从文本到网络:使用生成式人工智能构建台湾中国研究知识图谱
台湾的中国研究(CS)已发展成为一个丰富且跨学科的研究领域,这一领域的形成受到台湾独特地缘政治位置和长期与中国大陆学术互动的影响。本研究响应了系统性回顾和重组数十年来台湾中国研究学术成果的日益增长的需求,提出了一种由人工智能辅助的方法,将非结构化的学术文本转化为结构化、可交互的知识表示。我们应用生成式人工智能(GAI)技术和大型语言模型(LLM),从1996年至2019年间发表的1367篇同行评议
邵轩磊*
台北医学大学健康与生物技术法学研究所
台湾
hlshao@tmu.edu.tw
摘要
台湾的中国研究(CS)已发展成为一个丰富且跨学科的研究领域,这一领域的形成受到台湾独特地缘政治位置和长期与中国大陆学术互动的影响。本研究响应了系统性回顾和重组数十年来台湾中国研究学术成果的日益增长的需求,提出了一种由人工智能辅助的方法,将非结构化的学术文本转化为结构化、可交互的知识表示。
我们应用生成式人工智能(GAI)技术和大型语言模型(LLM),从1996年至2019年间发表的1367篇同行评议的中国研究文章中提取并标准化实体-关系三元组。这些三元组通过一个基于D3.js的轻量级系统进行可视化,构成了该领域特定知识图谱和向量数据库的基础。这一基础设施允许用户探索语料库中的概念节点和语义关系,揭示以前未被发现的智识轨迹、主题集群和研究空白。
通过将文本内容分解为图结构化的知识单元,我们的系统实现了从线性文本消费到基于网络的知识导航的范式转变。在此过程中,它增强了对CS文献的学术访问,同时提供了一个可扩展的数据驱动的传统本体构建替代方案。这项工作不仅展示了生成式人工智能如何增强区域研究和数字人文科学,还强调了其在支持重新构想的区域知识系统学术基础设施方面的潜力。
关键词
知识图谱,信息获取,可视化,人工智能,大型语言模型
1 引言
台湾的“中国研究”已发展成为一个丰富且多学科的学术领域,这一领域的形成受到其独特的地缘政治背景和与大陆中国的知识互动的影响。这一领域深受台湾民主转型及其复杂身份政治的影响。从1990年代末到2019年,这是两岸关系的关键时期,台湾见证了学术产出的重大转变,反映了更广泛的社会和外交变化。
在台湾背景下,“中国研究”(CS)学术领域在过去几十年积累了丰富的研究成果。随着对政治科学研究中“原则发展”需求的关注不断增加 [3,5,8][3,5,8][3,5,8],越来越多的声音呼吁采用“对中国研究的文本研究”作为一种新的方法论途径。本研究响应了这一呼吁,通过应用数字方法——特别是文本挖掘(TM)和机器学习(ML)技术——回顾并分析CS社区的知识结构 [5,7][5,7][5,7]。
基于作者研究团队建立的数据集,共收集了1996年至2019年间台湾期刊上发表的1367篇论文,并对其进行解析和结构化,形成了一个全面的“中国研究”数据库。该数据库有助于提取和分析元数据,包括作者信息、期刊归属和机构信息。
图1:数据集结构
作为进一步的步骤,本研究通过应用生成式人工智能(GAI)和大型语言模型(LLM),将CS文献分析并结构化为一个向量化、可搜索的知识基础设施。同时,我们提出了一个基于结构化三元组(主语-谓语-宾语)的交互式可视化系统,旨在探索和解释CS及政治知识中更广泛的语义关系 [9]。基于三元组的模型在语义网和自然语言处理应用中广泛使用,提供了结构化且可解释的实体关系表示。通过将这种方法与从政治话语中提取的数据相结合,我们的可视化系统将计算工具与政治科学研究中的特定领域需求相连接,特别是在追踪台湾学术景观中意识形态和智识趋势的变化轮廓方面。
2 方法论
2.1 三元组注释
为了构建知识图谱,我们遵循这一路径,应用三元组(主语-谓语-宾语)和基于向量的索引技术,映射台湾中国研究论文之间的关系。
本研究的注释过程主要由两个大型语言模型支持:GPT-4o 和 Breeze-7B,作为自动三元组提取引擎。每个模型独立处理训练数据集,并从文章元数据和摘要中生成候选主语-谓语-宾语三元组。为了提高提取知识的质量,我们应用过滤机制去除低价值的词汇项目——如通用术语“结果”或“研究”——这些术语对知识图谱的语义结构贡献甚微。
在提取出多个语义相似的三元组时,我们采用了以清晰性和主题精确性为导向的选择策略。例如,短语“地方政府倾向于投资于产业”简化为“地方政府倾向于投资”,以确保概念的通用性和图表结构的一致性。
图2:基本三元组可视化
2.2 预处理:减少分歧
预处理阶段对于确保关系数据的一致性、清晰度和可用性至关重要。由于信息可视化,特别是基于图的信息可视化,对输入数据中的冗余和模糊性非常敏感,因此需要一个稳健的预处理策略。我们的预处理管道包括四个关键阶段,每个阶段旨在解决特定类型的不一致性,并改进下游视觉分析的可解释性。
在我们的原始数据集中,由广泛来源提取的主体-关系-客体三元组中,关系类型表现出高度偏斜分布。虽然一小部分关系类型出现频率较高,但长尾类别仅出现一次或两次。这些不频繁的类别通常是由噪声、不一致的标记或孤立案例引起的,这些案例在分析上并不重要。将它们包含在可视化中会导致过度碎片化,阻碍用户识别主导模式。
2.3 预处理II:语义标签合并
即使经过基于频率的整合后,我们仍观察到因词汇变体和不一致术语引起的冗余。例如,像 no 和 not 或 related-to 和 related to 这样的关系实际上指的是相同的底层语义关系
图3:原始三元组和减少分歧
但由于数据录入或源格式的不同而编码不同。
为了解决这些不一致性,我们应用语义标签合并。这涉及将具有相似含义的关系标签归类为统一术语。我们通过半结构化过程手动实现此步骤:首先通过字符串相似性指标识别候选同义词,并与领域特定字典进行交叉检查。然后我们在三元组语料库中审查它们的上下文用法,以确保合并的术语不会混淆语义不同的类别。这一过程在知识图谱构建中尤为重要,因为关系语义的准确性直接影响基于图的推理和解释。
2.4 预处理III:重复项删除
冗余三元组——那些具有相同主体、关系和客体的三元组——是提取数据集中常见的伪影,特别是在聚合多个数据源时。尽管这样的重复可能反映原始语料库中的频率,但在图形可视化时可能导致误判。例如,同一节点对之间重复的边可能会人为地增加节点度或产生重叠标签,降低图形布局算法的有效性。
我们通过在预处理期间执行精确匹配去重操作来解决此问题。每个三元组根据其组成元素进行哈希,并仅保留一次。这确保了生成图的结构性质,如度分布和聚类系数,更准确地反映不同的关系而非冗余提及。
2.5 预处理IV:缩写映射
为了增强网络可视化中关系标签的可读性,我们引入了标准化的缩写映射步骤。长或描述性的关系标签往往超出图形布局中可用的空间,尤其是在节点密集连接或网络以较小比例渲染时。缩写不仅节省空间,还使经验丰富的用户能够更快地进行视觉解析。
我们构建了一个专门的缩写查找表,将每个完整的长关系标签映射为较短的别名(例如,influenced-by → IFB)。该表经过人工策划,以确保缩写直观、唯一并在整个数据集中保持一致。该表还加载到可视化界面中,为用户提供按需图例进行解释。这种设计平衡了视觉经济性和可访问性,支持新手和专家与系统的交互。
3 可视化系统设计
为了促进复杂关系数据的探索,我们使用D3.js库开发了一个交互式网络可视化系统,并部署在基于Web的环境中以实现最大可访问性。该系统旨在支持高层次的结构分析和细粒度的关系检查,使用户能够交互式地探索、过滤和解释从知识图谱或文本挖掘语料库中派生的密集网络。此外,该系统针对实时响应进行了优化,确保对用户交互做出平滑和即时的反馈。关键组件如下:
3.1 数据加载模块
在初始化时,系统加载三元组数据和一个缩写映射表,该表将冗长的关系名称链接到其相应的简码。
解析由客户端通过JavaScript处理,利用高效的数组结构将节点和边数据存储在内存中。在此阶段,系统执行完整性检查,以确保数据集中的每个关系都有相应的缩写。如果检测到不匹配的情况,例如关系标签未在缩写表中找到,系统会在控制台记录警告并将标签标记为手动检查。这个质量控制步骤对于确保标签一致性以及避免因未定义映射而导致的运行时可视化错误至关重要。
3.2 布局引擎和边标签管理
我们采用D3的forceSimulation模块作为布局生成的基础。每个节点对应一个唯一的实体(主语或宾语),而边则代表连接它们的标记关系。力导向方法模拟物理动力学,迭代定位节点和边,从而生成既视觉连贯又结构信息丰富的图形布局。
此外,节点半径根据度中心性(即传入和传出边的数量)动态缩放,使用户能够视觉识别高连通枢纽,这些枢纽可能代表数据集中的关键参与者或概念。
在许多现实世界的网络中,实体可能通过多个不同的关系相连。为了准确表示此类多边场景,我们实现了一个自定义的边偏移和标签机制。标签沿弯曲的SVG路径绘制,使用path和textPath元素。对于连接相同节点对的每组边,系统根据边索引和方向性计算适当的曲率,确保标签不会堆叠或碰撞。
这种动态标签放置策略显著提高了可读性,特别是在需要区分关系的密集子图中。它还保留了语义上下文,使用户能够在没有歧义的情况下区分不同类型的关系。
3.3 交互式过滤和搜索
系统提供了多种交互控件以支持探索性分析:
-
度阈值滑块:用户可以动态调整数值阈值以过滤掉低于某个度的节点。
这使得关注最具有结构意义的实体成为可能,并抑制外围噪音。当阈值发生变化时,系统会实时重新计算子图,并更新视觉渲染和底层数据模型。 -
关键词搜索和层扩展:用户可以输入关键词以在图中定位特定实体。系统突出显示目标节点,并可选择扩展其关系邻域至用户定义的深度。这种多层扩展特别适用于追踪概念或行动者在其更广泛网络中的上下文嵌入 [6]。
这些工具旨在支持自下而上的发现和自上而下的假设检验,使用户能够无缝切换于聚焦查询和全局探索之间。
3.4 用户交互和控件
为了增强交互性并促进深入探索,整个图布景支持平滑的平移、缩放和节点拖动操作。用户可以通过点击并拖动重新定位单个节点,暂时将其固定在原位,以重新组织局部子结构以获得更清晰的可视化效果。此功能在检查密集连接的簇或解开重叠区域时尤其有用。
系统监控用户输入的变化——如搜索查询、阈值调整或拖动事件——并通过触发完整模拟重新渲染作出响应。这确保视觉布局与当前交互上下文保持一致,同时通过动画过渡保持空间连续性。
所有视觉元素均使用可缩放矢量图形(SVG)呈现,这保证了高分辨率清晰度并与现代网络浏览器兼容。使用SVG还启用了精细样式、交互性(如悬停时的工具提示)和响应式布局调整,从而贡献于整体用户友好且视觉吸引的界面。
通过结合实时交互、语义清晰和灵活的视觉控制,该系统为分析复杂的关联结构提供了强大的平台——特别是在知识图谱探索、书目映射或政治科学和数字人文学科中的主题聚类等领域。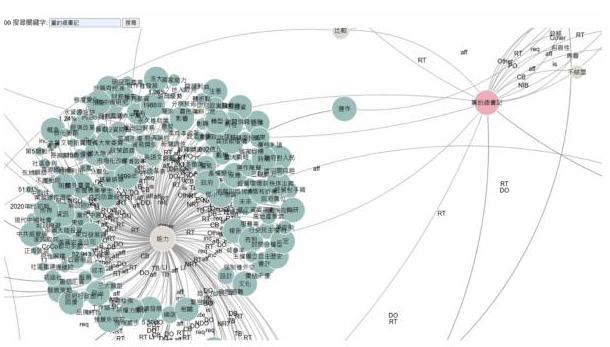
图4:知识图谱UI设计
4 评估
为了评估所提系统的有效性和鲁棒性,我们进行了多维度评估,重点关注四个关键标准:清晰度、响应性、可用性和可扩展性。这些维度的选择不仅反映了输出的视觉分析质量,还反映了系统在探索性研究场景中的实时交互性能。
超越传统的基于关键词的检索系统,该系统要求大量的文本阅读,我们的方法引入了一种结构上截然不同的知识表示形式。具体而言,我们从每篇学术论文中提取基本的概念单元,并将其转换为主语-谓语-宾语三元组,从而将每份文档编码为语义结构。这些知识三元组随后嵌入到更大的知识图谱中,其中每篇文章或想法占据拓扑概念空间中的一条线或一个区域。这使得学者能够导航、比较和整合论文中的想法,从而实现对知识景观更为直观和整体的理解。
这种表示不仅通过视觉交互增强了用户体验,还重新定义了学术知识的获取和扩展方式。新的学术贡献不再作为孤立的参考条目添加;相反,它们作为概念增补被同化到一个不断演进的知识系统中。这种概念颗粒度允许更精确的跨论文推断和比较分析。
此外,我们的框架通过使用大型语言模型(LLM)发现研究产出之间的潜在语义联系,超越了传统的引文网络分析。经典本体工程需要广泛的专业知识和手动策划的模式(例如基于OWL或RDF的本体),而我们的方法采用了一种轻量级的数据驱动替代方案。预训练的LLM能够在无需预定义本体的情况下实现文档间的自动语义链接,从而显著降低知识图谱构建的成本和复杂性。
这种双重创新——(1)将学术文本分解为机器可读的概念单元,(2)通过LLM引导的推理生成新兴知识结构——展示了构建半自动化知识基础设施的可行性。它不仅降低了构建特定领域知识系统的门槛,而且与
5 结论与未来工作
本研究展示了一个端到端的系统,用于预处理和可视化基于三元组的知识图谱数据,重点在于语义清晰度、用户交互和实时响应性。通过系统性的数据精炼——包括类别合并、标签合并、重复项删除和缩写映射——我们生成了一个适合交互可视化的结构化且可解释的数据集。由此产生的系统通过D3.js和基于SVG的渲染实现,能够进行复杂关系结构的探索性分析,并支持用户参与的多种入口点。
我们的工作为信息可视化、知识表示和数字人文学科交叉领域的研究做出了贡献。特别是,我们展示了预处理质量如何直接影响可视化清晰度,
以及交互设计如何增强知识图谱分析的可解释性。集成以用户为中心的功能——如搜索层扩展和基于度的过滤——提供了一个灵活的环境,支持探索性查询和假设生成。
未来的工作将沿着三个主要方向展开:
- 以用户为中心的评估:我们计划与政治科学、信息研究和数字人文学科的学者和学生进行正式的可用性研究。这将提供关于任务特定性能和用户满意度的见解,并帮助确定系统功能中的差距。
-
- 与LLM增强接口的集成:鉴于大型语言模型(LLM)在自然语言理解中的兴起,我们旨在探索这些模型如何协助自动关系分类、语义聚类,甚至对话式的图查询。
-
- 知识中心性和本体:基于社会网络分析的基础,我们采用中心性概念 [4,8][4,8][4,8] 来识别中国研究领域内最具影响力的节点。这种方法不仅突出了特定主题和实体的结构重要性,甚至是领域特定的本体。
- 这项研究直接贡献于第五届台湾研究世界大会的核心使命,通过提供一种创新的数字方法来理解台湾与中国学术互动的知识景观。通过系统地映射和可视化台湾“中国研究”的演变,该项目促进了对台湾几十年跨学科研究成果的新模式的学术访问。
研究团队将在会议演示期间提供基于Web的系统及其相关发现的现场演示。我们欢迎参与者提供批判性反馈和建设性讨论。
参考文献
[1] Kenneth Benoit, Kohei Watanabe, Haiyan Wang, Paul Nulty, Adam Obeng, Stefan Müller, and Akitaka Matsuo. 2018. quanteda: An R package for the quantitative analysis of textual data. Journal of Open Source Software 3, 30 (2018), 774-774.
[2] Michael Bostock, Vadim Ogievetsky, and Jeffrey Heer. 2011. D 3{ }^{3}3 data-driven documents. IEEE transactions on visualization and computer graphics 17, 12 (2011), 2301-2309.
[3] Stuart K Card, Jock Mackinlay, and Ben Shneiderman. 1999. Readings in information visualization: using vision to think. Morgan Kaufmann.
[4] Linton C Freeman et al. 2002. Centrality in social networks: Conceptual clarification. Social network: critical concepts in sociology. Londres: Routledge 1, 3 (2002), 238−263238-263238−263.
[5] Justin Grimmer and Brandon M Stewart. 2013. Text as data: The promise and pitfalls of automatic content analysis methods for political texts. Political analysis 21, 3 (2013), 267-297.
[6] Po-Hsuan Huang and Hsuan-Lei Shao. 2024. Comparison between the Structures of Word Co-occurrence and Word Similarity Networks for Ill-formed and Well-formed Texts in Taiwan Mandarin. arXiv:2408.09404. https://arxiv.org/abs/2408.09404 arXiv preprint.
[7] Michael Laver, Kenneth Benoit, and John Garry. 2003. Extracting policy positions from political texts using words as data. American political science review 97, 2 (2003), 311-331.
[8] Miller McPherson, Lynn Smith-Lovin, and James M Cook. 2001. Birds of a feather: Homophily in social networks. Annual review of sociology 27, 1 (2001), 415-444.
[9] Hinrich Schütze, Christopher D Manning, and Prabhakar Raghavan. 2008. Introduction to information retrieval. Vol. 39. Cambridge University Press Cambridge.
参考论文:https://arxiv.org/pdf/2505.10093

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 24
24 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)