基于PyTorch的CNN手写数字识别 毕业论文+项目源码及数据库文件
总之,本研究成功地展示了深度学习在手写数字识别任务中的强大能力,通过系统的设计和优化,达到了高效、准确的识别效果,达到了99.5%的准确率。但是我们的模型也还有可以完善的地方,因为对于比较奇异的数字,模型也会出现识别错误的情况,如下图数字8一直识别成数字4。该步骤可能对图像的像素值进行了进一步处理,导致模型在预测时对图像的感知不同,确实成功使得模型成功识别出了数字8,但是却又把原先识别成功的数字4
!!! 有需要的小伙伴可以通过文章末尾名片咨询我哦!!!
💕💕作者:优创学社
💕💕个人简介:本人在读博士研究生,拥有多年程序开发经验,辅导过上万人毕业设计,支持各类专业;如果需要论文、毕设辅导,程序定制可以联系作者
💕💕各类成品java系统 。javaweb,ssh,ssm,springboot等等项目框架,源码丰富,欢迎咨询交流。学习资料、程序开发、技术解答、代码讲解、源码部署,需要请看文末联系方式。
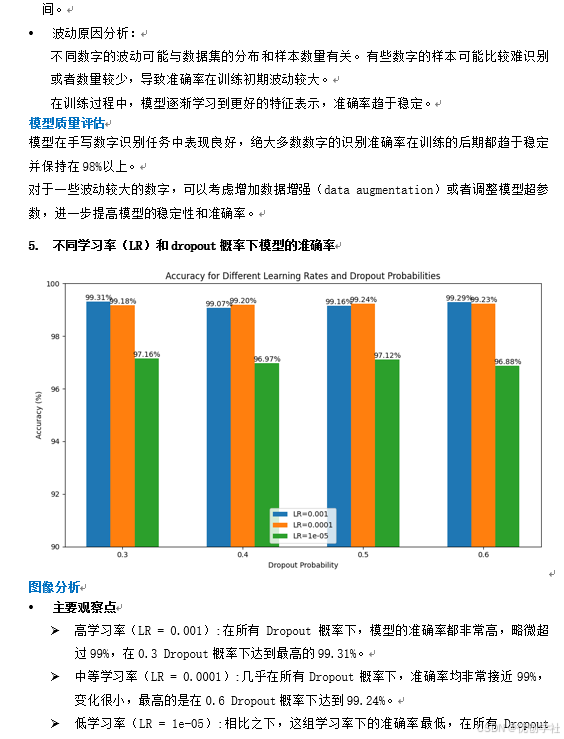
5. 不同学习率(LR)和dropout概率下模型的准确率. 16
6. 训练集(train)验证集(validation)损失曲线. 17
一、 实验目的
本实验的目的是开发一款能够识别手写数字的程序。我们使用著名的MNIST数据集进行模型训练和测试。MNIST数据集包含大量手写数字的灰度图像,每张图像的大小为28x28像素。
二、 项目准备
在实验开始前,我们需要准备以下内容:
- 一些测试图片,用于测试模型的效果。

- 训练集直接使用 torchvision 中所提供的 MNIST 数据集。

MNIST数据库是Google实验室的Corinna Cortes和纽约大学柯朗 研究所的YannLeCun建立的一个手写数字数据库。该数据集中的这些图片代表了阿拉伯数字从0到9的每一个数字,每张图片的规格尺寸均为28×28,用一个数组来表示这张图片。MNIST数据集的功能是:能够提供大量的数据来进行训练和测试,能够提供丰富的资源;可以使研究者通过使用相同的数据集对不同的图片进行分析,将结果进行对比,从而得出准确率更高的程序。
三、 环境配置
本次实验使用Python编译器为PyCharm
主要使用的库如下:
torch:用于深度学习模型的构建和训练。
torchvision:用于加载和处理图像数据集。
numpy:用于数值计算和数组操作。
matplotlib:用于绘图和图形界面的创建。
opencvpython:用于图像处理。
四、手写体数字识别系统概述
手写体数字识别系统的主要任务是将手写数字图像转换为对应的数字字符,具体流程包括图像预处理和神经网络进行数字识别两个主要步骤(如图1.1所示):

系统总流程图(图1.1)
(一)其中图像预处理的流程
读取图片: 从输入设备(如扫描仪、相机)中获取手写数字图像。
灰度化: 将彩色图像转换为灰度图像,以简化后续处理步骤。灰度化将每个像素的颜色信息转换为一个灰度值。
二值化: 将灰度图像转换为二值图像,使图像仅包含黑白两种颜色。常用的方法是使用阈值分割技术。
去噪声: 对二值图像进行去噪处理,以消除噪声点和其他不必要的细节,提高图像的质量。
数字分割: 将包含多个手写数字的图像分割成单个数字,以便于单独识别。
归一化调整: 将分割后的数字图像进行尺寸归一化,使所有图像具有相同的尺寸,便于特征提取和分类。
图像细化: 对归一化后的图像进行细化处理,以保留主要的笔画和结构信息,同时减少冗余信息。
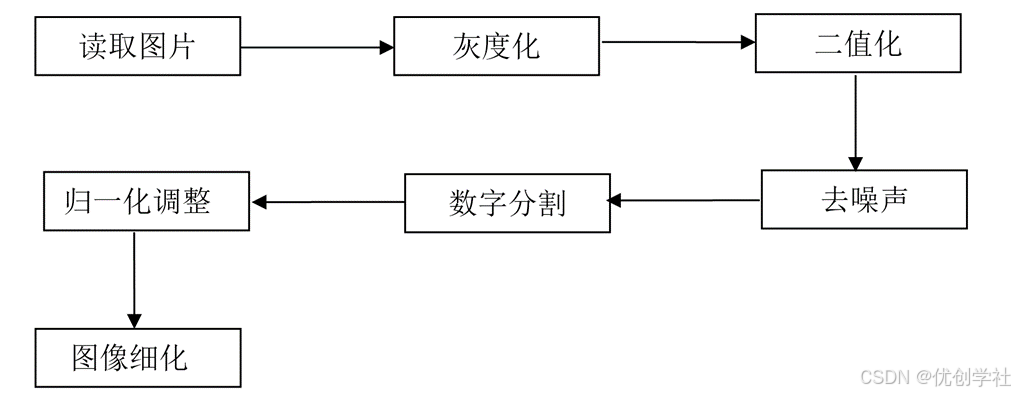
图1.2 图像预处理流程图
(二)神经网络数字识别的具体流程
字符特征提取:提取图像中的字符特征,卷积神经网络自动学习并提取有效的特征。该部分由 net.py 文件定义的模型结构实现。
样本训练:使用卷积神经网络(CNN)对训练数据进行训练。该过程在 train.py 文件中实现。
识别:使用训练好的模型对输入的手写数字进行识别,输出对应的数字字符。该过程在 predict.py 文件中实现。

图1.3 神经网络数字识别流程图
(三)文件说明
- 手写体识别系统的文件组织结构
后续补充
- 文件内容概述
net.py: 定义卷积神经网络的结构,包括各层的配置和前向传播过程。
train.py: 负责模型的训练过程,包括数据加载、模型训练、损失计算、优化器更新等。
predict.py: 负责模型的预测过程,加载训练好的模型,输入新的手写数字图像并输出识别结果。
五、数字手写体识别实验代码设计逻辑
(一)搭建网络——net.py
概述:net.py文件定义了一个名为 ConvNet 的深度卷积神经网络模型,用于处理手写数字分类任务。模型包括四个卷积层和对应的批量归一化层,随后是最大池化层进行特征提取和降维。接着是两个全连接层,其中第一层包含了 Dropout 功能,以防止过拟合。最终的输出通过 Log-Softmax 激活函数得到分类的对数概率分布,适用于多类别分类问题。
net.py的设计主要借鉴了LeNet-5模型的思想。LeNet-5模型是最早的卷积神经网络之一,也是基础的CNN模型。LeNet-5包含卷积层、池化层和全连接层的组合,模型架构为输入层-卷积层-池化层-卷积层-池化层-全连接层-全连接层-输出,为串联模式。如图所示。
虽然net.py更复杂,但它遵循了LeNet-5的基本架构。此外net.py文件中每个卷积层的卷积核大小为3x3,这是借鉴了VGG模型。
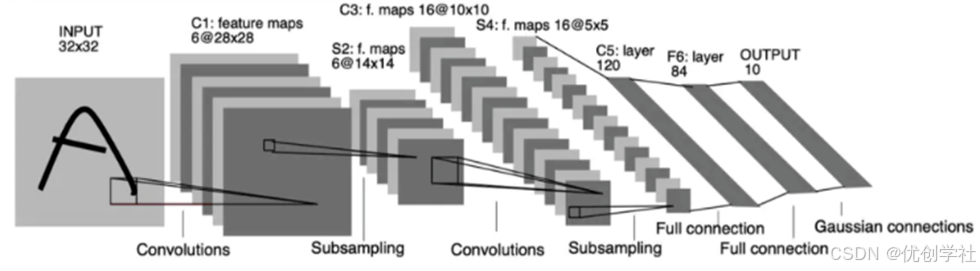
图 LeNet-5模型
(1) 卷积层
在 net.py 文件中,包含四个卷积层,分别是 conv1、conv2、conv3 和 conv4。这种设计使得随着网络层数的增加,特征图的深度逐渐加深,从而能够捕捉到更多的高层次特征。每个卷积层的详细设计如下:
- 卷积核大小:3x3
- 步长:1
- 填充:padding=1,用于保持输入和输出的空间维度一致
- 通道数:conv1:32个输出通道;conv2:64个输出通道;conv3:128个输出通道;conv4:256个输出通道
代码片段:
![]()
(2) 批归一化层
每个卷积层之后都紧跟一个批归一化层,分别是 batchnorm1、batchnorm2、batchnorm3 和 batchnorm4。批归一化有助于加速训练并稳定网络的学习过程。
代码片段:

(3) 激活函数
每个批归一化层之后使用 ReLU激活函数。ReLU 的计算非常简单,即 ReLU(x)=max(0,x),相比较于 Sigmoid 和 Tanh 函数,计算更加高效。并且ReLU 在负输入上的输出为零,这意味着神经元在激活后会更加稀疏,有助于减少网络的参数量和计算复杂度,同时能够更好地进行特征选择和泛化能力。
代码片段:

(4) 池化层
每两个卷积层之后,都使用最大池化层(Max Pooling)进行下采样,通过 F.max_pool2d(x, 2, 2) 实现。用于减小特征图的尺寸,从而降低计算复杂度。池化层的设计如下:
- 核大小:2x2
- 步长:2
- 代码片段:

(5) 全连接层
在卷积层之后,有两个全连接层,分别是 fc1 和 fc2。在 fc1 之后使用了 dropout(丢弃率为0.4),以防止过拟合。具体设计如下:
- fc1:将特征图展平为一维向量,并将其大小调整为128个单元
- fc2:输出10个单元,对应于10个分类标签
代码片段:

(6) 输出层
最后,通过 F.log_softmax(x, dim=1) 对全连接层 fc2 的输出进行 Log-Softmax 变换,得到分类的对数概率分布。每一行表示一个样本在10个类别上的对数概率,这些对数概率可以用于计算交叉熵损失,从而训练模型进行0~9数字识别的多分类任务。下图是net.py文件整个的网络结构图。

net.py网络结构图
(二)模型训练——train.py
概述:train.py 文件是手写体数字识别系统的核心部分。它定义了数据预处理和增强方法,构建并训练卷积神经网络模型,通过训练和验证循环不断优化模型参数,并使用早停策略避免过拟合。最终,训练好的模型可以用于对手写体数字的准确识别。该文件确保模型在训练过程中能够有效地学习数据特征,提升识别准确率,并通过保存最佳模型状态,确保在实际应用中能够得到最佳的性能表现。
在 train.py 中,首先定义超参数,这些参数对模型的训练过程和性能具有显著影响。
(1) 代码片段:

(2) 作用和原理:
- BATCH_SIZE:批量大小设置为512,这是每一批训练数据的样本数。
- EPOCHS:总训练周期设置为20,这表示整个训练数据集将被遍历20次。
- LEARNING_RATE:学习率设置为0.001,用于控制优化器在每次迭代中更新模型权重的步长。
- DEVICE:模型训练的执行环境,自动选择使用GPU(如果可用)或CPU,以加速训练过程。
- DROPOUT_PROB:为0.3,即30%的神经元将在训练过程中随机丢弃,以防止过拟合。
对训练数据应用一系列转换,以增强数据,这有助于使模型对新数据的变化更加鲁棒。
(1)代码片段:
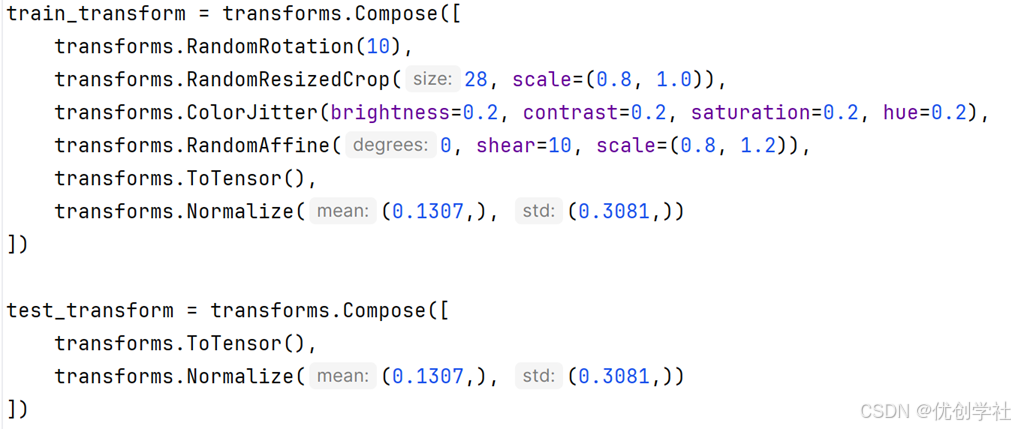
(2)作用和原理:
- RandomRotation 和 RandomAffine: 最多旋转10度,提供图像的随机旋转和仿射变换,模仿实际情况下数字的不同排列和形态。
- RandomResizedCrop 和 ColorJitter: 调整图像大小并改变颜色设置,图像被重新缩放并裁剪到28x28像素。模拟不同的光照和尺度变化,增强模型对不同环境的适应性。
- ToTensor 和 Normalize: 将图像转换为模型可处理的格式,并进行归一化处理,有助于优化训练过程。
调用卷积神经网络模型 ConvNet
(1)代码片段:
![]()
(2)作用和原理:
- ConvNet: 在net.py文件里面包含多个卷积层、批量归一化层和全连接层的网络,能够有效地从图像中提取层次特征,对于图像分类任务非常适用。
- Dropout: 在训练过程中随机使部分神经元的激活值为0,减少对单个神经元的依赖,增加网络的泛化能力。
设置了训练和验证的循环,不断优化模型参数并监控模型性能。
(1)代码片段:

(2)作用和原理:
- 模型训练: 利用损失函数计算误差,通过反向传播更新权重,不断迭代优化模型参数。
- zero_grad: 清除旧的梯度,为新的优化迭代做准备。
- 反向传播和优化: 根据计算出的梯度进行优化步骤,调整模型权重以减少误差。
早停策略用于防止模型在训练过程中过拟合。这是通过监控验证集上的损失来实现的。如果损失不再改善,即认为模型已经开始学习训练数据中的噪声。当验证损失达到新低时,当前模型的状态将被保存
(1)代码片段:
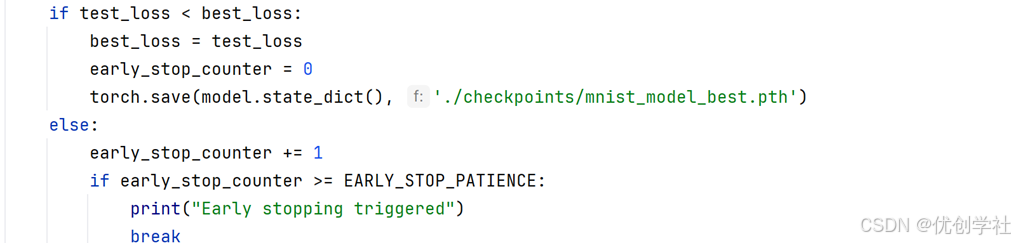
(2)作用和原理:
- 实现方式:在每个训练周期后评估模型在验证集上的表现。如果模型的表现(基于损失)改善,则更新 best_loss 并重置 early_stop_counter。如果没有改善,early_stop_counter 会增加。当 early_stop_counter 达到设定的耐心阈值 EARLY_STOP_PATIENCE 时,训练过程将停止。
- 保存最优模型:当验证损失达到新低时,当前模型的状态将被保存。这确保了即使训练终止,也能从最佳状态恢复模型,以进行预测或进一步分析。


在本研究中,我们基于深度学习设计了一个的准确率手写数字识别系统,具体应用了多层卷积神经网络(CNN)。我们利用广泛认可的MNIST数据库进行模型训练和测试,该数据库包含70,000个28x28像素的标记灰度手写数字图像。此数据集不仅是我们实验的基准,还使本研究能够与其他研究结果进行比较,验证模型的有效性。
在项目准备阶段,我们详细说明了实验所需的测试图片、训练集、以及环境配置。我们使用了Python编译器PyCharm,结合torch、torchvision、numpy、matplotlib、opencv-python等库,以实现数据加载、处理、模型训练和可视化。手写体数字识别系统的设计包括图像预处理和神经网络数字识别两个主要步骤。图像预处理部分涵盖了图像的读取、灰度化、二值化、去噪声、数字分割、归一化调整和图像细化等步骤,确保输入图像符合模型的预期。神经网络识别部分则通过卷积神经网络进行字符特征提取和分类预测,实现了高效的手写数字识别。
在代码设计逻辑部分,我们详细介绍了模型的搭建、训练和预测过程。net.py文件定义了卷积神经网络的结构,借鉴了经典的LeNet-5模型,同时加入了批量归一化和Dropout层以提高模型的泛化能力。train.py文件负责模型的训练过程,包括数据加载、模型训练、损失计算和优化器更新等。predict.py文件则用于加载训练好的模型,对新输入的手写数字图像进行预测。
在模型性能评估中,我们通过t-SNE高维数据可视化、混淆矩阵和各数字准确率曲线等手段,详细分析了模型的识别能力。t-SNE可视化显示不同类别的数字在特征空间中形成清晰的聚类,混淆矩阵则揭示了模型在某些易混淆数字间的误分类情况。通过对不同学习率和Dropout概率下模型表现的比较,我们进一步优化了模型参数,实现了在MNIST数据集上的高准确率。
总之,本研究成功地展示了深度学习在手写数字识别任务中的强大能力,通过系统的设计和优化,达到了高效、准确的识别效果,达到了99.5%的准确率。但是我们的模型也还有可以完善的地方,因为对于比较奇异的数字,模型也会出现识别错误的情况,如下图数字8一直识别成数字4。这个问题我们尝试了优化网络结构,进行超参数调优等,依旧失败未识别成功。于是我们引入了阈值处理步骤(apply_threshold,threshold = 1.5 # 设置阈值,小于1的灰度值将被归为黑色 该步骤可能对图像的像素值进行了进一步处理,导致模型在预测时对图像的感知不同,确实成功使得模型成功识别出了数字8,但是却又把原先识别成功的数字4,5等识别出错。因此,我们训练出的手写体数字识别系统虽然已经很不错了,但仍旧有可以优化的地方。
更多项目:
另有10000+份项目源码,项目有java(包含springboot,ssm,jsp等),小程序,python,php,net等语言项目。项目均包含完整前后端源码,可正常运行!
!!! 有需要的小伙伴可以点击下方链接咨询我哦!!!

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 27
27 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)