Prompt工程论文:ExpeL- 大语言模型智能体是体验式学习者
论文地址:https://ojs.aaai.org/index.php/AAAI/article/download/29936/31635摘要:近期,关于将大型语言模型(LLMs)应用于决策任务的研究兴趣激增,并通过利用LLMs中蕴含的广泛世界知识取得了显著进展。尽管人们对定制LLMs以适应特定决策任务的需求日益增长,但对其进行微调不仅资源消耗巨大,还可能削弱模型的泛化能力。此外,最先进的语言模型
论文地址:https://ojs.aaai.org/index.php/AAAI/article/download/29936/31635
摘要:近期,关于将大型语言模型(LLMs)应用于决策任务的研究兴趣激增,并通过利用LLMs中蕴含的广泛世界知识取得了显著进展。尽管人们对定制LLMs以适应特定决策任务的需求日益增长,但对其进行微调不仅资源消耗巨大,还可能削弱模型的泛化能力。此外,最先进的语言模型如GPT-4和Claude主要通过API调用访问,其参数权重仍为专有,公众无法获取。在这种背景下,亟需新的方法论,以便在无需对模型参数进行更新的前提下,从智能体的经验中进行学习。
为了解决上述问题,我们提出了**体验学习(Experiential Learning, ExpeL)**智能体。该智能体能够自主收集经验,并通过自然语言从一系列训练任务中提取知识。在推理阶段,智能体能够回忆起其提取的见解和过往经验,从而做出更有依据的决策。我们的实验证明了ExpeL智能体在学习效果上的稳健性,表现出随着经验积累,其性能持续提升的趋势。我们还通过定性观察和补充实验进一步探索了ExpeL智能体的新兴能力及其迁移学习潜力。
研究背景
- 研究问题:本文提出了一种新的大语言模型(LLM)代理,称为Experiential Learning (ExpeL)代理,旨在通过自主收集经验和提取知识来改善决策任务的表现,而无需进行模型参数的微调。传统的微调方法需要大量的计算资源和人类标注数据,并且可能会损害模型的泛化能力。现有的LLM在处理上下文信息时受到限制,无法在有限的上下文窗口之外进行学习。
- 创新点:
- ExpeL代理通过试错的方式收集成功和失败的经验,并在推理时利用提取的知识进行决策。
- 该方法强调跨任务的经验保留,允许代理在不同任务之间进行学习,而无需进行参数更新。
- 通过与现有基线模型的比较,ExpeL展示了在多种任务中的优越性能,表明经验学习的有效性。
研究方法
- 方法:ExpeL代理在三个阶段操作:收集成功和失败的经验、从这些经验中提取知识、在评估任务中应用所获得的见解。
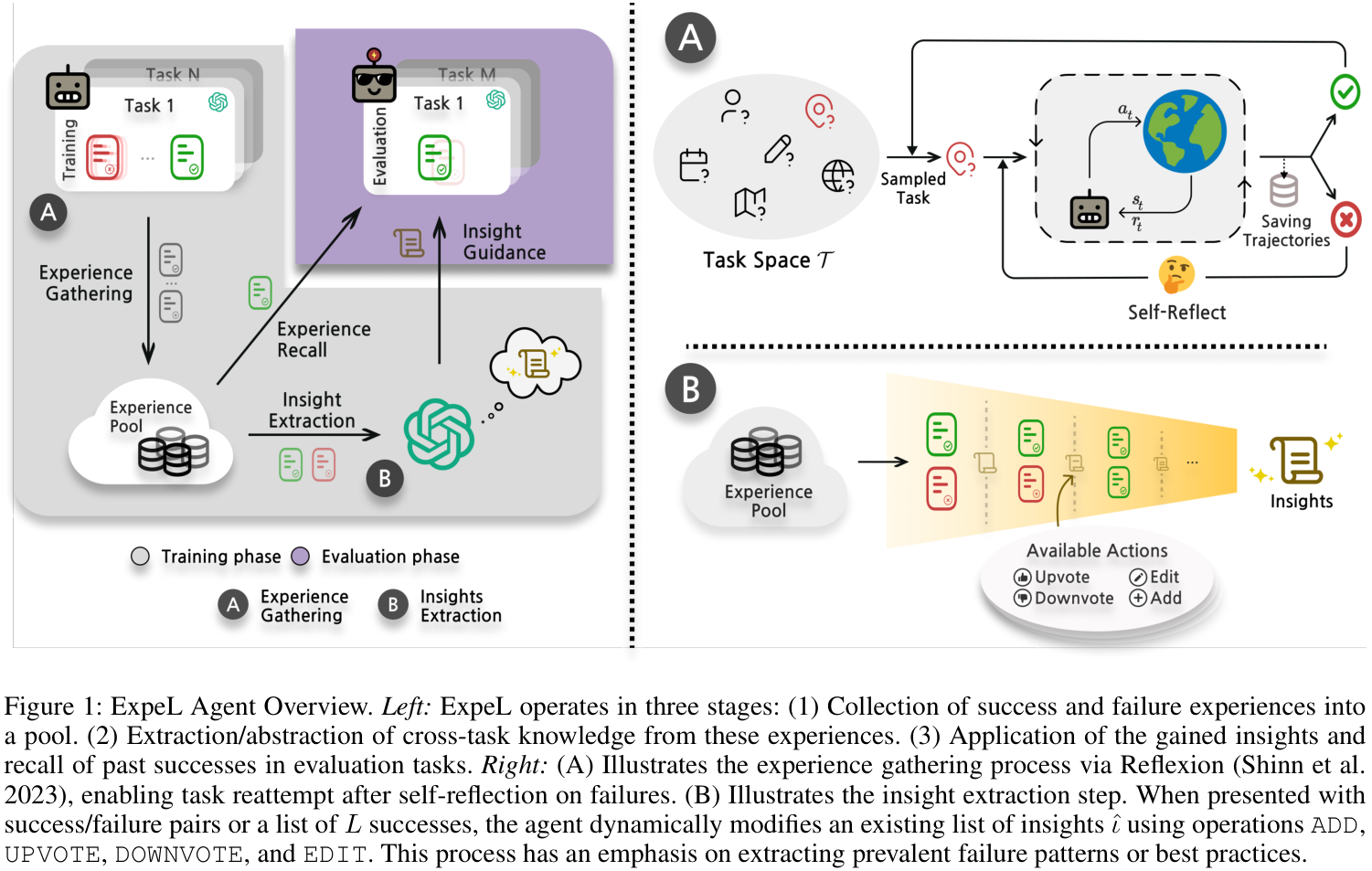
- 经验收集:代理通过试错方式收集经验,最多进行ZZZ次尝试。每次尝试时,代理会使用少量示例和先前的反思来指导其决策。具体来说,代理在每次尝试后将轨迹存储在经验池中,并在失败时进行自我反思以改进后续尝试。
- 学习机制:ExpeL通过两种方式进行学习:存储成功的轨迹以供回忆,以及从经验中提取高层次的见解。代理能够利用成功和失败的轨迹进行比较,以识别改进的方向。具体的操作包括:添加新见解、编辑现有见解、投票支持或反对见解。
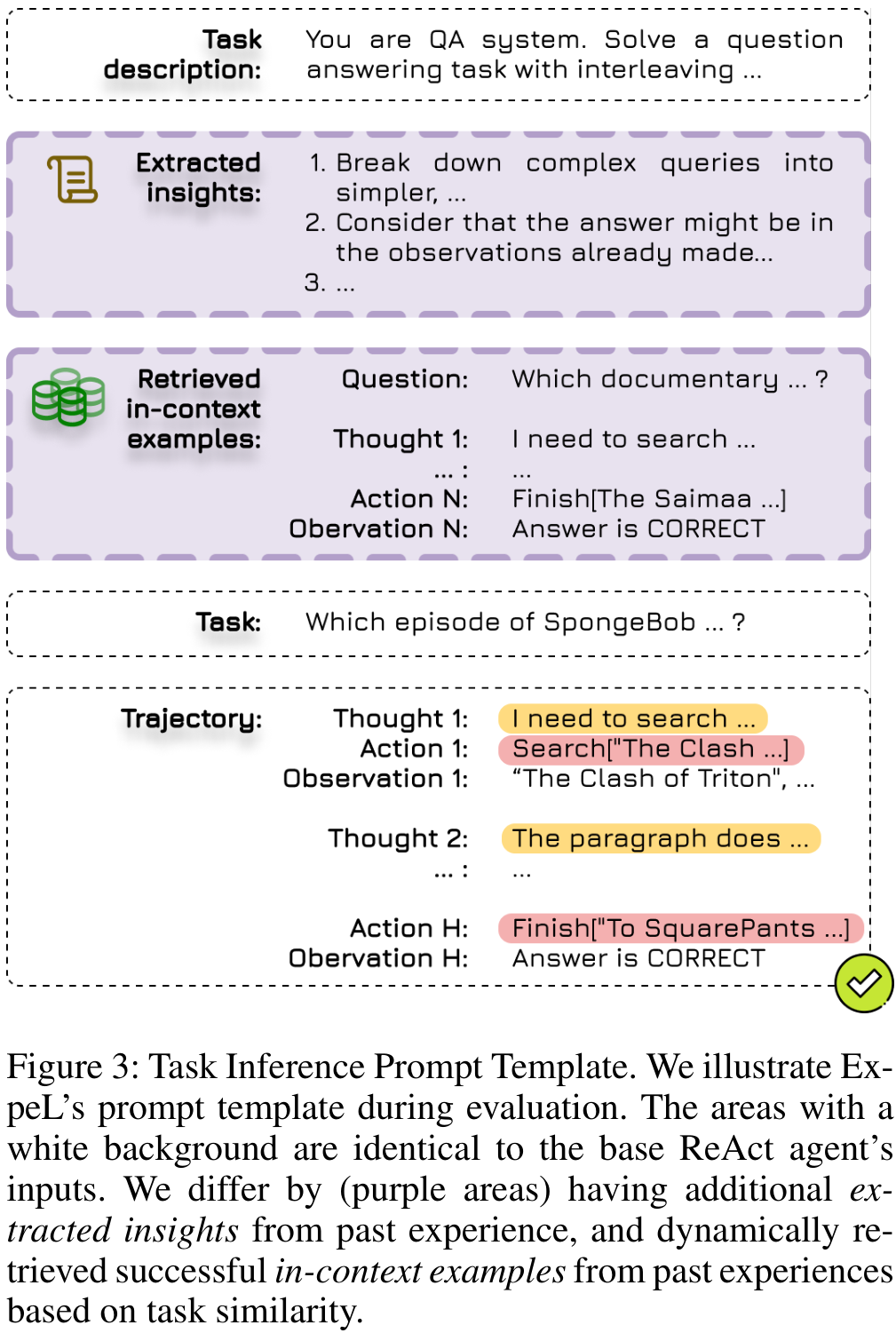
- 任务推理:在评估阶段,代理将任务规范与提取的见解结合,并动态检索与任务相似的成功轨迹作为少量示例,以提高决策能力。
结果与分析
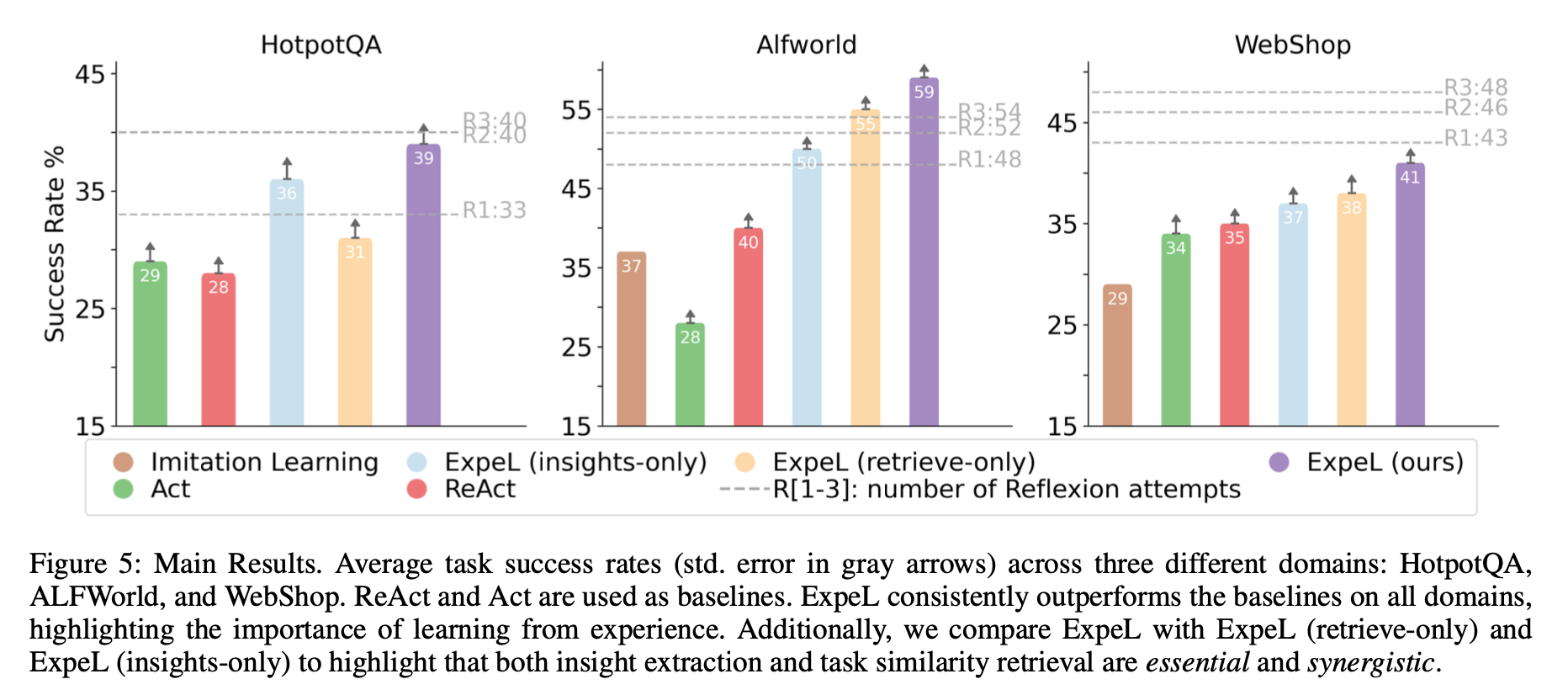
实验结果表明,ExpeL在多个任务中均优于基线模型:
-
主要结果:ExpeL在HotpotQA、ALFWorld和WebShop等任务中表现出色,成功率持续高于基线模型。
-
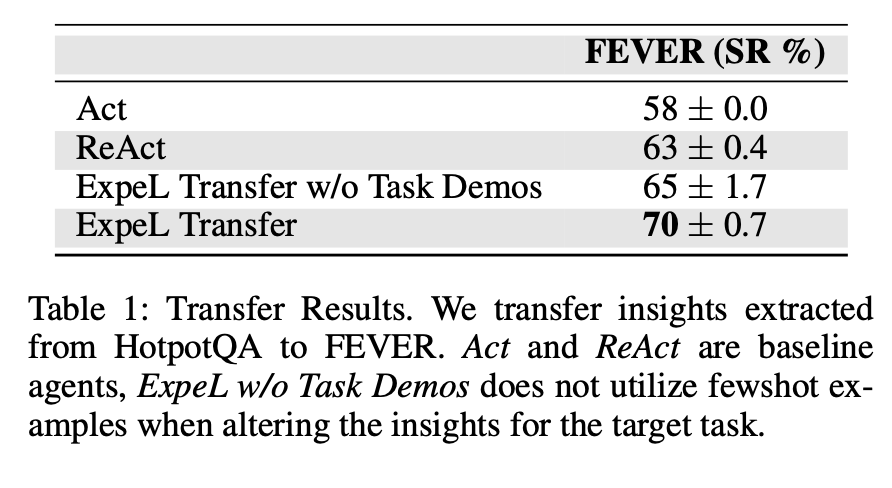
跨任务学习:ExpeL能够通过积累任务经验实现跨任务学习,表现与Reflexion相当,甚至在某些任务中超越了Reflexion。尤其是在ALFWorld任务中,ExpeL的表现明显优于仅依赖单一任务的代理。
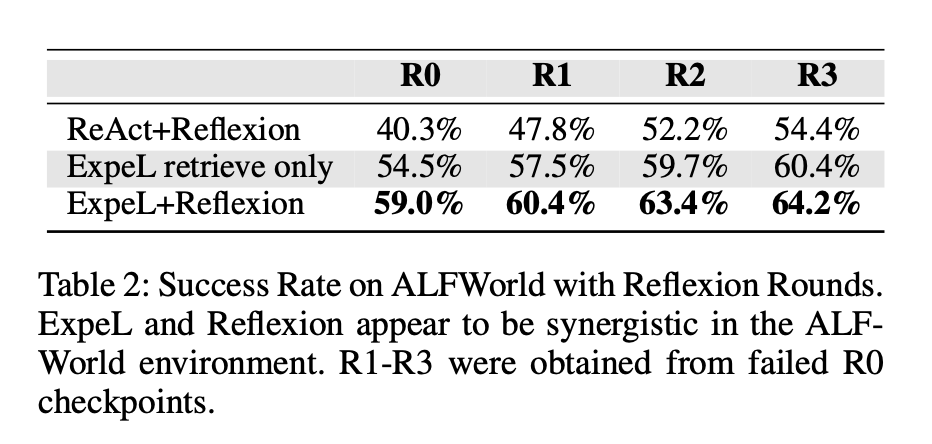
-
经验影响:通过对比不同代理的表现,发现经验的多样性对ExpeL的成功至关重要。具体来说,使用Reflexion收集的成功和失败对比数据显著提升了ExpeL的学习效果。

总体结论
本文提出的ExpeL代理通过自主学习经验,显著提升了在决策任务中的表现。与传统的微调方法相比,ExpeL能够在不进行参数更新的情况下,利用收集到的经验和提取的见解进行有效的决策。实验结果表明,ExpeL在多个任务中表现优越,并展示了跨任务学习的潜力。未来的研究可以进一步探索如何将视觉信息整合到ExpeL中,以增强其在更复杂场景中的应用能力。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 20
20 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)