山东大学软件学院创新项目实训开发日志——第14周
第14周项目目标:本项目旨在开发一款基于人工智能的文档审阅工具,解决当前在文档审阅过程中人工检查效率低、遗漏错误和格式不规范等问题。
山东大学软件学院创新项目实训开发日志——第14周
项目名称:文档大师
项目目标:
本项目旨在开发一款基于人工智能的文档审阅工具,解决当前在文档审阅过程中人工检查效率低、遗漏错误和格式不规范等问题。
本周完成任务
一、搭建文章润色功能语言索引库
之前已将中文词语、成语和英文单词、短语以及它们的释义保存到了MongoDB:

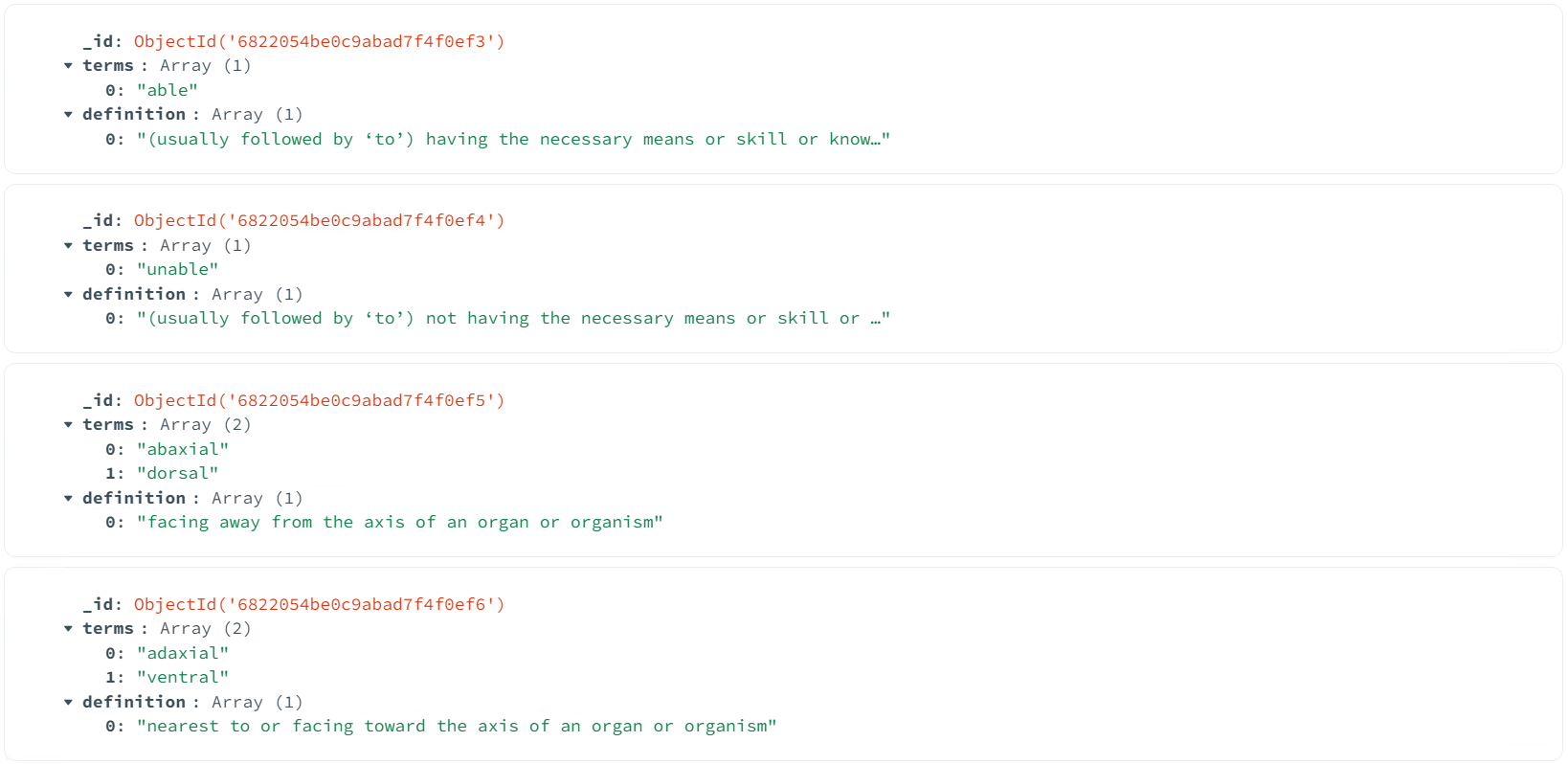
为搭建语言索引库,需对这些词语进行自然语言处理。以中文处理为例,首先利用spacy的中文模型(zh_core_web_sm)对定义进行分词和词性标注,提取名词、动词和形容词作为关键词,过滤停用词(中文停用词来自github项目stopwords,对其进行了合并处理),再使用SentenceTransformer(all-MiniLM-L6-v2)生成定义的嵌入向量,用于表示文本的语义。处理后的数据结构为一个字典,参见下面函数的返回值。
def process_chinese_term(term, definition, embedder_cache=None):
if embedder_cache is None:
embedder_cache = {}
doc = nlp_zh(definition)
keyword_pos_pairs = [(token.text, token.pos_) for token in doc if token.text not in stop_words_zh and token.pos_ in ["NOUN", "VERB", "ADJ"]]
seen = set()
keyword_pos_pairs = [(k, p) for k, p in keyword_pos_pairs if not (k in seen or seen.add(k))]
keywords, pos = zip(*keyword_pos_pairs) if keyword_pos_pairs else ([], [])
if definition not in embedder_cache:
embedder_cache[definition] = embedder.encode(definition).tolist()
embedding = embedder_cache[definition]
return {
"term": term,
"definition": definition,
"keywords": list(keywords),
"pos": list(pos),
"embedding": embedding
}
在主函数中运行以下内容即处理所有中文词语,由于数据量巨大,与数据库的交互使用了session与no_cursor_timeout参数防止cursor超时,为提高操作效率使用到了batch_size。
embedder_cache = {}
chinese_index = {}
with client.start_session() as session:
with chinese_collection.find(no_cursor_timeout=True, session=session).batch_size(100) as cursor:
for doc in cursor:
term = doc["term"]
definition = doc["definition"]
chinese_index[term] = process_chinese_term(term, definition, embedder_cache)
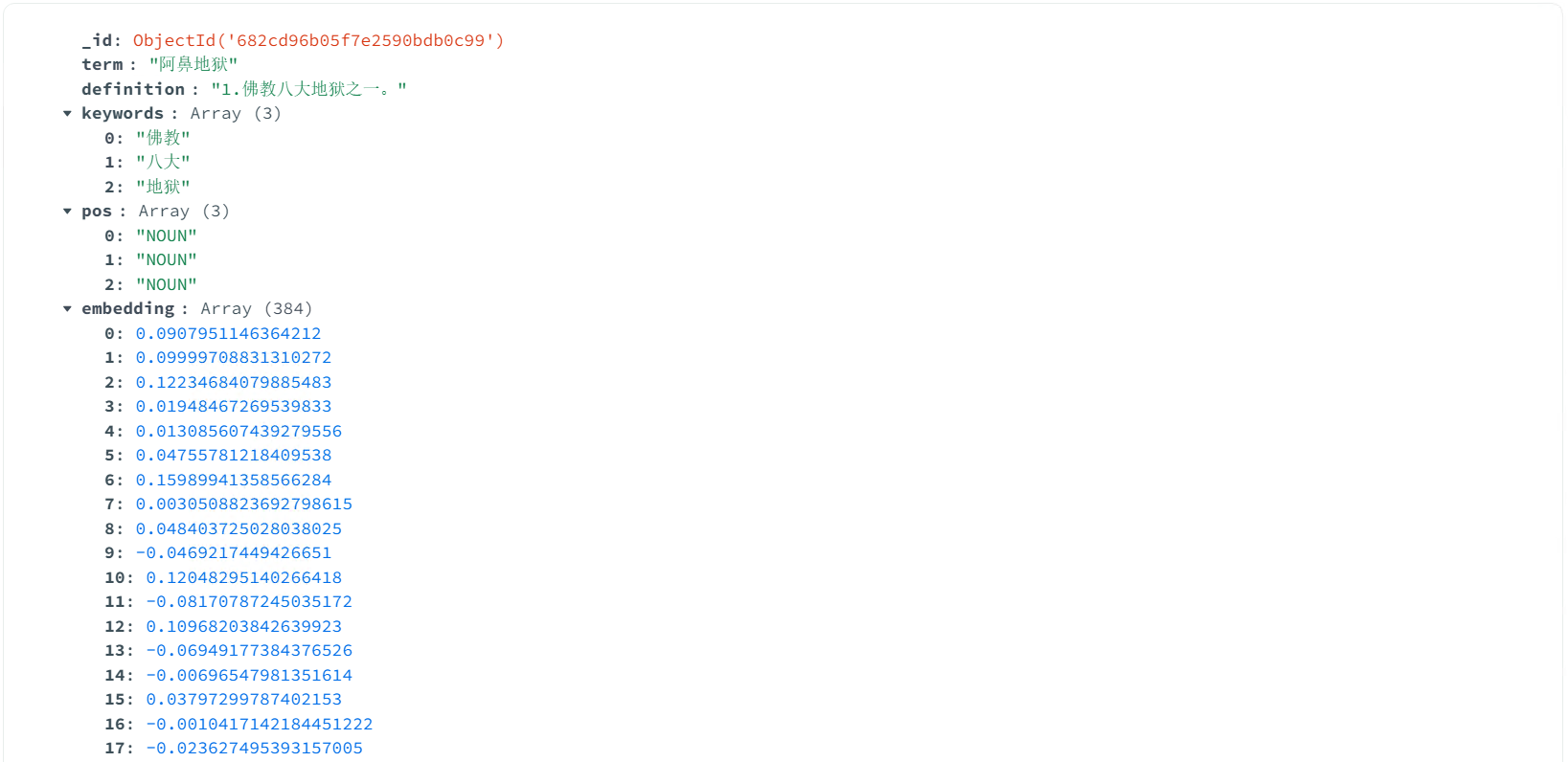
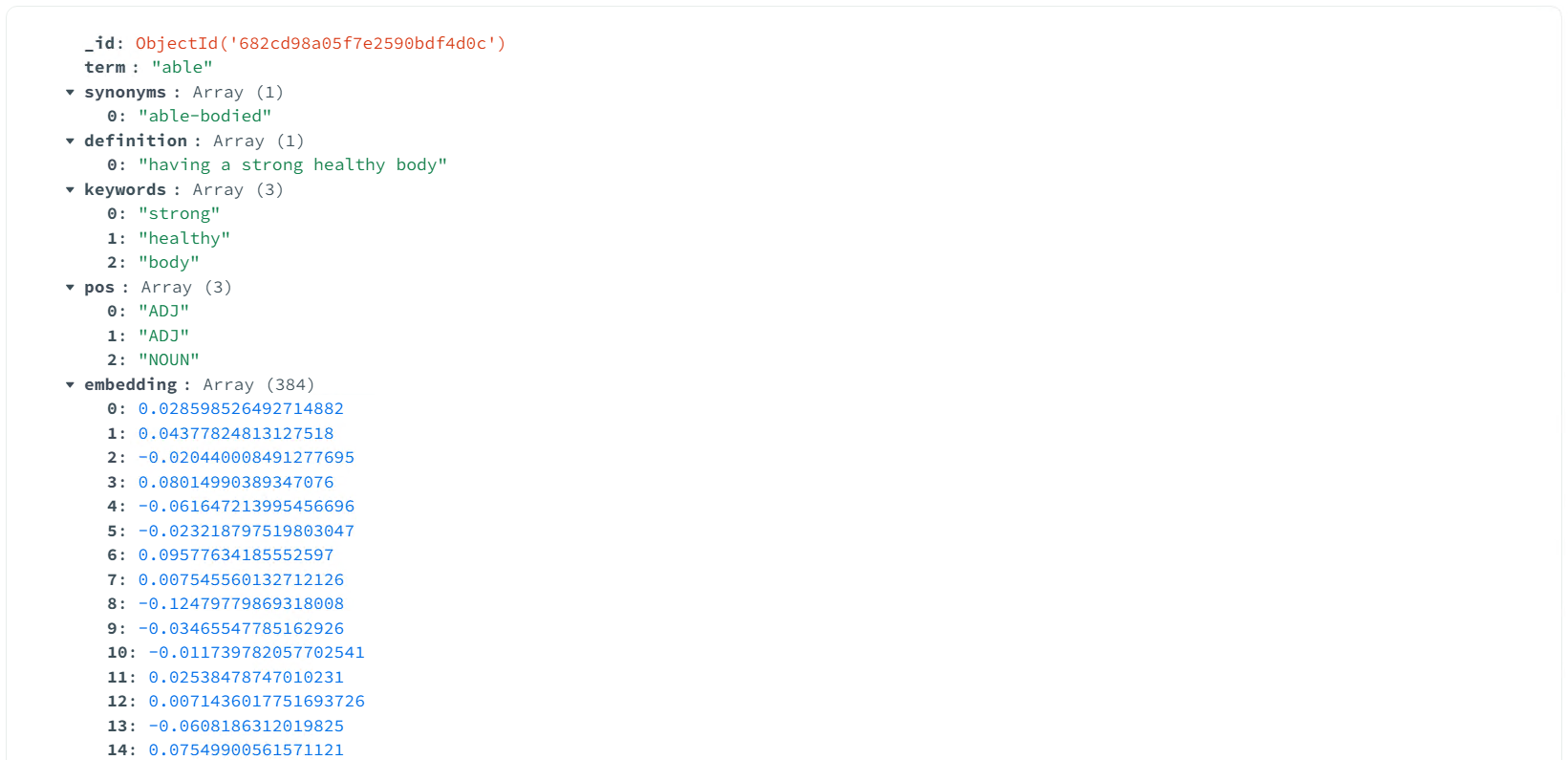
以下是处理完成并存入数据库的中英数据。
二、文风转换及文章润色功能文本数据预处理
在前期收集的文本基础上,增加了Hugging Face上的开源数据集IndustryCorpus2中的高质量分层数据。对于该数据集中的数据,本欲直接根据quality_score排序后直接取排名靠前的数据作为训练数据,但调试时发现其中存在内容几乎完全一致,仅存在略微差异的文章,如下图中下标为2和3的两篇。
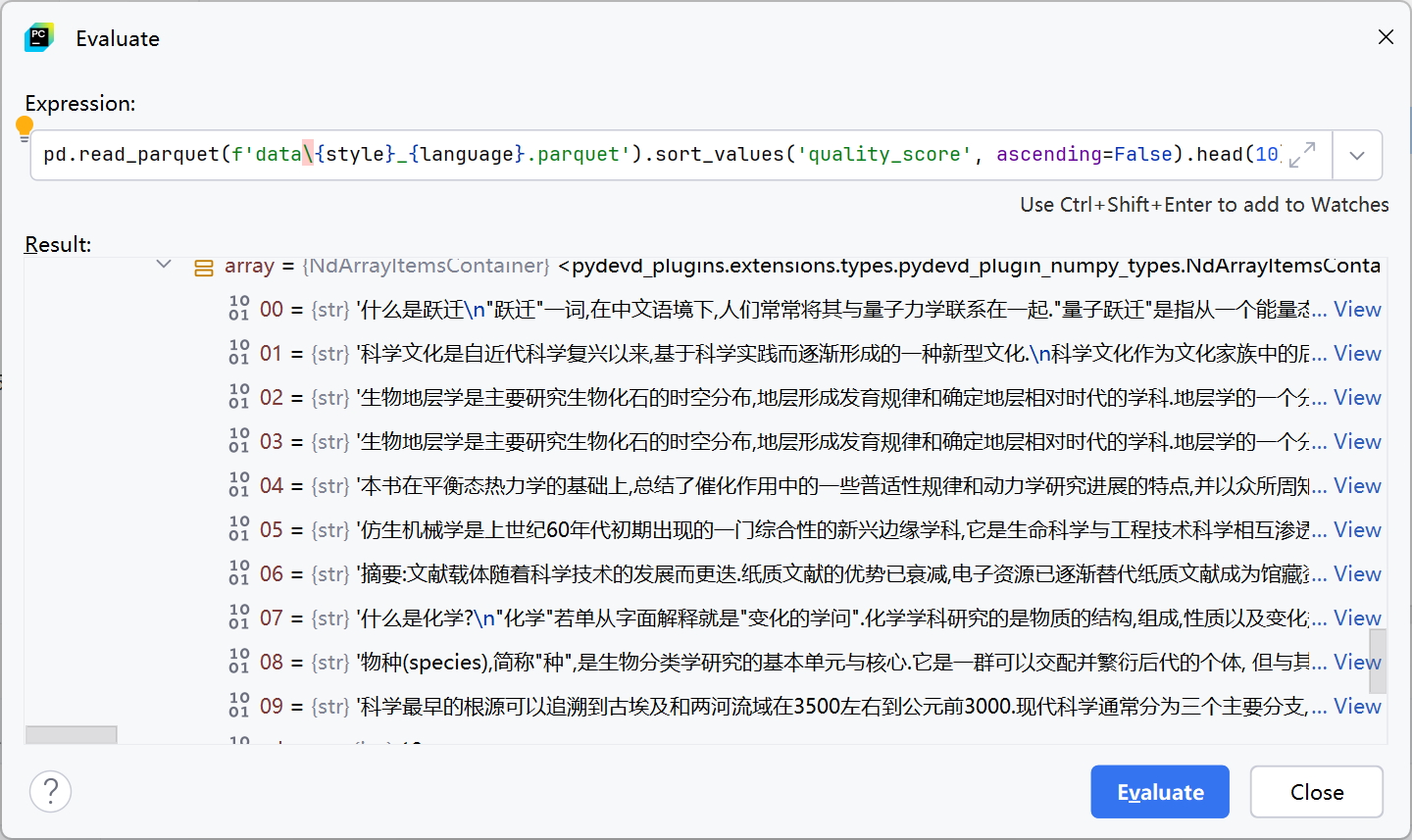
这些文章可以认为是重复的,但无法直接用pandas库提供的去重方法去重(如drop_duplicates),因此采用基于文本相似度的方法为其去重,下述去重思路与代码。
要保留的数据有科技、医疗、财经、法律4行业,中英双语共组合成8个文件,每个文件15000条数据,为尽量减小处理的数据量,同时确保去重后的数据量足够,每个原始数据集在经过上述排序后保留前30000条,仅保留text列,并添加一列style。
之后使用jieba对每篇文章进行分词,并将结果存入一个新列。随后将文本向量化,初始化一个TfidfVectorizer,同时限制特征数量最多为10000以优化性能,调用fit_transform将新列转为稀疏矩阵。
转换完毕后进行DBSCAN聚类,首先初始化DBSCAN,指定一系列参数:eps=0.05对应余弦相似度0.95,控制簇内文本的最大距离;min_samples=1允许单个文本形成簇,确保不丢失孤立文本;metric='cosine’使用余弦距离,适合文本向量比较;n_jobs=-1利用多核并行计算,加速处理大量数据。随后调用fit对向量矩阵进行聚类,其结果的labels_属性是一个数组,为每条文本分配簇标签,将其添加给df作为一个新列cluster。
接下来调用groupby(‘cluster’).first()去重,重置索引,并仅保留前15000条。随后选择text和style列,丢弃数据处理过程中新增的两列,这样就得到了去重的,根据quality_score排序的数据,最后将其存为csv文件以备将来使用。完整代码如下:
import jieba
import pandas as pd
from sklearn.cluster import DBSCAN
from sklearn.feature_extraction.text import TfidfVectorizer
SIMILARITY_THRESHOLD = 0.95
EPSILON = 0.05
def tokenize(text):
return ' '.join(jieba.cut(text, cut_all=False))
vectorizer = TfidfVectorizer(max_features=10000)
for style in ['technology', 'medicine', 'finance', 'law']:
for language in ['zh', 'en']:
df = pd.read_parquet(f'data\{style}_{language}.parquet').sort_values('quality_score', ascending=False).head(30000).reset_index(drop=True)[['text']].assign(style=style)
df['text_tokens'] = df['text'].apply(tokenize)
X = vectorizer.fit_transform(df['text_tokens'])
clustering = DBSCAN(eps=EPSILON, min_samples=1, metric='cosine', n_jobs=-1).fit(X)
df['cluster'] = clustering.labels_
deduplicated_df = df.groupby('cluster').first().reset_index(drop=True).head(15000)
deduplicated_df = deduplicated_df[['text', 'style']]
deduplicated_df.to_csv(f'result\{style}_{language}.csv', index=False)
问题描述
文本数据量巨大,对其的处理往往要花上数小时甚至更久,这是前期没有考虑到的一个问题,之后在设计处理数据的程序时要考虑执行效率和时间。
下阶段任务
对现有数据做更进一步的处理。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 22
22 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)