无状态训练与有状态训练
无状态训练和有状态训练是机器学习中的两种不同训练方法。无状态训练假设每个训练样本独立,模型在处理每个样本时不依赖之前的信息,适用于处理独立同分布的数据,如图像分类。有状态训练则保留并利用之前样本的信息,适用于处理序列数据或具有上下文相关性的数据,如语言模型。无状态训练模型结构简单,训练速度快,易于并行化;而有状态训练模型结构复杂,训练速度慢,但能更好地捕捉数据中的长期依赖关系。两种方法的选择取决于
目录
无状态训练:在无状态训练中,模型在处理每个训练样本时,不依赖于之前处理过的样本的任何信息,每次输入都是独立的,模型仅根据当前输入数据来计算输出和更新参数。可以将其理解为模型在训练过程中没有 “记忆”,每个训练步骤都是孤立进行的,就像一个人在每次面对新问题时,都完全依靠当前所看到的信息来解决问题,而不参考过去的经验。例如,在训练一个图像分类模型时,每次输入一张图像,模型根据该图像的像素信息来判断它属于哪个类别,而不会考虑之前已经看过的图像对当前判断有什么影响。
有状态训练:有状态训练则相反,模型在训练过程中会保留和利用之前样本的相关信息,这些信息会作为模型当前状态的一部分,影响对后续样本的处理和参数更新。也就是说,模型具有 “记忆” 能力,它会根据以往的经验来更好地处理当前的任务。以语言模型为例,在有状态训练中,模型在生成一个单词时,不仅会考虑当前输入的上下文,还会记住之前已经生成过的单词序列,以便生成更符合语义和语法的文本。比如,当模型看到 “我正在” 这几个字时,它会根据之前学习到的语言模式和已经生成的部分内容,来预测接下来可能是 “吃饭”“跑步” 等合适的词汇,而不是随机地生成一些不相关的词语。
1.无状态训练原理
无状态训练基于独立同分布(IID)假设,即假设所有训练数据都是从同一个分布中独立抽取的。模型通过对大量独立样本的学习,逐渐捕捉到数据分布的统计规律,从而实现对未知数据的泛化能力。在训练过程中,每个样本都被视为一个独立的事件,模型根据当前样本的输入特征和目标输出,通过优化算法来调整模型的参数,以最小化损失函数。例如,在一个基于梯度下降的优化算法中,模型根据当前样本计算出的梯度来更新参数,而不考虑其他样本的梯度信息。这种方式使得训练过程相对简单,易于并行化,可以高效地处理大规模数据集。
以常见的神经网络模型为例,假设模型的输入为 x,输出为 y,模型的参数为 θ,损失函数为 L(θ,x,y)。在无状态训练中,对于每个训练样本 (xi,yi),通过反向传播算法计算梯度

2.有状态训练原理
有状态训练主要是为了更好地处理序列数据或具有上下文相关性的数据。模型通过引入一些机制来保存和更新状态信息,例如循环神经网络(RNN)中的隐藏状态或长短期记忆网络(LSTM)中的细胞状态。这些状态信息会在处理每个时间步的输入时进行更新,并作为下一个时间步的输入的一部分。这样,模型就能够利用之前时间步的信息来更好地理解当前输入的上下文,从而提高对序列数据的处理能力。以 LSTM 为例,它通过门控机制来控制信息的流动,决定哪些信息需要保留在细胞状态中,哪些信息需要更新或遗忘,从而有效地捕捉到长序列中的依赖关系。
以简单的RNN为例,设xt是时刻t的输入,ht是时刻t的隐藏状态,yt是时刻t的输出,Wxh、Whh 和Why是模型的参数,bh和by是偏置项。则RNN的前向传播过程可以表示为:
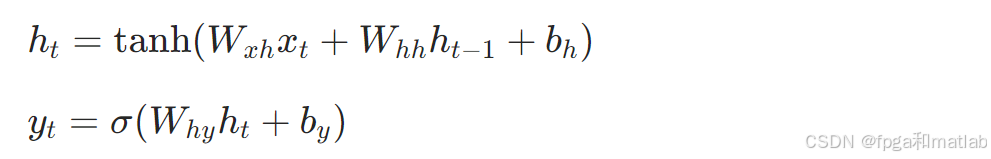
其中tanh是双曲正切激活函数,σ是Sigmoid激活函数。在训练过程中,通过计算损失函数L(yt,y^t)(y^t 是真实标签)关于参数的梯度,并利用反向传播算法来更新参数。与无状态训练不同的是,这里的隐藏状态ht依赖于上一时刻的隐藏状态ht−1,体现了模型的状态信息传递。
3.无状态训练与有状态训练区别
无状态训练和有状态训练之间的区别可以通过如下图来表示:
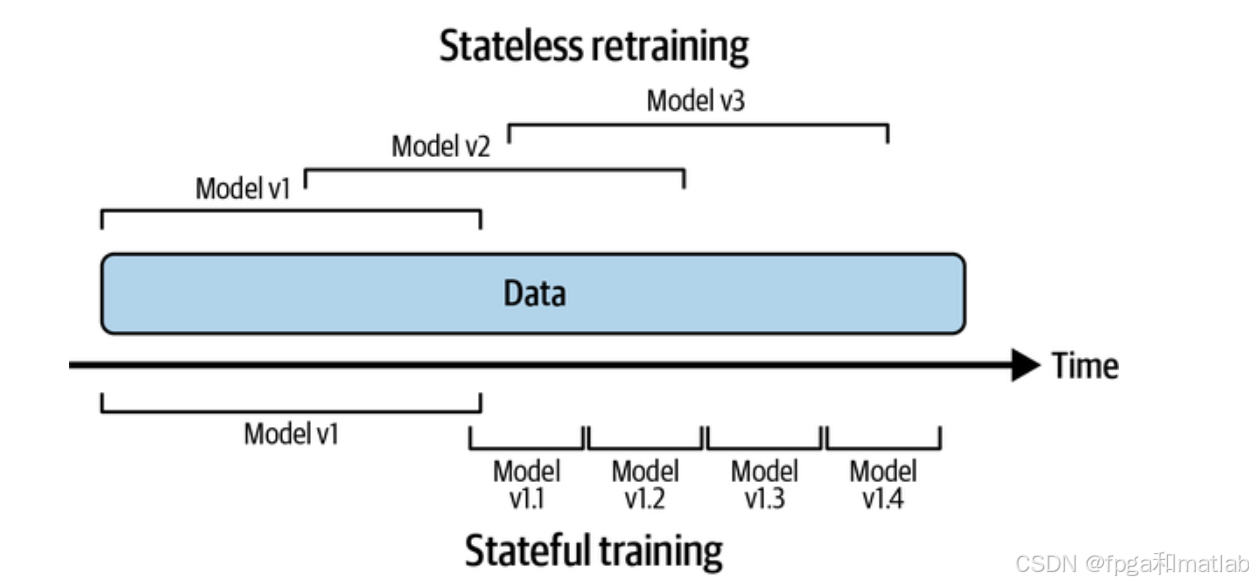
无状态训练中,每个数据样本被独立处理,模型不考虑数据之间的顺序或上下文关系。而有状态训练则注重数据的顺序和上下文信息,模型会根据之前处理过的数据来调整当前的状态,以更好地处理后续数据。例如,在处理文本数据时,无状态训练可能将每个单词视为独立的个体,而有状态训练会将单词序列作为一个整体来考虑,利用单词之间的顺序和语义关系来进行处理。
无状态训练的模型结构通常相对简单,例如前馈神经网络,它由输入层、隐藏层和输出层组成,信息从输入层向前传播到输出层,不涉及反馈或状态信息的传递。而有状态训练的模型结构通常较为复杂,需要引入一些特殊的机制来处理状态信息,如 RNN、LSTM、GRU 等。这些模型结构能够更好地捕捉数据中的长期依赖关系,但也增加了模型的复杂度和训练难度。
一般来说,无状态训练的训练和推理速度相对较快,因为每个样本的处理是独立的,可以并行计算,能够充分利用现代硬件设备(如 GPU)的并行计算能力。而有状态训练由于需要处理状态信息,每个样本的处理依赖于之前的状态,因此难以并行化,训练和推理速度相对较慢。例如,在训练一个大规模的无状态图像分类模型时,可以同时处理多个图像样本,大大提高训练效率;而对于有状态的语言模型,由于需要依次处理每个单词,训练速度会相对较慢。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 18
18 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)