【机器学习】决策树
决策树是一种常用的机器学习算法和决策分析工具,基于树结构进行决策,每个内部节点是一个属性上的测试,分支是测试输出,叶节点是类别或值,通过不断测试属性来将样本分类或预测值。决策树包括根节点内部节点和叶节点。根节点是决策树的起始点,内部节点表示对某个属性的测试,叶节点则代表最终的决策结果或类别。边用来连接各个节点,代表属性的取值或决策路径。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
一、决策树简述
1.概述
决策树是一种常用的机器学习算法和决策分析工具,基于树结构进行决策,每个内部节点是一个属性上的测试,分支是测试输出,叶节点是类别或值,通过不断测试属性来将样本分类或预测值。决策树包括根节点、内部节点和叶节点。根节点是决策树的起始点,内部节点表示对某个属性的测试,叶节点则代表最终的决策结果或类别。边用来连接各个节点,代表属性的取值或决策路径。
2.构建
步骤1:数据准备:收集和整理用于构建决策树的数据集,包括特征(属性)和目标变量(类别或值)。
步骤2:选择最优划分属性:使用信息增益、信息增益比、基尼指数等准则,计算每个属性对数据集划分的优劣程度,选择最优属性作为当前节点的划分属性。
步骤3:划分数据集:根据选定的划分属性的不同取值,将数据集划分为多个子集,为每个子集创建一个分支。
步骤4:递归构建子树:对每个子集递归地重复步骤 2 和步骤 3,直到满足停止条件,如叶节点中的样本属于同一类别、达到预设的树深度或节点中的样本数量小于某个阈值等。
二、信息熵
信息熵是信息论中的一个重要概念,用于衡量一个随机变量的不确定性或混乱程度。
假设当前样本集合D中第k个样本所占的比例为Pk(k=1,2,…,|y|),则D的信息熵定义为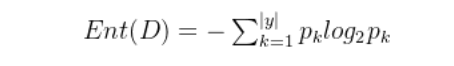
Ent(D)的值越小,则D的纯度越高。
三、划分
1.信息增益(ID3算法)
假定离散属性a有V个可能的取值{},若使用a来对样本集D进行划分,则会产生V个分支结点,其中第v个分支结点包含了D中所有在a上取值为的样本,记为。根据信息熵公式可以计算出的信息熵,再考虑到不同的分支结点所包含的样本数不同,给分支结点赋予权重||/|D|,即样本数越多的分支结点的影响越大,于是可以计算出用属性a对样本集D进行划分所获得的“信息增益”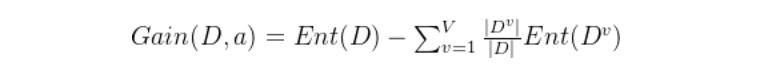
一般而言,信息增益越大,意味着使用属性a来进行划分所获得的“纯度提升”越大。著名的ID3决策树学习算法[Quinlan,1986]就是以信息增益作为准则来选择划分属性。但是ID3 仅仅适用于二分类问题。
2.信息增益率
C4.5 克服了 ID3 仅仅能够处理离散属性的问题,以及信息增益偏向选择取值较多特征的问题。信息增益准则对可取数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,C4.5决策树算法[Quinlan,1993]使用“增益率”来选择最优划分属性。增益率定义为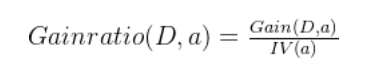
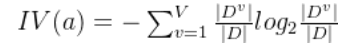
IV(a)称为属性a的“固有值”。属性a的可能取值数目越多(即V越大),则IV(a)的值通常会越大。
但是,增益率准则对可取值数目较少的属性有所偏好。
3.基尼系数
CART决策树使用“基尼指数”来选择划分属性,数据集D的纯度可用基尼值来度量: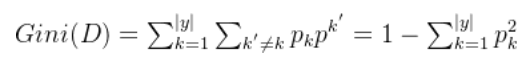
CART 与 ID3,C4.5 不同之处在于 CART 生成的树必须是二叉树。直观来说,Gini(D)反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率。因此,Gini(D)越小,则数据集D的纯度越高。基尼指数越大,集合不确定性越高,不纯度也越大。属性a的基尼指数定义为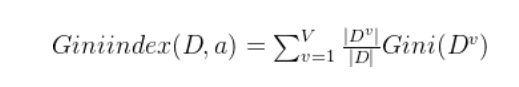
于是,在候选属性集合A中,选择那个使得划分后基尼指数最小的属性作为最优划分属性,即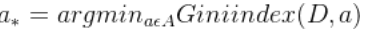
四、决策树的剪枝
1.目的
(1)防止过拟合:决策树在训练过程中可能会过度拟合训练数据,即学习到了训练数据中的噪声和一些不具有一般性的规律。这样的决策树在面对新的测试数据时,往往表现不佳,泛化能力较差。通过剪枝,可以去掉一些可能导致过拟合的分支,使决策树更加简洁,提高其对未知数据的预测准确性和泛化能力。
(2)降低模型复杂度:未经剪枝的决策树可能会非常复杂,包含大量的节点和分支。这不仅会增加模型的存储和计算成本,还会使模型难以理解和解释。剪枝可以减少决策树的节点和分支数量,降低模型复杂度,使模型更易于理解和维护,同时也能提高模型的运行效率。
(3)提高模型的稳定性:过于复杂的决策树对训练数据的微小变化可能非常敏感,即数据的微小波动可能导致决策树结构的较大变化,从而影响模型的预测结果。剪枝后的决策树更加稳定,对数据的微小变化具有更强的鲁棒性,能够提供更可靠的预测结果。
2.策略
(1)预剪枝
预剪枝是在决策树的生成过程中,提前对某些分支进行判断,决定是否继续分裂该分支。如果在某个节点上进行划分不能带来模型性能的显著提升,或者满足了某些预先设定的停止条件,那么就停止该节点的分裂,将其标记为叶节点。
(2)后剪枝
后剪枝是在决策树完全生长完成后,再对树进行剪枝操作。它从叶节点开始,自下而上地评估每个非叶节点对模型性能的影响,如果剪掉某个节点及其子树不会导致模型性能下降,或者能够在一定程度上提高模型的泛化能力,那么就将该节点及其子树剪掉,使其成为叶节点。
五、实验
1.信息增益(ID3)
import numpy as np
import math
def cal_entropy(data):
"""计算数据集的信息熵"""
num_entries = len(data)
label_counts = {}
for feat_vec in data:
current_label = feat_vec[-1]
if current_label not in label_counts.keys():
label_counts[current_label] = 0
label_counts[current_label] += 1
entropy = 0.0
for key in label_counts:
prob = float(label_counts[key]) / num_entries
entropy -= prob * math.log(prob, 2)
return entropy
def split_data(data, axis, value):
"""按照指定特征和特征值划分数据集"""
ret_data = []
for feat_vec in data:
if feat_vec[axis] == value:
reduced_feat_vec = feat_vec[:axis]
reduced_feat_vec.extend(feat_vec[axis + 1:])
ret_data.append(reduced_feat_vec)
return ret_data
def choose_best_feature_to_split(data):
"""选择最好的特征来划分数据集(基于信息增益)"""
num_features = len(data[0]) - 1
base_entropy = cal_entropy(data)
best_info_gain = 0.0
best_feature = -1
for i in range(num_features):
feat_list = [example[i] for example in data]
unique_vals = set(feat_list)
new_entropy = 0.0
for value in unique_vals:
sub_data = split_data(data, i, value)
prob = len(sub_data) / float(len(data))
new_entropy += prob * cal_entropy(sub_data)
info_gain = base_entropy - new_entropy
if info_gain > best_info_gain:
best_info_gain = info_gain
best_feature = i
return best_feature
def majority_cnt(class_list):
"""多数表决决定类别"""
class_count = {}
for vote in class_list:
if vote not in class_count.keys():
class_count[vote] = 0
class_count[vote] += 1
sorted_class_count = sorted(class_count.items(), key=lambda x: x[1], reverse=True)
return sorted_class_count[0][0]
def create_tree(data, labels):
"""创建决策树"""
class_list = [example[-1] for example in data]
if class_list.count(class_list[0]) == len(class_list):
return class_list[0]
if len(data[0]) == 1:
return majority_cnt(class_list)
best_feat = choose_best_feature_to_split(data)
best_feat_label = labels[best_feat]
my_tree = {best_feat_label: {}}
del (labels[best_feat])
feat_values = [example[best_feat] for example in data]
unique_vals = set(feat_values)
for value in unique_vals:
sub_labels = labels[:]
my_tree[best_feat_label][value] = create_tree(split_data(data, best_feat, value), sub_labels)
return my_tree
if __name__ == '__main__':
dataSet = [[0, 0, 0, 0, 'no'],
[0, 0, 0, 1, 'no'],
[0, 1, 0, 1, 'yes'],
[0, 1, 1, 0, 'yes'],
[0, 0, 0, 0, 'no'],
[1, 0, 0, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 1, 1, 'yes'],
[1, 0, 1, 2, 'yes'],
[1, 0, 1, 2, 'yes'],
[2, 0, 1, 2, 'yes'],
[2, 0, 1, 1, 'yes'],
[2, 1, 0, 1, 'yes'],
[2, 1, 0, 2, 'yes'],
[2, 0, 0, 0, 'no']]
labels = ['年龄', '有工作', '有自己的房子', '信贷情况']
decision_tree = create_tree(dataSet, labels)
print(decision_tree)

顶层节点:决策树从 ‘有自己的房子’ 这个特征开始判断。这意味着在判断是否放贷时,首先看客户是否有自己的房子。
第一层分支:
当 ‘有自己的房子’ 的值为 0 (表示没有自己的房子)时,继续根据 ‘有工作’ 这个特征进一步判断。
当 ‘有自己的房子’ 的值为 1 (表示有自己的房子)时,直接得出结论为 ‘yes’ ,即会放贷。
第二层分支(针对’有自己的房子’为0的情况 ):当 ‘有工作’ 的值为 0 (表示没有工作)时,结论是 ‘no’ ,即不放贷;当 ‘有工作’ 的值为 1 (表示有工作)时,结论是 ‘yes’ ,即放贷。
2.信息增益率(C4.5)
import numpy as np
import math
def cal_entropy(data):
"""计算数据集的信息熵"""
num_entries = len(data)
label_counts = {}
for feat_vec in data:
current_label = feat_vec[-1]
if current_label not in label_counts.keys():
label_counts[current_label] = 0
label_counts[current_label] += 1
entropy = 0.0
for key in label_counts:
prob = float(label_counts[key]) / num_entries
entropy -= prob * math.log(prob, 2)
return entropy
def split_data(data, axis, value):
"""按照指定特征和特征值划分数据集"""
ret_data = []
for feat_vec in data:
if feat_vec[axis] == value:
reduced_feat_vec = feat_vec[:axis]
reduced_feat_vec.extend(feat_vec[axis + 1:])
ret_data.append(reduced_feat_vec)
return ret_data
def choose_best_feature_to_split(data):
"""选择最好的特征来划分数据集(基于信息增益率)"""
num_features = len(data[0]) - 1
base_entropy = cal_entropy(data)
best_gain_ratio = 0.0
best_feature = -1
for i in range(num_features):
feat_list = [example[i] for example in data]
unique_vals = set(feat_list)
new_entropy = 0.0
split_info = 0.0
for value in unique_vals:
sub_data = split_data(data, i, value)
prob = len(sub_data) / float(len(data))
new_entropy += prob * cal_entropy(sub_data)
split_info -= prob * math.log(prob, 2)
if split_info == 0:
continue
info_gain = base_entropy - new_entropy
gain_ratio = info_gain / split_info
if gain_ratio > best_gain_ratio:
best_gain_ratio = gain_ratio
best_feature = i
return best_feature
def majority_cnt(class_list):
"""多数表决决定类别"""
class_count = {}
for vote in class_list:
if vote not in class_count.keys():
class_count[vote] = 0
class_count[vote] += 1
sorted_class_count = sorted(class_count.items(), key=lambda x: x[1], reverse=True)
return sorted_class_count[0][0]
def create_tree(data, labels):
"""创建决策树"""
class_list = [example[-1] for example in data]
if class_list.count(class_list[0]) == len(class_list):
return class_list[0]
if len(data[0]) == 1:
return majority_cnt(class_list)
best_feat = choose_best_feature_to_split(data)
best_feat_label = labels[best_feat]
my_tree = {best_feat_label: {}}
del (labels[best_feat])
feat_values = [example[best_feat] for example in data]
unique_vals = set(feat_values)
for value in unique_vals:
sub_labels = labels[:]
my_tree[best_feat_label][value] = create_tree(split_data(data, best_feat, value), sub_labels)
return my_tree
if __name__ == '__main__':
dataSet = [[0, 0, 0, 0, 'no'],
[0, 0, 0, 1, 'no'],
[0, 1, 0, 1, 'yes'],
[0, 1, 1, 0, 'yes'],
[0, 0, 0, 0, 'no'],
[1, 0, 0, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 1, 1, 'yes'],
[1, 0, 1, 2, 'yes'],
[1, 0, 1, 2, 'yes'],
[2, 0, 1, 2, 'yes'],
[2, 0, 1, 1, 'yes'],
[2, 1, 0, 1, 'yes'],
[2, 1, 0, 2, 'yes'],
[2, 0, 0, 0, 'no']]
labels = ['年龄', '有工作', '有自己的房子', '信贷情况']
decision_tree = create_tree(dataSet, labels)
print(decision_tree)

顶层节点:决策树从 ‘有自己的房子’ 这个特征开始判断。这意味着在判断是否放贷时,首先看客户是否有自己的房子。
第一层分支:
当 ‘有自己的房子’ 的值为 0 (表示没有自己的房子)时,继续根据 ‘有工作’ 这个特征进一步判断。
当 ‘有自己的房子’ 的值为 1 (表示有自己的房子)时,直接得出结论为 ‘yes’ ,即会放贷。
第二层分支(针对’有自己的房子’为0的情况 ):当 ‘有工作’ 的值为 0 (表示没有工作)时,结论是 ‘no’ ,即不放贷;当 ‘有工作’ 的值为 1 (表示有工作)时,结论是 ‘yes’ ,即放贷。
六、实验小结
本次实验分别运用信息增益和信息增益率构建决策树,用于判断是否放贷。
在使用信息增益构建决策树时,通过计算不同特征划分数据集所带来的信息增益,选择信息增益最大的特征进行数据集划分,从而逐步构建决策树。该方法能有效筛选出对分类贡献大的特征,但可能对取值较多的特征有偏好,导致过拟合风险。而信息增益率构建决策树,在信息增益的基础上引入分裂信息,以信息增益与分裂信息的比值作为选择特征的依据。这一方式有效校正了信息增益对取值多特征的偏好问题,使决策树构建更加稳健。
实验结果表明,两种方法都能构建出可行的决策树模型来处理放贷判断问题。信息增益构建的决策树在特征选择上直观反映了特征对分类的贡献程度;信息增益率构建的决策树则在特征选择的均衡性上表现更好。同时也发现,不同构建方法的决策树在实际应用中各有优劣,在处理具体问题时,需根据数据特点和实际需求合理选择,以优化决策树模型性能。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 38
38 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)