给萌新的YOLO介绍
本文介绍了目标检测模型YOLO及其原理。YOLO作为单阶段检测模型,通过将图像网格化并同步执行定位和分类任务,实现了高效的目标识别。相较于传统两阶段方法,YOLO只需一次扫描即可完成物体检测和定位,大大提升了识别效率。文章用生动比喻对比了YOLO与传统方法的差异,并详细解析了其网格化编码、多任务联合预测等技术特点。虽然YOLOv1存在单网格单物体的限制,但后续版本通过引入锚框、多尺度预测等创新不断
我目前除了做项目写代码,弄硬件,还会训练模型,比如YOLO,下图正在打标。
所谓人工智能就是,先人工,后智能。
很多人工智能专业研究生毕业设计都是基于yolo的,了解,学习,应用yolo都对进入人工智能领域有帮助,下面就对新手介绍一下YOLO以及基本原理。

YOLO 是什么?
YOLO 是目标检测模型。
目标检测是计算机视觉中比较简单的任务,用来在一张图篇中找到某些特定的物体,目标检测不仅要求我们识别这些物体的种类,同时要求我们标出这些物体的位置。
简单来讲就是一个能帮电脑"看图找东西"的智能工具。就像小朋友看图画,不仅要说出图上有什么动物,还要用手指指出它们的位置。
YOLO 就是做类似的事情:
- 找东西
在照片里快速扫描,把汽车、小狗、红绿灯这些东西都找出来
- 说名字
每个找到的东西都会贴上标签(这是猫还是自行车?)
- 画框框
用方框精准框住找到的物体,就像我们用手指出东西在哪
更厉害的是,它不仅能辨认固定类型的物品(比如知道世界上有20种常见动物),还能精确到像素级地标出这些物体的具体位置(比如小狗正好在画面左下角1/3处)。
就像玩"大家来找茬"时,既能说出哪里不同,又能准确圈出不同之处的位置。
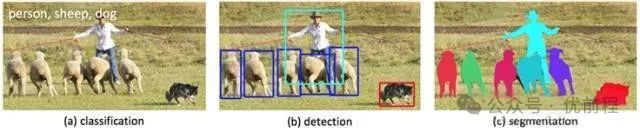
上面的图片中,分别是计算机视觉的三类任务:分类,目标检测,实例分割。
很显然,整体上这三类任务从易到难,我们要讨论的目标检测位于中间。前面的分类任务是我们做目标检测的基础,至于像素级别的实例分割,太难了别想了。
YOLO 在 2016 年被提出,发表在计算机视觉顶会 CVPR(Computer Vision and Pattern Recognition) 上,论文的国内镜像在这里:
YOLO 的全称是 you only look once,指只需要浏览一次就可以识别出图中的物体的类别和位置。
因为只需要看一次,YOLO 被称为 Region-free 方法,相比于 Region-based 方法,YOLO 不需要提前找到可能存在目标的 Region。
也就是说,一个典型的 Region-base 方法的流程是这样的:先通过计算机图形学(或者深度学习)的方法,对图片进行分析,找出若干个可能存在物体的区域,将这些区域裁剪下来,放入一个图片分类器中,由分类器分类。
因为 YOLO 这样的 Region-free 方法只需要一次扫描,也被称为单阶段(1-stage)模型。Region-based 方法方法也被称为两阶段(2-stage)方法。
两种方式下面详细介绍,YOLO的出现整体的提升了识别效率。
YOLO 之前的世界
咱们用「找钥匙」这件头疼事打个比方,看不同方式怎么找到钥匙。
1、原始人版·瞎摸法(滑窗法)
你妈怒吼:"钥匙肯定在客厅!”
于是你趴在地上,举着钥匙孔形状的纸板,一寸寸挪动扫描地板(这就是滑窗)
然后你爬的时候遇到几个痛点: 钥匙可能在茶几上/沙发缝/花盆底(位置不确定),钥匙可能是挂饰大钥匙扣/小门禁卡(尺寸不确定),还可能混着硬币、打火机等杂物(多物体干扰)。
最后你爬了三个小时,终于,找到了你一个月前丢掉的弹珠。
2、工程师版·智能排除法(R-CNN)
这次你学聪明了,先拿金属探测器扫全屋:"滴滴!这200个地方可能有金属!"(Region Proposal),再用钥匙孔模具逐个验证这些可疑点(区域分类)。
这次不用爬完整间房,但…探测器总误报(硬币、钉子都响),每个可疑点还要单独检查,腿依然跑断。
3、天才少年版·YOLO闪现
抄起全景相机"咔嚓"拍下客厅,茶几左下角:大门钥匙(置信度99%),书架第二层:自行车钥匙(置信度85%),地毯边缘:疑似钥匙但可能是口香糖(置信度50%)。
核心原理是,把房间划分成小网格(就像地板砖),每个网格同时做三件事:有没有钥匙?(物体存在概率),要是存在,具体在网格哪个位置?(坐标回归),是哪种钥匙?(分类判断)。
于是你1秒锁定目标,还能边找边喊:"妈!顺带发现了你失踪的口红在沙发缝!”
YOLO 原理(学术)
YOLO(You Only Look Once)是一种基于单阶段检测框架的端到端目标识别模型,其核心思想是将目标检测建模为统一的回归问题。
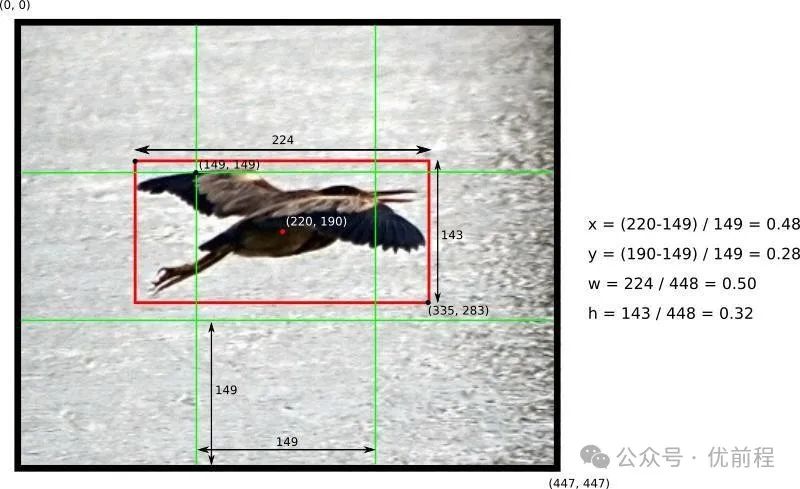
算法采用监督学习范式,输入图像经标准化处理后,通过卷积神经网络直接输出目标的位置坐标(中心点x,y,高度h,宽度w)及类别概率。
核心机制:
-
网格化编码
将输入图像划分为S×S的均匀网格,每个网格单元负责预测B个候选边界框(Bounding Box)。边界框参数包含归一化坐标偏移量(相对于网格单元)及尺寸比例(相对于整图尺寸),通过引入平方根变换(√w, √h)平衡大/小物体的回归敏感性。

-
多任务联合预测
每个网格单元同步执行两项任务:
- 定位预测
输出边界框的置信度(Confidence Score),定义为Pr(obj)×IoU,反映目标存在概率与预测框/真实框的交并比

- 分类预测输出条件类别概率分布(C维one-hot向量)
3、损失函数设计
采用多分量加权损失函数:
-
坐标损失(λ_coord=5):强化中心点与尺寸的回归精度
-
置信度损失:区分正/负样本(含目标网格λ_noobj=0.5)
-
分类损失:交叉熵优化类别判别 通过梯度权重调节,缓解正负样本不均衡问题。
4、后处理优化
应用非极大值抑制(NMS)消除冗余检测:基于置信度排序,保留IoU阈值内最高分框,实现多目标去重。

创新优势:
突破传统两阶段检测的级联范式(如R-CNN),通过全局感知与并行预测,将检测速度提升至实时级别(45-155 FPS),同时保持较高mAP精度。其"网格-边界框"耦合机制与多任务联合训练策略,为后续单阶段检测模型奠定了理论基础。
YOLO 的设计虽然精巧,但是还有许多不足的地方,比如一个 grid 只能识别出一种物体。我们会在 YOLO v2 和 YOLO v3 中看到更巧妙的设计。
YOLOv2通过引入Anchor Boxes与多尺度预测,允许多个边界框检测,提升小目标召回率;YOLOv3在此基础上采用多尺度特征融合(类似FPN)、更深层的Darknet-53网络及Logistic回归分类,进一步优化小目标检测与复杂场景分类,mAP从67.2%提升至44.7%,同时保持实时性。
两者均突破YOLOv1中“单grid单物体”的限制,但YOLOv3通过多尺度特征整合与网络结构优化实现了更高精度。
以上只是入门,在实际工作中还需要考虑工程化问题,比如通信,软硬件的格式(onnx),算子类型转换和版本兼容等问题,也是一个需要技术也需要耐心的工作。
最后
如果你真的想学习人工智能,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
这里也给大家准备了人工智能各个方向的资料,大家可以微信扫码找我领取哈~
也可以微信搜索gupao66回复32无偿获取哦~


脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 21
21 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)