视觉语言动作模型 (VLAs) :赋予机器行动的智慧
视觉语言动作模型(VLA)正推动具身智能迈上新台阶,实现AI从感知理解到物理交互的闭环。作为多模态技术的突破性进展,VLA将视觉编码器、语言编码器和动作解码器融合,赋予机器"看-懂-动"的完整能力链。前沿研究涌现出RT-2、GR00T等标志性模型,通过大规模预训练和架构创新,显著提升机器人的语义理解与任务执行能力。应用场景涵盖人形机器人、自动驾驶和医疗工业领域,NVIDIA的GR00T项目更将推动
文章目录
人工智能的浪潮正以前所未有的速度席卷全球,其中,赋予机器感知、理解并与物理世界交互的能力,一直是科学家们孜孜以求的目标。在这一探索征程中,视觉语言动作模型 (Vision-Language-Action, VLA) 作为一颗冉冉升起的新星,正引领着具身智能 (Embodied AI) 领域迈向新的高峰。VLA模型旨在将视觉感知、自然语言理解和机器人动作执行紧密地结合在单一的计算框架内,让智能体不仅能“看懂”世界、“听懂”指令,更能“行动”起来,完成复杂的物理任务。这与主要进行信息处理和对话的聊天AI(如ChatGPT)不同,VLA更强调与物理实体的交互和对环境的控制。VLA被广泛认为是通向通用人工智能 (AGI) 的关键要素之一。

一、VLA 的诞生:从单模态到多模态的飞跃
VLA模型的出现并非一蹴而就,而是建立在人工智能多个领域长期积累和发展的基石之上。
-
早期单模态模型的贡献:计算机视觉 (CV) 的发展,如ResNet、ViT、SAM等模型的出现,使得机器能够高效地从图像中提取特征和理解场景。 自然语言处理 (NLP) 领域的突破,特别是Transformer架构及其衍生的大语言模型 (LLM) 如BERT、ChatGPT,赋予了机器强大的文本理解和生成能力。 同时,强化学习 (RL) 的进步,例如DQN、PPO等算法,为机器通过试错学习最优行为策略提供了可能。
-
多模态模型的兴起:随着单模态技术日趋成熟,研究者们开始探索如何融合多种模态的信息,以应对更复杂的任务。视觉语言模型 (VLM) 如CLIP、Flamingo、LLaVA等应运而生,它们能够连接视觉和语言,实现图像描述、视觉问答等功能。
-
VLA 的出现:在VLM的基础上,为了让智能体能够在物理世界中执行任务,VLA模型应运而生。谷歌DeepMind提出的Robotic Transformer 2 (RT-2) 被认为是较早明确提出VLA概念并展示其强大潜力的代表性工作。 VLA的出现标志着AI从感知理解走向了感知-理解-行动的闭环。
二、深入剖析 VLA:核心组件与工作原理
理解VLA模型,首先需要了解其核心构成和基本工作流程。
-
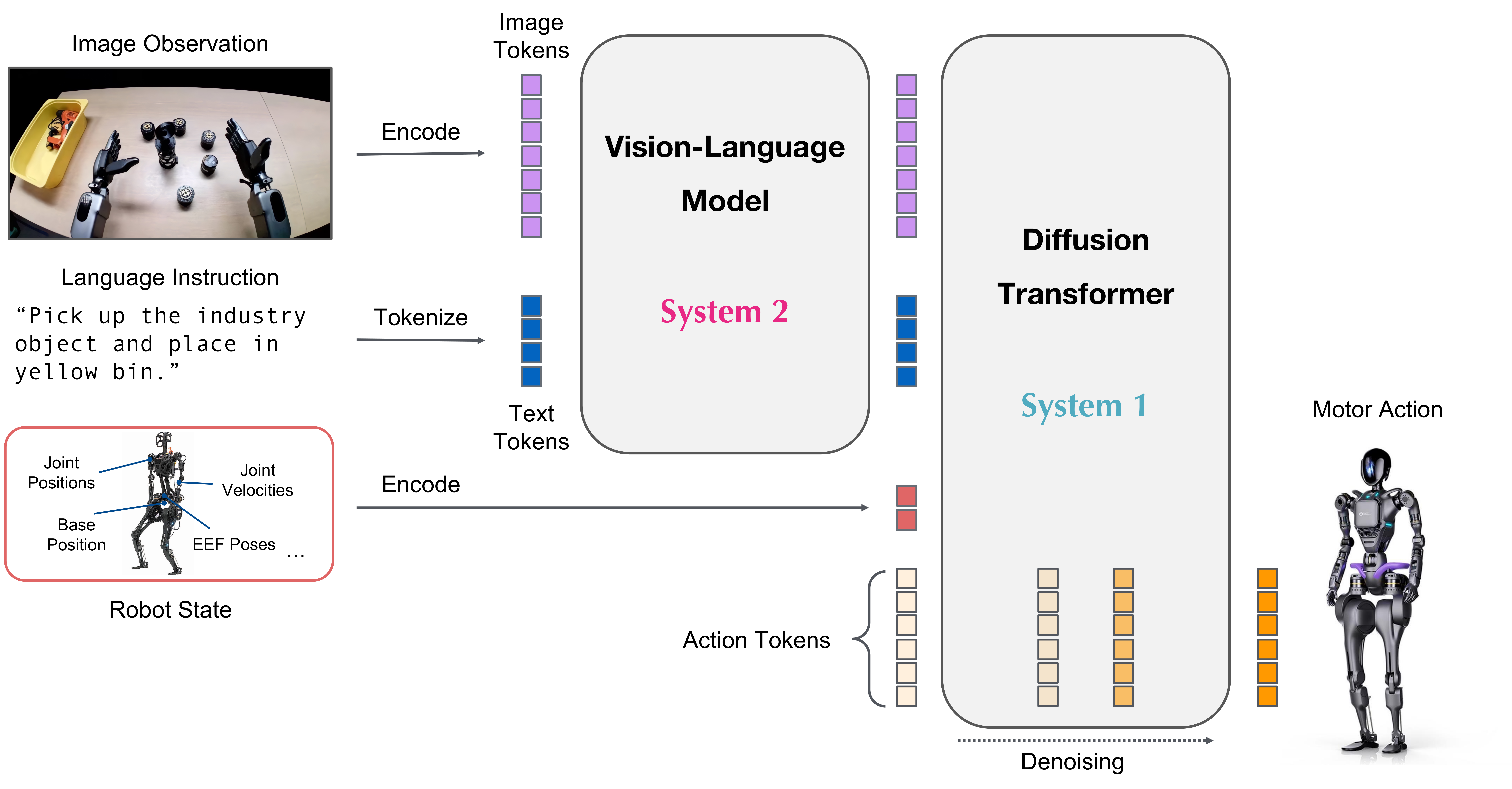
VLA 的通用架构:典型的VLA模型通常包含以下几个关键组件(如图1所示):
- 视觉编码器 (Vision Encoder):负责处理来自摄像头等传感器的视觉输入,提取环境状态的关键信息,例如物体类别、姿态、几何形状等。通常采用预训练的视觉基础模型(如ViT、SAM)作为骨干网络。
- 语言编码器 (Language Encoder):负责理解用户下达的自然语言指令,将其编码为机器可理解的表征。大语言模型因其强大的语义理解能力而被广泛应用。
- 动作解码器 (Action Decoder):基于融合后的视觉和语言信息,生成机器人在物理世界中执行的具体动作指令,如机械臂的关节角度、移动平台的平移和旋转等。
- 多模态融合策略 (Multimodal Fusion Strategy):如何有效地融合视觉和语言两种模态的信息是VLA模型的核心挑战之一。研究者们探索了多种融合方法,借鉴了BLIP-2、LLaVA等VLM中的技术。
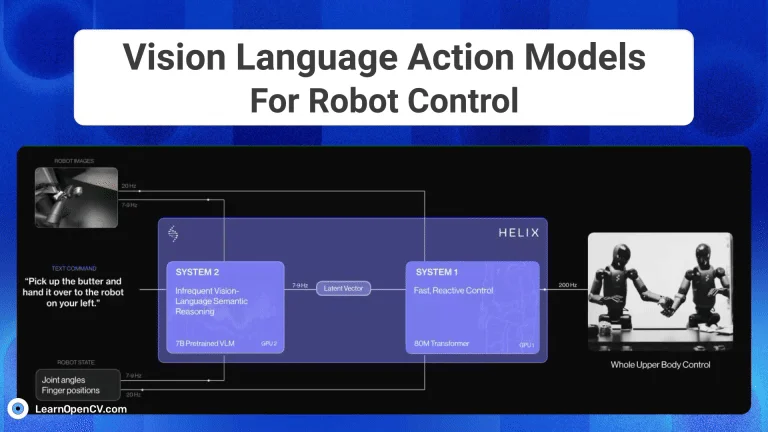
图1:视觉-语言-动作模型的一般架构
-
VLA 的分类与主要研究方向:根据其侧重点和实现路径,VLA的研究可以大致分为几个主要方向:
- 关注单个组件的优化:这类研究致力于提升VLA模型中某一特定模块的性能,例如改进预训练视觉表示的质量、学习更精准的环境动态模型 (dynamics learning)、构建世界模型 (world model) 以进行更长远的预测和规划,或者增强模型的推理能力。
- 低级控制策略 (Low-level Control Policies):这类模型直接将视觉感知和语言指令映射到机器人的低级动作指令(如关节扭矩、末端执行器速度等)。语言指令和视觉感知被输入到控制策略中,然后控制策略生成低级动作,如平移和旋转。
- 高级任务规划器 (High-level Task Planners):对于需要多步骤完成的复杂长期任务,这类模型充当高级规划者的角色,负责将宏大的任务目标分解为一系列更简单、可执行的子任务序列,从而引导VLA逐步实现最终目标。
三、前沿进展:那些令人瞩目的 VLA 模型与趋势
近年来,VLA领域的研究取得了显著进展,涌现出一批具有代表性的模型和技术,并呈现出一些重要发展趋势。
-
大规模视觉语言动作模型 (LVLA) 的探索:借鉴大语言模型在NLP领域的成功经验,研究者们开始构建参数量更大、在更广泛数据上训练的LVLA模型,以期获得更强的泛化能力和涌现能力。
- RT-2 (Robotic Transformer 2): 通过在互联网规模的视觉问答数据和机器人数据上进行联合微调,RT-2展现出了符号推理和语义理解等高级能力。
- RT-H (Robotic Transformer-H): 引入了语言动作中间层,构建了“指令-语言动作-底层动作”的三层架构,这种设计改善了不同任务间的知识共享,并支持在语言层面进行错误修正。
- RT-X 系列: 通过在Open X-Embodiment等大规模多样化机器人数据集上进行训练,RT-X验证了跨不同机器人硬件和任务的知识迁移的可行性。
- OpenVLA: 作为RT系列的一个开源替代方案,OpenVLA探索了利用LoRA(Low-Rank Adaptation)等参数高效微调技术,在降低训练成本的同时保持了强大的性能。
- π-0 (Pi-Zero): 采用流匹配 (flow matching) 架构将预训练的VLM扩展为VLA,并通过混合专家 (Mixture-of-Experts) 框架来平衡模型的通用知识和专业技能。
- 其他代表性模型: Figure AI 推出的 Helix 模型展示了人形机器人在语音指令下进行复杂家务协作的能力。清华大学、字节跳动等机构提出的 RoboVLMs 通过简化设计实现了性能突破。还有研究探索了 知识隔离 (Knowledge Insulating) 的VLA模型,旨在提升训练和运行效率,并增强泛化能力。
-
人形机器人通用基础模型的突破:NVIDIA GR00T
- NVIDIA 在2024年GTC大会上发布的 Project GR00T (Generalist Robot 00 Technology) 是一个里程碑式的进展。GR00T 旨在为人形机器人打造一个通用的基础模型,使其能够理解自然语言、观察人类行为(包括视频演示),并模仿这些动作来学习协调性、灵活性和与现实世界交互的技能。
- GR00T 的目标是让机器人通过多模态指令(文本、语音、视频)执行各种复杂任务,并能通过观察人类行为进行学习,而无需对每个任务进行显式编程。
- 为支持GR00T,NVIDIA还推出了基于Jetson Thor系统级芯片(SoC)的新型人形机器人计算机,并对Isaac机器人平台进行了重大升级,包括Isaac Manipulator(用于机械臂的灵巧操作)和Isaac Perceptor(提供多摄像头、3D环绕视觉能力)等生成式AI基础模型和工具。GR00T 将作为机器人的“大脑”,通过 Isaac 平台的工具进行训练和部署。
- 众多领先的人形机器人公司,如Agility Robotics, Apptronik, Boston Dynamics, Figure AI 等,已与NVIDIA合作,共同推动GR00T的发展和应用。
[建议配图:NVIDIA Project GR00T 的概念图,或展示人形机器人在GR00T驱动下学习和执行任务的场景。例如,一个人形机器人通过观察视频学习泡咖啡,然后自主完成该任务。]
-
最新趋势与研究方向:
- 具身基础模型 (Embodied Foundation Models, EFM):VLA是EFM的核心组成部分。研究者们致力于构建能够理解物理世界并与之交互的通用基础模型,强调模型在真实物理环境中的泛化和适应能力。
- 世界模型 (World Models) 的集成:在VLA中集成更强大的世界模型,使机器人能够更好地预测其行为的长期后果,理解环境的动态变化,并进行更有效的规划。
- 通过视频学习 (Learning from Videos):让机器人通过观看人类演示视频来学习新技能,是提升VLA数据效率和泛化能力的重要途径。这需要模型具备高级的视频理解、跨模态表征学习和动作生成能力。
- 与大型语言模型 (LLM) 的更深度融合:进一步探索如何将LLM强大的常识推理、复杂指令理解和任务规划能力更紧密地集成到VLA框架中,以指导机器人的行为并提升其智能水平。
- 模拟到现实的迁移 (Sim-to-Real Transfer):虽然模拟环境为VLA的训练提供了便利,但如何有效地将模拟环境中学习到的策略迁移到真实世界的机器人上,并克服现实差距,仍然是一个关键挑战。
-
训练范式的创新:
- 协同微调 (Co-finetuning):利用大规模的互联网视觉语言语料库(如LAION-5B)和机器人轨迹数据集(如Open X-Embodiment, RT-X)进行联合训练,将从网络数据中学到的语义理解能力与从机器人数据中学到的运动技能相结合。
- 参数高效训练策略 (Parameter-Efficient Training Strategies):为了降低训练大规模VLA模型的计算成本,研究者们引入了如LoRA、Adapter等高效微调技术。
- 架构创新: 探索了早期融合、双系统处理(例如,一个系统负责快速反应的低级控制,另一个系统负责深思熟虑的高级规划)、自校正反馈回路等新型架构。
四、VLA 的广阔天地:应用场景一览
凭借其强大的多模态理解和行为生成能力,VLA模型在众多领域展现出巨大的应用潜力:
- 人形机器人 (Humanoid Robots):让机器人在家庭、办公、工厂等非结构化环境中完成复杂的日常任务,如整理房间、取递物品、执行装配任务、协助人类进行某些操作等。NVIDIA的GR00T项目正致力于推动这一领域的革命性发展。
- 自动驾驶汽车 (Autonomous Vehicles):提升自动驾驶系统对复杂交通环境的理解和应对能力,实现更安全、更智能的自主导航和驾驶决策。
- 医疗与工业机器人 (Medical and Industrial Robots):在医疗领域辅助医生进行手术操作或病人护理;在工业领域执行精密的装配、检测、物流搬运等任务,提高生产自动化水平和效率。
- 精准农业 (Precision Agriculture):控制农业机器人进行作物监测、智能灌溉、自动采摘等作业,提高农业生产效率。
- 增强现实导航 (Augmented Reality Navigation):为用户提供更智能、更自然的交互式导航体验。
- 日常生活任务 (Daily Life Tasks):除了上述特定领域,VLA还有望应用于更广泛的日常生活场景,例如智能家居控制、个性化辅助、灾难救援等。
[建议配图:一组展示VLA在不同应用场景(如人形机器人在家中服务、自动驾驶汽车在城市中行驶、工业机器人在工厂作业、医疗机器人在手术室辅助)的图片。]
五、挑战与荆棘:VLA 面临的难题
尽管VLA模型取得了令人鼓舞的进展,但其发展仍面临诸多挑战:
-
数据层面:
- 机器人数据的稀缺性与多样性:与互联网上丰富的文本和图像数据相比,高质量、多样化的机器人交互数据(包含视觉、语言和动作序列)相对匮乏,且获取成本高昂。
- 数据集与基准测试的局限性:现有数据集和基准测试在规模、多样性和评估粒度方面仍有待提升,难以全面支持模型的诊断与优化。
-
模型层面:
- 基础模型的泛化能力:当前VLA模型在泛化到未见过的任务、环境和机器人形态方面的能力,与NLP领域的LLM相比仍存在较大差距。 如何构建适应多样化场景的通用机器人基础模型 (RFM) 是一个重要方向,GR00T等项目正是在尝试解决这一问题。
- 多模态信息的高效对齐与动态环境下的自适应推理:如何更有效地融合视觉、语言甚至触觉、听觉等多种模态的信息,并在快速变化的动态环境中进行实时、准确的推理和决策,是一个持续的挑战。
- 实时控制与推理速度:许多机器人应用场景对模型的响应速度有严苛要求,而大规模VLA模型的推理延迟可能成为瓶颈。NVIDIA的Jetson Thor等硬件平台旨在为这类模型提供强大的计算支持。
- 运动规划的复杂性:生成平滑、安全、高效的机器人运动轨迹本身就是一个难题,尤其是在复杂的约束条件下。
- 系统可扩展性:如何设计可扩展的VLA架构,使其能够方便地集成新的传感器、执行器或学习新的技能,是实现通用具身智能的关键。
-
安全与伦理:
- 机器人系统的安全性:确保机器人在与物理世界交互过程中的安全性至关重要,这需要模型具备常识推理、风险评估和遵循安全协议的能力。
- 伦理部署风险:随着VLA能力的增强,其在军事、监控等敏感领域的应用也带来了潜在的伦理风险,需要审慎考虑和规范。
六、未来展望:VLA 将走向何方?
展望未来,VLA模型的发展将朝着更智能、更通用、更安全的方向不断迈进:
- 构建更通用的机器人基础模型 (RFM):类似于NLP领域的LLM,打造能够适应多种机器人形态、任务和环境的机器人基础模型,是VLA领域的核心目标之一。NVIDIA GR00T等项目的出现预示着这一方向的加速发展。
- 智能体AI适应与跨具身泛化:提升VLA模型对不同机器人硬件平台(跨具身形态)的适应能力,以及从一个任务或环境中学到的知识迁移到其他未见场景的能力。
- 统一的神经符号规划:结合神经网络强大的模式识别能力和符号推理的逻辑严谨性,发展更鲁棒和可解释的规划与决策系统。
- VLA、VLM与智能体AI的进一步融合:这三个领域将进一步交叉渗透,共同推动具备社会适应性、灵活性和通用性的具身智能体的发展。
- 提升机器人的灵活性和对未见任务的泛化:通过更有效的数据利用、更先进的模型架构和训练方法,使机器人能够更好地应对新颖和非结构化的任务。
- 与推理和规划能力的更强结合:未来的VLA模型不仅能够执行指令,还将具备更强的自主推理和复杂任务规划能力,能够理解更抽象的目标并自主制定执行策略。
- 人机协作的深化:VLA将使机器人能够更自然、更直观地与人类协作,理解人类的意图并提供有效的帮助。
[建议配图:一张展望未来的概念图,描绘人类与高度智能化的VLA驱动的机器人在各种场景下无缝协作的和谐画面。]
七、重要资源参考
对于希望深入了解和研究VLA领域的读者,以下是一些重要的资源类型:
- 代表性数据集:例如Open X-Embodiment, LAION-5B, RT-X 等,这些数据集为VLA模型的训练和评估提供了宝贵的数据基础。 此外,还有许多针对特定任务和场景的数据集,如CALVIN、SimplerEnv等。
- 模拟器与基准:机器人模拟器(如NVIDIA Isaac Sim, Habitat等)为VLA模型的开发和测试提供了低成本、高效率的平台。标准化的基准测试则有助于公平地比较不同模型的性能。
- 开源项目与社区:关注如OpenVLA等开源项目及其社区,可以获取最新的研究进展和代码实现。
- 顶级会议与期刊:关注机器人学(如ICRA, IROS)、人工智能(如NeurIPS, ICML, CVPR)等领域的顶级会议和期刊,可以追踪最新的VLA研究成果。
八、结论
视觉语言动作模型 (VLA) 正处在飞速发展的快车道上,它为我们描绘了一个智能体能够深度理解世界并与之高效交互的未来蓝图。从早期的多模态探索到如今像NVIDIA GR00T这样雄心勃勃的通用基础模型的出现,VLA正在不断突破AI能力的边界。尽管前方仍有诸多挑战,但随着基础模型的不断进步、多模态技术的持续创新、机器人硬件(如专用SoC)的快速迭代以及大规模数据集的构建,我们有理由相信,VLA将在推动具身智能乃至通用人工智能的发展中扮演越来越重要的角色。这不仅是科研人员的探索前沿,更将深刻改变我们与机器协作的方式,并最终影响我们生活的方方面面。持续的研究投入、跨学科合作以及对安全伦理的关注,将是解锁VLA全部潜力的关键。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)