PD³:通过适应性多智能体辩论的项目重复检测框架
项目重复检测对于项目质量评估至关重要,因为它通过防止对已经研究过的项目进行新的投资,提高了资源利用效率。这需要具备理解高层次语义并生成建设性和有价值的反馈的能力。现有的检测方法依赖于基本的词级或句级比较,或者单纯应用大型语言模型,缺乏为专家提供有价值的见解以及对项目内容和评审标准的深入理解。为了解决这个问题,我们提出了PD3PD3,一个通过适应性多智能体辩论的项目重复检测框架。受现实世界专家辩论的
Dezheng Bao
浙江大学
baodezheng@zju.edu.cn
Yueci Yang
浙江大学
baodezheng@zju.edu.cn
Xin Chen
浙江大学
xin.21@intl.zju.edu.cn
Zhengxuan Jiang
浙江大学
mystery_jiang@zju.edu.cn
Zeguo Fei
浙江大学
feizg@zju.edu.cn
Daoze Zhang
浙江大学
zhangdz@zju.edu.cn
Xuanwen Huang
独立贡献者
xuanwhuang@gmail.com
Junru Chen
浙江大学
jrchen_cali@zju.edu.cn
Chutian Yu
国网供电公司
yu_chutian@zj.sgcc.com.cn
Xiang Yuan
国网供电公司
yuan_xiang@zj.sgcc.com.cn
Yang Yang 1{ }^{1}1
浙江大学
yangya@zju.edu.cn
摘要
项目重复检测对于项目质量评估至关重要,因为它通过防止对已经研究过的项目进行新的投资,提高了资源利用效率。这需要具备理解高层次语义并生成建设性和有价值的反馈的能力。现有的检测方法依赖于基本的词级或句级比较,或者单纯应用大型语言模型,缺乏为专家提供有价值的见解以及对项目内容和评审标准的深入理解。为了解决这个问题,我们提出了PD3\mathbf{P D}^{3}PD3,一个通过适应性多智能体辩论的项目重复检测框架。受现实世界专家辩论的启发,它采用公平竞争的形式来引导多智能体辩论以检索相关项目。对于反馈,它结合了定性和定量分析以提高其实用性。使用涵盖超过20个专业领域的800多个真实电力项目数据来评估该框架,结果表明我们的方法在两个下游任务中分别优于现有方法7.43%7.43 \%7.43%和8.00%8.00 \%8.00%。此外,我们建立了一个在线平台Review Dingdang,以协助电力专家,在超过100个新提议项目的初步检测中节省了573万美元。
1 引言
项目重复检测对于质量评估非常重要,将新提议的项目与参考项目进行比较,以避免冗余的研究投资。近年来,研发资金和项目数量持续增长。例如,中国国家电网公司在2023年投资超过52.5亿美元用于科技项目,获得了8,521项授权专利[28]。美国能源部设立了智能电网拨款基金,
1{ }^{1}1 对应作者。
图1:(a) 缺乏严格偏序的情况案例。此案例展示了排名不可传递性:参考项目A、B和C形成两两比较循环,因为每个项目在研究内容、关键技术或应用结果方面比其他项目更接近目标项目。(b) 检索到的参考项目数量中的前五覆盖率。
从2022年到2026年投资3000亿美元资助改善电力系统的项目[29]。因此,项目数量的增长扩大了比较需求,使手动重复检测变得越来越困难和不可持续。此外,项目数量的快速增长和资源投入的增加需要更全面和有价值的检测反馈,以帮助合理分配资源并改进新提议的项目。简单的数值指标无法为专家提供详细信息或帮助申请人优化他们的项目,突显了对更全面反馈的需求。
项目重复检测的主要目标是检索最相关的参考项目。理想的检测方法需要深入理解项目的语义和领域知识,并根据领域特定的标准定制召回能力。传统方法包括基于词频的方法(如ROUGE [17],BM25 [23])和基于向量距离的方法(如具有不同参数规模的嵌入器:Bert [7],gte [15])。基于词频的方法使用文本中的词出现情况来表示文章间的重复。然而,这些方法过于依赖分词化,使其容易受到同义词替换和其他文本操作的影响,从而在检测故意避免重复时无效。此外,它们对所有文本的统一处理阻止了在重复检测中优先考虑核心项目内容。为解决这些局限性,其他研究人员提出了通过将全文语义编码为向量的基于向量距离的方法。然而,它们的静态语义表示缺乏任务特定的适应性。尽管一些嵌入模型(如gte,bge [4, 14])通过前缀引导预训练(如“给定一个网络搜索查询,检索回答查询的相关段落”在gte中)增强了任务对齐性,但其高度压缩的全文嵌入仅捕获粗粒度的语义关系,缺乏更详细的语义比较。由于其灵活性不足、粗粒度和相似性函数[27]的有限表达性,这些方法主要用于初步检索。
对于进一步的细粒度检索,大型语言模型(LLMs)提供了一个直接解决方案。对于需要深度语义理解的任务(如重复检测或同行评审),LLMs可以作为专家评审员利用其理解和生成能力。例如,LLMs成功应用于自动化同行评审[24, 35]。当前基于LLM的检索方法通常要么(1)利用LLMs作为评委通过逐点评分或成对比较[37]来决定排名,要么(2)使用链式思维(CoT)提示或使用具有推理能力的LLMs[12]来进行任务感知的数据排序。得益于测试时的可扩展性,这些方法克服了刚性的词或向量依赖。虽然上述逐点评分和成对比较方法推进了该领域,但项目重复检测仍然具有挑战性。
从场景角度来看,如何在没有严格偏序的情况下从参考项目中检索是一个挑战。现有方法的性能受限于数据集中存在偏序关系(其中A > B且B > C ⇒ A > C)。然而,重复检测中项目的相关性关系不是严格的偏序。如图1 (a)所示,相关性评估必须考虑多个因素(如研究内容、关键技术、应用成果),即使是有经验的专家也无法通过逐点或成对比较提供明确的排名。这表明需要更多关于整个参考项目集的全局信息。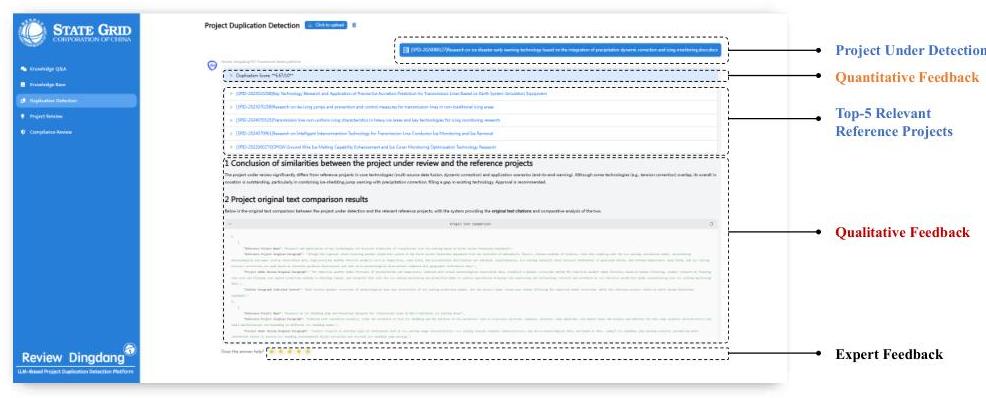
图2:基于PD3\mathrm{PD}^{3}PD3的电力项目重复平台Review Dingdang。
然而,当前的逐点或成对评分方法(也包括基于向量距离的方法)错误地假设了偏序关系,限制了其有效性。
从方法论的角度来看,有效的检测方法应支持多视角分析以确保全面的项目比较。传统的单LLM方法本质上受限于其单一分析视角。多智能体辩论(MAD)范式 [3,16,8][3,16,8][3,16,8] 提供了一个有前途的解决方案,通过协调多个LLM代理模拟审议辩论。通过考虑所有候选对象的全局信息,MAD提供了更全面的分析,融合了不同代理的不同观点。然而,直接应用普通的MAD在同时处理所有候选参考项目时变得不切实际,因为长上下文导致性能下降。先前的工作[18]表明,较长的上下文会降低模型性能,因为注意力丢失在中间。图1 (b)暗示,为了覆盖大约90%90 \%90%的前5个相关项目,至少需要30个候选人。在这种规模的上下文长度下,无论是单LLM还是基于MAD的方法的性能都会下降。虽然基于向量距离的方法有助于缩小候选池,但大幅减少候选人数会影响最终性能,因为过早排除相关项目,未能从根本上解决问题。
为克服这些局限性,我们提出PD3\mathbf{P D}^{3}PD3,一个通过适应性多智能体辩论的项目重复检测框架。通过改进的MAD机制,PD3\mathrm{PD}^{3}PD3通过限制并发项目比较优化上下文长度,同时通过其轮循竞赛结构保持必要的上下文信息。这种平衡方法能够更准确地检索出前5个最相关的参考项目。除了检索之外,一个有用的重复检测框架还应通过有价值的见解增强人机协作。与仅输出数值分数或逐字匹配的传统方法不同,PD3\mathrm{PD}^{3}PD3生成了定性摘要(包含关键相似性结论和原文比较)和定量重复分数。这种双重反馈方法帮助专家高效验证结果,同时为申请人提供清晰的项目改进指导,使PD3\mathrm{PD}^{3}PD3成为一个以人为中心的框架。
基于PD3\mathrm{PD}^{3}PD3,我们开发了一个名为Review Dingdang的在线平台,以帮助电力系统专家检测重复的科研项目。在2025年4月平台的现场测试中,该平台表现出显著的有效性,防止了约573万美元被投资于重复项目。我们的主要贡献包括:
- 我们提出了PD3\mathrm{PD}^{3}PD3,一个通过适应性多智能体辩论的项目重复检测框架,据我们所知,这是第一个基于LLM的项目重复检测框架。
-
- 在我们的框架中,我们引入了一种新颖的轮循竞赛格式的MAD检索方法,实现了更公平和全面的候选评估。此外,我们首次提出了基于LLM的双重反馈设计用于项目重复检测,整合了定性和定量分析以增强人机协作和支持。
-
- 通过对涉及多个专业领域的实际电力项目数据的验证,PD3\mathrm{PD}^{3}PD3在两个下游任务中分别优于基线方法7.43%7.43 \%7.43%和8.00%8.00 \%8.00%。基于PD3\mathrm{PD}^{3}PD3,
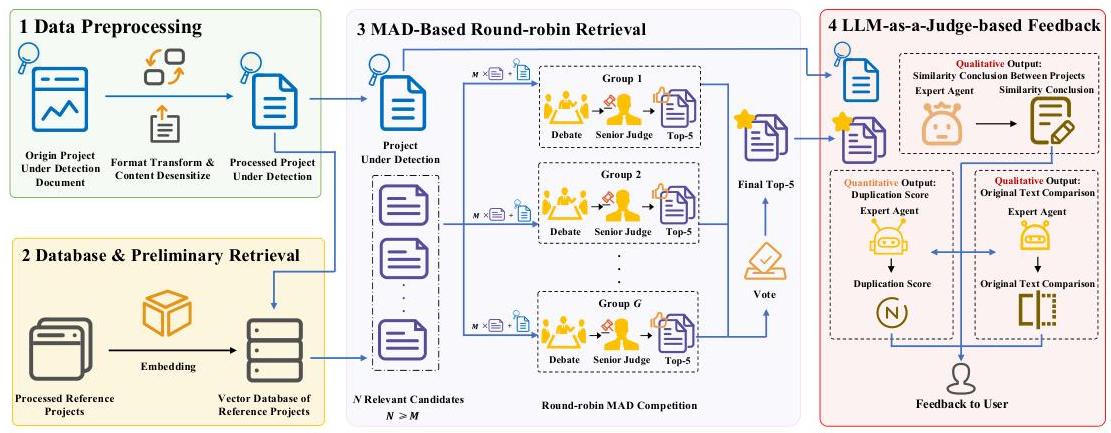
图3:PD3\mathrm{PD}^{3}PD3框架概述。根据待检测项目的输入/输出序列,框架包括四个部分:数据预处理、数据库和初步检索、基于MAD的轮循检索和基于LLM-as-a-Judge的反馈。
我们还实施了一个在线平台Review Dingdang,在新项目现场测试期间通过防止数百万美元的冗余投资实现实际影响。
2PD32 \mathrm{PD}^{3}2PD3框架设计
2.1 概述
问题公式化 在介绍整体框架之前,我们首先形式化本文解决的关键问题。设PPP表示一个项目,定义两个主要的项目重复检测任务如下:(1) 为给定的待检测项目PaP_{\mathrm{a}}Pa检索前K个最相关的参考项目R={Pj∗}j=1K⊆SR=\left\{P_{j}^{*}\right\}_{j=1}^{K} \subseteq SR={Pj∗}j=1K⊆S,其中S={Pi}i=1MS=\left\{P_{i}\right\}_{i=1}^{M}S={Pi}i=1M是参考项目的候选集。(2) 根据检索结果R={Pi}i=1KR=\left\{P_{i}\right\}_{i=1}^{K}R={Pi}i=1K提供一个定量的综合重复分数su∈Ds_{u} \in \mathcal{D}su∈D和(可选的)定性评估输出,其中D\mathcal{D}D是分数域,分数函数f:(Pa,R)→Df:\left(P_{\mathrm{a}}, R\right) \rightarrow \mathcal{D}f:(Pa,R)→D评估PaP_{\mathrm{a}}Pa相对于RRR的整体重复水平。
如图3所示,PD3\mathrm{PD}^{3}PD3框架包括四个关键组件。我们在深入讨论核心组件之前,先简要概述每个组件:
1 数据预处理 为处理格式和敏感级别各异的异构项目数据(无论用于检测还是参考),框架首先通过格式统一、敏感信息脱敏(通过正则表达式匹配)和文本内容提取标准化输入。
2 数据库和初步检索 框架维护一个向量数据库(离线可更新),用于存储参考项目。框架使用待检测项目的文本内容筛选数据库,检索出30个候选参考项目(最佳数量,已在初步实验中验证;见图1 (b))。
3 基于MAD的轮循检索 该模块将30个候选项目组织成若干个5 -out-of- MMM轮循子竞赛任务。多个专家代理辩论以选择每个子竞赛中的前5名候选人。随后由资深评委通过分析辩论记录作出小组最终决策。通过聚合所有子任务的投票确定最终的前5个项目。
4 基于LLM-as-a-Judge的反馈 该模块通过以下方式分析待检测项目:(1) 生成相似性结论,(2) 使用LLM评委(基于评审标准)分配定量的重复分数,(3) 使用文本比较代理丰富输出,突出原始文本中的具体相似表达。综合反馈为人专家提供了可测量和可操作的见解。
2.2 基于MAD的轮循检索:辩论让真相大白
检索最相关的参考项目是项目重复检测中的关键步骤。高质量的检索显著减少了下游工作量,而错误可能会危及整个检测过程。受实际专家讨论的启发,我们提出了一种改进的多智能体辩论机制。我们的方法通过有限数量的辩论回合让更有依据支持的项目脱颖而出,自然胜出。
与为问答任务设计的传统MAD方法(如MMLU-Pro [33],GPQA [22])不同,我们的场景面临独特的挑战:检索任务必须在全局信息和上下文长度约束之间取得平衡,需要定制分解而非直接应用MAD。
为了在两个冲突的约束之间达到最佳折衷,我们通过轮循竞赛机制增强了普通的MAD。受现实世界锦标赛的启发,这种格式确保了公平性而不是强度,不像淘汰赛或双败淘汰制系统。在我们的任务中,候选对象之间的公平竞争至关重要,证明轮循格式更为合适。
具体来说,我们将30个候选项目随机分成6组,每组包含5个候选参考项目。然后将这些组织成G=C6M/5G=C_{6}^{M / 5}G=C6M/5个唯一的5 -out-of- MMM子竞赛(非重复组合),每个子竞赛由来自M/5M / 5M/5组的MMM个参考项目组成(在我们的设置下M=20M=20M=20和G=C6M/5=15G=C_{6}^{M / 5}=15G=C6M/5=15)。在每个小组子竞赛中,独立的专家代理首先选择他们的前5名候选人并简要说明理由。然后他们参与结构化的辩论——批评提案、回答问题或修改选择,同时审查所有之前的辩论记录后再发言。经过固定数量的辩论回合后,资深专家根据话语作出最终的小组决策。一旦所有小组竞赛结束,我们通过投票(受[13]中基于知识的任务投票的启发)聚合结果以选择全球前5名。这种格式的另一个优势是小组竞赛是独立的,可以并行运行,显著减少了执行时间。
总之,我们的改进的基于MAD的轮循检索通过利用LLM深入分析项目内容和评审标准,实现了更准确的横向比较和候选选择。与其他基于LLM的方法相比,这种方法在以下几个方面优于LLM-as-a-Judge、R1-like方法和普通MAD方法:(1) 消除因不受控制的推理长度造成的成本不确定性;(2) 更好地平衡非严格偏序关系与上下文长度;(3) 通过并行任务分解提高效率,同时保留测试时扩展的好处。
2.3 基于LLM-as-a-Judge的反馈:定量和定性输出
通过文献回顾和专家咨询,我们识别出重复检测中的一个关键限制:缺乏建设性反馈。有效的反馈应通过提供可操作的见解来桥接人机交互,从而提高效率和项目质量。定量上,大多数算法无法为评审内容生成全面的复杂度分数,不一致的评分范围/分布削弱了结果的可信度。定性上,很少有算法能检测超出连续词匹配的重复,忽略了研究主题、应用技术和重点领域的重叠。这种反馈缺陷阻碍了评审效率,迫使专家和申请人依赖僵硬的重复阈值。因此,高质量项目中的非核心重复风险被误判,而有价值的项目错过了改进机会。
为解决这些限制,我们开发了一个基于LLM的专家代理反馈模块,提供全面的定量和定性反馈。对于定量反馈,我们采用全项目级别的LLM-as-a-Judge方法,定义明确的标准(1-10分,高分表示更高的重复度)和任务特定的提示。与逐点或成对评分不同,我们的代理使用所有前5个相关的参考项目作为上下文评估目标项目,避免依赖严格的序数比较,同时利用更丰富的全局信息。这种方法还提供了灵活性:评分规则可以通过修改提示轻松适应——例如,指示代理在检测到任何一个高度相关的参考项目时分配高分。
此外,我们设计了两种关键的定性反馈:(1) 相似性结论。将待检测项目与前5个相关的参考项目进行比较的人类可读结论,突出主要内容、关键技术及应用成果的相似之处。该总结源自成对分析,不仅有助于重复审查,还增强了定量评估性能,当集成到输入中时。(2) 原始文本比较。利用LLM,该输出根据相似性结论识别原始内容中的语义相似文本段。与传统的基于单词的重复检测不同,这种方法有效检测相关内容,同时减轻了诸如词替代等欺骗策略的影响。
作为一个能够直接与人互动的模块,我们优先改进设计以提高效率并提供切实的好处。通过优化定量结果和弥补定性分析的差距,PD3\mathrm{PD}^{3}PD3显著增强了其支持用户的能力,建立了更以人为中心的项目重复检测框架。
3 实验
3.1 数据集
为了评估PD3\mathrm{PD}^{3}PD3的真实世界性能,我们分析了一个包含833个科学和技术项目(从2022年到2024年)的数据集,平均长度为957个标记,数据来源于中国国家电网公司(SGCC)。这些项目涵盖了22个广泛的领域,包括调度、配电网、输变电、数字化和信息化。常见主题包括基于AI的电力消耗预测、线路覆冰预测和除冰、以及碳排放检测。人类专家主要评估研究内容、关键技术及应用成果以进行重复检测。详见附录A.2节。
3.2 实验设置
任务 利用第2.1节中描述的符号,我们定义了两个带有电力领域专家注释数据的评估任务。
任务1:最相关的前5个检索 给定一个待检测项目PuP_{\mathrm{u}}Pu和从数据库中使用基于向量距离检索得到的30个候选参考项目集合S={Pi}i=130S=\left\{P_{i}\right\}_{i=1}^{30}S={Pi}i=130。任务输出一个结果集R={Pj∗}j=15⊆SR=\left\{P_{j}^{*}\right\}_{j=1}^{5} \subseteq SR={Pj∗}j=15⊆S,包含最相关的前5个参考项目。
为了成本效率,我们随机选择了331个科学和技术项目作为测试项。评审专家为每个测试项标注最优结果R^={P^j∗}j=15\hat{R}=\left\{\hat{P}_{j}^{*}\right\}_{j=1}^{5}R^={P^j∗}j=15。我们采用了交叉重复检测设置:当一个项目被检测时,所有其他832个项目都作为参考候选。这种方法不像仅与参考项目比较,更能反映实际情况,即同一批次的项目一起被检测。
任务2:项目的综合重复分数评估 给定两个待检测项目Pu−AP_{\mathrm{u}-\mathrm{A}}Pu−A和Pu−BP_{\mathrm{u}-\mathrm{B}}Pu−B,以及它们的前5个相关参考项目集合RA={PAj}j=15R_{A}=\left\{P_{A j}\right\}_{j=1}^{5}RA={PAj}j=15和RB={PBj}j=15R_{B}=\left\{P_{B j}\right\}_{j=1}^{5}RB={PBj}j=15,任务输出重复分数su−A,su−B∈Ds_{\mathrm{u}-\mathrm{A}}, s_{\mathrm{u}-\mathrm{B}} \in \mathcal{D}su−A,su−B∈D。其中D\mathcal{D}D是分数范围。
由于不同的算法使用不同的分数范围D\mathcal{D}D和不同的分布评分函数f:(Pu,R)→Df:\left(P_{\mathrm{u}}, R\right) \rightarrow \mathcal{D}f:(Pu,R)→D,我们设置了任务2以确保公平比较。对于测试集,我们从331个人工标注的项目中随机抽取100对项目C={(Pu−Aj,Pu−Bj)}j=1100C=\left\{\left(P_{\mathrm{u}-\mathrm{A} j}, P_{\mathrm{u}-\mathrm{B} j}\right)\right\}_{j=1}^{100}C={(Pu−Aj,Pu−Bj)}j=1100。三位专家独立投票哪个项目具有更高的重复度,产生标注H^={Hj}j=1100\hat{H}=\left\{H_{j}\right\}_{j=1}^{100}H^={Hj}j=1100,其中Hj∈{u−A,u−B}H_{j} \in\{\mathrm{u}-\mathrm{A}, \mathrm{u}-\mathrm{B}\}Hj∈{u−A,u−B}。
基线。为了全面比较,我们评估了来自四个类别的方法:基于词频、基于向量距离、基于LLM和基于MAD:
- 基于词频的方法(WF):ROUGE-L [17]:通过最长公共子序列(LCS)衡量文本相似度,常用于摘要评估。BM25 [23]:一种增强的TF-IDF方法,通过词频和逆文档频率计算查询-文档相关性。
-
- 基于向量距离的方法(VD):gte-Qwen2-1.5B-instruction [15](gte-1.5B):基于Transformer的嵌入模型(带/不带指令)用于查询增强,也是实验中从数据库初步检索使用的模型。重新排序器:使用更大的模型(如gte-Qwen2-7B-instruction [15](gte-7B))或预训练的重新排序器
- 表1:任务1的实验结果:最相关的前5个检索
| 方法 | 分类 | 精确度/ 0/10 / 10/1 | Match@K | | | | |
| :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: |
| | | | K=1\mathrm{K}=1K=1 | K=2\mathrm{~K}=2 K=2 | K=3\mathrm{~K}=3 K=3 | K=4\mathrm{~K}=4 K=4 | K=5\mathrm{~K}=5 K=5(命中率@5) |
| Random | 随机 | 0.1680 | 209 | 0.6314 | 64 | 0.1934 | 5 | 0.0151 | 0 | 0.0000 | 0 | 0.0000 |
| ROUGE-L | WF | 0.2399 | 248 | 0.7492 | 125 | 0.3776 | 23 | 0.0695 | 1 | 0.0030 | 0 | 0.0000 |
| BM25 | | 0.2870 | 273 | 0.8248 | 145 | 0.4381 | 52 | 0.1571 | 5 | 0.0151 | 0 | 0.0000 |
| gte-1.5B | VD | 0.3813 | 296 | 0.8943 | 219 | 0.6166 | 97 | 0.2931 | 18 | 0.0544 | 1 | 0.0030 |
| 带指令的gte-1.5B | | 0.3782 | 294 | 0.8882 | 213 | 0.6435 | 96 | 0.2900 | 21 | 0.0636 | 2 | 0.0060 |
| 作为重新排序器的gte-5B | | 0.3897 | 298 | 0.9003 | 212 | 0.6405 | 105 | 0.3172 | 29 | 0.0876 | 1 | 0.0030 |
| 作为重新排序器的jina | | 0.2798 | 275 | 0.8308 | 141 | 0.4260 | 42 | 0.1269 | 4 | 0.0121 | 1 | 0.0030 |
| DeepSeek V3 | LLM | 0.3686 | 297 | 0.8973 | 194 | 0.5861 | 88 | 0.2659 | 27 | 0.0816 | 4 | 0.0121 |
| DeepSeek R1 | | 0.3952 | 298 | 0.9003 | 214 | 0.6465 | 110 | 0.3323 | 29 | 0.0876 | 3 | 0.0091 |
| LLM-as-a-Judge | | 0.3849 | 303 | 0.9154 | 211 | 0.6375 | 99 | 0.2991 | 21 | 0.0634 | 3 | 0.0091 |
| MAD Direct | 具有不同竞赛格式的MAD | 0.3964 | 307 | 0.9275 | 229 | 0.6918 | 129 | 0.3897 | 42 | 0.1269 | 3 | 0.0091 |
| MAD Traversal | | 0.4211 | 304 | 0.9184 | 224 | 0.6727 | 125 | 0.3776 | 30 | 0.1208 | 4 | 0.0121 |
| MAD Residue | | 0.4272 | 309 | 0.9335 | 234 | 0.7069 | 125 | 0.3776 | 35 | 0.1057 | 4 | 0.0121 |
| MAD Sliding Window | | 0.4344 | 307 | 0.9275 | 233 | 0.7039 | 133 | 0.4018 | 42 | 0.1269 | 4 | 0.0121 |
| PD 3{ }^{3}3 MAD Round-Robin(Ours) | MAD | 0.4423 | 310 | 0.9366 | 238 | 0.7190 | 133 | 0.4018 | 41 | 0.1239 | 10 | 0.0302 |
(jina-reranker-v2-base-multilingual [26](jina),bge-reranker-v2-m3 [14, 4](bge)) 用于候选重新排序。
- 基于LLM的方法(LLM):DeepSeek V3 [6]:标准LLM,直接从提示生成响应。DeepSeek R1 [12]:增强推理的LLM,在响应前进行自我批评。LLM-as-a-Judge [3, 16, 8](使用DeepSeekV3作为基础模型):使用单个LLM作为法官并通过生成或评分方法评估任务。
-
- 基于MAD的方法具有不同的竞赛格式(MAD):Direct:用于5-out-of-30检索的普通MAD。Traversal:每轮从10个候选者中选出5个获胜者,然后将获胜者与5个新候选者合并直到完成。Random:与轮循子事件计数匹配但每轮随机选择MMM参与者。Sliding Window:保持轮循子事件计数但通过滑动窗口(步长=1)选择MMM参与者。
设置 我们使用gte-Qwen2-1.5B-instruction(无指令)作为嵌入模型,从矢量数据库检索中获取任务1的初步30个候选项目。
- 基于MAD的方法具有不同的竞赛格式(MAD):Direct:用于5-out-of-30检索的普通MAD。Traversal:每轮从10个候选者中选出5个获胜者,然后将获胜者与5个新候选者合并直到完成。Random:与轮循子事件计数匹配但每轮随机选择MMM参与者。Sliding Window:保持轮循子事件计数但通过滑动窗口(步长=1)选择MMM参与者。
而在任务2中,对于缺乏直接重复分数输出的方法,我们报告了前5个候选者的最大值和平均值以确保公平和平衡的比较。此外,任务2在使用不同前5个参考集RRR的两种设置下评估评分方法:(1)人工检索:任务1中统一的专家注释参考集,允许直接方法比较。(2)方法检索:特定于方法的前5个参考集,评估端到端评审性能。由于任务2的专家注释来源于任务1的注释,可用于评估整体性能。
对于PD3\mathrm{PD}^{3}PD3,我们选择DeepSeek V3作为基础模型。作为一种开源模型,它在中文支持和基准性能方面表现出色[30]。更多细节请参阅附录A.3。在MAD轮循检索中,我们将代理数量和辩论轮数(初始轮除外)分别设置为3和2,参照[8]中的设置。
评估指标 在任务1中,我们采用Precision@5和Match@K。Precision@5 =∣R∧R^∣/5=|R \wedge \hat{R}| / 5=∣R∧R^∣/5 衡量与专家选择的重叠程度。Match@K =∑I(∣R∧R^∣≥K),K=1,2,…,5=\sum \mathbb{I}(|R \wedge \hat{R}| \geq K), K=1,2, \ldots, 5=∑I(∣R∧R^∣≥K),K=1,2,…,5 计算与专家选择重叠大于等于K的结果。其中I(⋅)\mathbb{I}(\cdot)I(⋅)是指示函数(如果为真则为1,否则为0)。特别地,Match@1≡1 \equiv1≡ Hit Rate@5。对于Match@K,我们还以Match@K!(Match@K/测试集大小)的形式报告其比率。
在任务2中,我们使用100个测试集上的Accuracy,采用两种评估方法:(1)原始组:严格以专家多数意见为真实值。(2)加权组:以专家投票为权重(例如,2A:1B →\rightarrow→ B得分0.33)。这是考虑到专家分歧反映了样本比较难度和潜在的多维重复率。
3.3 实验结果
任务1分析 表1呈现了任务1的实验结果。我们提出的具有轮循竞赛的MAD方法在所有指标上均取得了优异的结果。具体而言,它平均提高了Precision@5 7.43%7.43 \%7.43%,并在Match@K上显示出一致的提升
表2:任务2的实验结果:项目的综合重复分数评估。
| 方法 | 分类 | 人工检索 | 方法检索 | |||
|---|---|---|---|---|---|---|
| Acc 原始组 | Acc 加权组 | Acc 原始组 | Acc 加权组 | |||
| ROUGE-L MAX | WF | 0.6200 | 0.5867 | 0.5600 | 0.5733 | |
| ROUGE-L AVG | 0.6400 | 0.5933 | 0.6500 | 0.6233 | ||
| BM25 MAX | WF | 0.5300 | 0.5500 | 0.5300 | 0.5500 | |
| BM25 AVG | 0.5300 | 0.5500 | 0.5400 | 0.5533 | ||
| gte-1.5B MAX | VD | 0.5800 | 0.4900 | 0.6500 | 0.5100 | |
| gte-1.5B AVG | 0.6500 | 0.5400 | 0.6100 | 0.5100 | ||
| 带重新排序器的gte-1.5B MAX | VD | - | - | 0.6300 | 0.4900 | |
| 带重新排序器的gte-1.5B AVG | - | - | 0.6200 | 0.5200 | ||
| LLM-as-a-Judge MAX | VD | 0.5000 | 0.4867 | 0.4700 | 0.4500 | |
| LLM-as-a-Judge AVG | 0.5800 | 0.5767 | 0.6400 | 0.6200 | ||
| PD 3{ }^{3}3 反馈(我们的) | MAD | 0.6400 | 0.6267 | 0.6600 | 0.6300 | |
| 带结论的PD 3{ }^{3}3 反馈(我们的) | - | - | 0.6700 | 0.6467 |
(K=1-5),分别提升了5.14%,11.62%,11.74%,5.09%5.14 \%, 11.62 \%, 11.74 \%, 5.09 \%5.14%,11.62%,11.74%,5.09%, 和2.32%2.32 \%2.32%。基于词频和向量距离的传统方法效果有限,表明这些简单方法不足以满足重复检测检索任务。在基于LLM的方法中,DeepSeek R1和LLM-as-a-Judge优于其他方法(包括DeepSeek V3),表明推理增强可以在推理过程中更好地利用LLM能力。基于MAD的方法的卓越表现表明,当不存在严格的部分顺序关系时,辩论机制在整合全局信息方面的有效性。
我们在MAD方法中评估了各种竞赛格式以分析其对性能的影响。直接进行5-out-of-30检索而无需分解的MAD Direct显示了最差的结果。在所有竞赛格式中,MAD Traversal通过增加后期候选人的最终获胜机会创造了不公平性。MAD Random和MAD Sliding Window改进了候选人的曝光率,但未能确保平等竞争。我们的轮循竞赛格式保证了所有候选人平等的参与机会,实现了最佳性能。
Match@K指标中不同的KKK设置进一步揭示了随着任务难度增加(更高的K值),我们的方法的优势逐渐增大。与基线相比,它在K=1K=1K=1时平均提升了5.81%5.81 \%5.81%,在K=2K=2K=2时提升了19.27%19.27 \%19.27%,在K=3K=3K=3时提升了41.26%41.26 \%41.26%,在K=4K=4K=4时提升了69.78%69.78 \%69.78%,在K=5K=5K=5时提升了332.86%332.86 \%332.86%。这突显了我们的方法更具竞争力且具有更大的应用价值。
任务2分析 表2呈现了任务2的实验结果。1{ }^{1}1 我们的方法在所有检索设置下的两种评估设置中均优于基线。
在"人工检索"设置下,它在各组中平均提升了6.13%6.13 \%6.13%和8.00%8.00 \%8.00%,表明在相同输入下生成更合理的定量反馈。"加权组"中较大的提升(8.00%8.00 \%8.00%)特别表明我们的方法更符合人类评审专家的偏好。在"方法检索"设置下,性能提升增加到7.00%7.00 \%7.00%和9.00%9.00 \%9.00%,确认更好的检索增强了最终评分质量,并验证了PD3\mathrm{PD}^{3}PD3的有效性。值得注意的是,当将相似性总结作为先验知识纳入时,优势进一步扩大到8.00%8.00 \%8.00%和10.67%10.67 \%10.67%,突显了中介代理处理在无需参考答案的情况下优化定量反馈的能力。
1{ }^{1}1 在人工检索设置中,由于手动注释的前5个相关文档的标准化使用,重新排序器得分被省略,而带有结论的PD3\mathrm{PD}^{3}PD3反馈得分也被排除,因为它们代表仅适用于方法检索设置的复合性能指标。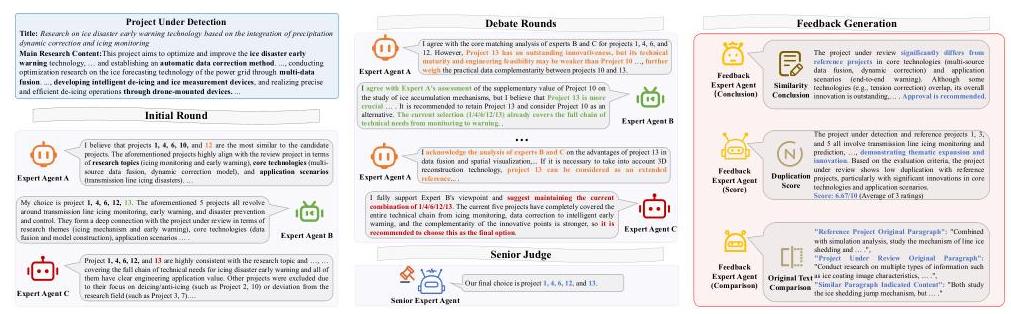
图5:由PD3\mathrm{PD}^{3}PD3进行的Review DingDang检测过程的一个案例研究。在一个子竞赛阶段,三位专家首先独立选择他们的前5个选择。经过辩论各自不同的观点后,专家A最终接受了专家B和C的观点。然后资深评委做出最终决定。通过投票选出的前5个参考项目进入反馈阶段,进行定量评分和定性反馈。
3.4 超参数分析

图4:(a) 不同组大小的性能比较。(b) 不同辩论轮数的性能比较。© 不同辩论代理数量的性能比较。
基于先前关于MAD参数敏感性的发现[25],我们对MAD框架的三个核心超参数进行了系统的消融实验:初步检索中的候选项目数量MMM、辩论轮数和代理数量。
如图4 (a)所示,不同MMM值的实验结果表现出推理性能的“先升后降”趋势,在M=20M=20M=20时达到最佳性能。这一现象表明,虽然增加MMM可以增强代理对更多全局信息的访问,但过大的值会引入更长的上下文,最终损害推理质量。完整结果见表5。
为了优化计算成本,我们在一个60个样本的随机子集上进行以下实验。如图4 (b)所示,当固定代理数量为3时,模型性能随着额外的辩论轮数而提高,但在超过3轮后下降。图4 ©显示在3个代理和3轮辩论时达到最佳性能。这些发现突显了两个竞争因素:(1) 充足的辩论轮数和代理数量有助于多视角分析和全面推理。(2) 过多的轮数或代理数量由于错误传播和上下文过载会导致收益递减,如[9]中所讨论。
尽管我们的PD3\mathrm{PD}^{3}PD3实现未采用经验上的最佳配置(3个代理+3轮,与我们的3个代理+2轮设置相比)是由于资源限制,但结果表明其具有性能改进的潜力。同时,在实际应用中值得平衡有效性和计算成本。详见表6和表7。
4 应用
基于PD3\mathrm{PD}^{3}PD3框架,我们开发了Review DingDang,一个用于电力领域项目重复检测的在线系统。如图2所示,它清楚地展示了所有关键的重复检测细节,包括待检测项目信息、相关参考项目以及
定量-定性反馈。作为一个以人为中心的系统,Review DingDang还使专家能够指导系统优化——例如,通过修改辩论提示规则。
案例研究 Review DingDang的工作流程首先基于向量距离检索30个候选参考项目。按照轮循竞赛格式,30个候选项目被分为15个并行子竞赛任务。图5详细说明了其中一个子竞赛:三位专家代理首先独立选择他们的前5个选择,然后进行指定轮数的辩论。在此案例中,专家A最终接受了专家B和C的意见,资深专家做出最终决定。完成所有子竞赛后,投票机制确定最终的前5个项目。在反馈阶段,专业代理随后生成定量分数和定性评估以供人类专家参考。
应用影响 PD3\mathrm{PD}^{3}PD3通过Review DingDang平台在线测试,协助专家在118个新提议项目(总计4328万美元)中检测重复项目,试图申请SGCC的资金。该平台帮助专家检测出20个不合格项目(16.95%,57316.95 \%, 57316.95%,573万美元),证明了其有效性和潜在的积极社会影响。
5 结论
我们提出了PD3\mathrm{PD}^{3}PD3,一个通过适应性多智能体辩论的项目重复检测框架。其新颖的轮循竞赛MAD基础检索方法实现了上下文长度和全局信息之间的平衡。设计为以人为中心的平台,PD3\mathrm{PD}^{3}PD3提供了定量重复分数和定性反馈。实际电力项目数据实验表明其优越性,我们部署的平台Review DingDang已经产生了社会影响。
这项工作存在一些局限性。首先,测试集规模受限于专家注释成本和计算资源,尽管有全面的评估指标,仍需要使用更广泛领域的数据进行验证。其次,虽然框架与基础模型选择无关(我们使用DeepSeek V3因其开源优势),但使用其他LLM(包括专有或不同尺寸变体)进行测试将加强验证。未来方向包括通过基于LLM的强化学习增强评审性能和扩展到多模态项目分析。
参考文献
[1] Imene Bensalem, Paolo Rosso, 和 Salim Chikhi. 使用n-gram类进行内在抄袭检测。在Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP),第1459-1464页,2014年。
[2] 字节跳动. volcengine, 2025. URL https://www.volcengine.com/. 访问日期: 2025-05-15.
[3] Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, 和 Zhiyuan Liu. Chateval: 通过多智能体辩论构建更好的基于LLM的评估者。arXiv预印本 arXiv:2308.07201, 2023.
[4] Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, 和 Zheng Liu. Bge m3-embedding: 通过自知识蒸馏实现多语言、多功能、多粒度文本嵌入。arXiv预印本 arXiv:2402.03216, 2024.
[5] Xi Chen, Mao Mao, Shuo Li, 和 Haotian Shangguan. Debate-feedback: 一种高效的法律判决预测多智能体框架。在Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers),第462-470页,2025.
[6] DeepSeek-AI. Deepseek-v3技术报告,2024. URL https://arxiv.org/abs/2412.19437.
[7] Jacob Devlin, Ming-Wei Chang, Kenton Lee, 和 Kristina Toutanova. Bert: 预训练深度双向Transformer以理解语言。在Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers),第4171-4186页,2019.
[8] Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, 和 Igor Mordatch. 通过多智能体辩论改进语言模型的事实性和推理能力。在Forty-first International Conference on Machine Learning, 2023.
[9] Andrew Estornell 和 Yang Liu. 多LLM辩论: 框架、原则和干预。Advances in Neural Information Processing Systems, 37:28938-28964, 2024.
[10] Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno, 等. 朝着AI协同科学家迈进。arXiv预印本 arXiv:2502.18864, 2025.
[11] Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, 等. 关于LLM-as-a-Judge的调查。arXiv预印本 arXiv:2411.15594, 2024.
[12] Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, 等. Deepseek-r1: 通过强化学习激励LLM的推理能力。arXiv预印本 arXiv:2501.12948, 2025.
[13] Lars Benedikt Kaesberg, Jonas Becker, Jan Philip Wahle, Terry Ruas, 和 Bela Gipp. 投票还是共识?多智能体辩论中的决策。arXiv预印本 arXiv:2502.19130, 2025.
[14] Chaofan Li, Zheng Liu, Shitao Xiao, 和 Yingxia Shao. 让大型语言模型成为更好的密集检索基础。arXiv预印本 arXiv:2312.15503, 2023.
[15] Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, 和 Meishan Zhang. 通过多阶段对比学习实现通用文本嵌入。arXiv预印本 arXiv:2308.03281, 2023.
[16] Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, 和 Zhaopeng Tu. 通过多智能体辩论鼓励大型语言模型的发散思维。在Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing,第17889−17904,202417889-17904,202417889−17904,2024.
[17] Chin-Yew Lin. ROUGE: 自动摘要评估包。在Text summarization branches out,第74−81,200474-81,200474−81,2004.
[18] Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, 和 Percy Liang. 在中间迷失:语言模型如何使用长上下文。arXiv预印本 arXiv:2307.03172, 2023.
[19] Tongxuan Liu, Xingyu Wang, Weizhe Huang, Wenjiang Xu, Yuting Zeng, Lei Jiang, Hailong Yang, 和 Jing Li. Groupdebate: 使用小组讨论增强多智能体辩论的效率。arXiv预印本 arXiv:2409.14051, 2024.
[20] Tomas Mikolov, Kai Chen, Greg Corrado, 和 Jeffrey Dean. 在向量空间中高效估计词表示。arXiv预印本 arXiv:1301.3781, 2013.
[21] Chau Pham, Boyi Liu, Yingxiang Yang, Zhengyu Chen, Tianyi Liu, Jianbo Yuan, Bryan A Plummer, Zhaoran Wang, 和 Hongxia Yang. 让模型说话密码:通过嵌入的多智能体辩论。在The Twelfth International Conference on Learning Representations, 2024.
[22] David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, 和 Samuel R Bowman. GPQA: 一个研究生级别的Google-proof问答基准。在First Conference on Language Modeling, 2024.
[23] Stephen Robertson, Hugo Zaragoza, 等. 概率相关性框架:BM25及其超越。Foundations and Trends® in Information Retrieval, 3(4):333-389, 2009.
[24] Chenhui Shen, Liying Cheng, Ran Zhou, Lidong Bing, Yang You, 和 Luo Si. MRED: 一个用于结构可控文本生成的元评论数据集。在Findings of the Association for Computational Linguistics: ACL 2022,第2521-2535页,2022.
[25] Andries Smit, Nathan Grinsztajn, Paul Duckworth, Thomas D Barrett, 和 Arnu Pretorius. 我们应该疯狂吗?看看多智能体辩论策略对LLM的影响。在Proceedings of the 41st International Conference on Machine Learning,第45883-45905页,2024.
[26] Saba Sturua, Isabelle Mohr, Mohammad Kalim Akram, Michael Günther, Bo Wang, Markus Krimmel, Feng Wang, Georgios Mastrapas, Andreas Koukounas, Nan Wang, 等. jina-embeddings-v3: 带任务LoRA的多语言嵌入。arXiv预印本 arXiv:2409.10173, 2024.
[27] Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, 和 Iryna Gurevych. BEIR: 一个用于零样本评估信息检索模型的异构基准。在Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021.
[28] 中国国家电网公司. 中国国家电网公司2023社会责任报告,2024. URL http://www.sgcc.com.cn/u/cms/sgcc_main/other/202408/ 20240806163601853978745.pdf. [在线;访问日期 2025-05-15].
[29] 美国能源部. 智能电网拨款 I 部门能源,2024. URL https: //www.energy.gov/gdo/smart-grid-grants. [在线;访问日期 2025-05-15].
[30] TIGER AI实验室. MMLU-Pro排行榜,2025. URL https://huggingface.co/spaces/ TIGER-Lab/MMLU-Pro. [在线;访问日期 2025-05-15].
[31] Qineng Wang, Zihao Wang, Ying Su, Hanghang Tong, 和 Yangqiu Song. 重新思考LLM推理的界限:多智能体讨论是关键吗?在62nd Annual Meeting of the Association for Computational Linguistics, ACL 2024, 第6106-6131页。Association for Computational Linguistics (ACL), 2024.
[32] Sijia Wang 和 Lifu Huang. 作为优化的辩论:自适应符合性预测和多样检索以提取事件。在Findings of the Association for Computational Linguistics: EMNLP 2024, 第16422−16435,202416422-16435,202416422−16435,2024.
[33] Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, 等. MMLU-Pro: 更强大且更具挑战性的多任务语言理解基准。在The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024.
[34] Yang Yu, Lei Liu, Xiangyi Xu, 和 Shaoqian Bai. 文本检测方法、设备、计算设备及计算机可读存储介质,cn108829780b版,2022.
[35] Daoze Zhang, Zhijian Bao, Sihang Du, ZHiyi Zhao, Kuangling Zhang, Dezheng Bao, 和 Yang Yang. Re 2{ }^{2}2 : 一个确保一致性的同行评审和多轮反驳讨论数据集。arXiv预印本 arXiv:2505.07920, 2025.
[36] Zhenhai Zhang 和 Xiongyong Sun. 一种自动检测学术不端文献的方法和系统,cn101833579b版,2012.
[37] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, 等. 通过MT-Bench和Chatbot Arena评判LLM-as-a-Judge。Advances in Neural Information Processing Systems, 36:46595-46623, 2023.
A 附录
A. 1 相关工作
A.1.1 文本重复检测
文本重复检测是识别文档间内容复制的关键计算语言学任务,在保护学术诚信和知识产权方面发挥着重要作用。早期方法主要依赖词汇级分析,例如n-gram重叠量化[1]和Smith-Waterman等动态规划算法进行局部比对。值得注意的是,Yu等人[34]引入了句法级处理——包括句子分割、词汇分解和TF-IDF差异计算——用于构建相似性矩阵,这在万方重复检测平台中得以实现。
虽然这些字符匹配方法在逐字检测中实现了高精度,但它们缺乏语义理解,容易因改写(例如同义词替换和句法重构)而被规避。后来的发展采用了分布式语义表示,运用主题建模(如潜在狄利克雷分配)和词嵌入(如Word2Vec [20])进行文档相似性分析。Zhang和Sun [36]提出了一种分层检测框架,结合文档级关键词排名和句子级同义词检测,广泛应用于CNKI重复检测平台。尽管这些方法捕捉到了表面层次的语义关系,但它们在复杂的语义转换面前显得力不从心。大型语言模型(LLMs)的兴起革新了推理任务[11],但其机制本质上与项目重复检测的非严格偏序现实相冲突。
A.1.2 多智能体辩论系统
多智能体辩论(MAD)[16, 8]通过LLM代理间的协作互动实施“心智社会”框架。这种方法通过迭代对抗性知识精炼解决了单模型推理的关键限制——如确认偏差、幻觉和逻辑不一致性。实证研究表明,MAD通过三种机制提高了推理能力:(1)集体错误纠正,(2)视角多样化,(3)系统推理强化。
MAD在多种应用中证明了其有效性。在科学发现中,Gottweis等人[10]使用锦标赛式辩论生成和精炼生物医学假设。对于法律判决预测,Chen等人[5]将MAD与可靠性评估结合以减少对大数据集的依赖。在事件提取中,Debate as Optimization(DAO)系统[32]通过迭代改进输出而不需参数调整。然而,MAD尚未在重复检测中得到探索,这是我们工作的填补空白之处。
最近MAD的发展主要集中于三个关键维度:(1)通信优化,Pham等人[21]展示了基于嵌入的互动优于自然语言辩论;(2)角色专业化,Chan等人[3]建立了异质代理角色显著优于同质配置的观点;(3)决策效率,Liu等人[19]引入分组辩论以减少计算开销,而Kaesberg等人[13]系统评估了不同类型任务中的投票与共识协议。然而,这些方法论改进主要针对单一知识问答场景,对其在复杂、多面的任务如项目重复检测中的适用性尚待探索。
尽管其优点,MAD面临批评。研究表明它主要在零样本设置下优于单代理推理[31],当代理共享训练数据时辩论可能放大偏差[9]。例如,Wang等人[31]发现经过良好提示的单代理可以与MAD匹敌,而Estornell和Liu[9]表明辩论往往收敛到多数意见,强化误解。这些局限性强调了仔细的角色多样性和共识设计的必要性——这是我们的工作通过定制代理角色和特定任务投票解决的问题。我们在项目重复检测中的实证结果进一步证实了MAD优于单LLM。
A. 2 数据集详情
本工作中使用的数据来自中国国家电网公司的真实项目。我们匿名化了敏感信息(如申请人详情)并随机生成ID,仅保留项目标题和文本内容。更多信息见表3。
表3:电力科研项目的数据集详情
| 年份 | 项目数量 | 平均长度(标记数) |
|---|---|---|
| 2022 | 223 | 835.0404 |
| 2023 | 292 | 997.1678 |
| 2024 | 318 | 1004.3459 |
| 总计 | 833\mathbf{8 3 3}833 | 956.5054\mathbf{9 5 6 . 5 0 5 4}956.5054 |
A. 3 实验设置详情
任务1的实验设置详情 对于基于词频、向量距离检索和LLM-as-a-Judge的方法,我们直接计算待检测项目的分数和初步检索结果,然后选择得分最高的前5个结果。对于DeepSeek V3和DeepSeek R1,我们将待检测项目与所有初步检索结果一起作为提示输入以生成输出。
任务2的实验设置详情 对于所有LLM-as-a-Judge方法(包括LLM-as-aJudge MAX、LLM-as-a-Judge AVG和PD*的带或不带结论的LLM-as-a-Judge-based反馈),我们进行三次独立生成并使用平均值作为最终分数。虽然我们使用三次评分的平均值作为最终评估指标,但在测试集中可能出现LLM为Pa−AP_{\mathrm{a}-\mathrm{A}}Pa−A和Pa−BP_{\mathrm{a}-\mathrm{B}}Pa−B分配相同分数的情况。为公平起见,我们的评分协议在这种情况下有所不同:(1)在"原始组"设置下,这些情况得分为0。(2)在"加权组"设置下,我们为标注中较少出现的标签分配相应的分数(例如,2:1比例将产生0.33分)。
A. 4 实验结果详情
表4:任务1的附加实验结果
| 方法 | 精确度/05 | Match@K | ||||
|---|---|---|---|---|---|---|
| K=1\mathrm{K}=1K=1 | K=2\mathrm{~K}=2 K=2 | K=3\mathrm{~K}=3 K=3 | K=4\mathrm{~K}=4 K=4 | K=5\mathrm{~K}=5 K=5(命中率@5) | ||
| gte-7B作为重新排序器+任务指令 | 0.3770 | 29310.8852 | 21010.6344 | 9310.2810 | 2610.0785 | 210.0060 |
| gte-7B作为重新排序器(无指令) | 0.3897 | 29810.9003 | 21210.6405 | 10510.3172 | 2910.0876 | 110.0030 |
| gte-1.5B+ EN默认指令 | 0.3692 | 29010.8761 | 20910.6314 | 9210.2779 | 1910.0574 | 110.0030 |
| gte-1.5B+ CN默认指令 | 0.3722 | 29510.8912 | 20710.6254 | 9410.2840 | 1910.0574 | 110.0030 |
| gte-1.5B带指令(+任务指令) | 0.3782 | 29410.8882 | 21310.6435 | 9610.2900 | 2110.0636 | 210.0060 |
| bge作为重新排序器 | 0.2435 | 26010.7855 | 11310.3413 | 2510.0755 | 410.0121 | 110.0030 |
| jina作为重新排序器 | 0.2798 | 27510.8308 | 14110.4260 | 4210.1269 | 110.0030 | 110.0030 |
任务1实验结果详情 对于基于向量距离的方法,我们在正文中报告的实验之外进行了额外实验。由于篇幅限制,表1仅呈现了每个类别中表现最好的方法,而附录中的表4提供了完整的实验结果。在每个类别中,粗体条目表示根据优越性能选择的表1方法。
表5:组大小的超参数分析实验结果。
| 轮循初始项数 ( M ) | Precision@5 | Match @ K | |||||
|---|---|---|---|---|---|---|---|
| K=5\mathrm{K}=5K=5 | K=4\mathrm{~K}=4 K=4 | K=3\mathrm{~K}=3 K=3 | K=2\mathrm{~K}=2 K=2 | K=1\mathrm{~K}=1 K=1 | |||
| 10 | 0.4230 | 6 | 0.0181 | 39 | 0.1178 | 119 | 0.3595 |
| 15 | 0.4344 | 4 | 0.0121 | 45 | 0.1360 | 132 | 0.3988 |
| 20(我们的) | 0.4423 | 10 | 0.0302 | 41 | 0.1239 | 133 | 0.4018 |
| 25 | 0.4290 | 3 | 0.0091 | 42 | 0.1269 | 129 | 0.3897 |
| 30 | 0.3964 | 3 | 0.0091 | 42 | 0.1269 | 129 | 0.3897 |
表6:辩论轮数的超参数分析实验结果。
| 辩论轮数 | Precision@5 | Match @ K | |||||
|---|---|---|---|---|---|---|---|
| K=5\mathrm{K}=5K=5 | K=4\mathrm{~K}=4 K=4 | K=3\mathrm{~K}=3 K=3 | K=2\mathrm{~K}=2 K=2 | K=1\mathrm{~K}=1 K=1 | |||
| 1 | 0.4667 | 2 | 0.0333 | 9 | 0.1500 | 28 | 0.4667 |
| 2 | 0.4767 | 2 | 0.0333 | 8 | 0.1333 | 29 | 0.4833 |
| 3 | 0.4933 | 1 | 0.0167 | 11 | 0.1833 | 33 | 0.5500 |
| 4 | 0.4633 | 1 | 0.0167 | 8 | 0.1333 | 30 | 0.5000 |
表7:辩论代理数量的超参数分析实验结果。
| 代理数量 | Precision@5 | Match @ K | |||||
|---|---|---|---|---|---|---|---|
| K=5\mathrm{K}=5K=5 | K=4\mathrm{~K}=4 K=4 | K=3\mathrm{~K}=3 K=3 | K=2\mathrm{~K}=2 K=2 | K=1\mathrm{~K}=1 K=1 | |||
| 2 | 0.4733 | 1 | 0.0167 | 12 | 0.2000 | 25 | 0.4167 |
| 3 | 0.4933 | 1 | 0.0167 | 11 | 0.1833 | 33 | 0.5500 |
| 4 | 0.4800 | 1 | 0.0167 | 10 | 0.1667 | 30 | 0.5000 |
| 5 | 0.4867 | 1 | 0.0167 | 10 | 0.1667 | 34 | 0.5667 |
超参数实验结果详情 表5、表6和表7分别显示了超参数分析的详细实验结果——初步检索中的候选项目数量MMM、辩论轮数和代理数量。
A. 5 运行时性能
本节评估了Review Dingdang的运行时性能,通过Volcengine的Model API [2]使用Python的并发模块并行执行。我们的结果显示每个项目重复检测的平均执行时间为3\mathbf{3}3分钟。如表8所示,辩论期间的令牌消耗平均每项目为442万个令牌(436万个提示令牌/57.98千个完成令牌),而反馈阶段每项目需要35.36千个令牌(31.75千个提示令牌/3.61千个完成令牌)。基于Volcengine的Model API定价[2],每项目约为1.34\mathbf{1 . 3 4}1.34美元。这些指标量化了PD3\mathrm{PD}^{3}PD3框架和Review Dingdang平台的时间和计算成本。
表8:运行时间令牌消耗分析。
| 过程阶段 | 令牌消耗指标 | 平均令牌使用量 | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
MAD轮循检索的高级专家提示模板
作为一名电力领域的高级专家负责项目重复检测,您需要组织专家辩论以选出几个候选相关项目中最相关的五个项目。
您将在本次辩论中担任讨论评审员,评估专家的辩论并确定最终选出的五个项目。
## 审查目标:
基于预先定义的审查标准和讨论程序,严格讨论并确定与待检测项目最相关的五个候选项目。
## 审查标准:
(review_criteria)
## 待检测项目信息 :
[project_under_detection_info]
## 候选相关参考项目信息:
[candidates_project_info]
## 辩论记录:
[debate_records]
请分析专家的共识,并最终在[RESULT]后按相关性顺序输出项目编号列表。
图8:MAD轮循检索中设置高级专家轮次使用的提示模板。
基于LLM-as-judge反馈的重复评分提示模板
您是一名电力领域的专家,正在进行项目重复检测。
给定一个待检测项目,您将获得数据库中提供的五个最相关的历届项目,以及评审专家对参考项目和待检测项目相关内容的结论。
您的任务是根据评审标准对正在评审的项目的重复程度进行评分。
## 审查标准:
- 评分采用10分制:1分最低,表示所有历史项目基本与待评审项目无关;4-6分居中,表示多个历史项目在某些维度上与待评审项目有重复;10分最高,表示一个或多个参考项目与待检测项目完全相同。鼓励差异化评分。
-
- 评分时需要综合考虑候选相关项目在研究主题、核心技术、应用场景方面的相似性。
-
- 如果五个参考项目中有任何一个与待检测项目高度相关,应给予较高评分。只有当所有五个参考项目都不够相关时,才应给予较低评分。
-
- 注意到提供的五个参考项目可能与待评审项目不高度相关。
- ## 待检测项目信息 :
- [project_under_detection_info]
- ## 候选相关参考项目信息:
- [candidates_project_info]
- ## 评审专家结论
- [expert_conclusion]
- 您需要首先提供分析理由,然后以’[RESULT]score’的形式给出评分,其中score是从1到10的整数。
图9:用于生成基于LLM-as-a-Judge反馈的重复评分的提示模板。
参考论文:https://arxiv.org/pdf/2505.17492

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 24
24 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)