Google机器学习实践指南(TensorFlow特征工程六法)
分类标识列主要用于非数值类型(总类型是有限集合)的特征进行数值化,分类标识列视为分桶列的一种特殊情况,其将将分桶数据映射为一个具体数值。组合列主要适用于单个特征在独立使用时基本无法表达意义的场景方法使通过将两个或两个以上的特征组合起来构造成一个特征(称为特征组合)。主要用于将数据类别的数量非常大需要消耗大量内存的情况下,通过哈希处理对类别数量进行限制,其原理是利用哈希算法将不同的输入值强制划分成更
🔥 Google机器学习(11)-TensorFlow特征工程实战
Google机器学习实战(11)-特征列组合六大方法深度解析与应用
一、特征工程核心概念
▲ 特征处理本质:
通过特征工程将原始数据转化为模型可理解的特征表示,构建特征与标签的映射关系:
预测结果 = ∑(特征权重 × 特征值) + 偏置项
二、特征列类型详解
1. 数值列(Numeric Column)
适用场景:连续数值型数据
技术实现:
numeric_feature_column = tf.feature_column.numeric_column(
key="SepalLength",
dtype=tf.float64
)
2. 分桶列(Bucketized Column)

▲ 图1 分桶列数值转换流程
技术实现:
bucketized_feature_column = tf.feature_column.bucketized_column(
source_column = tf.feature_column.numeric_column("Year"),
boundaries = [1960, 1980, 2000]
)
分桶列主要用于需要根据数值范围将其值分为不同的类别组将成特征集,采用分桶列具有如下优势:
可以让模型接收更多的特征
可构造特征的非线性关系
桶分类型是一种独热矢量特征
例如分桶列需要将数据列按小于1960,大于等于1960小于1980,大于等于1980小于2000,大于等于2000进行分桶,代码实现数据分桶如下:

3. 分类标识列(Categorical Identity Column)

▲ 图2 分类标识编码流程
技术实现:
identity_feature_column = tf.feature_column.categorical_column_with_identity(
key='my_feature_b',
num_buckets=4
)
分类标识列主要用于非数值类型(总类型是有限集合)的特征进行数值化,分类标识列视为分桶列的一种特殊情况,其将将分桶数据映射为一个具体数值。代码实现效果类似如下: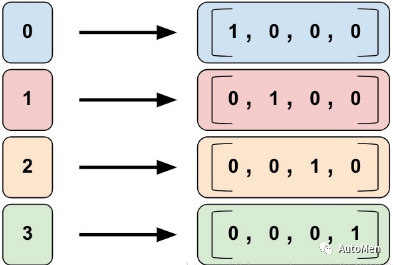
4. 分类词汇列(Vocabulary List Column)
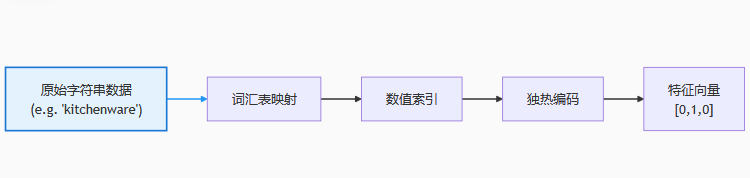
▲ 图3 词汇表独热编码示意图
技术实现:
vocabulary_feature_column = tf.feature_column.categorical_column_with_vocabulary_list(
key="product_category",
vocabulary_list=["kitchenware", "electronics", "sports"]
)
分类词汇列主要用于字符串映射到数值或分类值,分类词汇列提供了一种将字符串表示为独热矢量的好方法,代码实现效果类似如下: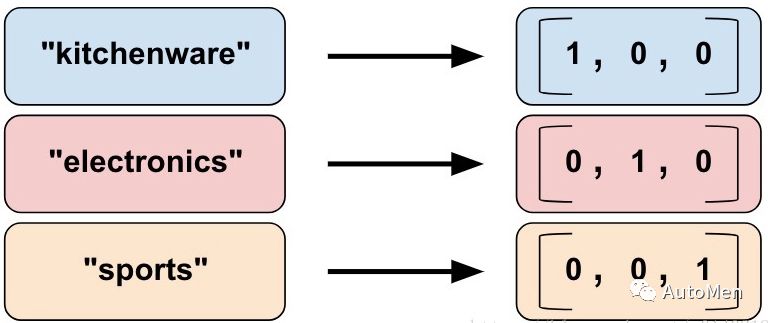
5. 哈希列(Hashed Column)

▲ 图4 哈希分桶机制
技术实现:
hashed_feature_column = tf.feature_column.categorical_column_with_hash_bucket(
key = "user_id",
hash_bucket_size = 100
)
哈希分桶机制
主要用于将数据类别的数量非常大需要消耗大量内存的情况下,通过哈希处理对类别数量进行限制,其原理是利用哈希算法将不同的输入值强制划分成更少数量的类别。
6. 组合列(Crossed Column)

▲ 图5 地理位置特征组合编码过程
技术实现:
crossed_feature = tf.feature_column.crossed_column(
["latitude", "longitude"],
hash_bucket_size=1000
)
组合列主要适用于单个特征在独立使用时基本无法表达意义的场景方法使通过将两个或两个以上的特征组合起来构造成一个特征(称为特征组合)。代码实现如下场景应用: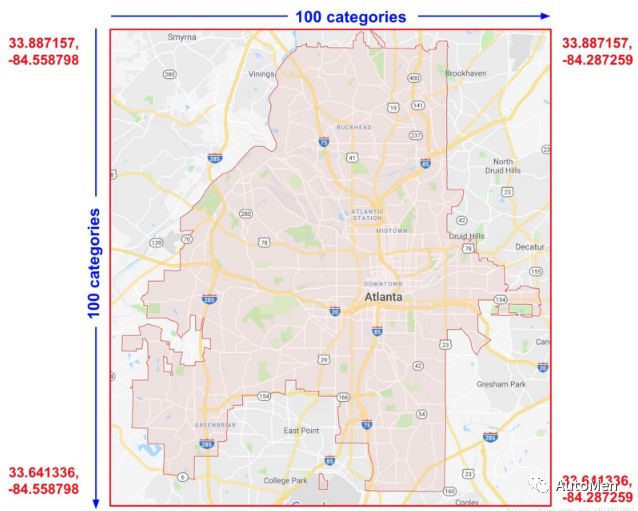
三、特征选择策略
| 特征类型 | 适用场景 | 内存消耗 | 计算效率 |
|---|---|---|---|
| 数值列 | 连续变量 | 低 | ⭐⭐⭐⭐ |
| 分桶列 | 区间划分 | 中 | ⭐⭐⭐ |
| 哈希列 | 高基数特征 | 低 | ⭐⭐ |
四、最佳实践
✅ 特征工程准则:
- 优先使用数值列处理连续数据
- 对高基数分类数据使用哈希列
- 时空数据采用组合列增强特征表达
✅ 性能优化:
dataset = tf.data.Dataset.from_tensor_slices(features)
dataset = dataset.batch(32).prefetch(1)
# 技术问答 #
Q:如何选择分桶数量?
A:根据数据分布采用等频/等宽分桶,通常5-10个桶为宜
Q:哈希冲突如何处理?
A:适当增加hash_bucket_size,一般设置为类别数的1/10
附录:学习资源
TensorFlow特征列官方指南:https://www.tensorflow.org/guide/feature_columns
特征工程实战案例:https://blog.csdn.net/amao1998/article/details/80191978
参考文献:
[1] TensorFlow特征处理机制解析
[2] 大规模特征工程优化实践

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 30
30 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)