决策树算法原理与实现
决策树是一种常用的机器学习算法,它通过树状结构对数据进行分类或回归。本文详细介绍了决策树的基本原理,包括特征选择、树的构建和剪枝策略,并使用Python的scikit-learn库实现了完整的决策树分类器。文章还探讨了决策树的优缺点及适用场景,并提供了可视化方法帮助理解模型。关键词:决策树、ID3、C4.5、CART、机器学习。
摘要
决策树是一种常用的机器学习算法,它通过树状结构对数据进行分类或回归。本文详细介绍了决策树的基本原理,包括特征选择、树的构建和剪枝策略,并使用Python的scikit-learn库实现了完整的决策树分类器。文章还探讨了决策树的优缺点及适用场景,并提供了可视化方法帮助理解模型。
关键词:决策树、ID3、C4.5、CART、机器学习
1. 引言
决策树是一种直观的机器学习算法,它模拟人类决策过程,通过一系列的判断规则对数据进行分类或预测。决策树算法因其简单易懂、可解释性强等特点,在数据挖掘、模式识别等领域得到广泛应用。
决策树算法主要包括三种经典方法:ID3、C4.5和CART。ID3算法使用信息增益作为特征选择标准,C4.5算法改进了ID3,使用信息增益比来选择特征,而CART算法则使用基尼指数,并且可以用于分类和回归问题。
2. 决策树基本原理
2.1 决策树结构
决策树由节点和有向边组成,包含三种类型的节点:
-
根节点:包含样本全集,没有入边,有若干出边
-
内部节点:对应于一个特征测试,每个测试结果对应一个出边
-
叶节点:对应于决策结果,没有出边
2.2 特征选择标准
2.2.1 信息增益(ID3算法)
信息增益表示得知特征X的信息而使类Y的信息不确定性减少的程度。信息增益越大,说明该特征对分类提供的信息越多。
信息熵计算公式:
H(D)=−∑k=1Kpklog2pkH(D)=−∑k=1Kpklog2pk
条件熵计算公式:
H(D∣A)=∑i=1n∣Di∣∣D∣H(Di)H(D∣A)=∑i=1n∣D∣∣Di∣H(Di)
信息增益:
g(D,A)=H(D)−H(D∣A)g(D,A)=H(D)−H(D∣A)
2.2.2 信息增益比(C4.5算法)
信息增益比是信息增益与训练数据集关于特征A的值的熵之比:
gR(D,A)=g(D,A)HA(D)gR(D,A)=HA(D)g(D,A)
其中:
HA(D)=−∑i=1n∣Di∣∣D∣log2∣Di∣∣D∣HA(D)=−∑i=1n∣D∣∣Di∣log2∣D∣∣Di∣
2.2.3 基尼指数(CART算法)
基尼指数表示数据集的不纯度,基尼指数越小,数据集的纯度越高。
基尼指数定义:
Gini(D)=1−∑k=1Kpk2Gini(D)=1−∑k=1Kpk2
特征A条件下的基尼指数:
Gini(D,A)=∑i=1n∣Di∣∣D∣Gini(Di)Gini(D,A)=∑i=1n∣D∣∣Di∣Gini(Di)
2.3 决策树剪枝
决策树容易过拟合,剪枝是为了简化模型,提高泛化能力。剪枝分为预剪枝和后剪枝:
-
预剪枝:在树构建过程中提前停止树的生长
-
后剪枝:先构建完整的树,然后自底向上进行剪枝
3. 决策树实现
下面我们使用Python的scikit-learn库实现一个完整的决策树分类器,并使用iris数据集进行演示。
3.1 数据准备
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, export_text, plot_tree
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
import matplotlib.pyplot as plt
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
feature_names = iris.feature_names
class_names = iris.target_names
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
print("数据集特征:", feature_names)
print("类别标签:", class_names)
print("训练集样本数:", len(X_train))
print("测试集样本数:", len(X_test))3.2 构建决策树模型
# 创建决策树分类器
dt_classifier = DecisionTreeClassifier(
criterion='gini', # 使用基尼指数
max_depth=3, # 树的最大深度
min_samples_split=2, # 内部节点再划分所需最小样本数
min_samples_leaf=1, # 叶节点最少样本数
random_state=42
)
# 训练模型
dt_classifier.fit(X_train, y_train)
# 预测测试集
y_pred = dt_classifier.predict(X_test)
# 评估模型
print("\n模型评估:")
print("准确率:", accuracy_score(y_test, y_pred))
print("\n分类报告:")
print(classification_report(y_test, y_pred, target_names=class_names))
print("\n混淆矩阵:")
print(confusion_matrix(y_test, y_pred))3.3 决策树可视化
# 可视化决策树
plt.figure(figsize=(15, 10))
plot_tree(dt_classifier,
feature_names=feature_names,
class_names=class_names,
filled=True,
rounded=True)
plt.title("决策树可视化")
plt.show()
# 输出决策树文本表示
tree_rules = export_text(dt_classifier, feature_names=feature_names)
print("\n决策树规则:")
print(tree_rules)3.4 特征重要性分析
# 特征重要性分析
feature_importance = dt_classifier.feature_importances_
print("\n特征重要性:")
for name, importance in zip(feature_names, feature_importance):
print(f"{name}: {importance:.4f}")
# 可视化特征重要性
plt.figure(figsize=(10, 5))
plt.barh(feature_names, feature_importance)
plt.xlabel("特征重要性")
plt.ylabel("特征名称")
plt.title("决策树特征重要性分析")
plt.show()3.5运行效果图
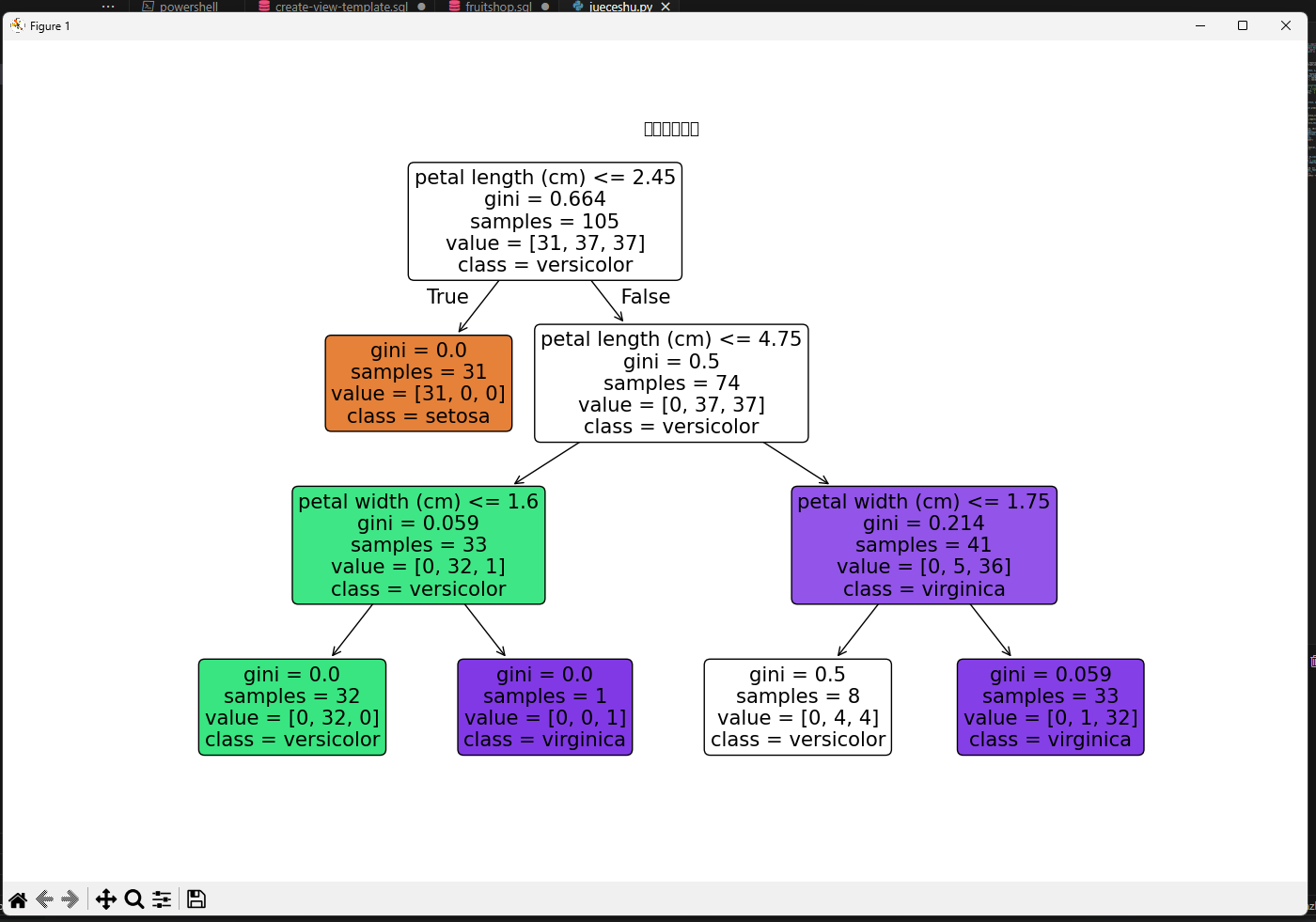
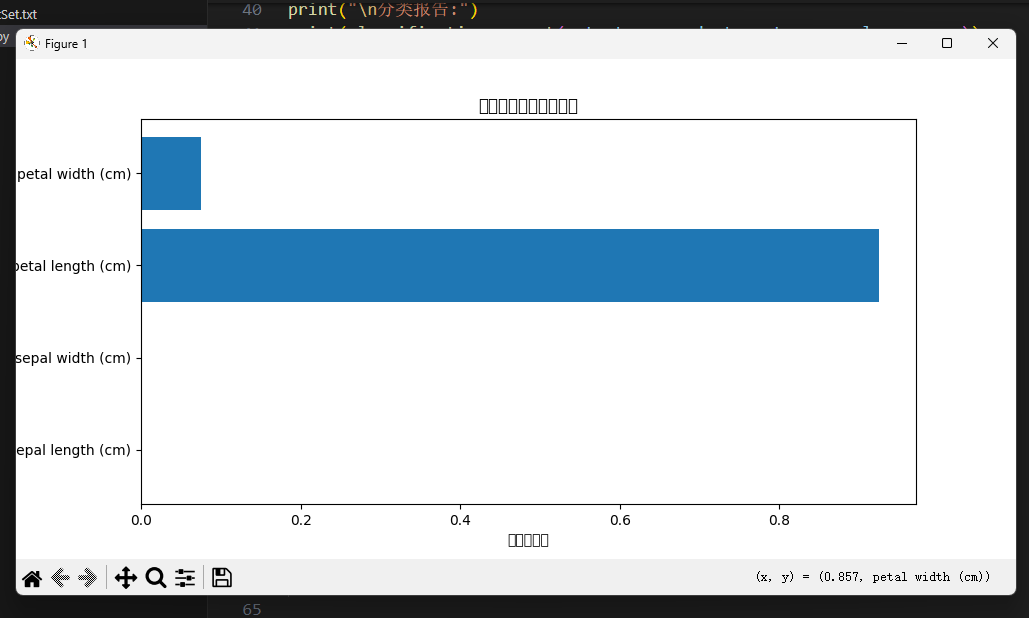
4. 决策树优缺点分析
4.1 优点
-
易于理解和解释:决策树可以可视化,非专业人士也能理解
-
数据准备简单:不需要数据归一化,能处理数值和类别数据
-
能够处理多输出问题
-
可以处理缺失值:通过替代分裂等技术
-
效率较高:对大数据集也有较好的表现
4.2 缺点
-
容易过拟合:需要剪枝或设置停止条件
-
不稳定:数据的小变化可能导致完全不同的树
-
偏向于多值属性:倾向于选择多值的属性作为分裂属性
-
忽略属性间的相关性
-
处理连续变量效果不佳:需要离散化处理
5. 决策树应用场景
决策树适用于以下场景:
-
需要可解释性的分类问题
-
数据探索和特征重要性分析
-
医疗诊断、信用评估等需要明确规则的领域
-
作为复杂模型的基准模型
6. 结论
决策树是一种强大而直观的机器学习算法,特别适合需要模型可解释性的场景。通过合理设置参数和剪枝策略,可以构建出既准确又简洁的决策树模型。在实际应用中,决策树常作为集成学习(如随机森林、梯度提升树)的基础学习器,能够进一步提升模型性能。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 42
42 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)