联邦学习常见问题
例如神经网络的层参数(如卷积核权重、全连接层偏差)。以图像分类模型为例,本地训练时客户端通过反向传播更新这些参数,仅将更新后的参数上传至服务器。:从横向联邦(数据特征重叠、样本不同)扩展到纵向联邦(样本重叠、特征不同)和联邦迁移学习,应用领域从金融、医疗扩展到物联网等。:医院A本地训练癌症检测模型,参数是卷积核的权重。:开源框架(如FATE、TensorFlow Federated)和行业标准(如
1. 联邦学习的发展历程与形成原因
1.1发展历程
-
萌芽阶段(2016年前):分布式机器学习、隐私保护技术(如差分隐私)的发展为联邦学习奠定基础。
-
提出阶段(2016年):谷歌首次提出“联邦学习”(Federated Learning)概念,用于解决安卓手机用户数据隐私问题。
-
扩展阶段(2017-2020年):从横向联邦(数据特征重叠、样本不同)扩展到纵向联邦(样本重叠、特征不同)和联邦迁移学习,应用领域从金融、医疗扩展到物联网等。
-
标准化阶段(2020年后):开源框架(如FATE、TensorFlow Federated)和行业标准(如IEEE联邦学习标准)逐步完善。
1.2联邦学习的产生源于三大需求
- 数据隐私保护:欧盟 GDPR、中国《数据安全法》等法规限制数据跨域流动,联邦学习通过 “数据不动模型动” 实现合规。
- 数据孤岛破解:企业、机构间数据难以共享,联邦学习允许在本地数据上协同建模,如医院联合训练疾病预测模型。
- 分布式计算优势:边缘设备(如手机、传感器)算力提升,联邦学习利用分布式资源降低对中心服务器的依赖。
2. 本地训练与参数上传的机制
2.1本地训练的必要性
联邦学习要求数据不出本地,避免原始数据泄露。本地训练的参数是模型的权重、梯度或中间特征,例如神经网络的层参数(如卷积核权重、全连接层偏差)。以图像分类模型为例,本地训练时客户端通过反向传播更新这些参数,仅将更新后的参数上传至服务器。
2.2为什么参数不易泄密?
-
参数是抽象特征:如图像分类模型中,参数可能是边缘检测滤波器的数值,无法反推原始图片。
-
隐私增强技术:配合差分隐私(添加噪声)、同态加密(加密后运算)进一步保护参数。
例子说明:
-
医疗场景:医院A本地训练癌症检测模型,参数是卷积核的权重。上传的权重仅反映“如何识别肿瘤特征”,而非具体患者的CT扫描图。
2.3参数上传的核心逻辑
- 隐私保护:参数是数据的抽象表示,不含原始样本信息。例如,医院A的肺癌数据在本地训练后,上传的是模型对 “结节大小”“密度” 等特征的权重,而非具体患者的CT图像。
- 通信效率:参数体积远小于原始数据。假设一个神经网络有100万个参数,每个参数占4字节,总传输量约4MB,而原始CT图像可能达数十MB。
3. 参数上传的安全性与本地训练示例
3.1参数不泄密的原理
- 加密技术:同态加密允许在加密参数上直接计算,如服务器聚合加密后的梯度时无需解密。例如,WorldQuant 的 Federated Alpha 系统采用同态加密处理金融机构的本地梯度,确保交易数据不泄露。
- 差分隐私:在参数中添加随机噪声,使单个数据点的影响被稀释。例如,某医院上传的模型参数加入噪声后,攻击者无法推断出特定患者的病情。
- 模型分解:FedCG算法将模型分为私有特征提取器和公共分类器,仅上传生成器参数,避免暴露原始特征。
3.2本地训练内容与示例
本地训练的是模型对本地数据的适应性。例如,多个医院联合训练糖尿病预测模型:
- 本地数据特征提取:医院A用本地患者的血糖、血压数据训练特征提取器,生成高维特征向量。
- 本地模型更新:通过梯度下降优化分类器参数,使模型在本地数据上的预测准确率提升。
- 参数上传:仅将特征提取器的权重和分类器的梯度上传至服务器。
4. 参数聚合过程与算法实现
4.1服务器端的参数聚合
- FedAvg 算法:服务器对客户端参数进行加权平均,权重由客户端数据量决定。例如,医院 A 有10万条数据,医院B有5万条,聚合时 A 的参数贡献占比为 2/3。
- FedProx 优化:针对数据异质性,引入近端项限制参数偏离全局模型,防止模型崩溃。公式为:
-
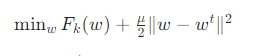
-

- FedKTL 框架:服务器通过生成器生成原型图像对,结合ETF分类器实现域对齐,将知识转移至客户端,减少通信开销。
4.2具体流程示例

5. 联邦学习的现存问题与挑战
5.1技术层面
- 通信开销:模型参数的多次上传下载耗时,尤其在大规模网络中。例如,FedAvg 训练 ResNet-18模型时,每轮通信需传输数十MB数据。
- 数据异质性:客户端数据分布差异(如标签偏斜、特征偏斜)导致模型收敛慢。例如,医院A的糖尿病患者以老年人为主,医院B以年轻人为主,全局模型可能对某一群体效果差。
- 安全漏洞:梯度反推攻击可通过参数还原部分原始数据。例如,攻击者利用GAN生成与训练数据相似的样本。
5.2系统层面
- 设备异构性:边缘设备算力、电量差异大,部分客户端可能无法完成训练。例如,手机在低电量时可能中断联邦学习任务。
- 激励机制:参与方缺乏动力贡献资源。例如,小型医院可能不愿为大型机构的模型优化提供数据。
5.3应用层面
- 模型可解释性:联邦学习模型复杂,难以向监管机构或用户解释决策逻辑。例如,欧盟 MiFID II 要求算法透明,联邦学习需记录决策路径。
- 合规风险:不同国家的数据法规冲突可能阻碍跨国合作。例如,某跨国银行的联邦学习系统需同时满足GDPR和中国《个人信息保护法》。
5.4最新研究进展
- 通信优化:FedKTL通过生成器生成原型图像,将上传量减少90%以上。
- 安全增强:量子安全联邦学习协议利用量子密钥分发技术,将传输时延降至微秒级。
- 异构处理:FedCG通过图卷积网络连接不同域的模型,提升异质数据下的性能。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)