探索机器学习中的决策树:从理论到实践
决策树是一种基于树结构的分类和回归算法。它通过一系列的“决策”或“问题”来对数据进行划分,最终将数据分配到某个类别或预测一个数值。根节点:包含整个数据集。内部节点:表示一个特征或属性上的测试。叶子节点:表示一个类别或数值。决策树的目标是找到一种划分方式,使得每个子集的纯度最高(例如,在分类任务中,子集尽可能只包含一个类别的样本)。易于理解:决策树的结构直观,易于解释。处理非线性数据:决策树可以处理
摘要:决策树是一种简单且强大的机器学习算法,广泛应用于分类和回归任务。本文将介绍决策树的基本概念、工作原理,并使用Python实现一个简单的决策树分类器。
一. 什么是决策树?
决策树是一种基于树结构的分类和回归算法。它通过一系列的“决策”或“问题”来对数据进行划分,最终将数据分配到某个类别或预测一个数值。决策树由节点和边组成,其中:
- 根节点:包含整个数据集。
- 内部节点:表示一个特征或属性上的测试。
- 叶子节点:表示一个类别或数值。
决策树的目标是找到一种划分方式,使得每个子集的纯度最高(例如,在分类任务中,子集尽可能只包含一个类别的样本)。
二. 决策树的工作原理
决策树通过以下步骤构建:
- 选择最佳特征:使用某种指标(如信息增益、基尼指数)选择当前数据集中最重要的特征。
1.1:信息熵
度量数据的不确定性,熵值越高,样本越混乱。
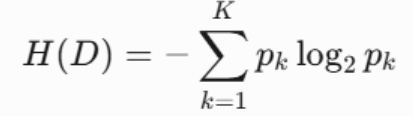
其中,pk 是数据集中第 k 类样本的比例。
1.2:信息增益率
选择信息增益最大的特征作为划分依据。
以下为信息增益计算公式
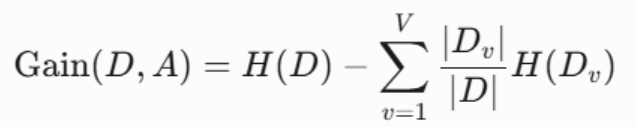
1.3:基尼指数
衡量数据的不纯度
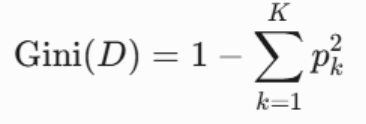
- 划分数据集:根据选择的特征将数据集划分为多个子集。
- 递归构建子树:对每个子集重复上述步骤,直到满足停止条件(如子集为空、所有样本属于同一类别、达到最大深度等)。
三.决策树的主要算法
1. ID3算法
核心思想:基于信息增益选择最佳划分特征。
-
信息增益:衡量一个特征对数据集分类不确定性的减少程度。
-
特点:
- 只能处理离散特征。
- 倾向于选择取值较多的特征,可能导致过拟合。
-
公式:
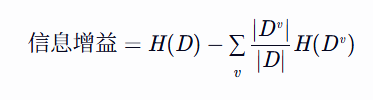
2. C4.5算法
核心思想:改进ID3,基于信息增益率选择最佳划分特征。
-
信息增益率:

特征固有值衡量特征取值的多寡,避免选择取值过多的特征。
- 特点:
- 可以处理连续特征(通过离散化)。
- 支持缺失值处理。
- 生成多叉树(每个节点可以有多个子节点)。
3. CART算法(Classification and Regression Tree)
核心思想:基于基尼指数(分类)或最小二乘法(回归)选择最佳划分特征。
- 分类树:
-
使用基尼指数衡量数据集的不纯度:
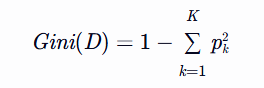
-
四. Python实现决策树分类器
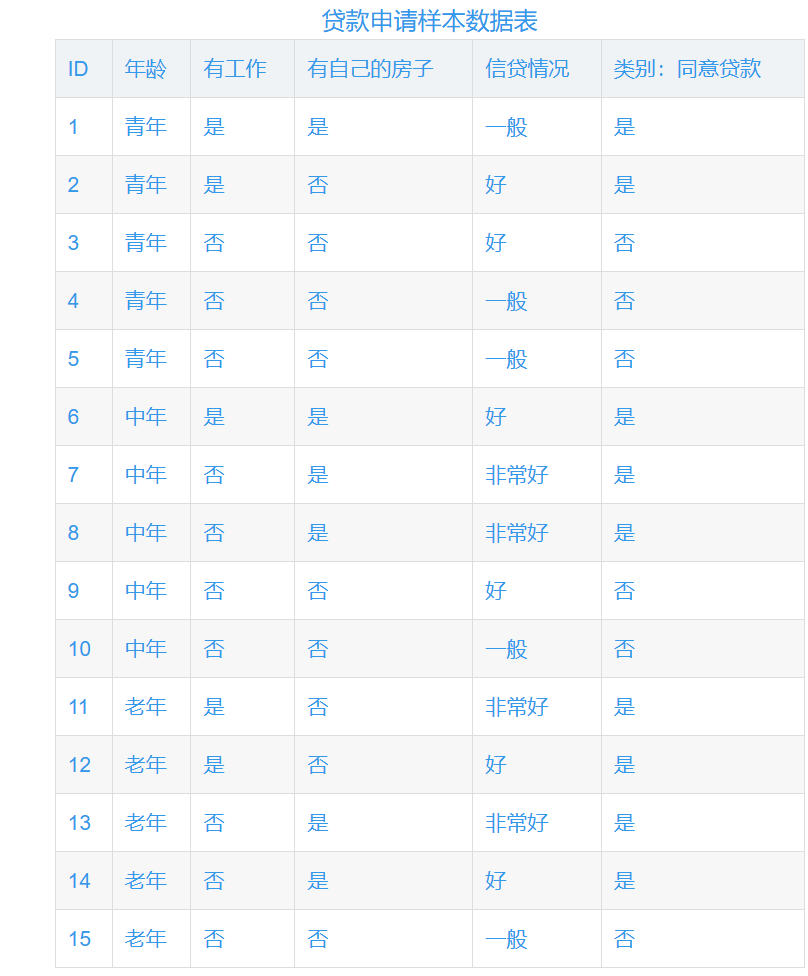
问题引入:下表示由15个样本组成的贷款申请训练数据。数据包括贷款申请人的4个特征(属性):年龄(3个可能值:青年、中年、老年)、工作(2个可能值:是,否)、有自己的房子(2个可能值:是、否)、信贷情况(3个可能值:非常好、好、一般)。表的最后一列是类别,是否同意贷款:是、否。
ID3算法与C4.5算法代码实现
import pandas as pd
import numpy as np
from collections import Counter
# 数据集
data = {
'ID': range(1, 16),
'年龄': ['青年', '青年', '青年', '青年', '青年',
'中年', '中年', '中年', '中年', '中年',
'老年', '老年', '老年', '老年', '老年'],
'有工作': ['是', '是', '否', '否', '否',
'是', '否', '否', '否', '否',
'是', '是', '否', '否', '否'],
'有自己的房子': ['是', '否', '否', '否', '否',
'是', '是', '是', '否', '否',
'否', '否', '是', '是', '否'],
'信贷情况': ['一般', '好', '好', '一般', '一般',
'好', '非常好', '非常好', '好', '一般',
'非常好', '好', '非常好', '好', '一般'],
'类别': ['是', '是', '否', '否', '否',
'是', '是', '是', '否', '否',
'是', '是', '是', '是', '否']
}
df = pd.DataFrame(data)
# 计算熵
def entropy(y):
hist = np.bincount(y)
ps = hist / len(y)
return -np.sum([p * np.log2(p) for p in ps if p > 0])
# 计算信息增益
def information_gain(X, y, feature):
total_entropy = entropy(y)
vals, counts = np.unique(X[feature], return_counts=True)
weighted_entropy = np.sum([
(counts[i] / np.sum(counts)) * entropy(y[X[feature] == vals[i]])
for i in range(len(vals))
])
return total_entropy - weighted_entropy
# 计算信息增益比(C4.5)
def gain_ratio(X, y, feature):
ig = information_gain(X, y, feature)
vals, counts = np.unique(X[feature], return_counts=True)
split_info = -np.sum([(counts[i] / np.sum(counts)) * np.log2(counts[i] / np.sum(counts)) for i in range(len(vals))])
return ig / split_info if split_info != 0 else 0
# 构建决策树(ID3或C4.5)
class DecisionTree:
def __init__(self, criterion='id3'):
self.criterion = criterion
self.tree = None
def fit(self, X, y):
self.tree = self._build_tree(X, y)
def _build_tree(self, X, y):
num_samples, num_features = X.shape
num_labels = len(np.unique(y))
# 如果所有样本属于同一类,返回该类
if num_labels == 1:
return Counter(y).most_common(1)[0][0]
# 如果没有特征可用,返回样本最多的类
if num_features == 0:
return Counter(y).most_common(1)[0][0]
# 选择最佳特征
best_gain = -np.inf
best_feature = None
for feature in X.columns:
if self.criterion == 'id3':
gain = information_gain(X, y, feature)
elif self.criterion == 'c4.5':
gain = gain_ratio(X, y, feature)
if gain > best_gain:
best_gain = gain
best_feature = feature
# 创建子树
tree = {best_feature: {}}
feature_values = np.unique(X[best_feature])
for value in feature_values:
sub_X = X[X[best_feature] == value].drop(columns=[best_feature])
sub_y = y[X[best_feature] == value]
subtree = self._build_tree(sub_X, sub_y)
tree[best_feature][value] = subtree
return tree
def predict(self, X):
return np.array([self._predict_single(x, self.tree) for _, x in X.iterrows()])
def _predict_single(self, x, tree):
if not isinstance(tree, dict):
return tree
feature = list(tree.keys())[0]
subtree = tree[feature][x[feature]]
return self._predict_single(x, subtree)
# 准备数据
X = df.drop(columns=['ID', '类别'])
y = df['类别'].map({'是': 1, '否': 0})
# 训练ID3决策树
id3_tree = DecisionTree(criterion='id3')
id3_tree.fit(X, y)
print("ID3 Decision Tree:")
print(id3_tree.tree)
# 训练C4.5决策树
c45_tree = DecisionTree(criterion='c4.5')
c45_tree.fit(X, y)
print("\nC4.5 Decision Tree:")
print(c45_tree.tree)
五.总结与优化
决策树具有以下优点:
- 易于理解:决策树的结构直观,易于解释。
- 处理非线性数据:决策树可以处理非线性关系。
- 特征重要性:可以通过决策树分析特征的重要性。
然而,决策树也存在一些缺点,如容易过拟合。为了解决这些问题,可以使用以下方法:
- 剪枝:通过限制树的深度或叶子节点的最小样本数来减少过拟合。
- 集成学习:使用随机森林或梯度提升树(如XGBoost)来提高模型的稳定性和准确性。
结语:决策树是一种简单而强大的机器学习算法,适用于分类和回归任务。在实际应用中,可以根据具体问题选择合适的决策树变种或集成学习方法。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 67
67 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)