[线性回归]机器学习-part8
回归的目的是预测数值型的目标值y。最直接的办法是依据输入x写出一个目标值y的计算公式。假如你想预测小姐姐男友汽车的功率,可能会这么计算:写成中文就是:小姐姐男友汽车的功率 = 0.0015 * 小姐姐男友年薪 - 0.99 * 收听公共广播的时间这就是所谓的回归方程(regression equation),其中的0.0015和-0.99称为回归系数(regression weights),求这些
前面介绍了很多分类算法,分类的目标变量是标称型数据,回归是对连续型的数据做出预测。
标称型数据(Nominal Data)是统计学和数据分析中的一种数据类型,它用于分类或标记不同的类别或组别,数据点之间并没有数值意义上的距离或顺序。例如,颜色(红、蓝、绿)、性别(男、女)或产品类别(A、B、C)。
标称数据的特点:
-
无序性:标称数据的各个类别之间没有固有的顺序关系。例如,“性别”可以分为“男”和“女”,但“男”和“女”之间不存在大小、高低等顺序关系。
-
非数值性:标称数据不能进行数学运算,因为它们没有数值含义。你不能对“颜色”或“品牌”这样的标称数据进行加减乘除。
-
多样性:标称数据可以有很多不同的类别,具体取决于研究的主题或数据收集的目的。
-
比如西瓜的颜色,纹理,敲击声响这些数据就属于标称型数据,适用于西瓜分类
连续型数据(Continuous Data)表示在某个范围内可以取任意数值的测量,这些数据点之间有明确的数值关系和距离。例如,温度、高度、重量等
连续型数据的特点包括:
-
可测量性:连续型数据通常来源于物理测量,如长度、重量、温度、时间等,这些量是可以精确测量的。
-
无限可分性:连续型数据的取值范围理论上是无限可分的,可以无限精确地细分。例如,你可以测量一个物体的长度为2.5米,也可以更精确地测量为2.53米,甚至2.5376米,等等。
-
数值运算:连续型数据可以进行数学运算,如加、减、乘、除以及求平均值、中位数、标准差等统计量。
在数据分析中,连续型数据的处理和分析方式非常丰富,常见的有:
-
描述性统计:计算均值、中位数、众数、标准差、四分位数等,以了解数据的中心趋势和分布情况。
-
概率分布:通过拟合概率分布模型,如正态分布、指数分布、伽玛分布等,来理解数据的随机特性。
-
图形表示:使用直方图、密度图、箱线图、散点图等来可视化数据的分布和潜在的模式。
-
回归分析:建立连续型变量之间的数学关系,预测一个或多个自变量如何影响因变量。
-
比如西瓜的甜度,大小,价格这些数据就属于连续型数据,可以用于做回归
1.什么是回归?
回归的目的是预测数值型的目标值y。最直接的办法是依据输入x写出一个目标值y的计算公式。假如你想预测小姐姐男友汽车的功率,可能会这么计算:
HorsePower = 0.0015 * annualSalary - 0.99 * hoursListeningToPublicRadio
写成中文就是:
小姐姐男友汽车的功率 = 0.0015 * 小姐姐男友年薪 - 0.99 * 收听公共广播的时间
这就是所谓的回归方程(regression equation),其中的0.0015和-0.99称为回归系数(regression weights),求这些回归系数的过程就是回归。一旦有了这些回归系数,再给定输入,做预测就非常容易了。具体的做法是用回归系数乘以输入值,再将结果全部加在一起,就得到了预测值。
2.线性回归
说到回归,一般都是指线性回归(linear regression)。线性回归意味着可以将输入项分别乘以一些常量,再将结果加起来得到输出。线性回归是机器学习中一种有监督学习的算法,回归问题主要关注的是因变量(需要预测的值)和一个或多个数值型的自变量(预测变量)之间的关系.
需要预测的值:即目标变量,target,y
影响目标变量的因素:X_1,X_2...X_n,可以是连续值也可以是离散值
因变量和自变量之间的关系:即模型,model,就是我们要求解的
比如1个包子是2元 3个包子是6元 预测5个包子多少钱
列出方程: y=wx+b
带入:
2=w*1+b
6=w*3+b
轻易求得 w=2 b=0
模型(x与y的关系): y=2*x+0
预测 x=5 时 target_y=2*5+0=10元
上面的方程式我们人类很多年以前就知道了,但是不叫人工智能算法,因为数学公式是理想状态,是100%对的,而人工智能是一种基于实际数据求解最优最接近实际的方程式,这个方程式带入实际数据计算后的结果是有误差的.
人工智能中的线性回归:数据集中,往往找不到一个完美的方程式来100%满足所有的y目标
我们就需要找出一个最接近真理的方程式
比如:
有这样一种植物,在不同的温度下生长的高度是不同的,对不同温度环境下,几颗植物的环境温度(横坐标),植物生长高度(纵坐标)的关系进行了采集,并且将它们绘制在一个二维坐标中,其分布如下图所示:
坐标分别为[4.2, 3.8],[4.2, 2.7],[2.7, 2.4],[0.8, 1.0],[3.7, 2.8],[1.7, 0.9],[3.2, 2.9]。
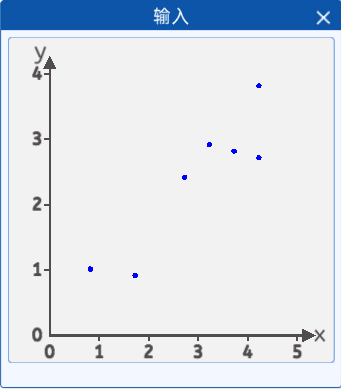
我们发现这些点好像分布在一条直线的附近,那么我们能不能找到这样一条直线,去“拟合”这些点,这样的话我们就可以通过获取环境的温度大概判断植物在某个温度下的生长高度了。
于是我们的最终目的就是通过这些散点来拟合一条直线,使该直线能尽可能准确的描述环境温度与植物高度的关系。
3.损失函数
数据: [[4.2, 3.8],[4.2, 2.7],[2.7, 2.4],[0.8, 1.0],[3.7, 2.8],[1.7, 0.9],[3.2, 2.9]]
我们假设 这个最优的方程是:
y=wx+b
这样的直线随着w和b的取值不同 可以画出无数条
在这无数条中,哪一条是比较好的呢?
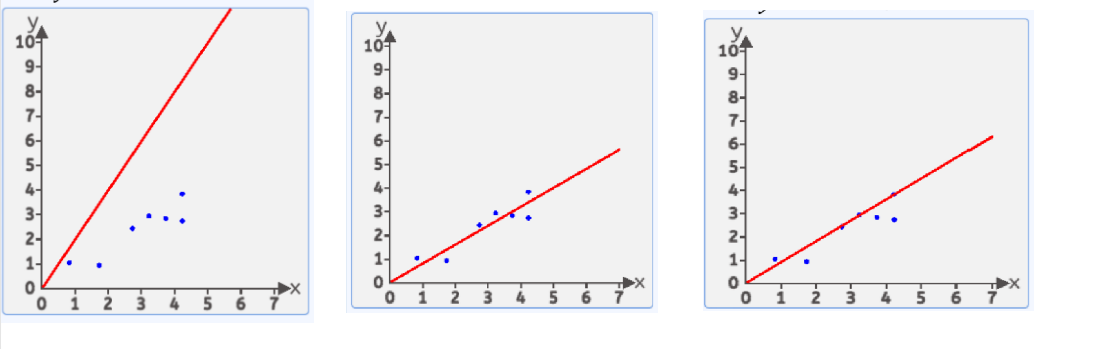
我们有很多方式认为某条直线是最优的,其中一种方式:均方差
就是每个点到线的竖直方向的距离平方 求和 在平均 最小时 这条直接就是最优直线
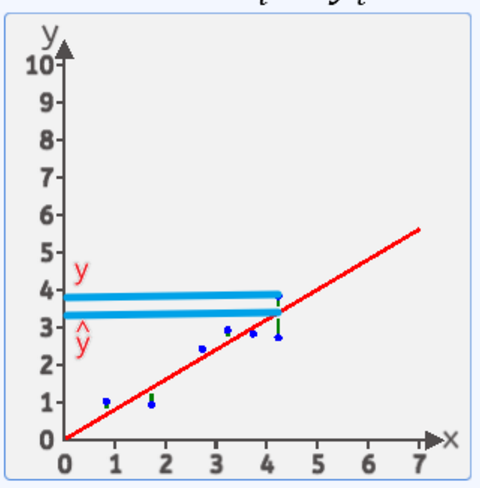
假设: y=wx+b
把x_1,x_2,x_3...带入进去 然后得出:
y_1^,=wx_1+b
y_2^,=wx_2+b
y_3^,=wx_3+b
...
然后计算{y_1-y_1^,} 表示第一个点的真实值和计算值的差值 ,然后把第二个点,第三个点...最后一个点的差值全部算出来
有的点在上面有点在下面,如果直接相加有负数和正数会抵消,体现不出来总误差,平方后就不会有这个问题了
所以最后:
总误差(也就是传说中的损失):
![]()
平均误差(总误差会受到样本点的个数的影响,样本点越多,该值就越大,所以我们可以对其平均化,求得平均值,这样就能解决样本点个数不同带来的影响)
这样就得到了传说中的损失函数:

怎么样让这个损失函数的值最小呢?
我们先假设b=0 (等后面多元方程求解这个b就解决了)

然后就简单了 算w在什么情况下损失函数的值最小(初中的抛物线求顶点的横坐标,高中求导数为0时)
求得w=0.795时损失函数取得最小值
那我们最终那个真理函数(最优解)就得到了
y=0.795x+0
在这个求解的过程中,我们是假设了b=0的 学了多元方程求解后 这个b也是可以求解出来的,因为一元方程是一种特殊的多元方程
总结:
1.实际数据中 x和y组成的点 不一定是全部落在一条直线上
2.我们假设有这么一条直线 y=wx+b 是最符合描述这些点的
3.最符合的条件就是这个方程带入所有x计算出的所有y与真实的y值做 均方差计算
4.找到均方差最小的那个w
5.这样就求出了最优解的函数(前提条件是假设b=0)
4.多参数回归
上面案例中,实际情况下,影响这种植物高度的不仅仅有温度,还有海拔,湿度,光照等等因素:
实际情况下,往往影响结果y的因素不止1个,这时x就从一个变成了n个,x_1,x_2,x_3...x_n 上面的思路是对的,但是求解的公式就不再适用了
案例: 假设一个人健康程度怎么样,由很多因素组成
| 被爱 | 学习指数 | 抗压指数 | 运动指数 | 饮食情况 | 金钱 | 心态 | 压力 | 健康程度 |
|---|---|---|---|---|---|---|---|---|
| 0 | 14 | 8 | 0 | 5 | -2 | 9 | -3 | 339 |
| -4 | 10 | 6 | 4 | -14 | -2 | -14 | 8 | -114 |
| -1 | -6 | 5 | -12 | 3 | -3 | 2 | -2 | 30 |
| 5 | -2 | 3 | 10 | 5 | 11 | 4 | -8 | 126 |
| -15 | -15 | -8 | -15 | 7 | -4 | -12 | 2 | -395 |
| 11 | -10 | -2 | 4 | 3 | -9 | -6 | 7 | -87 |
| -14 | 0 | 4 | -3 | 5 | 10 | 13 | 7 | 422 |
| -3 | -7 | -2 | -8 | 0 | -6 | -5 | -9 | -309 |
| 11 | 14 | 8 | 10 | 5 | 10 | 8 | 1 | ? |
求如果karen的各项指标是:
被爱:11 学习指数:14 抗压指数:8 运动指数:10 饮食水平:5 金钱:10 心态:8 压力:1
那么karen的健康程度是多少?
直接能想到的就是八元一次方程求解:
14w_2+8w_3+5w_5+-2w_6+9w_7+-3w_8=399
-4w_1+10w_2+6w_3+4w_4+-14w_5+-2w_6+-14w_7+8w_8=-144
-1w_1+-6w_2+5w_3+-12w_4+3w_3+-3w_6+2w_7+-2w_8=30
5w_1+-2w_2+3w_3+10w_4+5w_5+11w_6+4w_7+-8w_8=126
-15w_1+-15w_2+-8w_3+-15w_4+7w_5+-4w_6+-12w_7+2w_8=126
11w_1+-10w_2+-2w_3+4w_4+3w_5+-9w_6+-6w_7+7w_8=-87
-14w_1+4w_3+-3w_4+5w_5+10w_6+13w_7+7w_8=422
-3w_1+-7w_2+-2w_3+-8w_4+-6w_6+-5w_7+-9w_8=-309
解出 权重 w(w_1,w_2...w_8) 然后带入即可求出karen的健康程度
权重即重要程度,某一项的权重越大说明它影响最终健康的程度越大
但是这有一个前提:这个八元一次方程组得有解才行
因此我们还是按照损失最小的思路来求权重 w(w_1,w_2...w_8)
多元线性回归:
y^,=w_1x_1+w_2x_2+....w_nx_n+b
b是截距,我们也可以使用w_0来表示只要是个常量就行
y^,=w_1x_1+w_2x_2+....w_nx_n+w_0
y^,=w_1x_1+w_2x_2+....w_nx_n+w_0*1
那么损失函数就是
loss=[(y_1-y_1^,)^2+(y_2-y_2^,)^2+....(y_n-y_n^,)^2]/n
如何求得对应的W{(w_1,w_2..w_0)} 使得loss最小呢?
数学家高斯给出了答案
5.最小二乘法MSE
| x1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | x0 | y |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 14 | 8 | 0 | 5 | -2 | 9 | -3 | 1 | 339 |
| -4 | 10 | 6 | 4 | -14 | -2 | -14 | 8 | 1 | -114 |
| -1 | -6 | 5 | -12 | 3 | -3 | 2 | -2 | 1 | 30 |
| 5 | -2 | 3 | 10 | 5 | 11 | 4 | -8 | 1 | 126 |
| -15 | -15 | -8 | -15 | 7 | -4 | -12 | 2 | 1 | -395 |
| 11 | -10 | -2 | 4 | 3 | -9 | -6 | 7 | 1 | -87 |
| -14 | 0 | 4 | -3 | 5 | 10 | 13 | 7 | 1 | 422 |
| -3 | -7 | -2 | -8 | 0 | -6 | -5 | -9 | 1 | -309 |
5.1前景知识: 矩阵相关公式

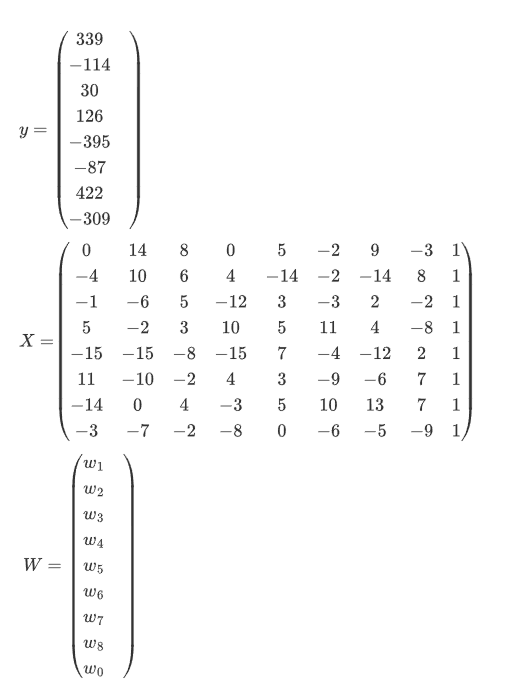
5.2最小二乘法

虽然这个案例中n=8,但是常常令n=2,因为是一个常数 求最小值时n随便取哪个正数都不会影响W结果,但是求导过程可以约掉前面的系数,会加速后面的计算
h(x_1)表示y^,_1= X第1行分别和W相乘
h(x_2)表示y^,_2= X第2行分别和W相乘
...
高斯把公式给了,但是何时loss最小呢?
1.二次方程导数为0时最小
![]() 求导:
求导:
2.先展开矩阵乘法
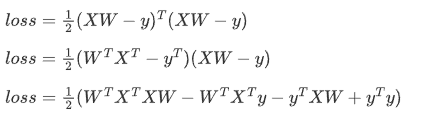
3.进行求导(注意X,y都是已知的,W是未知的)
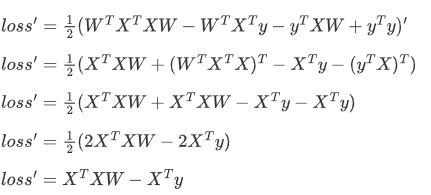
4.令导数loss'=0
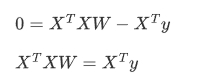
5.矩阵没有除法,使用逆矩阵转化
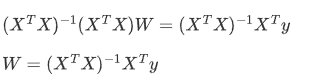
第二种方式链式求导(推荐,因为后期深度学习全是这种):
内部函数是 f(W) = XW - y ,外部函数是![]()
外部函数的导数: ![]()
内部函数的导数: ![]()
应用链式法则,我们得到最终的梯度: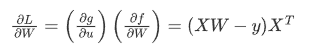
有了W,回到最初的问题:
求如果karen的各项指标是:
被爱:11 学习指数:14 抗压指数:8 运动指数:10 饮食水平:5 金钱:10 权利:8 压力:1
那么karen的健康程度是多少?
分别用W各项乘以新的X 就可以得到y健康程度
5.3 API
from sklearn.linear_model import LinearRegression
import numpy as np
data = np.array([[0,14,8,0,5,-2,9,-3,399],
[-4,10,6,4,-14,-2,-14,8,-144],
[-1,-6,5,-12,3,-3,2,-2,30],
[5,-2,3,10,5,11,4,-8,126],
[-15,-15,-8,-15,7,-4,-12,2,-395],
[11,-10,-2,4,3,-9,-6,7,-87],
[-14,0,4,-3,5,10,13,7,422],
[-3,-7,-2,-8,0,-6,-5,-9,-309]])
x,y = data[:,:-1],data[:,-1]
# fit_intercept=True表示是否需要计算截距项,默认为True 也叫偏执
model = LinearRegression(fit_intercept=True)
model.fit(x,y)
print("权重系数,w向量",model.coef_)
print("截距项,b",model.intercept_)
w = model.coef_
b = model.intercept_
x = [[0,14,8,0,5,-2,9,-3]]
x_new=[[11,14,8,10,5,10,8,1]]
# y_pred = np.sum(x*w) + b
y_pred = model.predict(x_new)
print("预测值",y_pred)
脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 18
18 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)