第三周综述
贝叶斯定理:P(c|x)=P(c)P(x|c)/p(x),其中P(x)是证据因子与类别无关,P(c)先验概率是样本空间中各类样本所占比例,可通过各类样本出现的频率估计,P(x|c)是样本相对于类标记的类条件概率,亦称“似然”。周志华《机器学习》的理论深度,为“我是土堆”教程的PyTorch实践指明方向,经典理论与PyTorch实践教程的融合,打通了机器学习“知”与“”行“的通道,让知识学习从碎片化
一、摘要
在机器学习知识体系构建中,周志华《机器学习》经典概论与‘我是土堆’PyTorch深度学习入门教程,从算法原理阐释到代码实践落地,共同勾勒出机器学习从理论到应用的完整路径,为理解与运用机器学习技术提供支撑。
二、周志华《机器学习》
2.1特征空间映射
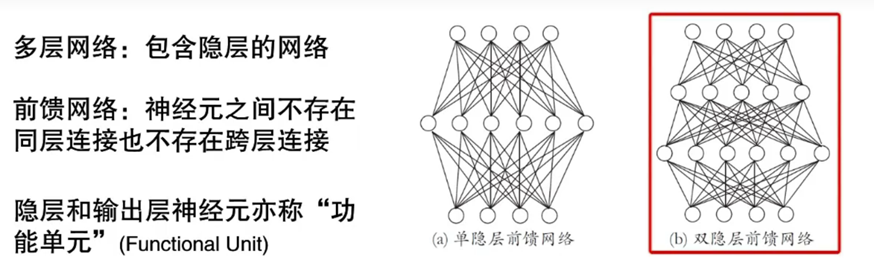
如果原始空间是有限维(属性数有限),那么一定存在一个高维特征空间是样本线性可分。核函数的基本思路是设计核函数绕过显式考虑特征映射以及高维内积的困难。Mercer定理是若一个对称函数所对应的核矩阵半正定,则它能作为核函数来使用。任何一个核函数都隐式的定义了一个RKHS(再生核希尔伯特空间)。支持向量机性能的关键是“核函数选择”。神经网络是具有适应性的简单单元组成的广泛并行的网络,它的组织能够模拟生物神经系统对真实世界物体所做出的交互反应。神经网络学得的知识蕴含在连接权与阈值中。理想的激活函数是阶跃函数,0表示抑制神经元,1表示激活神经元。常见的神经元模型是M—P神经元模型:
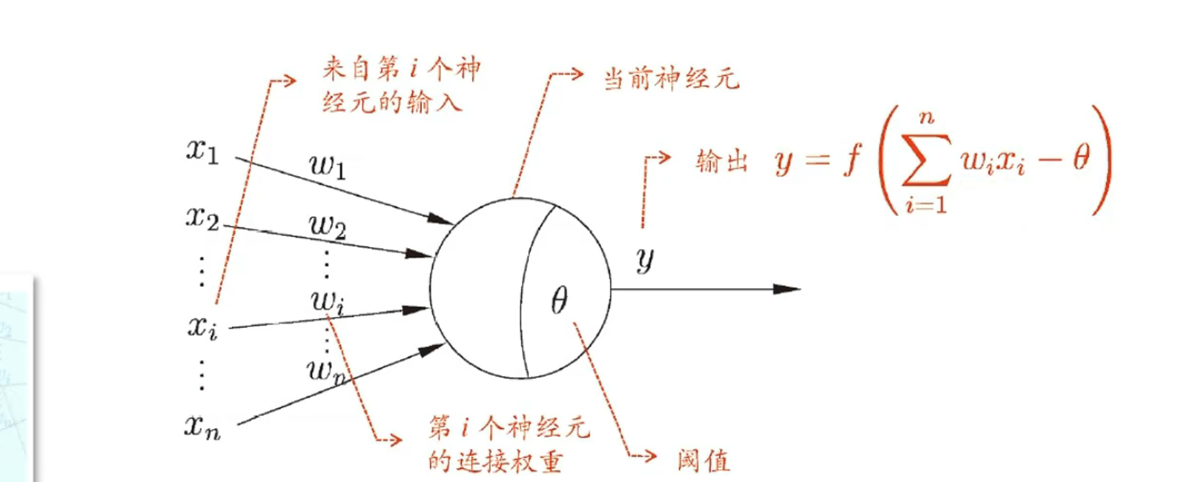
2.2分类与概率模型
分类任务中,贝叶斯理论基于概率推理,利用先验、条件概率计算后验,虽简化假设,但在文本等场景中高效实用。贝叶斯决策论包含判别式模型和生成式模型。判别式模型的思路是直接对P(c|x)建模,代表包括决策树、BP神经网络、SVM。生成式模型的思路是先对联合概率分布p(x|c)建模,再由此获得p(c|x),代表是贝叶斯分类器。贝叶斯定理:P(c|x)=P(c)P(x|c)/p(x),其中P(x)是证据因子与类别无关,P(c)先验概率是样本空间中各类样本所占比例,可通过各类样本出现的频率估计,P(x|c)是样本相对于类标记的类条件概率,亦称“似然”。贝叶斯定理的困难在于估计似然。极大似然估计基本思路是先假设某种概率分布式,在基于训练样例对参数进行估计。拉普拉斯修正是若某个属性值在训练集中没有与某个类同时出现过,则直接计算会出现问题,因为概率连乘将‘抹去’其他属性提供的信息。集成学习中‘多样性’是关键,其常用方法是序列方法和并行化方法,Boosting(提升算法)是集成学习中典型的序列化方法,Bagging(引导聚集算法)是集成学习中典型的并行化方法。
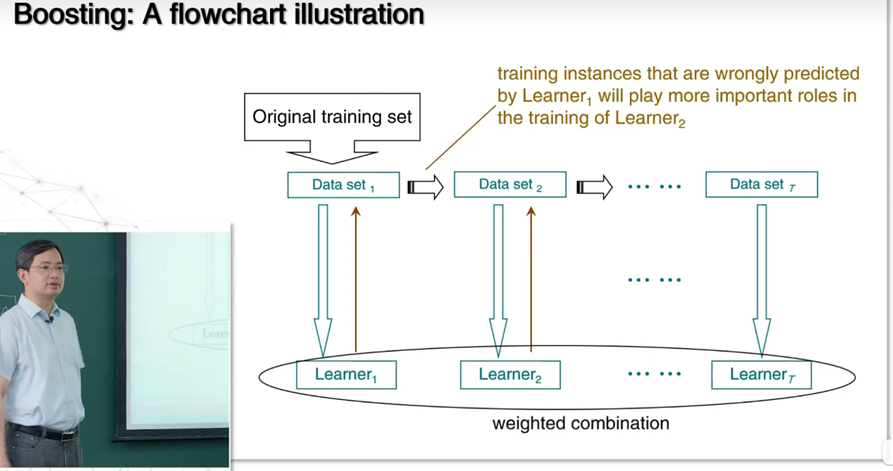

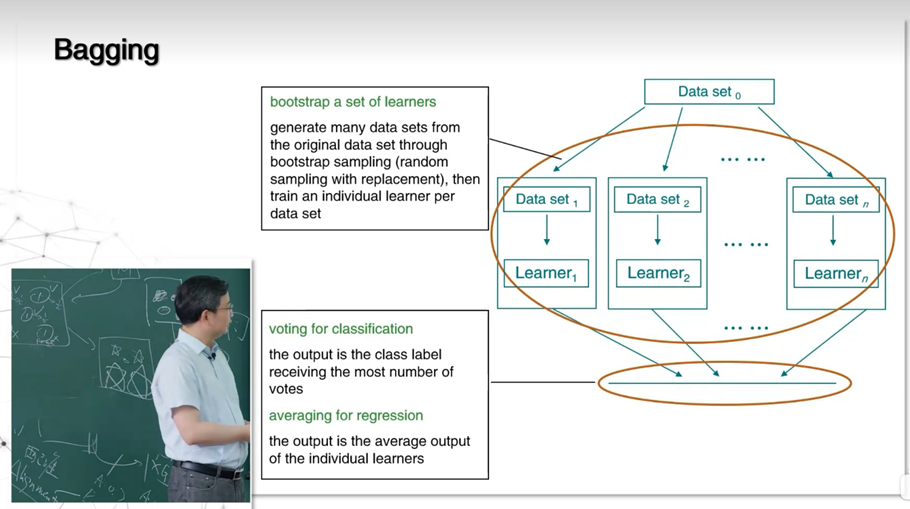

2.3聚类算法体系
聚类在无监督学习中应用最广,其目标是将数据样本划分为若干个通常不相交的‘簇’,既可以作为一个单独过程(用于寻找数据内在的分布结构)也可以作为其他学习任务的前驱过程。聚类性能度量亦称“有效性指标”包含①外部指标:将聚类结果与某个“参考模型”进行比较。②内部指标:直接考察聚类结果而不用任何参考模型,其基本想法是“簇内相似度”高且“簇间相似度”低。常见的聚类算法:①原型聚类②密度聚类③层次聚类


三、PyTorch实践聚能
3.1Dataset
Dataset(数据集)是机器学习、数据分析和统计建模中用于训练、验证和测试模型的一组结构化或非结构化的数据集合。它是模型学习规律和模式的基础,数据集的质量和特性直接影响模型的性能和泛化能力。
import self
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self ,root_dir,label_dir):
self.root_dir=root_dir
self.label_dir=label_dir
self.path=os.path.join(self.root_dir,self.label_dir)
self.img_path=os.listdir(self.path)
def __getitem__(self, idx):
img_name=self.img_path[idx]
img_item_path=os.path.join(self.root_dir,self.label_dir,img_name)
img=Image.open(img_item_path)
label=self.label_dir
return img.label
def __len__(self):
return len(self.img_path)
root_dir=r"D:/python learning/pythonProject/learn/dataset/train"
ants_label_dir="ants"
bees_label_dir="bees"
ants_dataset=MyData(root_dir,ants_label_dir)
bees_dataset=MyData(root_dir,bees_label_dir)
train_dataset=ants_dataset+bees_dataset3.2Transforms
在机器学习和深度学习中,Transforms(数据变换)是对原始数据进行预处理的关键步骤,用于将数据转换为模型可接受的格式,并提升数据质量、增强模型泛化能力。
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img_path=r"D:/python learning/pythonProject/learn/dataset/train/ants_image/0013035.jpg"
img=Image.open(img_path)
writer=SummaryWriter("logs")
tensor_trans=transforms.ToTensor()
tensor_img=tensor_trans(img)
writer.add_image("Tensor_img",tensor_img)
writer.close()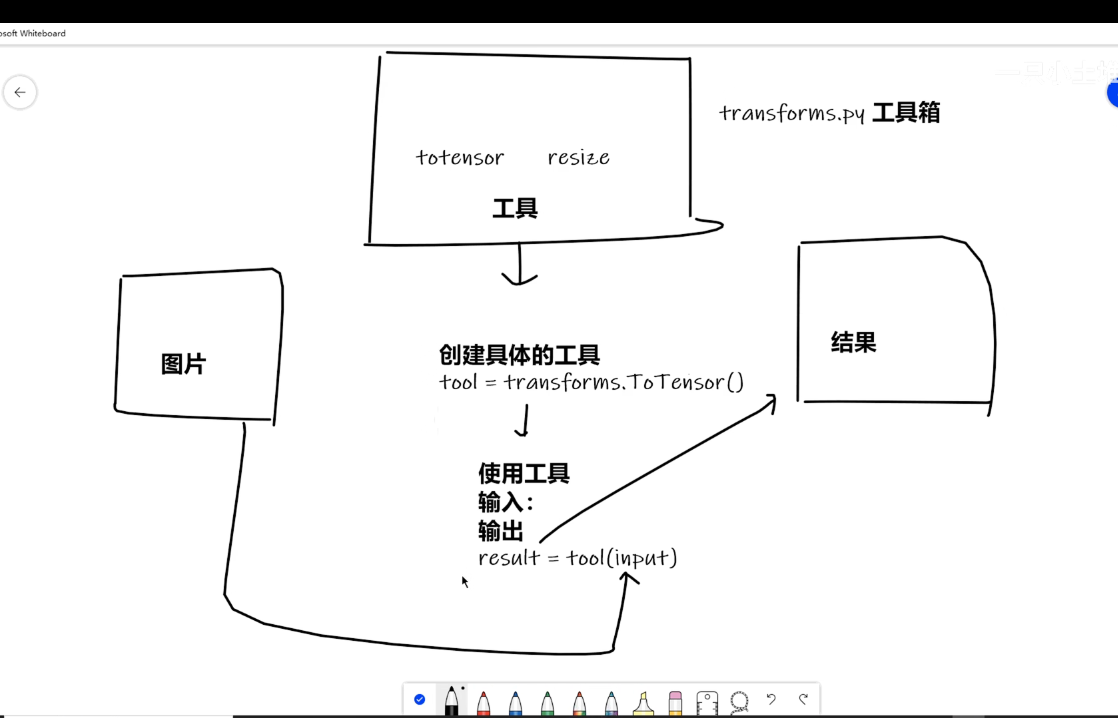
3.3DataLoader
在深度学习中,DataLoader是用于高效加载和处理数据的工具,它的核心作用是将数据集封装成可迭代的批次,并支持多进程加速、数据打乱等功能、从而提升模型训练的效率和稳定性。
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
test_loader=DataLoader(dataset=test_data,batch_size=4,shuffle=True,num_workers=0,drop_last=False)
img,target=test_data[0]
print(img.shape)
print(target)
writer=SummaryWriter("dataloader")
for epoch in range(2):
step=0
for data in test_loader:
imgs,targets=data
#print(imgs.shape)
#print(targets)
writer.add_image("Epoch:{}".format(epoch),imgs,step)
step=step+1
writer.close()四、总结
周志华《机器学习》的理论深度,为“我是土堆”教程的PyTorch实践指明方向,经典理论与PyTorch实践教程的融合,打通了机器学习“知”与“”行“的通道,让知识学习从碎片化理论理解,进阶为可落地、可验证的实践能力,推动对机器学习技术的深度掌握与灵活运用。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 44
44 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)