通过LoRA适配器对齐中间层大小以实现知识蒸馏
中间层蒸馏(Intermediate Layer Distillation, ILD)是知识蒸馏(Knowledge Distillation, KD)的一种变体,属于神经网络压缩方法。ILD需要通过映射对齐教师模型与学生模型中间层的维度以计算训练损失函数,但该映射在推理阶段并不会被使用。这种不一致性可能会降低中间层的学习效果。本研究提出LoRAILD方法,利用LoRA适配器消除这种不一致性。然而
Aligning Sizes of Intermediate Layers by LoRA Adapter for Knowledge Distillation
发表:WS 2025
机构:东京科学研究所
Abstract
中间层蒸馏(Intermediate Layer Distillation, ILD)是知识蒸馏(Knowledge Distillation, KD)的一种变体,属于神经网络压缩方法。ILD需要通过映射对齐教师模型与学生模型中间层的维度以计算训练损失函数,但该映射在推理阶段并不会被使用。这种不一致性可能会降低中间层的学习效果。本研究提出LoRAILD方法,利用LoRA适配器消除这种不一致性。然而,实验结果表明,LoRAILD并未超越现有方法。此外,与先前研究相反,我们发现传统ILD的表现甚至未超过原始KD(vanilla KD)。通过对蒸馏模型中间层的分析,我们认为ILD并未提升语言模型的性能。
Introduction
大语言模型(LLM)在各种自然语言处理(NLP)任务上的性能正在快速提升,但这是以巨大的参数量为代价的,由此产生了高昂的计算成本。因此,如何在保持模型性能的同时减少参数量成为一个重要研究课题。知识蒸馏(Knowledge Distillation, KD)(Buciluǎ等,2006;Hinton等,2015)是模型压缩方法之一。KD采用两个模型:教师模型和学生模型。教师模型已针对特定任务完成训练,其输出作为软标签(soft labels)指导学生模型模仿教师行为。传统KD通常仅利用教师模型的输出,而中间层蒸馏(Intermediate Layer Distillation, ILD)(Romero等,2015)额外利用中间层信息;先前研究(Sun等,2019;Passban等,2021;Haidar等,2022)声称ILD优于原始KD(vanilla KD)。
本研究提出LoRAILD,通过采用LoRA(Hu等,2021)适配器对齐师生模型的中间层维度来改进传统ILD。我们通过与传统KD基线的实证对比评估LoRAILD的性能。总体而言,发现LoRAILD未超越传统ILD基线,且即使在我们的实验设置下,传统ILD也未必优于原始KD。
Background
Knowledge Distillation

Intermedite Layer Distillation
中间层蒸馏(Intermediate Layer Distillation, ILD)(Romero等,2015)是知识蒸馏(KD)的一种扩展方法。ILD不仅利用教师模型和学生模型的输出,还利用其中间层的信息。ILD要求学生模型与教师模型的层数和每层维度必须对齐。
当两个模型的层数不同时,需要进行调整,这是过去ILD研究的核心课题。PKD(Sun等,2019)采用启发式方法从教师模型中选取与学生模型层数相同的层,且这些选定层在整个学生模型训练过程中保持不变。ALP-KD(Passban等,2021)则将教师模型的层分组,每组对应学生模型的一个层,并通过加权平均聚合组内各层的输出。RAIL-KD(Haidar等,2022)则动态地在每个训练周期随机选择教师模型的层。
当教师模型与学生模型的中间层维度不一致时,必须通过维度对齐才能计算损失函数。先前研究(Romero等,2015;Haidar等,2022)采用了多种映射方法实现对齐:FitNets(Romero等,2015)使用卷积回归器,RAIL-KD(Haidar等,2022)采用线性层进行映射。在学生模型训练过程中,这些映射层与学生的其他参数一起被训练。然而,这些映射仅用于训练阶段,导致模型在训练和推理时的结构不一致。
这种不一致性可能会降低ILD的有效性。如果映射层在任务中被过度优化,而学生模型的中间层未能学习到良好特征,则在推理阶段移除映射层将导致模型性能下降。
Method
LoRAILD
为解决模型结构不一致性问题,我们提出LoRAILD方法,采用LoRA适配器替代传统映射层。由于LoRAILD在设计和实现上均保持训练与推理阶段适配器的存在,从而彻底消除了模型结构差异。
LoRA(Hu等,2021)是一种通过为模型特定模块分配两个低秩矩阵(维度分别为ℝⁱˣʳ和ℝʳˣᵒ)并仅训练这些矩阵来降低计算成本的方法。其中i和o分别表示目标模块的输入和输出维度,r作为输入侧矩阵的输出维度可手动设定。通过合理设置r值,低秩矩阵能够实现教师与学生模型中间层维度的对齐,因此可替代传统线性映射层。这些矩阵在推理阶段仍被保留,从而维持了线性映射的连续性。图1b展示了LoRAILD的架构:传统ILD使用线性层输出(图1a黄色部分)计算损失,而LoRAILD采用LoRA适配器输入侧矩阵的输出(图1b梯形部分)进行损失计算。
损失函数定义如下:
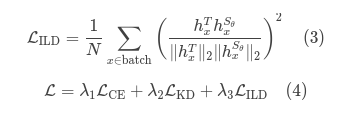
其中N为批次大小,hₓ表示样本x经LoRA适配器输入侧矩阵的输出(代表教师T或学生Sθ),各层输出经拼接后参与损失计算。式(4)中LCELCE和LKDLKD与式(1)定义相同,该损失函数形式与先前ILD方法(Sun等,2019;Haidar等,2022)保持一致。
Alignment of layers
尽管LoRA适配器解决了中间层维度对齐问题,师生模型间的层数差异仍需处理。本研究采用以下三种层对齐方法:
固定映射(Fixed)
在训练过程中始终选择教师模型的相同层与学生层对应。
平均池化(Average)
将教师模型的若干层分配给学生模型的每一层,并对所分配层的输出取平均值(未加权)。
随机选择(Random)
为每个学生层随机选择教师层,同时保持层序结构。随机操作可在每个小批量(Random step)或每个训练周期(Random epoch)执行。
上述方法与先前研究的实现基本一致:
-
Fixed 对应PKD(Sun等,2019)的启发式层选择
-
Average 简化了ALP-KD(Passban等,2021)的分组策略(未使用加权平均)
-
Random 延续了RAIL-KD(Haidar等,2022)的动态机制
附录A展示了Fixed与Average方法中师生层的具体对齐模式。
Curriculum Learning
在初步实验中,LoRAILD表现未达预期。我们观察到中间层蒸馏损失LILD首先下降,而交叉熵损失LCELCE未能有效降低。为确保LCE的优化效果,我们引入课程学习(curriculum learning)策略:初始阶段仅训练LCE和LKD,待其稳定后再将LILD加入总损失函数。
Experiment
Experimantal Settings
本实验采用RoBERTa-large(Liu等,2019)作为教师模型,DistilRoBERTa-base(Sanh等,2019)作为学生模型。两模型均添加LoRA适配器,其中教师模型仅训练LoRA适配器参数,学生模型则同步训练LoRA及原始模型参数。
实验数据集选自GLUE基准(Wang等,2018)的六个任务:CoLA、MRPC、QNLI、RTE、SST-2和STS-B。由于GLUE测试集的真实标签未公开,我们将原始验证集作为测试集,原始训练集的10%作为验证集,剩余90%用于训练。评估指标包括:CoLA采用Matthews相关系数,MRPC采用F1值,STS-B采用Pearson相关系数,其余任务使用准确率。
基线模型包含:
-
未使用知识蒸馏的微调学生模型(w/o KD)
-
原始知识蒸馏(Vanilla KD)
-
RAIL-KD的两种变体(RAIL-KD_c层输出拼接模式,RAIL-KD_l逐层计算模式)
-
添加课程学习的RAIL-KD_c(Curriculum,原RAIL-KD论文未采用此策略)
所有报告结果为五次运行的平均值,并执行显著性水平2.5%的单尾置换检验(one-tailed permutation tests)。超参数配置详见附录C。
Result
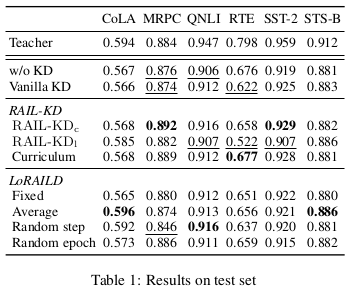
表1展示了实验结果,加粗数字表示各任务的最优性能指标,其显著高于带下划线的结果。基于LoRAILD的模型均未表现出明显优于基线的性能提升:Fixed和Random epoch在所有任务中均未超越已有方法;Average在CoLA和STS-B任务中取得最高分,但统计显著性未达标准;尽管Random step在QNLI任务上达到所有模型中的最佳表现,但其改进幅度微弱,且与RAIL-KD_c的性能差异无统计学意义。LoRAILD的有限改进表明,其采用的LoRA适配器未能实现预期效果,甚至可能干扰中间层的有效学习。
此外,所有RAIL-KD变体模型的表现均未超越未使用知识蒸馏的基准模型(w/o KD)和原始知识蒸馏(Vanilla KD),这一结果与先前研究(Haidar等,2022)的结论相矛盾——原论文声称RAIL-KD在所有任务中均优于w/o KD和Vanilla KD。RAIL-KD性能低于Vanilla KD的现象支持了我们的假设:推理阶段移除线性映射层会损害中间层蒸馏的有效性。
Analysis
Analysis method
为探究RAIL-KD和LoRAILD模型中各中间层的特征编码机制,我们对损失函数计算所用特征及中间层输出进行了聚类分析。针对LoRAILD、RAIL-KD以及未使用中间层蒸馏的对照组(设λ3=0)的教师模型与学生模型,我们分别获取了以下两类特征向量:
-
损失计算相关特征(h∗x,其中LoRAILD的hTx为层对齐前的原始值)
-
中间层直接输出
实验数据来自训练集样本,聚类采用k-means算法(MacQueen,1967),簇数k=2(分类任务)。除回归任务STS-B外,其余实验任务均参与分析。
聚类效果通过调整兰德指数(Adjusted Rand Index, ARI)(Hubert和Arabie,1985;Steinley,2004)评估,其对比基准为根据真实标签构建的黄金簇分布。
指标解读:
-
学生模型的ARI越高,表明其通过训练获得了更优的任务表征能力;
-
教师模型的ARI越高,说明其中间层能为学生训练提供更具价值的特征信息。
Analysis result
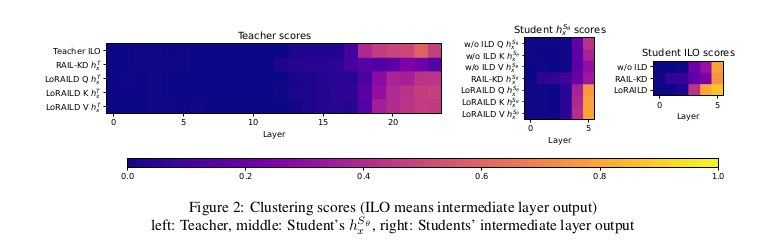
图2展示了调整兰德指数(ARI)的评分结果。左侧和中间的矩阵分别表示教师模型的hTx和学生模型的hSxθ对应的评分,右侧矩阵则为学生模型中间层直接输出的评分。各单元格数值为跨任务平均后的综合得分(CoLA除外,因其他任务均涉及句子语义处理,而BERT深层网络(≥18层)主要负责语义编码(Tenney等,2019;Jawahar等,2019))。
在左图中,RAIL-KD的hTx在深层(≥18层)评分显著低于教师原始中间层输出(Teacher ILO),表明其未能向学生传递有效的任务相关信息。相反,LoRAILD在深层表现出更高ARI值,证实教师特征信息得到更好保留。我们原假设移除线性映射会损害性能(因其丢弃了映射层学习的信息),但实际发现RAIL-KD的线性映射并未学习到任务相关特征,反而降低了教师原始信号(Teacher ILO)的质量。
中图和右图显示,RAIL-KD在学生模型深层(≥4层)未表现出相对w/o ILD基线的改进,而LoRAILD则成功实现提升。这一结果证明,LoRAILD为师生模型中间层对齐提供了更优方案。
Conclusion
实验结果表明(表1),无论是否采用中间层蒸馏(ILD)——包括使用LoRA适配器的LoRAILD或传统线性映射的RAIL-KD——模型性能均未显著超越原始知识蒸馏(Vanilla KD)。尽管聚类分析证实LoRAILD实现了更优的中间层特征对齐(如图2所示),但这种改进未能转化为下游任务性能的提升。因此,我们得出结论:当前形式的ILD方法对语言模型性能的影响有限。
Limitation
尽管本实验得出的负面结论与RAIL-KD(Haidar等,2022)先前报道的结果不一致,但我们的发现并未直接否定前人研究,而是表明中间层蒸馏(ILD)的普适性可能低于最初预期。实验采用的RAIL-KD及其他基线方法在基础模型、数据集和超参数设置上均与原论文存在差异,因此并非严格复现原始实验条件。
我们注意到教师模型的差异:由于原研究使用的教师模型未公开,本实验采用RoBERTa-large并添加了LoRA适配器,导致模型架构变化。数据集划分方面,如4.1节所述,我们将GLUE训练集的90%作为训练集,剩余10%作为验证集,原始验证集作为测试集。上述差异使得我们必须重新进行超参数搜索以适配当前设置。
实验范围聚焦于师生模型中间层维度不同的场景,始终需要对输出进行维度变换与对齐,因此所有实验中教师中间层输出均未直接作为学生模型的监督信号。我们明确声明:对于师生模型中间层维度相同、无需对齐的特殊情况(即教师中间层输出可直接使用),本研究未给出结论——此场景超出本文讨论范畴。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)