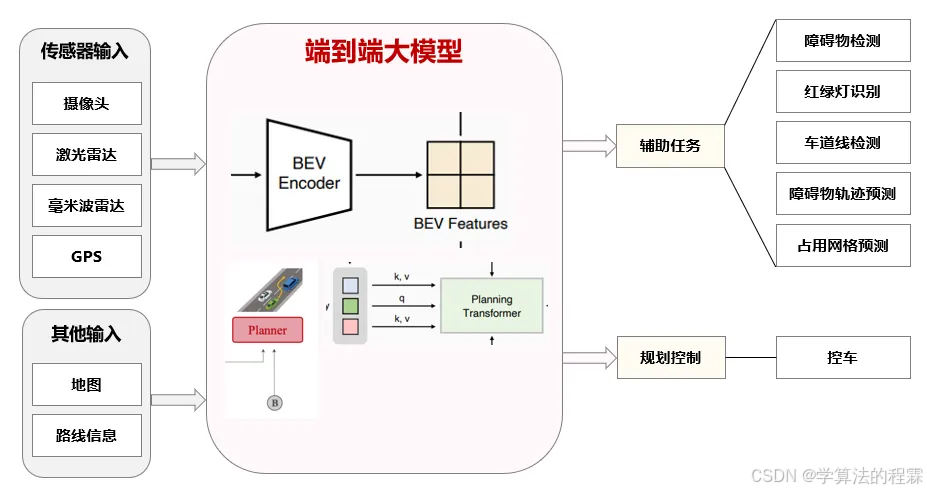
建议收藏起来:一文看懂目前端到端自动驾驶算法实现原理
端到端自动驾驶基本流程:(1)子任务模型被更大规模的神经网络模型取代,最终即为端到端神经网络模型;(2)由数据驱动的方式来解决长尾问题,取代rule-based的结构。优点:(1)直接输出控车指令,避免信息损失;(2)具备零样本学习能力,更好解决OOD问题;(3)数据驱动方式解决自动驾驶长尾问题;(4)避免上下游模块误差的过度传导;(5)模型集成统一,提升计算效率。● 开环指标○ L2误差○ 碰撞
从传感器数据到控制策略的端到端方法

端到端自动驾驶基本流程:
(1)子任务模型被更大规模的神经网络模型取代,最终即为端到端神经网络模型;
(2)由数据驱动的方式来解决长尾问题,取代rule-based的结构。
优点:
(1)直接输出控车指令,避免信息损失;
(2)具备零样本学习能力,更好解决OOD问题;
(3)数据驱动方式解决自动驾驶长尾问题;
(4)避免上下游模块误差的过度传导;
(5)模型集成统一,提升计算效率。
完全端到端是怎么做的
评估指标
● 开环指标
○ L2误差
○ 碰撞率
● 闭环仿真
○ 路线完成率(RC)路线完成的百分比
○ 违规分数(IS)衡量触发的违规行为
○ 驾驶分数(DS)表示驾驶进度和安全性
【自动驾驶算法入门到进阶教程】
端到端的一些主流方法
UniAD算法详解
算法动机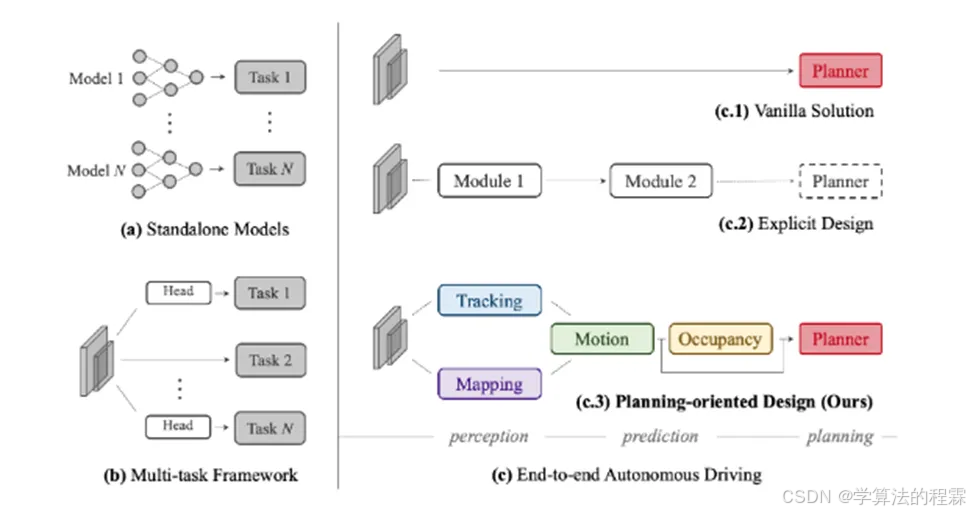
跨模块信息丢失、错误积累和特征misalignment
● 负向传输
● 安全保障和可解释性方面
● 考虑模块较少
开创性思路
● 第一项全面研究自动驾驶领域包括感知、预测和规划在内的多种任务的联合合作的工作
● 以查询方式链接各模块的灵活设计
● 一种以决策为导向的端到端框架
主体结构
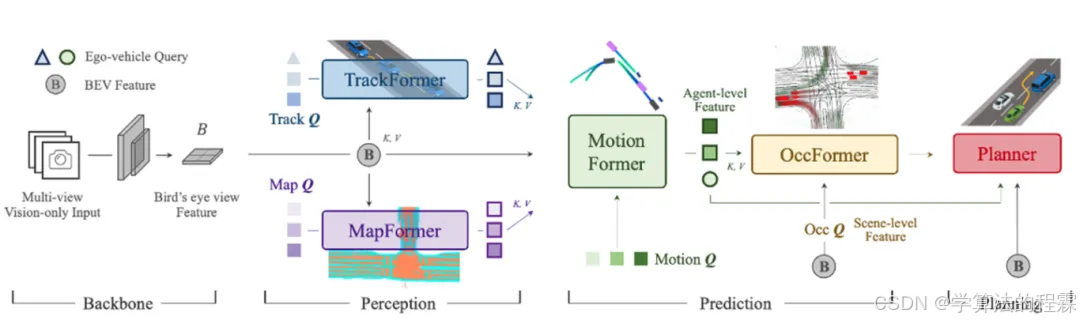
该模型包括特征提取,特征转换,感知模块(目标检测+多目标跟踪+建图部分,TrackFormer、MapFormer),预测模块(MotionFormer、OccFormer),规划模块(指令导航、Occ矫正轨迹)
性能对比
消融实验证明各个模块都是不可或缺的,然后再去对比单个模块的性能。各个模块的对比这里不再展开。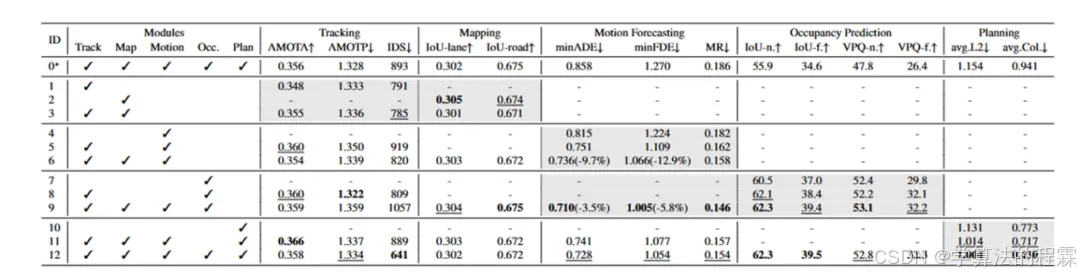

VAD算法详解
算法动机
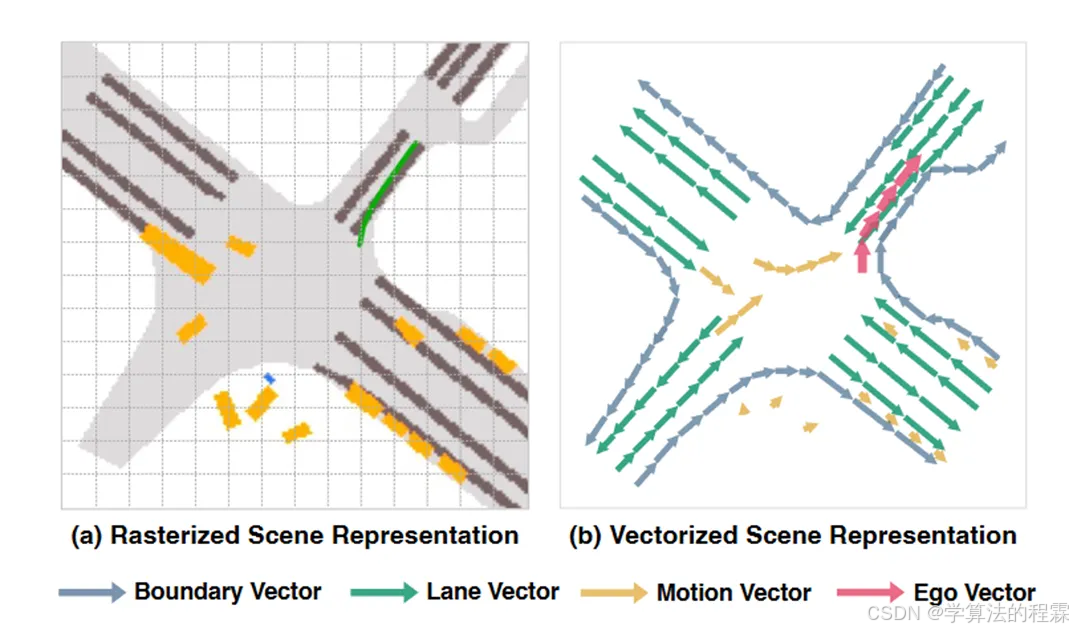
栅格化表示计算量大,并且缺少关键的实例级结构信息
矢量化表示,计算方面效率高
主体结构
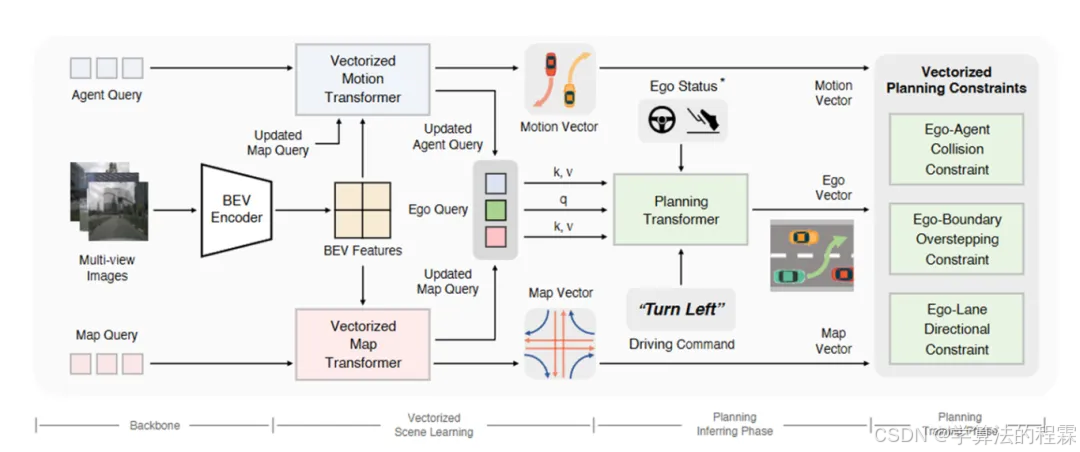
该模型包括特征提取、特征转换、矢量化场景学习、规划模块。
性能对比
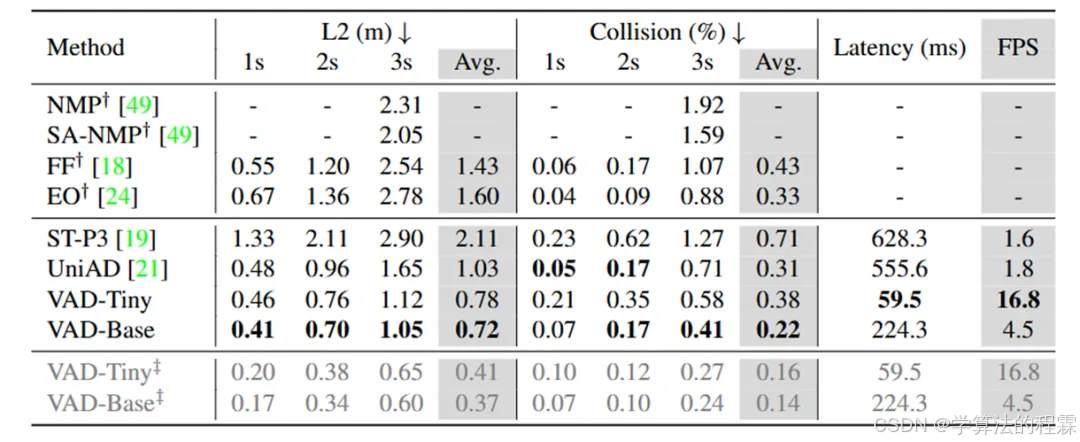
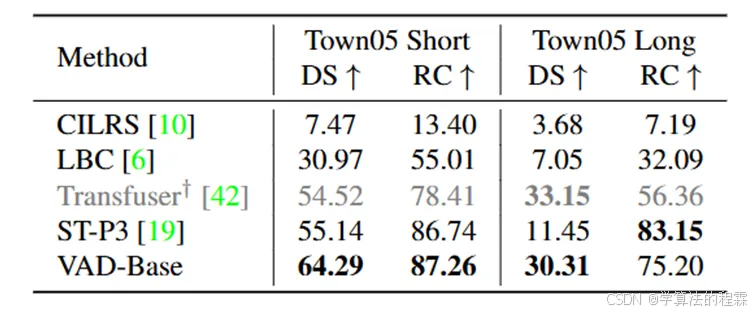 UAD算法详解
UAD算法详解
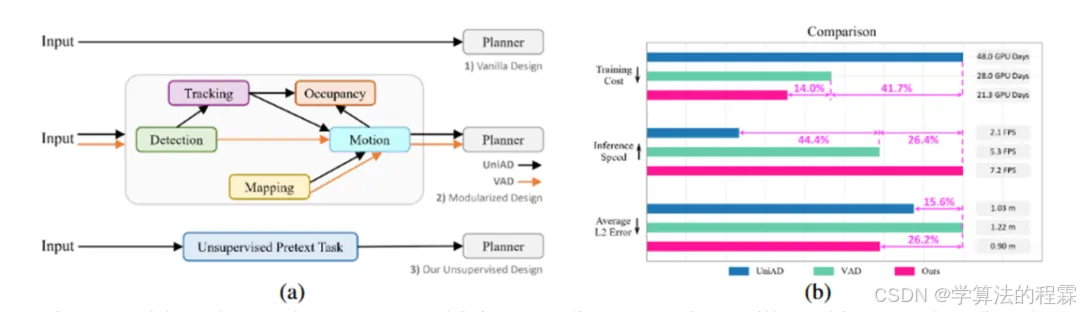
算法动机
● 现存方法的标注和计算开销过大,所以本篇没有人工标注的需求
● 感知模块的标注不是提升规划性能的关键,扩大数据量才是关键。只对数据量扩大但不增加标注成本。
开创性思路
● 无监督代理任务
● 自监督方向感知策略
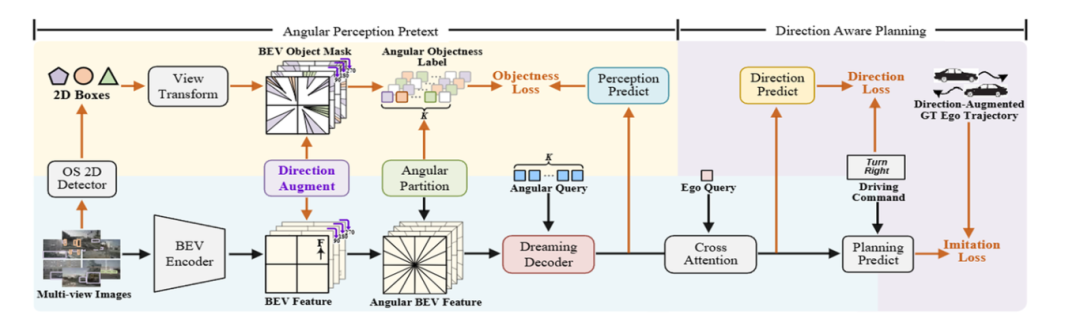
主体结构
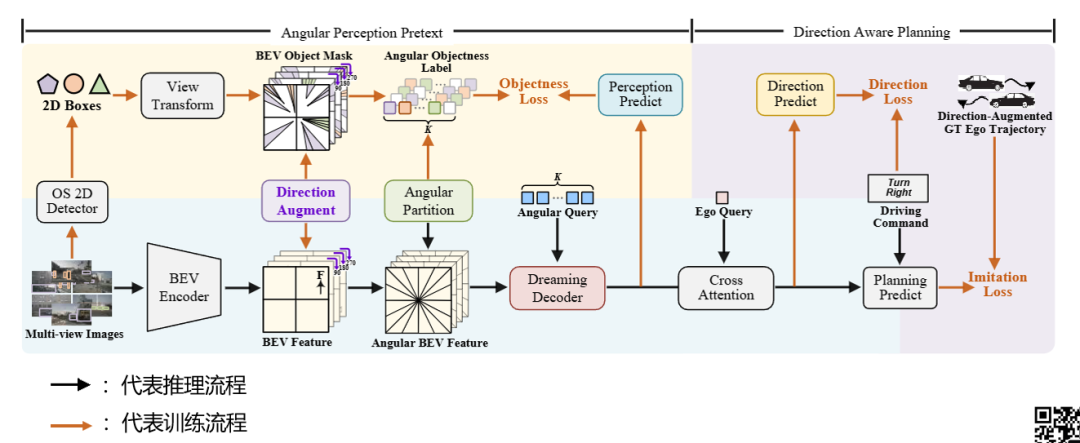
整体结构包括两部分的内容,分别是
● 无监督的代理任务
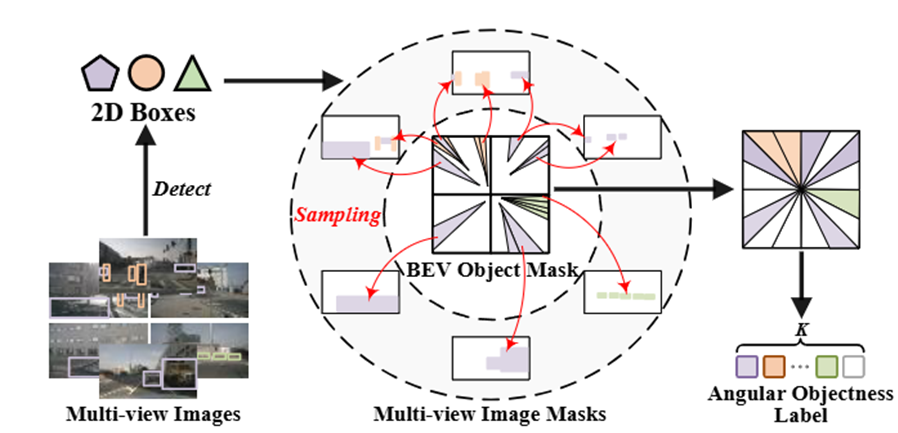
输入是一个环视的图像,通过GroundingDINO(开集检测器,在训练集中10个类别的数据,但是验证集中有多出来的其他类别也要要求能检测出来),然后得到BEV特征,经过Dreaming Decoder得到预测结果与刚才说获取的标签去计算一个loss(二分类交叉loss)
用于对物体预测的Dreaming decoder的整体结构是:初始化K个角度的Query,BEV特征被分成了K个区域跟Query一一对应,经过GRU模块(用t-1时刻的Query和当前时刻t的特征F去计算当前时刻t的Query),用t时刻的特征和t时刻的Query做一个CrossAttention得到下一时刻的特征。即自回归的一种方式。Query之间对平均值和方差进行一个DreamingLoss,让其分布尽量相似。
● 利用方向感知的规划模块
该模块包括三部分的内容
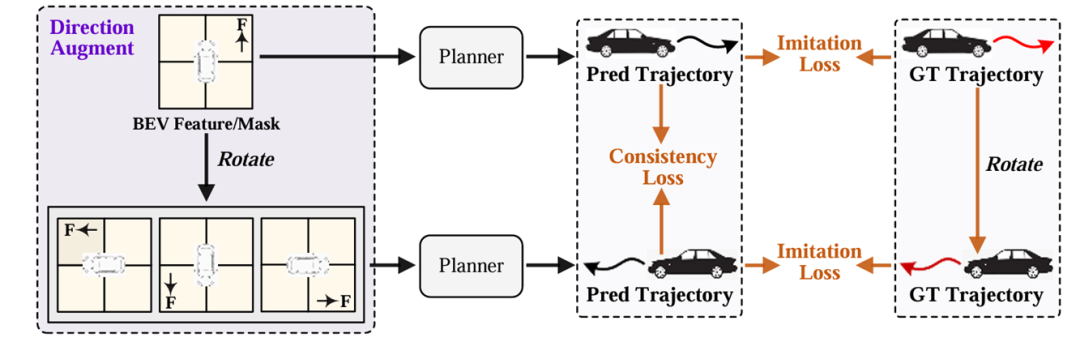
(1)PlanningHead规划头(通过模仿学习来计算未来轨迹,对BEV特征进行旋转,过规划头得到响应的预测轨迹,然后GT也要旋转,两者得到一个模仿学习的loss。)
(2)Directional Augmentation方向增强(先对轨迹沿着车辆行驶方向划分为直行、左转、右转,然后通过这个预测头做一个三分类)
(3)Directional Consistency方向一致性(旋转后的特征得到的轨迹再旋转回去之后,跟之前的对比得到loss。)
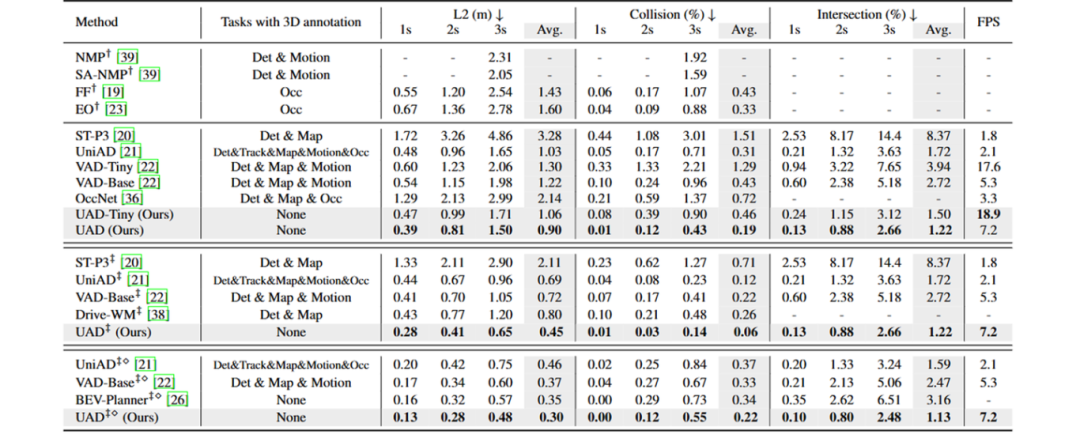
性能对比
SparseDrive算法详解
算法动机
● 认为传统方法中BEV特征计算成本高
● 忽略了自车对周围代理的影响
● 场景信息是在agent周围提取,忽略了自车
● 运动预测和规划都是多模态问题,应该输出多种轨迹
开创性思路
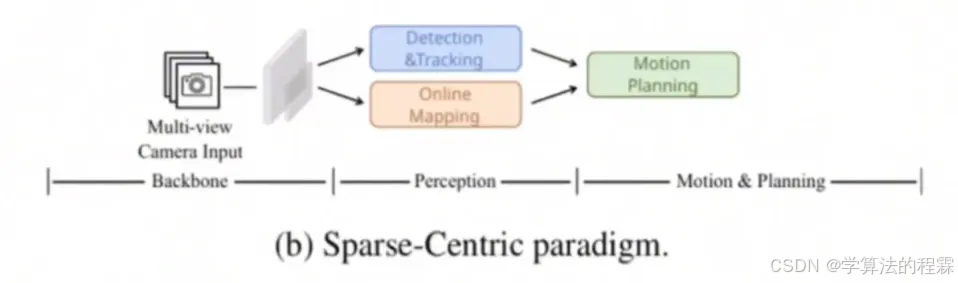
● 探索了端到端自动驾驶的稀疏场景表示,并提出了一种以稀疏为中心的范式
● 修改了运动预测和规划之间的巨大相似性,提出了一种分层规划选择策略
主体结构
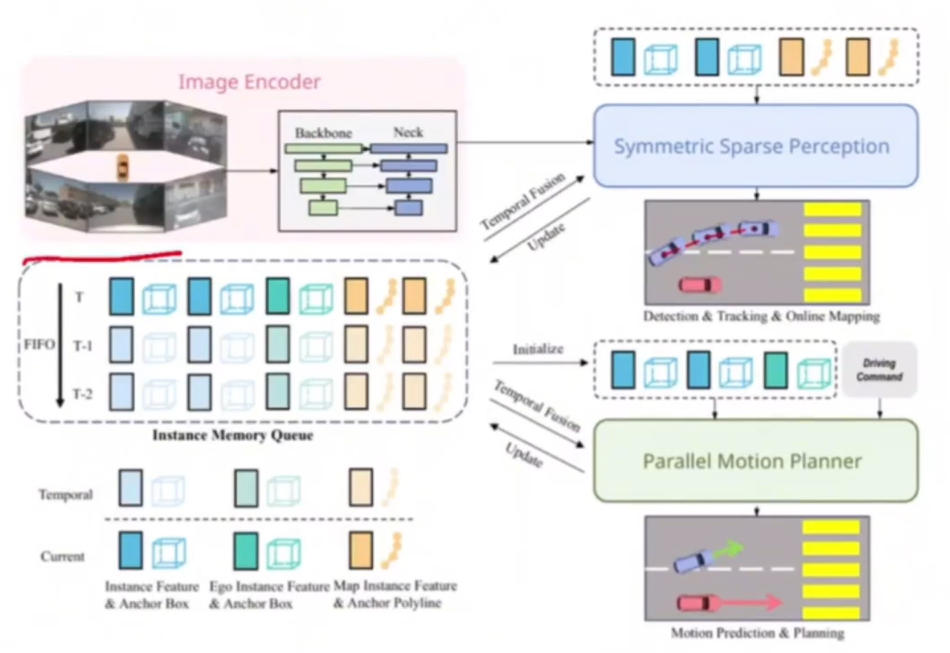
输入环视的6幅图像,输出是其他agent的预测和规划结果。
中途处理过程包括:特征提取、对称稀疏感知、平行运动规划三大模块。
在对称稀疏感知模块中,主要包含:稀疏检测、稀疏跟踪、稀疏在线建图任务,我们来具体看一下。
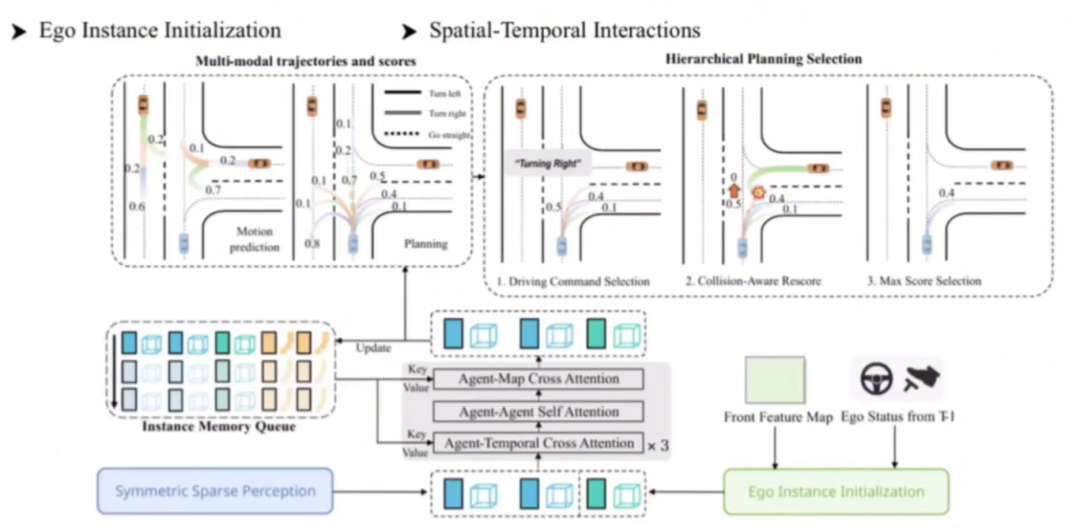
在平行运动规划器模块中:作者认为其他agent的轨迹预测和自车的轨迹预测应该是一个任务,并且是互相影响的。
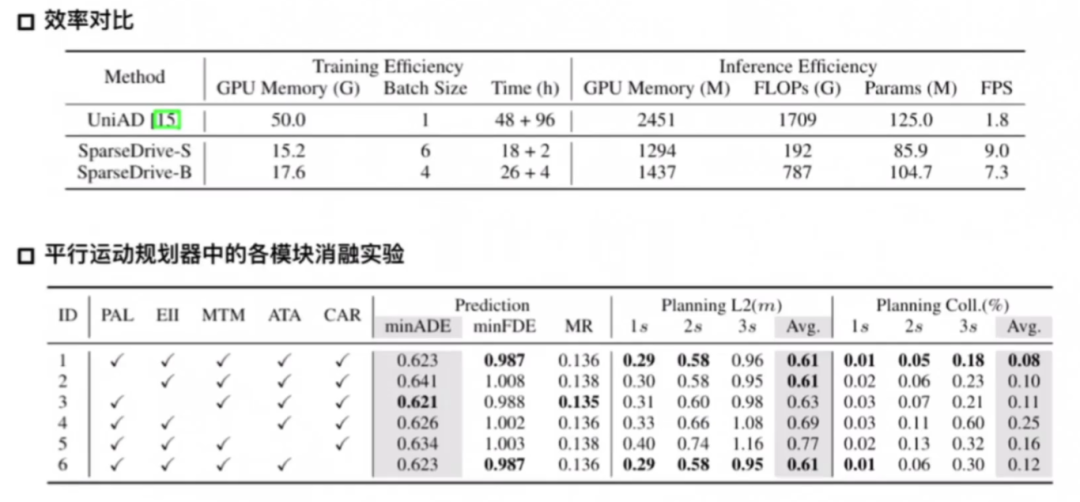
性能对比
ReasonNet算法详解
这是一个时序+多模态的方案,这篇论文对一些特殊的场景进行了考虑。
算法动机
● 应该对驾驶场景的未来发展做出高保真的预测;
● 处理长尾分布中罕见不利事件,遮挡区域中未被发现但相关的物体。
开创性思路
● 提出一种新型的时间和全局推理网络,增加历史的场景推理,提高全局情景的感知性能;
● 提出一种新基准,由城市驾驶中各种遮挡场景所组成,用于系统性地评估遮挡事件。
主体结构
这篇文章是多模态的,所以其输入是图像输入和雷达点云的输入所组成的,输出是waypoints。
主体结构分为三个模块:
● 感知模块:从Lidar和RGB数据中提取BEV特征;
● 时间推理模块:处理时间信息并维护存储历史特征的存储库;S用于计算存在Memory Bank中的历史特征和当前特征的相似度
● 全局推理模块:捕获物体与环境之间的交互关系,以检测不利事件(如遮挡)并提高感知性能。
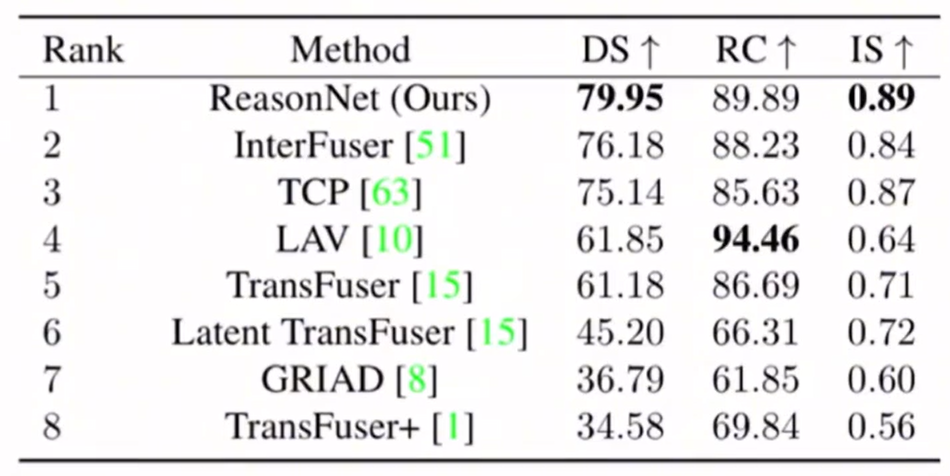
性能对比
基于本文提出的新的benchmark叫做DOS benchmark:四种场景分别包含25种不同的情况,包括车辆和行人的遮挡,有间歇性遮挡和持续遮挡但有交互线索。
FusionAD算法详解
这是一篇多模态的方案,是在UniAD的基础上加入了点云数据,改造成了多模态的方案。
算法动机
● 传统的模块化方法没办法支持梯度反传,会造成信息的丢失。
● UniAD只支持图像输入,不支持激光雷达信息。
开创性思路
● 第一个统一的基于BEV多模态、多任务的端到端学习框架,重点关注自动驾驶的预测和规划任务;
● 探索融合特征增强预测和规划任务,提出一个融合辅助模态感知预测和状态感知规划模块,称为FMSPnP。
主体结构
该模型的主体结构包括特征融合模块、预测模块、规划模块。
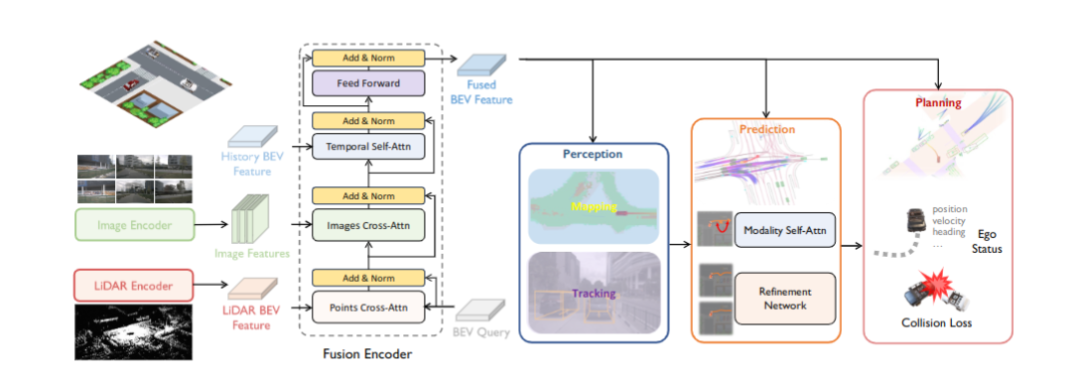
性能对比

Hydra-MDP算法详解
CVPR 2024端到端自动驾驶挑战赛冠军+多模态方案,具备多个目标的多头蒸馏。
算法动机
本文作者提出的新的范式,就是规划模块是多模的输出,同时,目标也是多样性的,即不仅是GT的轨迹也同时引入了更多的正样本,由不同的专家给出的。此外,将后处理的模块变成了可微分的用于训练的神经网络的模块,从而消除了第二种范式中由于不可微分而带来的信息损失的情况。
开创性思路
● 引入了更多的正样本,由不同专家给出;
● 感知真值引入规划模块用于训练。
主体结构
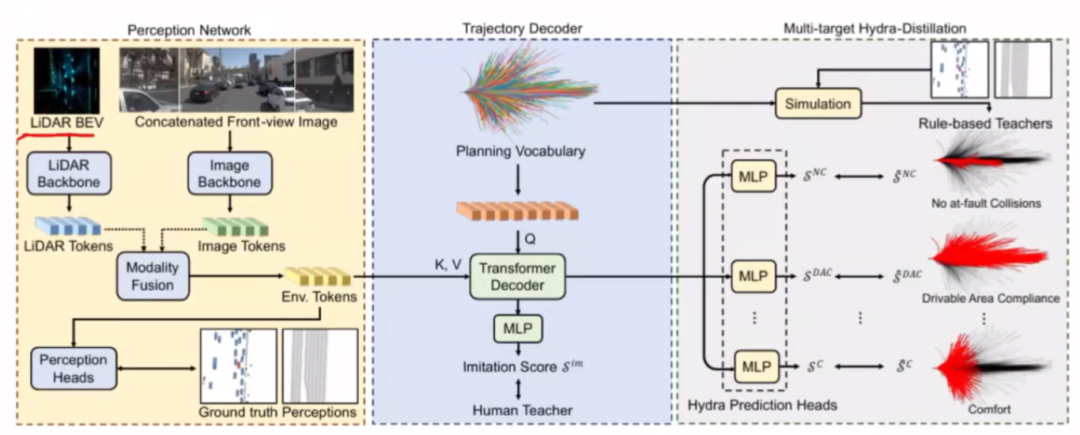
第一部分是感知的信息处理融合和提取,第二个模块是用前面得到的特征去解码出轨迹,最后一个模块是多目标学习范式部分。
感知模块用的Transfuser的baseline
轨迹解码器:计算不同的预测轨迹与GT轨迹的距离,这里用的是L2,用这个距离做softmax,然后去产生不同轨迹的得分情况,从而去监督得分。
多目标多头蒸馏模块:我们看到轨迹模仿学习之后的轨迹还过了其他的MLP,这就是其他头,它的目标也是不一样的,第一个是跟碰撞相关的,第二个是跟行驶区域相关的,第三个是跟舒适度相关的,也就是说不同的评判指标都有一个teacher,之前的模仿学习就是人类的teacher,那么这些teacher是怎么来的呢?怎么通过这些teacher来蒸馏的呢?我们看下作者是怎么去做的,首先我们得到规划词表Planning Vocabulary之后,对规划词表进行了一个模拟(用感知模块的GT进行训练的),有了这两个之后,我们就能算出来这些评估指标,从而计算每条轨迹的得分。总结一下就是对整个训练数据集的规划词汇进行离线模拟,在训练过程中引入每条轨迹的模拟分数的监督。
性能对比


脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 30
30 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)