基于Python代码机器学习的汽车购买用户类型分析
基于Python代码机器学习的汽车购买用户类型分析数据➕代码➕报告报告采用Python代码,字数共4500字左右,数据集8000条运用了随机森林和朴素贝叶斯模型进行数据建模与预测,并对模型效果进行了对比。机器学习,建模,数据清洗,数据分析。分析了不同用户类型对汽车购买的影响因素,如婚姻状态、年龄、职业、消费水平等
基于Python代码机器学习的汽车购买用户类型分析
数据➕代码➕报告
报告采用Python代码,字数共4500字左右,数据集8000条
运用了随机森林和朴素贝叶斯模型进行数据建模与预测,并对模型效果进行了对比。
机器学习,建模,数据清洗,数据分析。
分析了不同用户类型对汽车购买的影响因素,如婚姻状态、年龄、职业、消费水平等
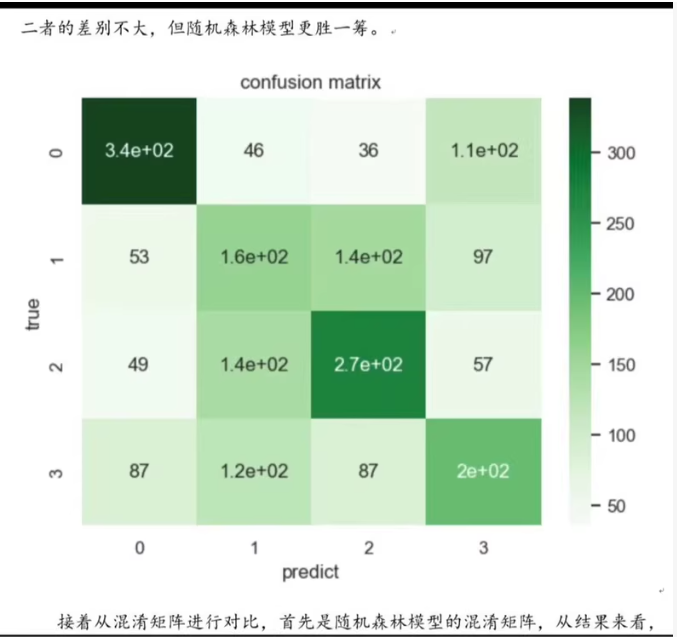
为了基于Python代码构建一个机器学习模型来分析汽车购买用户类型,我们需要经过数据收集、预处理、探索性数据分析(EDA)、特征工程、模型选择和训练等步骤。以下是一个示例项目流程,包括必要的代码片段。
1. 安装必要的库
首先确保安装了以下Python库:
pip install numpy pandas scikit-learn matplotlib seaborn
2. 数据准备与预处理
假设我们有一个包含客户信息的数据集,这些信息可能包括年龄、性别、年收入、信用评分等,并且每个客户都有一个标签表示他们是否购买了汽车(例如:0代表未购买,1代表购买)。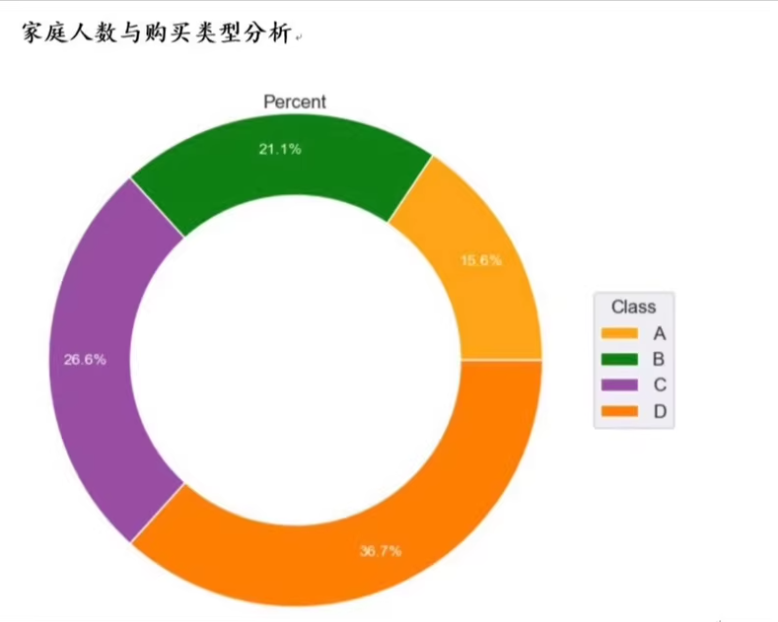
加载并预处理数据
# car_purchase_data_preprocessing.py
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, LabelEncoder
def load_and_preprocess_data(file_path='car_purchase_data.csv'):
# 加载数据
df = pd.read_csv(file_path)
# 查看数据基本信息
print("Data head:")
print(df.head())
# 特征与标签分离
X = df.drop('Purchased', axis=1) # 假设'Purchased'是目标变量
y = df['Purchased']
# 对分类变量进行编码
for column in X.select_dtypes(include=['object']).columns:
le = LabelEncoder()
X[column] = le.fit_transform(X[column])
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 特征缩放
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
return X_train, X_test, y_train, y_test
3. 探索性数据分析(EDA)
在开始建模之前,做一些简单的EDA可以帮助我们更好地理解数据。
# eda.py
import seaborn as sns
import matplotlib.pyplot as plt
def exploratory_data_analysis(df):
# 绘制各特征之间的相关性热图
plt.figure(figsize=(10,8))
sns.heatmap(df.corr(), annot=True, fmt=".2f")
plt.show()
# 检查目标变量分布
sns.countplot(x='Purchased', data=df)
plt.title('Distribution of Purchased')
plt.show()
4. 构建并训练模型
我们将尝试几种不同的机器学习模型(如逻辑回归、随机森林、支持向量机),以找到最适合这个任务的模型。
# model_building.py
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report
def train_models(X_train, X_test, y_train, y_test):
models = {
"Logistic Regression": LogisticRegression(max_iter=1000),
"Random Forest": RandomForestClassifier(n_estimators=100),
"SVM": SVC(probability=True)
}
trained_models = {}
for name, model in models.items():
print(f"Training {name}...")
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
trained_models[name] = model
print(f"{name} Accuracy: {accuracy:.4f}")
print(report)
return trained_models
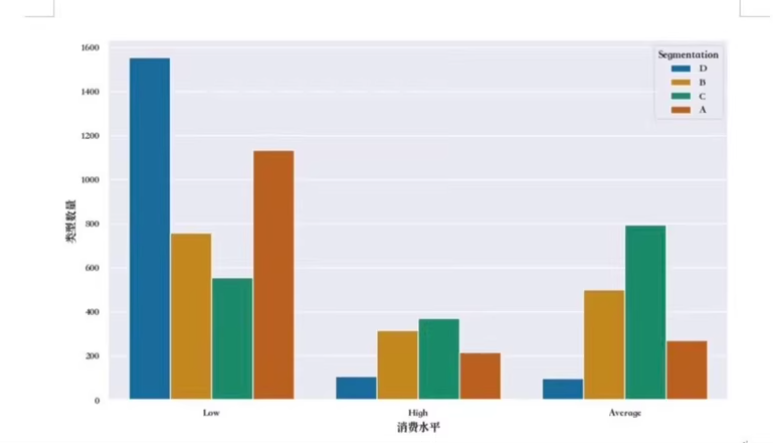
5. 主程序执行
将所有部分组合在一起,并运行整个流程。
# main.py
if __name__ == "__main__":
# 数据文件路径
file_path = 'car_purchase_data.csv'
# 加载数据
df = pd.read_csv(file_path)
# EDA
exploratory_data_analysis(df)
# 加载并预处理数据
X_train, X_test, y_train, y_test = load_and_preprocess_data(file_path)
# 训练模型
trained_models = train_models(X_train, X_test, y_train, y_test)
注意事项
- 数据集:请根据实际情况调整代码中的数据加载部分。如果使用公开数据集,请确保遵守其使用条款。
- 特征工程:在实际应用中,你可能需要对原始数据进行更多的特征工程工作,比如创建交互项、处理缺失值等。
- 模型选择:这里仅提供了三种基础模型作为示例。你可以根据实际情况尝试更多类型的模型,并利用交叉验证等技术来优化模型选择过程。
- 评估指标:除了准确率之外,考虑使用其他评估指标(如精确率、召回率、F1分数等)来更全面地评价模型性能。
通过上述步骤,你应该能够建立起一个基本的机器学习模型用于分析汽车购买用户类型。


脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 43
43 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)