神经网络与深度学习(1)
定义:最简单的深度网络称为多层感知机。多层感知机由多层神经元组成,每一层与它的上一层相连,从中接收输入;同时每一层也与它的下一层相连,影响当前层的神经元。线性不可分问题: Minsky 1969 年提出 XOR 问题,无法进行线性分类。解决方法:使用多层感知机。在输入和输出层间加一或多层隐单元,构成多层感知器(多层前馈神经网络)。加一层隐节点(单元)为三层网络,可解决异或( XOR )问题。
神经网络与深度学习(1)
目录
一、多层感知机
1.1 多层感知机介绍
定义:最简单的深度网络称为多层感知机。多层感知机由多层神经
元组成,每一层与它的上一层相连,从中接收输入;同时每一层也与它的下一层相连,影响当前层的神经元。
线性不可分问题: Minsky 1969 年提出 XOR 问题,无法进行线性分类。
解决方法:使用多层感知机。在输入和输出层间加一或多层隐单元,构成多层感知器(多层前馈神经网络)。加一层隐节点(单元)为三层网络,可解决异或( XOR )问题。
由输入得到两个隐节点、一个输出层节点的输出: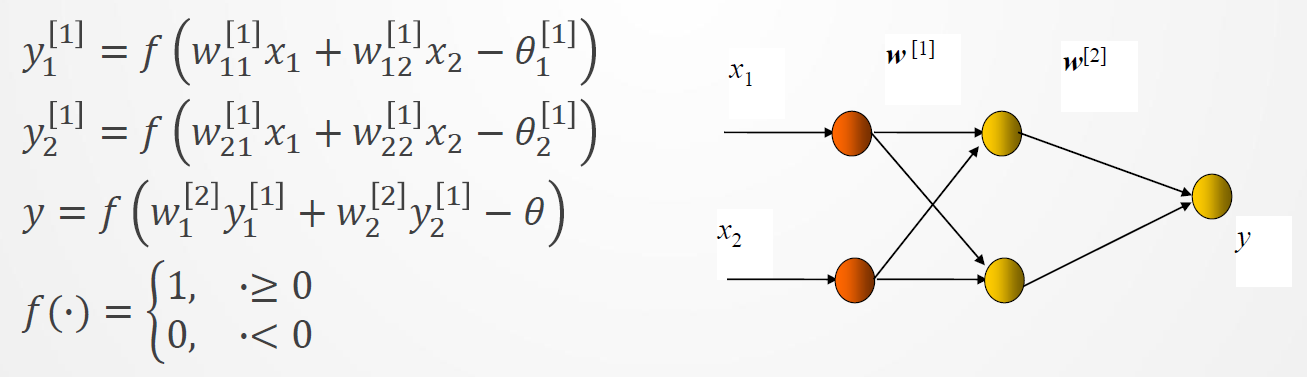
可得到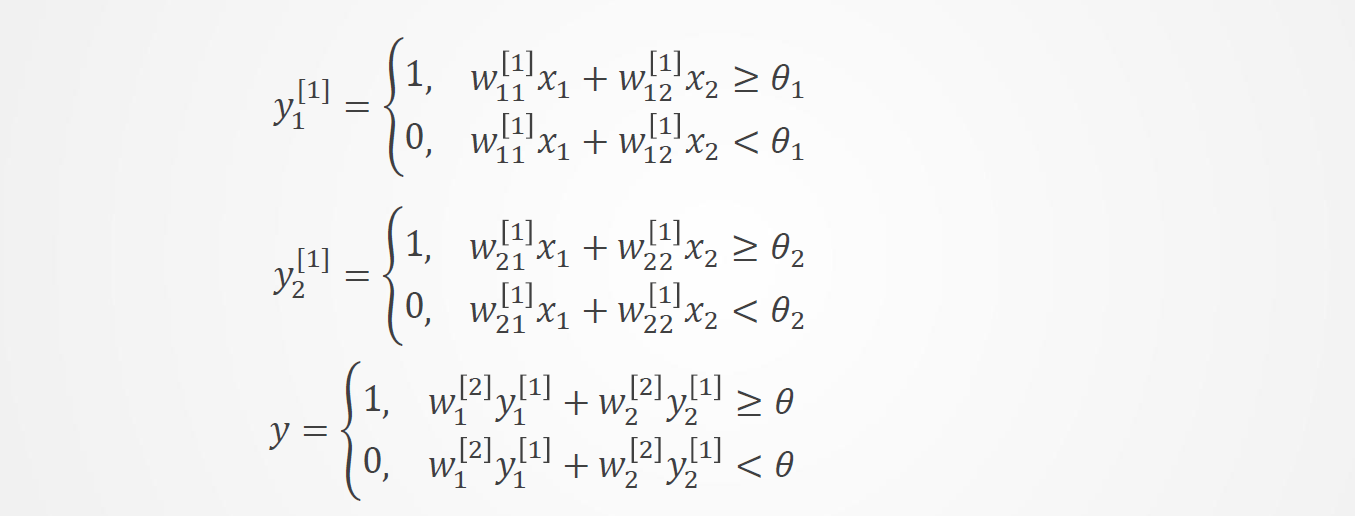
设网络有如下一组权值和阈值,可得各节点的输出: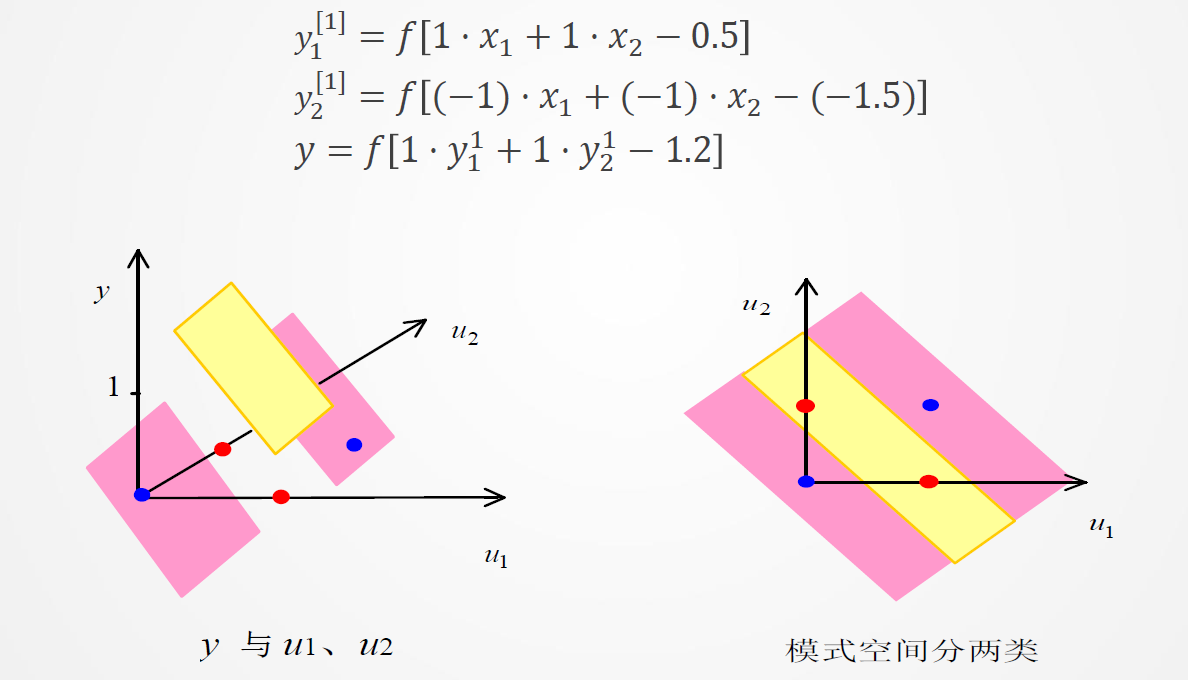
关于多层感知器网络,有如下定理:
定理1 若隐层节点(单元)可任意设置,用三层阈值节点的网络,可以实现任意的二值逻辑函数。
定理2 若隐层节点(单元)可任意设置,用三层 S 型非线性特性节点的网络,可以一致逼近紧集上的连续函数或按 范数逼近紧集上的平方可积函数。
二、多层前馈网络及BP 算法概述
2.1 多层前馈网络
多层感知机是一种多层前馈网络, 由多层神经网络构成,每层网络将输出传递给下一层网络。神经元间的权值连接仅出现在相邻层之间,不出现在其他位置。如果每一个神经元都连接到上一层的所有神经元(除输入层外),则成为 全连接网络 。下面讨论的都是此类网络。
多层前馈网络的反向传播(BP)学习算法,简称 BP 算法 ,是有导师的学习,它是梯度下降法在多层前馈网中的应用。
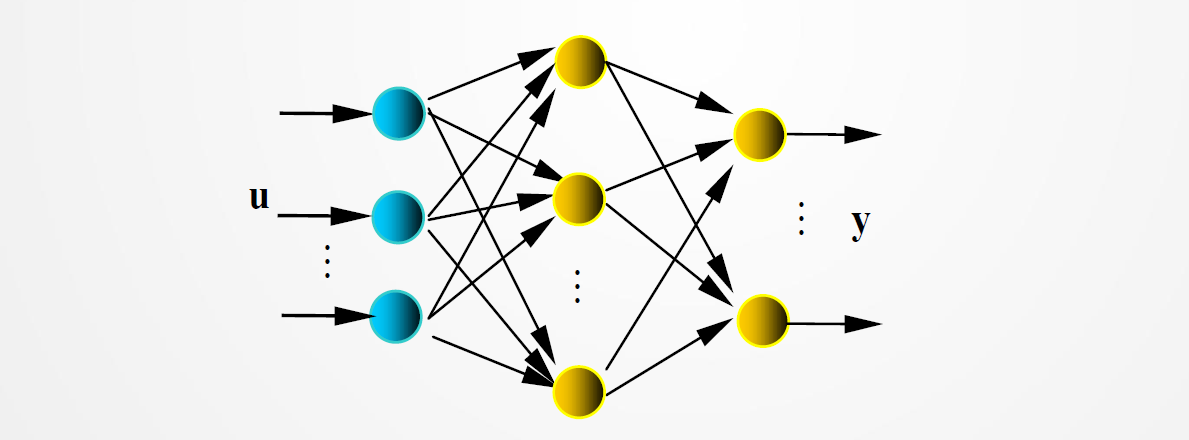
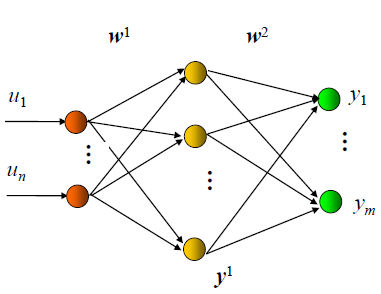
网络结构:见图 ,𝐮(或 𝐱)、 𝐲是网络的输入、输出向量,神经元用节点表示,网络由输入层、隐层和输出层节点组成,隐层可一层,也可多层(图中是单隐层),前层至后层节点通过权联接。由于用 BP 学习算法,所以常称 BP 神经网络。
2.2 BP算法简述
BP 学习算法由正向传播和反向传播组成:
①正向传播是输入信号从输入层经隐层,传向输出层,若输出层得到了期望的输出,则学习算法结束;否则,转至反向传播。
②反向传播是将误差 样本输出与网络输出之差)按原联接通路反向计算,由梯度下降法调整各层节点的权值和阈值,使误差减小。
三、BP算法详解
3.1 BP算法基本思想
设算法的输入输出样本(导师信号)为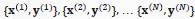
即共N个样本。或记为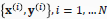
网络训练的目的,是使对每一个输入样本,调整网络权值参数w,使
输出均方误差最小化。这是一个最优化问题。
选取: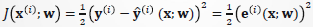
其中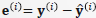
为求解上述最小化问题,考虑迭代算法:
设初始权值为 ,k时刻权值为
,k时刻权值为 ,则使用泰勒级数展开,有:
,则使用泰勒级数展开,有: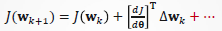
选择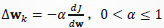
这样每一步都能保证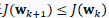 ,从而使 𝐽最终可收敛到最小。
,从而使 𝐽最终可收敛到最小。
这就是梯度下降算法,也是 BP 学习算法的基本思想。
计算过程:
①设置初始权系数 为较小的随机非零值;
为较小的随机非零值;
②给定输入/输出样本对,计算网络输出 , 完成前向传播
③计算目标函数 𝐽。如 𝐽<𝜀, 训练成功,退出;否则转入④
④反向传播计算 由输出层,按梯度下降法将误差反向传播,逐层调整权值。
3.2 BP算法推导
前向传播
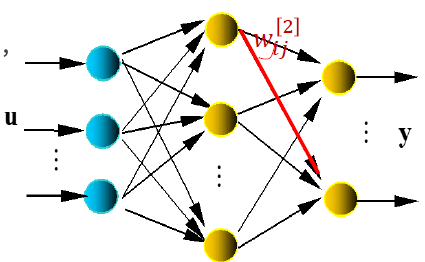
考虑二层神经网络(有一层隐含层)。
对于当前样本,隐含层输出:
对于第 l 层第 i 个神经元,其输出: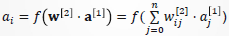
𝑓可选取为LogSigmoid函数: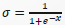
在输出端计算误差: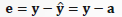 误差反传——输出层
误差反传——输出层
首先考虑输出层权值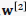 。 根据链式求导法则,注意到
。 根据链式求导法则,注意到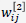 仅和
仅和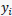 有关,因此
有关,因此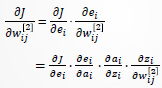
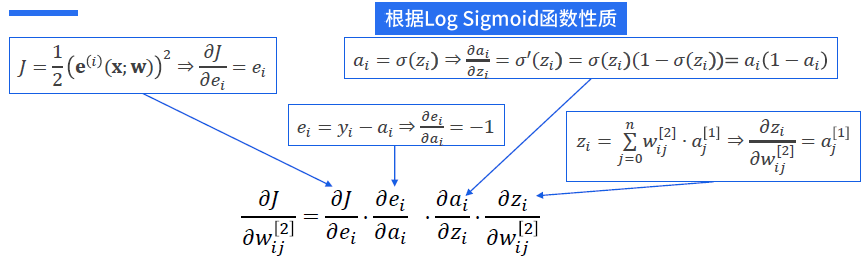
进一步有: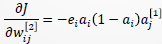
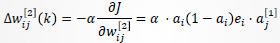
令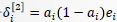 ,则有:
,则有: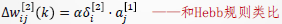
误差反传——隐含层
注意到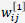 仅和
仅和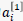 有关,因此
有关,因此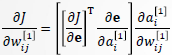
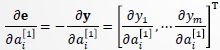
以为 例说明求法。由
例说明求法。由 表达式(见前向传播),有:
表达式(见前向传播),有: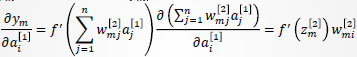
根据 Sigmoid 函数性质,同时利用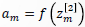 ,有:
,有: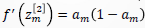
因此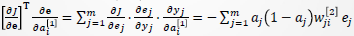
即误差进行反向传播。
综合上述结果,有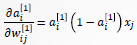
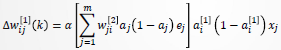
令 ,则
,则

误差反传——总结
1.初始化:𝑙=𝐿,𝐿为网络层数
2.如果 𝑙=𝐿 (输出层 ),则: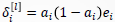
,否则(隐含层)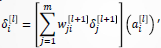
3.权值更新 :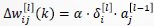
4.如果𝑙>0,则 𝑙←(𝑙−1),返回步骤 2 ,进行前一层更新(按从后向前顺序更新)对应输入层: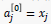
3.3 算法评述
优点
学习完全自主;
可逼近任意非线性函数;
缺点
算法非全局收敛;
收敛速度慢;
学习速率 α 选择
神经网络如何设计 几层?节点数?
四、性能优化
4.1 常用技巧
模型初始化
简单的考虑,把所有权值在[-1,1]区间内按均值或高斯分布进行初始化。
Xavier初始化:为了使得网络中信息更好的流动,每一层输出的方差应该尽量相等。因此需要实现下面的均匀分布: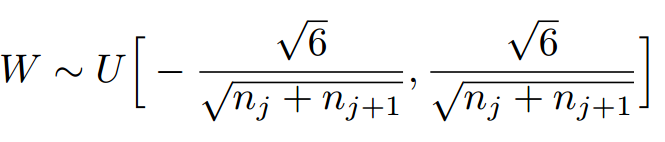
训练数据与测试数据
数据包括:
- 训练数据
- 验证数据
- 测试数据
通常三者比例为70%,15%,15%或60%,20%,20%。当数据很多时,训练和验证数据可适当减少
训练数据与测试数据:𝐾折交叉验证
原始训练数据被分成 K 个不重叠的子集。 然后执行 K 次模型训练和验证,每次在 K−1 个子集上进行训练, 并在剩余的一个子集(在该轮中没有用于训练的子集)上进行验证。 最后,通过对 𝐾 次实验的结果取平均来估计训练和验证误差。
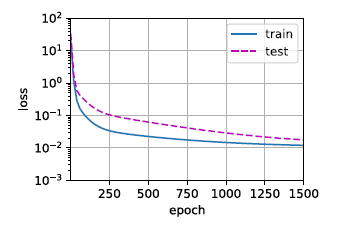
欠拟合与过拟合
- 欠拟合:误差一直比较大
- 过拟合:在训练数据集上误差小而在测试数据集上误差大
权重衰减 (𝐿2正则化)
为防止过拟合和权值震荡,加入新的指标函数项: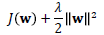
第二项约束了权值不能过大。在梯度下降时,导数容易计算: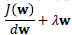
Dropout(暂退)
在整个训练过程的每一次迭代中,标准暂退法包括在计算下一层之前将当前层中的一些节点置零。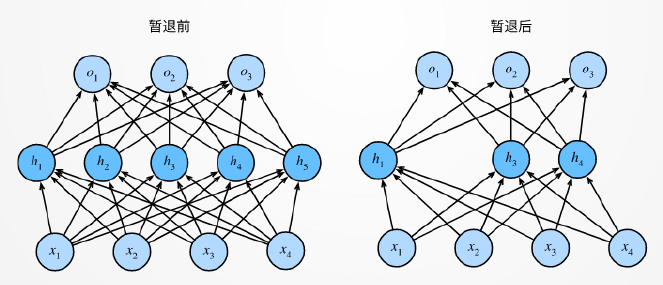
4.2 动量法
SGD问题:病态曲率
图为损失函数轮廓。在进入以蓝色标记的山沟状区域之前随机开始。颜色实际上表示损失函数在特定点处的值有多大,红色表示最大值,蓝色表示最小值。我们想要达到最小值点,为此但需要我们穿过山沟。这个区域就是所谓的病态曲率。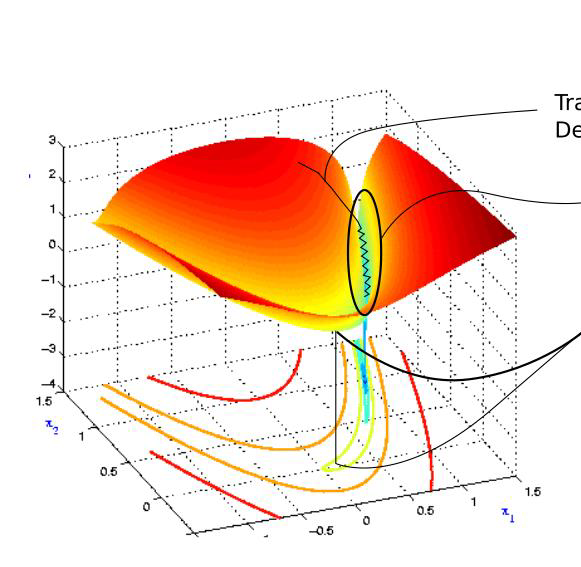
梯度下降沿着山沟的山脊反弹,向极小的方向移动较慢。这是因为脊的表面在W1方向上弯曲得更陡峭。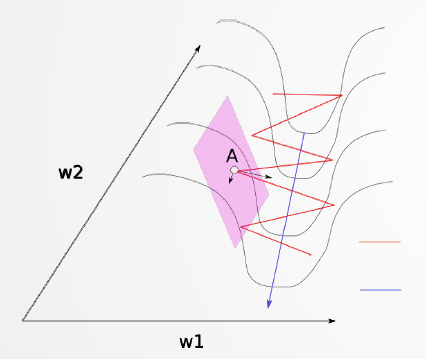
如果把原始的 SGD 想象成一个纸团在重力作用向下滚动,由于质量小受到山壁弹力的干扰大,导致来回震荡;或者在鞍点处因为质量小速度很快减为 0,导致无法离开这块平地。
动量方法相当于把纸团换成了铁球;不容易受到外力的干扰,轨迹更加稳定;同时因为在鞍点处因为惯性的作用,更有可能离开平地。
动量法更新公式
4.3 自适应梯度算法
Adaptive Gradient:自适应梯度
参数自适应变化:具有较大偏导的参数相应有一个较大的学习率,而具有小偏导的参数则对应一个较小的学习率
具体来说,每个参数的学习率会缩放各参数反比于其历史梯度平方值总和的平方根
AdaGrad问题
学习率是单调递减的,训练后期学习率过小会导致训练困难,甚至提前结束
需要设置一个全局的初始学习率
RMSProp: Root Mean Square Prop
RMSProp 解决 AdaGrad 方法中学习率过度衰减的问题
RMSProp 使用指数衰减平均以丢弃遥远的历史,使其能够快速收敛;此外,RMSProp 还加入了超参数 𝜌 控制衰减速率。
具体来说(对比 AdaGrad 的算法描述),即修改 𝑟 为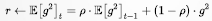
记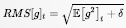 ,则
,则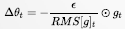
RMSProp算法
Adam算法
Adam 在 RMSProp 方法的基础上更进一步:
- 除了加入历史梯度平方的指数衰减平均(𝑟)外,
- 还保留了历史梯度的指数衰减平均(𝑠),相当于动量。
Adam 行为就像一个带有摩擦力的小球,在误差面上倾向于平坦的极小值。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)