机器学习——logistic回归
Logistic回归通过计算输入数据的线性组合(即加权和),然后应用一个逻辑函数将结果转换为0到1之间的概率值。假设现在有一些数据点,我们用一条直线对这些点进行拟合(该线称为最佳拟合曲线),这个拟合的过程就称作回归(如下图中的蓝色直线就为最佳拟合曲线)1>代码:通过线性回归计算出z,再将该数据输入sigmoid函数,转化为某个概率值,从而实现相应的测试集的分类。2>其中第一列表示该数据的横坐标,第
一、logistic回归
1、概念
Logistic回归是一种在机器学习和统计学中广泛使用的分类算法,主要用于二分类问题。尽管它的名字中包含“回归”,但实际上它是一种分类方法,因为它预测的是输入数据实例属于某个类别的概率。
2、基本原理
Logistic回归通过计算输入数据的线性组合(即加权和),然后应用一个逻辑函数将结果转换为0到1之间的概率值。这个概率值表示输入数据实例属于某个类别的可能性。通常情况下用于二分类问题,若输出的概率值在0到0.5之间,则将输入的数据实例分为0类;若输出的概率值在0.5到1之间,则将输入的数据实例分1类
3、逻辑函数(Sigmoid函数)
![]()
在不同坐标尺度下的sigmoid函数的两天曲线图:
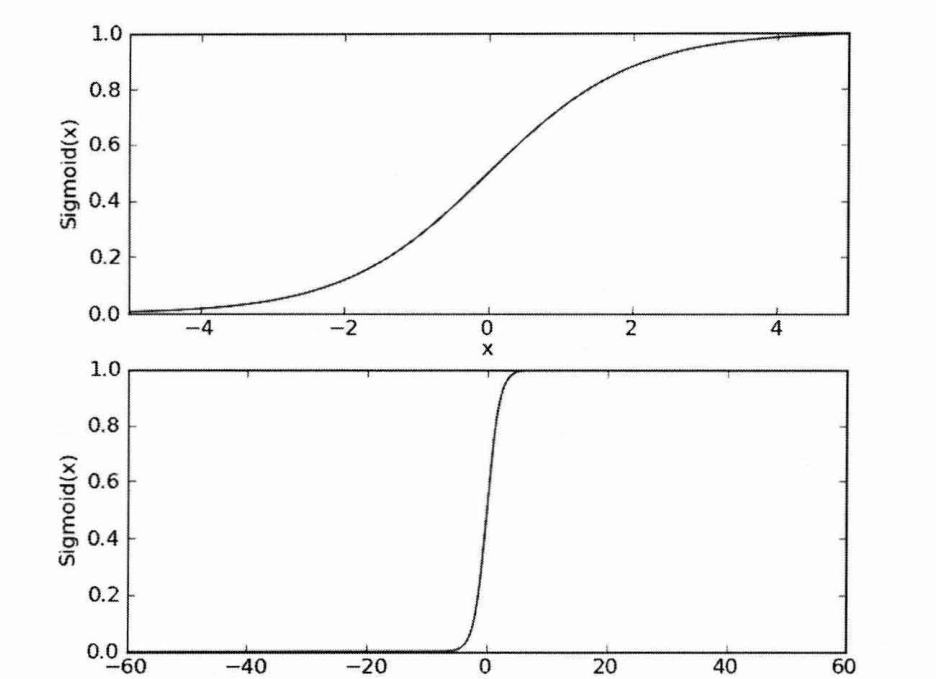
其中,( z ) 是输入数据的线性组合(即加权和)。sigmoid将任何实数映射到0到1之间的值,这使得它可以用于预测概率。本次logistc回归就是利用sigmoid函数作为逻辑函数将结果转换到0-1之间,从而实现对输入的数据实例进行分类
4、线性组合
对于sigmoid函数的输入数据z,其线性组合可以表示为:
其中的向量x是分类器的输入数据,向量w也就是我们要找到的最佳参数(系数),从而使得分类器尽可能地精确
5、回归的概念
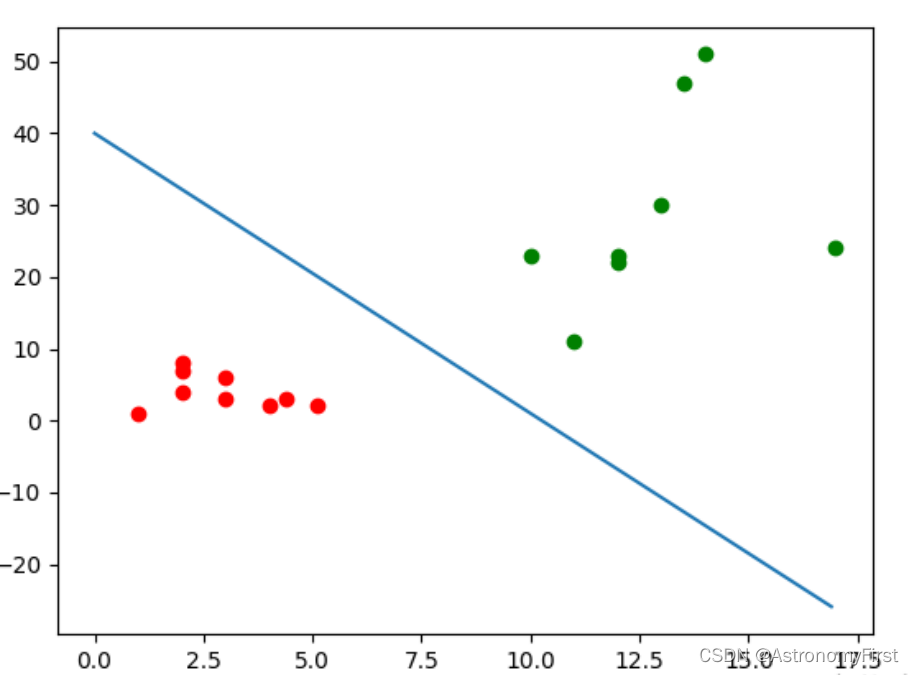
假设现在有一些数据点,我们用一条直线对这些点进行拟合(该线称为最佳拟合曲线),这个拟合的过程就称作回归(如下图中的蓝色直线就为最佳拟合曲线)
6、优缺点
优点:(1)解释性强:结果易于解释,因为它直接给出了每个特征对结果的影响程度
(2)计算效率高 (3)适用于二分类问题
(4)稳健性:Logistic回归对数据的分布没有严格的要求,只要数据满足线性可分
缺点:(1)对非线性问题的处理能力有限
(2)容易过拟合:当数据中存在较多特征且特征之间存在高度相关性时,Logistic回归模型容易出现过拟合现象
(3)对缺失值和异常值敏感 (4)多分类问题处理困难
二、梯度上升算法求解回归系数
def loaddataset():
testset = [[-3.141592,2.343434],[7.12121,3.232323],[-1.222222,3.2323232],[2.794747,-4.67890]]
datamat = [] ; labelmat = []
fr = open("D:\\University_Second_down------\\机器学习data\\testSet.txt")
for line in fr.readlines():
linearr = line.strip().split()
datamat.append([1.0, float(linearr[0]), float(linearr[1])])
labelmat.append(int(linearr[2]))
return datamat , labelmat , testset1>文本文件的内容大致如下图:
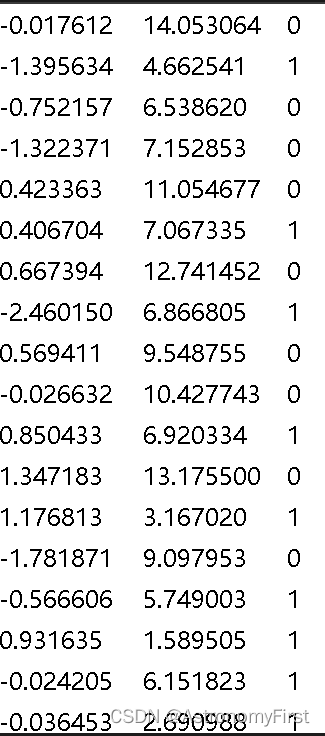
2>其中第一列表示该数据的横坐标,第二列表示数据的纵坐标,第三列表示该数据点的所属于的标签的类别,为0类或者是1类
def sigmoid(intx):
return 1.0/(1+exp(-intx))
def gradascent(datamatin, classlabels):
datamatrix = mat(datamatin) #将datamatrix转化为矩阵
labelmat = mat(classlabels).transpose() #将labelmat转化为矩阵同时转置
m , n = shape(datamatrix) #m为矩阵的行数,n为矩阵的列数
alpha = 0.001 #学习率(梯度上升的步长)
maxcycles = 500 #最大迭代次数
weights = ones((n,1)) #权重矩阵(n,1)的列向量
for k in range(maxcycles): #梯度上升循环
h = sigmoid(datamatrix*weights) #使用当前权重和输入数据计算每个数据点的预测概率
error = (labelmat - h) #计算预测概率和真实标签的误差
weights = weights + alpha * datamatrix.transpose()*error
return weights #datamatrix.transpose()*error为梯度,再利用梯度*学习率来更新权值3.对测试集进行分类
1>代码:通过线性回归计算出z,再将该数据输入sigmoid函数,转化为某个概率值,从而实现相应的测试集的分类
def coutresult(weights , testset):
list = weights.tolist() #将矩阵转化为列表
w0 = list[0]; w1 = list[1]; w2 = list[2] #获取列表中的每一个元素
count = 0
for sample in testset:
count += 1 #用来记录当前的测试集
z = w0[0]*1 + w1[0]*sample[0] + w2[0]*sample[1]
result = sigmoid(z)
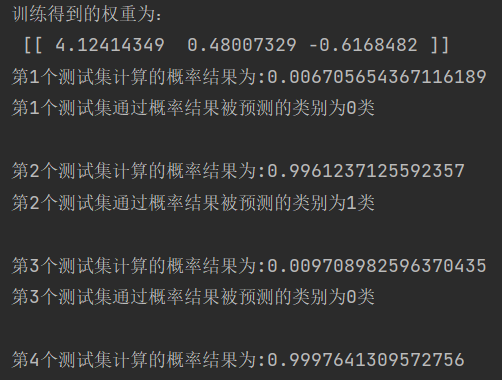
print(f"第{count}个测试集计算的概率结果为:{result}")
if result>0.5:
print(f"第{count}个测试集通过概率结果被预测的类别为1类")
else:
print(f"第{count}个测试集通过概率结果被预测的类别为0类")def main():
datamat, labelmat , testset= loaddataset()
weights = gradascent(datamat, labelmat)
print("训练得到的权重为:", weights.T)
coutresult(weights, testset)2>运行结果:
4.利用matplotlib绘制图像,并利用最小二乘法来拟合数据点
1>代码:最小二乘法和图像绘制并显示,其中w和b的计算公式如下
def calwandb(dataset):
length = len(dataset)
xaverage = 0
xihef = 0
result = 0
for sample in dataset:
xaverage += sample[0]
xihef = xaverage*xaverage / length
xaverage /= length
wtop = 0
wunder = 0
for sample in dataset:
wtop += sample[1]*(sample[0]-xaverage)
wunder += sample[0]*sample[0]
wunder -= xihef
w = wtop / wunder
for sample in dataset:
result += sample[1] - w*sample[0]
b = result / length
print(f"w={w:.3f},b={b:.3f}")
return w, bdef plotDataSet():
dataMat, labelMat ,testset= loaddataset() # 加载数据集
dataArr = np.array(dataMat) # 转换成numpy的array数组
n = np.shape(dataMat)[0] # 数据个数
xcord1 = [];
ycord1 = [] # 正样本
xcord2 = [];
ycord2 = [] # 负样本
for i in range(n): # 根据数据集标签进行分类
if int(labelMat[i]) == 1:
xcord1.append(dataArr[i, 1]);
ycord1.append(dataArr[i, 2]) # 1为正样本
else:
xcord2.append(dataArr[i, 1]);
ycord2.append(dataArr[i, 2]) # 0为负样本
x_values = np.array([dataArr[:, 1].min() - 1, dataArr[:, 1].max() + 1])
y_values = 1.109 * x_values + 6.543 # 根据斜率和偏移量计算y值
fig = plt.figure()
ax = fig.add_subplot(111) # 添加subplot
ax.scatter(xcord1, ycord1, s=20, c='red', marker='s', alpha=.5) # 绘制正样本
ax.scatter(xcord2, ycord2, s=20, c='green', alpha=.5) # 绘制负样本
ax.plot(x_values, y_values, 'k-')
plt.title('DataSet') # 绘制title
plt.xlabel('x');
plt.ylabel('y') # 绘制label
plt.show()2>运行结果
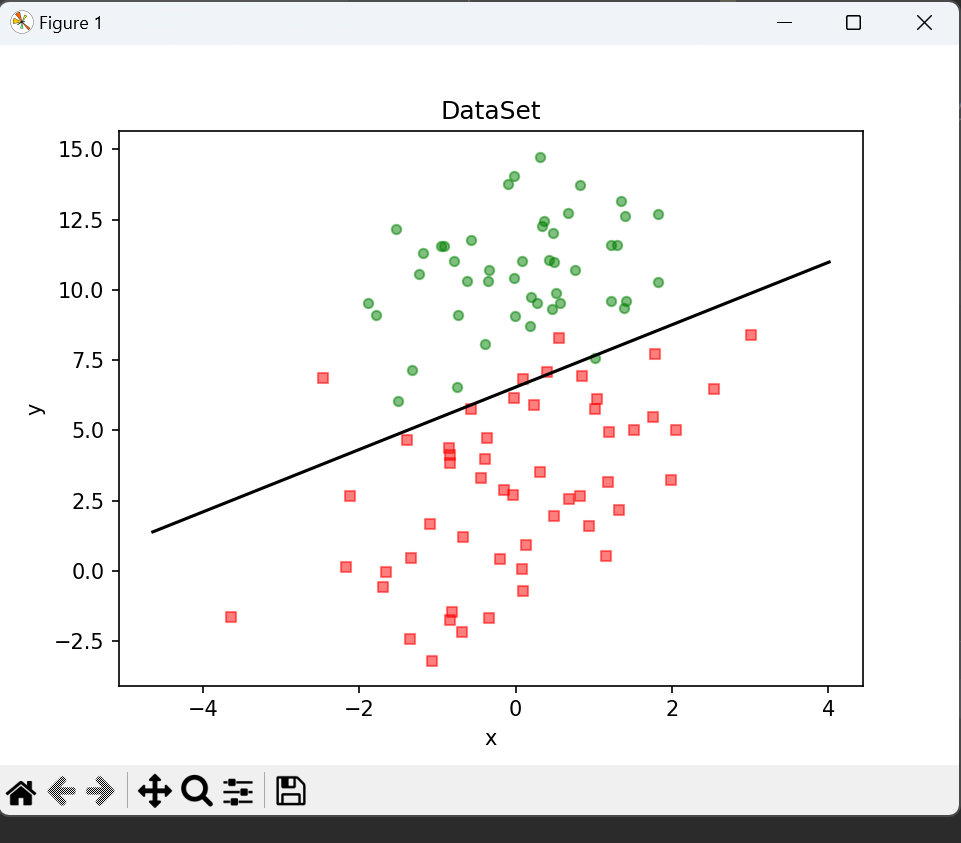

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)