⛵️ 机器学习进阶篇:从数据清洗到全球排名前 11% 的泰坦尼克预测完整通关攻略!
【新手进阶】决策树+特征工程:泰坦尼克生存预测完整指南。
🚢 背景
泰坦尼克号数据集是机器学习领域最经典的入门项目
其中包含 891 名乘客的详细信息
本文将介绍如何使用决策树算法进行泰坦尼克号生存预测
✅ 真实数据集的预处理技巧
✅ 特征工程的核心方法
✅ 决策树模型的实战应用
✅ Kaggle 竞赛完整提交流程
🔍 1.数据集深度解析
三份关键文件:
train.csv- 训练集(891 名乘客)test.csv- 测试集(418 名乘客)gender_submission.csv- 提交格式示例

1.train.csv(训练集)
作用:这是用来 “教” 机器学习模型的主要数据
内容:
- 包含 891 名乘客的详细信息
- 每一行代表一名乘客
- “Survived” 列是我们要预测的目标(标签)
- 1 = 幸存
- 0 = 遇难
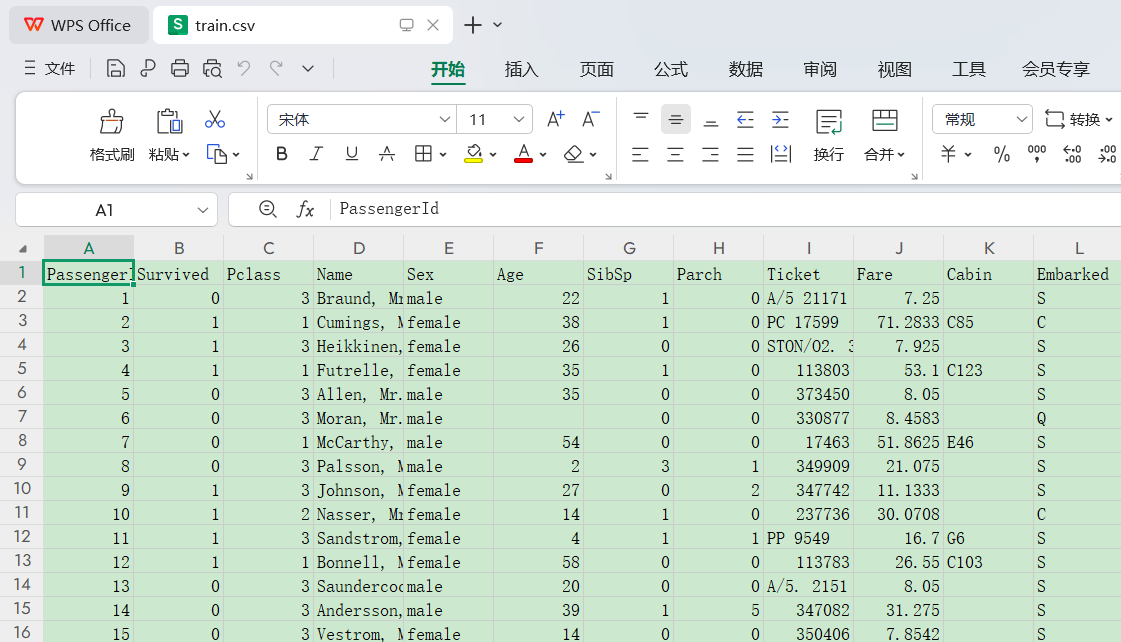
核心特征说明:
| 特征 | 重要性 | 示例值 |
|---|---|---|
| Pclass | 舱位等级反映社会地位 | 1=头等舱,2=二等舱, 3=三等舱 |
| Sex | 女性生存率显著更高 | male / female |
| Age | 儿童优先原则 | 22.0 |
| Fare | 船票价格关联舱位等级 | 7.25 |
2.test.csv(测试集)
作用:用来检验模型学得好不好的 “考试题”
内容:
- 包含 418 名乘客的详细信息
- 没有 Survived 列(因为要我们用训练好的模型来预测)
- 其他列和 train.csv 完全一样
特别注意:
- 这个文件里的乘客和 train.csv 里的不同
- 我们最终要用模型预测这些乘客的生存情况
3.gender_submission.csv(基准提交)
作用:展示最简单的预测方法应该长什么样
内容:
- PassengerId(乘客ID,和 test.csv 对应)
- Survived(预测结果)
示例内容:
PassengerId,Survived
892,0
893,1
894,0
...
(892 号乘客预测为 0=遇难,893 号预测为 1=幸存,以此类推)
训练集和测试集关系图示
训练阶段:
train.csv → [机器学习模型] → 学会预测规律
测试阶段:
test.csv → [训练好的模型] → 预测结果.csv
新手常见问题解答
Q:为什么 test.csv 没有 Survived 列?
A: 因为这是要你预测的!就像考试时不给你答案一样。
Q:能用 train.csv 测试模型吗?
A: 可以但不推荐,这像 “开卷考试”,不能反映真实水平。
Q:gender_submission.csv 必须用吗?
A:不是必须的,它只是展示提交格式和提供一个简单基准。
Q:三个文件乘客有重复吗?
A:没有,所有乘客都是独立的。
🧹 2.数据预处理
1.显示各列信息和缺失值情况
print("训练集形状(行,列):", train_data.shape)
train_data.info()

- Age 缺失 177 个(891 - 714)
- Cabin 缺失 687 个
- Embarked 缺失 2 个
2.逐列分析缺失情况
2.1 Age 列 (年龄)
-
缺失数量:177 / 891 (约 20%)
-
处理理由:
- 年龄是重要特征,不能直接删除
- 用 中位数 填充比平均值更抗 outliers (异常值)
2.2 Cabin 列 (客舱)
-
缺失数量:687 / 891 (约 77%)
-
处理理由:
- 缺失太多,直接删除该列
2.3 Embarked 列 (登船港口)
-
缺失数量:2 / 891
-
处理理由:
- 只有 2 个缺失,可以直接用最常见的 ‘S’ 填充
对于测试集 test.csv 同理
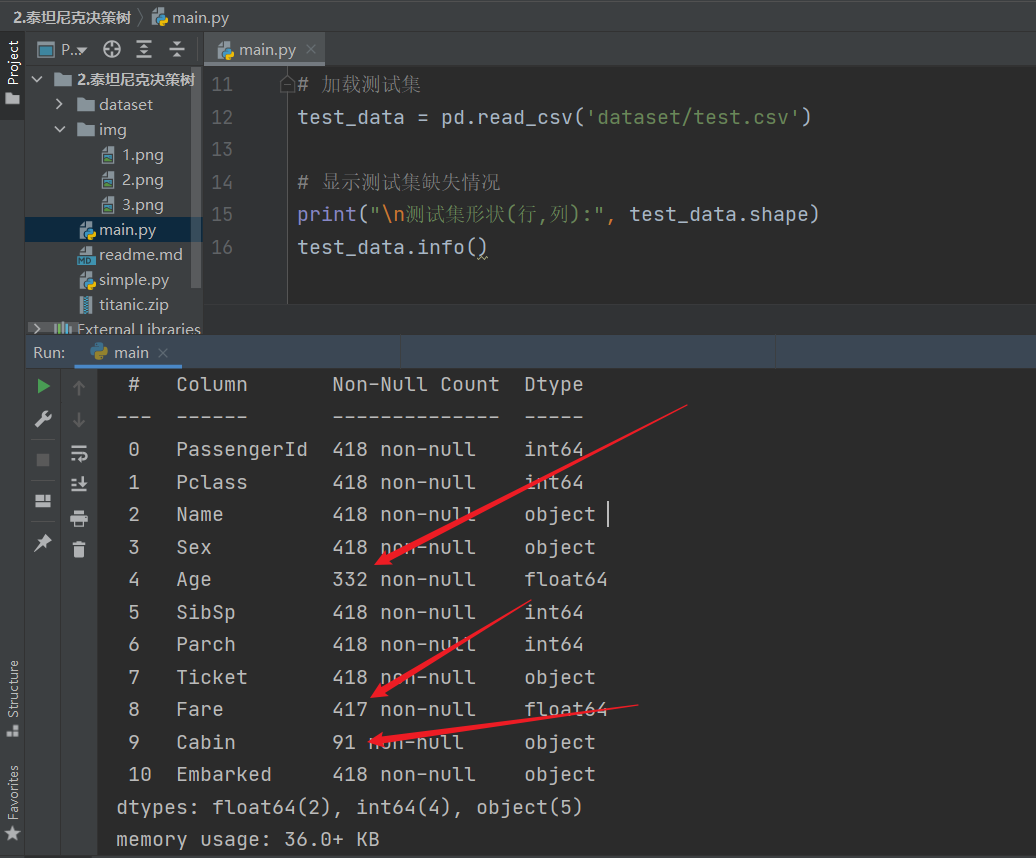
在测试集中,Fare 列有一个缺失,本文用中位数填充。
3.预处理代码实现
# 填充 Age
train_data['Age'].fillna(train_data['Age'].median(), inplace=True)
test_data['Age'].fillna(test_data['Age'].median(), inplace=True)
# 删除 Cabin 列
train_data.drop('Cabin', axis=1, inplace=True)
test_data.drop('Cabin', axis=1, inplace=True)
# 填充 Embarked
train_data['Embarked'].fillna('S', inplace=True)
# 填充 Fare(仅测试集)
test_data['Fare'].fillna(test_data['Fare'].median(), inplace=True)
# 验证是否还有缺失值
print("\n预处理后训练集缺失值:")
print(train_data.isnull().sum())
print("\n预处理后测试集缺失值:")
print(test_data.isnull().sum())
结果如下

现在所有缺失值都已处理完毕!这样做的目的是:
- 保留尽可能多的数据
- 用合理的值填充缺失
- 确保训练集和测试集处理方式一致
⚙️ 3.特征工程精要
特征工程 (Feature Engineering) 是机器学习中非常重要但常被初学者忽略的环节
简单说,它就是通过一系列技巧,把原始数据转换成更适合机器学习模型理解的格式
就像厨师准备食材一样,好的处理能让最终 “菜品” (模型效果) 更出色。
1. 特征转换示例:性别文字转数字
原始数据:
| Sex |
|--------|
| male |
| female |
| female |
转换后:
| Sex |
|-----|
| 1 |
| 0 |
| 0 |
(male = 1, female = 0)
为什么要转换:
- 决策树等算法不能直接处理文字
- 转换为数字后模型能计算
2. 年龄分组
原始 Age:年龄连续数值(如22.0, 35.5等)
分组后:
bins = [0, 12, 18, 30, 50, 100]
labels = ['Child', 'Teenager', 'Young Adult', 'Adult', 'Senior']
train_data['AgeGroup'] = pd.cut(train_data['Age'], bins=bins, labels=labels)
效果:
| Age | AgeGroup |
|------|-------------|
| 8 | Child |
| 16 | Teenager |
| 25 | Young Adult |
| 45 | Adult |
分组理由:
- 不同年龄段生存率差异明显 (如儿童优先)
- 连续年龄值可能引入噪声
- 分组后模型更容易发现规律
综上,特征工程的核心作用:
- 提高模型性能
- 降低计算成本
- 增强可解释性
💡 记住:特征工程既是科学也是艺术,需要不断尝试和验证!
特征工程代码实现
# 特征工程1:性别文字转数字
train_data['Sex'] = train_data['Sex'].map({'female': 0, 'male': 1})
test_data['Sex'] = test_data['Sex'].map({'female': 0, 'male': 1})
# 特征工程2:年龄分组
bins = [0, 12, 18, 30, 50, 100]
labels = [0, 1, 2, 3, 4] # 直接用数字表示分组
train_data['AgeGroup'] = pd.cut(train_data['Age'], bins=bins, labels=labels)
test_data['AgeGroup'] = pd.cut(test_data['Age'], bins=bins, labels=labels)
# 不删除原始 Age 列(保留备用)
# 选择特征(包含原始特征和新工程特征)
features = ['Pclass', 'Sex', 'AgeGroup', 'SibSp', 'Parch', 'Fare', 'Embarked']
X = train_data[features]
y = train_data['Survived']
# 将 Embarked 转换为数字(原始特征处理)
embarked_mapping = {'S': 0, 'C': 1, 'Q': 2}
X['Embarked'] = X['Embarked'].map(embarked_mapping)
test_data['Embarked'] = test_data['Embarked'].map(embarked_mapping)
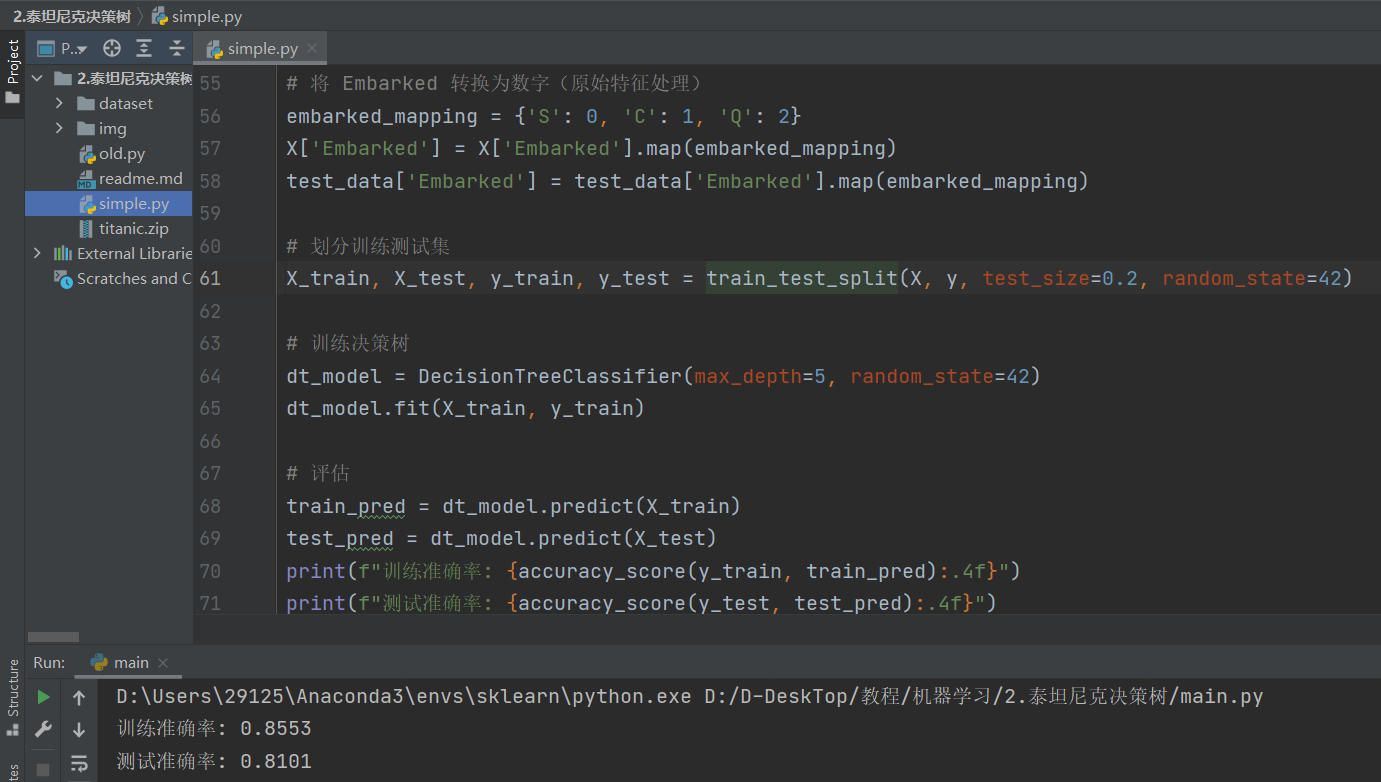
🌲 4.决策树训练与评估
# 划分训练测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练决策树
dt_model = DecisionTreeClassifier(max_depth=5, random_state=42)
dt_model.fit(X_train, y_train)
# 评估
train_pred = dt_model.predict(X_train)
test_pred = dt_model.predict(X_test)
print(f"训练准确率: {accuracy_score(y_train, train_pred):.4f}")
print(f"测试准确率: {accuracy_score(y_test, test_pred):.4f}")
训练结果如下
完整代码(特别提醒,运行时要定位到数据集所在的位置)
import pandas as pd
import matplotlib.pyplot as plt
# 加载训练集
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.tree import plot_tree, DecisionTreeClassifier
train_data = pd.read_csv('dataset/train.csv')
# 显示各列信息和缺失值情况
# print("训练集形状(行,列):", train_data.shape)
# train_data.info()
# 加载测试集
test_data = pd.read_csv('dataset/test.csv')
# 显示测试集缺失情况
# print("\n测试集形状(行,列):", test_data.shape)
# test_data.info()
# 填充Age
train_data['Age'].fillna(train_data['Age'].median(), inplace=True)
test_data['Age'].fillna(test_data['Age'].median(), inplace=True)
# 填充Embarked
train_data['Embarked'].fillna('S', inplace=True)
# 填充Fare(仅测试集)
test_data['Fare'].fillna(test_data['Fare'].median(), inplace=True)
# 删除Cabin列
train_data.drop('Cabin', axis=1, inplace=True)
test_data.drop('Cabin', axis=1, inplace=True)
# # 验证是否还有缺失值
# print("\n预处理后训练集缺失值:")
# print(train_data.isnull().sum())
# print("\n预处理后测试集缺失值:")
# print(test_data.isnull().sum())
# 特征工程1:性别文字转数字
train_data['Sex'] = train_data['Sex'].map({'female': 0, 'male': 1})
test_data['Sex'] = test_data['Sex'].map({'female': 0, 'male': 1})
# 特征工程2:年龄分组
bins = [0, 12, 18, 30, 50, 100]
labels = [0, 1, 2, 3, 4] # 直接用数字表示分组
train_data['AgeGroup'] = pd.cut(train_data['Age'], bins=bins, labels=labels)
test_data['AgeGroup'] = pd.cut(test_data['Age'], bins=bins, labels=labels)
# 不删除原始 Age 列(保留备用)
# 选择特征(包含原始特征和新工程特征)
features = ['Pclass', 'Sex', 'AgeGroup', 'SibSp', 'Parch', 'Fare', 'Embarked']
X = train_data[features]
y = train_data['Survived']
# 将 Embarked 转换为数字(原始特征处理)
embarked_mapping = {'S': 0, 'C': 1, 'Q': 2}
X['Embarked'] = X['Embarked'].map(embarked_mapping)
test_data['Embarked'] = test_data['Embarked'].map(embarked_mapping)
# 划分训练测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练决策树
dt_model = DecisionTreeClassifier(max_depth=5, random_state=42)
dt_model.fit(X_train, y_train)
# 评估
train_pred = dt_model.predict(X_train)
test_pred = dt_model.predict(X_test)
print(f"训练准确率: {accuracy_score(y_train, train_pred):.4f}")
print(f"测试准确率: {accuracy_score(y_test, test_pred):.4f}")
# 生成测试集的预测结果
X_test_final = test_data[features] # 使用和训练时相同的特征
test_predictions = dt_model.predict(X_test_final)
# 创建提交文件
submission = pd.DataFrame({
'PassengerId': test_data['PassengerId'],
'Survived': test_predictions
})
# 保存为CSV文件(Kaggle要求的格式)
submission.to_csv('titanic_submission.csv', index=False)
print("提交文件已生成: titanic_submission.csv")
🏆 Kaggle竞赛排名
Kaggle 排名
- 得分:0.78708
- 排名:全球前11.9%(1912/16044)
1.生成预测结果文件
# 生成测试集的预测结果
X_test_final = test_data[features] # 使用和训练时相同的特征
test_predictions = dt_model.predict(X_test_final)
# 创建提交文件
submission = pd.DataFrame({
'PassengerId': test_data['PassengerId'],
'Survived': test_predictions
})
# 保存为CSV文件(Kaggle要求的格式)
submission.to_csv('titanic_submission.csv', index=False)
print("提交文件已生成: titanic_submission.csv")
2.进入 Titanic竞赛页面,点击 Submit Predictions,将生成的文件拖进去
3.上传成功后点击 Submit

4.本次提交得分为 0.78708
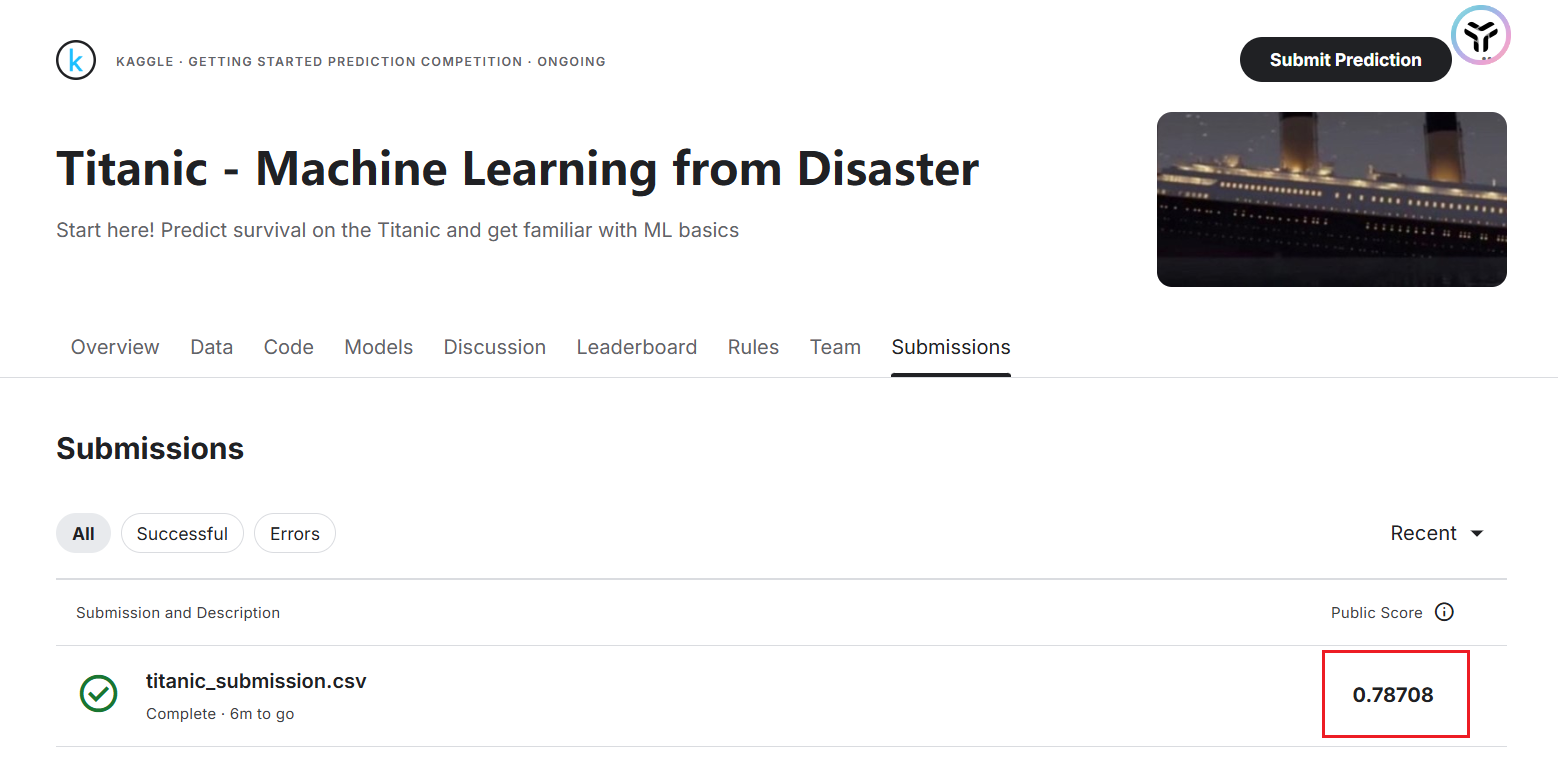
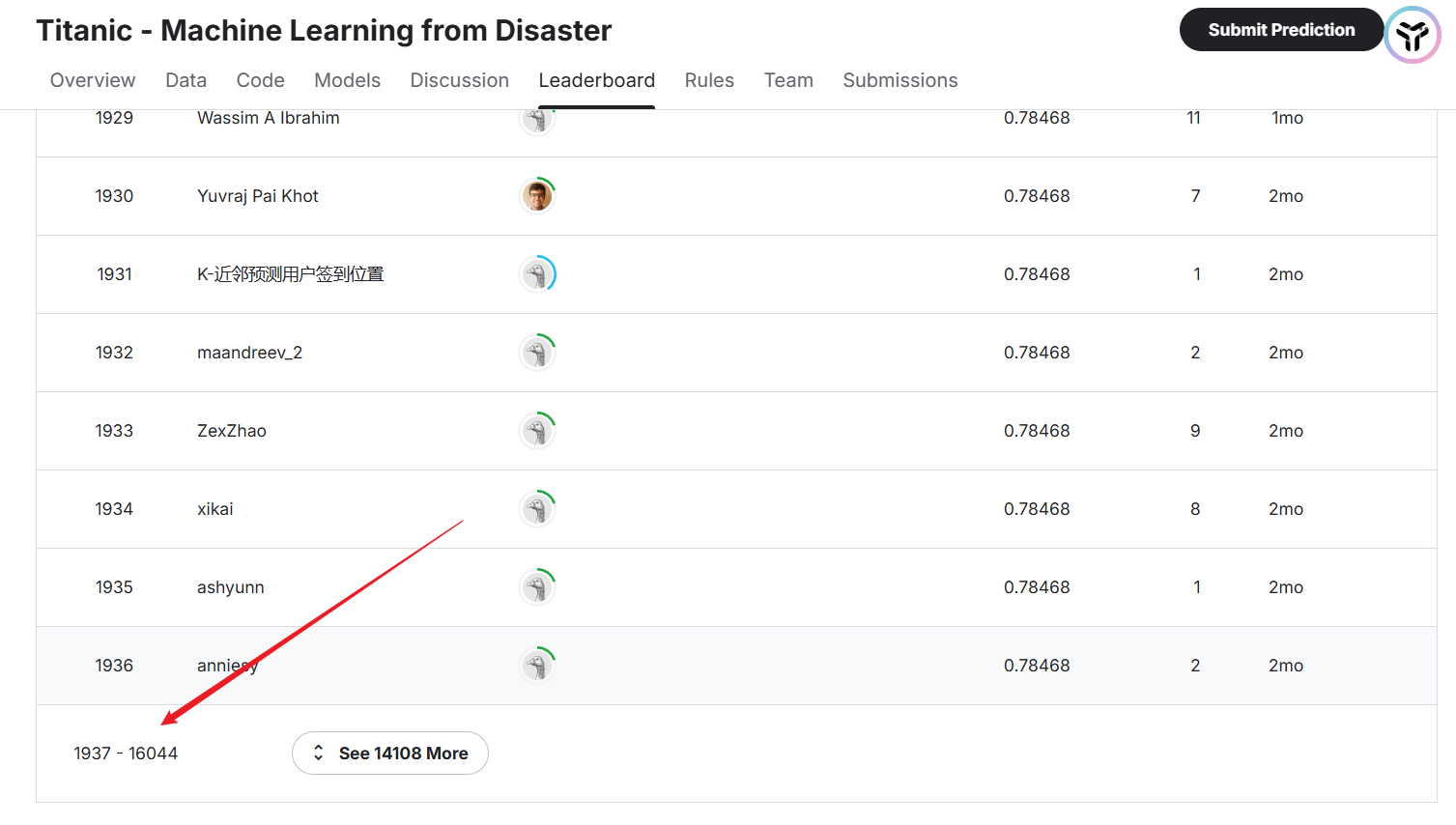
5.进入 Leaderboard 查看排名,本次排名为全球第 1912 名,还不错!

6.滑到左下角,发现目前一共有 16044 人参赛,所以本次大约排在前 11.9% (1912 / 16044)
🚀 进阶挑战
- 尝试随机森林/XGBoost等更强大算法
- 创造更有意义的特征组合
- 使用交叉验证优化超参数
📢 下期预告
本期输出内容很多,能消化的同学可以期待下一篇进阶版,如果喜欢,点赞关注不迷路 🐾
《冲击 Kaggle 顶峰:高级特征工程与模型优化技巧》
- 特征重要性分析
- 高级编码技巧
- 模型集成方法
💬 有任何的建议或者见解,都可以在评论区分享!

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)