Milvus密集向量
密集向量是一种在机器学习和数据分析中广泛应用的数值数据表示方法,由包含实数的数组组成,其中大部分或所有元素都不为零。与稀疏向量相比,密集向量在同一维度上包含更多信息,能有效捕捉复杂的模式和关系,使数据在高维空间中更容易分析和处理。密集向量通常有固定的维数,从几十到几百甚至上千不等,具体取决于应用需求。它们主要用于需要理解数据语义的场景,如语义搜索和推荐系统。在语义搜索中,密集向量有助于捕捉查询和文
密集向量是广泛应用于机器学习和数据分析的数值数据表示法。它们由包含实数的数组组成,其中大部分或所有元素都不为零。与稀疏向量相比,密集向量在同一维度上包含更多信息,因为每个维度都持有有意义的值。这种表示方法能有效捕捉复杂的模式和关系,使数据在高维空间中更容易分析和处理。密集向量通常有固定的维数,从几十到几百甚至上千不等,具体取决于具体的应用和要求。
密集向量主要用于需要理解数据语义的场景,如语义搜索和推荐系统。在语义搜索中,密集向量有助于捕捉查询和文档之间的潜在联系,提高搜索结果的相关性。在推荐系统中,密集矢量有助于识别用户和项目之间的相似性,从而提供更加个性化的建议。
相关概述
密集向量通常表示为具有固定长度的浮点数数组,如[0.2, 0.7, 0.1, 0.8, 0.3, ..., 0.5] 。这些向量的维度通常从数百到数千不等,如 128、256、768 或 1024。每个维度都能捕捉对象的特定语义特征,通过相似性计算使其适用于各种场景。
密集向量
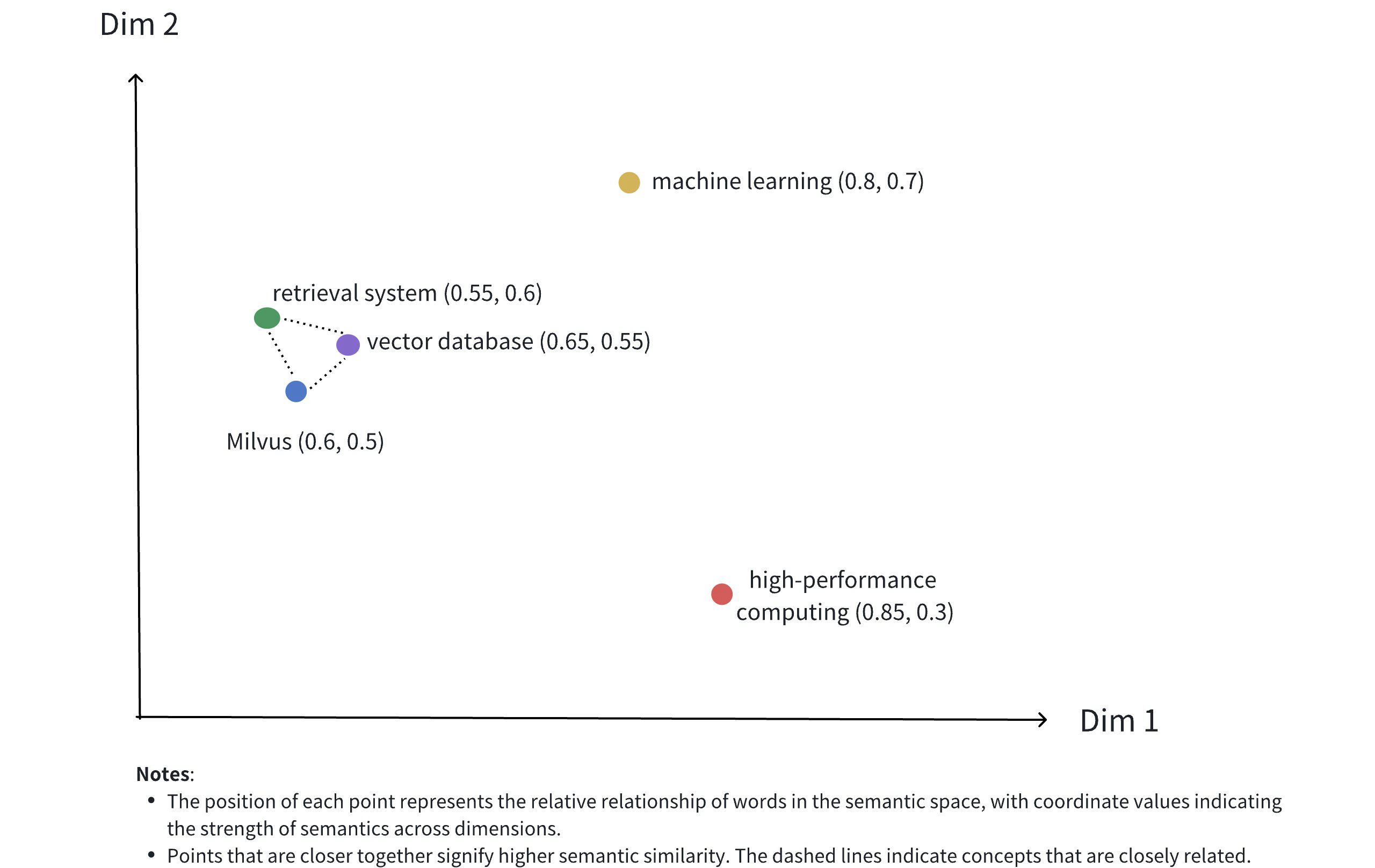
上图展示了密集向量在二维空间中的表现形式。虽然实际应用中的密集向量通常具有更高的维度,但这种二维插图有效地传达了几个关键概念:
-
多维表示:每个点代表一个概念对象(如Milvus、向量数据库、检索系统等),其位置由其维度值决定。
-
语义关系:点之间的距离反映了概念之间的语义相似性。距离较近的点表示语义关联度较高的概念。
-
聚类效应:相关概念(如Milvus、向量数据库和检索系统)在空间中的位置相互靠近,形成语义聚类。
下面是一个代表文本"Milvus is an efficient vector database" 的真实稠密向量示例:
[
-0.013052909,
0.020387933,
-0.007869,
-0.11111383,
-0.030188112,
-0.0053388323,
0.0010654867,
0.072027855,
// ... more dimensions
]稠密向量可使用各种嵌入模型生成,如用于图像的 CNN 模型(如ResNet、VGG)和用于文本的语言模型(如BERT、Word2Vec)。这些模型将原始数据转化为高维空间中的点,捕捉数据的语义特征。此外,Milvus 还提供便捷的方法,帮助用户生成和处理密集向量,详见 Embeddings。
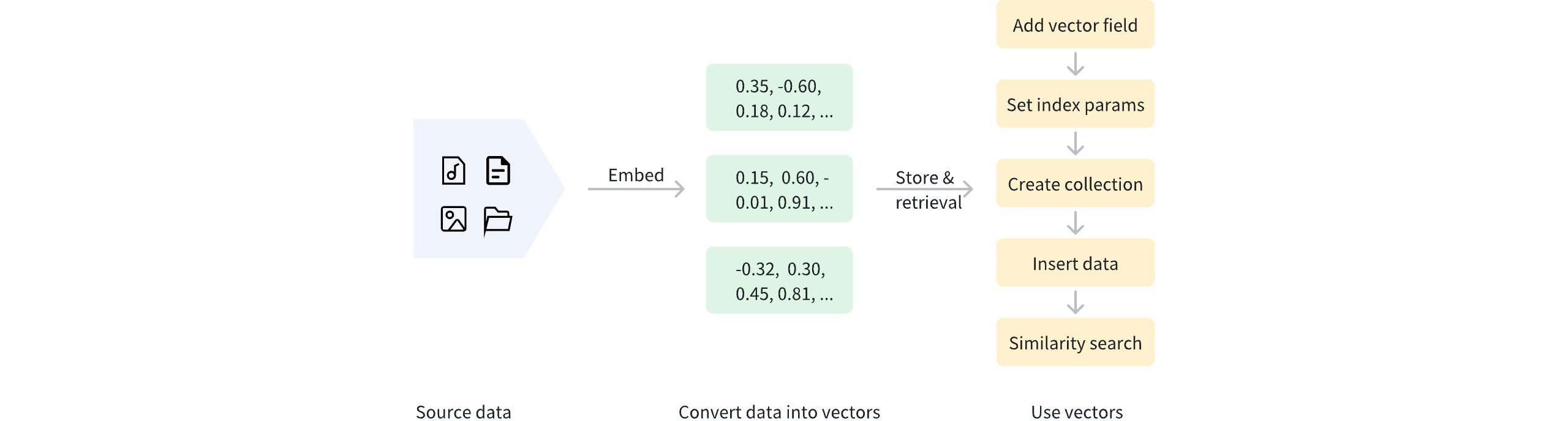
一旦数据被向量化,就可以存储在 Milvus 中进行管理和向量检索。下图显示了基本流程。
使用密集向量
除了密集向量,Milvus 还支持稀疏向量和二进制向量。稀疏向量适用于基于特定术语的精确匹配,如关键词搜索和术语匹配,而二进制向量常用于高效处理二进制化数据,如图像模式匹配和某些散列应用。更多信息,请参阅二进制向量和稀疏向量。
使用密集向量
添加向量场
要在 Milvus 中使用密集向量,首先要在创建 Collections 时定义一个用于存储密集向量的向量场。这一过程包括
-
将
datatype设置为支持的密集向量数据类型。有关支持的密集向量数据类型,请参阅数据类型。 -
使用
dim参数指定密集向量的维数。
在下面的示例中,我们添加了一个名为dense_vector 的向量字段来存储密集向量。字段的数据类型为FLOAT_VECTOR ,维数为4 。
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
import io.milvus.v2.common.DataType;
import io.milvus.v2.service.collection.request.AddFieldReq;
import io.milvus.v2.service.collection.request.CreateCollectionReq;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("http://localhost:19530")
.build());
CreateCollectionReq.CollectionSchema schema = client.createSchema();
schema.setEnableDynamicField(true);
schema.addField(AddFieldReq.builder()
.fieldName("pk")
.dataType(DataType.VarChar)
.isPrimaryKey(true)
.autoID(true)
.maxLength(100)
.build());
schema.addField(AddFieldReq.builder()
.fieldName("dense_vector")
.dataType(DataType.FloatVector)
.dimension(4)
.build());
支持的密集向量字段数据类型:
|
数据类型 |
描述 |
|---|---|
|
|
存储 32 位浮点数,常用于表示科学计算和机器学习中的实数。非常适合需要高精度的场景,例如区分相似向量。 |
|
|
存储 16 位半精度浮点数,用于深度学习和 GPU 计算。在精度要求不高的情况下,如推荐系统的低精度召回阶段,它可以节省存储空间。 |
|
|
存储 16 位脑浮点(bfloat16)数,提供与 Float32 相同的指数范围,但精度有所降低。适用于需要快速处理大量向量的场景,如大规模图像检索。 |
为向量场设置索引参数
为了加速语义搜索,必须为向量场创建索引。索引可以大大提高大规模向量数据的检索效率。
import io.milvus.v2.common.IndexParam;
import java.util.*;
List<IndexParam> indexes = new ArrayList<>();
indexes.add(IndexParam.builder()
.fieldName("dense_vector")
.indexType(IndexParam.IndexType.AUTOINDEX)
.metricType(IndexParam.MetricType.IP)
.build());
在上面的示例中,使用AUTOINDEX 索引类型为dense_vector 字段创建了名为dense_vector_index 的索引。metric_type 设置为IP ,表示将使用内积作为距离度量。
Milvus 提供多种索引类型,以获得更好的向量搜索体验。AUTOINDEX 是一种特殊的索引类型,旨在平滑向量搜索的学习曲线。有很多索引类型可供您选择。详情请参阅 xxx。
Milvus 支持其他度量类型。更多信息,请参阅公制类型。
创建 Collections
完成密集向量和索引参数设置后,就可以创建包含密集向量的 Collections。下面的示例使用create_collection 方法创建了一个名为my_collection 的集合。
import io.milvus.v2.client.ConnectConfig;
import io.milvus.v2.client.MilvusClientV2;
MilvusClientV2 client = new MilvusClientV2(ConnectConfig.builder()
.uri("http://localhost:19530")
.build());
CreateCollectionReq requestCreate = CreateCollectionReq.builder()
.collectionName("my_collection")
.collectionSchema(schema)
.indexParams(indexes)
.build();
client.createCollection(requestCreate);
插入数据
创建集合后,使用insert 方法添加包含密集向量的数据。确保插入的密集向量的维度与添加密集向量字段时定义的dim 值相匹配。
import com.google.gson.Gson;
import com.google.gson.JsonObject;
import io.milvus.v2.service.vector.request.InsertReq;
import io.milvus.v2.service.vector.response.InsertResp;
List<JsonObject> rows = new ArrayList<>();
Gson gson = new Gson();
rows.add(gson.fromJson("{\"dense_vector\": [0.1, 0.2, 0.3, 0.4]}", JsonObject.class));
rows.add(gson.fromJson("{\"dense_vector\": [0.2, 0.3, 0.4, 0.5]}", JsonObject.class));
InsertResp insertR = client.insert(InsertReq.builder()
.collectionName("my_collection")
.data(rows)
.build());
执行相似性搜索
基于密集向量的语义搜索是 Milvus 的核心功能之一,可以根据向量之间的距离快速找到与查询向量最相似的数据。要执行相似性搜索,请准备好查询向量和搜索参数,然后调用search 方法。
import io.milvus.v2.service.vector.request.data.FloatVec;
Map<String,Object> searchParams = new HashMap<>();
searchParams.put("nprobe",10);
FloatVec queryVector = new FloatVec(new float[]{0.1f, 0.3f, 0.3f, 0.4f});
SearchResp searchR = client.search(SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(queryVector))
.annsField("dense_vector")
.searchParams(searchParams)
.topK(5)
.outputFields(Collections.singletonList("pk"))
.build());
System.out.println(searchR.getSearchResults());
// Output
//
// [[SearchResp.SearchResult(entity={pk=453444327741536779}, score=0.65, id=453444327741536779), SearchResp.SearchResult(entity={pk=453444327741536778}, score=0.65, id=453444327741536778)]]

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 24
24 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)