SpringAIM6-从入门-媒体生成-记忆存储-工具调用-RAG-内容安全-自定义拦截
Spring AI Advisors API提供了一种灵活而强大的方式来拦截、修改和增强Spring应用程序中人工智能驱动的交互。通过利用Advisors API,开发人员可以创建更复杂、可重用和可维护的AI组件。主要的好处包括封装循环生成的人工智能模式,转换发送到大型语言模型(LLM)的数据,以及提供跨各种模型和用例的可移植性。:用于在调用聊天模型之前和之后执行自定义逻辑。它允许你在发送请求到聊
目录
一、概览
官网:https://spring.io/projects/spring-ai#learn
1、为啥学SpringAI?及其应用场景?
SpringAI基于Spring Boot构建,继承了Spring强大的依赖注入、自动配置和应用启动特性,使得集成过程变得简单快捷。支持多种AI模型,如Ollama、WatsonX等,满足不同场景下的需求。开发者可以根据需要添加新的AI模型或服务,只需遵循现有的模块化设计模式,这使得SpringAI具有很高的灵活性。
在微服务架构下,SpringAI可以作为一个独立的AI推理服务,供其他微服务调用,或者嵌入到多个微服务中,实现分布式推理。这提高了系统的可用性和可扩展性。SpringAI在电商推荐、智能客服、实时分析等领域有着广泛的应用。例如,在电商推荐系统中,SpringAI可以利用用户的历史购买记录和浏览行为,为用户推荐感兴趣的商品;在智能客服系统中,SpringAI可以通过自然语言处理技术,与用户进行交互,提供智能化的服务。
随着人工智能技术的不断发展,掌握SpringAI这样的前沿技术将成为开发者在竞争激烈的市场中脱颖而出的关键。
2、常见名词
- RAG:检索增强生成,一般用某个应用内数据的辅助应用。
- fine-tuning:微调,用在垂直领域,带具有某个领域内的特色。
- function-call:函数微调,对于一些实时性的场景,可以去调用别的方法和和接口
二、实战学习
1、创建项目
选择Web下的Spring Web模块和AI下的OpenAI模块
1)、pom.xml
这里jdk的版本是17,SpringAI的版本是M6
<properties>
<java.version>17</java.version>
<spring-ai.version>1.0.0-M6</spring-ai.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
#声明了Spring AI给定版本使用的所有依赖项的推荐版本。使用应用程序构建脚本中的BOM可以避免您自己指定和维护依赖版本的需要。
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
从1.0 M6版本开始,在Maven Central中发布。不需要对构建文件进行任何更改。
如果你需要在M6 1.0之前版本-添加Spring存储库
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>
2)、配置文件
spring:
ai:
openai:
api-key: sk-xMuwTF10o9Esxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
base-url: https://api.chatanywhere.tech
key 和 url可以去淘宝搜 open ai key,个人根据情况购买
2、快速的示例
package com.ai.controller;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RestController
public class AiController {
private final ChatClient chatClient;
//这个有参构造Spring会自动给你注入
public AiController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@GetMapping("/chatCall")
String chatCall(@RequestParam("message") String message) {
//prompt()方法可以理解为构造一个prompt对象,可以理解为给大模型一点提示
return this.chatClient.prompt()
//user()接收用户输入
.user(message)
//call()远程请求大模型所有的文本的准备好,一次性响应,用户的体验效果比较不好
//stream()远程请求大模型,流式响应内容,
.call()
//content()获取大模型的返回结果,为字符串类型
.content();
}
}
AiController 有参构造Spring会自动的注入
.prompt()方法可以理解为构造一个prompt对象,可以理解为给大模型一点提示。
.user(message) :接收用户输入
.call():远程请求大模型所有的文本的准备好一次性响应,用户的体验效果比较不好
3、格式化输出
ChatClientAPI提供了几种使用fluent API格式化来自AI模型的响应的方法。
1)返回ChatResponse
返回了JSON元数据,元数据包括用于创建响应的标记数量(每个标记大约是一个单词的3/4)。这个信息很重要,因为托管AI模型根据每个请求使用的令牌数收费。
@GetMapping("/chatResponse")
ChatResponse chatResponse(@RequestParam("message") String message) {
//prompt()方法可以理解为构造一个prompt对象,可以理解为给大模型一点提示
return this.chatClient.prompt()
//system()为了避免在运行时代码中重复系统提示文本,
// .system()
//user()接收用户输入
.user(message)
//call()远程请求大模型所有的文本的准备好,一次性响应,用户的体验效果比较不好
//stream()远程请求大模型,流式响应内容
.call()
//content()获取大模型的返回结果
.chatResponse();
}
{"result":{"metadata":{"finishReason":"STOP","contentFilters":[],"empty":true},"output":{"messageType":"ASSISTANT","metadata":{"finishReason":"STOP","refusal":"","index":0,"role":"ASSISTANT","id":"chatcmpl-B4WxAihJRUq9XKZLBdG1UIW1lP5Jy","messageType":"ASSISTANT"},"toolCalls":[],"media":[],"text":"小Ti老师是一位在网络上较为知名的教育工作者,主要通过视频、直播等形式进行知识分享和在线教学。她的教学风格通常生动有趣,受到很多学生的喜爱。具体信息可能会因时间而有所变化,如果你想了解她的最新动态,可以查看她的社交媒体或相关平台。"}},"metadata":{"id":"chatcmpl-B4WxAihJRUq9XKZLBdG1UIW1lP5Jy","model":"gpt-4o-mini-2024-07-18","rateLimit":{"requestsLimit":null,"requestsRemaining":null,"tokensLimit":null,"tokensRemaining":null,"requestsReset":null,"tokensReset":null},"usage":{"promptTokens":12,"completionTokens":77,"totalTokens":89,"generationTokens":77,"nativeUsage":{"completion_tokens":77,"prompt_tokens":12,"total_tokens":89,"prompt_tokens_details":{"audio_tokens":0,"cached_tokens":0},"completion_tokens_details":{"reasoning_tokens":0,"audio_tokens":0}}},"promptMetadata":[],"empty":false},"results":[{"metadata":{"finishReason":"STOP","contentFilters":[],"empty":true},"output":{"messageType":"ASSISTANT","metadata":{"finishReason":"STOP","refusal":"","index":0,"role":"ASSISTANT","id":"chatcmpl-B4WxAihJRUq9XKZLBdG1UIW1lP5Jy","messageType":"ASSISTANT"},"toolCalls":[],"media":[],"text":"小Ti老师是一位在网络上较为知名的教育工作者,主要通过视频、直播等形式进行知识分享和在线教学。她的教学风格通常生动有趣,受到很多学生的喜爱。具体信息可能会因时间而有所变化,如果你想了解她的最新动态,可以查看她的社交媒体或相关平台。"}}]}
2)返回实体
返回一个从返回的映射而来的固定实体类JSON字符串。这entity()方法提供了这一功能。
@GetMapping("/chatEntity")
ActorFilms chatEntity(@RequestParam("message") String message) {
//prompt()方法可以理解为构造一个prompt对象,可以理解为给大模型一点提示
return this.chatClient.prompt()
//system()为了避免在运行时代码中重复系统提示文本,
// .system()
//user()接收用户输入
.user(message)
//call()远程请求大模型所有的文本的准备好,一次性响应,用户的体验效果比较不好
//stream()远程请求大模型,流式响应内容
.call()
//content()获取大模型的返回结果的内容
.entity(ActorFilms.class);
}
小贴士:produces = “text/html;charset=UTF-8”,告诉浏览器当前的字符串的编码格式,这样显示就不会乱码。
3)流式响应
stream()远程请求大模型,流式响应内容,前端就会一字一字显示内容。
@GetMapping(value = "/chatStream",produces = "text/html;charset=UTF-8")
Flux<String> chatStream(@RequestParam("message") String message) {
Flux<String> output = chatClient.prompt()
.user(message)
.stream()
.content();
return output;
}
4、默认提示词
为了避免在运行时代码中用户重复给系统提示文本.
1)方式一
@Configuration
public class Config {
//将配置系统默认文本,使其知道明明家小狗
//为了避免在运行时代码中重复系统提示文本,我们将创建一个ChatClient中的实例@Configuration类。
@Bean
ChatClient chatClient(ChatClient.Builder builder) {
return builder.defaultSystem("你是个友好的聊天机器人,我希望你记住这个信息:明明家小狗的名字是小兰,会很多特技,空中翻,握手,缉毒。")
.build();
}
}
@GetMapping("/simple")
public String completion(@RequestParam(value = "message", defaultValue = "你好,hellowrld") String message) {
return chatClient.prompt().user(message).call().content();
}
2)方式二
@GetMapping("/chatCall")
String chatCall(@RequestParam("message") String message) {
//prompt()方法可以理解为构造一个prompt对象,可以理解为给大模型一点提示
return this.chatClient.prompt()
.system("你是个友好的聊天机器人,我希望你记住这个信息:明明家小狗的名字是小兰,会很多特技,空中翻,握手,缉毒。")
//user()接收用户输入
.user(message)
//call()远程请求大模型所有的文本的准备好,一次性响应,用户的体验效果比较不好
//stream()远程请求大模型,流式响应内容,
.call()
//content()获取大模型的返回结果,为字符串类型
.content();
}
访问:http://localhost:8080/chatCall?message=你知道明明家的小狗吗?
结果:当然知道!明明家的小狗叫小兰,它会很多特技,比如空中翻、握手,还有缉毒呢!真是一只非常聪明的小狗!你喜欢小兰吗?
5、代理配置-使用Open AI的接口
在配置文件中使用了Open AI的接口和秘钥,用于Open AI公司禁用国内的IP,这时候只能通过科学上网软件,进行访问,但是这时候你的代码还需要设置代理。
public static void main(String[] args) {
System.setProperty("proxyType","4");
System.setProperty("proxyPort","7890");//科学上网软件的端口
System.setProperty("proxyHost","127.0.0.1");//科学上网软件的IP,一般都是本机
System.setProperty("proxySet","true");
SpringApplication.run(SpringAiExerciseApplication.class, args);
}
6、ChatModel
客户端 API通常通过向AI模型发送提示或部分对话来工作;然后ChatModel根据其训练数据和对自然语言模式的理解来生成完整或继续的对话。然后,将完成的响应返回给应用程序,应用程序可以将它呈现给用户或使用它进行进一步处理。
Spring AI Chat Model API旨在成为一个简单、可移植的界面,用于与各种人工智能模型,允许开发人员以最少的代码更改在不同的模型之间切换。这种设计符合Spring的模块化和可互换性理念。
ChatModel底层自动封装了ChatCilent的相关代码。
代码示例:
前提要导入:openai stater
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
@Autowired
private ChatModel chatModel;
@GetMapping("/chatModel")
String chatModel(@RequestParam("message") String message) {
ChatResponse response = chatModel.call(
new Prompt(
message,
OpenAiChatOptions.builder()
.model("gpt-4o")
.temperature(0.4)
.build()
));
return response.getResult().getOutput().getText();
}
1)文生图
通过告诉大模型文本,让大模型生成图片。
官网文档:https://docs.spring.io/spring-ai/reference/1.0/api/image/openai-image.html
@Autowired
private OpenAiImageModel openaiImageModel;
@GetMapping("/textToImage")
String toImage(@RequestParam(value = "message",defaultValue = "一只可爱的黄色小狗") String message) {
ImageResponse response = openaiImageModel.call(
new ImagePrompt(message,
OpenAiImageOptions.builder()
.quality("hd")
.N(1)
.height(1024)
.width(1024).build())
);
return response.getResult().getOutput().getUrl();
}
参数可以规定:质量,数量,图片大小。
2)文生语音
通过告诉大模型文本,让大模型生成音频文件。
官网文档:https://docs.spring.io/spring-ai/reference/1.0/api/audio/speech/openai-speech.html
@Autowired
private OpenAiAudioSpeechModel openAiAudioSpeechModel;
@GetMapping("/textToAudio")
void ToAudio(@RequestParam(value = "message",defaultValue = "一只可爱的黄色小狗") String message) throws IOException {
OpenAiAudioSpeechOptions speechOptions = OpenAiAudioSpeechOptions.builder()
.model("tts-1")
.voice(OpenAiAudioApi.SpeechRequest.Voice.ALLOY)
.responseFormat(OpenAiAudioApi.SpeechRequest.AudioResponseFormat.MP3)
.speed(1.0f)
.build();
SpeechPrompt speechPrompt = new SpeechPrompt(message, speechOptions);
SpeechResponse response = openAiAudioSpeechModel.call(speechPrompt);
byte[] output = response.getResult().getOutput();
//将字节流的MP3文件保存到resouces文件夹下
// 保存字节流到文件
String fileName = "output.mp3";
saveMp3ToFile(output, fileName);
}
public void saveMp3ToFile(byte[] mp3Bytes, String fileName) throws IOException {
// 定义保存文件的目录
String outputDir = "output";
Path directoryPath = Paths.get(outputDir);
// 如果目录不存在,则创建目录
if (!Files.exists(directoryPath)) {
Files.createDirectories(directoryPath);
}
// 定义文件路径
Path filePath = directoryPath.resolve(fileName);
// 将字节流写入文件
try (FileOutputStream fos = new FileOutputStream(filePath.toFile())) {
fos.write(mp3Bytes);
} catch (IOException e) {
e.printStackTrace();
}
}
3)语音翻译(语音转文字)
语音翻译
官网:https://docs.spring.io/spring-ai/reference/1.0/api/audio/transcriptions/openai-transcriptions.html
//这里最好用管方的API
@Autowired
private OpenAiAudioTranscriptionModel openAiAudioTranscriptionModel;
@GetMapping("/audioToText")
String transcription(@RequestParam(value = "message",defaultValue = "一只可爱的黄色小狗") String message) {
var transcriptionOptions = OpenAiAudioTranscriptionOptions.builder()
.responseFormat(OpenAiAudioApi.TranscriptResponseFormat.TEXT)
.temperature(0f)
.build();
var audioFile = new ClassPathResource("/a.mp3");
AudioTranscriptionPrompt transcriptionRequest = new AudioTranscriptionPrompt(audioFile, transcriptionOptions);
AudioTranscriptionResponse response = openAiAudioTranscriptionModel.call(transcriptionRequest);
return response.getResult().getOutput();
}
7、多模态
多模态是指同一模型同时理解和处理来自各种来源的信息的能力,包括文本、图像、音频和其他数据格式。
人类处理知识,同时跨越多种数据输入模式。我们学习的方式,我们的经历都是多模态的。我们不只有视觉、听觉和文字。
与这些原则相反,机器学习通常专注于为处理单一模态而定制的专门模型。例如,我们为文本到语音或语音到文本等任务开发了音频模型,为对象检测和分类等任务开发了计算机视觉模型。
然而,新一波的多模态大型语言模型开始出现。例子包括OpenAI的GPT-4o,谷歌的Vertex AI Gemini 1.5,Anthropic的Claude3,以及开源产品Llama3.2,LLaVA和BakLLaVA能够接受多种输入,包括文本图像,音频和视频,并通过整合这些输入来生成文本响应。
官网:https://docs.spring.io/spring-ai/reference/1.0/api/chat/openai-chat.html#_multimodal
@GetMapping("/multimodal")
String multimodal() {
var imageResource = new ClassPathResource("/dog.jpg");
var userMessage = new UserMessage(
"这张照片中有什么?", // content
new Media(MimeTypeUtils.IMAGE_PNG, imageResource)); // media
ChatResponse response = chatModel.call(new Prompt(userMessage));
return response.getResult().getOutput().getText();
}
8、ToolCallback(FunctionCall)
工具调用(也称为函数调用)是人工智能应用程序中的一种常见模式,允许模型与一组API进行交互,或者工具增强了它的能力。
场景举例:我想问成都的天气如何?大模型这是肯定不知道的,这时我们就可以通过ToolCallback API来调用其它平台的天气查询API,进行查询,将查询到的结果返回给SpringAI,SpringAI将天气数据返回给大模型,进行响应。
执行顺序: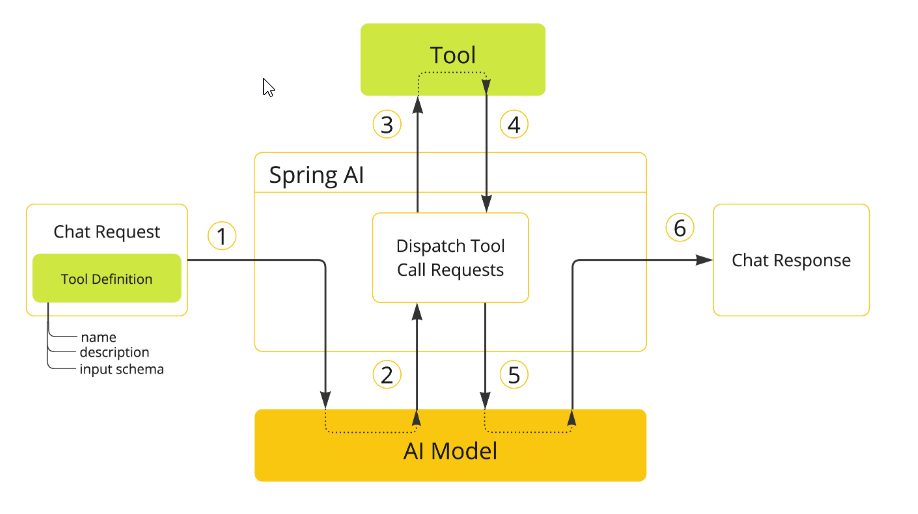
步骤解释:
- 当我们想让一个工具对模型可用时,我们在聊天请求中包含它的定义。每个工具定义由名称、描述和输入参数的模式组成。
- 当模型决定调用一个工具时,它会发送一个响应,其中包含工具名称和按照定义的模式建模的输入参数。
- 应用程序负责使用工具名称来识别和执行具有所提供的输入参数的工具。
- 工具调用的结果由应用程序处理。
- 应用程序将工具调用结果发送回模型。
- 该模型使用工具调用结果作为附加上下文来生成最终响应。
代码实操:
在SpringAI中FunctionCallback在下一版本中将要被弃用,所以这次我们直接使用ToolCallback。
官网地址:https://docs.spring.io/spring-ai/reference/api/tools-migration.html
先写个天气查询的工具类:
//天气查询
@Slf4j
public class WeatherTool {
@Tool(description = "查询该城市的天气")
public String weather(String city) throws IOException {
System.out.println(city);
System.out.println("---");
String link = "https://v.api.aa1.cn/api/api-weather/qq-weather.php?msg=" + city;
// //创建URL对象
// URL url = new URL(link);
// //创建链接:返回一个 URLConnection 实例,该实例表示与 URL 引用的远程对象的连接。
// HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
// //如果此类连接尚未建立,则打开指向此 URL 引用的资源的通信链接
// urlConnection.connect();
// //返回从此打开的连接读取的输入流。
// InputStream is = urlConnection.getInputStream();
// //输出字符串
// byte[] bytes = new byte[1024];
// int len = 0;
// String result = "";
// while ((len = is.read(bytes)) != -1) {
// result += new String(bytes, 0, len);
// }
RestTemplate restTemplate = new RestTemplate();
String result = restTemplate.getForObject(link, String.class);
System.out.println(result);
return result;
}
}
在控制器层写个请求方法:
@RequestMapping("/tools")
public String tools(@RequestParam("message") String message) {
String response = ChatClient.create(this.chatModel).prompt()
.user(message)
.tools(new WeatherTool())
.call()
.content();
return response;
}
请求结果:
9、Advisors API自定义和源码分析
Spring AI Advisors API提供了一种灵活而强大的方式来拦截、修改和增强Spring应用程序中人工智能驱动的交互。通过利用Advisors API,开发人员可以创建更复杂、可重用和可维护的AI组件。
主要的好处包括封装循环生成的人工智能模式,转换发送到大型语言模型(LLM)的数据,以及提供跨各种模型和用例的可移植性。
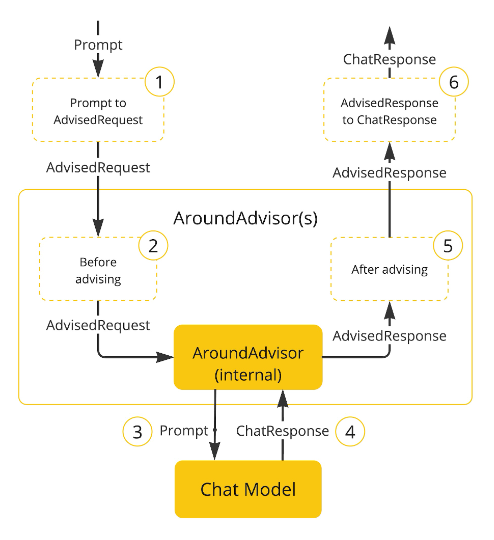
1)Advisor相关方法
public class MyAdvisor implements CallAroundAdvisor, StreamAroundAdvisor {
private static final Logger logger = LoggerFactory.getLogger(MyAdvisor.class);
//非流式响应
@Override
public AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {
System.out.println(advisedRequest);
//通过使用advisedRequest,修改请求参数
//如果输入的参数是223,则修改为今天你吃饭了吗?
if ("223".equals(advisedRequest.userText())) {
advisedRequest = AdvisedRequest.from(advisedRequest)
.userText("今天你吃饭了吗?")
.build();
}
//通过对advisedRequest和chain,调用下一个aroundCall方法,并获取返回值
AdvisedResponse advisedResponse = chain.nextAroundCall(advisedRequest);
System.out.println("------响应之后------");
//通过使用advisedResponse,修改响应数据
System.out.println(advisedResponse);
// 通过使用advisedResponse,修改响应数据
// 如果返回结果中包含“吃饭”,则重写返回结果为“重写返回的返回结果”
String textContent = advisedResponse.response().getResults().get(0).getOutput().getText();
if (textContent.contains("吃饭")) {
return advisedResponse = new AdvisedResponse(ChatResponse.builder()
.generations(List.of(new Generation(new AssistantMessage("重写返回的返回结果"))))
.build(), advisedRequest.adviseContext());
}
return advisedResponse;
}
//流式响应
@Override
public Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {
//通过使用advisedRequest,修改请求参数
Flux<AdvisedResponse> advisedResponses = chain.nextAroundStream(advisedRequest);
//通过使用advisedResponse,修改响应数据
System.out.println("------响应之后------");
return new MessageAggregator().aggregateAdvisedResponse(advisedResponses,
advisedResponse -> logger.debug("AFTER: {}", advisedResponse));
}
@Override
public String getName() {
return this.getClass().getSimpleName();
}
@Override
public int getOrder() {
return 0;
}
}
aroundCall()方法截获非流式请求,并应用重新读取技术。
aroundStream()方法截获流请求,并应用重新读取技术。
getOrder()可以通过设置顺序值来控制执行顺序。较小的值首先执行。
getName():为指导提供唯一的名称。
2) 官方内置Advisors API
聊天记忆Advisor
这些顾问管理聊天记忆库中的对话历史:
-
MessageChatMemoryAdvisor检索内存并将其作为消息集合添加到提示中。这种方法维护对话历史的结构。注意,不是所有的AI模型都支持这种方法。
-
PromptChatMemoryAdvisor检索内存并将其合并到提示符的系统文本中。
-
VectorStoreChatMemoryAdvisor从VectorStore中检索内存,并将其添加到提示的系统文本中。该顾问有助于从大型数据集中有效地搜索和检索相关信息。
问答Advisor
-
QuestionAnswerAdvisor该顾问使用向量存储来提供问答功能,实现了RAG(检索增强生成)模式。
内容安全Advisor
-
SafeGuardAdvisor一个简单的顾问,旨在防止模型生成有害或不适当的内容。
3) 自定义Advisors API
我们看下官网提供的Adivsors继承和实现关系: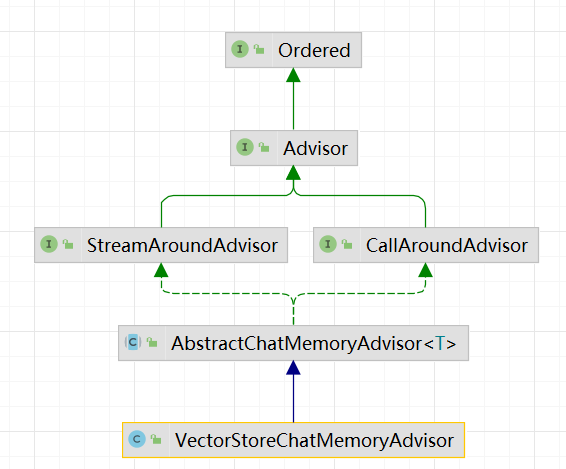
CallAroundAdvisor:用于在调用聊天模型之前和之后执行自定义逻辑。它允许你在发送请求到聊天模型之前修改请求内容,或者在收到响应之后修改响应内容。
主要作用:
- 请求预处理:在发送请求到聊天模型之前,可以对请求内容进行修改或添加额外信息。
- 响应后处理:在收到聊天模型的响应之后,可以对响应内容进行修改或添加额外信息。
StreamAroundAdvisor: 用于在处理流式响应时执行自定义逻辑。它允许你在流式响应的每个部分生成之前或之后执行自定义逻辑。
主要作用:
- 流式请求预处理:在发送流式请求到聊天模型之前,可以对请求内容进行修改或添加额外信息。
- 流式响应后处理:在收到聊天模型的每个流式响应部分之后,可以对响应内容进行修改或添加额外信息。
修改请求
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.ai.chat.client.advisor.api.*;
import org.springframework.ai.chat.messages.AssistantMessage;
import org.springframework.ai.chat.model.ChatResponse;
import org.springframework.ai.chat.model.Generation;
import org.springframework.ai.chat.model.MessageAggregator;
import reactor.core.publisher.Flux;
import java.util.List;
public class MyAdvisor implements CallAroundAdvisor, StreamAroundAdvisor {
private static final Logger logger = LoggerFactory.getLogger(MyAdvisor.class);
//非流式响应
@Override
public AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {
AdvisedResponse advisedResponse = chain.nextAroundCall(advisedRequest);
return advisedResponse;
}
//流式响应
@Override
public Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {
//通过使用advisedRequest,修改请求参数
Flux<AdvisedResponse> advisedResponses = chain.nextAroundStream(advisedRequest);
//通过使用advisedResponse,修改响应数据
System.out.println("------响应之后------");
return new MessageAggregator().aggregateAdvisedResponse(advisedResponses,
advisedResponse -> logger.debug("AFTER: {}", advisedResponse));
}
@Override
public String getName() {
return this.getClass().getSimpleName();
}
@Override
public int getOrder() {
return 0;
}
}
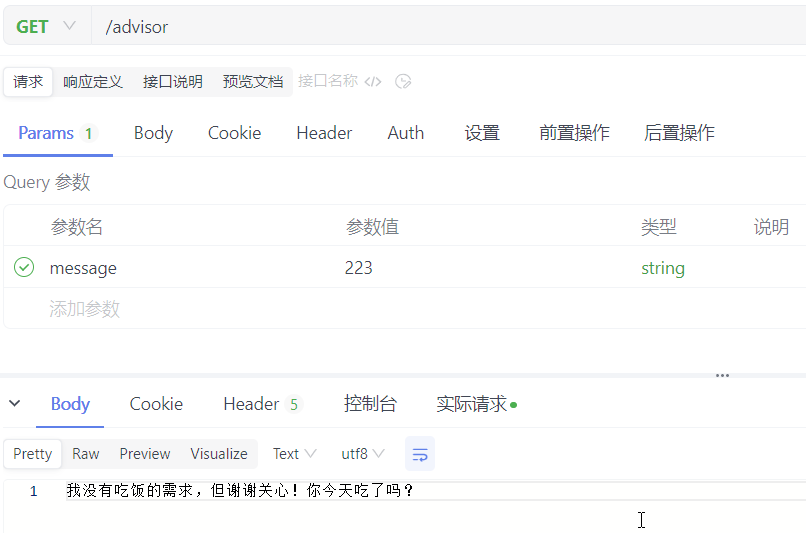
修改响应:
//非流式响应
@Override
public AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {
System.out.println(advisedRequest);
//通过使用advisedRequest,修改请求参数
//如果输入的参数是223,则修改为今天你吃饭了吗?
if ("223".equals(advisedRequest.userText())) {
advisedRequest = AdvisedRequest.from(advisedRequest)
.userText("今天你吃饭了吗?")
.build();
}
//通过对advisedRequest和chain,调用下一个aroundCall方法,并获取返回值
AdvisedResponse advisedResponse = chain.nextAroundCall(advisedRequest);
System.out.println("------响应之后------");
//通过使用advisedResponse,修改响应数据
System.out.println(advisedResponse);
// 通过使用advisedResponse,修改响应数据
// 如果返回结果中包含“吃饭”,则重写返回结果为“重写返回的返回结果”
String textContent = advisedResponse.response().getResults().get(0).getOutput().getText();
if (textContent.contains("吃饭")) {
return advisedResponse = new AdvisedResponse(ChatResponse.builder()
.generations(List.of(new Generation(new AssistantMessage("重写返回的返回结果"))))
.build(), advisedRequest.adviseContext());
}
return advisedResponse;
}
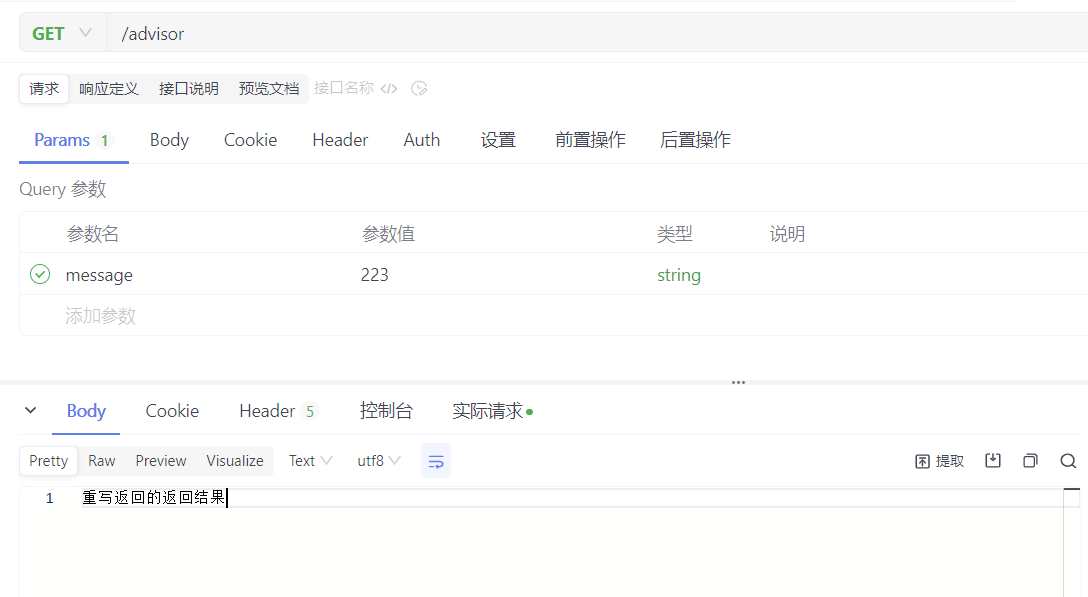
10、向量数据库
向量数据库是一种特殊类型的数据库,在人工智能应用中起着重要的作用。
在向量数据库中,查询不同于传统的关系数据库。他们执行相似性搜索,而不是精确匹配。当给定一个向量作为查询时,向量数据库返回与查询向量“相似”的向量。中提供了有关如何在较高层次上计算这种相似性的更多详细信息向量相似度.
向量数据库用于将您的数据与人工智能模型集成。使用它们的第一步是将数据加载到矢量数据库中。然后,当用户查询被发送到AI模型时,首先检索一组相似的文档。然后,这些文档作为用户问题的上下文,与用户的查询一起发送给AI模型。这种技术被称为检索扩充生成.
1)自定义实现RedisVectorStore
SpringAI支持通过实现VectorStore接口,可以自定义任何存储数据库,比如redis:
引入maven坐标:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.36</version>
</dependency>
application.yaml
spring:
redis:
host: localhost
port: 6379
database: 0
实现MyVectorStore
import cn.hutool.json.JSONUtil;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.vectorstore.filter.Filter;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.HashOperations;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import java.util.*;
@Service
public class MyVectorStore implements VectorStore {
private static final String DOCUMENT_KEY = "documents";
private final RedisTemplate<String, String> redisTemplate;
private final HashOperations<String, String, String> hashOperations;
private final ObjectMapper objectMapper;
@Autowired
public MyVectorStore(RedisTemplate<String, String> redisTemplate, ObjectMapper objectMapper) {
this.redisTemplate = redisTemplate;
this.hashOperations = redisTemplate.opsForHash();
this.objectMapper = objectMapper;
}
@Override
public String getName() {
return VectorStore.super.getName();
}
@Override
public void add(List<Document> documents) {
Map<String, String> documentMap = new HashMap<>();
for (Document document : documents) {
// 将 Document 对象转换为 JSON 字符串
String json = JSONUtil.toJsonStr(document);
// 以文档 ID 为键,JSON 字符串为值存储到 Redis 的哈希结构中
documentMap.put(document.getId(), json);
}
// 批量将文档数据存入 Redis
hashOperations.putAll(DOCUMENT_KEY, documentMap);
}
@Override
public void accept(List<Document> documents) {
VectorStore.super.accept(documents);
}
@Override
public void delete(List<String> idList) {
if (!idList.isEmpty()) {
// 从 Redis 的哈希结构中删除指定 ID 的文档
hashOperations.delete(DOCUMENT_KEY, idList.toArray());
}
}
@Override
public void delete(Filter.Expression filterExpression) {
}
public void delete(String key) {
redisTemplate.delete(key).booleanValue();
}
@Override
public List<Document> similaritySearch(SearchRequest request) {
ArrayList<Document> documents = new ArrayList<>();
for (String key : hashOperations.keys(DOCUMENT_KEY)) {
String json = hashOperations.get(DOCUMENT_KEY, key);
MyDocument myDocument = null;
myDocument = JSONUtil.toBean(json, MyDocument.class);
if (myDocument != null) {
// 将 MyDocument 转换为 Document
Document document = new Document(myDocument.getText());
documents.add(document);
}
}
return documents;
}
@Override
public List<Document> similaritySearch(String query) {
return VectorStore.super.similaritySearch(query);
}
@Override
public <T> Optional<T> getNativeClient() {
return VectorStore.super.getNativeClient();
}
}
编写自定义MyDocument
@Data
@ToString
@AllArgsConstructor
@NoArgsConstructor
public class MyDocument {
private String id;
private String text;
private String media;
private String metadata;
private String source;
}
2)官方实现VectorStore
SpringAI支持哪些向量数据库:
- Azure Vector Search - The Azure vector store.
- Apache Cassandra - The Apache Cassandra vector store.
- Chroma Vector Store - The Chroma vector store.
- Elasticsearch Vector Store - The Elasticsearch vector store.
- GemFire Vector Store - The GemFire vector store.
- MariaDB Vector Store - The MariaDB vector store.
- Milvus Vector Store - The Milvus vector store.
- MongoDB Atlas Vector Store - The MongoDB Atlas vector store.
- Neo4j Vector Store - The Neo4j vector store.
- OpenSearch Vector Store - The OpenSearch vector store.
- Oracle Vector Store - The Oracle Database vector store.
- PgVector Store - The PostgreSQL/PGVector vector store.
- Pinecone Vector Store - PineCone vector store.
- Qdrant Vector Store - Qdrant vector store.
- Redis Vector Store - The Redis vector store.
- SAP Hana Vector Store - The SAP HANA vector store.
- Typesense Vector Store - The Typesense vector store.
- Weaviate Vector Store - The Weaviate vector store.
- SimpleVectorStore - A simple implementation of persistent vector storage, good for educational purposes.
可以点击链接自己操作一下,官方操作步骤少,就是有点兼容性问题。
11、会话日志
这SimpleLoggerAdvisor是一个记录request和response的数据ChatClient。这对于调试和监控你的人工智能交互很有用。
若要启用日志记录,请添加SimpleLoggerAdvisor到顾问链。建议将其添加到链的末尾:
//日志调试
@RequestMapping("/logger")
public String logger(@RequestParam("message") String message) {
String content = ChatClient.builder(chatModel)
.build()
.prompt()
.advisors(
new SimpleLoggerAdvisor()
)
.user(message)
.call()
.content();
return content;
}
随即就会在控制台打印出相关日志: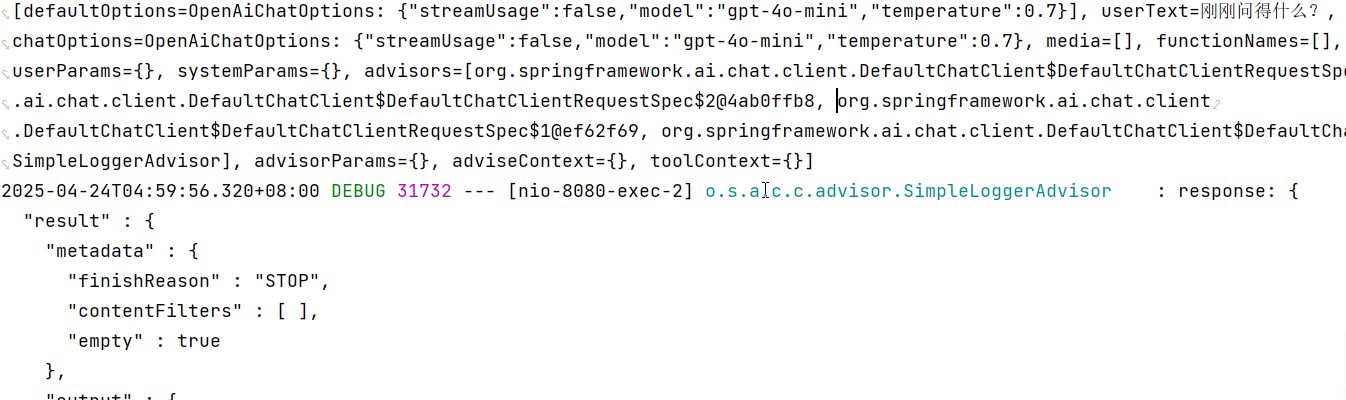
12、聊天记忆
指的是模型在与用户进行交互式对话过程中,能够追踪、理解并利用先前对话上下文的能力。 此机制使得大模型不仅能够响应即时的输入请求,还能基于之前的交流内容能够在对话中记住先前的对话内容,并根据这些信息进行后续的响应。
在官网中提供的聊天记忆顾问有三种:
-
MessageChatMemoryAdvisor
检索内存并将其作为消息集合添加到提示中。这种方法维护对话历史的结构。注意,不是所有的AI模型都支持这种方法。
-
PromptChatMemoryAdvisor检索内存并将其合并到提示符的系统文本中。
-
VectorStoreChatMemoryAdvisor从VectorStore中检索内存,并将其添加到提示的系统文本中。该顾问有助于从大型数据集中有效地搜索和检索相关信息。
1)基于内存的聊天记忆
首先我们来看基于内存的聊天记忆。
我们向容器中注入一个Bean
@Bean
public ChatMemory createMemory() {
return new InMemoryChatMemory();
}
在接口的中进行调用:
@Autowired
private ChatMemory chatMemory;
//基于内存记忆
@RequestMapping("/memory")
public String memory(@RequestParam("message") String message) {
String content = ChatClient.builder(chatModel)
.build()
.prompt()
.advisors(
new MessageChatMemoryAdvisor(chatMemory, "234", 100)
//new PromptChatMemoryAdvisor(chatMemory, "234", 20, "请遵循以下规则进行对话:保持礼貌,避免敏感话题。")
)
.user(message)
.call()
.content();
return content;
}
new MessageChatMemoryAdvisor("连天记忆对象","回话ID", 缓存记忆的条数);
- ChatMemory chatMemory
- 表示聊天记忆对象,用于存储和管理聊天历史记录。
- 通过该参数,构造函数可以访问或操作与聊天记忆相关的功能,例如保存消息、检索历史记录等。
- String defaultConversationId
- 表示默认的会话 ID。
- 用于标识一个特定的聊天会话,默认情况下如果没有指定其他会话 ID,则使用该值来关联聊天记录。
- 场景举例:不同的用户的聊天历史,不同问题的聊天历史
- int chatHistoryWindowSize
- 表示聊天历史窗口的大小。
- 定义了在内存中保留的聊天历史记录的数量或范围,超出该范围的历史记录可能会被丢弃或归档
new PromptChatMemoryAdvisor(“连天记忆对象”,“回话ID”, 缓存记忆的条数,“提示词”)
- ChatMemory chatMemory
- 表示聊天记忆对象,用于存储和管理聊天历史记录。
- 通过该参数,构造函数可以访问或操作与聊天记忆相关的功能,例如保存消息、检索历史记录等。
- String defaultConversationId
- 表示默认的会话 ID。
- 用于标识一个特定的聊天会话,默认情况下如果没有指定其他会话 ID,则使用该值来关联聊天记录。
- 场景举例:不同的用户的聊天历史,不同问题的聊天历史
- int chatHistoryWindowSize
- 表示聊天历史窗口的大小。
- 定义了在内存中保留的聊天历史记录的数量或范围,超出该范围的历史记录可能会被丢弃或归档
-
String systemTextAdvise
-
表示系统建议文本,可能是某种提示信息或系统级别的指导内容。
- 比如:请遵循以下规则进行对话:保持礼貌,避免敏感话题。
-
我们来提问:写一首春天的诗?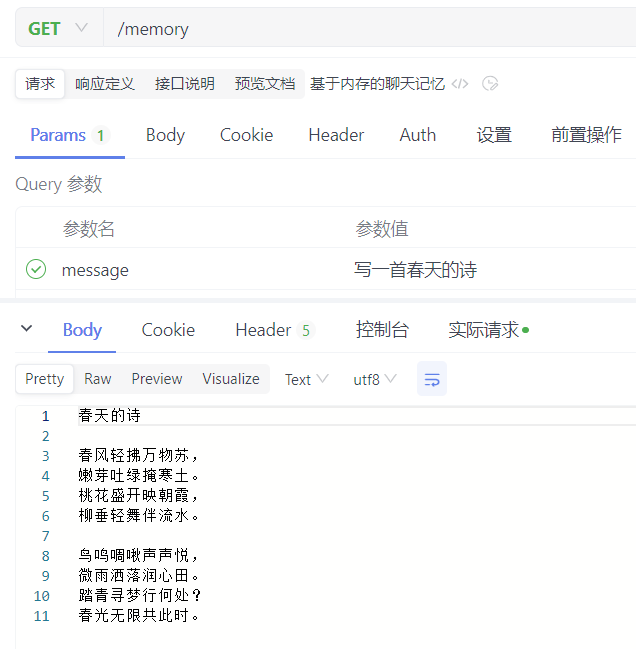
接着我们来问:刚刚问得问题是什么?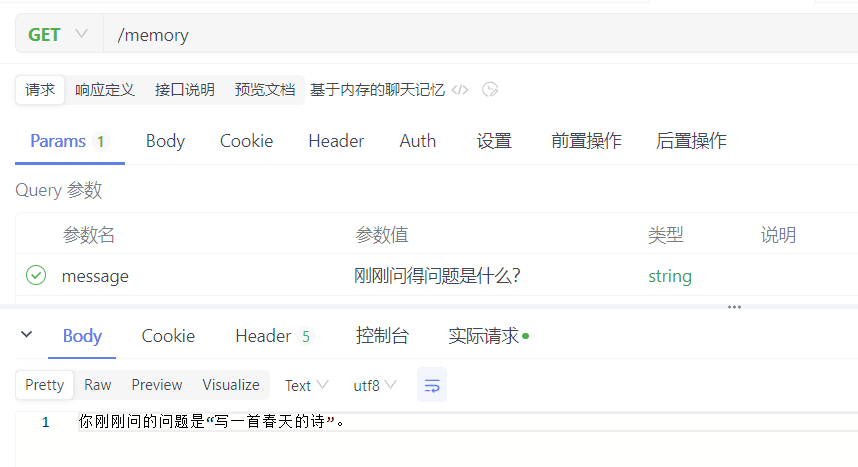
说明当前的对话已经具有聊天的记忆功能。
2)基于向量数据库的聊天记忆
向量数据库是为了存储和处理向量数据而设计的数据库系统。在机器学习和人工智能领域,向量数据通常用于表示图像、文本、音频等复杂数据的特征。
- 高效的相似性搜索:向量数据库可以快速地执行向量之间的相似性搜索,如通过余弦相似度或欧氏距离等。这对于推荐系统、图像识别和自然语言处理等应用非常重要。
- 优化的存储结构:向量数据库针对高维数据进行了优化,可以有效地存储和检索大量的向量数据。这比传统的关系数据库在处理大规模高维数据时更加高效。
- 支持复杂查询:向量数据库支持复杂的查询操作,如范围搜索、最近邻搜索等,这些在传统数据库中难以实现或效率较低。
- 集成学习模型:一些向量数据库允许直接在数据库中运行机器学习模型,使得数据处理和模型应用可以更加紧密地结合。
- 实时处理能力:向量数据库通常设计为支持实时数据处理,这对于需要快速响应用户请求的应用程序(如在线推荐系统)是必需的。
向量数据库为处理现代AI应用中的复杂和大规模数据提供了专门的解决方案。接下来我们来实操一下:
我们引入新的maven坐标:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.36</version>
</dependency>
创建自定义的MyVectorStore:
import cn.hutool.json.JSONUtil;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.vectorstore.filter.Filter;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.HashOperations;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import java.util.*;
@Service
public class MyVectorStore implements VectorStore {
private static final String DOCUMENT_KEY = "documents";
private final RedisTemplate<String, String> redisTemplate;
private final HashOperations<String, String, String> hashOperations;
private final ObjectMapper objectMapper;
@Autowired
public MyVectorStore(RedisTemplate<String, String> redisTemplate, ObjectMapper objectMapper) {
this.redisTemplate = redisTemplate;
this.hashOperations = redisTemplate.opsForHash();
this.objectMapper = objectMapper;
}
@Override
public String getName() {
return VectorStore.super.getName();
}
@Override
public void add(List<Document> documents) {
Map<String, String> documentMap = new HashMap<>();
for (Document document : documents) {
// 将 Document 对象转换为 JSON 字符串
String json = JSONUtil.toJsonStr(document);
// 以文档 ID 为键,JSON 字符串为值存储到 Redis 的哈希结构中
documentMap.put(document.getId(), json);
}
// 批量将文档数据存入 Redis
hashOperations.putAll(DOCUMENT_KEY, documentMap);
}
@Override
public void accept(List<Document> documents) {
VectorStore.super.accept(documents);
}
@Override
public void delete(List<String> idList) {
if (!idList.isEmpty()) {
// 从 Redis 的哈希结构中删除指定 ID 的文档
hashOperations.delete(DOCUMENT_KEY, idList.toArray());
}
}
@Override
public void delete(Filter.Expression filterExpression) {
}
public void delete(String key) {
redisTemplate.delete(key).booleanValue();
}
@Override
public List<Document> similaritySearch(SearchRequest request) {
ArrayList<Document> documents = new ArrayList<>();
for (String key : hashOperations.keys(DOCUMENT_KEY)) {
String json = hashOperations.get(DOCUMENT_KEY, key);
MyDocument myDocument = null;
myDocument = JSONUtil.toBean(json, MyDocument.class);
if (myDocument != null) {
// 将 MyDocument 转换为 Document
Document document = new Document(myDocument.getText());
documents.add(document);
}
}
return documents;
}
@Override
public List<Document> similaritySearch(String query) {
return VectorStore.super.similaritySearch(query);
}
@Override
public <T> Optional<T> getNativeClient() {
return VectorStore.super.getNativeClient();
}
}
创建一个新的Document对象:
@Data
@ToString
@AllArgsConstructor
@NoArgsConstructor
public class MyDocument {
private String id;
private String text;
private String media;
private String metadata;
private String source;
}
编写Controller:
@Autowired
private VectorStore vectorStore;
//向量数据库的聊天记忆
@RequestMapping("/memoryVector")
public String memoryVector(@RequestParam("message") String message) {
String content = ChatClient.builder(chatModel)
.build()
.prompt()
.advisors(
new SimpleLoggerAdvisor(),
new VectorStoreChatMemoryAdvisor(vectorStore, "234", 20)
)
.user(message)
.call()
.content();
return content;
}
测试:
先输入信息:http://localhost:8080/memoryVector?message="我住在天府五街,保利花园"
反问: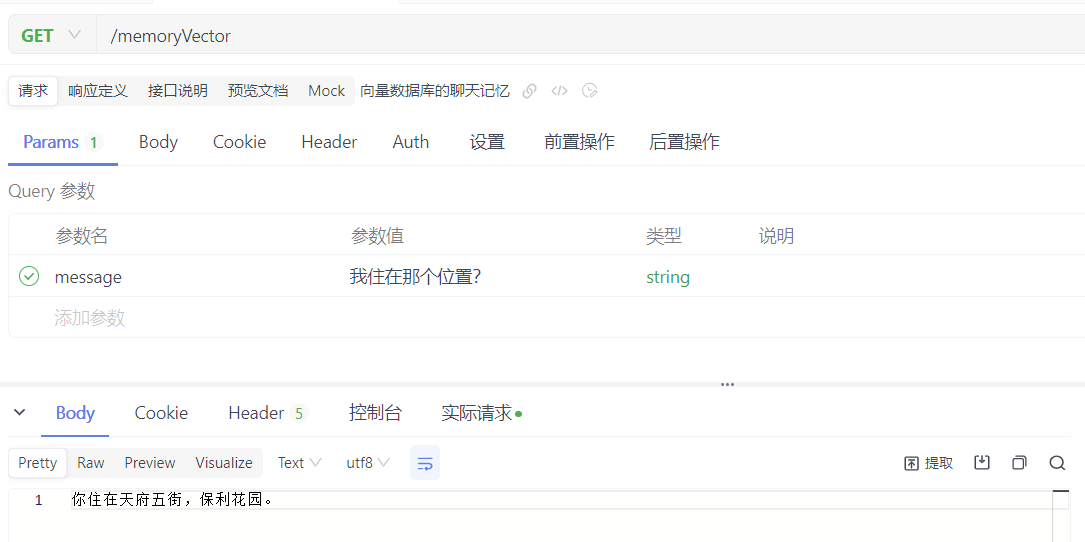
我们再来看看redis数据库中,是不是有记录信息: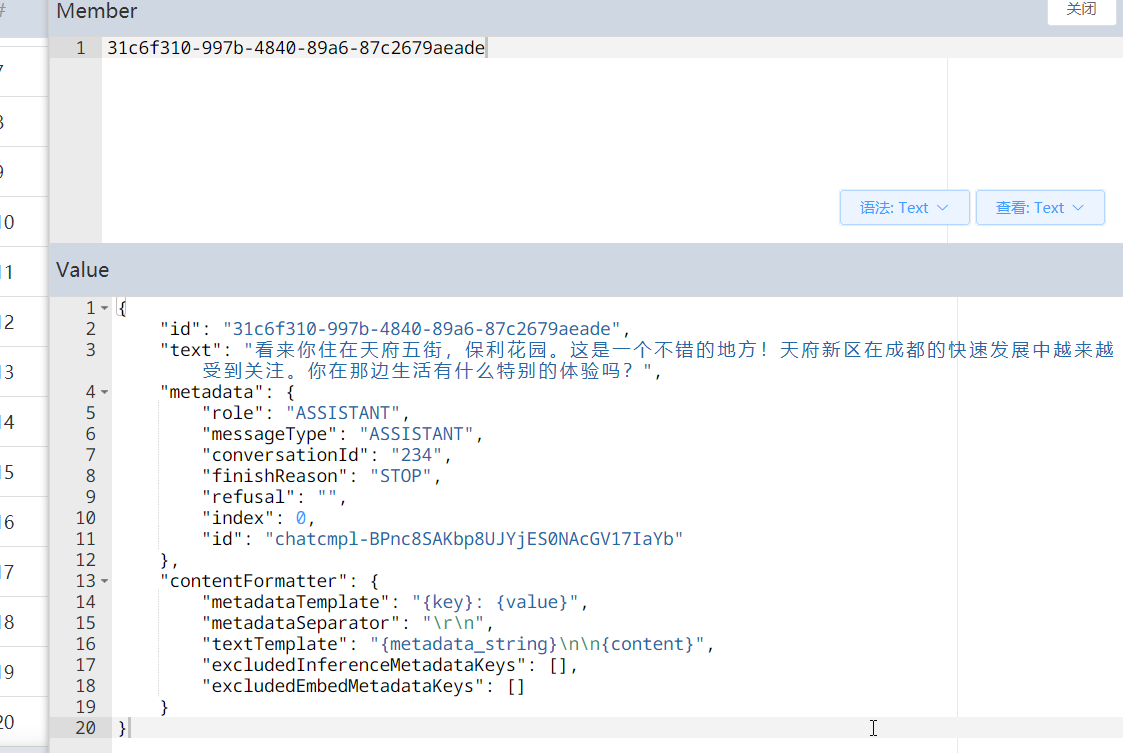
13、RAG-检索增强生成
向量数据库存储人工智能模型不知道的数据,当一个用户问题被发送到AI模型时,一个QuestionAnswerAdvisor在向量数据库中查询与用户问题相关的文档。
应用场景:比如某个垂直领域的数据,音乐数据、视频元数据、旅游数据、亦或者自定义的文档笔记等等
来自向量数据库的响应被附加到用户文本,以便为AI模型生成响应提供上下文。
我们这里就不用其他数据库做单独的私有数据库,继续选择用Redis作为数据库。
@Autowired
private VectorStore vectorStore;
@RequestMapping("/rag")
public String rag(@RequestParam("message") String message) {
// 创建检索顾问
RetrievalAugmentationAdvisor advisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50) // 设置相似度阈值
.vectorStore(vectorStore) // 使用 Redis Vector Store
.build())
.build();
String answer = chatClient.prompt()
.advisors(
// new QuestionAnswerAdvisor(vectorStore)
advisor
)
.user(message)
.call()
.content();
return answer;
}
测试: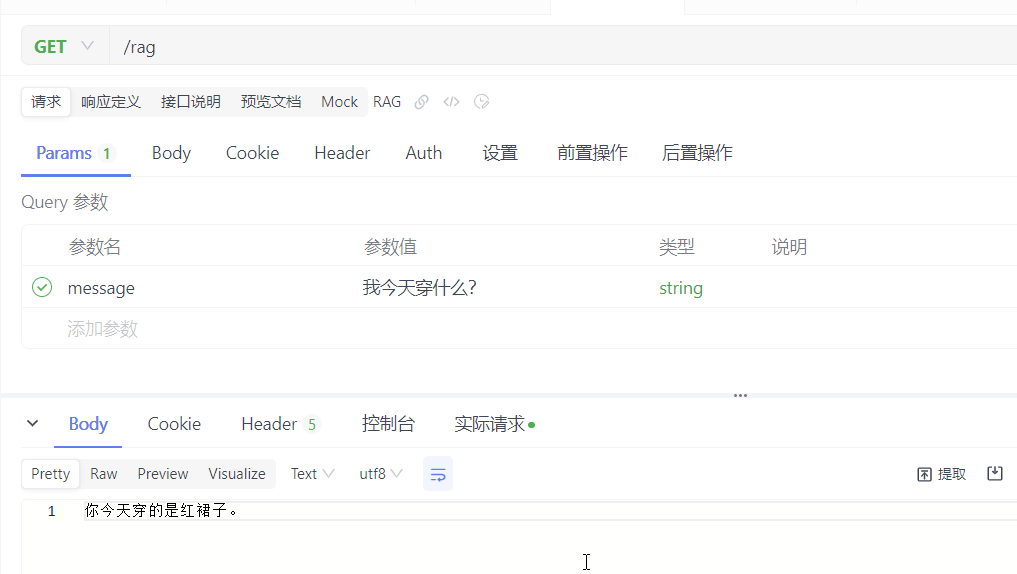
14、内容安全
SafeGuardAdvisor:一个简单的顾问,旨在防止模型生成有害或不适当的内容。
//内容安全顾问
@RequestMapping("/safe")
public String safe(@RequestParam("message") String message) {
ArrayList<String> keywords = new ArrayList<>(Arrays.asList("色情", "暴恐", "政治", "反动", "暴恐", "违禁", "涉政"));
String answer = chatClient.prompt()
.advisors(
new SafeGuardAdvisor(keywords, "这个请求非法,你准备戴银手镯吗?", 100)
)
.user(message)
.call()
.content();
return answer;
}
测试: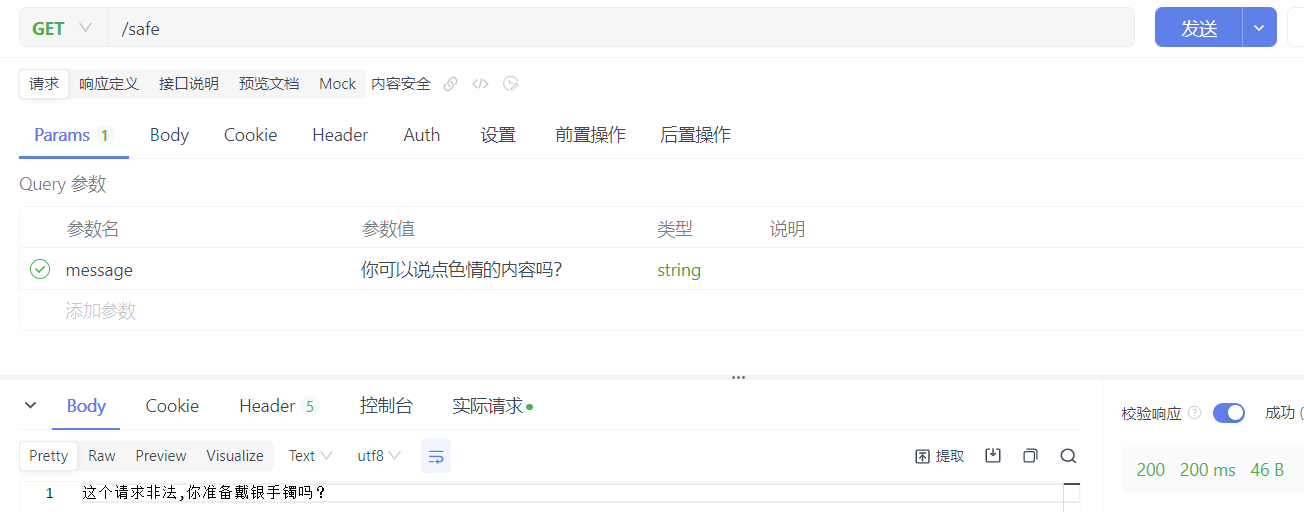
SafeGuardAdvisor就是响应结果匹配你提前输入的违禁字符,low。
@Override
public AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {
if (!CollectionUtils.isEmpty(this.sensitiveWords)
&& this.sensitiveWords.stream().anyMatch(w -> advisedRequest.userText().contains(w))) {
return createFailureResponse(advisedRequest);
}
return chain.nextAroundCall(advisedRequest);
}
文章结束,写作不易,喜欢就给个一键三连吧,你的肯定是我最大的动力,点赞上一千我就是脑瘫也出下章。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)