机器学习中的PCA降维
主成分分析(Principal Component Analysis, PCA)作为一种经典的降维技术,能够有效地将高维数据投影到低维空间,同时保留数据的主要特征。本文将详细介绍PCA的数学原理、Python实现方法,并分析其优缺点,帮助读者全面理解并正确应用这一强大的降维技术。PCA的核心思想是通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量(主成分),这些主成分按照方差从大到小
引言
在当今大数据时代,高维数据处理已成为机器学习和数据分析中的常见挑战。随着特征数量的增加,不仅计算复杂度急剧上升("维度灾难"),而且数据可视化也变得困难。主成分分析(Principal Component Analysis, PCA)作为一种经典的降维技术,能够有效地将高维数据投影到低维空间,同时保留数据的主要特征。PCA广泛应用于图像处理、生物信息学、金融分析等领域,是数据科学家工具箱中不可或缺的工具。本文将详细介绍PCA的数学原理、Python实现方法,并分析其优缺点,帮助读者全面理解并正确应用这一强大的降维技术。
PCA原理详解
1. 基本概念
PCA的核心思想是通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量(主成分),这些主成分按照方差从大到小排列。第一个主成分对应于数据方差最大的方向,第二个主成分对应于与第一个主成分正交且方差次大的方向,以此类推。
2. 数学推导
步骤1:数据标准化
对原始数据进行中心化处理(均值为0)和缩放(方差为1):
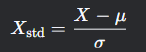 其中μ是均值,σ是标准差。
其中μ是均值,σ是标准差。
步骤2:计算协方差矩阵
协方差矩阵表示各特征之间的线性关系:
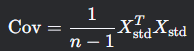
步骤3:特征值分解
对协方差矩阵进行特征值分解:
![]()
其中V是特征向量矩阵,Λ是对角矩阵,对角线元素为特征值。
步骤4:选择主成分
按特征值从大到小排序,选择前k个特征值对应的特征向量组成投影矩阵W。
步骤5:数据投影
将原始数据投影到主成分空间:
![]()
3. 关键指标
缺点
Python实现PCA降维
-
解释方差比例:每个主成分捕获的方差占总方差的比例

-
累计解释方差比例:前k个主成分累计解释的方差比例

-
PCA的优缺点分析
优点
-
降维效果显著:能够有效减少特征数量,降低计算复杂度
-
去除特征相关性:转换后的主成分彼此正交,消除了原始特征间的相关性
-
保留主要信息:通过最大化方差保留数据中最具信息量的部分
-
改善模型性能:去除噪声和冗余特征可能提高后续机器学习模型的性能
-
可视化工具:可将高维数据降至2D或3D便于可视化分析
-
线性限制:PCA是基于线性变换的方法,对非线性结构的数据效果不佳
-
方差≠信息量:PCA仅考虑方差最大化,但高方差方向不一定是最具判别性的方向
-
可解释性降低:主成分是原始特征的线性组合,物理意义不如原始特征明确
-
需要标准化:对特征的尺度敏感,必须事先进行标准化处理
-
确定k值困难:需要人工选择保留的主成分数量,缺乏明确标准
1. 使用scikit-learn实现
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import numpy as np
# 加载数据
data = load_iris()
X = data.data
y = data.target
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# PCA降维
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
# 可视化
plt.figure(figsize=(8, 6))
for color, i, target_name in zip(['navy', 'turquoise', 'darkorange'], [0, 1, 2], data.target_names):
plt.scatter(X_pca[y == i, 0], X_pca[y == i, 1], color=color, alpha=.8, lw=2,
label=target_name)
plt.legend(loc='best', shadow=False, scatterpoints=1)
plt.title('PCA of IRIS dataset')
plt.xlabel(f'PC1 ({pca.explained_variance_ratio_[0]*100:.2f}%)')
plt.ylabel(f'PC2 ({pca.explained_variance_ratio_[1]*100:.2f}%)')
plt.show()
# 解释方差
print("解释方差比例:", pca.explained_variance_ratio_)
print("累计解释方差:", np.cumsum(pca.explained_variance_ratio_))2. 手动实现PCA
def manual_pca(X, n_components=2):
# 标准化
X_std = (X - np.mean(X, axis=0)) / np.std(X, axis=0)
# 协方差矩阵
cov_mat = np.cov(X_std.T)
# 特征值分解
eig_vals, eig_vecs = np.linalg.eig(cov_mat)
# 排序
idx = eig_vals.argsort()[::-1]
eig_vals = eig_vals[idx]
eig_vecs = eig_vecs[:, idx]
# 选择主成分
components = eig_vecs[:, :n_components]
X_pca = X_std.dot(components)
# 解释方差
explained_var = eig_vals[:n_components] / eig_vals.sum()
return X_pca, explained_var, components
# 使用手动PCA
X_manual, explained_var, _ = manual_pca(X)
print("手动PCA解释方差:", explained_var)3. 主成分数量选择
# 绘制碎石图确定最佳主成分数量
pca_full = PCA().fit(X_scaled)
plt.figure(figsize=(8, 4))
plt.plot(range(1, len(pca_full.explained_variance_ratio_)+1),
np.cumsum(pca_full.explained_variance_ratio_),
'b-o')
plt.xlabel('Number of Components')
plt.ylabel('Cumulative Explained Variance')
plt.axhline(y=0.95, color='r', linestyle='--')
plt.title('Scree Plot for Determining Optimal Number of Components')
plt.grid()
plt.show()运行截图
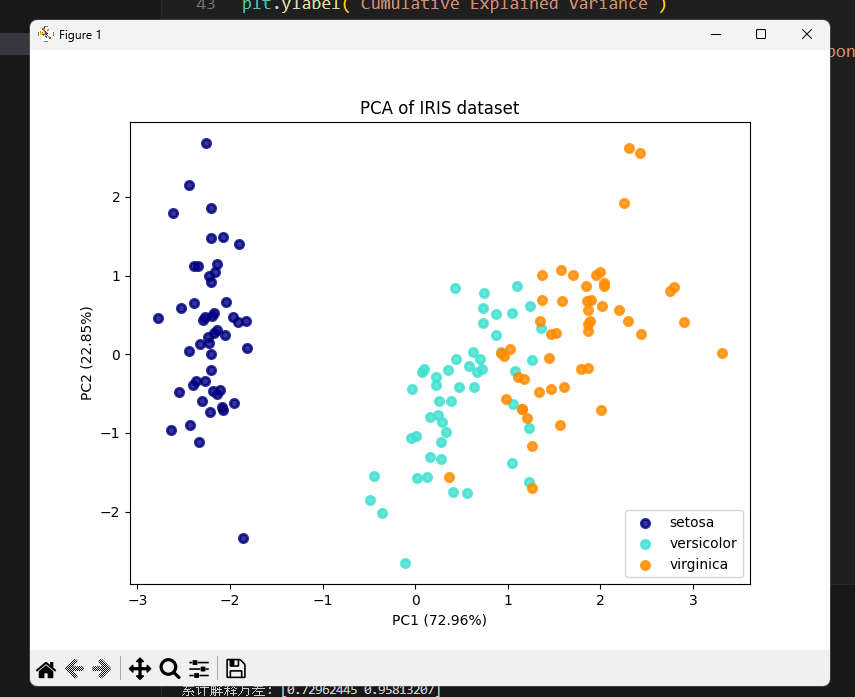
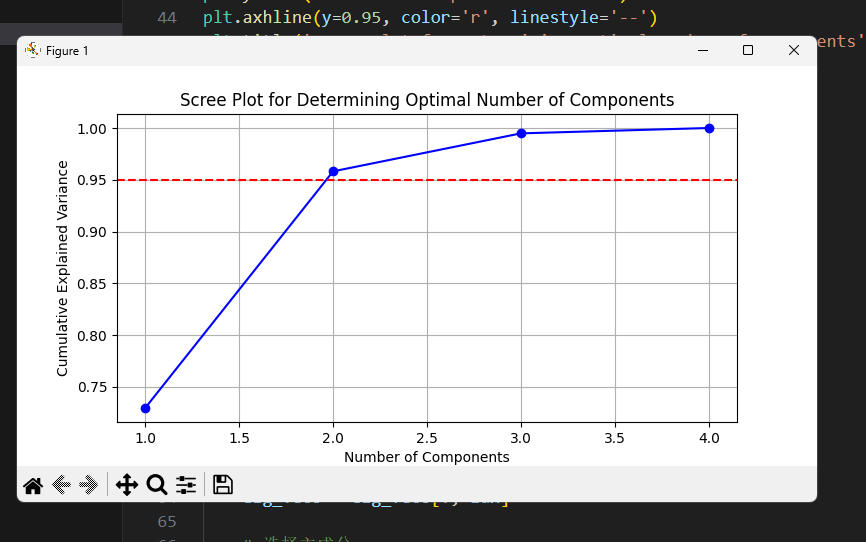
应用建议
-
预处理步骤:在应用PCA前务必进行数据标准化
-
主成分选择:通常选择累计解释方差达到95%的主成分数量
-
结果验证:降维后应检查主成分是否保留了关键信息
-
非线性替代:对于非线性数据,考虑使用t-SNE或UMAP等非线性降维方法
-
领域知识:结合领域知识解释主成分的物理意义
结论
PCA作为一种经典且强大的降维技术,在数据预处理和特征工程中扮演着重要角色。通过本文的理论讲解和Python实现,读者可以掌握PCA的核心原理和实际应用方法。然而,PCA并非适用于所有场景,理解其优缺点有助于在实际问题中做出合理选择。对于更复杂的数据结构,可以考虑核PCA或其他非线性降维方法作为补充。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 40
40 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)