神经网络与深度学习(4)——语义分割与FCN、循环神经网络与NLP
LSTM:参数量参数量是RNN的4倍:LSTM:输入输出和RNN相同。
神经网络与深度学习(4)——语义分割与FCN、循环神经网络与NLP
目录
一、语义分割要做什么
1.1 语义分割问题
语义分割:找到同一画面中的不同类型目标区域
语义分割问题和其他问题的区别
实例分割:同一类型目标要分出来具体实例(谁是谁)
目标检测:标出来外包围矩形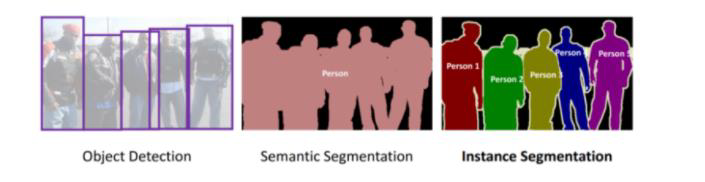
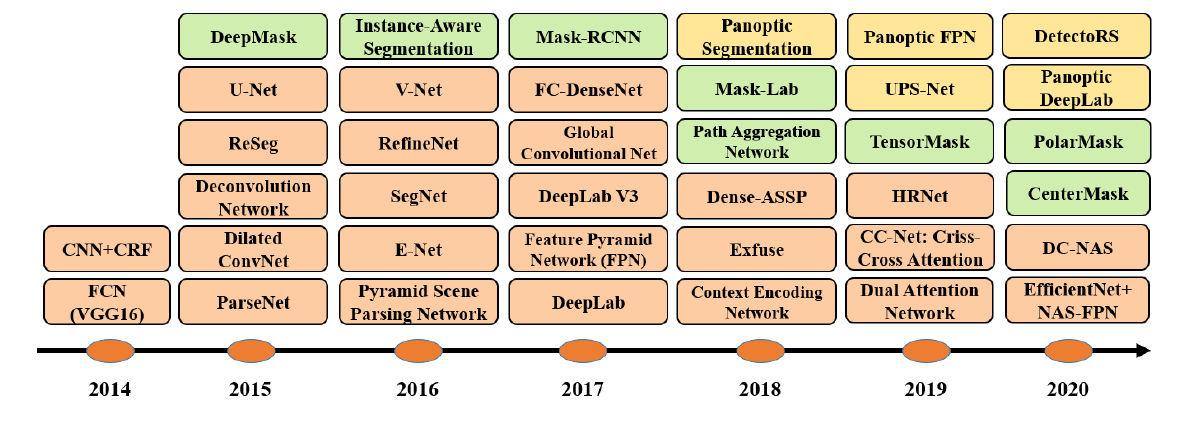
1.2 深度学习图像分割算法发展
二、语义分割基本思想
2.1 语义分割目标
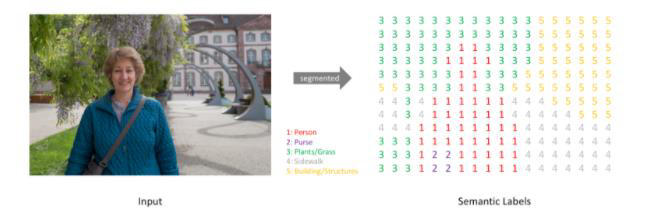

对图中每一个像素进行分类,得到对应标签
2.2 语义分割基本思想
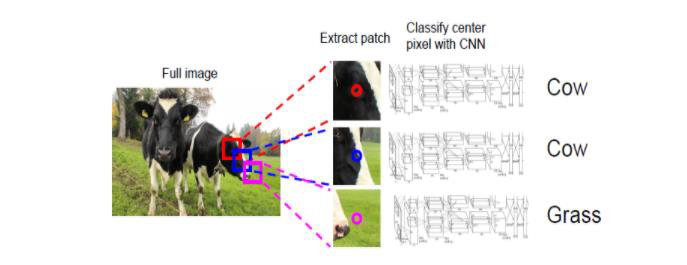
基本思想:滑动窗口
- 滑动次数太多,计算太慢,重复计算太多
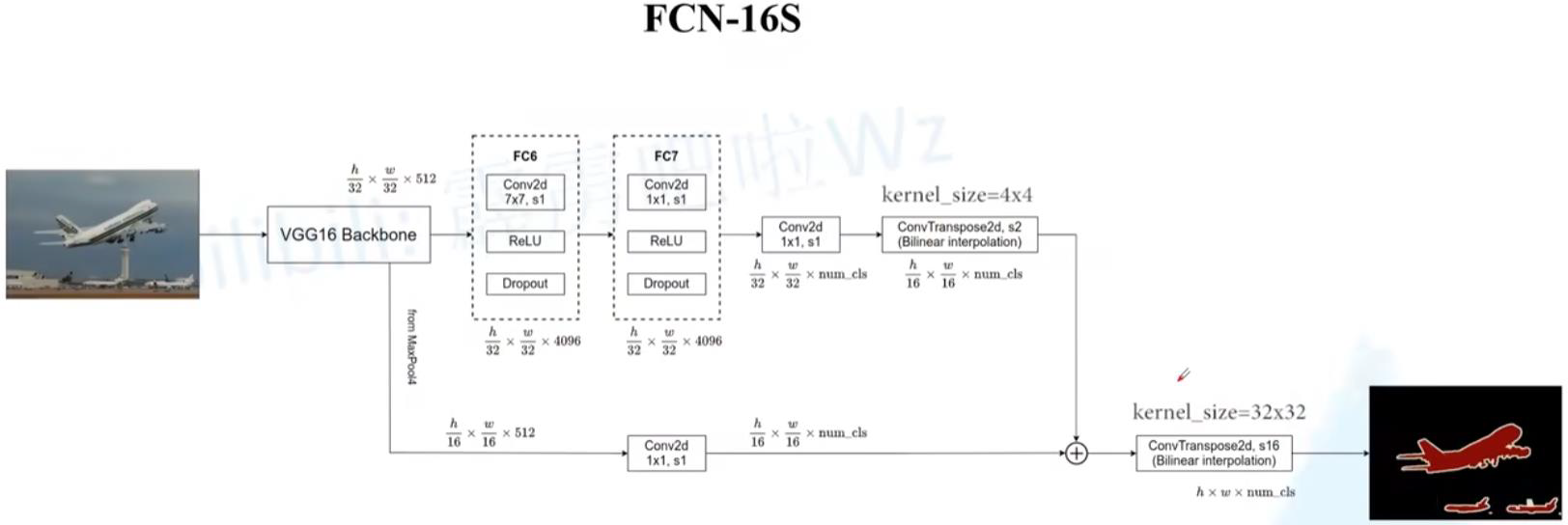
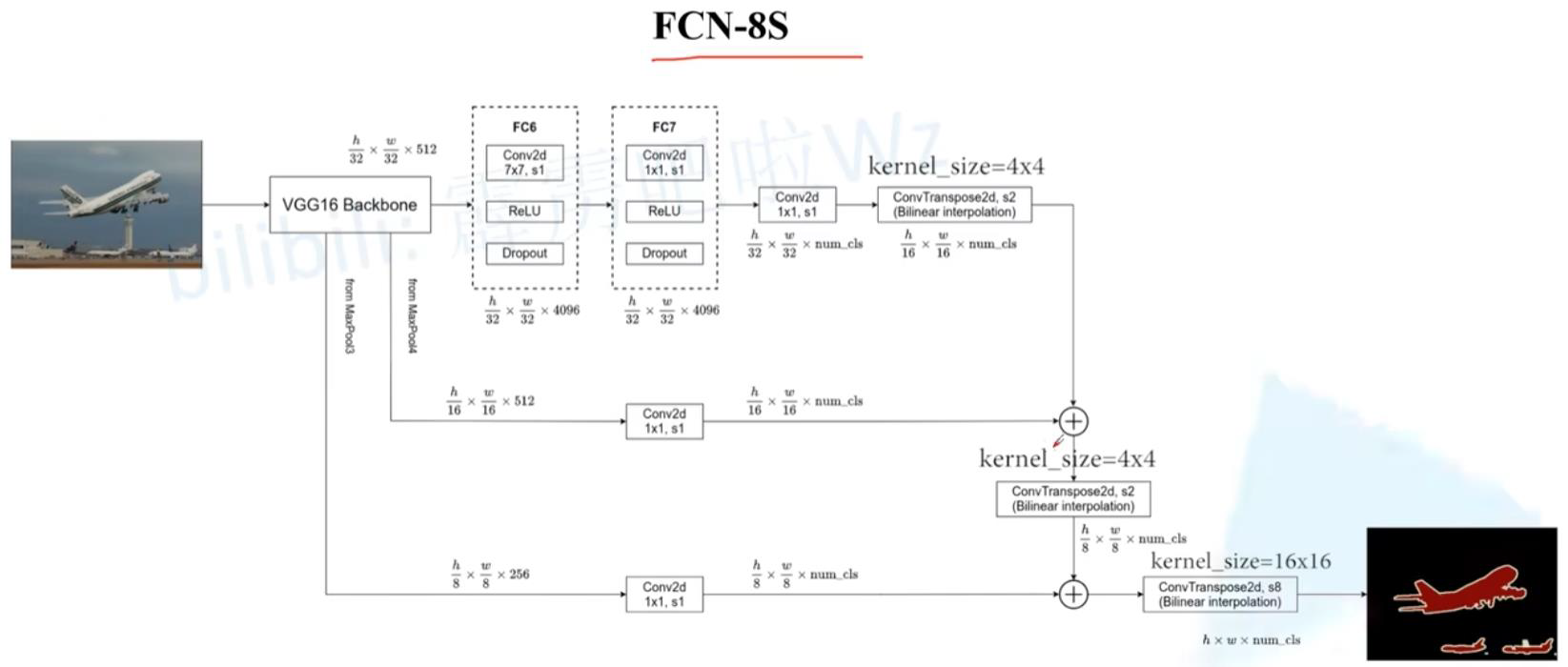
FCN网络结构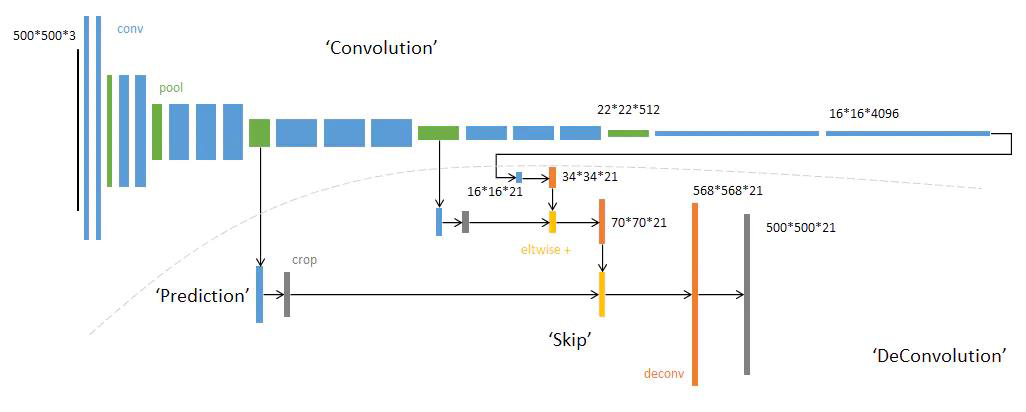
网络结构分为两个部分:全卷积部分和反卷积部分。全卷积部分借用了一些经典的 CNN 网络,并把最后的全连接层换成卷积,用于提取特征,形成热点图;反卷积部分则是将小尺寸的热点图上采样得到原尺寸的语义分割图像。
三、反卷积与反池化
3.1 基本概念
𝟏×𝟏卷积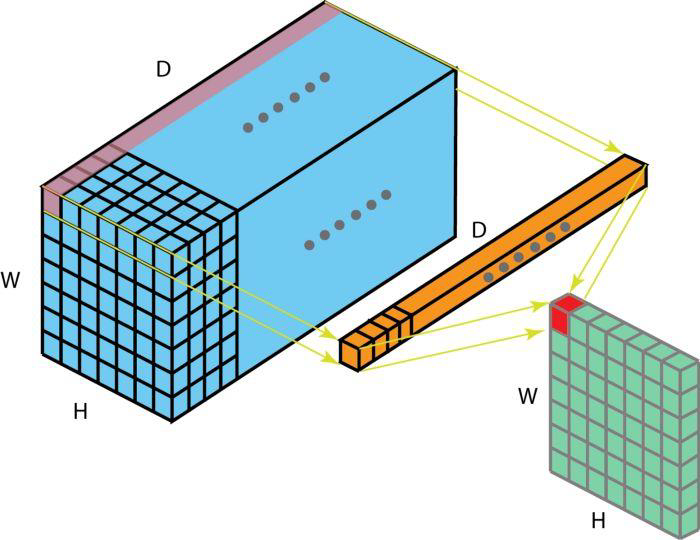
转置卷积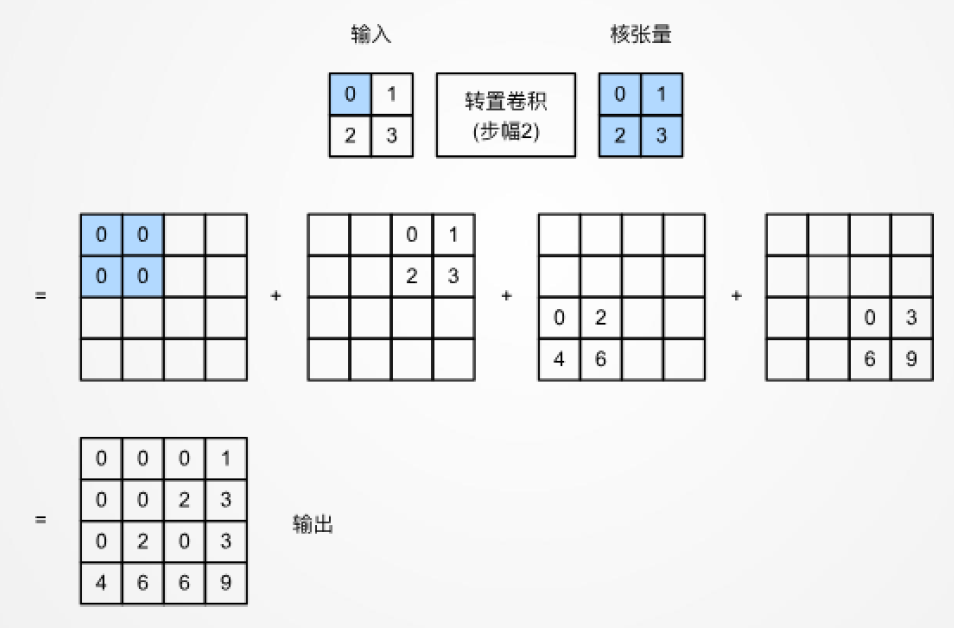
上池化(unpooling)
四、FCN具体实现
4.1 FCN实现结构之卷积部分
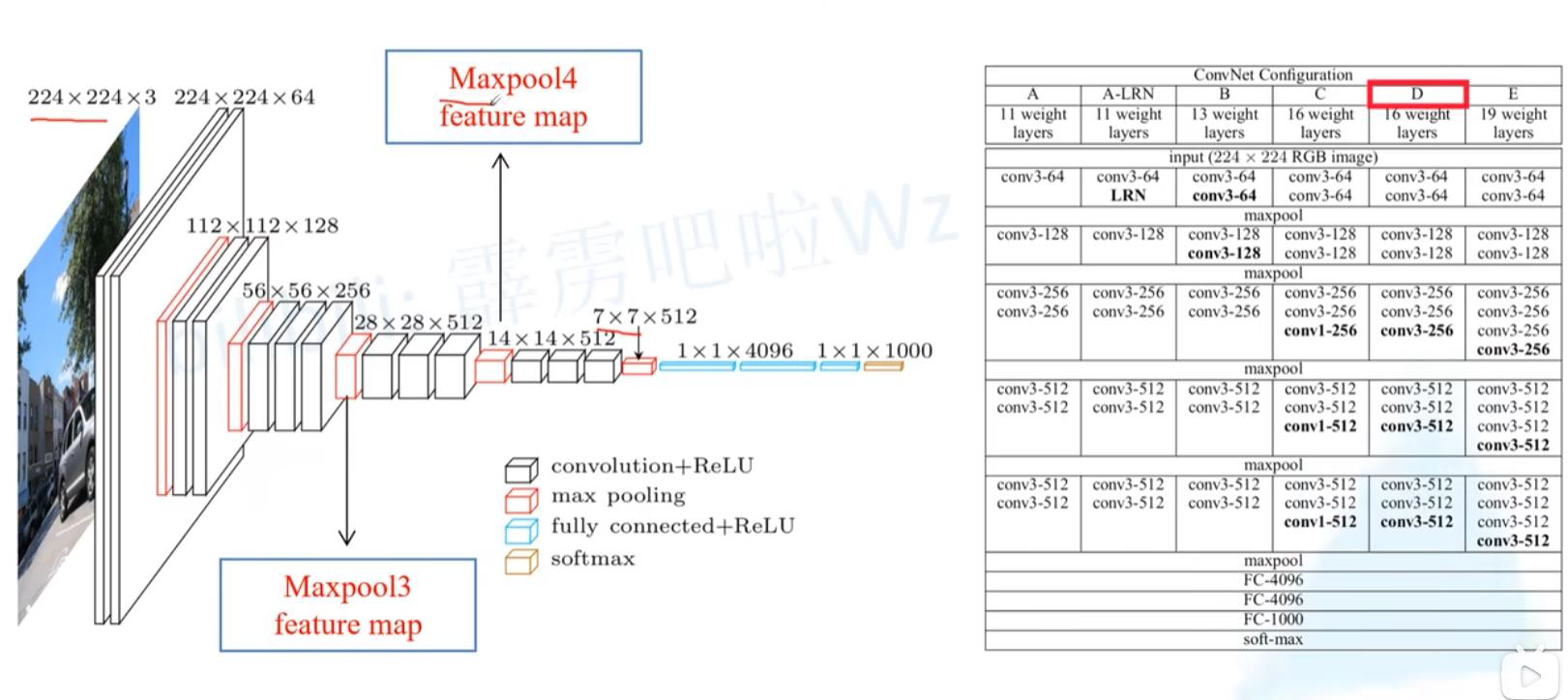
FCN网络结构:卷积部分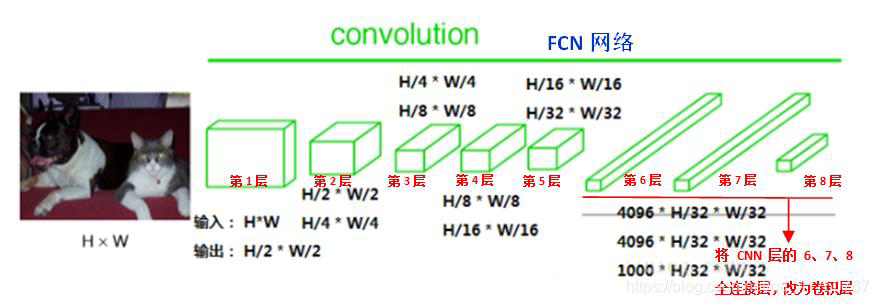
FCN中第6 、7 、8层都是通过1×1卷积得到的,第6层的输出通道是4096,第7层的输出通道是4096,第8层的输出是1000(类),即1000个特征图(称为heatmap)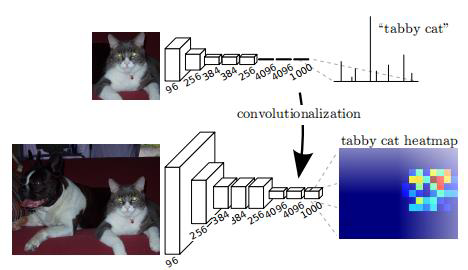
输出的特征图(称为 heatmap),颜色越贴近红色表示对应数值越大
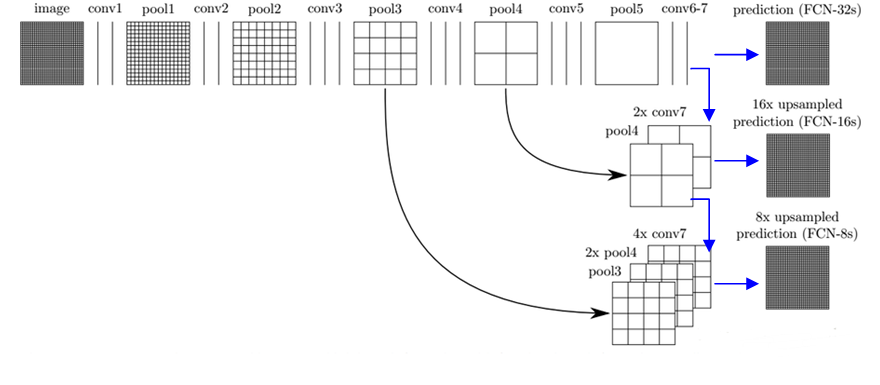
4.2 FCN实现结构之反卷积部分
反卷积部分:跳级结构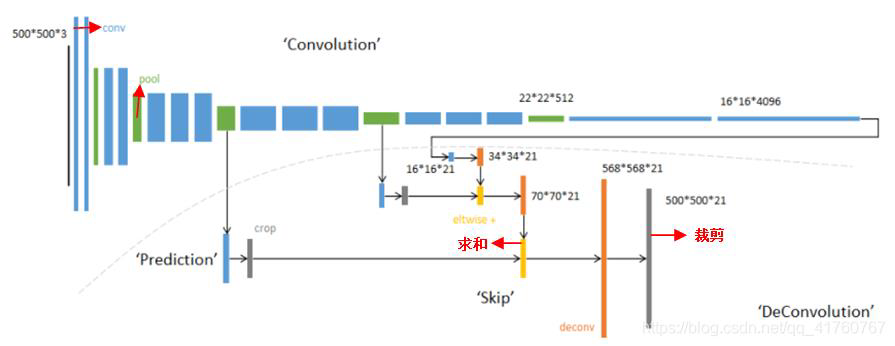
蓝色:卷积层;绿色:Max Pooling 层;黄色:求和运算;灰色:裁剪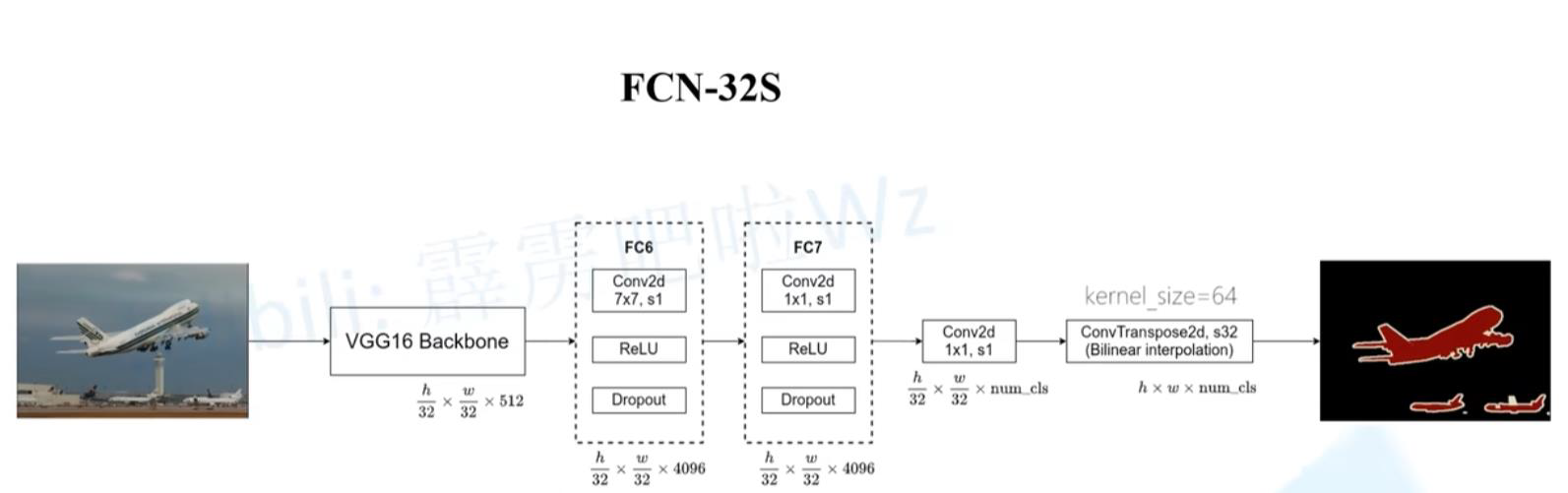
FCN结果
五、FCN评价指标与标注工具
5.1 常见语义分割评价指标

5.2 常见标注工具
Labelme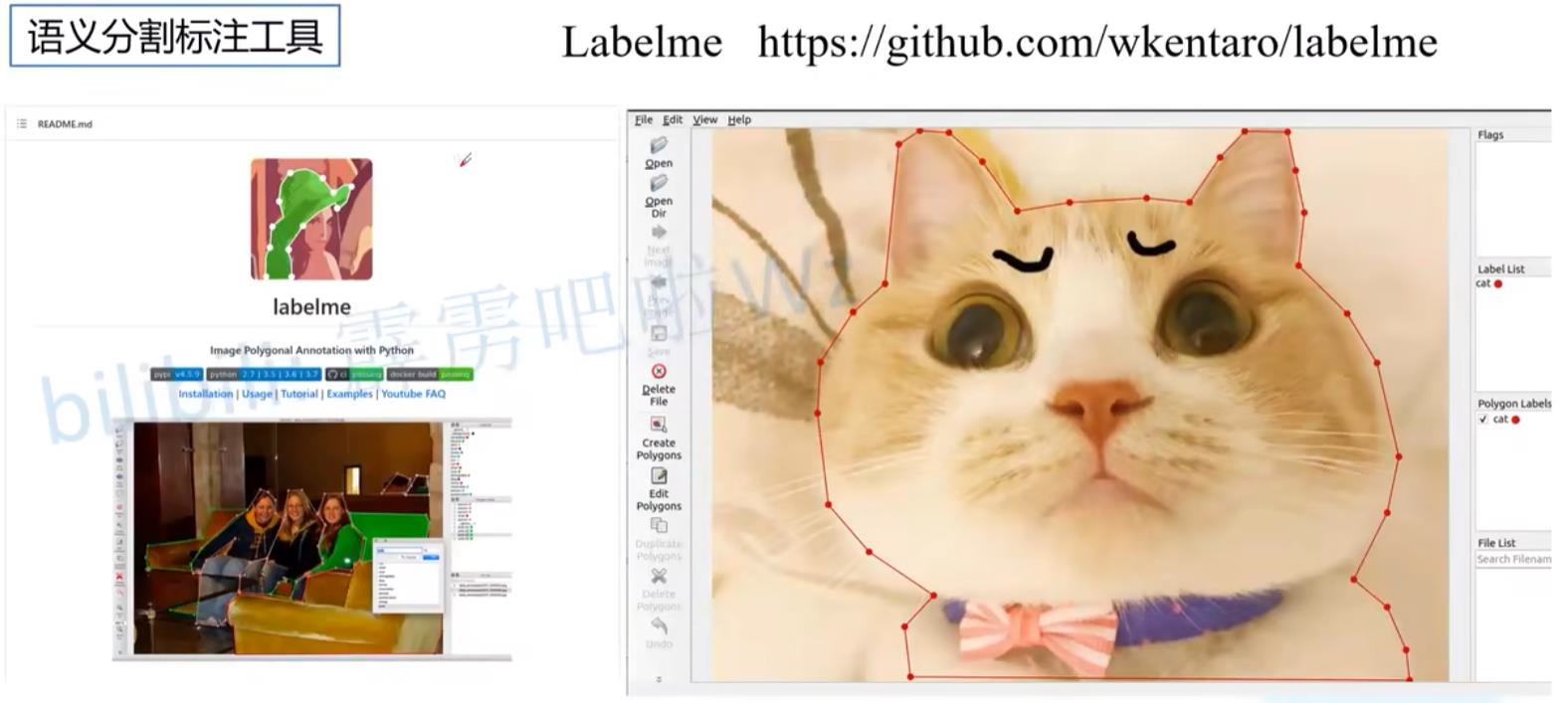
EISeg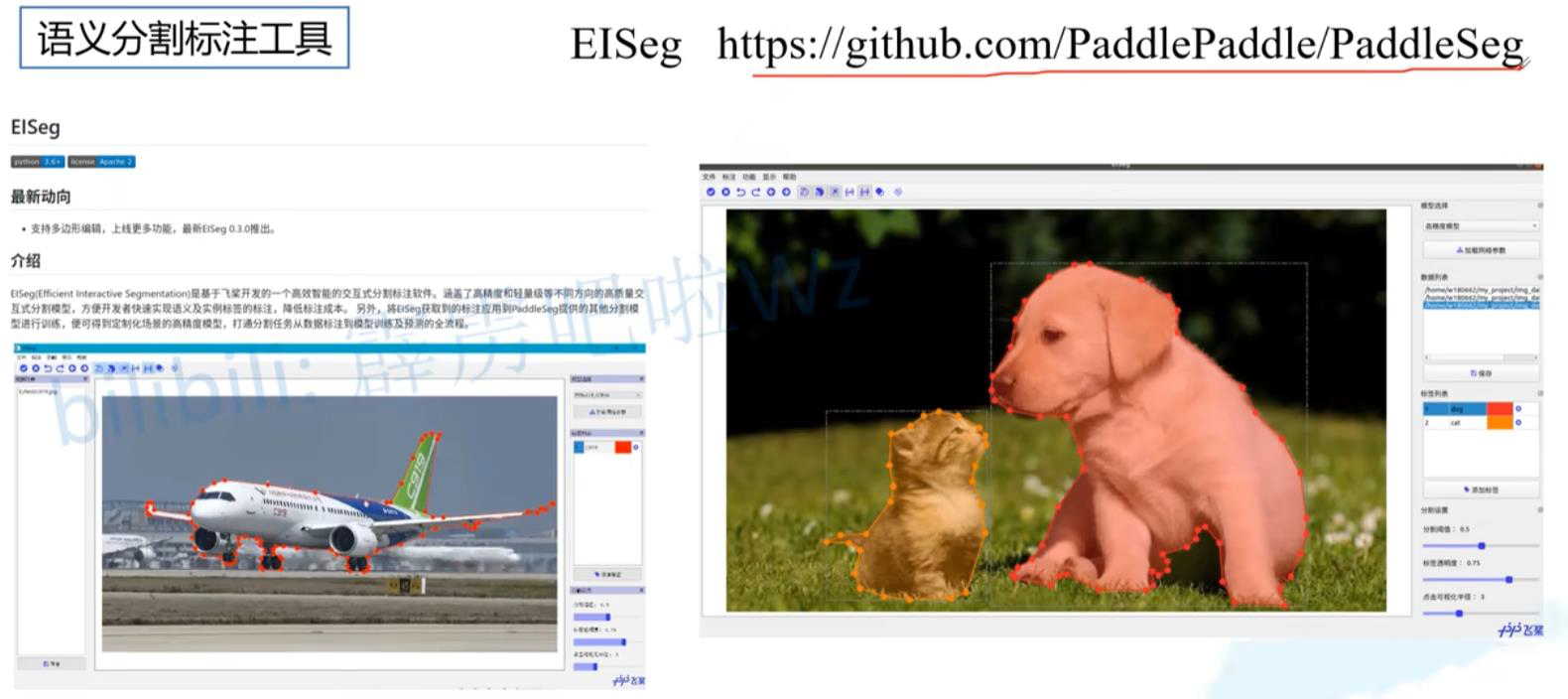
六、序列模型
6.1 序列模型
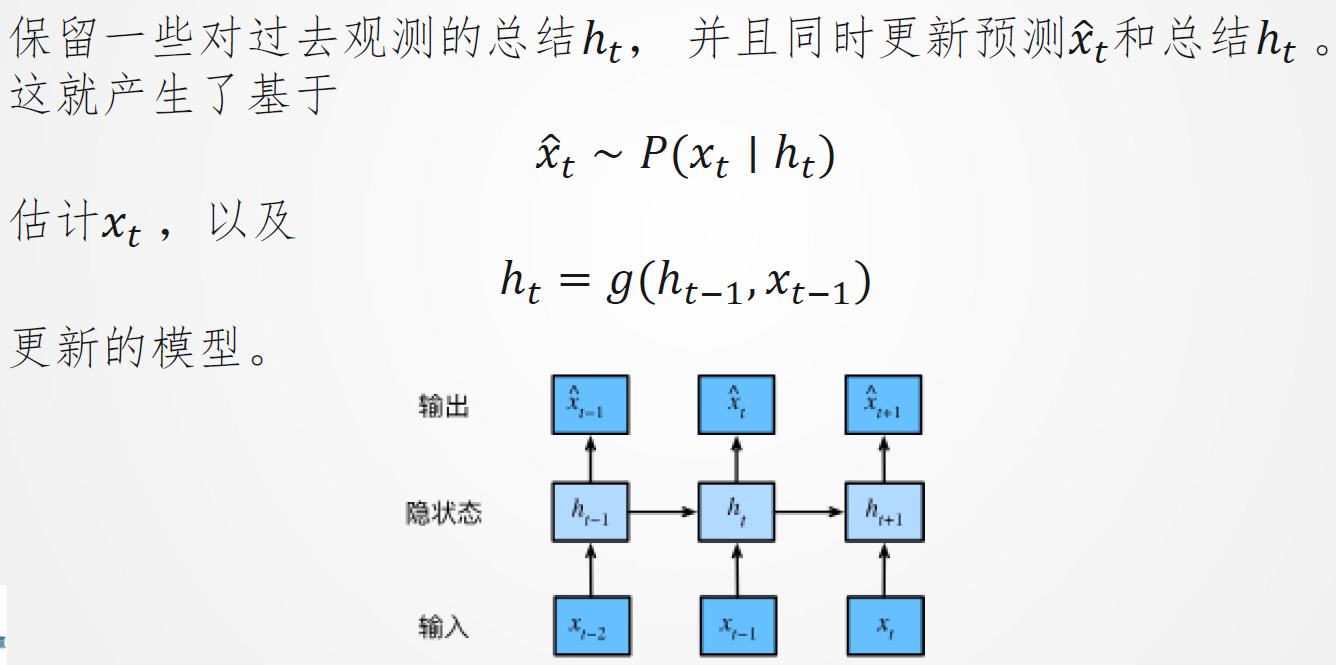
分类问题与预测问题
- 图像分类:当前输入−>当前输出
- 时间序列预测:当前+过去输入−>当前输出
自回归模型
七、数据预处理
7.1 特征编码
数值特征与类别特征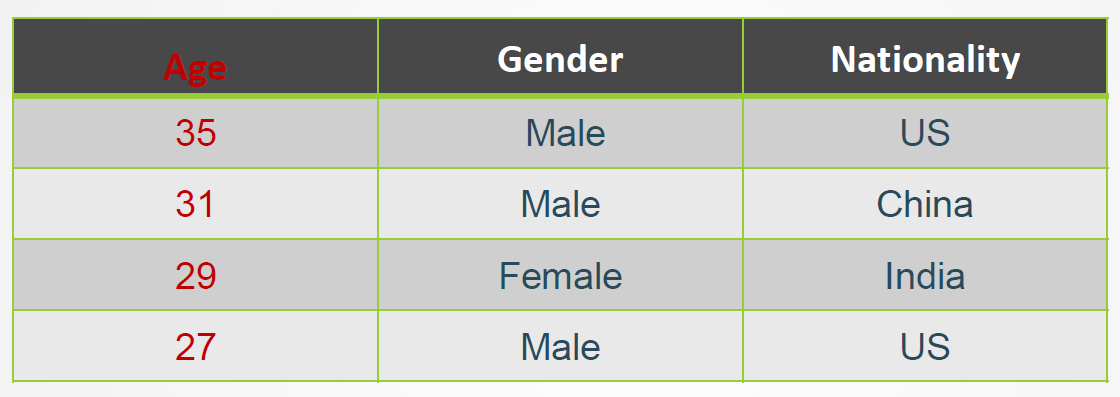
第1列表示年龄,是一个数值特征
第2列表示性别,是一个只有一位(0,1)的特征,0 -> Male, 1 -> Female
第3列表示国籍,目前有197个国家,1 -> US, 2 -> China, …。可以用一个整数来表示,或者用一个独热向量来表示, 如US: [1,0, ….,0]。数值特征不适合表示类别,因此一般使用独热编码。国家编码从1开始,1~197,因为实际国籍有可能不填(对应0)。
使用199维特征向量表达一个人的特征:
7.2 文本处理
按字母处理
给定文本片段,如:S = “… to be or not to be…”.
将文本切分为字母序列:L = […, ‘t’, ‘o’, ‘ ’, ‘b’, ‘e’, …],
按单词处理:文本切分 (tokenization)
给定文本片段,如:S = “… to be or not to be…”.
将文本切分为单词序列:L = […, to, be, or, not, to, be, …],
八、文本预处理与词嵌入
8.1 文本预处理
一篇文章可以被简单地看作一串单词序列,甚至是一串字符序列。 我们将解析文本的常见预处理步骤。 这些步骤通常包括:
1.将文本作为字符串加载到内存中。
2.将字符串切分为词元(如单词和字符)。
3.建立一个字典,将拆分的词元映射到数字索引。
4.将文本转换为数字索引序列,方便模型操作。
第一步:读取数据集
以H.G.Well的时光机器为例,从中加载文本。 这是一个相当小的语料库,只有30000多个单词,而现实中的文档集合可能会包含数十亿个单词。如Chatgpt包含65T数据。
第二步:词汇切分
将原始文本以文本行为单位进行切分
第三步:构建词索引表
打印前几个高频词及索引
[(‘’,0),(‘the’,1),(‘i’,2),(‘and’,3),(‘of’,4),(‘a’,5),(‘to’,6),(‘was’,7),(‘in’,8),(‘that’,9)]
将每一条文本行转换成一个数字索引列表
文本:[‘the’,‘time’,‘machine’,‘by’,‘h’,‘g’,‘wells’]
索引:[1,19,50,40,2183,2184,400]
文本:‘twinkled’,‘and’,‘his’,‘usually’,‘pale’,‘face’,‘was’,‘flushed’,‘and’,‘animated’,‘the’]
索引:[2186,3,25,1044,362,113,7,1421,3,1045,1]
8.2 文本嵌入
如何将词映射成向量?
直接想法:使用之前所述的独热向量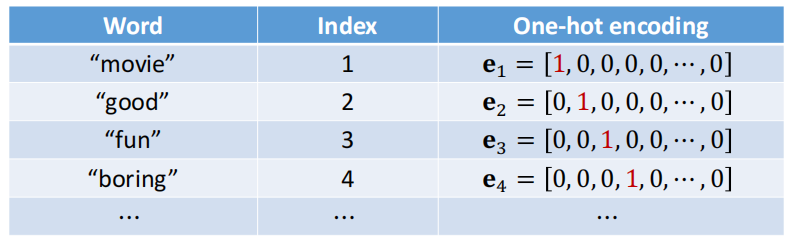
问题:维数过高
词嵌入(word embedding):将独热向量映射为低维向量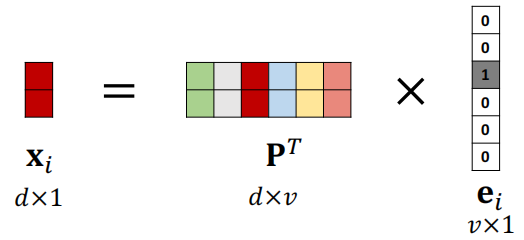
原始向量:𝑣维;映射后:𝑑维,𝑑 ≪ 𝑣;
映射矩阵:𝑑 × 𝑣,根据训练数据学习得到
理解映射参数矩阵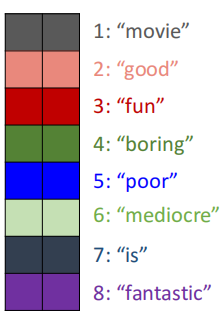
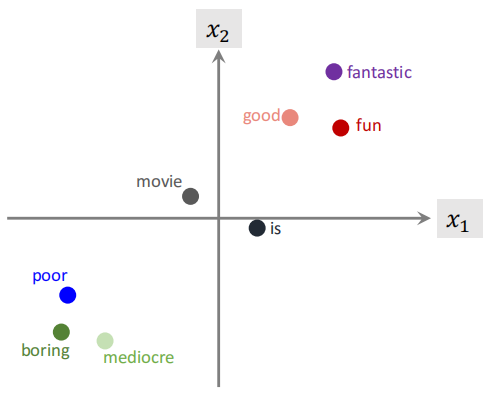
词嵌入训练效果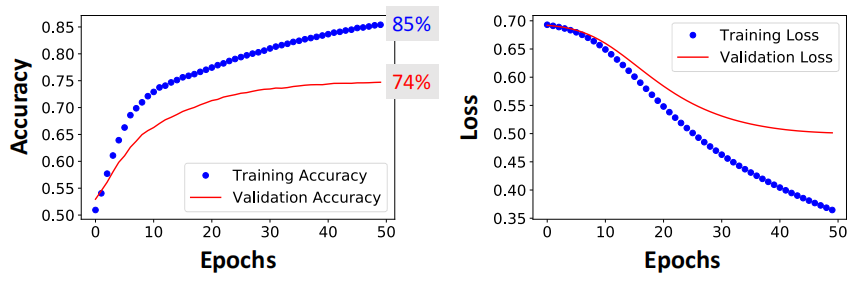
准确率74%(测试集),不好不差
九、RNN模型
9.1 RNN概要
如何建模序列数据?
图像分类中使用:1对1模型
输入和输出维度:固定
文本处理中:输入维度不定(可能一直有单词输入);输出维度不定或者是1(直接最终理解结果)
用RNN建模序列数据
输入:The cat sat on the mat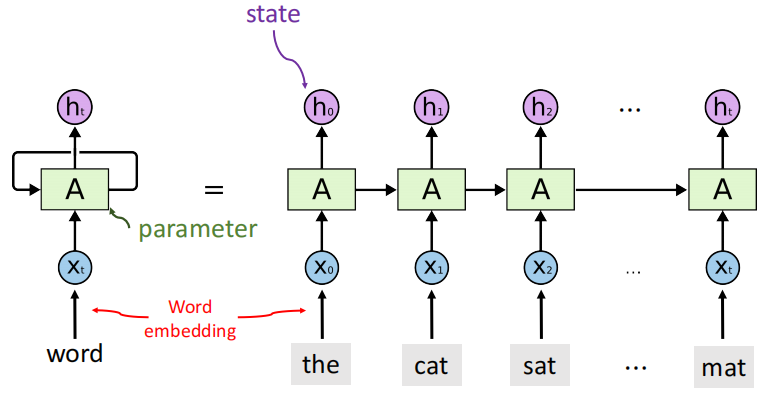
9.2 RNN模型
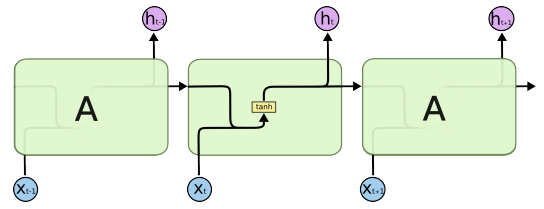
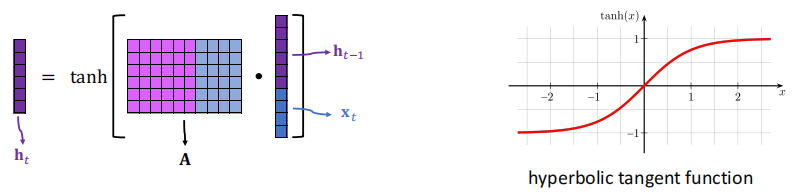
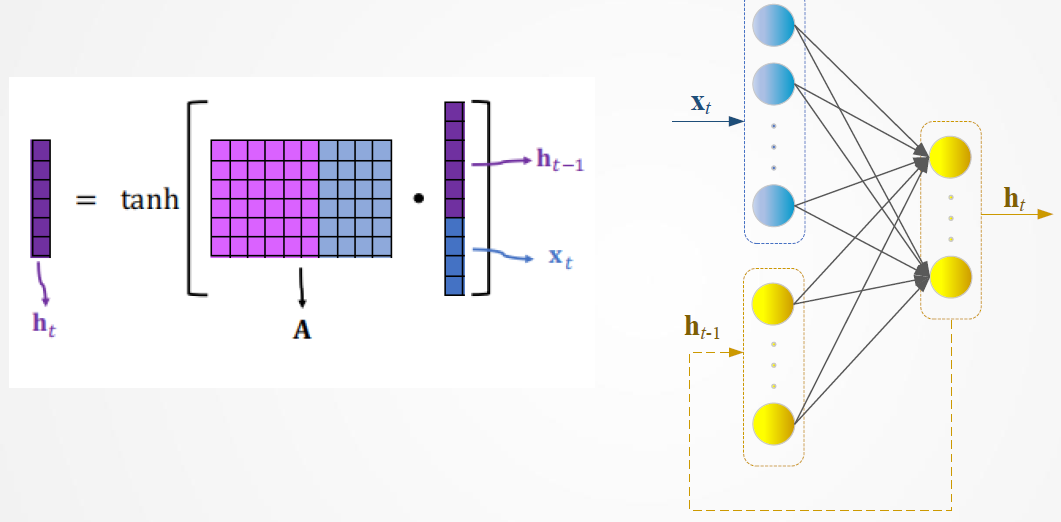
9.3 RNN问题
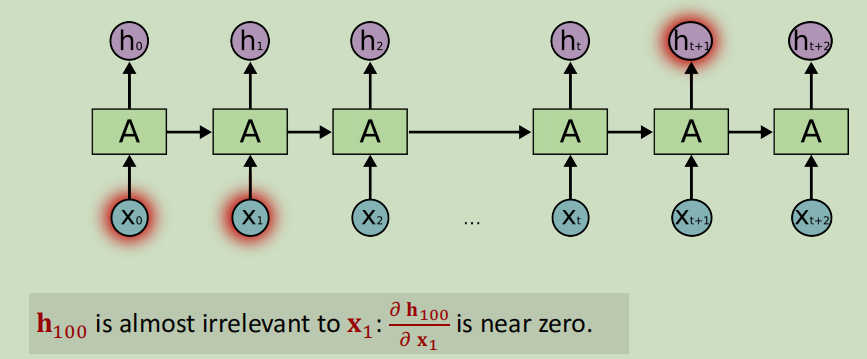
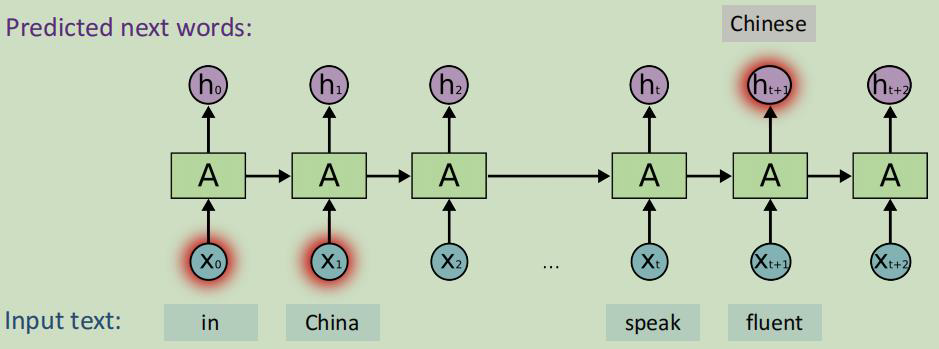
随着输入的增加,会产生“遗忘”问题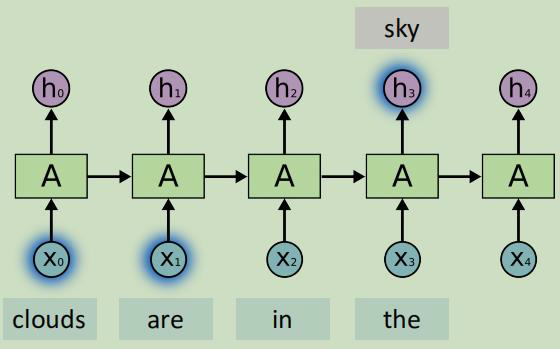
十、RNN模型实现
参见“动手学深度学习”8.5小节。
十一、RNN误差反传
11.1 RNN误差反传
每个时间步的隐状态和输出可以写为: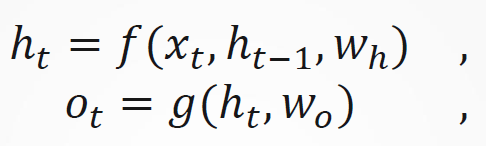
通过一个目标函数在所有𝑇个时间步内评估输出𝑜𝑡和对应的标签𝑦𝑡之间的差异: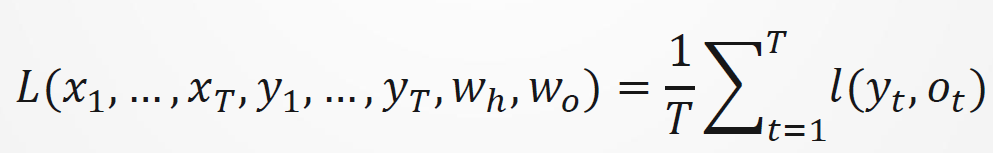
按照链式法则: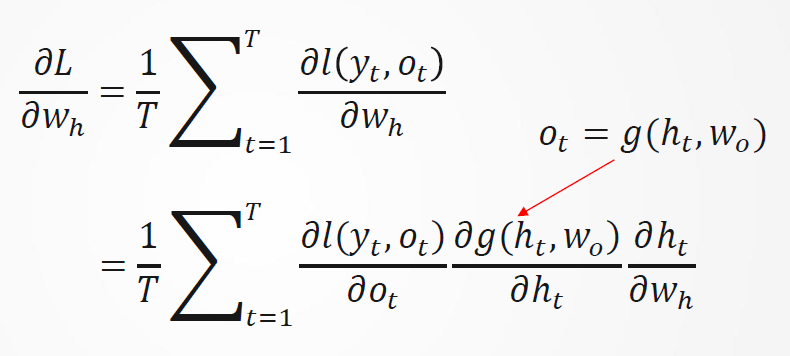
ℎ𝑡既依赖于ℎ𝑡−1,又依赖于𝑤ℎ , 其中ℎ𝑡−1的计算也依赖于𝑤ℎ 。因此,用链式法则产生: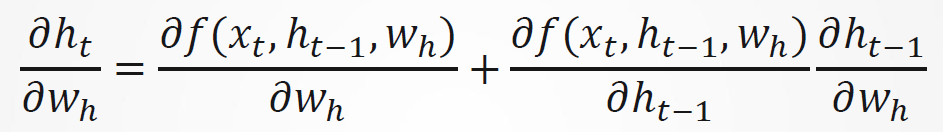
使用下面的公式移除 上页中的循环计算: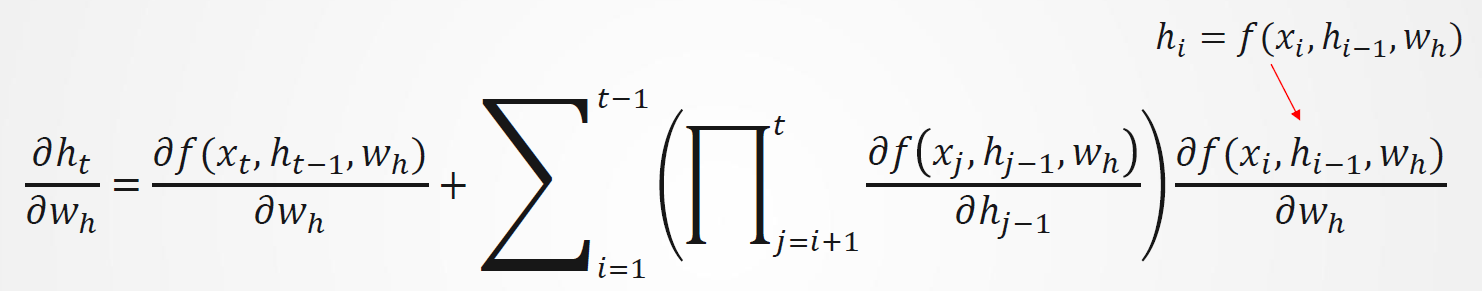
截断时间步:我们可以在𝜏步后截断上页式中的求和计算
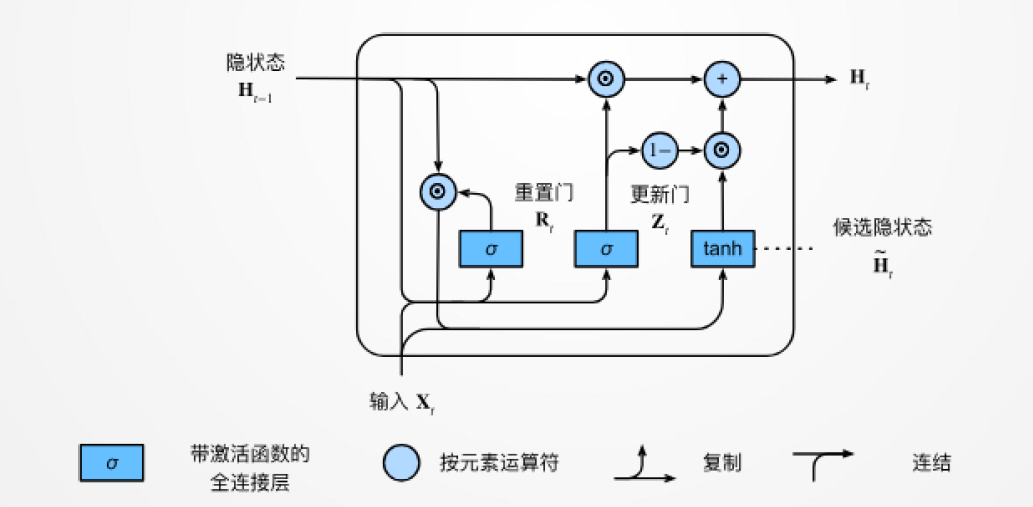
十二、门控循环单元(GRU)
12.1 门控循环单元
基本思想:不是每个观察都同等重要
一个良好的记忆产生一个良好的预测。良好的记忆要素:
- 关注机制(更新门)
- 遗忘机制(重置门)
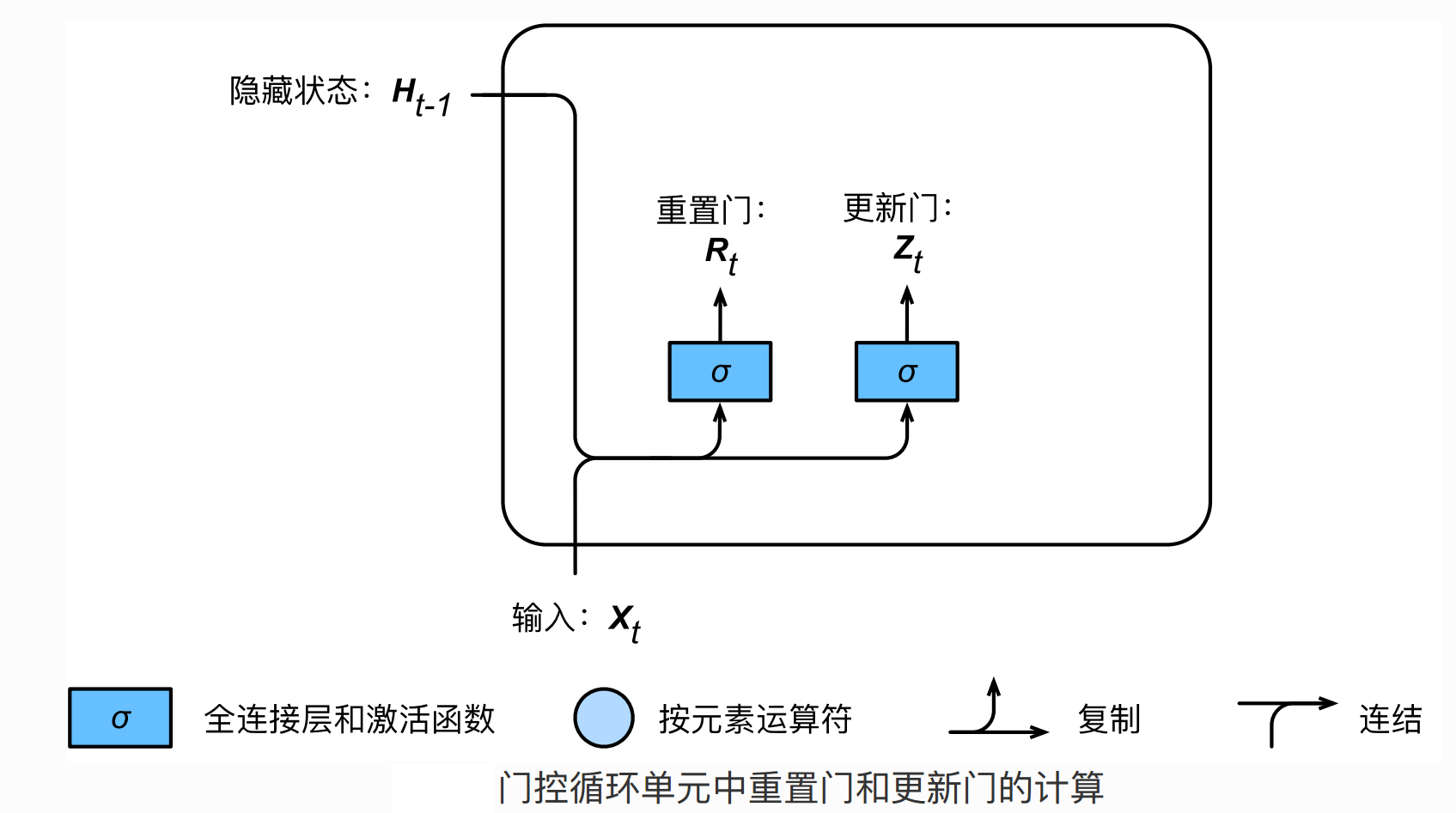
GRU基本结构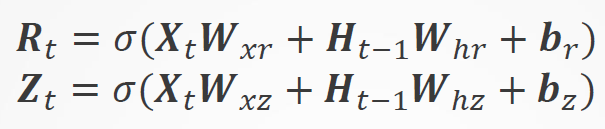
候选隐状态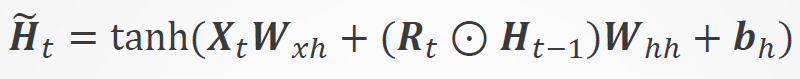
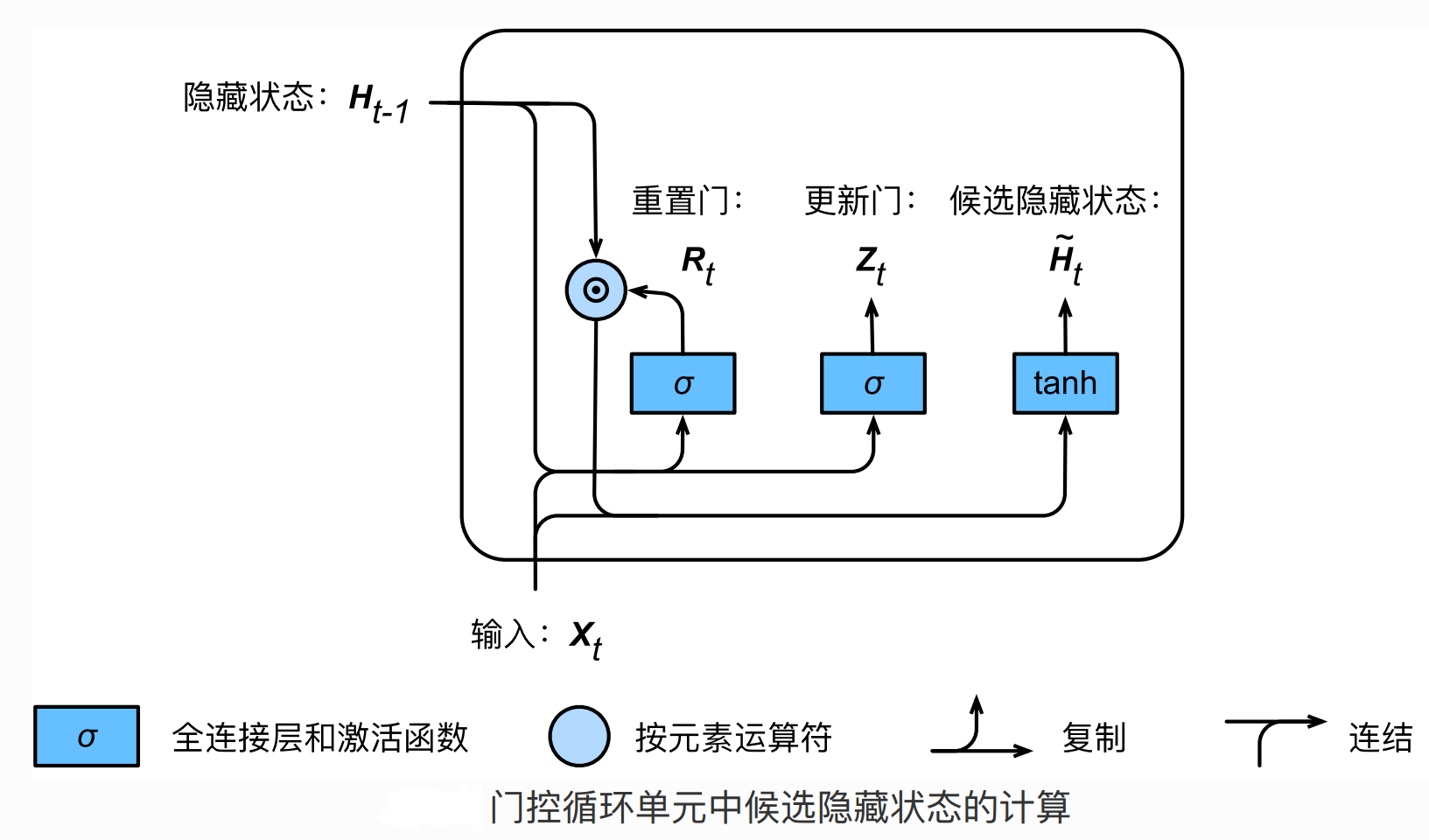
隐状态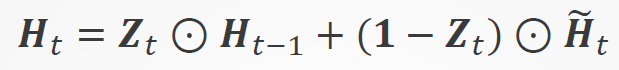
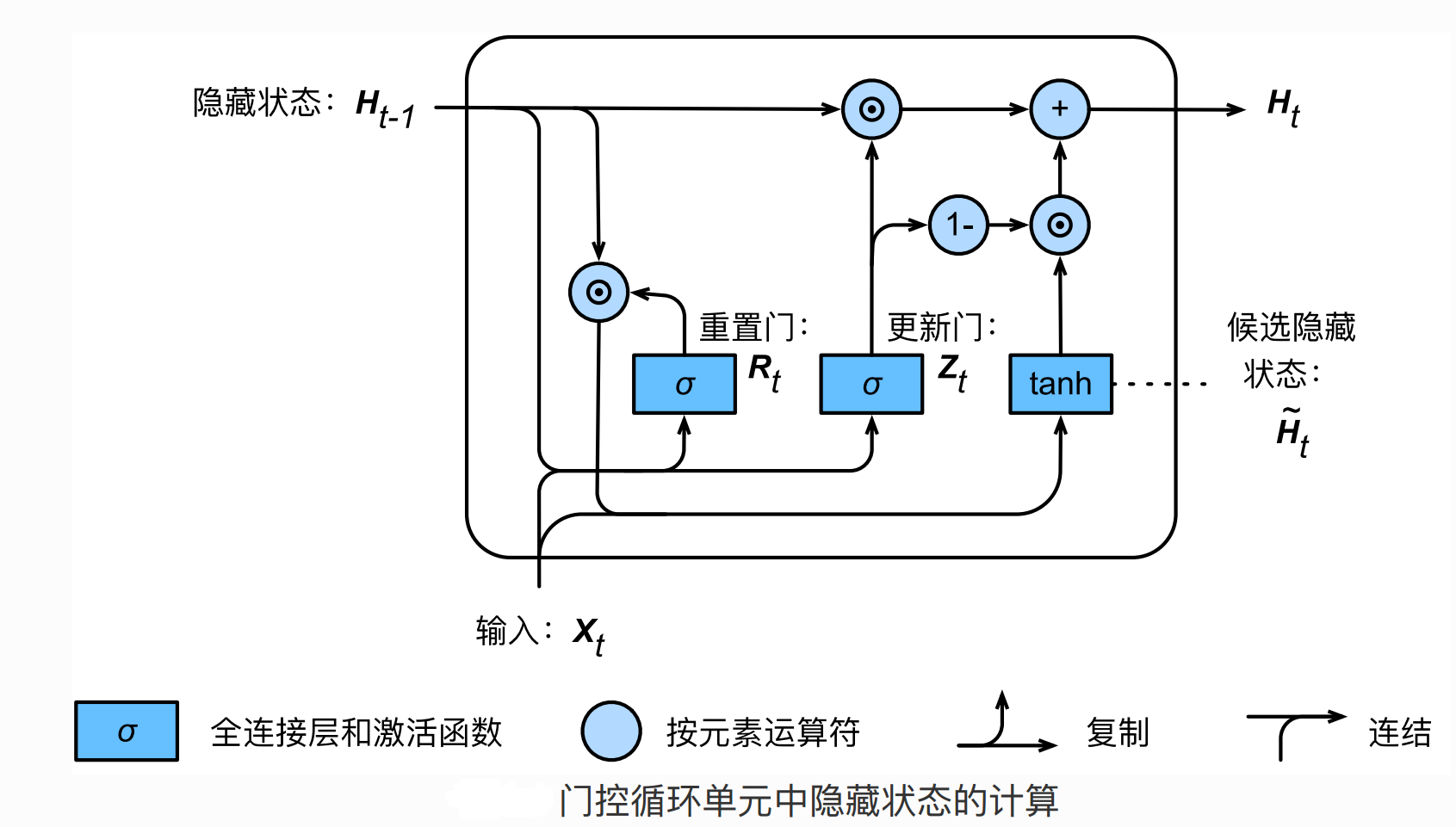
总结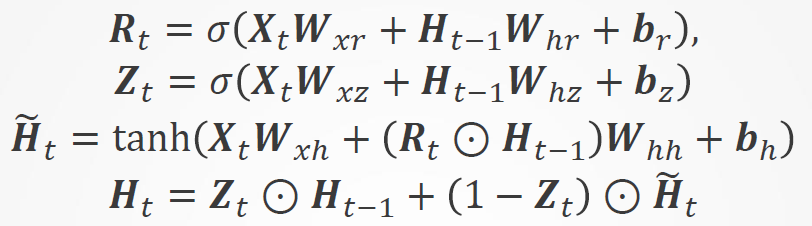
12.2 模型实现
参见《动手学深度学习》9.1节
十三、长短期记忆网络(LSTM)
13.1 LSTM模型
LSTM网络模型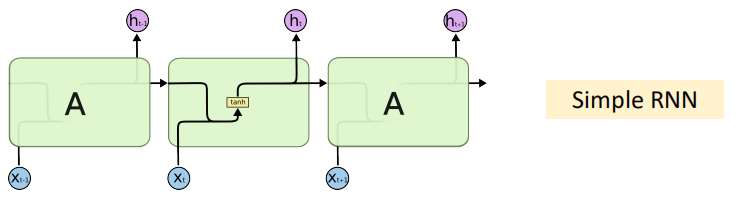
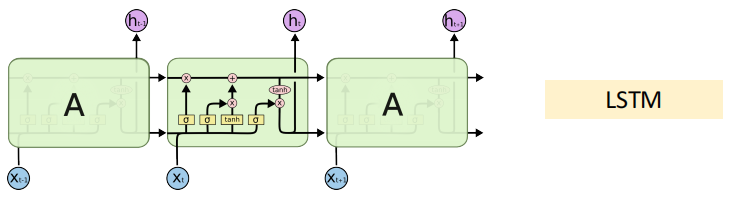
LSTM:“传送带”: 新引入记忆状态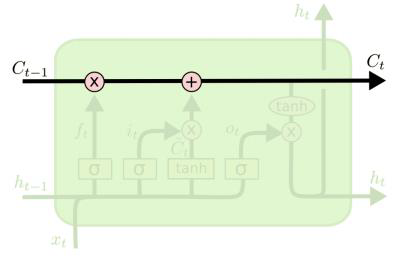
13.2 LSTM:遗忘门
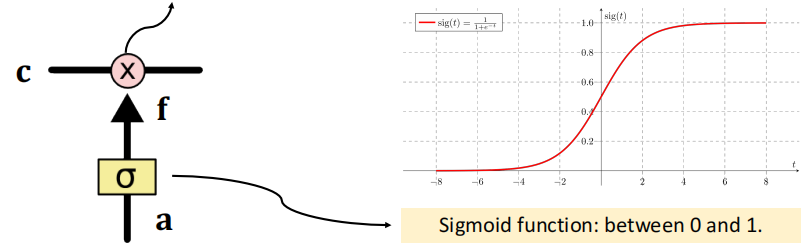
×代表逐元素相乘(点积)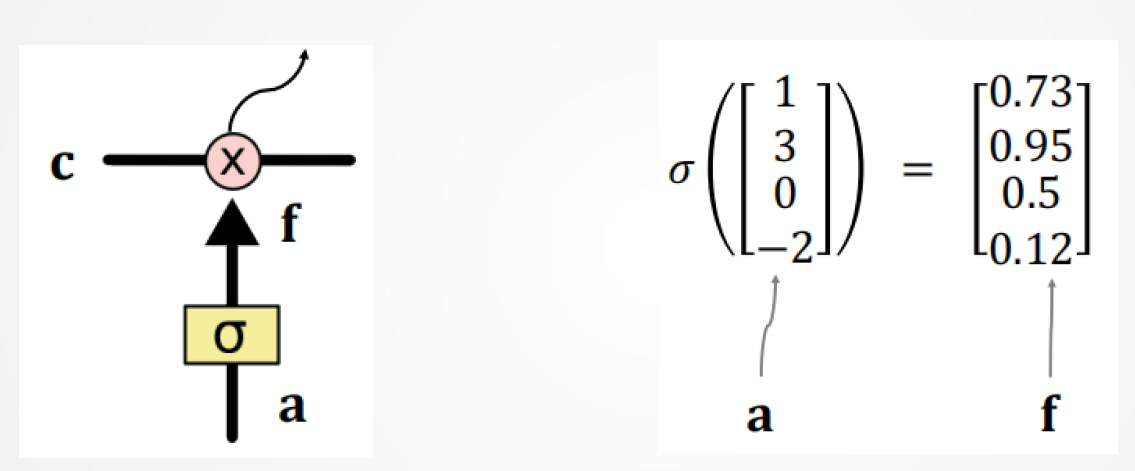
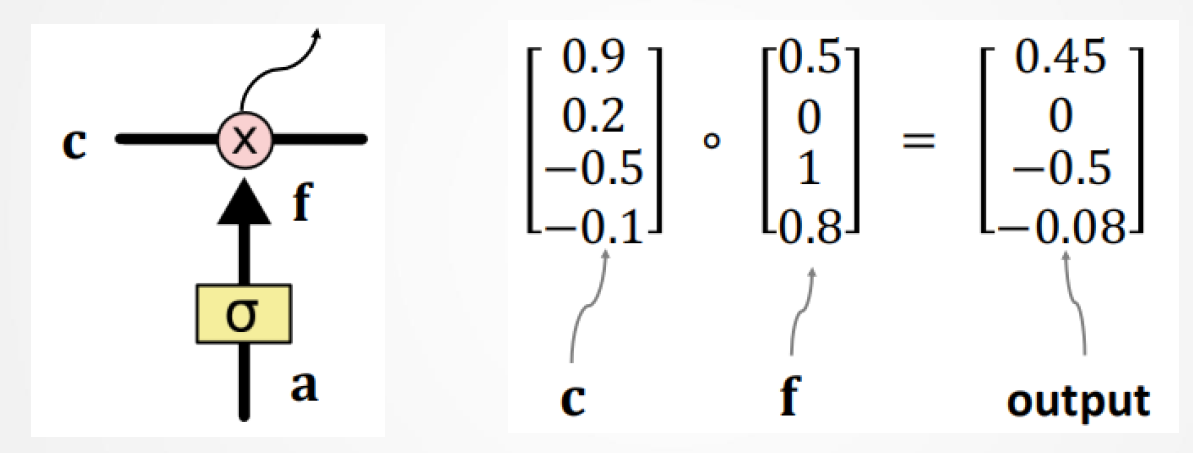
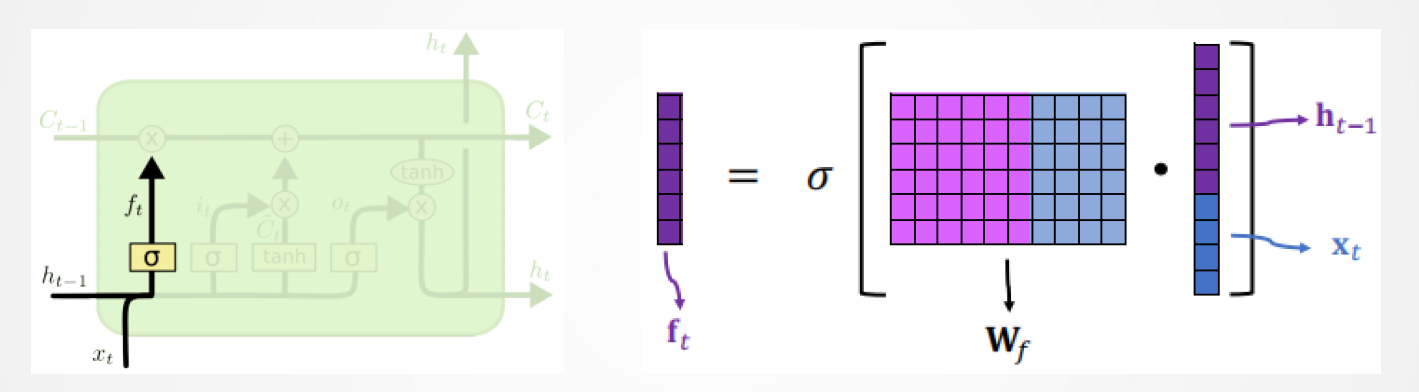
值为0:什么都记不住(0通过)
值为1:全记住(全部通过)
13.3 LSTM:输入门
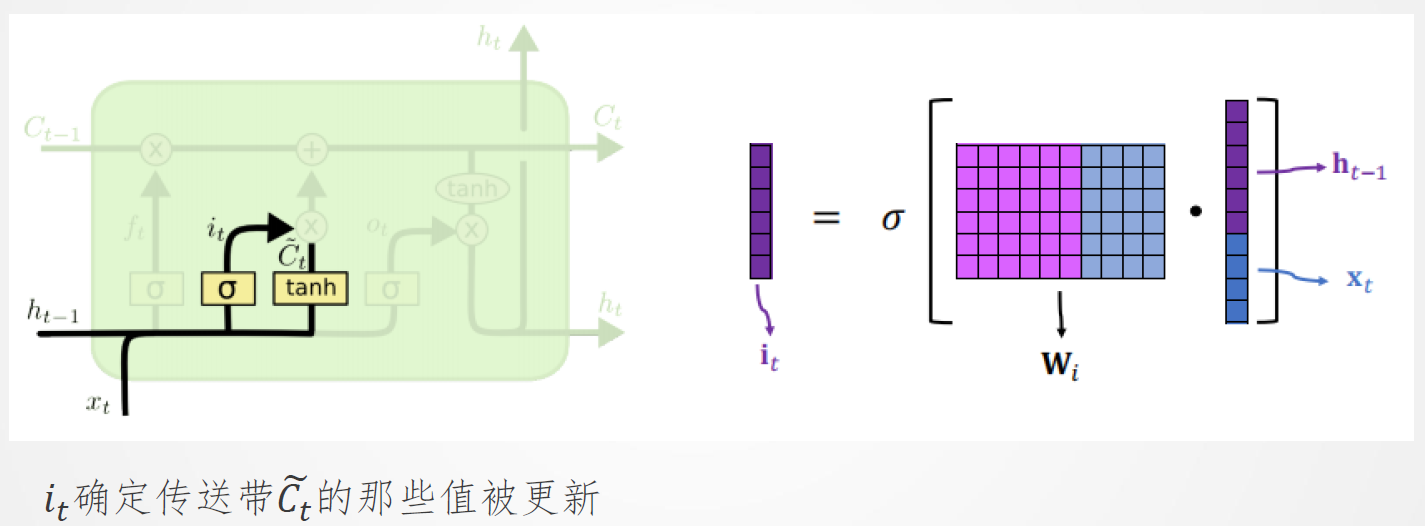
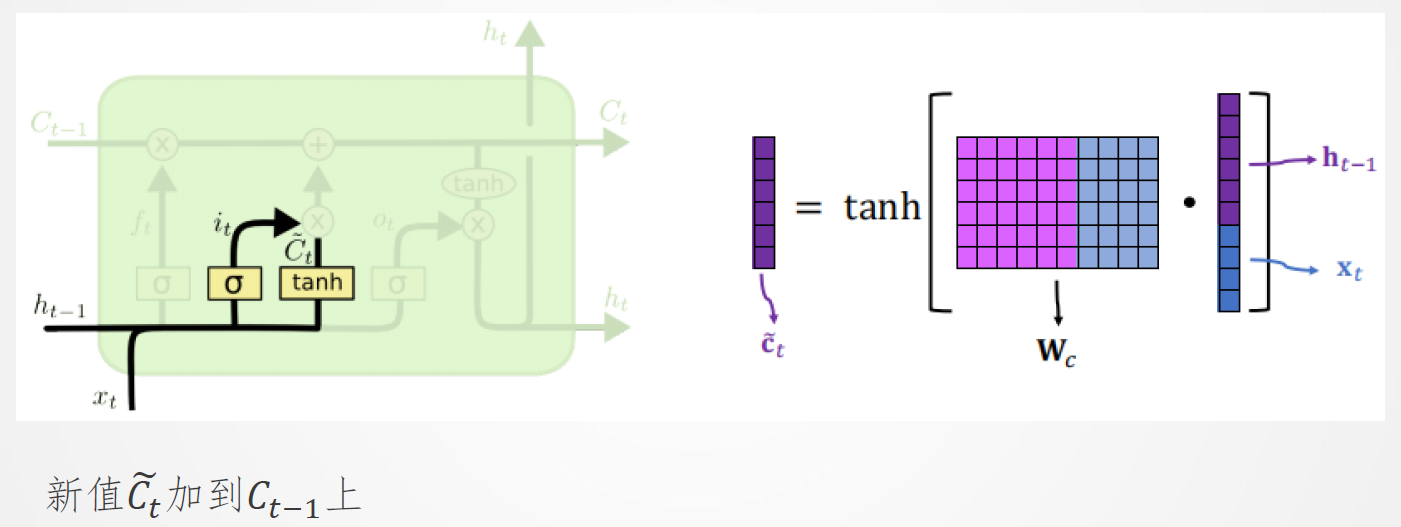
13.4 LSTM:更新传送带
计算传送带更新值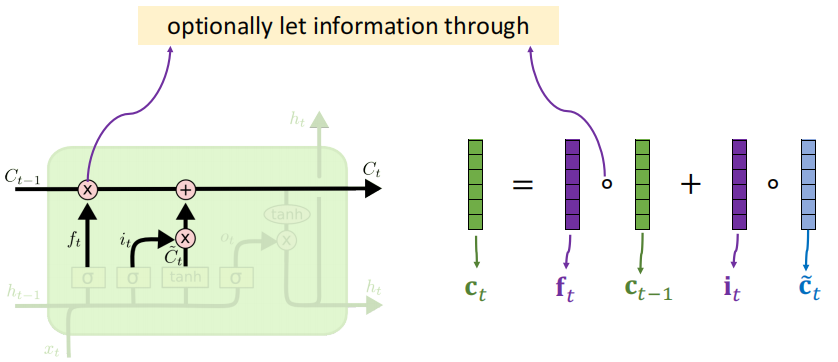
13.5 LSTM:输出门
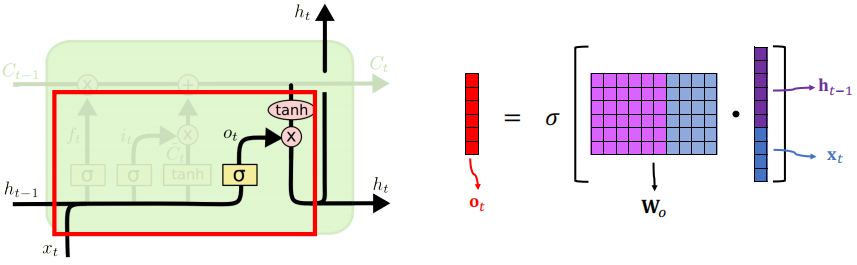
更新状态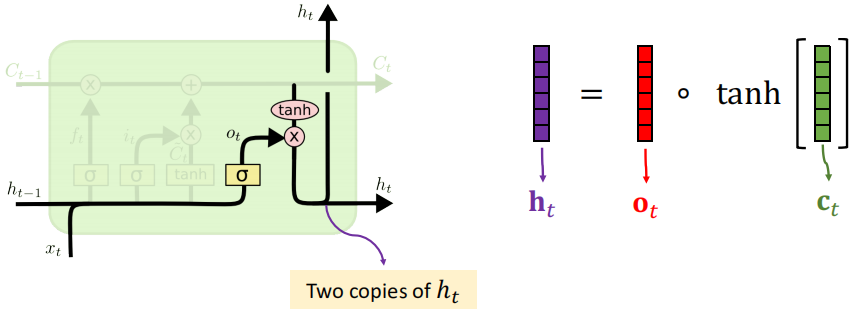
13.6 LSTM:总结
LSTM:参数量
参数量是RNN的4倍: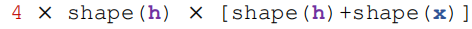
LSTM:输入输出和RNN相同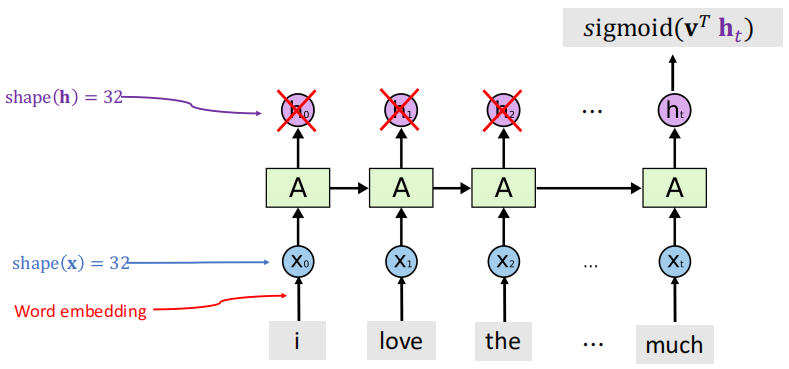
13.7 模型实现
参见《动手学深度学习》9.2节
十四、深度循环神经网络
14.1深度循环神经⽹络
回顾:RNN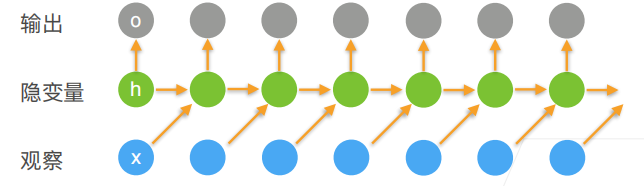
隐含状态可能很“深”,怎么办?−>具有𝑳个隐含层的深度循环神经网络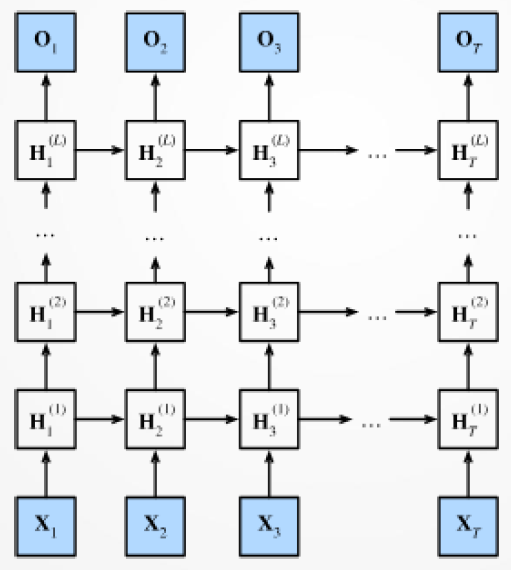
具有𝑳个隐含层的深度循环神经网络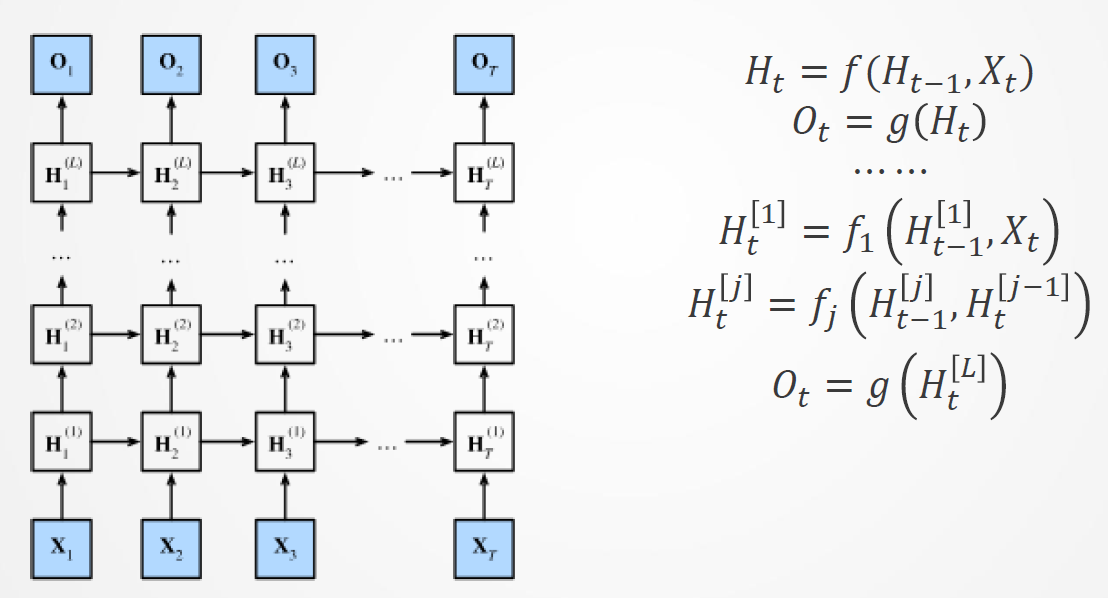

14.2 模型实现
参见《动手学深度学习》9.3节

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)