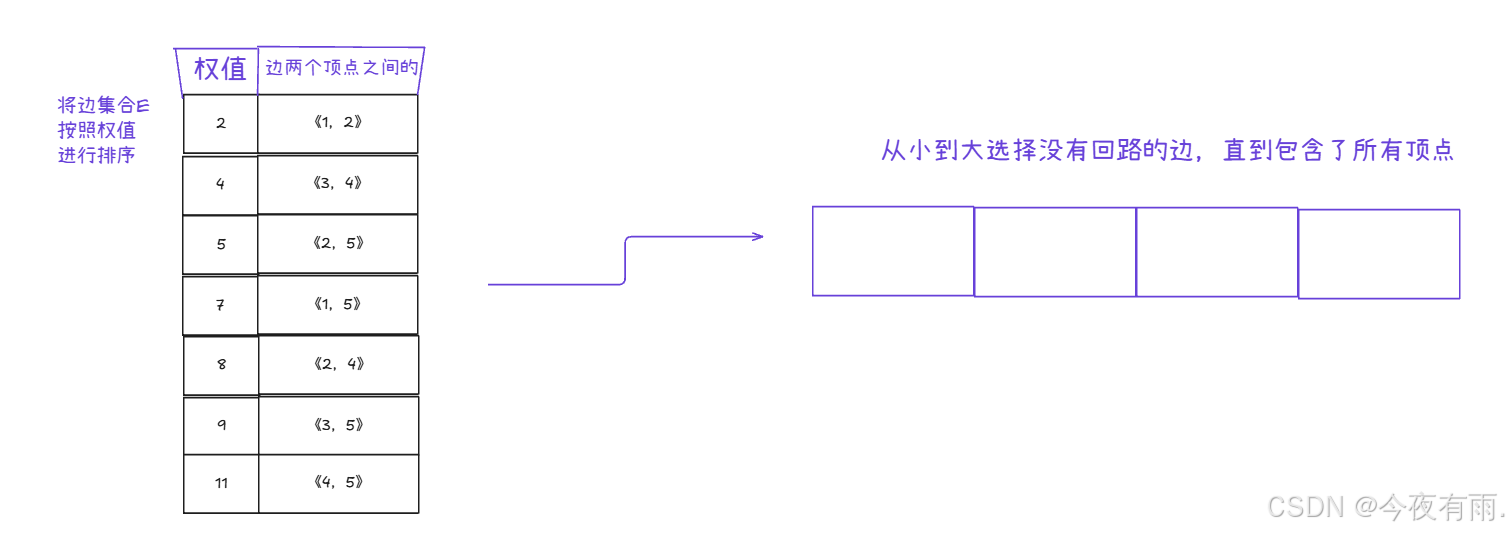
我们依次选择权值最小的边
但是不能形成回环!!!!!!!!!!!!!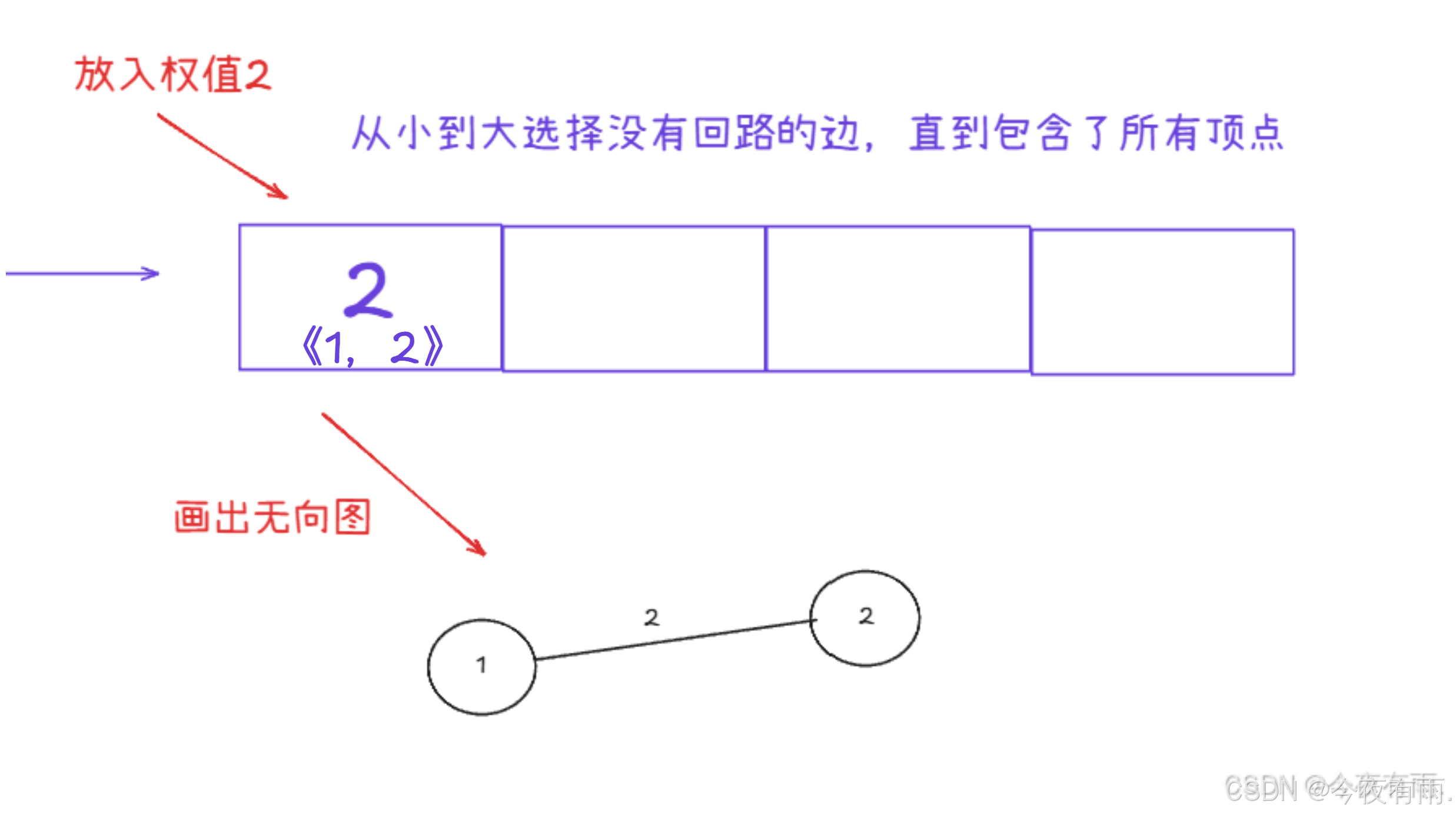
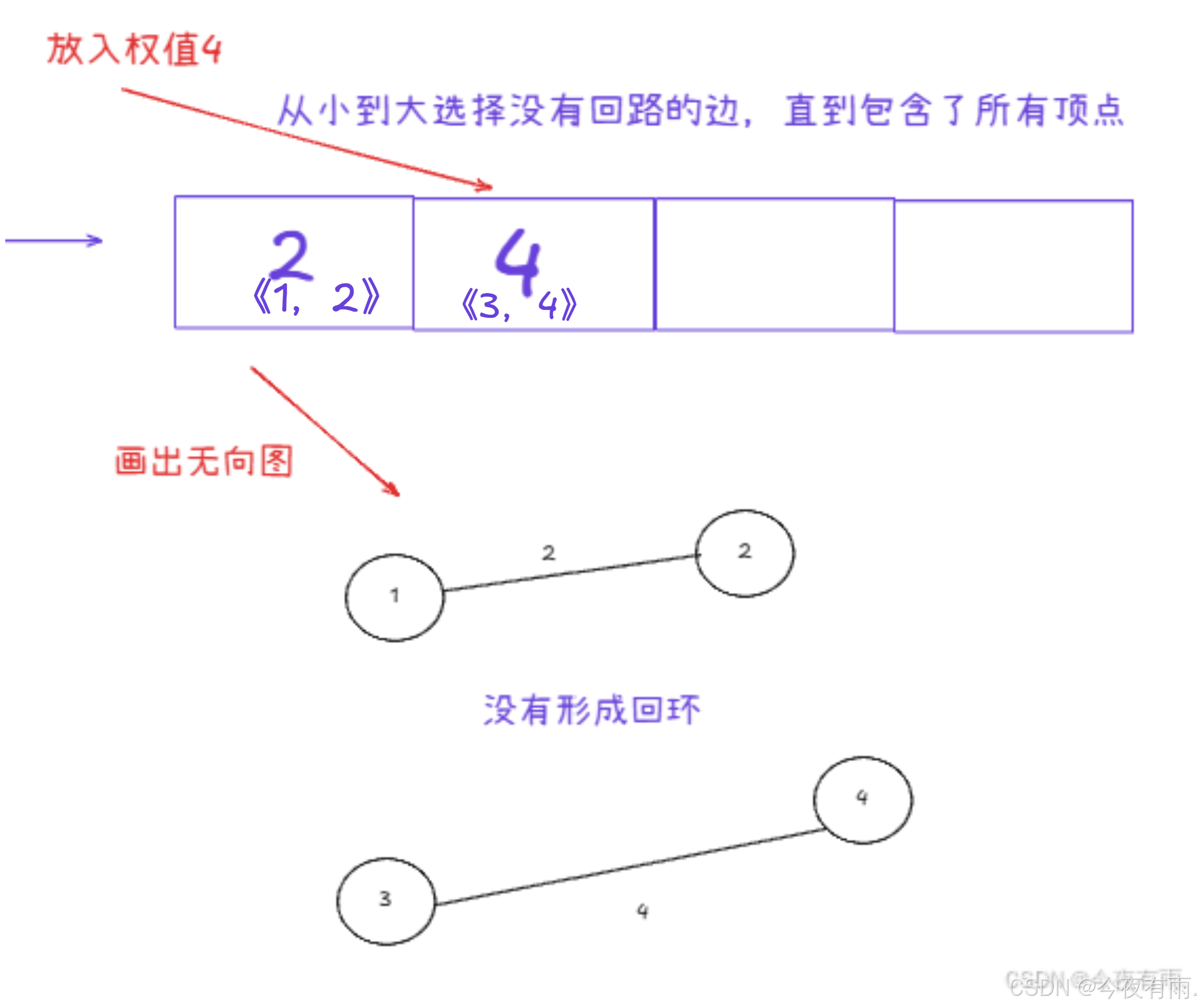
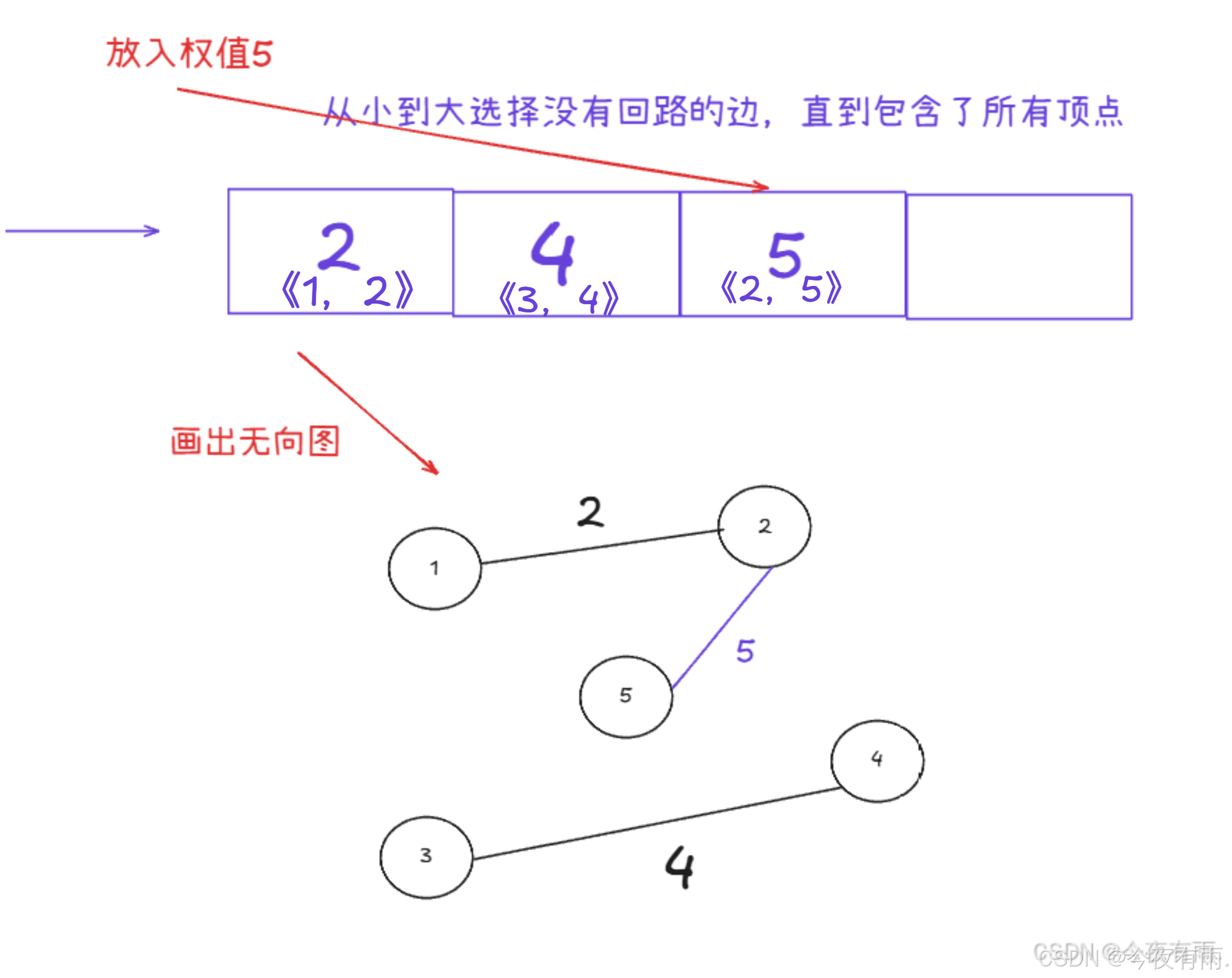
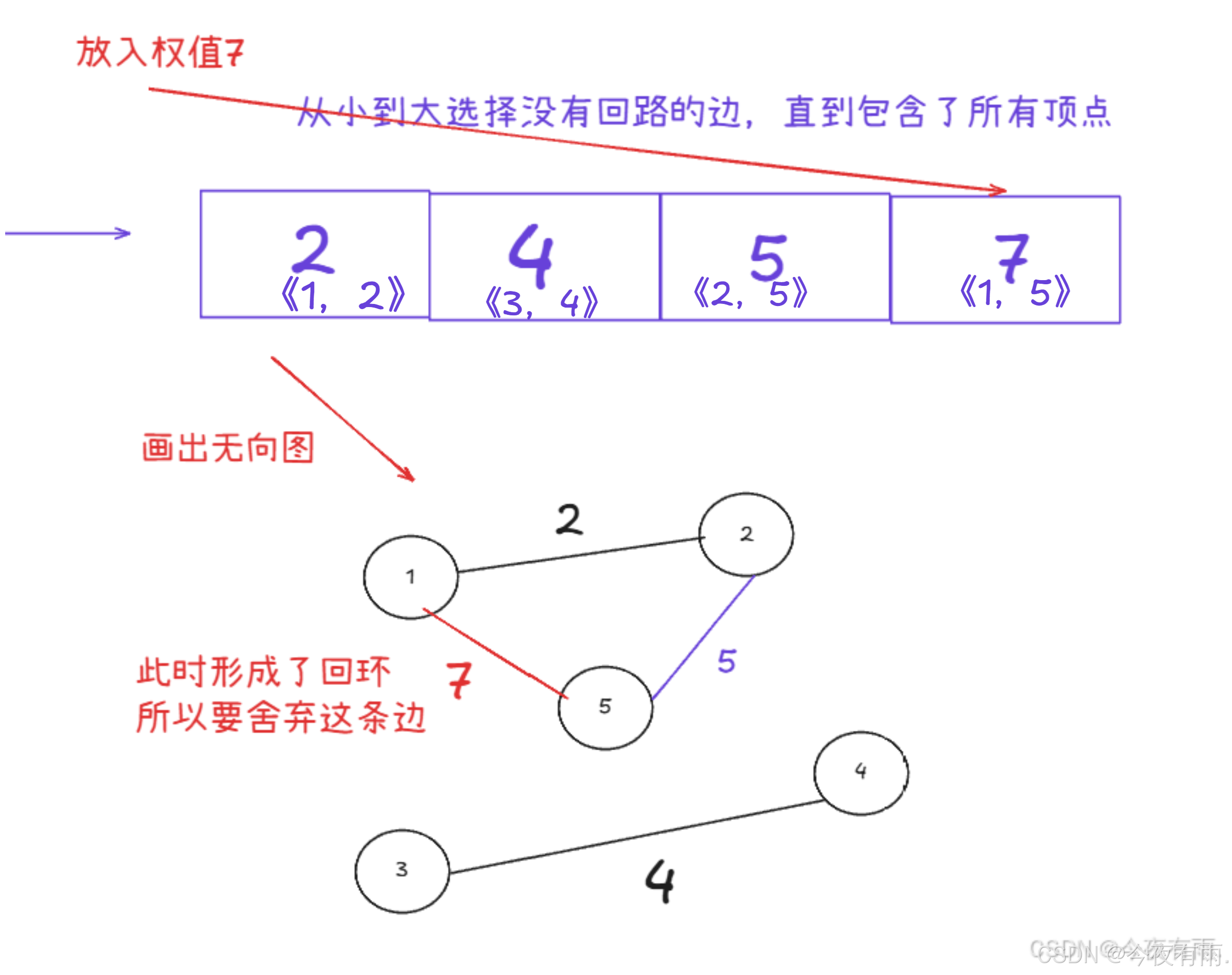
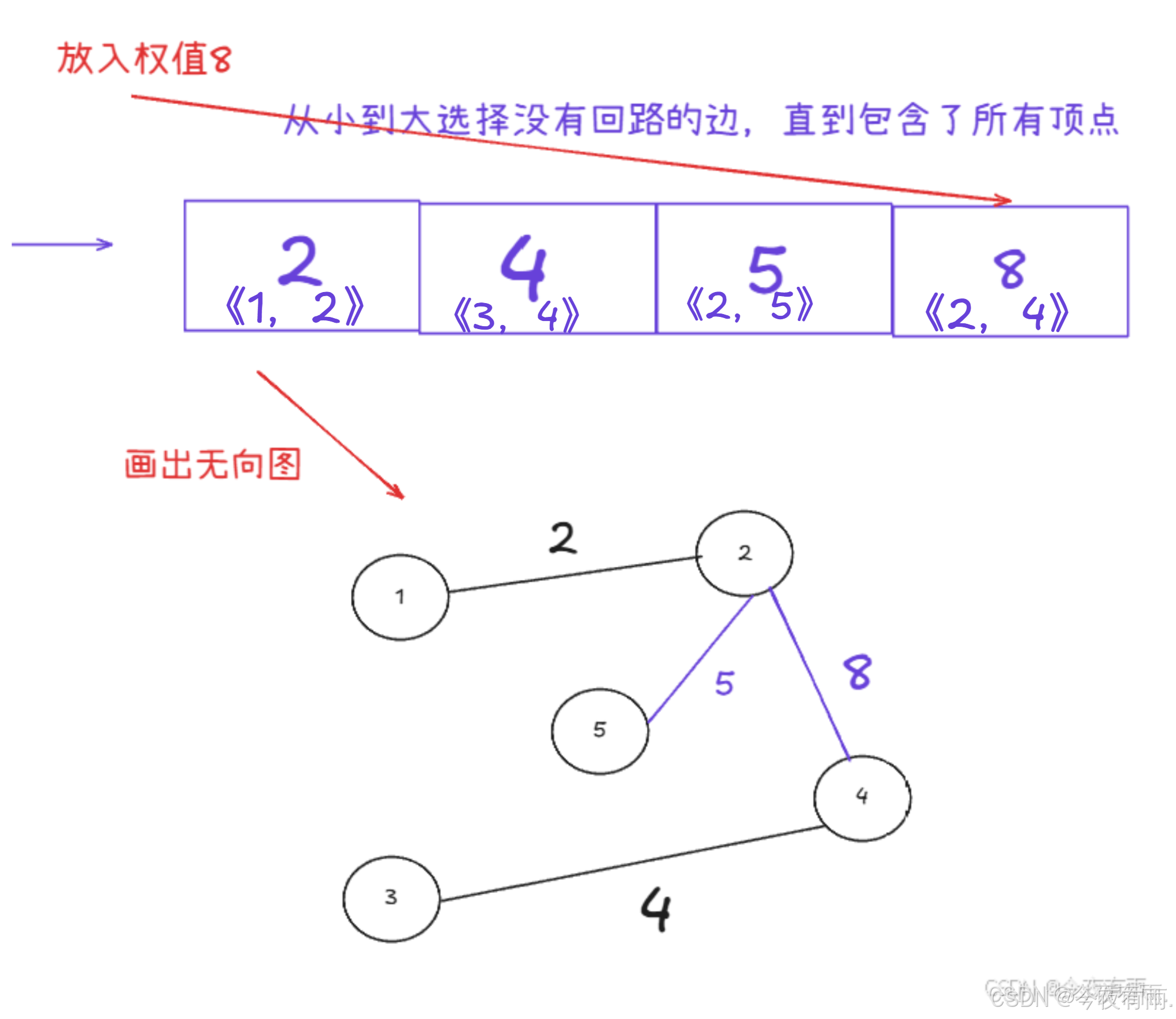
此时已经包含了所有的顶点了,权值一定是最小的,故可得出结果。最终的最小生成树为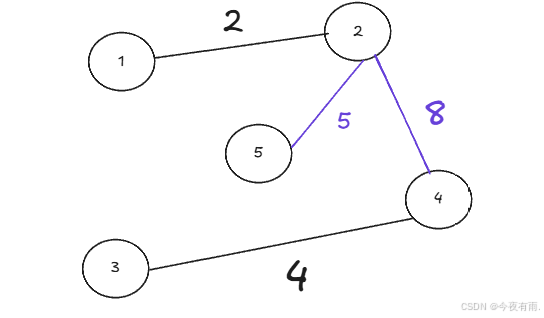
2.Kruskal算法代码实现
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
//定义边的结构体
struct Edge{
int src,dest,weight;
Edge(int s,int d,int w):src(s),dest(d),weight(w){}
bool operator<(const Edge& e) const{
return weight < e.weight;
}
};
//查找集合中的元素
int find(vector<int> &parent,int i)
{
if(parent[i] != i)
{
parent[i] = find(parent,parent[i]);
}
return parent[i];
}
//合并两个集合
void unionSets(vector<int> &parent,vector<int> &rank,int x,int y)
{
int xRoot= find(parent,x);
int yRoot= find(parent,y);
if(rank[xRoot]<rank[yRoot])
{
parent[xRoot] = yRoot;
}
else if(rank[xRoot]>rank[yRoot])
{
parent[yRoot] = xRoot;
}
else{
parent[yRoot] = xRoot;
rank[xRoot]++;
}
}
//Kruskal算法实现最小生成树
int kruskalMST(vector<Edge> &edges,int V)
{
vector<int> parent(V);
vector<int> rank(V,0);
//初始化parent数组
for(int i=0;i<V;i++)
{
parent[i] = i;
}
//对边按权重排序
sort(edges.begin(),edges.end());
int e=0;//边计数器
int MSTcost=0;//MST的权重
while(e<V-1)
{
Edge nextEdge = edges[e++];
int x = find(parent,nextEdge.src);
int y = find(parent,nextEdge.dest);
if(x!=y)
{
MSTcost += nextEdge.weight;
unionSets(parent,rank,x,y);
}
else{
continue;
}
}
return MSTcost;
}
int main()
{
int V = 4;
vector<Edge> edges;
edges.push_back(Edge(0,1,10));
edges.push_back(Edge(0,2,6));
edges.push_back(Edge(0,3,5));
edges.push_back(Edge(1,3,15));
edges.push_back(Edge(2,3,4));
cout<<"最小生成树的权重为:"<<kruskalMST(edges,V)<<endl;
return 0;
}
四、结语
通过对 Prim 算法和 Kruskal 算法的深入剖析和代码实现,我们对无向图有权值的最小生成树的实现有了较为全面的理解。这两种算法在不同的场景下各有优劣,Prim 算法适合稠密图,其基于顶点的扩展方式在处理边数较多的图时效率较高;而 Kruskal 算法则更适合稀疏图,通过对边的排序和处理,能高效地找到最小生成树。在实际应用中,我们可以根据具体的图结构和问题需求,灵活选择合适的算法来解决最小生成树相关的问题,从而更好地实现资源优化、成本降低等目标。希望本文的内容能对大家在图论算法的学习和应用中有所帮助,也期待大家能在更多的实际场景中探索和应用这些算法,挖掘出它们更大的价值。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)