生成式语义通信的视觉保真度指数与关键信息嵌入
黄建浩,曾群松,IEEE会员,以及黄凯斌,IEEE院士生成式语义通信(GenSemCom)结合大型人工智能(AI)模型为6G网络提供了一种变革性的范式,通过传输低维提示而非原始数据来减少通信成本。然而,纯提示驱动的生成会丢失细粒度的视觉细节。此外,缺乏系统性指标来评估Gen-SemCom系统的性能。为了解决这些问题,我们开发了一种混合GenSemCom系统,采用关键信息嵌入(CIE)框架,其中同时
黄建浩,曾群松,IEEE会员,以及黄凯斌,IEEE院士
摘要
生成式语义通信(GenSemCom)结合大型人工智能(AI)模型为6G网络提供了一种变革性的范式,通过传输低维提示而非原始数据来减少通信成本。然而,纯提示驱动的生成会丢失细粒度的视觉细节。此外,缺乏系统性指标来评估Gen-SemCom系统的性能。为了解决这些问题,我们开发了一种混合GenSemCom系统,采用关键信息嵌入(CIE)框架,其中同时提取和传输文本提示和语义关键特征。首先,提出了一种新颖的语义过滤方法,选择并传输与语义标签相关的图像的语义关键特征。通过整合文本提示和关键特征,接收端使用基于扩散的生成模型重建高保真图像。接下来,我们提出了生成视觉信息保真度(GVIF)指标来评估生成图像的视觉质量。通过表征图像特征的统计模型,GVIF指标量化了失真特征与其原始对应物之间的互信息。通过最大化GVIF指标,我们设计了一种自适应信道的Gen-SemCom系统,该系统根据信道状态自适应地控制特征量和压缩率。实验结果验证了GVIF指标对视觉保真的敏感性,与峰值信噪比(PSNR)和关键信息量相关。此外,优化后的系统在更高的PSNR和更低的Fréchet Inception Distance (FID)得分方面优于基准方案。
关键词-生成人工智能,语义通信,视觉保真度指标,变分自编码器,扩散模型。
I. 引言
语义通信(SemCom)被设想为第六代(6G)无线网络的独特范式,它通过强调源数据的语义意义重新定义传输协议 [1]-[3]。与传统系统关注原始数据传输不同,SemCom利用源数据分析识别上下文关键特征,从而减少通信开销。这涉及跨语法和语义层面的数据分析,以确保仅传输与任务相关的信息,例如图像中的对象或语音中的意图。
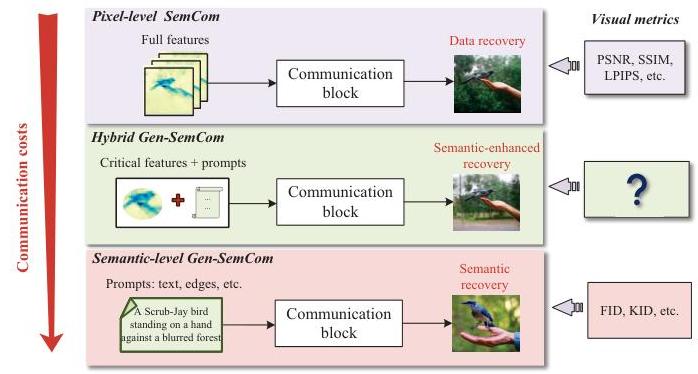
图1:具有不同视觉度量的多级SemCom系统的比较。
对于自动驾驶车辆、工业物联网(IoT)和扩展现实等应用,SemCom可以实现更高效的频谱利用率和更低的延迟,符合6G超快、智能连接的愿景 [4][8]。
当前SemCom研究主要围绕语法级(或像素级)传输展开,其中变分自编码器(VAEs)通过优化恢复失真和压缩率之间的权衡来压缩数据 [9]-[12]。大多数研究集中于探索先进的VAE架构,如卷积神经网络(CNN)和Transformer,以改善率失真权衡 [10]-[13]。一方面,层次化VAEs利用多尺度CNNs将图像压缩到潜在特征域 [10]。另一方面,增强型VAEs利用自注意力机制捕捉长距离依赖关系,实现接近最优的率失真性能 [11], [14]。考虑到传输错误,研究人员已将VAE架构集成到联合源信道编码框架中,产生了一种深联合源信道编码(DJSCC)方案,平衡了端到端失真和传输率 [15], [16]。对于极端信道衰落场景,VAE解码器可与生成对抗网络(GAN)结合,以增强重建视觉质量 [17]。然而,这些方法仍然受到依赖像素级度量(如峰值信噪比(PSNR)和结构相似性指数(SSIM)的限制,这些度量强调语法准确性而非语义相关性。尽管提出了学习感知图像块相似性(LPIPS)度量以更好地捕捉图像的结构相似性,但它未能考虑语义内容(如对象)[18]。例如,忽略视频通话中的冗余背景像素可能不会改变其语义内容,但会降低像素级度量。传统方法的局限性需要向语义级处理转变。
生成式语义通信(Gen-SemCom)作为一种变革性方法出现,通过利用生成式AI(GenAI)从给定的语义含义中重建数据来解决这些局限性 [19]-[24]。与像素级传输不同,语义级Gen-SemCom将数据编码为低维提示(如文本描述 [19], [20], [25], 语义布局 [21] 或边缘图 [20])进行传输,并在接收端使用生成模型生成语义准确的输出 [26], [27]。由于提示的大小远小于图像的完整特征,这种方法可以显著减少传输成本。特别是,已经提出了一种基于扩散的SemCom框架,通过迭代去噪步骤从传输的语义布局逐步生成高保真图像 [21]。这种方法已被证明可以在保持与像素级方法相当的语义准确性的同时减少92%的比特数。然而,纯提示驱动的生成存在丢失细粒度视觉保真度的风险(见图1),因为微妙的纹理或特定领域的细节(如医学成像异常)可能会在生成过程中被过度简化。此外,传统的度量标准,如PSNR和LPIPS,不足以量化生成图像的质量。评估这种生成系统通常采用视觉度量,如核初始距离(KID)和Fréchet初始距离(FID),这些度量评估生成数据分布与真实数据分布之间的统计相似性 [28]。然而,这些度量计算复杂且不适合逐样本质量评估。
为了解决这些问题,混合Gen-SemCom系统作为中间框架出现,统一了语义级提示的效率与语法级传输的可靠性 [29]-[31]。通过战略性地传输提示和数据的关键像素,混合Gen-SemCom系统平衡了频谱效率和重建保真度。该框架的关键组件是关键信息嵌入(CIE),即有选择地传输语义关键像素信息以及提取的提示。这种嵌入设计对于视频和医疗应用尤为重要,因为在这些应用中保留关键像素对于锚定生成过程至真实细节至关重要。然而,现有工作要么传输所有图像信息 [30],这是低效的,要么随机选择像素 [29]。缺少一种有效且可控的方法来提取和传输语义关键信息。虽然基于分割的方法可以识别对象像素,但它们计算成本高昂 [31], [32]。此外,这些方法缺乏根据信道条件调整传输信息量的灵活性。更重要的是,没有适合的度量来评估混合Gen-SemCom系统,因为传统的FID或PSNR无法将视觉保真度与语义关键信息联系起来。
本文专注于带有CIE的无线图像传输的混合Gen-SemCom系统。在这个系统中,大语言模型和VAE方法相结合,用于提示提取和将图像投影到低维潜在特征空间以进行有效的CIE处理。本文的主要贡献和发现总结如下。
- 语义过滤:首先,我们提出应用语义过滤以通过选择语义关键特征进行传输来启用CIE过程。我们的方法利用CNN的空间一致性来建模特征重要性。为此,采用类激活映射(CAM)[33]生成突出与语义标签相关区域的空间重要性矩阵。在此基础上,我们引入了一种基于阈值的过滤机制,选择性地丢弃重要性分数低于可调阈值α\alphaα的特征以减少传输开销。阈值用于平衡效率和保真度:较高值减少通信开销,而较低值保留更丰富的原始视觉信息。
-
- 视觉保真度指数:其次,我们提出生成视觉信息保真度(GVIF)指标来评估生成图像的视觉质量。不同于像素级度量,GVIF指标关注生成图像特征相对于原始特征所保留的信息量,旨在服务于人类视觉系统(HVS)[34]。为了设计GVIF,我们首先使用高斯尺度混合(GSM)模型来建模图像特征的分布,并推导出由各种系统操作引入的失真模型,即基于VAE的压缩、语义过滤和生成。然后,将HVS建模为“高斯信道”,通过向特征添加高斯噪声来限制进入人脑的信息流[34]。最后,GVIF计算失真特征与其原始对应物之间的归一化互信息。提出的GVIF指标被证明与源速率和传输特征数量相关,这两者共同贡献了Gen-SemCom系统的总传输成本。
-
- 应用于自适应信道Gen-SemCom:最后,我们通过根据信道状态最大化提出的GVIF指标来优化混合GenSemCom系统的性能。对于给定的接收信噪比(SNR),基于VAE的源编码器和过滤阈值α\alphaα联合优化以在延迟约束下最大化平均GVIF。为高效解决此问题,我们提出了一种两步算法:首先固定基于VAE的源编码器并通过零阶梯度下降法优化阈值α\alphaα;然后从一组预训练的不同率失真对的模型中选择最佳源编码器。
-
- 实验结果:实验结果表明,提出的GVIF指标具有强大的能力来量化生成图像的视觉保真度。特别是,我们观察到GVIF与PSNR和关键特征体积呈正相关,验证了其对视觉保真度的敏感性。通过使用GVIF优化混合Gen-SemCom框架,系统在关键区域的PSNR高于JPEG2000和基于VAE的基准方案。此外,GVIF驱动的框架减少了语义模糊,产生的FID得分明显低于仅从提示到图像生成的情况。
- 本文其余部分组织如下。混合Gen-SemCom的系统模型在第二部分介绍。第三部分介绍了提出的语义过滤。第四部分提出了GVIF度量。第五部分展示了实验结果,随后在第六部分给出结论。
符号:我们使用小写和大写字母,例如xxx和MMM,表示标量,并使用粗体字母,例如x\boldsymbol{x}x和X\boldsymbol{X}X,表示向量、矩阵和张量。Z,R\mathbb{Z}, \mathbb{R}Z,R, 和 C\mathbb{C}C 分别表示所有整数、实数和复数值的集合。∥x∥\|\boldsymbol{x}\|∥x∥ 表示 x\boldsymbol{x}x 的 2-范数。p(x)p(\boldsymbol{x})p(x) 表示连续随机变量 x\boldsymbol{x}x 的概率密度函数(PDF)。P(y)P(\boldsymbol{y})P(y) 表示离散随机变量 y\boldsymbol{y}y 的概率质量函数(PMF)。Ey(⋅)\mathbb{E}_{\boldsymbol{y}}(\cdot)Ey(⋅) 表示关于随机变量 y\boldsymbol{y}y 的期望。O(⋅)O(\cdot)O(⋅) 表示大O记号。log2(⋅)\log _{2}(\cdot)log2(⋅) 是以 222 为底的对数函数。[N][N][N] 表示整数集 {1,2,⋯ ,N}\{1,2, \cdots, N\}{1,2,⋯,N}。
II. 混合Gen-SemCom系统
考虑一个用于无线图像传输的混合Gen-SemCom系统,如图2所示,其中仅从原始数据中提取语义关键信息以指导接收端的高保真图像生成。该系统的核心是CIE过程。CIE过程与其他系统操作和模型一起描述如下。
A. 关键信息嵌入
CIE过程编码并传输两个组件:(1) 语义级提示(例如,文本描述和布局)和 (2) 关键像素信息。通过嵌入这两个组件,接收端利用生成式AI输出语义准确的图像。以下是详细说明。
- 语义级提示:在本文中,我们将广泛使用的文本描述视为提示。文本描述封装了图像背后粗糙但高级别的语义信息。现代基于大型AI的语言模型如GPT-4 [35], [36], BLIP-2 [37] 可以自动生成详细的标题,描述图像内容、空间关系,甚至视觉场景中存在的抽象概念。虽然这些基于文本的表示不能捕捉每一个细粒度的视觉细节,但它们传输所需的带宽极小——通常只需几百字节,相比原始图像所需的几十千字节或兆字节而言。通过图像样本x\boldsymbol{x}x,文本提取过程可以参数化为
q=H(x;Γ) \boldsymbol{q}=\mathcal{H}(\boldsymbol{x} ; \boldsymbol{\Gamma}) q=H(x;Γ)
其中Γ\boldsymbol{\Gamma}Γ是NN的参数集。
2) 关键像素信息:为了提高图像生成的质量,我们不仅使用文本描述,还嵌入部分但关键的图像像素。这些像素提供了关键的视觉细节,提高了生成图像的准确性和真实性。然而,传输这些像素是有代价的,与传输文本描述的成本相比并不容忽视。因此,在传输前对图像进行额外的压缩和编码是先决条件。这里,我们将编码过程表示为
b=F(x;Φ) \boldsymbol{b}=\mathcal{F}(\boldsymbol{x} ; \boldsymbol{\Phi}) b=F(x;Φ)
其中b\boldsymbol{b}b是关键信息的编码位,Φ\boldsymbol{\Phi}Φ是NN参数集。由于文本提示仅提供语义级别的描述,生成图像的视觉保真度主要受限于关键像素的传输。这为设计有效的编码和传输框架带来了中心挑战。
B. 系统操作和模型
在本小节中,我们介绍了一个针对混合Gen-SemCom与CIE的有效框架设计。特别是,我们利用了训练良好的BLIP模型 [37] 来获得文本描述 q\boldsymbol{q}q,其传输成本被忽略。关键像素的编码和传输如下所述。
- 关键信息提取:考虑一个图像样本 x∈RW×H×3\boldsymbol{x} \in \mathbb{R}^{W \times H \times 3}x∈RW×H×3,取值范围为 [0,255][0,255][0,255],其中 WWW 和 HHH 分别为宽度和高度。对于关键像素,我们采用基于VAE的方案来实现充分编码,如图3所示。首先,图像样本 x\boldsymbol{x}x 被输入到基于CNN的编码函数 F(⋅)F(\cdot)F(⋅) 中,提取其连续特征 y∈RWy×Hy×Cy\boldsymbol{y} \in \mathbb{R}^{W_{y} \times H_{y} \times C_{y}}y∈RWy×Hy×Cy,其中 Wy,HyW_{y}, H_{y}Wy,Hy 和 CyC_{y}Cy 分别为特征的宽度、高度和特征图的数量。换句话说,
y=F(x;ΦE) \boldsymbol{y}=F\left(\boldsymbol{x} ; \Phi_{E}\right) y=F(x;ΦE)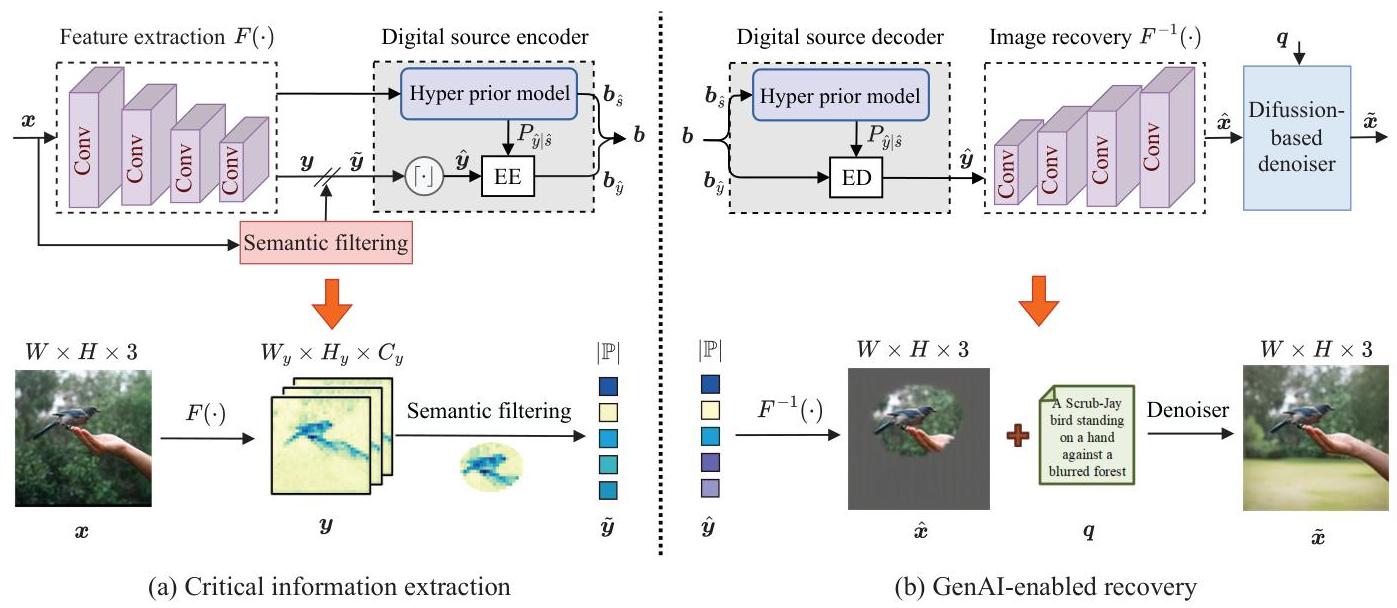
图3:CIE过程的系统操作。Conv, ⌈⋅⌉\lceil\cdot\rceil⌈⋅⌉, EE, 和 ED 分别代表卷积层、标量量化、熵编码器和熵解码器。
其中ΦE\Phi_{E}ΦE表示基于CNN函数的参数集。设yijcy_{i j c}yijc表示特征y\boldsymbol{y}y的(i,j,c)(i, j, c)(i,j,c)-th元素。然后,y\boldsymbol{y}y被送入语义过滤过程,选择与语义信息相对应的关键特征元素,这将在第三节中介绍。过滤后的特征元素遵循y~ijc=yijc,∀(i,j,c)∈P\tilde{y}_{i j c}=y_{i j c}, \forall(i, j, c) \in \mathbb{P}y~ijc=yijc,∀(i,j,c)∈P,其中P\mathbb{P}P为选定的索引集。接下来,连续元素y~ijc\tilde{y}_{i j c}y~ijc使用单位步长的标量均匀量化器量化为离散值元素y~ijc∈Z\tilde{y}_{i j c} \in \mathbb{Z}y~ijc∈Z,操作为y~ijc=⌈y~ijc⌉\tilde{y}_{i j c}=\left\lceil\tilde{y}_{i j c}\right\rceily~ijc=⌈y~ijc⌉。然后,整数元素{y~ijc}\left\{\tilde{y}_{i j c}\right\}{y~ijc}通过熵编码器编码为比特流by~\boldsymbol{b}_{\tilde{y}}by~,例如算术编码器 [38],根据其PMF Py~(y~)P_{\tilde{\boldsymbol{y}}}(\tilde{\boldsymbol{y}})Py~(y~)。
为了准确计算PMF,我们采用了超先验模型 [10],假设这些特征元素服从高斯分布,其方差由NN估计。首先,连续值特征y\boldsymbol{y}y被送入函数L1(y;Ω1)L_{1}\left(\boldsymbol{y} ; \Omega_{1}\right)L1(y;Ω1),参数为Ω1\Omega_{1}Ω1,提取潜在特征s∈RWs×Hs×Cs\boldsymbol{s} \in \mathbb{R}^{W_{s} \times H_{s} \times C_{s}}s∈RWs×Hs×Cs,并量化为s^∈ZWs×Hs×Cs\hat{\boldsymbol{s}} \in \mathbb{Z}^{W_{s} \times H_{s} \times C_{s}}s^∈ZWs×Hs×Cs,即s^=⌈s⌋\hat{\boldsymbol{s}}=\lceil\boldsymbol{s}\rfloors^=⌈s⌋。s^\hat{\boldsymbol{s}}s^的维度远小于y\boldsymbol{y}y的维度。条件于s^\hat{\boldsymbol{s}}s^的过滤特征元素{y~ijc}\left\{\tilde{y}_{i j c}\right\}{y~ijc}可以建模为独立而非同分布(i.n.i.d.)的高斯随机变量,均值为零,方差为θijc2\theta_{i j c}^{2}θijc2。换句话说,
py~ijc∣s^(y~ijc∣s^)=N(y~ijc;0,θijc2),(i,j,c)∈P p_{\tilde{y}_{i j c} \mid \hat{\boldsymbol{s}}}\left(\tilde{y}_{i j c} \mid \hat{\boldsymbol{s}}\right)=\mathcal{N}\left(\tilde{y}_{i j c} ; 0, \theta_{i j c}^{2}\right),(i, j, c) \in \mathbb{P} py~ijc∣s^(y~ijc∣s^)=N(y~ijc;0,θijc2),(i,j,c)∈P
其中N(a;u,θ2)\mathcal{N}\left(a ; u, \theta^{2}\right)N(a;u,θ2)表示均值为uuu,方差为θ2\theta^{2}θ2的高斯分布的概率密度函数(PDF),在点aaa处求值。{θijc}\left\{\theta_{i j c}\right\}{θijc}由应用变换函数L2(⋅;Ω2)L_{2}\left(\cdot ; \Omega_{2}\right)L2(⋅;Ω2)到s^\hat{\boldsymbol{s}}s^估计得到,即θ=L2(s^;Ω2)\boldsymbol{\theta}=L_{2}\left(\hat{\boldsymbol{s}} ; \Omega_{2}\right)θ=L2(s^;Ω2),其中θijc\theta_{i j c}θijc是张量θ∈RWs×Hs×Cs\boldsymbol{\theta} \in \mathbb{R}^{W_{s} \times H_{s} \times C_{s}}θ∈RWs×Hs×Cs的(i,j,c)(i, j, c)(i,j,c)-th元素,分别。给定s^\hat{\boldsymbol{s}}s^条件下y~ijc\tilde{y}_{i j c}y~ijc的条件i.n.i.d.分布可以表示为
Py~ijc∣s^(y~ijc=k∣s^)=∫k=0.5k+0.5N(y~ijc;0,θijc2)dy~ijc P_{\tilde{y}_{i j c} \mid \hat{\boldsymbol{s}}}\left(\tilde{y}_{i j c}=k \mid \hat{\boldsymbol{s}}\right)=\int_{k=0.5}^{k+0.5} \mathcal{N}\left(\tilde{y}_{i j c} ; 0, \theta_{i j c}^{2}\right) d \tilde{y}_{i j c} Py~ijc∣s^(y~ijc=k∣s^)=∫k=0.5k+0.5N(y~ijc;0,θijc2)dy~ijc
其中k∈Zk \in \mathbb{Z}k∈Z。然后,条件PMFs {Py~ijc∣s^(y~ijc=k∣s^)}\left\{P_{\tilde{y}_{i j c} \mid \hat{\boldsymbol{s}}}\left(\tilde{y}_{i j c}=k \mid \hat{\boldsymbol{s}}\right)\right\}{Py~ijc∣s^(y~ijc=k∣s^)}被输入到熵编码器中,将量化特征y^\hat{\boldsymbol{y}}y^编码为比特by~∈{0,1}By~\boldsymbol{b}_{\tilde{y}} \in\{0,1\}^{B_{\tilde{y}}}by~∈{0,1}By~。潜在特征s^\hat{\boldsymbol{s}}s^根据其PMF Ps^(s^)P_{\hat{\boldsymbol{s}}}(\hat{\boldsymbol{s}})Ps^(s^)通过熵编码器编码为比特bs^∈{0,1}Bs^\boldsymbol{b}_{\hat{s}} \in\{0,1\}^{B_{\hat{s}}}bs^∈{0,1}Bs^,使用非参数全因子密度模型 [9] 计算。我们有By~≈−log2Py~∣s^(y^∣s^)B_{\tilde{y}} \approx-\log _{2} P_{\tilde{\boldsymbol{y}} \mid \hat{\boldsymbol{s}}}(\hat{\boldsymbol{y}} \mid \hat{\boldsymbol{s}})By~≈−log2Py~∣s^(y^∣s^)和Bs^≈−log2Ps^(s^)B_{\hat{s}} \approx-\log _{2} P_{\hat{\boldsymbol{s}}}(\hat{\boldsymbol{s}})Bs^≈−log2Ps^(s^)。图像样本x\boldsymbol{x}x的总编码比特收集为b=by~∪bs^\boldsymbol{b}=\boldsymbol{b}_{\tilde{y}} \cup \boldsymbol{b}_{\hat{s}}b=by~∪bs^,维度为B=By~+Bs^B=B_{\tilde{y}}+B_{\hat{s}}B=By~+Bs^。简而言之,编码关键信息的源速率为
R=Ex{−log2Ps^(s^)−log2Py~∣s^(y^∣s^)} \mathcal{R}=\mathbb{E}_{\boldsymbol{x}}\left\{-\log _{2} P_{\hat{\boldsymbol{s}}}(\hat{\boldsymbol{s}})-\log _{2} P_{\tilde{\boldsymbol{y}} \mid \hat{\boldsymbol{s}}}(\hat{\boldsymbol{y}} \mid \hat{\boldsymbol{s}})\right\} R=Ex{−log2Ps^(s^)−log2Py~∣s^(y^∣s^)}
- 传输模型:经过源编码后,比特b\boldsymbol{b}b被编码为一系列复数符号,记为g∈CLs\boldsymbol{g} \in \mathbb{C}^{L_{s}}g∈CLs,用于传输。发送符号的平均功率为E(∥g∥2)/Lx=1\mathbb{E}\left(\|\boldsymbol{g}\|^{2}\right) / L_{x}=1E(∥g∥2)/Lx=1。对于慢衰落信道,接收到的信号,记为r=\boldsymbol{r}=r= [r1,r2,⋯ ,rLs]T\left[r_{1}, r_{2}, \cdots, r_{L_{s}}\right]^{T}[r1,r2,⋯,rLs]T,可以建模为
r=hg+o \boldsymbol{r}=h \boldsymbol{g}+\boldsymbol{o} r=hg+o
其中h∈Ch \in \mathbb{C}h∈C表示信道系数,在LxL_{x}Lx符号时间内保持不变,o=[o1,o2,⋯ ,oLs]T\boldsymbol{o}=\left[o_{1}, o_{2}, \cdots, o_{L_{s}}\right]^{T}o=[o1,o2,⋯,oLs]T表示加性白高斯噪声(AWGN),每个元素服从oi∼CN(0,σ2)o_{i} \sim \mathcal{C N}\left(0, \sigma^{2}\right)oi∼CN(0,σ2)。根据香农定理 [39],最大可达速率为(每秒比特数)C=Blog2(1+∣h∣2σ2)C=B \log _{2}\left(1+\frac{|h|^{2}}{\sigma^{2}}\right)C=Blog2(1+σ2∣h∣2),其中BBB为带宽。考虑无误传输速率为CCC时,平均延迟(以秒为单位),记为TxT_{x}Tx,计算为
Tx=RBlog2(1+∣h∣2σ2) T_{x}=\frac{\mathcal{R}}{B \log _{2}\left(1+\frac{|h|^{2}}{\sigma^{2}}\right)} Tx=Blog2(1+σ2∣h∣2)R
- GenAI支持的恢复:接收端基于传输的比特b\boldsymbol{b}b和文本提示q\boldsymbol{q}q恢复高保真图像。如图3(b)所示,接收到的比特b\boldsymbol{b}b分为两部分:特征比特by~\boldsymbol{b}_{\tilde{y}}by~和辅助信息比特bs^\boldsymbol{b}_{\hat{s}}bs^。首先,bs^\boldsymbol{b}_{\hat{s}}bs^被送入熵解码器,根据共享的PMF Ps^(s^)P_{\hat{\boldsymbol{s}}}(\hat{\boldsymbol{s}})Ps^(s^)解码辅助信息s^\hat{\boldsymbol{s}}s^。然后,s^\hat{\boldsymbol{s}}s^被送入函数L2(⋅;Ω2)L_{2}\left(\cdot ; \Omega_{2}\right)L2(⋅;Ω2)计算给定(5)中的PMF,Py^∣s^(y^∣s^)P_{\hat{\boldsymbol{y}} \mid \hat{\boldsymbol{s}}}(\hat{\boldsymbol{y}} \mid \hat{\boldsymbol{s}})Py^∣s^(y^∣s^)。有了Py^∣s^(y^∣s^)P_{\hat{\boldsymbol{y}} \mid \hat{\boldsymbol{s}}}(\hat{\boldsymbol{y}} \mid \hat{\boldsymbol{s}})Py^∣s^(y^∣s^)和bs^\boldsymbol{b}_{\hat{\boldsymbol{s}}}bs^,特征向量y^\hat{\boldsymbol{y}}y^通过利用熵解码器进行解码。接下来,特征y^\hat{\boldsymbol{y}}y^被送入基于CNN的解码函数,记为F−1(⋅)F^{-1}(\cdot)F−1(⋅),输出图像x^\hat{\boldsymbol{x}}x^。换句话说,
x^=F−1(y^;ΦD) \hat{\boldsymbol{x}}=F^{-1}\left(\hat{\boldsymbol{y}} ; \Phi_{D}\right) x^=F−1(y^;ΦD)
其中ΦD\Phi_{D}ΦD表示解码函数的参数集。最后,含噪图像x^\hat{\boldsymbol{x}}x^和提示q\boldsymbol{q}q被送入基于扩散的去噪器生成图像x~\tilde{\boldsymbol{x}}x~,详情如下。
4) 扩散去噪器:在本文中,我们采用预训练的扩散模型[26], [40]从含噪输入x^\hat{\boldsymbol{x}}x^生成高质量图像x~\tilde{\boldsymbol{x}}x~。首先,我们生成二进制掩码m‾∈{0,1}W×H×3\overline{\boldsymbol{m}} \in\{0,1\}^{W \times H \times 3}m∈{0,1}W×H×3,值为1表示关键像素的位置。关键像素的位置将作为辅助信息传输到接收端,具体细节将在第III-C节中详细介绍。基于掩码m‾\overline{\boldsymbol{m}}m,生成过程可以表述为条件修复[26], [40],其中x^\hat{\boldsymbol{x}}x^中的关键像素和文本提示q\boldsymbol{q}q共同引导缺失像素的生成。我们采用反向扩散过程,通过TTT次迭代细化步骤将高斯噪声xT∼N(0,I)\boldsymbol{x}_{T} \sim \mathcal{N}(\mathbf{0}, \boldsymbol{I})xT∼N(0,I)逐渐转化为图像。在每次时间步ttt中,应用UNet模型[26] Uθ,tU_{\theta, t}Uθ,t预测基于部分像素和语义提示的噪声成分:
ϵθ,t=Uθ,t(xt,t,m‾⊙x^,q) \epsilon_{\theta, t}=U_{\theta, t}\left(\boldsymbol{x}_{t}, t, \overline{\boldsymbol{m}} \odot \hat{\boldsymbol{x}}, \boldsymbol{q}\right) ϵθ,t=Uθ,t(xt,t,m⊙x^,q)
其中xt\boldsymbol{x}_{t}xt是步骤ttt中的隐状态,m‾⊙x^\overline{\boldsymbol{m}} \odot \hat{\boldsymbol{x}}m⊙x^表示张量m‾\overline{\boldsymbol{m}}m和x~\tilde{\boldsymbol{x}}x~的元素乘法。反向转换遵循:
xt−1=1αt(xt−βt1−αˉtϵθ,t)+σt2z \boldsymbol{x}_{t-1}=\frac{1}{\sqrt{\alpha_{t}}}\left(\boldsymbol{x}_{t}-\frac{\beta_{t}}{\sqrt{1-\bar{\alpha}_{t}}} \boldsymbol{\epsilon}_{\theta, t}\right)+\sigma_{t}^{2} \boldsymbol{z} xt−1=αt1(xt−1−αˉtβtϵθ,t)+σt2z
其中αt,βt,σt\alpha_{t}, \beta_{t}, \sigma_{t}αt,βt,σt是调度参数,αˉt=∏s=1T(1−\bar{\alpha}_{t}=\prod_{s=1}^{T}(1-αˉt=∏s=1T(1− βs)\left.\beta_{s}\right)βs),z∼N(0,I)\boldsymbol{z} \sim \mathcal{N}(0, \boldsymbol{I})z∼N(0,I)是附加噪声。经过TTT次迭代后,我们得到x~=m‾⊙x^+(1−m‾)⊙x0\tilde{\boldsymbol{x}}=\overline{\boldsymbol{m}} \odot \hat{\boldsymbol{x}}+(1-\overline{\boldsymbol{m}}) \odot \boldsymbol{x}_{0}x~=m⊙x^+(1−m)⊙x0。反向过程构成从高斯噪声到真实图像分布的学习映射。因此,生成图像大致遵循条件分布,即x~∼p(x∣m‾⊙x~,q)\tilde{\boldsymbol{x}} \sim p(\boldsymbol{x} \mid \overline{\boldsymbol{m}} \odot \tilde{\boldsymbol{x}}, \boldsymbol{q})x~∼p(x∣m⊙x~,q)。
C. 源编码器的训练
本小节介绍基于VAE的源编码器的训练细节。令Φ={ΦE,ΦD,Ω1,Ω2}\boldsymbol{\Phi}=\left\{\Phi_{E}, \Phi_{D}, \Omega_{1}, \Omega_{2}\right\}Φ={ΦE,ΦD,Ω1,Ω2}为源编码和解码的完整神经网络参数集。Φ\boldsymbol{\Phi}Φ的训练独立于语义过滤和生成过程,遵循率失真理论的原则。根据率失真理论的形式化 [41],目标是确定重建原始图像所需最小比特率,同时尽量减少失真。为此,我们将每像素失真度量定义为均方误差(MSE):
D(Φ)=Ex{13×W×H∥x−x~∥2} \mathcal{D}(\boldsymbol{\Phi})=\mathbb{E}_{\boldsymbol{x}}\left\{\frac{1}{3 \times W \times H}\|\boldsymbol{x}-\tilde{\boldsymbol{x}}\|^{2}\right\} D(Φ)=Ex{3×W×H1∥x−x~∥2}
离散量化过程近似为向特征元素添加零均值半径1的均匀噪声。在训练期间,省略语义过滤过程,因此y~=y\tilde{\boldsymbol{y}}=\boldsymbol{y}y~=y。然后,神经网络参数Φ\boldsymbol{\Phi}Φ被训练以优化率失真权衡:
Φ=argminΦR(Φ)+λD(Φ) \boldsymbol{\Phi}=\arg \min _{\boldsymbol{\Phi}} \mathcal{R}(\boldsymbol{\Phi})+\lambda \mathcal{D}(\boldsymbol{\Phi}) Φ=argΦminR(Φ)+λD(Φ)
其中λ>0\lambda>0λ>0是一个平衡参数。通过调整λ\lambdaλ,可以获得具有不同率失真对的多个源编码模型。
III. 语义过滤
在本节中,我们提出了语义过滤方法来选择语义非关键特征元素进行修剪以节省传输资源。首先,我们开发了一个框架来量化特征相对于图像语义标签的重要性。基于特征重要性,我们提出了一个特征过滤策略,修剪非关键特征。
A. 语义重要性建模
在本文中,我们将图像的标签视为其语义信息,例如鸟、狐狸和人类,这些对应于图像中的特定像素部分。通常,一种简单的方法是通过基础模型的分割方法[32]来识别语义关键像素,其中属于对象的所有像素被赋予相等的重要性。然而,这种方法由于像素的高维度而计算昂贵。此外,同一对象内的像素在表示该对象的最关键信息时可能具有不平等的重要性[33]。
为了解决这些问题,我们在特征域中提出了一个重要性建模框架。通过利用VAE编码的潜在特征y\boldsymbol{y}y的空间相关性,我们直接量化每个特征元素相对于语义标签的重要性。以下是详细说明。
- 特征y\boldsymbol{y}y的空间属性。如图3所示,当图像通过函数F(⋅)F(\cdot)F(⋅)处理时,CNN层保持原始输入的空间层次结构,这意味着图像中对象的相对位置在特征图中得以保留。这种现象被称为CNN的空间一致性属性[42]。根据这一属性,我们可以在二维空间中对特征的空间重要性进行建模。不失一般性,我们定义一个重要性矩阵I∈RWy×Hy\boldsymbol{I} \in \mathbb{R}^{W_{y} \times H_{y}}I∈RWy×Hy,其元素Iij∈[0,1]I_{i j} \in[0,1]Iij∈[0,1]。重要性矩阵在特征y\boldsymbol{y}y的所有地图中是一致的。
-
- 语义重要性建模。我们采用广为人知的类别激活映射(CAM)[33]对空间重要性矩阵I\boldsymbol{I}I进行建模。如图4所示,CAM的关键在于生成一个热力图,表示对语义标签有贡献的空间网格的重要性。首先,利用骨干模型(例如预训练的ResNet-50),包含CNN层,
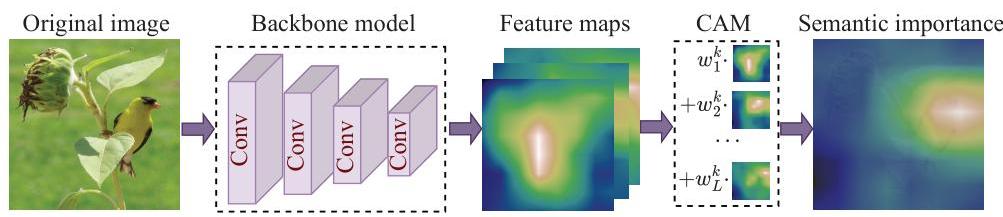
图4:使用CAM进行语义重要性建模。在此示例中,我们将重要性矩阵与调整大小的图像样本混合以更好地说明。CAM方案的输出突出了相对于对象标签的语义关键区域。
提取图像的特征图。对于一张图像,设f∈RWf×Hf×Cf\boldsymbol{f} \in \mathbb{R}^{W_{f} \times H_{f} \times C_{f}}f∈RWf×Hf×Cf表示从骨干模型中提取的特征,其中Wf,HfW_{f}, H_{f}Wf,Hf, 和CfC_{f}Cf分别是宽度、高度和特征图的数量。设fc∈RWf×Hf,c∈[Cf]\boldsymbol{f}_{c} \in \mathbb{R}^{W_{f} \times H_{f}}, c \in\left[C_{f}\right]fc∈RWf×Hf,c∈[Cf],表示f\boldsymbol{f}f的第ccc个特征图。当执行分类任务时,提取的特征f\boldsymbol{f}f将被输入到带有softmax函数的全连接神经网络中,以输出每个标签的概率。具体来说,标签kkk的概率,记为PkP_{k}Pk,计算为
Pk=eSk∑keSk, with Sk=∑cwck∑i,jfijc P_{k}=\frac{e^{S_{k}}}{\sum_{k} e^{S_{k}}}, \text { with } S_{k}=\sum_{c} w_{c}^{k} \sum_{i, j} f_{i j c} Pk=∑keSkeSk, with Sk=c∑wcki,j∑fijc
其中fijcf_{i j c}fijc表示特征f\boldsymbol{f}f的(i,j,c)(i, j, c)(i,j,c)-th元素,wckw_{c}^{k}wck表示标签kkk的全连接神经网络的参数。本质上,wckw_{c}^{k}wck表示第ccc个特征图对类kkk的重要性。因此,类kkk的重要性矩阵计算为特征图的加权和,即,
Ik=∑cwckfc \boldsymbol{I}^{k}=\sum_{c} w_{c}^{k} \boldsymbol{f}_{c} Ik=c∑wckfc
然后,将Ik\boldsymbol{I}^{k}Ik的每个元素归一化到区间[0,1][0,1][0,1]。最后,将归一化的矩阵Ik\boldsymbol{I}^{k}Ik上采样到特征y\boldsymbol{y}y的空间尺寸,即(Wy,Hy)\left(W_{y}, H_{y}\right)(Wy,Hy)。
CAM过程输出所有可能对象标签的重要性矩阵{Ik}\left\{\boldsymbol{I}^{k}\right\}{Ik}。对于包含多个对象的图像,发送方可以灵活选择感兴趣对象的重要性矩阵。在本文中,我们以单标签图像为例。因此,我们选择检测概率最大的语义重要性矩阵,即,
I=Ik, with k=argmaxPk \boldsymbol{I}=\boldsymbol{I}^{k}, \text { with } k=\arg \max P_{k} I=Ik, with k=argmaxPk
B. 特征过滤
通过获得的重要性矩阵I\boldsymbol{I}I,我们定义一个索引集为
P≜{(i,j,c)[Iij≥α,i∈[Wy],j∈[Hy],c∈[Cy]} \mathbb{P} \triangleq\left\{(i, j, c)\left[I_{i j} \geq \alpha, i \in\left[W_{y}\right], j \in\left[H_{y}\right], c \in\left[C_{y}\right]\right\}\right. P≜{(i,j,c)[Iij≥α,i∈[Wy],j∈[Hy],c∈[Cy]}
其中α≥0\alpha \geq 0α≥0表示过滤阈值。仅属于集合P\mathbb{P}P的特征元素,即yijc,(i,j,c)∈Py_{i j c},(i, j, c) \in \mathbb{P}yijc,(i,j,c)∈P,被选中进行传输。过滤过程可以表示如下,
y~ijc={yijc, if (i,j,c)∈P0, otherwise \tilde{y}_{i j c}= \begin{cases}y_{i j c}, & \text { if }(i, j, c) \in \mathbb{P} \\ 0, & \text { otherwise }\end{cases} y~ijc={yijc,0, if (i,j,c)∈P otherwise
其中y~ijc\tilde{y}_{i j c}y~ijc是特征y~\tilde{\boldsymbol{y}}y~的(i,j,c)(i, j, c)(i,j,c)-th元素。然后,过滤后的特征y~\tilde{\boldsymbol{y}}y~被量化为y~\tilde{\boldsymbol{y}}y~,然后编码为比特流进行传输。
备注3.1. 提出的过滤过程是一种可控程序,旨在通过调整阈值α\alphaα来平衡传输延迟和视觉质量。当α=0\alpha=0α=0时,所有视觉信息都被传输,使提出的框架相当于面向数据的设计。在零到一的范围内选择α\alphaα会导致某些视觉信息的丢失,同时有效地减少传输延迟。因此,优化α\alphaα对于平衡视觉保真度和传输至关重要,这将在第V节中详细讨论。
C. 辅助信息传输
为了传输过滤后的特征y~\tilde{\boldsymbol{y}}y~,索引集P\mathbb{P}P被视为辅助信息,需要传输到接收端以指示所选特征的位置。为了减少传输开销,过滤集P\mathbb{P}P应该被有效地压缩并编码为比特。根据(17),观察到只有P\mathbb{P}P的空间网格{(i,j)}\{(i, j)\}{(i,j)}需要传输。因此,我们可以构造一个二进制掩码mP∈RWy×Hy×1\boldsymbol{m}_{\mathbb{P}} \in \mathbb{R}^{W_{y} \times H_{y} \times 1}mP∈RWy×Hy×1,其(i,j)(i, j)(i,j)-th图像像素如果(i,j)∈P(i, j) \in \mathbb{P}(i,j)∈P则设置为1,否则为0。有效地将掩码图像编码为比特流bP∈{0,1}BP\boldsymbol{b}_{\mathbb{P}} \in\{0,1\}^{B_{\mathbb{P}}}bP∈{0,1}BP。注意,经过高效压缩后,BPB_{\mathbb{P}}BP比像素的比特数小得多,可以忽略不计。接收端将接收到的掩码mP\boldsymbol{m}_{\mathbb{P}}mP上采样到图像大小,即m~∈{0,1}W×H×3\tilde{\boldsymbol{m}} \in\{0,1\}^{W \times H \times 3}m~∈{0,1}W×H×3,以生成图像。
IV. 视觉信息保真度
在本节中,我们设计了GVIF度量来量化生成图像的视觉保真度。我们首先建立了图像特征及其失真的统计模型,然后结合了一个众所周知的人类视觉系统(HVS)模型。基于这些模型,我们推导出了GVIF度量。
A. 图像特征的统计模型
受传统VIF度量的启发,所提出的GVIF度量通过信息论参考-失真框架[34]、[44]评估图像质量。参考模型捕获原始图像特征的统计信息,而失真模型通过量化这些特征如何被Gen-SemCom系统改变来模拟退化过程。然而,当前用于图像分析的统计模型局限于频率域[34]、[44],留下了基于特征的质量评估的空白。为了解决这个问题,我们使用第II节中介绍的基于VAE的超先验模型推导出图像特征的统计模型。
- 参考模型:根据超先验模型[10],表示图像的特征元素{yijc}\left\{y_{i j c}\right\}{yijc}可以建模为条件高斯变量,即yijc∣θ∼N(0,θijc2)y_{i j c} \mid \boldsymbol{\theta} \sim \mathcal{N}\left(0, \theta_{i j c}^{2}\right)yijc∣θ∼N(0,θijc2),其中标准差θijc\theta_{i j c}θijc是参数θ\boldsymbol{\theta}θ的(i,j,c)(i, j, c)(i,j,c)-th元素。正式地,随机变量yijcy_{i j c}yijc可以通过GSM模型[34]进行表征,该模型是标量随机变量和零均值方差一的高斯随机变量的乘积,即,
yijc=θijc⋅uijc,∀i∈[Wy],y∈[Hy],c∈[Cy] y_{i j c}=\theta_{i j c} \cdot u_{i j c}, \forall i \in\left[W_{y}\right], y \in\left[H_{y}\right], c \in\left[C_{y}\right] yijc=θijc⋅uijc,∀i∈[Wy],y∈[Hy],c∈[Cy]
其中{uijc}\left\{u_{i j c}\right\}{uijc}是独立同分布的高斯随机变量,具有uijc∼u_{i j c} \simuijc∼ N(0,1)\mathcal{N}(0,1)N(0,1),并且独立于随机变量{θijc}\left\{\theta_{i j c}\right\}{θijc}。注意,(19)中的变量{θijc}\left\{\theta_{i j c}\right\}{θijc}受到源编码器的影响,这不可避免地引入了信息损失。然而,我们的目标是获得模拟无损图像特征的参考模型来表示原始图像。为了最小化源编码器带来的失真,我们选择具有相对较小源失真D(Φr)\mathcal{D}\left(\boldsymbol{\Phi}^{r}\right)D(Φr)的基于VAE的编码器,其参数集为Φr\boldsymbol{\Phi}^{r}Φr。然后,原始图像的参考模型定义为
yijcr=θijcr⋅uijc y_{i j c}^{r}=\theta_{i j c}^{r} \cdot u_{i j c} yijcr=θijcr⋅uijc
其中θijcr=L2(s^;Ω2r)\theta_{i j c}^{r}=L_{2}\left(\hat{\boldsymbol{s}} ; \Omega_{2}^{r}\right)θijcr=L2(s^;Ω2r)。令θr={θijcr}\boldsymbol{\theta}^{r}=\left\{\theta_{i j c}^{r}\right\}θr={θijcr}。
类似于图像的子带,所推导的GSM模型在特征域上产生重尾边缘和方差缩放联合密度,捕捉自然图像的关键统计特性[34],[44]。一方面,图像特征之间的关键依赖关系,例如边缘行为,可以使用相关的变量{θijc}\left\{\theta_{i j c}\right\}{θijc}进行建模。另一方面,随机变量θ\boldsymbol{\theta}θ的实现因不同的图像样本而异,反映了图像之间的不同内容。总之,随机变量θ\boldsymbol{\theta}θ的实现捕捉了图像样本的独特视觉信息,这将在第IV-B节中用于计算其视觉保真度指数。
2) 失真模型:失真模型的目的是描述图像特征如何被VAE、语义过滤和生成过程干扰。在这里,我们忽略量化过程,因为量化级别总是固定的,而其他由NN参数和过滤集P\mathbb{P}P影响的过程对保真度度量贡献最大。
- VAE的失真模型:根据(6)和(19),我们观察到从源编码器提取的所有特征元素都可以用GSM模型建模。源编码器的源速率位于方差{θijc2}\left\{\theta_{i j c}^{2}\right\}{θijc2}的缩放范围内。较大的θijc2\theta_{i j c}^{2}θijc2值对应于更多的图像表示保留信息。因此,我们可以简单地将特定VAE基源编码器的失真模型建立为一个缩放模型,即,
yijcc=βijc⋅yijcr y_{i j c}^{c}=\beta_{i j c} \cdot y_{i j c}^{r} yijcc=βijc⋅yijcr
其中0<βijc≤10<\beta_{i j c} \leq 10<βijc≤1是一个由源编码器和图像样本决定的随机变量。记β\boldsymbol{\beta}β为缩放变量的集合,即β={βijc}\boldsymbol{\beta}=\left\{\beta_{i j c}\right\}β={βijc}。
2) 语义过滤的失真模型:基于(18)中的过滤过程,我们有
yijcs={yijcc, if (i,j,c)∈P0, otherwise y_{i j c}^{s}= \begin{cases}y_{i j c}^{c}, & \text { if }(i, j, c) \in \mathbb{P} \\ 0, & \text { otherwise }\end{cases} yijcs={yijcc,0, if (i,j,c)∈P otherwise
- 生成过程的失真模型:对于生成图像x~\tilde{\boldsymbol{x}}x~,存在一个特征yg\boldsymbol{y}^{g}yg使得x~=F−1([yg];ΦD)\tilde{\boldsymbol{x}}=F^{-1}\left(\left[\boldsymbol{y}^{g}\right] ; \Phi_{D}\right)x~=F−1([yg];ΦD)。根据第II-D节,基于扩散的过程将锚定集合P\mathbb{P}P中的特征元素,同时通过基于扩散的模型独立生成其他特征元素。因此,生成的特征元素yijcgy_{i j c}^{g}yijcg遵循
yijcg=yijcs=yijcc, if (i,j,c)∈Pyijcg is independent of yijcc, if (i,j,c)∉P \begin{aligned} & y_{i j c}^{g}=y_{i j c}^{s}=y_{i j c}^{c}, \text { if }(i, j, c) \in \mathbb{P} \\ & y_{i j c}^{g} \text { is independent of } y_{i j c}^{c}, \text { if }(i, j, c) \notin \mathbb{P} \end{aligned} yijcg=yijcs=yijcc, if (i,j,c)∈Pyijcg is independent of yijcc, if (i,j,c)∈/P
验证:见附录A。
3) HVS模型:该模型旨在复制人类大脑感知和处理视觉信息的方式,如对象识别和深度感知。HVS模型可以近似为带有视觉噪声的“高斯信道”[34],[44],这限制了信息流过它的能力。
在本文中,我们探索了HVS模型在特征域中的应用,以测量图像的信息。视觉噪声可以建模为具有零均值和方差γ2\gamma^{2}γ2的平稳高斯噪声,它被添加到每个特征元素[34],[44]。通过HVS模型,失真特征yijcgy_{i j c}^{g}yijcg在(23)-(24)和参考特征yijcry_{i j c}^{r}yijcr可以分别受到干扰
yijcd=yijcg+nijcyijcr=yijcr+n^ijc \begin{aligned} & y_{i j c}^{d}=y_{i j c}^{g}+n_{i j c} \\ & y_{i j c}^{r}=y_{i j c}^{r}+\hat{n}_{i j c} \end{aligned} yijcd=yijcg+nijcyijcr=yijcr+n^ijc
其中视觉噪声nijc,n^ijc∼N(0,γ2)n_{i j c}, \hat{n}_{i j c} \sim \mathcal{N}\left(0, \gamma^{2}\right)nijc,n^ijc∼N(0,γ2)假设与yijcry_{i j c}^{r}yijcr和yijcgy_{i j c}^{g}yijcg独立。记gd={gijcd}∈\boldsymbol{g}^{d}=\left\{g_{i j c}^{d}\right\} \ingd={gijcd}∈ RWy×Hy×Cy,gr={gijcr}∈RWy×Hy×Cy,n={nijc},n^=\mathbb{R}^{W_{y} \times H_{y} \times C_{y}}, \boldsymbol{g}^{r}=\left\{g_{i j c}^{r}\right\} \in \mathbb{R}^{W_{y} \times H_{y} \times C_{y}}, \boldsymbol{n}=\left\{n_{i j c}\right\}, \hat{\boldsymbol{n}}=RWy×Hy×Cy,gr={gijcr}∈RWy×Hy×Cy,n={nijc},n^= {n^ijc}\left\{\hat{n}_{i j c}\right\}{n^ijc}。
B. GVIF定义、性质和计算
有了上述参考、失真和HVS模型,GenAI支持系统的GVIF度量如下推导。类似于传统的VIF度量[44],GVIF利用互信息作为度量来量化可以从HVS输出中提取的信息量。注意,我们感兴趣的是特定参考-失真图像对的视觉保真度,而不是图像集合的平均质量。因此,利用给定图像样本和失真过程的条件互信息来计算GVIF。
- GVIF度量:设θ^r\hat{\boldsymbol{\theta}}^{r}θ^r和β^\hat{\boldsymbol{\beta}}β^分别为随机变量θr\boldsymbol{\theta}^{r}θr和β\boldsymbol{\beta}β的实现。给定统计参数θ^r,β^\hat{\boldsymbol{\theta}}^{r}, \hat{\boldsymbol{\beta}}θ^r,β^和确定性集合P\mathbb{P}P,我们假设控制失真特征的随机过程是遍历的。这使得互信息可以通过单一图像样本的统计数据进行计算,绕过了对多个实现的集合平均的需求。然后,计算失真特征与其原始对应物之间的条件互信息为I(gy;yr∣θr=θ‾r,β=β‾)\boldsymbol{I}\left(\boldsymbol{g}^{y} ; \boldsymbol{y}^{r} \mid \boldsymbol{\theta}^{r}=\overline{\boldsymbol{\theta}}^{r}, \boldsymbol{\beta}=\overline{\boldsymbol{\beta}}\right)I(gy;yr∣θr=θr,β=β)。对于参考图像样本,条件互信息计算为I(gr;yr∣θr=θ‾r)\boldsymbol{I}\left(\boldsymbol{g}^{r} ; \boldsymbol{y}^{r} \mid \boldsymbol{\theta}^{r}=\overline{\boldsymbol{\theta}}^{r}\right)I(gr;yr∣θr=θr)。根据[44],视觉保真度取决于失真图像中保留信息的比例与参考图像中的信息比例。然后,我们有以下结果。
命题4.1. 对于图像样本x\boldsymbol{x}x,其实现为θ‾r\overline{\boldsymbol{\theta}}^{r}θr和β‾\overline{\boldsymbol{\beta}}β,以及给定视觉噪声的方差γ2\gamma^{2}γ2和过滤集P\mathbb{P}P,GVIF可以表示为
V(β‾,P;x)≜I(gd;yr∣θr=θ‾r,β=β‾)I(gr;yr∣θr=θ‾r)=∑(i,j,c)∈Plog2(1+(βˉijcθˉijcr)2γ2)∑(i,j,c)∈Ulog2(1+(θˉijcr)2γ2) \begin{aligned} V(\overline{\boldsymbol{\beta}}, \mathbb{P} ; \boldsymbol{x}) & \triangleq \frac{\boldsymbol{I}\left(\boldsymbol{g}^{d} ; \boldsymbol{y}^{r} \mid \boldsymbol{\theta}^{r}=\overline{\boldsymbol{\theta}}^{r}, \boldsymbol{\beta}=\overline{\boldsymbol{\beta}}\right)}{\boldsymbol{I}\left(\boldsymbol{g}^{r} ; \boldsymbol{y}^{r} \mid \boldsymbol{\theta}^{r}=\overline{\boldsymbol{\theta}}^{r}\right)} \\ & =\frac{\sum_{(i, j, c) \in \mathbb{P}} \log _{2}\left(1+\frac{\left(\bar{\beta}_{i j c} \bar{\theta}_{i j c}^{r}\right)^{2}}{\gamma^{2}}\right)}{\sum_{(i, j, c) \in \mathbb{U}} \log _{2}\left(1+\frac{\left(\bar{\theta}_{i j c}^{r}\right)^{2}}{\gamma^{2}}\right)} \end{aligned} V(β,P;x)≜I(gr;yr∣θr=θr)I(gd;yr∣θr=θr,β=β)=∑(i,j,c)∈Ulog2(1+γ2(θˉijcr)2)∑(i,j,c)∈Plog2(1+γ2(βˉijcθˉijcr)2)
其中θˉijcr\bar{\theta}_{i j c}^{r}θˉijcr和βˉijc\bar{\beta}_{i j c}βˉijc分别是张量参数θ‾r\overline{\boldsymbol{\theta}}^{r}θr和β‾\overline{\boldsymbol{\beta}}β的(i,j,c)(i, j, c)(i,j,c)-th元素,并且U={(i,j,c)∣i∈\mathbb{U}=\{(i, j, c) \mid i \inU={(i,j,c)∣i∈ [Wy;j∈[Hy;c∈[Cy]}\left[W_{y} ; j \in\left[H_{y} ; c \in\left[C_{y}\right]\right\}\right.[Wy;j∈[Hy;c∈[Cy]}是完整的维度集合。
证明:见附录B。
根据命题4.1,我们对GVIF的性质有以下观察:
- GVIF位于区间[0,1][0,1][0,1]内,并且相对于集合P\mathbb{P}P和{βˉijc}\left\{\bar{\beta}_{i j c}\right\}{βˉijc}是单调递增函数。首先,如果图像未失真(即P=U\mathbb{P}=\mathbb{U}P=U和βijc=1∀(i,j,c)\beta_{i j c}=1 \forall(i, j, c)βijc=1∀(i,j,c)),则GVIF等于1。其次,如果没有视觉信息传输(即P=∅\mathbb{P}=\emptysetP=∅),则GVIF等于0。第三,如果P≠∅\mathbb{P} \neq \emptysetP=∅但关键像素完全失真(即βijc=0\beta_{i j c}=0βijc=0),则GVIF也等于0。在第二和第三种情况下,接收端从随机噪声生成图像,导致视觉保真度完全丧失。
-
- GVIF与HVS感知图像内容的能力表现出强烈的关联。具体来说,当集合P\mathbb{P}P包含高方差特征时,(θijcr)2(\theta_{i j c}^{r})^{2}(θijcr)2指示关键信息如图像对象的存在,GVIF迅速增加。相反,在对象缺失的情况下,GVIF保持相对较低。为了更好地说明这一点,我们展示了具有不同集合P\mathbb{P}P的图像样本,如图6所示。观察到当对象被包括进传输区域时,
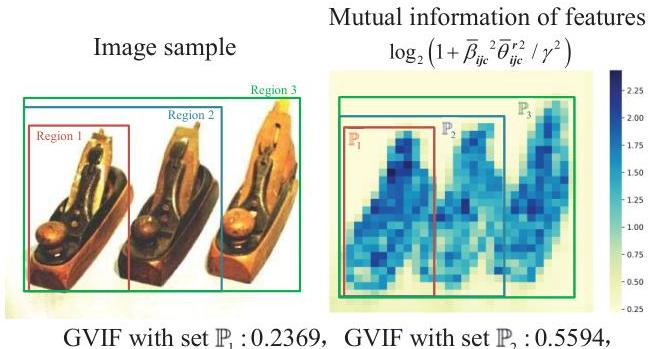
图6:GVIF在理解图像内容方面的能力示意图。在这个图像示例中,我们主动选择不同的集合P\mathbb{P}P来选择图像特征。为了更好的展示,我们将集合上采样到图像大小作为区域。我们设置βˉijc=1,∀i,j,c\bar{\beta}_{i j c}=1, \forall i, j, cβˉijc=1,∀i,j,c和γ=0.1\gamma=0.1γ=0.1。展示的互信息是对特征通道的平均值。
进入传输区域时,GVIF显著增加。使用集合P3\mathbb{P}_{3}P3时,GVIF约为0.9,表明其余背景像素仅包含所有图像信息的0.1。
- 计算步骤:这里,我们介绍了任何参考-失真对的GVIF度量的计算细节。设Φr={ΦEr,ΦDr,Ω1r,Ω2r}\boldsymbol{\Phi}^{r}=\left\{\Phi_{E}^{r}, \Phi_{D}^{r}, \Omega_{1}^{r}, \Omega_{2}^{r}\right\}Φr={ΦEr,ΦDr,Ω1r,Ω2r}为参考源编码器的参数集,其源失真为D(Φr)\mathcal{D}\left(\boldsymbol{\Phi}^{r}\right)D(Φr)。根据第II节中介绍的超先验模型,对于图像样本x\boldsymbol{x}x,参考参数θ‾r\overline{\boldsymbol{\theta}}^{r}θr计算为
θ‾r=L2([L1(F(x;ΦEr);Ω1r)];Ω2r) \overline{\boldsymbol{\theta}}^{r}=L_{2}\left(\left[L_{1}\left(F\left(\boldsymbol{x} ; \Phi_{E}^{r}\right) ; \Omega_{1}^{r}\right)\right] ; \Omega_{2}^{r}\right) θr=L2([L1(F(x;ΦEr);Ω1r)];Ω2r)
对于失真源编码器,其NN参数集为Φc=\boldsymbol{\Phi}^{c}=Φc= {ΦEc,ΦDc,Ω1c,Ω2c}\left\{\Phi_{E}^{c}, \Phi_{D}^{c}, \Omega_{1}^{c}, \Omega_{2}^{c}\right\}{ΦEc,ΦDc,Ω1c,Ω2c},我们有
θ‾c=L2([L1(F(x;ΦEc);Ω1c)];Ω2c) \overline{\boldsymbol{\theta}}^{c}=L_{2}\left(\left[L_{1}\left(F\left(\boldsymbol{x} ; \Phi_{E}^{c}\right) ; \Omega_{1}^{c}\right)\right] ; \Omega_{2}^{c}\right) θc=L2([L1(F(x;ΦEc);Ω1c)];Ω2c)
其中θ‾c={θˉijcc}\overline{\boldsymbol{\theta}}^{c}=\left\{\bar{\theta}_{i j c}^{c}\right\}θc={θˉijcc}。然后,缩放参数β‾={βˉijc}\overline{\boldsymbol{\beta}}=\left\{\bar{\beta}_{i j c}\right\}β={βˉijc}可计算为
βˉijc=θˉijccθˉijcc \bar{\beta}_{i j c}=\frac{\bar{\theta}_{i j c}^{c}}{\bar{\theta}_{i j c}^{c}} βˉijc=θˉijccθˉijcc
通过将估计的θ‾r\overline{\boldsymbol{\theta}}^{r}θr和β‾\overline{\boldsymbol{\beta}}β以及过滤集P\mathbb{P}P代入(27),得到失真图像样本的GVIF。
V. GVIF在自适应混合Gen-SemCom中的应用
在本节中,我们介绍了一种应用所提出的GVIF度量的方法,这有助于使Gen-SemCom系统适应信道状态。我们基于所提出的GVIF度量公式化问题,并提出一种有效的算法来优化系统性能。
A. 问题公式化
我们的目的是根据信道状态hhh和噪声方差σ2\sigma^{2}σ2的变化调整混合Gen-SemCom系统的输出图像质量。为此,我们优化集合P\mathbb{P}P和缩放变量βˉ\bar{\beta}βˉ以最大化给定接收SNR,∣h∣2σ2\frac{|h|^{2}}{\sigma^{2}}σ2∣h∣2下的预期GVIF。由于集合P\mathbb{P}P和缩放变量βˉ\bar{\beta}βˉ分别与(17)中的阈值α\alphaα和VAE参数Φ\boldsymbol{\Phi}Φ相关,优化问题可以公式化为:
maxα,ΦEx{V(Φ,α;x)} s.t. R(Φ,α)Blog2(1+∣h∣2/σ2)≤TmaxΦ∈{Φ1,Φ2,⋯ ,ΦP}D(Φ)≤D00≤α≤αth \begin{aligned} \max _{\alpha, \boldsymbol{\Phi}} & \mathbb{E}_{x}\{V(\boldsymbol{\Phi}, \alpha ; \boldsymbol{x})\} \\ \text { s.t. } & \frac{\mathcal{R}(\boldsymbol{\Phi}, \alpha)}{B \log _{2}\left(1+|h|^{2} / \sigma^{2}\right)} \leq T_{\max } \\ & \boldsymbol{\Phi} \in\left\{\boldsymbol{\Phi}_{1}, \boldsymbol{\Phi}_{2}, \cdots, \boldsymbol{\Phi}_{P}\right\} \\ & \mathcal{D}(\boldsymbol{\Phi}) \leq D_{0} \\ & 0 \leq \alpha \leq \alpha_{t h} \end{aligned} α,Φmax s.t. Ex{V(Φ,α;x)}Blog2(1+∣h∣2/σ2)R(Φ,α)≤TmaxΦ∈{Φ1,Φ2,⋯,ΦP}D(Φ)≤D00≤α≤αth
其中Tmax>0T_{\max }>0Tmax>0是最大传输延迟,αth\alpha_{t h}αth代表保护重要语义信息的最大阈值,(31a)表示平均延迟约束,其中R(Φ,α)=Ex{B(Φ,α;x)}\mathcal{R}(\boldsymbol{\Phi}, \alpha)=\mathbb{E}_{x}\{B(\boldsymbol{\Phi}, \alpha ; \boldsymbol{x})\}R(Φ,α)=Ex{B(Φ,α;x)}是在(6)中定义的源速率。在约束(31b)中,NN参数Φ\boldsymbol{\Phi}Φ从PPP个具有不同率失真对的预训练参数集中选择。约束(31c)表示关键区域可容忍的最大失真。
然而,问题(31)很难解决。首先,预期的GVIF,Ex{V(Φ,α;x)}\mathbb{E}_{x}\{V(\boldsymbol{\Phi}, \alpha ; \boldsymbol{x})\}Ex{V(Φ,α;x)},和源速率,R(Φ,α)\mathcal{R}(\boldsymbol{\Phi}, \alpha)R(Φ,α),由于NN的不可解性而没有闭式表达式。其次,这两个函数由于与阈值α\alphaα相关的集合P\mathbb{P}P而不平滑。第三,GVIF与过滤阈值α\alphaα和NN参数Φ\boldsymbol{\Phi}Φ耦合在一起,导致非凸优化问题。
B. 解决算法
为了解决问题(31),我们提出了一个两步算法,根据接收SNR,∣h∣2σ2\frac{|h|^{2}}{\sigma^{2}}σ2∣h∣2自适应优化(α,Φ)(\alpha, \boldsymbol{\Phi})(α,Φ)。
- 固定Φ\boldsymbol{\Phi}Φ,优化α\alphaα:设C=Blog2(1+∣h∣2/σ2)C=B \log _{2}\left(1+|h|^{2} / \sigma^{2}\right)C=Blog2(1+∣h∣2/σ2)。当NN参数Φ\boldsymbol{\Phi}Φ固定时,问题(31)变为
maxαEx{V(Φ,α;x)} s.t. Ex{B(Φ,α;x)}C≤Tmax0≤α≤αth \begin{aligned} \max _{\alpha} & \mathbb{E}_{x}\{V(\boldsymbol{\Phi}, \alpha ; \boldsymbol{x})\} \\ \text { s.t. } & \frac{\mathbb{E}_{x}\{B(\boldsymbol{\Phi}, \alpha ; \boldsymbol{x})\}}{C} \leq T_{\max } \\ & 0 \leq \alpha \leq \alpha_{t h} \end{aligned} αmax s.t. Ex{V(Φ,α;x)}CEx{B(Φ,α;x)}≤Tmax0≤α≤αth
通过引入二次惩罚函数[45],我们将问题(32)的新目标函数定义如下,
KaTeX parse error: Unexpected end of input in a macro argument, expected '}' at end of input: … \end{aligned}
其中p>0p>0p>0是惩罚参数。然后,问题(32)可以近似为
minαL(α) s.t. 0≤α≤αth \begin{aligned} \min _{\alpha} & \mathcal{L}(\alpha) \\ \text { s.t. } & 0 \leq \alpha \leq \alpha_{t h} \end{aligned} αmin s.t. L(α)0≤α≤αth
当惩罚参数ppp足够大时,问题(34)的最优解近似于问题(32)的最优解。根据我们的数值实验,观察到函数Ex{V(Φ,α;x)}\mathbb{E}_{x}\{V(\boldsymbol{\Phi}, \alpha ; \boldsymbol{x})\}Ex{V(Φ,α;x)}和Ex{B(Φ,α;x)}\mathbb{E}_{x}\{B(\boldsymbol{\Phi}, \alpha ; \boldsymbol{x})\}Ex{B(Φ,α;x)}相对于α\alphaα大致平滑,只要网格尺寸,即WqW_{q}Wq和HqH_{q}Hq足够大。因此,目标函数L(α)\mathcal{L}(\alpha)L(α)被认为相对于α\alphaα连续可微。
然而,目标函数L(α)\mathcal{L}(\alpha)L(α)及其梯度仍然难以处理。为了解决这个挑战,应用零阶优化方法[46]仅通过函数评估来估计梯度。然后,可以通过应用随机梯度下降法来优化α\alphaα。在每次迭代ttt中,梯度∇L(αt)\nabla \mathcal{L}\left(\alpha_{t}\right)∇L(αt)给出为
∇L(αt)=−∇G(αt)+2pmax(0,K(αt))∇K(αt) \nabla \mathcal{L}\left(\alpha_{t}\right)=-\nabla \mathcal{G}\left(\alpha_{t}\right)+2 p \max \left(0, \mathcal{K}\left(\alpha_{t}\right)\right) \nabla \mathcal{K}\left(\alpha_{t}\right) ∇L(αt)=−∇G(αt)+2pmax(0,K(αt))∇K(αt)
(35)中的难以处理的梯度∇G(αt)\nabla \mathcal{G}\left(\alpha_{t}\right)∇G(αt)和∇K(αt)\nabla \mathcal{K}\left(\alpha_{t}\right)∇K(αt)可以通过以下方式估计:
∇G(αt)≈1∣Γt∣∑i=1∣Γt∣1ν∣V(Φ,αt+νm;xi)−V(Φ,αt;xi)∣m\nabla \mathcal{G}\left(\alpha_{t}\right) \approx \frac{1}{\left|\Gamma_{t}\right|} \sum_{i=1}^{\left|\Gamma_{t}\right|} \frac{1}{\nu}\left|V\left(\boldsymbol{\Phi}, \alpha_{t}+\nu m ; \boldsymbol{x}_{i}\right)-V\left(\boldsymbol{\Phi}, \alpha_{t} ; \boldsymbol{x}_{i}\right)\right| m∇G(αt)≈∣Γt∣1∑i=1∣Γt∣ν1∣V(Φ,αt+νm;xi)−V(Φ,αt;xi)∣m,
∇K(αt)≈1∣Γt∣∑i=1∣Γt∣1ν∣B(Φ,αt+νm;xi)−B(Φ,αt;xi)∣m\nabla \mathcal{K}\left(\alpha_{t}\right) \approx \frac{1}{\left|\Gamma_{t}\right|} \sum_{i=1}^{\left|\Gamma_{t}\right|} \frac{1}{\nu}\left|B\left(\boldsymbol{\Phi}, \alpha_{t}+\nu m ; \boldsymbol{x}_{i}\right)-B\left(\boldsymbol{\Phi}, \alpha_{t} ; \boldsymbol{x}_{i}\right)\right| m∇K(αt)≈∣Γt∣1∑i=1∣Γt∣ν1∣B(Φ,αt+νm;xi)−B(Φ,αt;xi)∣m,
其中Γt\Gamma_{t}Γt表示迭代ttt中的小批量图像集合,ν>0\nu>0ν>0是一个平滑参数,mmm是从中心为零半径为1的均匀分布生成的。阈值αt+1\alpha_{t+1}αt+1通过以下公式更新:
αt+1=αt−η∇L(αt) \alpha_{t+1}=\alpha_{t}-\eta \nabla \mathcal{L}\left(\alpha_{t}\right) αt+1=αt−η∇L(αt)
其中η>0\eta>0η>0是步长。为了满足(34)中的约束,更新后的αt+1\alpha_{t+1}αt+1将基于最近的欧几里得距离投影到集合0≤0 \leq0≤ α≤αth\alpha \leq \alpha_{t h}α≤αth。最后,我们继续随机梯度下降算法直到变量{αt}\left\{\alpha_{t}\right\}{αt}收敛。
2) 找到最佳Φ\boldsymbol{\Phi}Φ:为了便于分析,我们假设基于VAE的源编码的源失真遵循D(Φ1)≤D(Φ2)≤⋯≤D(ΦP)\mathcal{D}\left(\boldsymbol{\Phi}_{1}\right) \leq \mathcal{D}\left(\boldsymbol{\Phi}_{2}\right) \leq \cdots \leq \mathcal{D}\left(\boldsymbol{\Phi}_{P}\right)D(Φ1)≤D(Φ2)≤⋯≤D(ΦP)。
然后,容易找到一个NN参数Φg,g≥1\boldsymbol{\Phi}_{g}, g \geq 1Φg,g≥1,满足D(Φg)≤D0\mathcal{D}\left(\boldsymbol{\Phi}_{g}\right) \leq D_{0}D(Φg)≤D0。这将Φ\boldsymbol{\Phi}Φ的可行集减少到集合G={Φ1,Φ2,⋯ ,Φg}\mathbb{G}=\left\{\boldsymbol{\Phi}_{1}, \boldsymbol{\Phi}_{2}, \cdots, \boldsymbol{\Phi}_{g}\right\}G={Φ1,Φ2,⋯,Φg}。通过步骤1),我们可以获得NN参数Φi,i=1,2,⋯ ,g\boldsymbol{\Phi}_{i}, i=1,2, \cdots, gΦi,i=1,2,⋯,g的解α∗(Φi)\alpha^{*}\left(\boldsymbol{\Phi}_{i}\right)α∗(Φi)。α∗(Φi)\alpha^{*}\left(\boldsymbol{\Phi}_{i}\right)α∗(Φi)和Φi\boldsymbol{\Phi}_{i}Φi的预期GVIF,记为Ex{V(Φi,α∗(Φ);x)}\mathbb{E}_{\boldsymbol{x}}\left\{V\left(\boldsymbol{\Phi}_{i}, \boldsymbol{\alpha}^{*}(\boldsymbol{\Phi}) ; \boldsymbol{x}\right)\right\}Ex{V(Φi,α∗(Φ);x)},可以通过对图像数据集上的GVIF取平均值轻松估计。最后,我们找到具有最大预期GVIF的最佳NN参数Φ∗\boldsymbol{\Phi}^{*}Φ∗,即,
Φ∗=argmaxΦi∈GEx{V(Φ,α∗(Φ);x)} \boldsymbol{\Phi}^{*}=\arg \max _{\boldsymbol{\Phi}_{i} \in \mathbb{G}} \mathbb{E}_{\boldsymbol{x}}\left\{V\left(\boldsymbol{\Phi}, \boldsymbol{\alpha}^{*}(\boldsymbol{\Phi}) ; \boldsymbol{x}\right)\right\} Φ∗=argΦi∈GmaxEx{V(Φ,α∗(Φ);x)}
基于上述解决方案,针对信道自适应混合Gen-SemCom的结果算法总结在算法1中。每次迭代步骤1)的计算复杂度计算为O(∣Γt∣gWgHgCg)O\left(\left|\Gamma_{t}\right| g W_{g} H_{g} C_{g}\right)O(∣Γt∣gWgHgCg)。
算法1 源编码和语义过滤的联合优化。
输入:NN参数集{Φ1,Φ2,⋯ ,ΦP}\left\{\boldsymbol{\Phi}_{1}, \boldsymbol{\Phi}_{2}, \cdots, \boldsymbol{\Phi}_{P}\right\}{Φ1,Φ2,⋯,ΦP},带宽BBB,信道SNR∂i2∂τ\frac{\partial i^{2}}{\partial \tau}∂τ∂i2,以及参数{γ,ν,η,Tmax,D0}\left\{\gamma, \nu, \eta, T_{\max }, D_{0}\right\}{γ,ν,η,Tmax,D0}。
输出:Φ∗\boldsymbol{\Phi}^{*}Φ∗和α∗\alpha^{*}α∗。
1: 找到可行集G={Φ1,Φ2,⋯ ,Φg}\mathbb{G}=\left\{\boldsymbol{\Phi}_{1}, \boldsymbol{\Phi}_{2}, \cdots, \boldsymbol{\Phi}_{g}\right\}G={Φ1,Φ2,⋯,Φg},满足D(Φg)≤D0\mathcal{D}\left(\boldsymbol{\Phi}_{g}\right) \leq D_{0}D(Φg)≤D0。
2: repeat
3: 初始化α0=0.5\alpha_{0}=0.5α0=0.5并固定NN参数Φ∈G\boldsymbol{\Phi} \in \mathbb{G}Φ∈G。
4: 根据(35)-(37)计算梯度∇L(αt)\nabla \mathcal{L}\left(\alpha_{t}\right)∇L(αt)。
5: 根据(38)更新变量αt+1\alpha_{t+1}αt+1。
6: until ∥αt+1−αt∥<ξ\left\|\alpha_{t+1}-\alpha_{t}\right\|<\xi∥αt+1−αt∥<ξ并输出α∗(Φ)\alpha^{*}(\boldsymbol{\Phi})α∗(Φ);
7: 对于每个NN参数Φ∈G\boldsymbol{\Phi} \in \mathbb{G}Φ∈G,优化α∗(Φ)\alpha^{*}(\boldsymbol{\Phi})α∗(Φ)。
8: 估计预期的GVIFs{Ex{V(Φ,α∗(Φ);x)}}\left\{\mathbb{E}_{\boldsymbol{x}}\left\{V\left(\boldsymbol{\Phi}, \boldsymbol{\alpha}^{*}(\boldsymbol{\Phi}) ; \boldsymbol{x}\right)\right\}\right\}{Ex{V(Φ,α∗(Φ);x)}}。
9: 根据(39)找到最优的(Φ∗,α∗(Φ))\left(\boldsymbol{\Phi}^{*}, \alpha^{*}(\boldsymbol{\Phi})\right)(Φ∗,α∗(Φ))。
基于上述解决方案,信道自适应混合Gen-SemCom的最终算法总结在算法1中。每次迭代步骤1)的计算复杂度计算为O(∣Γt∣gWgHgCg)O\left(\left|\Gamma_{t}\right| g W_{g} H_{g} C_{g}\right)O(∣Γt∣gWgHgCg)。
算法1 源编码和语义过滤的联合优化。
输入:NN参数集{Φ1,Φ2,⋯ ,ΦP}\left\{\boldsymbol{\Phi}_{1}, \boldsymbol{\Phi}_{2}, \cdots, \boldsymbol{\Phi}_{P}\right\}{Φ1,Φ2,⋯,ΦP},带宽BBB,信道SNR∂i2∂τ\frac{\partial i^{2}}{\partial \tau}∂τ∂i2,以及参数{γ,ν,η,Tmax,D0}\left\{\gamma, \nu, \eta, T_{\max }, D_{0}\right\}{γ,ν,η,Tmax,D0}。
输出:Φ∗\boldsymbol{\Phi}^{*}Φ∗和α∗\alpha^{*}α∗。
1: 找到可行集G={Φ1,Φ2,⋯ ,Φg}\mathbb{G}=\left\{\boldsymbol{\Phi}_{1}, \boldsymbol{\Phi}_{2}, \cdots, \boldsymbol{\Phi}_{g}\right\}G={Φ1,Φ2,⋯,Φg},满足D(Φg)≤D0\mathcal{D}\left(\boldsymbol{\Phi}_{g}\right) \leq D_{0}D(Φg)≤D0。
2: repeat
3: 初始化α0=0.5\alpha_{0}=0.5α0=0.5并固定NN参数Φ∈G\boldsymbol{\Phi} \in \mathbb{G}Φ∈G。
4: 根据(35)-(37)计算梯度∇L(αt)\nabla \mathcal{L}\left(\alpha_{t}\right)∇L(αt)。
5: 根据(38)更新变量αt+1\alpha_{t+1}αt+1。
6: until ∥αt+1−αt∥<ξ\left\|\alpha_{t+1}-\alpha_{t}\right\|<\xi∥αt+1−αt∥<ξ并输出α∗(Φ)\alpha^{*}(\boldsymbol{\Phi})α∗(Φ);
7: 对于每个NN参数Φ∈G\boldsymbol{\Phi} \in \mathbb{G}Φ∈G,优化α∗(Φ)\alpha^{*}(\boldsymbol{\Phi})α∗(Φ)。
8: 估计预期的GVIFs{Ex{V(Φ,α∗(Φ);x)}}\left\{\mathbb{E}_{\boldsymbol{x}}\left\{V\left(\boldsymbol{\Phi}, \boldsymbol{\alpha}^{*}(\boldsymbol{\Phi}) ; \boldsymbol{x}\right)\right\}\right\}{Ex{V(Φ,α∗(Φ);x)}}。
9: 根据(39)找到最优的(Φ∗,α∗(Φ))\left(\boldsymbol{\Phi}^{*}, \alpha^{*}(\boldsymbol{\Phi})\right)(Φ∗,α∗(Φ))。
VI. 实验结果
A. 实验设置
- 模型架构:基于VAE的源编码器遵循超先验模型的架构 [10]。我们采用ResNet-50模型 [47] 作为CAM的空间重要性建模的骨干模型。我们直接采用训练良好的扩散模型 [26], [40],使用31个去噪步骤生成图像,没有任何模型微调。
-
- 真实数据集:我们在著名的ImageNet 2012数据集 [48] 上测试混合Gen-SemCom系统,该数据集包含50000个图像样本用于验证。所有测试图像都被调整为 512×512512 \times 512512×512 像素。用于训练基于VAE的源编码器的数据集从Open Images Dataset [49] 的训练数据集中采样了100,000张图像。
-
- 参数设置:根据[34]中的经验设置,HVS噪声的方差设为γ2=0.1\gamma^{2}=0.1γ2=0.1。最大过滤阈值设为αth=0.8\alpha_{t h}=0.8αth=0.8。源编码器的查找表由19个模型组成,平均PSNR范围从27 dB到40 dB。我们利用PSNR为40 dB的源编码器作为参考模型来提取参考特征。信道带宽设为1 MHz。
-
- 基准方案:我们将经典的JPEG2000 [50] 和无过滤的基于VAE的源编码作为基准方案进行比较。前者是现代数字传输系统中广泛使用的源编码方案,后者相比传统方案(如JPEG和BPG [51])显示出优越的压缩效率。为了更好地比较生成性能,我们还展示了仅从文本提示生成的图像,称为“文本到图像生成”,但其传输延迟太小可以忽略不计。
-
- 评估指标:所提出的GVIF度量用于定量跟踪GenSemCom系统的性能。然而,它不能用于其他经典方案,如JPEG2000。因此,我们仍需要其他指标作为评估指标来展示性能差异。这里,我们考虑两个已知的指标,即掩码PSNR和FID得分 [18]。掩码PSNR描述感兴趣图像区域的像素级距离,计算如下
mask PSNR =10log10(2552∑Mijc∥M⊙(x−x^)∥2) \text { mask PSNR }=10 \log _{10}\left(\frac{255^{2}}{\sum M_{i j c}\left\|\boldsymbol{M} \odot(\boldsymbol{x}-\hat{\boldsymbol{x}})\right\|^{2}}\right) mask PSNR =10log10(∑Mijc∥M⊙(x−x^)∥22552)
- 评估指标:所提出的GVIF度量用于定量跟踪GenSemCom系统的性能。然而,它不能用于其他经典方案,如JPEG2000。因此,我们仍需要其他指标作为评估指标来展示性能差异。这里,我们考虑两个已知的指标,即掩码PSNR和FID得分 [18]。掩码PSNR描述感兴趣图像区域的像素级距离,计算如下
其中M∈{0,1}W×H×3\boldsymbol{M} \in\{0,1\}^{W \times H \times 3}M∈{0,1}W×H×3是一个二值图像,值为1表示感兴趣的区域,Mijc\boldsymbol{M}_{i j c}Mijc是其(i,j,c)(i, j, c)(i,j,c) th元素。二值图像M\boldsymbol{M}M可以通过上采样关于α\alphaα的索引集P\mathbb{P}P来构建,这在第三节-C中有所描述。FID得分用于测量生成图像的分布与原始图像相比的情况。FID得分越低,恢复的图像越接近原始图像。
B. GVIF度量的性质
在本小节中,我们研究了所提出的GVIF度量的性质。通过改变基于VAE的源编码器的源速率,我们描绘了不同阈值α\alphaα下平均GVIF随掩码PSNR变化的函数,如图9所示。掩码PSNR与基于VAE方案压缩的关键特征的源速率有关。阈值α\alphaα决定了传输到接收端的关键特征数量。这两个值都对所提出的GVIF有贡献,不仅衡量了传输图像内容的比例,还量化了它们因压缩过程而失真的质量。这个结果可以在图9中观察到,揭示了GVIF度量是掩码PSNR和项1−α1-\alpha1−α(对应于传输数量)的单调递增函数。例如,当掩码PSNR为32 dB时,当α\alphaα从0.7减小到0.3时,平均GVIF增加了约0.15。一个有趣的现象是,当α\alphaα接近1时,无论我们使用多么先进的源编码器,GVIF仍然非常低。这一观察结果与理解一致,即视觉保真度主要由原始内容决定。即使生成的像素传达了与原始像素相同的语义意义,它们在视觉水平上可能会有很大差异。最后,我们得出结论,GVIF度量全面评估了生成图像与原始图像之间的内容差异,超越了简单的像素级比较。
为了更好地说明语义过滤过程对SemCom系统的影响,我们在图8中展示了一些图像示例。可以观察到,α\alphaα越大,生成的图像与原始图像越不同。例如,如图8©所示,提示为“几个粉红色、橙色和桃红色的气球躺在靠近木门的石路上。”尽管生成的图像捕捉到了原始图像的准确语义信息,但它们的视觉信息正在减少。这种质量损失无法通过常用的PSNR度量来衡量,因为它仅关注像素级距离。然而,我们提出的GVIF度量可以定量描述信息损失。此外,我们观察到语义重要性建模能够准确描述与图像语义信息相关的空间重要性。例如,在图8(a)中,α=0.3\alpha=0.3α=0.3的区域几乎覆盖了所有与黑松鸡相关的特征。随着阈值α\alphaα的增加,信息保真度降低,但传输特征的数量也减少。这种所提出系统的灵活性促进了根据信道状态在GVIF和传输开销之间进行权衡。
C. 系统性能
在本小节中,我们研究了使用所提方案的混合Gen-SemCom系统与其他基准方案相比的性能。如图9(a)所示,我们绘制了平均GVIF度量随信道SNR变化的函数。为了公平比较,我们将感兴趣区域的最小掩码PSNR设为30 dB。最大传输延迟设为20 ms。从图9(a)可以看出,所提方案的GVIF随着信道SNR的增加表现出正相关性。类似的现象也可以在图9(b)中观察到,其中传输延迟的增加导致GVIF度量的上升。一个有趣的观察是,当信道SNR低于10 dB时,无过滤的基于VAE的源编码方案在GVIF上表现出悬崖效应现象。解释这一现象的原因是,较差的信道条件无法支持高质量完整图像的传输。然而,我们提出的带有过滤过程的方案提供了调节传输特征数量的灵活性,使GVIF度量对信道SNR更加稳健。例如,当信道SNR降至-2 dB时,过滤阈值α\alphaα增加到0.74以确保与语义信息相关的关键特征的成功传输。然而,观察到在高SNR区域,所提方案等同于无过滤的基于VAE的源编码。
为了更好地说明所提方案的性能增益,我们在图10中展示了一些图像示例。关键像素的平均传输延迟设为30 ms。图10中的图像提示成本约为0.3 ms的传输延迟,可以忽略不计。虽然“文本到图像生成”方案可以在最小传输延迟的情况下恢复图像,但与真实情况相比,生成的图像几乎失去了所有的视觉保真度。另一方面,观察到我们的所提方案在掩码PSNR方面表现出优于经典JPEG2000和基于VAE的方案的优越性能。特别是在低SNR区域,我们的所提方案显示出保护关键语义信息免受失真的能力。当信道SNR为-1 dB时,与基于VAE的方案相比,“狐狸”图像的掩码PSNR提高了约12 dB。当信道SNR增加到6 dB时,我们的所提方案可以自适应地控制过滤阈值α\alphaα以最大化GVIF度量。如图10(b)所示,通过我们的所提方案生成的“鸟”图像非常接近真实情况。
D. FID得分与GVIF度量
在本小节中,我们研究了所提方案的FID得分,如图11所示。从图11(a)可以看出,文本到图像生成方案表现出最高的FID得分,而其传输延迟最低。基于VAE的源编码方案表现出最低的FID,但成本最高的传输延迟。我们提出的方案通过控制传输特征的数量,在FID得分和传输延迟之间提供了灵活性。一个有趣的现象是,当α\alphaα接近1时,FID得分增加得更快。例如,当α\alphaα从1减小到0.8时,FID得分减少了40。这一现象表明,只要传输少量关键特征,生成图像的分布就可以紧密近似原始图像的分布。接下来,我们研究了FID得分与GVIF度量之间的关系,如图11(b)所示。可以观察到,FID得分是GVIF的单调递减函数,突出了GVIF度量衡量图像保真度的能力。
VII. 结论性意见
在本文中,我们提出了一种用于混合Gen-SemCom系统的CIE框架,其中仅编码和传输文本提示和关键特征元素以减少通信开销。为了控制CIE过程,我们提出了一种新颖的语义过滤方法,该方法基于语义重要性修剪非关键特征。在接收端,提示和关键特征结合使用基于扩散的模型生成高质量图像。此外,我们提出了GVIF度量来量化生成图像的视觉互信息,与人类视觉感知一致。GVIF度量实现了根据信道状态对编码和语义过滤进行联合优化,将传统率失真折衷的焦点转移到语义感知的视觉质量上。实验结果验证了GVIF度量对感知质量的敏感性,并展示了优化系统在基准方案上的优越性能,实现了更高的掩码PSNR和更低的FID得分。未来的研究可以将混合Gen-SemCom框架扩展到视频应用,并探索其与多种提示模式(如布局感知机制)的集成,以提高生成视觉内容的保真度。
附录A
(23) 和 (24) 中统计模型的验证
在本附录中,我们根据扩散模型的特性验证(23) 和 (24) 中介绍的统计模型。理论上,扩散模型的反向过程逐渐将样本从高斯分布N(0,I)\mathcal{N}(0, \boldsymbol{I})N(0,I)转换为逼近真实条件分布p(x∣q,m⊙x^)p(\boldsymbol{x} \mid \boldsymbol{q}, \boldsymbol{\boldsymbol { m }} \odot \hat{\boldsymbol{x}})p(x∣q,m⊙x^)的样本。条件将锚定关键像素并生成其余像素。在扩散模型中,去噪步骤中独立添加高斯噪声。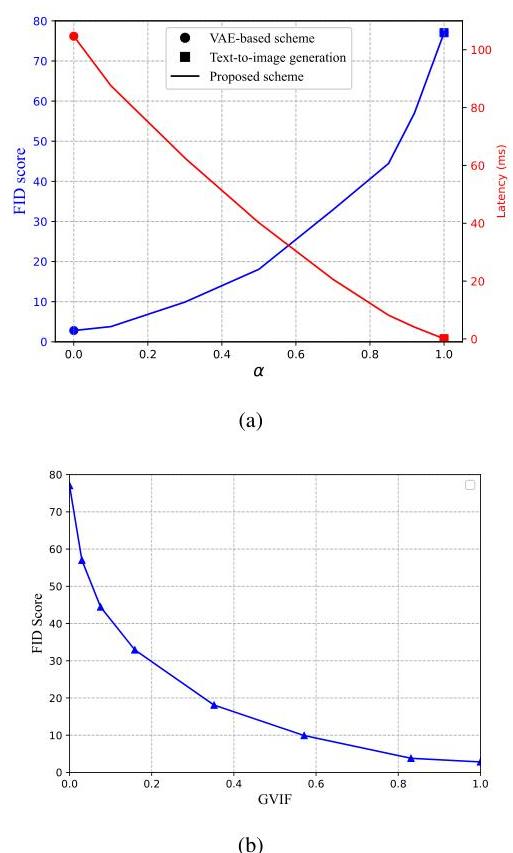
图11:所提SemCom系统的FID得分。接收SNR设置为10 dB。
因此,生成图像x~\tilde{\boldsymbol{x}}x~和真实图像x\boldsymbol{x}x表示从相同条件分布p(x∣q,ηηP)p\left(\boldsymbol{x} \mid \boldsymbol{q}, \boldsymbol{\eta} \boldsymbol{\eta}_{\mathrm{P}}\right)p(x∣q,ηηP)中独立抽取的样本。由于图像可以使用VAE编码器表示,生成图像x~\tilde{\boldsymbol{x}}x~可以表示为特征yg\boldsymbol{y}^{g}yg,即x~=F−1(⌈yg⌋;ΦD)\tilde{\boldsymbol{x}}=F^{-1}\left(\left\lceil\boldsymbol{y}^{g}\right\rfloor ; \Phi_{D}\right)x~=F−1(⌈yg⌋;ΦD)。因此,生成特征yg\boldsymbol{y}^{g}yg和真实特征y\boldsymbol{y}y可以视为从相同分布p(y)p(\boldsymbol{y})p(y)中独立抽取的样本。由于集合P\mathbb{P}P中的特征元素保持不变,(23)和(24)中的统计模型可以得到证明。
为了更好地验证统计模型,我们进行了一些实验来计算生成特征y~\tilde{\boldsymbol{y}}y~和真实特征y\boldsymbol{y}y之间的相关性,如图12所示。我们从ImageNet数据集中随机选择了2000个图像样本,并通过y=F(x;ΦD)\boldsymbol{y}=F\left(\boldsymbol{x} ; \Phi_{D}\right)y=F(x;ΦD)计算特征样本{y}\{\boldsymbol{y}\}{y}。每个图像都被送入所提出的框架中,使用图12(a)中显示的二进制掩码生成80个图像x~\tilde{\boldsymbol{x}}x~,通过采样高斯噪声实现。生成特征通过y~=F(x~;ΦD)\tilde{\boldsymbol{y}}=F\left(\tilde{\boldsymbol{x}} ; \Phi_{D}\right)y~=F(x~;ΦD)获得。然后,我们计算生成特征样本{y~}\{\tilde{\boldsymbol{y}}\}{y~}和真实特征样本{y}\{\boldsymbol{y}\}{y}之间的皮尔逊相关系数。相关系数在特征图上取平均值,如图12(b)-(d)所示。可以观察到,过滤集P\mathbb{P}P内的特征元素彼此之间具有高相关性,但在集合外则表现为不相关。这一现象验证了(23)和(24)中统计模型的假设。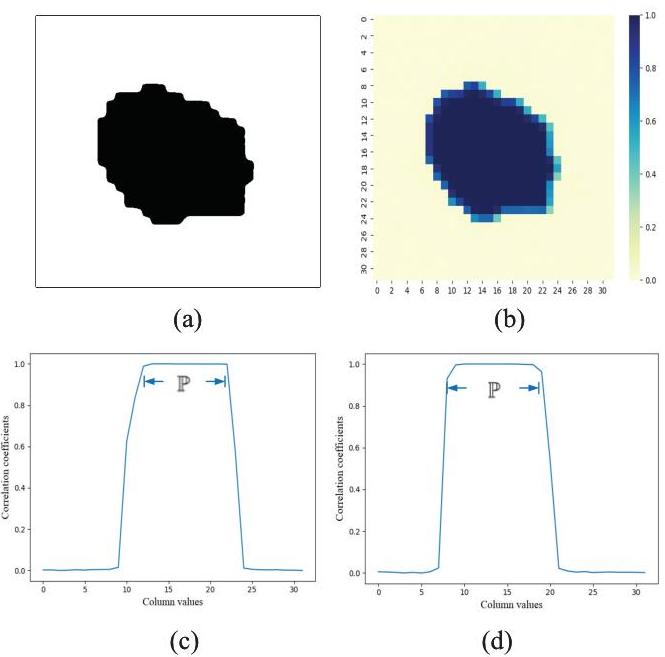
图12:特征图上的皮尔逊相关系数说明。(a) 二进制掩码;(b) 相关图;© 第22行的特征相关性;(d) 第12行的特征相关性。
附录B
命题4.1的证明
根据公式(26)中的HVS模型,条件互信息I(gr;yr∣θr=θ‾r)\boldsymbol{I}\left(\boldsymbol{g}^{r} ; \boldsymbol{y}^{r} \mid \boldsymbol{\theta}^{r}=\overline{\boldsymbol{\theta}}^{r}\right)I(gr;yr∣θr=θr)计算如下
I(gr;yr∣θr=θ‾r)=(a)∑(i,j,c)∈UI(gijcr;yijcr∣θr=θ‾r)=12∑(i,j,c)∈Ulog2(1+(θ~ijcr)2γ2) \begin{aligned} \boldsymbol{I}\left(\boldsymbol{g}^{r} ; \boldsymbol{y}^{r} \mid \boldsymbol{\theta}^{r}=\overline{\boldsymbol{\theta}}^{r}\right) & \stackrel{(a)}{=} \sum_{(i, j, c) \in \mathbb{U}} \boldsymbol{I}\left(g_{i j c}^{r} ; y_{i j c}^{r} \mid \boldsymbol{\theta}^{r}=\overline{\boldsymbol{\theta}}^{r}\right) \\ & =\frac{1}{2} \sum_{(i, j, c) \in \mathbb{U}} \log _{2}\left(1+\frac{\left(\tilde{\theta}_{i j c}^{r}\right)^{2}}{\gamma^{2}}\right) \end{aligned} I(gr;yr∣θr=θr)=(a)(i,j,c)∈U∑I(gijcr;yijcr∣θr=θr)=21(i,j,c)∈U∑log2 1+γ2(θ~ijcr)2
其中等式(a)来自于参考模型(19),即给定θ‾r\overline{\boldsymbol{\theta}}^{r}θr时,{gijcr}\left\{g_{i j c}^{r}\right\}{gijcr}相互独立,并且与视觉噪声{n~ijc}\left\{\tilde{n}_{i j c}\right\}{n~ijc}独立。
根据(21)-(24)中的失真模型和(25)中的HVS模型,我们有
gijcd={βijcyijcr+nijc, if (i,j,c)∈Pyijcd+nijc, otherwise g_{i j c}^{d}= \begin{cases}\beta_{i j c} y_{i j c}^{r}+n_{i j c}, & \text { if }(i, j, c) \in \mathbb{P} \\ y_{i j c}^{d}+n_{i j c}, & \text { otherwise }\end{cases} gijcd={βijcyijcr+nijc,yijcd+nijc, if (i,j,c)∈P otherwise
然后,条件互信息I(gd;yr∣θr=θ‾r,βr=β‾)\boldsymbol{I}\left(\boldsymbol{g}^{d} ; \boldsymbol{y}^{r} \mid \boldsymbol{\theta}^{r}=\overline{\boldsymbol{\theta}}^{r}, \boldsymbol{\beta}^{r}=\overline{\boldsymbol{\beta}}\right)I(gd;yr∣θr=θr,βr=β)计算如下:
KaTeX parse error: Expected '\right', got '&' at position 107: …ol{\theta}^{r} &̲ =\overline{\bo…
其中等式(a)来自以下事实:给定θ^r\hat{\boldsymbol{\theta}}^{r}θ^r时,{yijcr}\left\{y_{i j c}^{r}\right\}{yijcr}和{nijc}\left\{n_{i j c}\right\}{nijc}彼此独立,等式(b)成立是因为对于所有(i,j,c)∉P(i, j, c) \notin \mathbb{P}(i,j,c)∈/P的情况,yijk0y_{i j k}^{0}yijk0与yijkry_{i j k}^{r}yijkr独立,导致I(yijkr;yijkr∣θ^r=θ^r,β=β^)=0I\left(y_{i j k}^{r} ; y_{i j k}^{r} \mid \hat{\boldsymbol{\theta}}^{r}=\hat{\boldsymbol{\theta}}^{r}, \beta=\hat{\boldsymbol{\beta}}\right)=0I(yijkr;yijkr∣θ^r=θ^r,β=β^)=0,对于所有(i,j,c)∉P(i, j, c) \notin \mathbb{P}(i,j,c)∈/P。通过将(43)除以(41),命题4.1得以证明。
参考文献
[1] D. Gündüz, Z. Qin, I. E. Agaerti, H. S. Dhillon, Z. Yang, A. Yener, K. K. Wong, and C.-B. Chae, “Beyond transmitting bits: Context, semantics, and task-oriented communications,” IEEE J. Sel. Areas Commun., vol. 41, no. 1, pp. 5-41, Jan. 2022.
[2] P. Zhang, W. Xu, H. Gao, K. Niu, X. Xu, X. Qin, C. Yuan, Z. Qin, H. Zhao, J. Wei et al., “Toward wisdom-evolutionary and primitiveconcise 6G: A new paradigm of semantic communication networks,” Eng., vol. 8, pp. 60-73, Jan. 2022.
[3] Y. Sun, H. Chen, X. Xu, P. Zhang, and S. Cui, “Semantic knowledge base-enabled zero-shot multi-level feature transmission optimization,” IEEE Trans. Wired. Commun., vol. 23, no. 5, pp. 4904-4917, May 2024.
[4] W. Saad, M. Bennis, and M. Chen, “A vision of 6G wireless systems: Applications, trends, technologies, and open research problems,” IEEE Netw., vol. 34, no. 3, pp. 134-142, June 2019.
[5] G. Zhu, D. Liu, Y. Du, C. You, J. Zhang, and K. Huang, “Toward an intelligent edge: Wireless communication meets machine learning,” IEEE Commun. Mag., vol. 58, no. 1, pp. 19-25, Jan. 2020.
[6] G. Qu, Q. Chen, X. Chen, K. Huang, and Y. Fang, “PartialLoading: User scheduling and bandwidth allocation for parameter-sharing edge inference,” arXiv preprint arXiv:2303.22982, 2025.
[7] Z. Lin, G. Qu, X. Chen, and K. Huang, “Split learning in 6g edge networks,” IEEE Wirel. Commun., vol. 31, no. 4, pp. 170-176, Aug. 2024.
[8] Z. Lin, G. Zhu, Y. Deng, X. Chen, Y. Gao, K. Huang, and Y. Fang, “Efficient parallel split learning over resource-constrained wireless edge networks,” IEEE Trans. Mob. Comput., vol. 23, no. 10, pp. 9224-9239, Oct. 2024.
[9] J. Ballé, V. Laparra, and E. P. Simoncelli, “End-to-end optimized image compression,” in Proc. Int. Conf. Learn. Repres. (ICLR), Toulon, France, Apr. 2017.
[10] J. Ballé, D. Minnen, S. Singh, S. J. Hwang, and N. Johnston, “Variational image compression with a scale hyperprior,” in Proc. Int. Conf. Learn. Repres. (ICLR), Vancouver, CA, May 2018.
[11] J. Liu, H. Sun, and J. Katto, “Learned image compression with mixed transformer-cnn architectures,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2023, pp. 14388-14397.
[12] J. Huang, D. Li, C. Huang, X. Qin, and W. Zhang, “Joint task and data-oriented semantic communications: A deep separate source-channel coding scheme,” IEEE Internet Things J., vol. 11, no. 2, pp. 2255-2272, Jan. 2024.
[13] J. Dai, S. Wang, K. Tan, Z. Si, X. Qin, K. Niu, and P. Zhang, “Nonlinear transform source-channel coding for semantic communications,” IEEE J. Sel. Areas Commun., vol. 40, no. 8, pp. 2300-2316, June 2022.
[14] D. Li, J. Huang, C. Huang, X. Qin, H. Zhang, and P. Zhang, “Fundamental limitation of semantic communications: Neural estimation for rate-distortion,” J. Commun. Inf. Net., vol. 8, no. 4, pp. 303-318, Dec. 2023.
[15] E. Bourtsoulatze, D. B. Kurka, and D. Gündüz, “Deep joint sourcechannel coding for wireless image transmission,” IEEE Trans. Cog. Commun. Net., vol. 5, no. 3, pp. 567-579, May 2019.
[16] J. Huang, K. Yuan, C. Huang, and K. Huang, “D 2{ }^{2}2-ISCC: Digital deep joint source-channel coding for semantic communications,” IEEE J. Sel. Areas Commun., vol. 43, no. 4, pp. 1246-1261, Apr. 2025.
[17] E. Erdemir, T.-Y. Tung, P. L. Dragotti, and D. Gündüz, “Generative joint source-channel coding for semantic image transmission,” IEEE J. Sel. Areas Commun., vol. 41, no. 8, pp. 2645-2657, June 2023.
[18] R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proceedings of the IEEE conference on computer vision and pattern recognition, June 2018, pp. 586-595.
[19] Y. Zhao, Y. Yue, S. Hou, B. Cheng, and Y. Huang, “Lamosc: Large language model-driven semantic communication system for visual transmission,” IEEE Trans. Cogn. Commun. Netw., vol. 10, no. 6, pp. 20052018, Dec. 2024.
[20] M. Zhang, H. Wu, G. Zhu, R. Jin, X. Chen, and D. Gündüz, “Semanticsguided diffusion for deep joint source-channel coding in wireless image transmission,” arXiv preprint arXiv:2301.01138, 2025.
[21] E. Grassucci, S. Barbarossa, and D. Comminiello, “Generative semantic communication: Diffusion models beyond bit recovery,” arXiv preprint arXiv:2306.04321, 2023.
[22] F. Jiang, S. Tu, L. Dong, C. Pan, J. Wang, and X. You, “Large generative model-assisted talking-face semantic communication system,” arXiv preprint arXiv:2411.03876, 2024.
[23] F. Jiang, S. Tu, L. Dong, K. Wang, K. Yang, and C. Pan, “M4sc: An milm-based multi-modal, multi-task and multi-user semantic communication system,” arXiv preprint arXiv:2302.16418, 2025.
[24] L. Dong, F. Jiang, Y. Peng, K. Wang, K. Yang, C. Pan, and R. Schober, “Lambo: Large AI model empowered edge intelligence,” IEEE Commun. Mag., vol. 63, no. 4, pp. 88-94, 2025.
[25] Z. Lin, Y. Zhang, Z. Chen, J. Fang, X. Chen, P. Vepakomma, W. Ni, J. Luo, and Y. Gao, “Haplifora: A heterogeneous split parameterefficient fine-tuning framework for large language models,” arXiv preprint arXiv:2305.02795, 2025.
[26] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., June 2022, pp. 10 68410-695.
[27] W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y. Hou, Y. Min, B. Zhang, J. Zhang, Z. Dong et al., “A survey of large language models,” arXiv preprint arXiv:2303.18223, 2023.
[28] M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,” Adv. Neural Inf. Process. Syst., vol. 30, pp. 6626-6637, Dec. 2017.
[29] M. Thorsager, I. Leyva-Mayorga, B. Soret, and P. Popovski, “Generative network layer for communication systems with artificial intelligence,” IEEE Networking Letters, pp. 82-86, Jan. 2024.
[30] H. Du, G. Liu, D. Niyato, J. Zhang, J. Kang, Z. Xiong, B. Ai, and D. I. Kim, “Generative ai-aided joint training-free secure semantic communications via multi-modal prompts,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP). IEEE, April 2024, pp. 12 896-12 900.
[31] S. Tariq, B. E. Arfeto, C. Zhang, and H. Shin, “Segment anything meets semantic communication,” arXiv preprint arXiv:2306.02094, 2023.
[32] A. Kirillov, E. Minnen, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo et al., “Segment anything,” in Proc. of the IEEE/CVF Int. Conf. on Computer Vision (ICCV), Oct. 2023, pp. 4015-4026.
[33] B. Zhou, A. Khosla, A. Lapudriza, A. Oliva, and A. Torralba, “Learning deep features for discriminative localization,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2016, pp. 2921-2929.
[34] H. R. Sheikh and A. C. Bovik, “Image information and visual quality,” IEEE Trans. on Image Processing, vol. 15, no. 2, pp. 430-444, 2006.
[35] OpenAI, “ChatGPT (Mar 14 version) [Large language model],” 2023, accessed: Mar. 14, 2023. [Online]. Available: https://chat.openai.com
[36] G. Qu, Q. Chen, W. Wei, Z. Lin, X. Chen, and K. Huang, “Mobile edge intelligence for large language models: A contemporary survey,” Early Access in IEEE Commun. Surv. Tutor., 2025.
[37] J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping languageimage pre-training with frozen image encoders and large language models,” in Proc. Int. Conf. Mach. Learn. (ICML), Honolulu, USA, 2023, pp. 19 730-19 742.
[38] I. H. Witten, R. M. Neal, and J. G. Cleary, “Arithmetic coding for data compression,” Commun. ACM, vol. 30, no. 6, pp. 520-540, 1987.
[39] D. Tse and P. Viswanath, Fundamentals of wireless communication. Cambridge University Press, 2005.
[40] A. Lugmayr, M. Danelljan, A. Romero, F. Yu, R. Timofte, and L. Van Gool, “Repaint: Inpainting using denoising diffusion probabilistic models,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., 2022, pp. 11 461-11 471.
[41] R. G. Gallager, Information theory and reliable communication. New York, NY, USA: Wiley, 1968.
[42] B. Roh, W. Shin, I. Kim, and S. Kim, “Spatially consistent representation learning,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., June 2021, pp. 1144-1153.
[43] E. Zehavi and J. K. Wolf, “On runlength codes,” IEEE Trans. on Inf. Theory, vol. 34, no. 1, pp. 45-54, Aug. 1988.
[44] H. R. Sheikh, A. C. Bovik, and G. De Veciana, “An information fidelity criterion for image quality assessment using natural scene statistics,” IEEE Trans. on Image Processing, vol. 14, no. 12, pp. 2117-2128, Nov. 2005.
[45] S. Boyd and L. Vandenberghe, Convex optimization. UK: Cambridge University Press, 2004.
[46] S. Liu, P.-Y. Chen, B. Kailkhura, G. Zhang, A. O. Hero III, and P. K. Varshney, “A primer on zeroth-order optimization in signal processing and machine learning: Principals, recent advances, and applications,” IEEE Signal Process. Mag., vol. 37, no. 5, pp. 43-54, Sept. 2020.
[47] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in IEEE Conf. Comput. Vis. Pattern Recog. (CVPR), June 2016, pp. 770−778770-778770−778.
[48] J. Deng, W. Dong, R. Socher, L.-J. Li, L. Kai, and F.-F. Li, “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE Conf. Comput. Vis. Pattern Recog. (CVPR), Miami, FL, USA, June 2009, pp. 248-255.
[49] A. Kuznetsova, H. Rom, N. Alldrin, J. Uijlings, I. Krasin, J. Pont-Tuset, S. Kamali, S. Popov, M. Malloci, A. Kolesnikov et al., “The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale,” Inter. J. of Comput. Vis., vol. 128, no. 7, pp. 1956-1981, 2020.
[50] C. Christopoulos, A. Skodras, and T. Ebrahimi, “The JPEG2000 still image coding system: an overview,” IEEE Trans. Cons. Elec., vol. 46, no. 4, pp. 1103-1127, Nov. 2000.
[51] F. Bellard, “BPG image format”," 2014. [Online]. Available: http://bellard.org/bpg/
参考论文:https://arxiv.org/pdf/2505.10405

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 19
19 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)