发论文神器!即插即用多尺度融合模块
即插即用多尺度融合模块在计算机视觉任务中展现出显著优势,能够有效处理图像中不同尺寸和形态的目标。这些模块通过提取和融合多尺度特征,增强模型对复杂场景的理解能力,且无需修改现有深度学习模型,便于快速应用。本文介绍了四种最新的多尺度融合模块:Scale-Aware Modulation与Transformer结合、基于多尺度特征融合的源相机识别算法、面向Transformer基目标检测器的多尺度特征高
发论文神器!!即插即用多尺度融合模块
在CV任务中,图像中的目标往往以不同的尺寸和形态出现,传统的单尺度处理方法难以同时捕捉这些目标的细节信息
为解决这个问题,研究者们提出了即插即用多尺度融合模块:通过提取并融合不同尺度的特征,在保持高性能的同时,加强了模型对复杂场景的理解和处理能力。
另外,这种模块因为内部的优化设计,能无缝集成到现有深度学习模型中,无需修改原始模型,非常 适合我们快速验证和应用,改善我们的模型性能。
为方便各位理解和使用,加速论文进度,我这次挑选了10个即插即用多尺度融合模块,基本都是最新的,已经开源的代码也附上了
论文1
标题:
Scale-Aware Modulation Meet Transformer
尺度感知调制与Transformer的结合
方法:
-
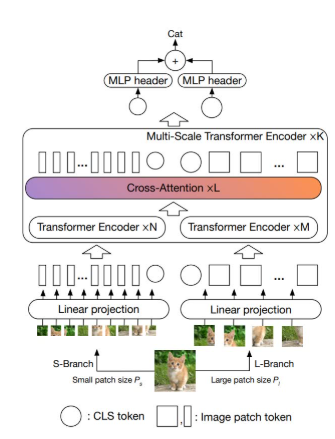
尺度感知调制(SAM):提出了结合多头混合卷积(MHMC)和尺度感知聚合(SAA)的尺度感知调制模块,用于捕捉多尺度特征并增强感受野。
-
进化混合网络(EHN):提出了一种新的混合网络架构,通过在浅层使用SAM块,深层使用多头自注意力(MSA)块,模拟从局部到全局依赖关系的过渡。
-
多头混合卷积(MHMC):通过不同大小的卷积核捕捉多尺度特征,同时通过分组和轻量级1×1卷积进行特征聚合。
-
尺度感知聚合(SAA):通过打乱和分组不同尺度的特征,利用逆瓶颈结构进行特征融合,增强多尺度特征的多样性。
创新点:
-
多头混合卷积(MHMC):通过引入多个不同大小的卷积核,能够捕捉多尺度特征并扩大感受野,显著提升了模型对局部细节的捕捉能力。例如,在浅层阶段,MHMC能够更准确地突出前景和目标对象。
-
尺度感知聚合(SAA):通过轻量级的特征聚合模块,能够有效整合不同尺度的特征,同时保持模型的轻量化。实验表明,SAA能够显著提升模型对目标对象的语义信息捕捉能力,例如在第二阶段的特征图中,能够更清晰地突出目标对象的关键特征。
-
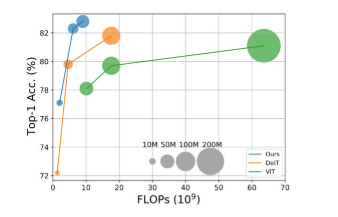
进化混合网络(EHN):通过在浅层使用SAM块,深层使用MSA块,有效地模拟了从局部到全局依赖关系的过渡。这种设计不仅提高了模型的性能,还显著降低了计算成本。例如,SMT在ImageNet-1K上的top-1准确率达到了82.2%(tiny模型)和84.3%(base模型),同时计算量和参数量均低于其他同类模型。
-
性能提升:SMT在多个视觉任务上均取得了显著的性能提升。例如,在COCO数据集上,SMT base模型在1×和3×训练计划下分别比Swin Transformer高出4.2和1.3 mAP;在ADE20K数据集上,SMT base模型在单尺度和多尺度测试中分别比Swin高出2.0和1.1 mIoU。
论文2
标题:
Source Camera Identification Algorithm Based on Multi-Scale Feature Fusion
基于多尺度特征融合的源相机识别算法
方法:
-
多尺度特征提取模块(CFUNet):基于U-Net结构,通过特征金字塔网络(FPN)机制融合不同尺度的特征。
-
特征融合模块:利用Transformer块将不同阶段的特征转换为同一维度,再通过图卷积网络(GCN)进行特征融合。
-
相机指纹分类网络:基于对比学习的孪生网络(Siamese network)对相机指纹特征进行分类。
创新点:
-
多尺度特征融合:通过融合不同尺度的特征,增强了模型对相机指纹的提取能力。例如,在Devices数据集上,该算法的分类准确率达到了91.85%,显著高于其他方法。
-
Transformer块的应用:利用Transformer块对不同阶段的特征进行维度转换,提高了特征融合的效率和效果。
-
图卷积网络(GCN):通过图卷积网络进一步融合特征,提升了分类性能。例如,在Types数据集上,该算法的分类准确率达到了97.87%,比其他方法高出2%以上。
-
性能提升:该算法在Brands、Types和Devices三个数据集上均取得了优异的性能。例如,在Brands数据集上,分类准确率达到了99.46%,在Types数据集上达到了97.87%,在Devices数据集上达到了91.85%,均优于其他现有方法。
论文3
标题:
Towards Efficient Use of Multi-Scale Features in Transformer-Based Object Detectors
面向Transformer基目标检测器的多尺度特征高效利用
方法:
-
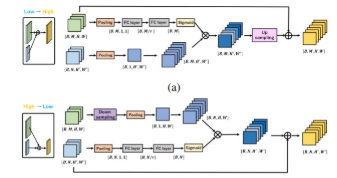
迭代多尺度特征聚合(IMFA):提出了一种新的范式,通过迭代更新编码特征和稀疏采样多尺度特征来提高Transformer基目标检测器的性能。
-
稀疏采样策略:在关键点位置稀疏采样多尺度特征,减少了计算开销。
-
迭代更新编码特征:通过重新排列Transformer编码器-解码器管道,使编码特征能够随着检测预测的细化而迭代更新
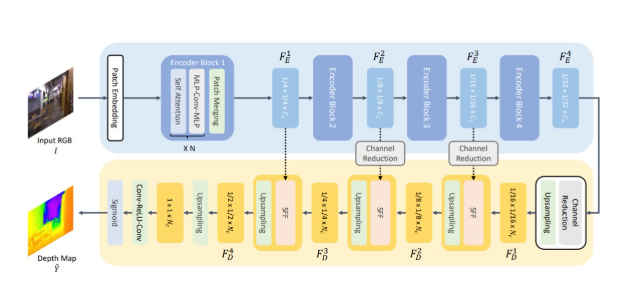
创新点:
-
迭代更新编码特征:通过重新排列编码器-解码器管道,使编码特征能够随着检测预测的细化而迭代更新,提高了模型对多尺度特征的利用效率。
-
稀疏采样策略:通过在关键点位置稀疏采样多尺度特征,显著减少了计算开销。例如,在COCO val2017数据集上,使用IMFA的DAB-DETR模型仅增加了约15 GFLOPs的计算量,但平均精度(AP)提升了3.3%。
-
性能提升:IMFA在多个Transformer基目标检测器上均取得了显著的性能提升。例如,DAB-DETR模型在COCO val2017数据集上的AP从42.2%提升到45.5%,同时计算量仅增加了约15 GFLOPs。
-
通用性:IMFA可以轻松集成到多种Transformer基目标检测器中,并在不同的数据集和任务上表现出色。例如,在COCO val2017数据集上,IMFA与多种检测器结合后,AP均显著提升,且计算开销较小
论文4
标题:
ViT-CoMer: Vision Transformer with Convolutional Multi-scale Feature Interaction for Dense Predictions
ViT-CoMer:用于密集预测的带有卷积多尺度特征交互的视觉Transformer
方法:
-
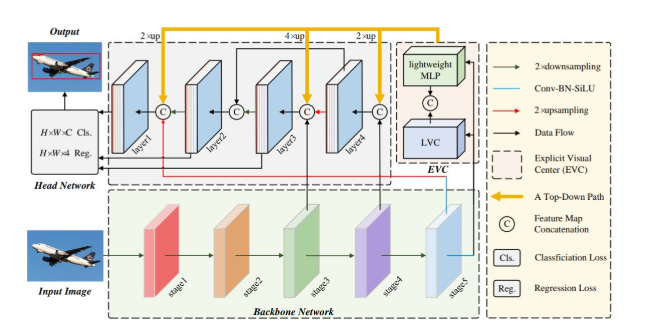
多尺度特征金字塔模块(MRFP):通过不同大小的卷积核捕捉多尺度特征,增强CNN特征的感受野。
-
CNN-Transformer双向融合交互模块(CTI):通过多尺度自注意力机制融合CNN和Transformer特征,增强模型的语义表示能力。
-
ViT-CoMer架构:结合了ViT和CNN的多尺度特征交互,通过特征金字塔和双向交互模块提升密集预测任务的性能。
创新点:
-
多尺度特征金字塔模块(MRFP):通过不同大小的卷积核捕捉多尺度特征,显著增强了CNN特征的感受野。例如,在COCO val2017数据集上,使用MRFP的ViT-CoMer模型比普通ViT模型的APb提升了5.6%,APm提升了3.4%。
-
CNN-Transformer双向融合交互模块(CTI):通过多尺度自注意力机制融合CNN和Transformer特征,增强了模型的语义表示能力。例如,在ADE20K数据集上,使用CTI的ViT-CoMer模型的mIoU达到了55.6%,比普通ViT模型高出2.1%。
-
性能提升:ViT-CoMer在多个密集预测任务上均取得了显著的性能提升。例如,在COCO val2017数据集上,ViT-CoMer-L模型的AP达到了64.3%,在ADE20K数据集上,ViT-CoMer-L模型的mIoU达到了62.1%,均优于其他现有方法。
-
预训练权重的利用:ViT-CoMer能够直接利用各种开源的ViT预训练权重,进一步提升性能。例如,使用DINOv2预训练权重的ViT-CoMer-L模型在COCO val2017数据集上的AP达到了55.9%,比使用ImageNet-22K预训练权重的模型高出3.0%。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)