自动驾驶---理想汽车之李想的AI Talk
在AITalk第二季的访谈中,理想汽车CEO李想与腾讯新闻科技主笔张小珺深入探讨了人工智能的最新发展,特别是理想汽车在自动驾驶技术上的进展。李想介绍了理想汽车从规则算法到端到端+VLM(视觉语言模型),再到VLA(视觉语言行动模型)的进化过程,将其比作从昆虫到哺乳动物再到人类的智能进化。
1 前言
说实话,笔者刚接触新能源汽车的时候,对理想汽车甚至李想都有点误解,经过长时间的跟踪了解,笔者对于理想汽车这家公司有了很大的改观。对我比较熟悉的粉丝朋友应该知道,新势力几家公司中,博客写的最多的就是理想汽车,当你想深入了解一家公司或者一个人的时候,看他做了什么,而不是听别人说了什么。
理想汽车CEO兼董事长李想、腾讯新闻科技主笔张小珺再次深度对话,聊聊对AI的最新观察,以及对未来Agent的思考,产品的形式等等。有些朋友对此非常好奇,李想对大模型的理解甚至比有些研发的同学都深,原因在于李想每周都会参加公司内部的AI大模型会议;同时也可以看到理想汽车在CVPR上发表了不少文章。

2 AI访谈
本次采访的内容非常多,关于生活,AI,家庭,创业等等,笔者看下来整篇的采访内容还是非常收益的,有兴趣的读者朋友可自行浏览原文。笔者在本篇博客做了筛选,更偏向技术。李想面对面丨理想AI Talk第二季访谈实录理想VLA司机大模型,从动物进化到人类![]() https://mp.weixin.qq.com/s/T7s6sC-74gFx0lt1vubfFg 笔者本篇博客主要内容仍然是关于VLA技术相关的,主要与理想汽车辅助驾驶功能相关,其它部分笔者省略。
https://mp.weixin.qq.com/s/T7s6sC-74gFx0lt1vubfFg 笔者本篇博客主要内容仍然是关于VLA技术相关的,主要与理想汽车辅助驾驶功能相关,其它部分笔者省略。
理想汽车这么多年从规则算法做到了端到端+VLM,然后今天真正的迈入到了VLA的阶段,你觉得比较像什么?
李想的回答是:比较像黎明前的黑暗吧。我认为黎明马上就要来了,但是会先经历一个黑暗的过程,之所以有黑暗是因为要迎来黎明。
2.1 生产力
无论我们是在端到端和 VLM(视觉语言模型)上,还是今天做 VLA(视觉语言行动模型),我们的研究团队其实表现得非常好。包括你可以看国外的像李飞飞,其实她在引用辅助驾驶的时候,也经常会引用我们关于辅助驾驶方面的研究论文。这个其实挺重要,研究跑通了以后研发效率会变得非常的高。
应该以这个为基础加速 VLA,加速端到端的多模态进展,研究团队也都在研究我们如何在芯片上也跑到同样的训练和推理的效率,大家都在同步地进行工作。
我发现大家并不纠结,因为理想这个企业的基因,还是要为用户推出最好的产品和服务。拥抱DeepSeek的这个过程比我们想象的要快,所以这是今天其实我们VLA推出的速度也会比原来的预期的要快。
2.2 关于VLA
(1)VLA发展历程
VLA(视觉语言行动模型)机器人领域也在讲,对于理想汽车而言, VLA是一个司机大模型,像人类的司机一样去工作的一个模型。到达VLA(司机大模型)它不是一个突变的过程,其实它是一个进化的过程,经历了三个阶段。
第一个阶段:我们从2021年开始,通过机器学习的感知,配合后边的规则算法,包括规划、控制、执行这些规则算法分段式的。
第一个阶段比较像什么?像昆虫动物的智能。它有既定的规则,还要依赖于高精地图,就比较像蚂蚁的行动和完成任务的一个方式。它能理解的世界非常之有限,效率比较低,也是个很麻烦的事情。它(规则算法)就这样一个规模的脑子,包括它的整个模型规模大概就只有几百万的一个参数,它就那么小的一个脑子,你让它去完成复杂的事情,几乎不可能的。所以你就不停地限定、限定,几乎把它做成了一个有轨交通的方式。这跟蚂蚁非常相似。
第二个阶段:我们从2023年开始搞研究,2024年推出的端到端。端到端比较像什么呢?端到端比较像哺乳动物的智能,比如马戏团里的一些动物像人类学习怎么骑自行车。它学了人类的这些行为,人类怎么去做出各种的行为的开车。但是它对物理世界并不理解,它只是看到了一个什么样的三维的图像,知道自身的速度,并给出了一个什么样的轨迹,所以它应付大部分的泛化是没有问题的,去面对它从来没有学到的、特别复杂的,其实就会遇到问题。所以这时候我们也会配合视觉语言模型VLM。但是我们能够用到的视觉语言模型这些开源的,用在交通上的能力都非常的有限,所以只能起到一些非常有限的辅助的一个作用。
到了VLA司机大模型,就是完全人类的运作方式了。它会像人类一样的用3D的vision和2D的组合,去看整个真实的物理世界,也包含它能够去看懂导航软件是怎么在运行的,而不是像VLM那样只能看到一张图片。另外一方面,它有自己的整个脑系统,不但要看到物理世界,还能够理解这个物理世界。它有它的language,然后它也有它的CoT(思维链),有推理的能力。
第三个阶段,它能够像人类一样,真正地去执行这样的行动。这个是VLA(视觉语言行动模型)在汽车辅助驾驶领域,我们把它称之为VLA的司机大模型。

(2)理想VLA架构
更多细节内容可参考《自动驾驶大模型---理想汽车下一代MindVLA大模型》。
端到端是 VLA(视觉语言行动模型)的基础。如果你把端到端想象成一个一个具身智能执行的环节,那它其实就是VLA的A(action行动)的部分。只是我要多语言的部分,还要多更强的3D vision和高清2D vision的部分。
我自己认为VLA(司机大模型)能够解决到全自动驾驶,但是VLA是否是一个效率最高的方式?是否有效率更高的架构出现?我打个问号,我认为大概率还是会有的。因为VLA还是基于Transformer这样子的,那Transformer是不是一个效率最高的一个架构?这个其实后边不知道。
我觉得它是能力最强的架构。今天辅助驾驶的这些规则算法、端到端跟人类差距还是太大了。VLA它是最接近人类的,甚至有机会在开车这件事情上超越人类的一种方式。那它是不是效率最高的方式?其实是打个问号。
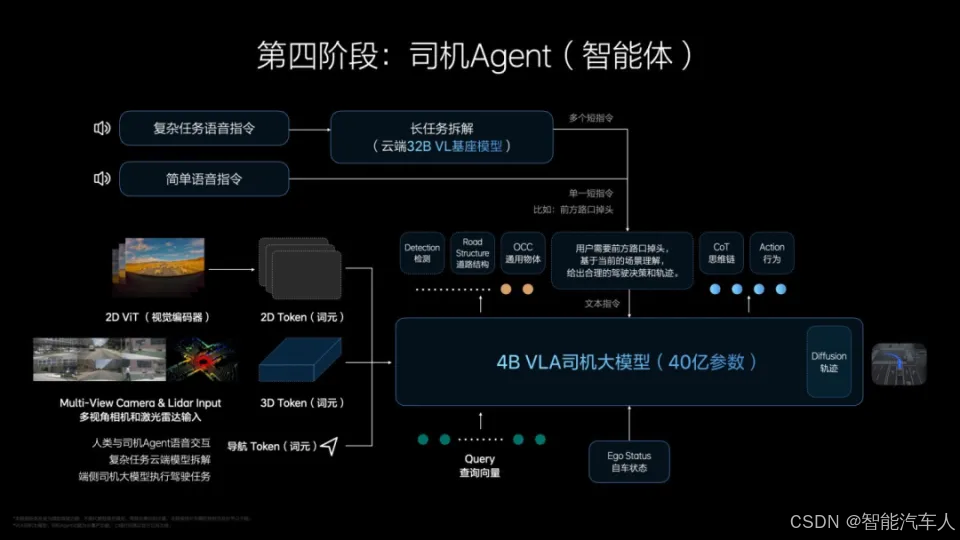
(3)基座模型
因为我们的业务并不是说只是做好语言模型就够了,我们车上要有对话、有多模态,这个仍然其实需要我们自己去训练一个适用我们需求的基座模型,包括我要去做VLA。因为VLA里边哪怕V(vision视觉)和L(language语言)都和正常的是不一样的:我需要3D的vision,还有高清2D的vision,然后token(词元)要用预训练,必须得涉及到更专业的车领域的语义语料,交通领域的语义语料,家庭用户的语义语料,然后来做训练。
大家在做VLA训练的时候,很多时候在做基座时说我要把VL(视觉和语言)也要连在一起,然后把VL(视觉和语言)的组合语料放进去,那这些无论是OpenAI还是DeepSeek,它都没有这样的数据,也没有这样的场景和需求,也不去解决这样的问题,那只能我自己来做了。只是好处是说VLA里边的这个language,我可以站在巨人的肩膀上,但是它只是我其中的一部分。
(4)VLA大模型训练
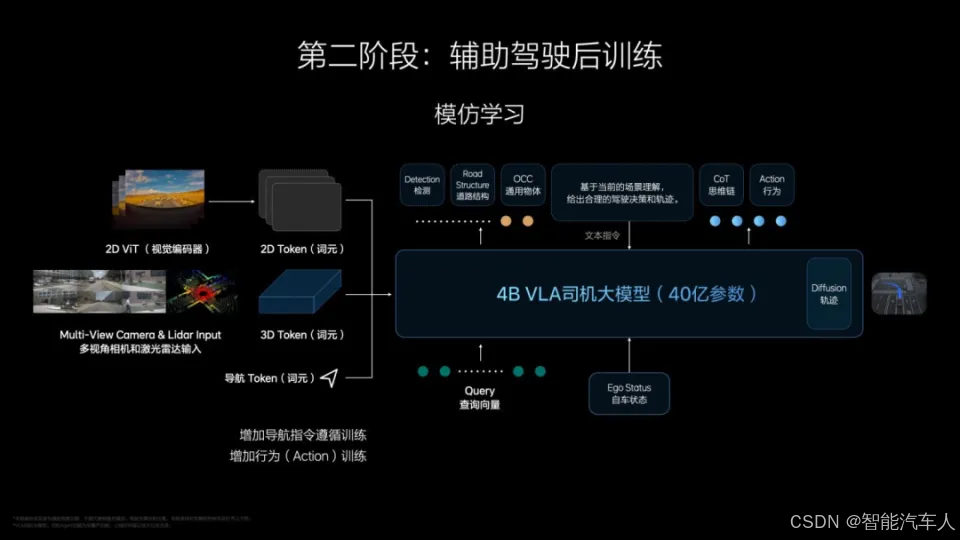
第一个其实是训练的环节。训练环节第一个部分是什么呢?要训出来一个VL(视觉和语言)的基座,就vision和language的基座。我们目前在训的,当前的这个版本,是一个32B的,就是320亿云端的一个基座模型,所以先训这个。这里边的话,跟过去的时候这些语言模型的差异在于什么呢?第一在于我要放入更多vision的语料,放入vision的token。vision里面包含两个部分,一部分是3D上的vision,物理世界3D的vision要放进去,第二个是高清的、2D的vision。因为今天的话,大家看到各种多模态的开源VLM里边,它整2D vision的清晰度太低,所以看的距离不够。那我们放进去的基本上图像分辨率提升了10倍。我觉得这是非常之重要的。这是一个部分,是vision的token和语料。
第二个是要放入language,跟交通、驾驶相关的足够多的这方面的语料。这是language的部分。
第三个还有一个很重要的,是大家可能容易忽略的,就我们必须放入很多VL(视觉和语言)联合的语料,就是三维图像和对世界的理解语义要同时产生的。比如我举一个例子,我要把导航的地图和车辆对导航地图的理解一起放进去。

训练步骤:
比如我要放入一个,看到导航以后人类做了一个什么判断,然后这个判断我们的车辆是怎么记录的。把这个语料放进去。其实整个VL(视觉和语言)基座模型训练的时候,包含了三个部分,数据是vision的数据,language的数据和VL联合的数据。然后它形成一个VL的一个基座。同时我要把这个基座干什么呢?我要蒸馏下来,然后变成一个3.2B端侧的蒸馏模型。因为我要保证它运行速度足够得快,然后无论是两个Orin-X还是Thor-U上能够流畅地运行。蒸馏下来是一个3.2B,8个专家组成的MoE(混合专家模型)模型。如果直接跑3.2B一个完整模型的话,双Orin-X和Thor-U的帧率是达不到的,token的整个输出率是达不到的,这是第一个步骤,这是预训练的环节。
第二个步骤是什么?第二个步骤是做后训练。后训练是什么呢?后训练其实是我把它变成VLA司机大模型。我要把action放进来。action的部分后训练什么呢?其实仍然是一种模仿学习。特别像你去驾校学开车,就相当于我训练VLA,把它组合成一个VLA的端到端的一个方式,这是第二个部分。这个时候模型规模就会从3.2B扩大到接近4B这么一个规模。
同时,它一方面是个VLA,能够直接从视觉、到理解、到最后的输出。但是我们的CoT(思维链)就会很短,我不会做超长的CoT,我的CoT链条一般两步到三步,我不会再做更多的,否则延时太长,没有办法满足交通或者机器人的安全。另外当我action做完以后,我还会做一个diffusion(扩散模型)的预测,就是下边会发生什么样的时长的一个场景。这个主要根据性能会做出来4到8秒的一个diffusion的轨迹和环境的预测。这是第二个部分,比较像人去驾校学开车这样的一个环节。
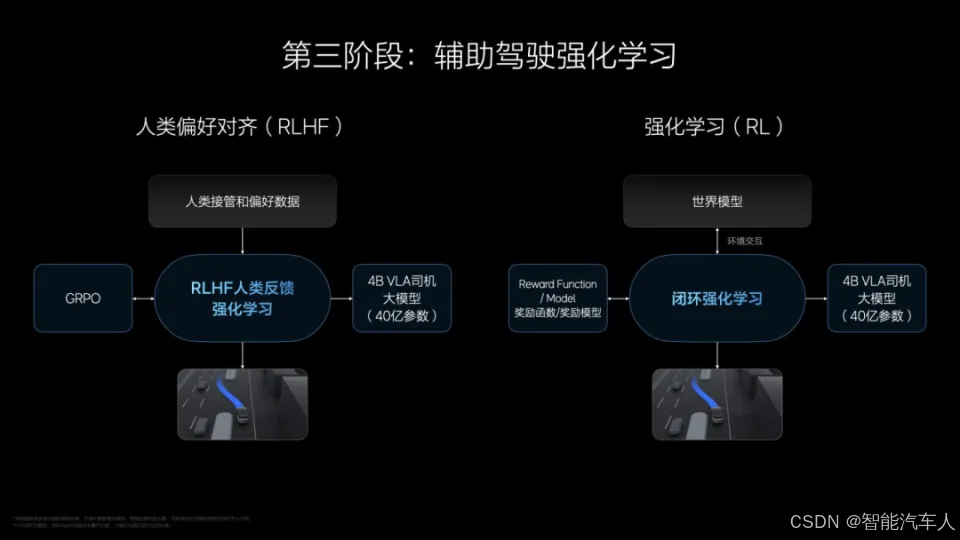
第三个部分是什么?是强化,是要做强化的训练,比较像人到社会上开车了。所以强化我们分成两个部分:
- 先做RLHF(人类反馈强化学习),带有人类反馈的,所以我们有很多人类数据。就是当它这样的话,人类就会接管,当它那样的话,人类不会接管。包括人类的一些习惯,所以拿这块来做一个带有人类反馈的强化训练。包括我们安全的对齐都是在这个强化的环节完成的,你除了要遵守交通规则以外,你要遵守比如中国的,大家的驾驶习惯。你的开车习惯能够融入社会,首先要开得跟整个社会环境上的大家一样好,不能给别人带来麻烦。
- 纯粹的RL(强化学习),是(拿RL模型放到)我们的世界模型来做训练。这块儿的目的什么呢?就是开得比人类更好。这块儿的话,我们中间不会给人类的反馈,只会给一个结果,就是从a点到b点要开过去。但是会有三类的训练要求,首先我们可以通过G值(加速度数值)来判断它的舒适性。其次是做碰撞的反馈,它碰撞了这个强化就没有完成。最后是交通规则的反馈,如果它违反交通规则就没有完成。所以是舒适、交通规则和碰撞事故,让它自己来做整个强化的训练。当这三个步骤完成了以后,VLA能够跑在车端的模型其实就产生了。
2.3 安全
司机Agent涉及到action进入了物理世界,怎么解决安全问题?
我们其实从去年年底成立了超级对齐的团队,比如说模型能力很强,但不遵守交通规则、经常去加塞等等,做出来一些让人类坐在车上感觉到不安全的行为。是否发生碰撞,是模型能力的问题;但是否产生这些问题,其实这个价值观是模型要去做的对齐。
这也是刚才我讲的,就是说我们要做强化训练的第一个环节,我们必须把人类的这些规则、习俗、驾驶习惯,对于很多东西的判断,变成整个的要训练的反馈。这个其实是我们必须要做的,所以我们有一个挺大规模的,100多人的超级对齐团队。
因为你能力越强、责任越大,这是责任。如果拿一个人举例子的话,模型相当于是这个人的专业能力,然后超级对齐,是这个人的职业性。
我们做到了1000万Clips(视频片段)以后开始做超级对齐,因为我发现这时候怎么去有效地运用模型的能力就很关键了,举个例子,它经常一拥堵就加塞,然后它的很多行为,虽然效率很高,但是人坐在车上不舒服,因为跟人类的一些处理方式不一样,它可能学到了一些不该学的行为。
2.4 Agent评价
我们只有让它变成一个真正的司机,它才是一个生产力工具,不只是一个辅助工具。今天L2、L2+其实是个辅助工具,辅助工具还需要人大量的参与。
如果想变成一个生产工具,我个人认为并不会出现通用的Agent,而是每个专业领域做专业的Agent。就像刚才讲的,要想开好车,它所有的vision的语料,language的语料,和action其实都是不一样的。
把司机大模型和Agent放在一起,这才是一个真正用户能够使用的产品。跟人的判断是一样,就我判断一个司机,第一是他开车水平好不好,其实是他模型能力强不强?第二他是否职业,很重要的一点就是我们的超级对齐工作,包括强化训练,是否做得足够的好?第三是否安全,他跟我之间的信任关系,我说上半句他就知道下半句,甚至我很多东西不说,他已经对我的记忆里边都可以独自去完成了。
我觉得以后所有的AI的,或者Agent的判断都应该是这样的,专业能力、职业能力、构建信任的能力。
2.5 特斯拉对比
从实测过来的话,特斯拉FSD大概在用12.5之前的模型,距离特斯拉真实能力还有巨大的差距。特斯拉13.0以后的能力还是非常强的。而且12.5之前应该是这个半规则算法的能力,所以我说不是特斯拉真实能力的体现,但是我们能看到特斯拉基本功是非常扎实的。
美国很多顶级的公司,像苹果、特斯拉,他们基本功特别扎实,这个是我们真正要去学的。尤其是在今天这种内卷环境下,包括外部的不确定的环境下,这时候更是每个企业扎扎实实练基本功的最好的时候。而且到了人工智能时代,基本功就更是不可能、不可跳跃的。
最重要的是学能力。我们在规模小的时候没有看懂苹果,当你做到千亿收入,你再去看这种万亿收入公司的能力的时候,你开始模模糊糊能看懂一些了。因为规模是一个可以确定衡量的变化,也会带来用户规模和用户需求的变化,技术和产品的变化,也会带来组织和能力的变化。
3 总结
在AITalk第二季的访谈中,理想汽车CEO李想与腾讯新闻科技主笔张小珺深入探讨了人工智能的最新发展,特别是理想汽车在自动驾驶技术上的进展。李想介绍了理想汽车从规则算法到端到端+VLM(视觉语言模型),再到VLA(视觉语言行动模型)的进化过程,将其比作从昆虫到哺乳动物再到人类的智能进化。
希望这篇博客所引用的内容,带给读者朋友们不只是VLA技术上的了解,更多的是宏观上对于未来/事情的一个看法或者思考。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)