Agent目前最全综述-ADVANCES AND CHALLENGES IN FOUNDATION AGENTS-2
本文探讨了智能体(如LLM)与人类认知系统的对比与融合。人类认知具有多脑区协同学习、结构化/非结构化推理和动态适应性等特点,而LLM通过预训练、微调和强化学习模拟类似机制。文章分析了两种学习方式:全心理状态学习(修改基础模型参数)和部分心理状态学习(调整特定认知组件)。在推理层面,对比了结构化(显式逻辑)和非结构化(隐式模式)方法,并探讨了规划中的长程整合挑战。当前LLM在感知、推理和世界理解方面
智能体的核心组件-Chapter 2
一、人类认知系统的本质:生物智能的核心特性
1. 心理状态:认知运作的基础
-
定义:心理状态指大脑在特定时刻的神经活动模式,涵盖感知、记忆、情绪、目标等多维度信息(如“看到红色苹果”的视觉表征、“想吃苹果”的动机)。
-
作用:
-
作为学习与推理的载体,例如通过工作记忆临时存储信息进行逻辑运算(如计算“2+3×4”时需记住运算顺序)。
-
动态更新以适应环境变化,如看到“前方修路”标志后,立即调整导航路线(目标导向的心理状态调整)。
-
2. 三大核心架构特性
(1)跨层次学习能力
-
脑区协作:
-
额叶(高阶认知)与颞叶(记忆/语言)协同实现整体学习(如学习新语言时,额叶规划学习策略,颞叶存储词汇语法)。
-
小脑等区域支持局部技能优化(如练习打字时,小脑通过误差校正逐步提升手指协调性)。
-
-
研究层级映射:
-
图1.1中“L1-L3”对应不同学习成熟度(如视觉感知属L1,已高度成熟;自我意识属L3,尚处探索阶段)。
-
(2)推理的结构化与灵活性
-
结构化推理:
-
依赖逻辑规则与预设模板(如数学证明、编程算法),由前额叶皮层的背外侧区域主导,需抑制无关信息干扰。
-
-
非结构化推理:
-
适应模糊情境(如创意构思、社交互动),依赖前额叶腹内侧区域与边缘系统的情感整合(如根据对方表情判断话语隐含意图)。
-
-
决策差异:
-
结构化推理追求最优解(如棋类AI的穷举搜索),非结构化推理侧重适应性(如人类在交通拥堵时即兴选择替代路线)。
-
(3)动态适应性:经验驱动的持续优化
-
监督反馈:
-
类似小脑的“误差校正机制”,如投篮时通过视觉反馈调整手臂角度(感觉运动协调)。
-
-
无监督学习:
-
从环境统计中自发提取规律(如婴儿通过观察成人行为学习手势含义),对应大脑默认模式网络的“静息态学习”。
-
二、认知系统的模块化架构:生物智能的分工与协同
1. 核心功能模块解析
|
模块 |
生物对应 |
功能描述 |
LLM代理的近似技术 |
|
感知系统 |
视觉/听觉皮层等 |
将感官信号(如光子、声波)转化为神经表征(如物体形状、语音语义) |
CNN(视觉)、语音识别模型(如Whisper) |
|
记忆系统 |
海马体+新皮层 |
短期记忆(工作记忆)存储即时信息,长期记忆存储经验与知识(如“昨天的会议内容”) |
向量数据库(短期)、知识图谱(长期) |
|
世界模型 |
前额叶预测编码机制 |
模拟环境动态(如“推杯子→杯子移动”),支持行为后果预判 |
物理模拟器(如Gazebo)、因果推理模型 |
|
奖励系统 |
多巴胺能通路(如腹侧被盖区) |
通过愉悦感强化有益行为(如进食、社交),驱动动机(如“完成任务获得奖励”) |
强化学习(RL)的奖励函数设计 |
|
情绪系统 |
边缘系统(杏仁核、海马体) |
调节注意力(如恐惧时聚焦危险信号)、影响决策优先级(如焦虑时优先处理紧急任务) |
情感分析模型(如SentiBERT) |
|
推理系统 |
前额叶皮层 |
逻辑推理、问题解决、目标分解(如“规划旅行路线”) |
LLM的逻辑推理能力(如GPT-4的Chain-of-Thought) |
|
行动系统 |
运动皮层+脊髓 |
执行物理动作(如行走)或语言动作(如表达观点) |
机器人控制算法、文本生成模型 |
2. 模块间协同机制
-
神经通路连接:
-
前额叶与顶叶通过神经纤维束传递空间信息(如驾驶时判断车距)。
-
边缘系统与前额叶交互调节情绪对决策的影响(如愤怒时抑制冲动行为需前额叶的执行控制)。
-
-
信息流动示例:
-
看到食物(感知系统)→ 激活味觉记忆(记忆系统)→ 产生食欲(情绪系统)→ 决定进食(推理系统)→ 伸手抓取(行动系统),全程伴随奖励预期(多巴胺释放)。
-
三、生物认知与LLM代理的对比:启发与差距
1. 生物启发的LLM代理设计方向
-
模块化整合:
-
借鉴大脑的“感知-认知-行动”分层架构,避免当前LLM代理的“拼凑式设计”(如独立的视觉模块与语言模块难以协同)。
-
案例:多模态大模型(如Flamingo、PaLM-E)尝试整合视觉Transformer与LLM,模拟人类跨模态关联能力(如“看到图片中的狗”并生成相关描述)。
-
-
动态适应性学习:
-
开发“持续学习”算法,避免灾难性遗忘(如人类学习新技能时不会忘记旧技能),可参考海马体的“记忆巩固”机制。
-
-
具身智能与物理交互:
-
通过模拟小脑的运动协调功能,提升机器人的精细操作能力(如用筷子夹取物体),当前强化学习在机械臂控制中已取得初步进展。
-
2. 当前LLM代理的核心局限
-
缺乏具身经验:
-
人类认知高度依赖物理交互(如触摸感知物体质地),而LLM仅通过文本训练,导致“语义 grounding”不足(如理解“柔软”一词但无法实际感知)。
-
-
推理的脆弱性:
-
结构化推理(如数学题)表现优异,但面对模糊情境(如歧义语句解读)时易出错,缺乏人类的常识与直觉(如“椅子可以用来堵门”的非常规用途推理)。
-
-
情绪与动机的表面化:
-
现有情感分析仅停留在文本极性判断(如“高兴”或“悲伤”),无法模拟人类复杂情绪的层级性(如“失望中带有一丝希望”),更无内在动机驱动(如好奇心引发的探索行为)。
-
暂时无法在飞书文档外展示此内容
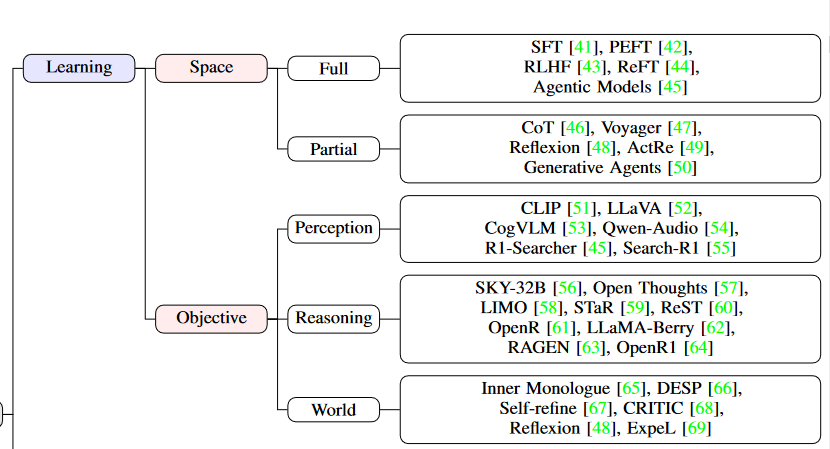
2.1 学习
学习是智能体将经验转化为心理状态中知识的基本过程。这一转化发生在不同的认知空间中,从心理状态的整体更新到特定认知组件的优化。学习的范围涵盖了多种能力,服务于不同目标:增强感知理解、提升推理能力、构建更丰富的世界认知。
一、人类学习的机制与特点
人类学习通过大脑适应性神经网络在多个空间和目标上运作,核心机制体现在以下方面:
-
多脑区协同的整体学习
-
海马体:负责快速编码情景记忆(如日常事件),支持 episodic 学习。
-
小脑:通过监督学习(如错误校正)精细化运动技能(如骑自行车)。
-
基底神经节:利用多巴胺奖励信号实现强化学习,驱动行为优化(如习惯养成)。
-
皮层区域:通过无监督学习提取环境模式(如语言规律、视觉特征)。
-
跨脑区协作:例如,前额叶皮层整合多脑区信息,支持复杂决策和目标导向行为。
-
-
特定神经回路的靶向适应
-
局部神经回路可针对特定任务强化,如音乐家的听觉-运动回路优化,或数学家的逻辑推理神经通路增强。
-
学习过程受注意力、情绪、社会环境等因素调节。例如,情绪唤醒(如压力或愉悦)会增强记忆巩固,社会互动(如教学)加速知识传递。
-
-
时间尺度的连续性
-
从即时反应(如条件反射)到终身学习(如职业技能发展),人类学习贯穿不同时间维度,依赖神经可塑性(如突触强度调整)。
-
二、LLM智能体的学习模式
LLM(大型语言模型)智能体虽架构与人类大脑迥异,但通过算法模拟了类似的学习过程:
-
整体层面的无监督学习
-
通过预训练(Pre-training)在海量文本数据中提取统计规律,实现对世界知识的泛化表征。例如,GPT模型通过Transformer架构学习语言结构和常识知识。
-
-
聚焦层面的参数优化
-
监督微调(Supervised Fine-tuning):针对特定任务(如问答、翻译)用标注数据优化模型参数,提升专项能力。
-
强化学习(Reinforcement Learning, RL):结合奖励信号(如人类反馈RLHF)调整行为策略,例如优化对话连贯性或事实准确性。
-
-
上下文学习(In-Context Learning, ICL)
-
无需更新参数,通过注意力机制利用输入上下文中的示例实现任务适应。例如,给定 few-shot 提示后,模型可模仿示例生成符合格式的回答,类似人类的“工作记忆”推理,但依赖算法而非神经活动。
-
三、人类与LLM学习的对比与启示
|
维度 |
人类学习 |
LLM智能体学习 |
|
数据效率 |
少量样本即可泛化(如识别新物体) |
依赖海量数据(数十亿token级预训练) |
|
情境整合 |
深度结合物理环境、情绪和社会经验 |
依赖文本数据,情境理解较抽象 |
|
跨域迁移 |
灵活迁移(如从驾驶经验类比到飞行模拟) |
需显式微调或提示引导跨任务适应 |
|
学习目标 |
生存、社交、自我实现等复杂目标 |
优化预定义指标(如困惑度、准确率) |
互补性与研究方向:
-
人类学习的高效性和情境感知为AI提供灵感,例如开发小样本学习(Few-shot Learning)或具身智能(Embodied AI)。
-
LLM的大规模数据处理和形式化知识表征可弥补人类认知局限,例如辅助科学发现或复杂系统建模。
-
未来研究可探索“神经符号”融合架构,结合生物启发的模块化学习与符号推理,提升AI的适应性和可解释性。
四、学习的空间与目标解析
-
学习空间(Mental State Spaces)
-
整体空间:更新全局认知模型(如世界观、价值观的改变)。
-
局部空间:优化特定模块(如语言理解中的语法规则,或视觉感知中的物体检测)。
-
-
学习目标
-
感知增强:提升对环境信号的解析能力(如语音识别中的降噪)。
-
推理优化:改进逻辑推导、因果推断等高级认知功能(如数学证明、策略规划)。
-
世界建模:构建更真实的环境动态模型(如预测物理系统行为或社会趋势)。
-
通过剖析学习的空间与目标,研究者可针对性地设计算法,推动智能体从“数据驱动”向“认知启发”的范式升级,最终实现更接近人类水平的适应性与泛化能力。
2.1.1 学习空间
一、人类学习 vs. LLM代理学习
|
维度 |
人类学习 |
LLM代理学习 |
|
驱动方式 |
情感驱动(好奇心、动机、情绪强化) |
数据驱动(参数更新、结构化记忆形成) |
|
学习过程 |
探索性、依赖经验积累和直觉 |
形式化(预训练、微调、强化学习等) |
|
核心目标 |
适应复杂环境、解决开放问题 |
优化模型参数、对齐人类偏好 |
关键结论:当前研究试图结合两者优势——用计算系统的高效性模拟人类学习的灵活性(如好奇心、反思能力)。
二、智能代理的学习空间:模型与心理状态
1. 内部状态定义
智能代理的内部状态由两部分组成:
-
基础模型(θ):决定代理的底层能力(如语言理解、推理逻辑),类似人类大脑的神经架构。
-
心理状态(M):包括5个核心组件:
-
M_mem(记忆):存储经验、知识和历史交互数据。
-
M_wm(世界模型):对外部环境的理解和预测(如因果关系、物理规则)。
-
M_emo(情绪状态):模拟情感对决策的影响(部分研究尝试引入)。
-
M_goal(目标):任务导向的意图(如完成对话、解决问题)。
-
M_rew(奖励信号):衡量行为效果的反馈机制(类似人类的“奖惩感知”)。
-
2. 学习的两种类型
根据是否修改基础模型θ,学习可分为全心理状态学习和部分心理状态学习。
三、全心理状态学习:重塑基础模型
定义:通过修改模型参数θ,全面更新代理的能力,影响所有心理状态组件(M_mem、M_wm等)。
核心方法:
-
预训练
-
目标:通过海量数据(如互联网文本)学习通用知识,类似人类婴儿的“环境信息吸收”。
-
案例:GPT系列通过预训练获取语言理解和生成能力。
-
-
训练后技术
-
监督微调(SFT):用人类标注数据直接调整模型权重(如InstructGPT学习遵循指令)。
-
参数高效微调(PEFT):
-
Adapter-BERT:仅修改少量“适配器”模块,而非全部参数,降低计算成本。
-
LoRA(低秩自适应):通过矩阵分解减少需调整的参数数量,适用于资源受限场景。
-
-
对齐人类偏好
-
RLHF(人类反馈强化学习):训练奖励模型评估代理输出与人类偏好的一致性,再用强化学习优化策略(如ChatGPT的“无害性”对齐)。
-
DPO(直接偏好优化):无需显式奖励模型,直接根据人类偏好排序数据训练,简化流程。
-
-
强化学习(RL)
-
目标:在特定环境中(如游戏、工具操作)通过试错学习优化行为策略。
-
案例:
-
ReFT:通过采样推理路径并施加奖励信号,增强数学推理能力。
-
DigiRL:在安卓模拟器中通过两阶段RL学会执行手机操作指令。
-
特点:能力提升全面但成本高(需重新训练模型参数),适合需要根本性改进的场景。
四、部分心理状态学习:聚焦特定组件
定义:不修改基础模型θ,仅调整心理状态M的特定组件(如记忆、奖励模型),实现高效局部优化。
核心方法:
-
上下文学习(ICL)
-
机制:通过输入示例或指令(如“少样本提示”),在上下文窗口内临时调整代理行为,类似人类的“工作记忆”。
-
案例:思维链(CoT)通过分步提示提升逻辑推理能力,无需重新训练模型。
-
-
记忆与技能更新
-
Generative Agents:通过社交互动积累记忆并“复盘”,生成高层次策略(如模拟人类日常规划)。
-
Voyager:在《我的世界》中通过环境交互直接更新技能库,无需模型再训练(即学即用)。
-
-
反思与错误修正
-
Reflexion:从试错中获取文本反馈,引导代理调整后续决策(类似人类“吃一堑长一智”)。
-
-
奖励与世界模型优化
-
ARMAP:从代理行为轨迹中提炼奖励模型,优化环境反馈机制。
-
ActRe:利用LLM预测动作后果,增强对“世界模型”(M_wm)的理解,提升任务规划能力。
-
特点:轻量级、响应快,适合实时适应新任务或环境,但能力提升局限于特定组件。
五、总结:两种学习的互补性
-
全心理状态学习是“地基”:决定代理的本质能力(如推理上限、知识广度),需大量数据和算力。
-
部分心理状态学习是“微调”:在不改变地基的前提下,通过灵活调整“心理组件”快速适应场景(如对话风格、专业领域知识)。
-
未来趋势:结合两者构建更接近人类的智能体,例如用预训练(全学习)奠定基础,再通过ICL和RL(部分学习)实现动态适应。
通过这种分层学习框架,LLM代理正逐步从“被动执行指令”向“主动学习、自主决策”演进。
2.1.2 学习目标
一、智能代理的学习目标:多层次交互框架
智能代理的学习是一个 “感知-处理-理解”的闭环过程,旨在通过与环境的动态交互实现能力进化。具体分为三个层级:
-
输入层(感知):学会解析视觉、语言、音频等多模态环境信息(如识别图像中的物体、理解用户指令)。
-
处理层(推理):基于已有知识和逻辑框架,对信息进行分析、推理和决策(如数学解题、工具调用规划)。
-
理解层(世界模型):通过持续交互构建“环境因果关系”的认知(如动作与结果的关联、物理规则建模)。
核心目标:使代理能在复杂场景中自主适应(如自动驾驶应对突发路况、AI助手处理模糊指令),而非被动执行预设规则。
二、提升感知能力的学习:从单模态到主动检索
感知能力决定了代理“能获取什么信息”,是智能的基础。当前研究通过多模态融合和外部知识检索突破人类生物感知的局限。
1. 多模态感知:模拟人类五感,突破数据类型限制
-
技术逻辑:将图像、文本、音频等不同模态数据映射到统一的语义空间,使代理能跨模态关联信息(如“猫”的图片与“cat”的文本对应)。
-
关键模型:
-
CLIP [51]:首次实现视觉图像与文本描述的对齐,例如输入“骑自行车的狗”可匹配对应图片,用于图像检索和生成。
-
LLaVA [52]:在CLIP基础上增加视觉投影层,通过“图像-文本对”训练,使模型能描述图片内容(如“图中是一只在草地上追蝴蝶的金毛犬”)。
-
Qwen-Audio [54]:将语音、环境音(如雨声、汽车鸣笛)编码为统一特征向量,支持语音识别、情感分析等任务。
-
-
前沿方向:触觉感知研究[115]通过触觉传感器数据与视觉、语言对齐,使代理能理解“软硬”“冷热”等物理属性(如机器人抓取物体时的力度控制)。
2. 检索机制:超越即时感官,整合外部知识
-
核心思路:人类感知受限于当前环境(如无法“记住”所有百科知识),而代理可通过检索外部知识库(如维基百科、数据库)补充信息。
-
典型方法:
-
RAG [116](检索增强生成):在回答问题时,先检索相关文档片段,再结合检索结果生成回答,避免“幻觉”(如回答“埃菲尔铁塔高度”时,先查数据再回复)。
-
Search-o1 [117]:通过提示词引导模型主动检索(如“请搜索2024年全球气温数据”),将检索结果作为推理依据。
-
R1-Searcher [45]:将检索模块嵌入模型架构,使代理在推理过程中自动触发检索(如解决数学题时查找公式定义),减少对预设知识的依赖。
-
应用价值:多模态感知让代理“能看会听”,检索机制让代理“博闻强识”,两者结合使代理能处理图文混合指令、跨领域知识问答等复杂任务。
三、提升推理能力的学习:从数据驱动到反馈优化
推理能力决定了代理“如何利用信息做决策”,是智能的核心。当前研究围绕高质量数据和反馈机制展开,解决“知识激活”与“路径优化”问题。
1. 高质量推理数据:激活模型内置知识
-
数据蒸馏:从大型模型(如GPT-4)中提取推理逻辑,训练更小模型(如320亿参数的SKY-32B),降低成本的同时保留推理能力。
-
结构化推理链:
-
LIMO [58]:对复杂问题(如法律案件分析),通过人工构建长推理链(“证据→法律条文→判决依据”),即使仅用100个样本也能训练出强推理模型。
-
思维链(CoT):Li等人[119]发现,模型通过CoT学习的是“先分解问题、再逐步验证”的思维结构,而非具体知识点(如数学题的解题步骤而非答案)。
-
2. 反馈机制:优化推理路径,减少错误
-
自举范式(Bootstrap):
-
STaR [59]:模型先尝试生成推理步骤,保留正确路径并微调,迭代提升推理准确性(如数学题先试算多种解法,保留正确步骤)。
-
rStar-Math [121]:结合强化学习,对正确推理路径给予奖励,错误路径惩罚,针对性提升数学推理能力。
-
-
强化学习与树搜索:
-
ReST-MCTS [122]:用蒙特卡洛树搜索(MCTS)模拟多种推理路径,通过奖励模型(PRM)评估每条路径的合理性,选择最优解(如医疗诊断中模拟不同治疗方案的效果)。
-
OpenR [61]:将推理视为马尔可夫决策过程(MDP),每个推理步骤是“状态-动作”的转移,通过树搜索探索全局最优解。
-
3. 推理与工具结合:扩展能力边界
-
Qwen-QwQ-32B [118]:通过强化学习训练模型在推理时自动调用工具(如计算器、地图API),例如计算“两地距离”时直接调用地图工具,而非依赖内置知识。
-
RAGEN [63]:在多步任务(如“规划旅行路线”)中,结合检索和工具调用,构建“检索信息→推理规划→工具执行”的闭环。
核心挑战:如何平衡推理的“准确性”与“效率”?例如,复杂推理需多步验证,但实时任务(如自动驾驶)要求快速决策。当前通过轻量化模型(如LoRA微调)和硬件加速(GPU/TPU)缓解这一矛盾。
四、提升世界理解能力的学习:从经验积累到因果建模
世界理解能力决定了代理“如何预测环境变化”,是智能的高阶目标。核心是通过交互构建因果关系模型(如“按下开关→灯亮”)和经验复用机制。
1. 经验学习:从“试错”到“系统化复盘”
-
基础交互:
-
Inner Monologue [65]:代理通过自言自语(如“我现在需要开门,首先要找到门把手”)模拟人类思考过程,积累基础动作经验。
-
Voyager [47]:在《我的世界》中通过不断挖矿、建造,自动更新技能库(如学会“用木材和石头制作工具”),无需人工编程。
-
-
经验复盘:
-
Generative Agents [50]:模拟人类记忆系统,每天“复盘”经历并提炼规律(如“每天早上8点浇水,植物生长更快”),用于后续决策。
-
Reflexion [48]:每次失败后生成反思报告(如“因未考虑天气因素导致野餐计划失败”),避免重复错误。
-
2. 奖励与世界模型优化:对齐目标与环境规则
-
Text2Reward [105]:用户通过自然语言反馈(如“这个回答不够详细”),模型自动调整奖励函数,使输出更符合需求(如增加细节描述)。
-
RAP [74]:用LLM同时作为“推理代理”和“世界模型”,在行动前模拟后果(如“如果我现在浇水,3小时后土壤会变湿吗?”),通过MCTS选择最优动作,类似人类“三思而后行”。
3. 认知地图与物理模拟:类人化环境建模
-
认知地图研究[128]:受人类大脑“海马体空间记忆”启发,构建结构化心理表征,使代理能在新环境中快速推断空间关系(如进入陌生房间后,推测“门在左侧,窗户在前方”)。
-
网页环境应用[107]:在点击网页按钮前,用LLM模拟点击后的页面变化(如“点击‘删除’按钮会永久删除文件吗?”),避免不可逆操作风险。
应用场景:机器人导航(如扫地机器人避开障碍物)、虚拟助手任务规划(如安排会议时考虑参与者时区)、游戏AI策略制定(如《星际争霸》中预判对手行动)。
五、总结:从“人工设计”到“自主进化”的智能跃迁
|
维度 |
核心方法 |
目标效果 |
典型案例 |
|
感知 |
多模态融合、检索增强 |
识别复杂环境信息,跨领域关联知识 |
LLaVA描述图片、RAG回答专业问题 |
|
推理 |
数据蒸馏、强化学习、树搜索 |
逻辑严谨、可解释的决策过程 |
STaR数学推理、Qwen-QwQ-32B工具调用 |
|
世界理解 |
经验复盘、因果建模、认知地图 |
预测环境动态,自主优化行为策略 |
Voyager游戏技能学习、RAP路径规划 |
未来趋势:
-
具身智能(Embodied AI):将感知、推理与物理实体(如机器人)结合,在真实环境中学习(如机械臂抓取物体)。
-
元学习(Meta-Learning):让代理学会“如何学习”,例如快速适应新任务(如从“图像分类”迁移到“视频分析”)。
-
类人化情感与动机:引入情感模型(M_emo),使代理的决策更贴近人类偏好(如根据用户情绪调整回答风格)。
通过这三个维度的协同进化,智能代理正从“被动执行指令的工具”迈向“能感知、会思考、善适应”的自主智能体,推动AI在医疗、教育、自动驾驶等领域的深度应用。
2.2 推理
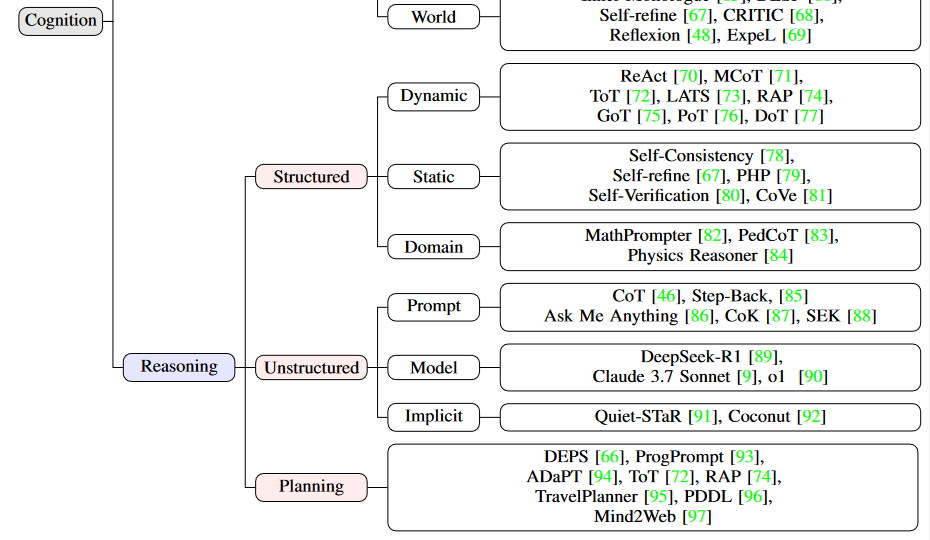
2.2.1 核心概念:推理的本质与形式化
1. 推理的定义与双重角色
-
人类推理:通过演绎、归纳、溯因三种策略处理信息,结合启发式方法(心理捷径)简化决策,并通过环境反馈持续优化推理逻辑。例如,医生根据医学指南(演绎)、患者病史(归纳)和症状(溯因)诊断病情。
-
LLM智能体推理:将原始信息转化为可执行动作的过程,形式化为 心理状态到动作的映射函数R(M_t)-> a_t。例如,智能客服通过分析用户问题(心理状态 M_t )选择回复策略或调用工具(动作 a_t)。
2. 环境的关键作用
-
信息源:提供文本、图像等多模态数据(如 o_t),更新智能体的心理状态(M_t = L(M_{t-1}, a_{t-1}, o_t))。
-
检验场:通过执行动作后的反馈(如用户满意度、任务完成度)验证推理有效性,形成“感知-推理-行动-反馈”闭环。
二、推理的分类:结构化与非结构化
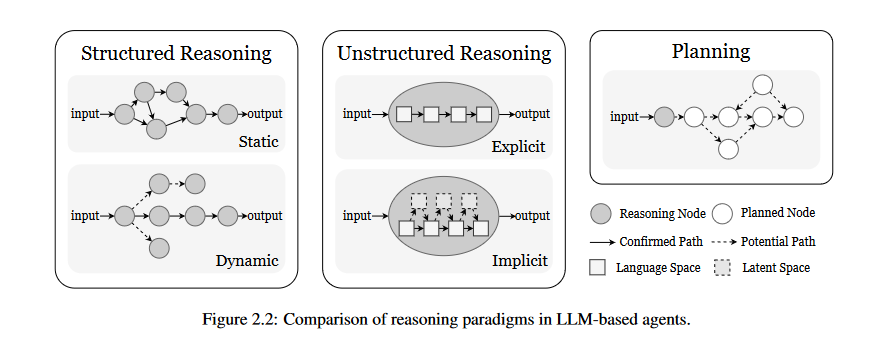
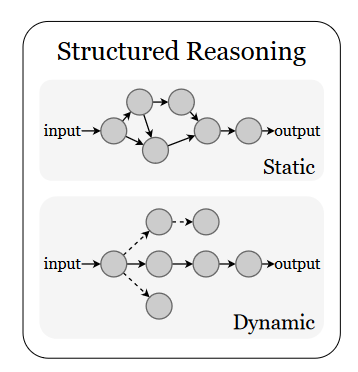
(一)结构化推理:显式逻辑与层次框架
特点:将推理拆解为明确步骤,具有可解释性和可追溯性,适用于需要严谨逻辑的场景(如数学证明、医疗诊断)。
1. 动态推理结构
-
线性序列推理:按顺序执行步骤,结合外部工具迭代优化。
-
ReAct:交替进行“推理轨迹生成”与“动作执行”(如搜索天气数据后调整行程规划)。
-
MCoT:将推理步骤压缩为马尔可夫状态(如将历史对话简化为数学表达式),减少上下文依赖。
-
-
树状探索结构:分层分支搜索,支持多路径并行评估。
-
ToT(思维树):将复杂问题分解为中间节点(如写作时先列大纲再扩展细节),通过广度/深度优先搜索选择最优路径。
-
LATS:结合蒙特卡洛树搜索(MCTS)与LLM,通过“价值函数评估+自我反思”平衡探索(尝试新路径)与利用(依赖已知有效路径)。
-
-
图状推理结构:非层级关系建模,捕捉复杂依赖。
-
GoT(思维图):连接看似无关的推理分支(如跨学科问题中关联物理定律与经济模型),适用于长链关系推理。
-
2. 静态推理结构
-
集成方法:聚合多路径结果提升准确性。
-
Self-Consistency:生成多条推理路径并投票(如数学题求解时采用多数答案),减少单一路径的偏差。
-
LLM-Blender:融合多个LLM的输出(如GPT-4与Claude的互补优势),提升复杂任务的可靠性。
-
-
渐进改进方法:通过反馈循环迭代优化。
-
Self-Refine:模型生成初始回答→自我批判→修正(如论文草稿的自我修订),无需额外训练数据。
-
Reflexion:结合环境反馈(如用户错误提示)更新记忆,指导后续决策(如客服系统记录用户投诉点以优化响应)。
-
3. 领域特定框架
-
MathPrompter:生成多种解法(代数表达式、Python函数)验证数学题答案,降低计算错误率。
-
Physics Reasoner:通过“问题分析→公式检索→引导推理”三阶段解决物理问题,减少知识应用错误。
(二)非结构化推理:隐式逻辑与整体映射
特点:推理过程隐含在LLM的内部计算中,无需显式步骤,灵活高效,适用于开放域问答、创意生成等场景。
1. 基于提示的推理
-
思维链(CoT)变体:
-
零样本CoT:仅需“逐步思考”提示即可激发推理(如用户问“如何煮咖啡”时自动拆解步骤)。
-
由易到难提示:先解决简单子问题(如“2+2=?”)再推导复杂问题(如“123×456”),降低认知负荷。
-
-
问题重构策略:
-
后退提示:先抽象出高层原理(如“能量守恒定律”)再解决具体问题(如计算机械效率),提升跨领域迁移能力。
-
思维抽象(AoT):要求模型先进行抽象思考(如定义“人工智能”的本质)再加入细节(如技术分类),避免逻辑断层。
-
2. 推理模型与隐式推理
-
专用推理模型:如DeepSeek R1、Claude 3.7 Sonnet,针对数学、逻辑任务微调,性能超越通用模型(如在GSM8K数学基准中准确率提升15%)。
-
隐式推理:在潜在空间中完成推理,减少token生成量。
-
Coconut:利用LLM的隐藏状态直接在连续空间中迭代(无需转换为自然语言),如编码多个备选推理路径以并行搜索。
-
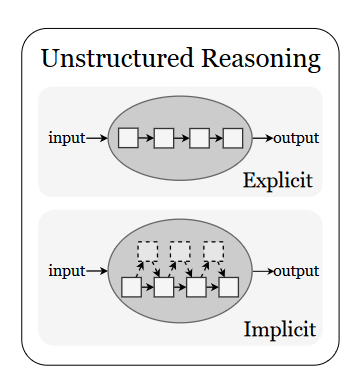
(三)结构化 vs 非结构化推理:核心差异
|
维度 |
结构化推理 |
非结构化推理 |
|
步骤可见性 |
显式(如流程图、树状图) |
隐式(LLM内部计算) |
|
适用场景 |
严谨逻辑任务(如法律文书、科学实验) |
灵活开放任务(如对话生成、创意写作) |
|
优势 |
可解释性强、错误易追溯 |
效率高、适应性强 |
|
典型方法 |
ToT、ReAct、Self-Consistency |
零样本CoT、AoT、Coconut |
2.2.2 规划:推理的长程整合与挑战
1. 规划的定义与形式化
-
本质:构建从初始状态(S_0)到目标状态(S_g)的动作序列({a_1, a_2, ..., a_n}),如旅行规划中“查天气→订机票→安排行程”。
-
关键能力:任务分解(拆分子目标)、路径模拟(预测动作后果)、资源分配(优化时间/成本)。
2. 核心挑战与解决方案
-
挑战1:缺乏因果推理
-
LLM依赖模式匹配(如“下雨→路面湿”),但难以理解因果关系(如“洒水车也可能导致路面湿”)。
-
解决方案:结合传统规划语言(如PDDL)定义因果规则,或通过物理模拟器(如Gazebo)增强环境建模。
-
-
挑战2:动态环境适应性
-
LLM基于静态训练数据,难以应对实时变化(如突发交通拥堵)。
-
解决方案:引入实时反馈机制(如ReAct的动作-观察循环),或通过强化学习动态调整策略。
-
-
挑战3:长程依赖管理
-
长序列规划中易出现“遗忘早期目标”(如写论文时偏离主题)。
-
解决方案:分层规划(Hierarchical Planning),如先定大纲再细化段落,通过记忆模块(如检索增强)维持上下文关联。
-
3. 典型方法
-
任务分解:如“由易到难提示”将复杂任务(如开发软件)拆解为“需求分析→编码→测试”子任务。
-
搜索优化:结合树搜索(如LATS)或遗传算法(如PlanCritic),在解空间中快速定位最优路径。
-
世界知识整合:通过工具调用(如API查询实时数据)或符号逻辑(如LTL-NL结合线性时态逻辑)弥补LLM的知识缺口。
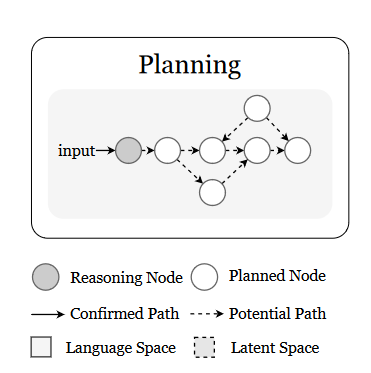
2.2.3 典型应用场景
1. 结构化推理的应用
-
医疗诊断:通过“症状输入→疾病概率计算→检查建议”线性流程,结合医学指南(演绎推理)和病例库(归纳推理)生成诊断报告。
-
代码生成:使用ToT探索多种算法路径(如排序问题中的冒泡排序 vs 快速排序),选择时间复杂度最优方案。
2. 非结构化推理的应用
-
智能客服:通过零样本CoT实时解析用户问题(如“退货流程”),生成自然语言回复,无需预定义规则。
-
创意写作:利用AoT先确定故事主题(抽象层),再生成具体情节(细节层),如从“爱情与成长”主题延伸出角色冲突和转折。
3. 规划的应用
-
自动驾驶:规划“感知路况→预测行人轨迹→调整车速→规避障碍”序列,结合实时传感器数据(环境反馈)动态修正路径。
-
项目管理:通过分层规划(如Gantt图)分解任务,设定依赖关系(如“设计完成→开发启动”),并利用Reflexion机制根据进度延迟调整资源分配。
2.2.4 未来挑战与发展方向
-
因果推理增强:融合符号逻辑(如贝叶斯网络)与LLM,提升对复杂因果关系的建模能力(如气候变化与经济影响的关联)。
-
小样本/零样本推理:通过元学习(Meta-Learning)或提示工程,使模型在极少示例下快速适应新任务(如罕见疾病诊断)。
-
多智能体协同推理:多个LLM智能体分工协作(如“法律专家+财务专家”联合处理商业合同),通过通信协议共享推理状态。
-
伦理与可解释性:开发可追溯的推理日志系统(如记录每个动作的决策依据),确保医疗、司法等敏感领域的推理透明性。
推理是人类与AI智能体实现复杂认知的核心能力。结构化推理通过显式框架提升逻辑严谨性,非结构化推理利用LLM灵活性实现高效响应,而规划则通过整合两者应对长程挑战。未来,随着因果建模、实时反馈等技术的突破,LLM推理将更接近人类水平,推动自主决策、科学发现等前沿领域的发展。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 22
22 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)