自动机器学习框架-pycaret使用指南(包含如何使用shap)
PyCaret 是一款强大的自动机器学习工具包,它将数据预处理、数据集划分、模型训练、调参、模型性能验证以及可视化等一系列复杂操作集成于简单易用的命令之中,极大地降低了机器学习的入门门槛,即使是初学者也能轻松上手并高效地完成模型训练。此外,PyCaret 还支持诸如堆叠(stacking)和提升(boosting)等高级操作,用户可以通过查阅官方文档深入学习更多功能。PyCaret 根据不同的任务
PyCaret 是一款强大的自动机器学习工具包,它将数据预处理、数据集划分、模型训练、调参、模型性能验证以及可视化等一系列复杂操作集成于简单易用的命令之中,极大地降低了机器学习的入门门槛,即使是初学者也能轻松上手并高效地完成模型训练。此外,PyCaret 还支持诸如堆叠(stacking)和提升(boosting)等高级操作,用户可以通过查阅官方文档深入学习更多功能。
PyCaret 根据不同的任务类型,可划分为以下几大模块:(1)分类任务(例如预测生存与否、并发症发生与否等);(2)回归任务;(3)聚类任务;(4)时序预测任务。
以下内容展示 如何使用PyCaret训练一个二分类模型
其中,分类模块涵盖如下模型: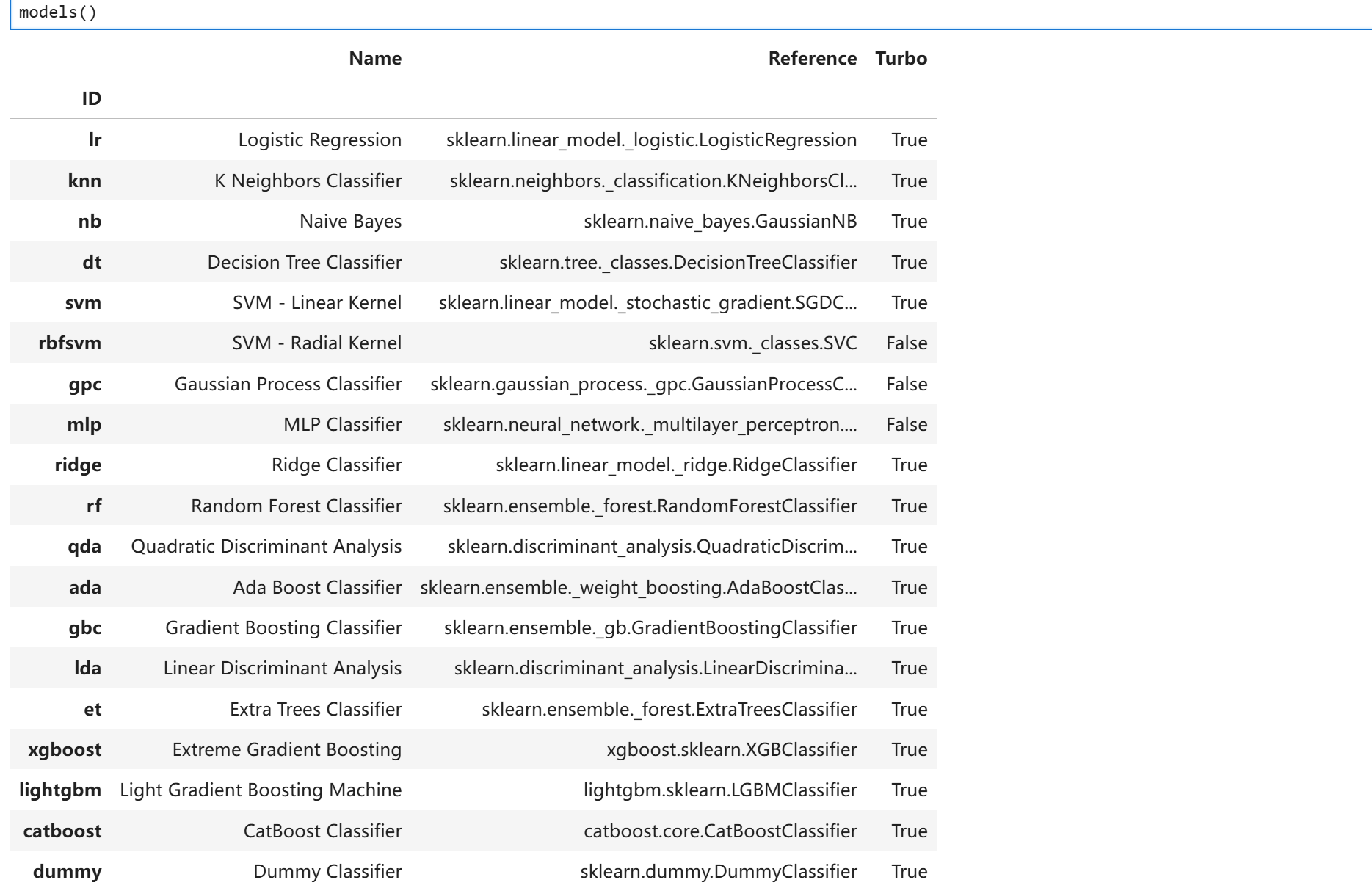
1. 环境准备
# 下述基于conda环境,Python 3.6或更高版本
pip install pycaret[full]
conda install -c conda-forge shap / pip install shap
2. 准备
2.1 包、函数导入
import pandas as pd
import numpy as np
import os
from collections import Counter
#os.environ['RAY_memory_monitor_refresh_ms'] = "0"
os.environ['RAY_memory_usage_threshold'] = "0.99"
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import shap
shap.initjs()
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
import sys
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix, roc_auc_score
def get_metrics(df, savefile):
with open(savefile, "w") as file:
y_pred = df['prediction_label']
y_true = df['label']
y_pred_proba = df['prediction_score_1']
# 计算准确率
accuracy = accuracy_score(y_true, y_pred)
print(f"Accuracy: {accuracy:.4f}", file=file)
print(f"Accuracy: {accuracy:.4f}")
# 计算精确率、召回率和 F1 分数
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
print(f"Precision: {precision:.4f}", file=file)
print(f"Precision: {precision:.4f}")
print(f"Recall: {recall:.4f}", file=file)
print(f"Recall: {recall:.4f}")
print(f"F1 Score: {f1:.4f}", file=file)
print(f"F1 Score: {f1:.4f}")
# 计算 ROC AUC 分数
roc_auc = roc_auc_score(y_true, y_pred_proba)
print(f"ROC AUC Score: {roc_auc:.4f}", file=file)
print(f"ROC AUC Score: {roc_auc:.4f}")
# 计算混淆矩阵
conf_matrix = confusion_matrix(y_true, y_pred)
print("Confusion Matrix:", file=file)
print(conf_matrix, file=file)
print("Confusion Matrix:")
print(conf_matrix)
2.2 输入数据准备
# 数据准备略过,下文出现的df_train为训练集(pycarts会自动划分df_train为训练集和验证集进行交叉验证),df_test为测试集用于最终模型性能测试。
2.3 输出结果文件夹准备
filein_name ="项目名称"
save_path = './Result_' + filein_name + '_s73_try1/' # raw_dataset
paths = [save_path + "/input/", save_path + "/result/", save_path + "/models/"]
for path in paths:
if not os.path.exists(path):
os.makedirs(path)
3. 模型训练-初级版(方便理解)
3.1 初始化建模环境并准备数据以供模型训练和评估使用
from pycaret.regression import *
from pycaret.classification import *
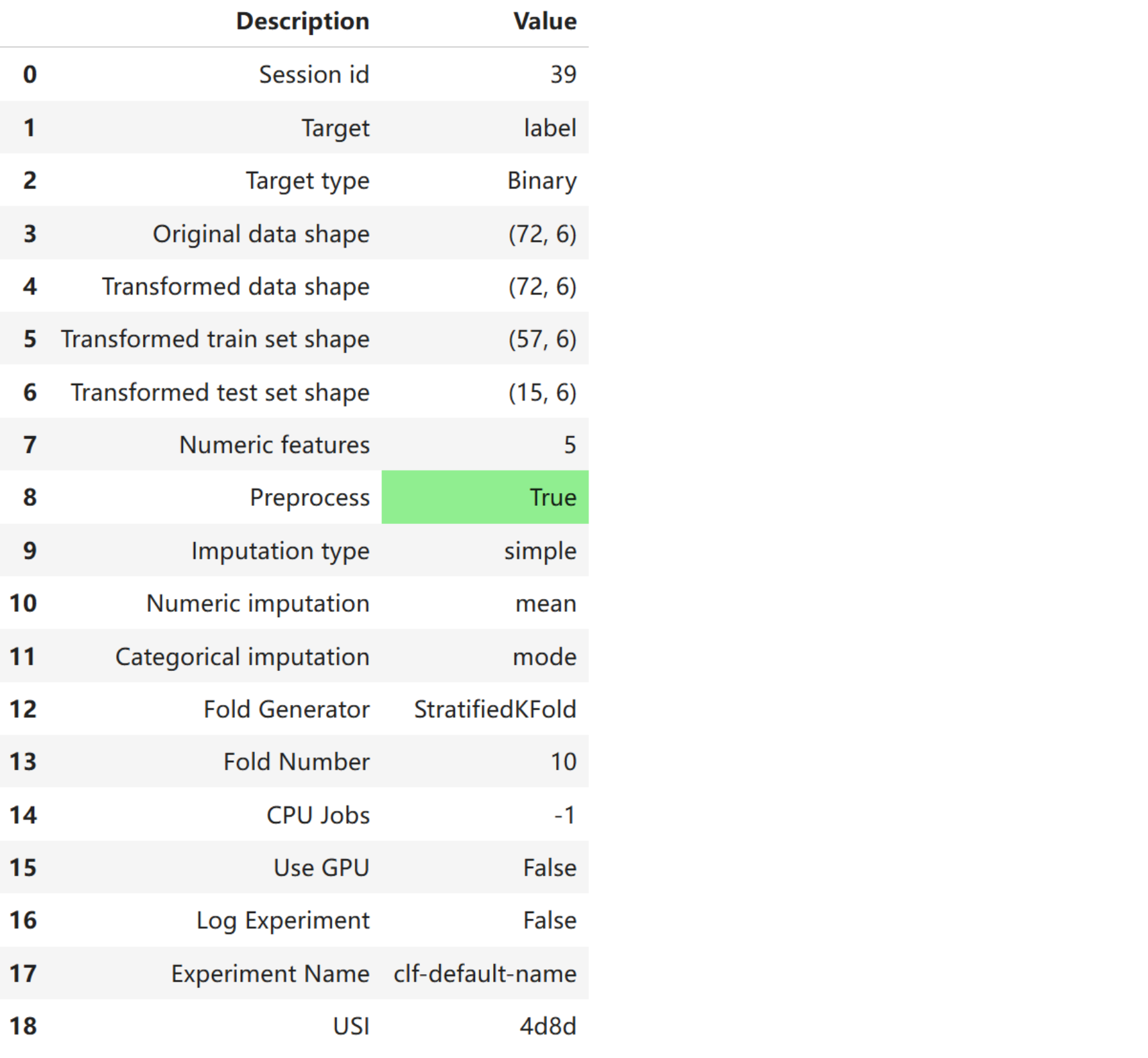
s = setup(df_train, target = 'label', session_id = 39, train_size = 0.7)
## 参数说明:
# normalize = True, normalize_method = 'minmax'
# K折叠交叉验证默认设置为10
# train_size默认7:3将输入数据划分为训练集和验证集
# session_id随机种子
## 查看基于setup函数创建的变量
# s.get_config()
# s.get_config('X_train_transformed')
PyCaret自动划分数据,并推断出所有特征的数据类型。
3.2 交叉验证找出默认参数下的最佳模型
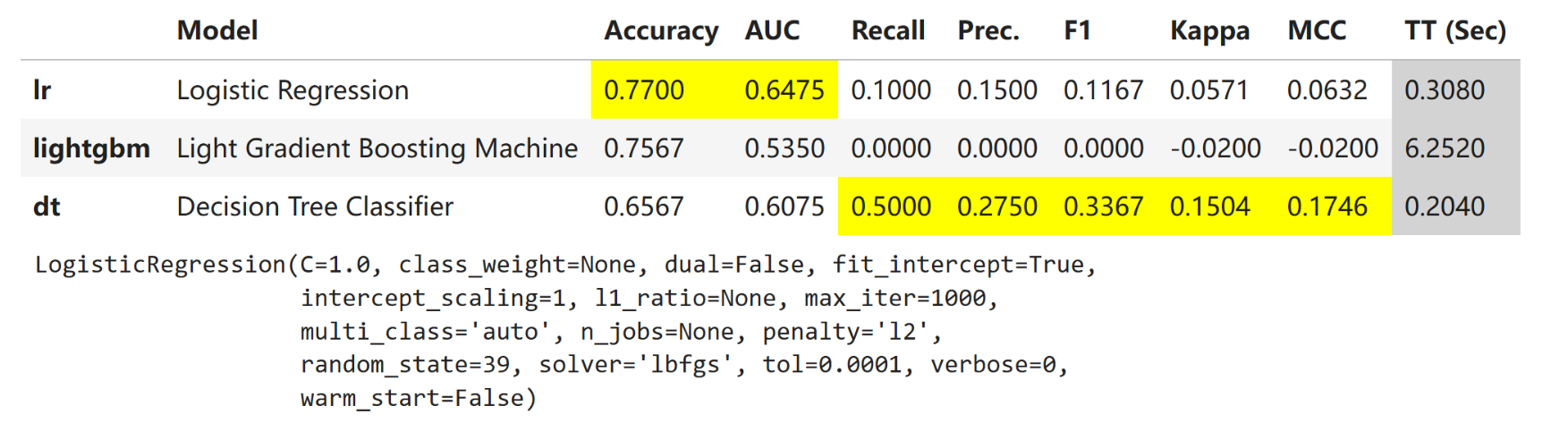
model_comp = s.compare_models()
## 参数说明:
# 最佳模型选择默认为Accuracy,可以通过sort = 'F1'调整指标选择最佳模型
# 可以选择部分感兴趣的模型进行比较,如:include = ['lr', 'rf', 'lightgbm']
# 是否使用交叉验证 cross_validation=False, 默认为True,交叉折数调整:fold = 5
# 按照召回率返回n_select性能最佳的模型 s.compare_models(sort = 'Recall', n_select = 3)
# compare_models()分数网格中打印的指标是所有折的平均分数
print(model_comp)
提取所有模型预测结果并进行保存
# 提取所有模型预测结果
multi_model_comp_results = s.pull()
outfile = save_path + "/result/multi_model_comp.csv"
multi_model_comp_results.to_csv(outfile,index=False)
multi_model_comp_results

3.3 基线模型调参寻找最佳模型
# 基于上述compare_models()选择默认参数下的最佳模型后,可通过下续命令进一步调参以提升模型性能
# 构建模型,单一模型默认展示所有折数的训练结果。
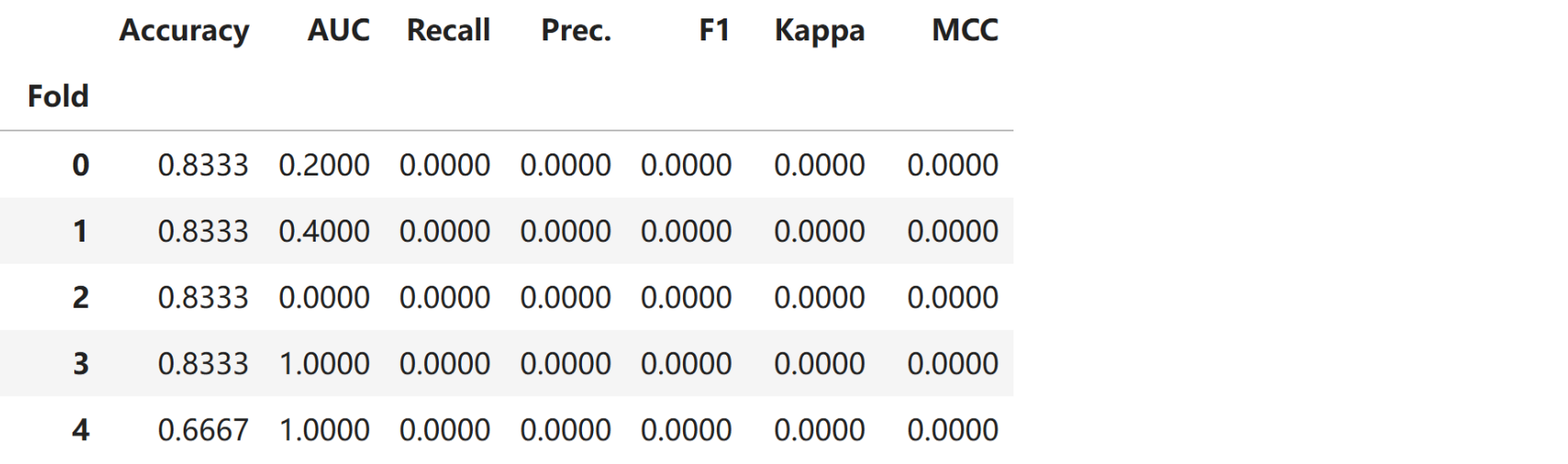
fold_best_model = create_model('lr')
print(fold_best_model)
# tune_model()函数使用预定义搜索空间中的随机网格搜索自动调整模型的超参数。
tuned_model = tune_model(fold_best_model,optimize='Accuracy')
print(tuned_model)
## 参数说明
# 默认调参优化精度,optimize='AUC'可设置为AUC
## 保存交叉验证结果
fold_results = s.pull()
outfile = save_path + "/result/best_model_fold_metric.csv"
fold_results.to_csv(outfile,index=False)
可通过print(model_comp) 和print(tuned_model)比较超参数的变化
# finalize_model()函数使模型拟合完整的数据集,即基于选择的最佳模型和调整后的超参数,在整个数据集上进行重新训练,也就是包括了最初的 70% 训练集 和 30% 测试集。
final_model = finalize_model(tuned_model)
final_model
4 模型训练-高级版-集成学习
-
ensemble_model(): 同质集成 (Homogeneous) 同一类型的多个模型 (e.g., 10个决策树) 使用 Bagging 或 Boosting 技术。
- ensemble_model() 是一个用来提升单个模型性能的强大工具。它通过 Bagging(并行训练,降低方差)或 Boosting(串行训练,降低偏差)来实现。
- Bagging 适合用于降低复杂模型(如决策树)的过拟合风险。
- Boosting 通常能带来更高的精度提升,但可能对噪声更敏感。
-
blend_models(): 异质集成 (Heterogeneous) 不同类型的模型 (e.g., 逻辑回归+SVM+KNN) 简单聚合:对所有模型的预测结果进行(软)投票或平均。
-
stack_models(): 异质集成 (Heterogeneous) 不同类型的模型 (e.g., 逻辑回归+SVM+KNN) 复杂聚合:训练一个元模型 (Meta Model) 来学习如何最好地结合基模型的预测结果。
s = setup(df_train, target = 'label', session_id = 39, train_size = 0.8)
crit = "AUC"
topN = compare_models(n_select=5,sort=crit)
# 循环为前N的模型进行超参数调优
tuned_topN = [tune_model(i, optimize=crit) for i in topN]
# 使用Bagging方法(默认)来创建集成模型,创建n_estimators个基学习器,在训练数据的不同子集上分别训练它们,最后将它们的预测结果进行平均(投票)。choose_better指在ensemble后的模型和tuned的模型中选择性能更优的进行保存。
ensem_topN = [ensemble_model(i, n_estimators = 10, optimize=crit, choose_better=True) for i in tuned_topN] # method='Bagging'(默认), method='Boosting'
# 创建一个“投票分类器”(Voting Classifier)。在预测时,它会综合所有前N个模型的预测概率,然后做出最终决策。
blend = blend_models(tuned_topN, optimize=crit)
# 创建一个“投票分类器”(Voting Classifier)。在预测时,它会综合所有ensemble后前N个模型的预测概率,然后做出最终决策。
blend_ensem = blend_models(ensem_topN, optimize=crit)
# 从到目前为止创建的所有模型中,基于 crit (AUC) 的交叉验证分数自动选出最终的冠军。,然后返回那个分数最高的模型。
auto_best_model = automl(optimize=crit)
final_model = finalize_model(auto_best_model)
final_model
5. 模型及结果保存及可视化
5.1 模型保存
# 保存模型到本地
outfile = save_path + '/models/best_model'
_ = s.save_model(best, outfile, verbose = False)
# # 导入模型
# model = s.load_model(outfile)
# # 查看模型结构
# model
5.2 可视化图形保存
交互式展示
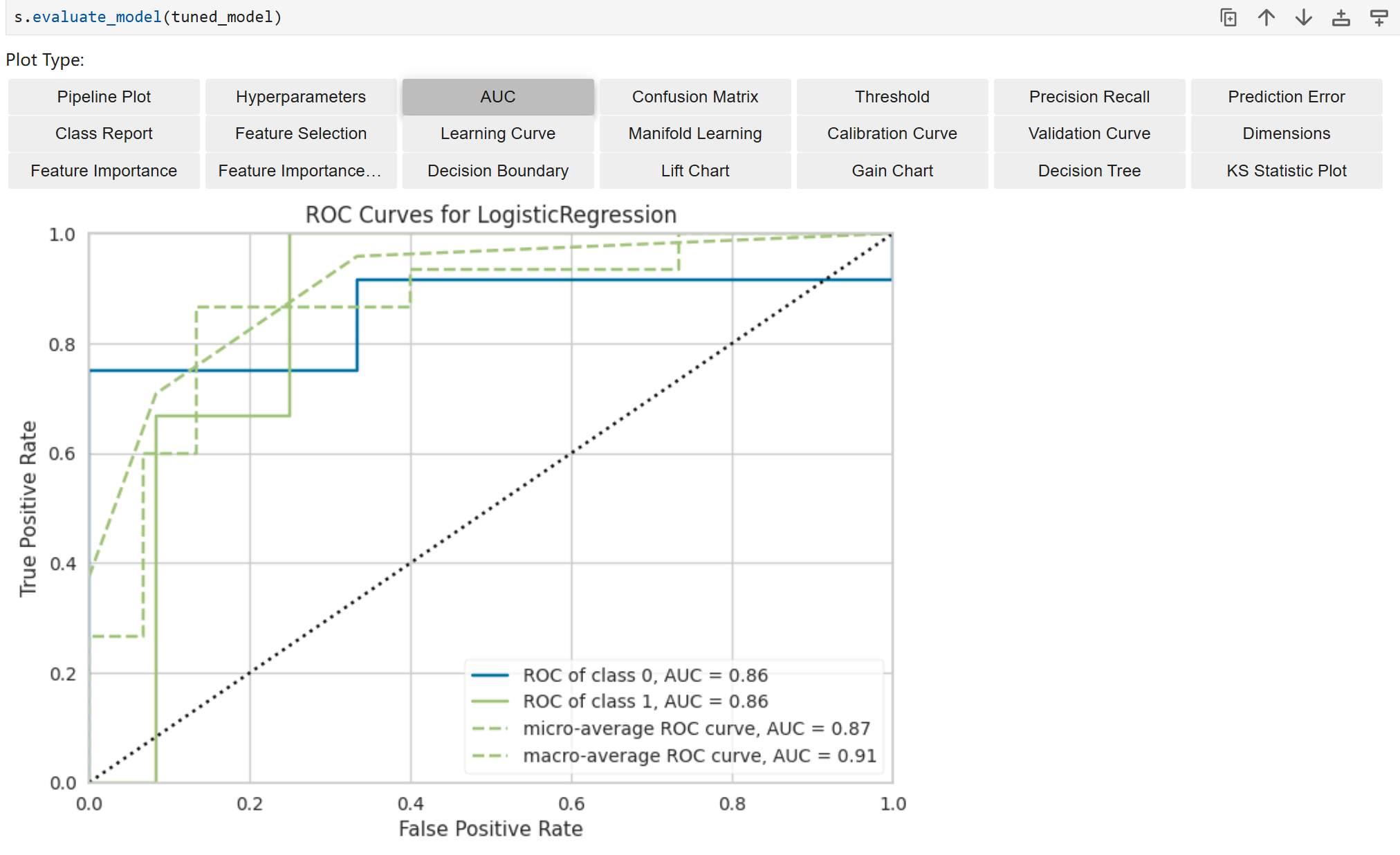
# evaluate_model 函数默认是通过 30% 验证集来生成相关图表的。由于 final_model 在finalize_model()时已经用这 30% 的验证集进行过训练,所以 evaluate_model(final_model) 实际上是在用模型已经见过的数据来评估模型,AUC等指标会虚高。因此,用于报告模型最终性能的 AUC等指标,应该来自 predict_model(final_model) 的输出,而不是 evaluate_model(final_model),可通过evaluate_model(tuned_model)进行模型性能的快速评估。
s.evaluate_model(tuned_model) # 或auto_best_model
单图保存
plot_model(final_model, plot = 'confusion_matrix')
plot_model(final_model, plot = 'auc')
plot_model(final_model, plot = 'pr')
plot_model(final_model, plot='feature')
5.3 训练集结果保存(保存prob_1, prob_0和pred_label)
# 查看模型在训练+验证集上的整体结果
# 如果测试集和训练集的结果之间存在较大差异,这通常表示可能过拟合
res_train = predict_model(final_model, raw_score = True,data=df_train)
outfile = save_path + "/result/trainset_model_prob.csv"
res_train.to_csv(outfile,index=False)
res_train
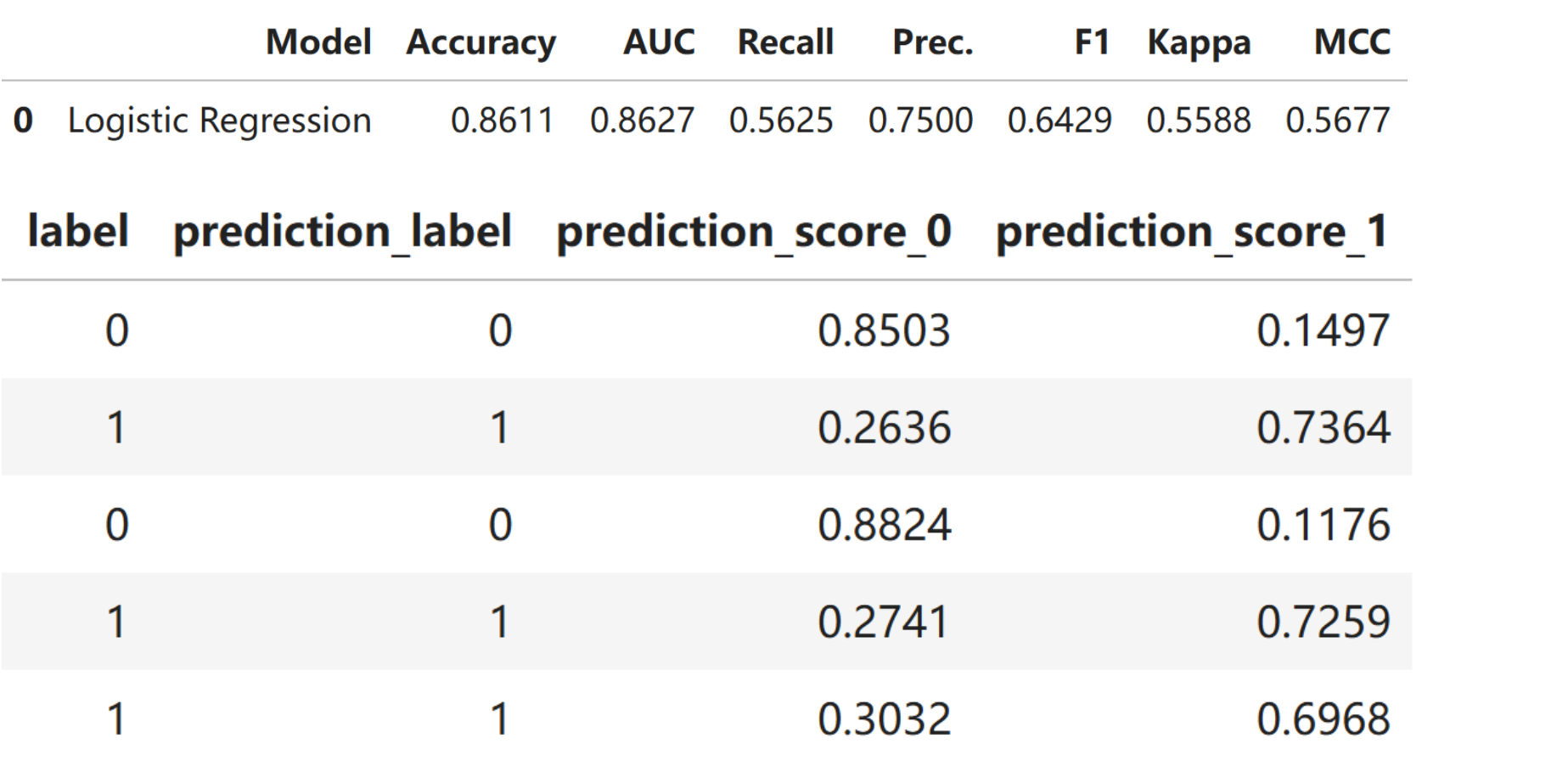
savefile = save_path + "/result/trainset_model_metrics.txt"
get_metrics(res_train,savefile)

5.4 测试集结果保存(保存prob_1, prob_0和pred_label)
res_test = predict_model(final_model, raw_score = True, data=df_test)
outfile = save_path + "/result/testset_model_prob.csv"
res_test.to_csv(outfile,index=False)
res_test
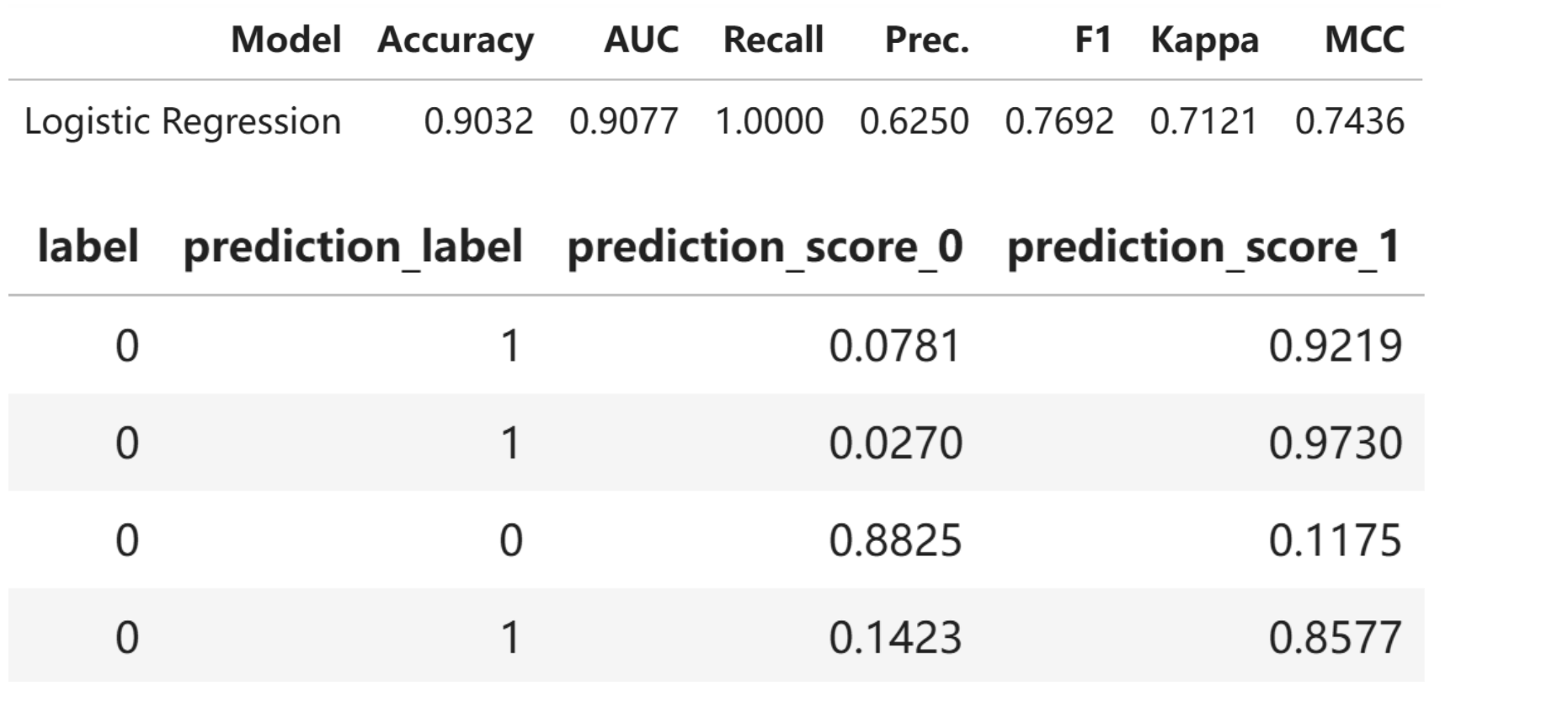
savefile = save_path + "/result/testset_model_metrics.txt"
get_metrics(res_test,savefile)

6. Pycarts采用shap进行解释
best_model = save_path + '/models/best_model'
best_model = load_model(best_model)
print(best_model)
model_estimator = best_model.named_steps['actual_estimator']
X_train_transformed = get_config('X_train_transformed')
X_test_transformed = get_config('X_test_transformed')
explainer = shap.TreeExplainer(model_estimator)
shap_values = explainer.shap_values(X_test_transformed)
# 对于分类问题,shap_values 是一个列表,包含每个类别的 SHAP 值
# shap_values[0] -> 类别0 (e.g., 'Not Purchase')
# shap_values[1] -> 类别1 (e.g., 'Purchase')
print(f"SHAP values 是一个列表,长度为: {len(shap_values)}")
print(f"针对类别1的 SHAP 值数组形状: {shap_values[1].shape}")
# 检查 expected_value 的结构 (分类问题中通常也是一个列表)
print(f"Expected values: {explainer.expected_value}")
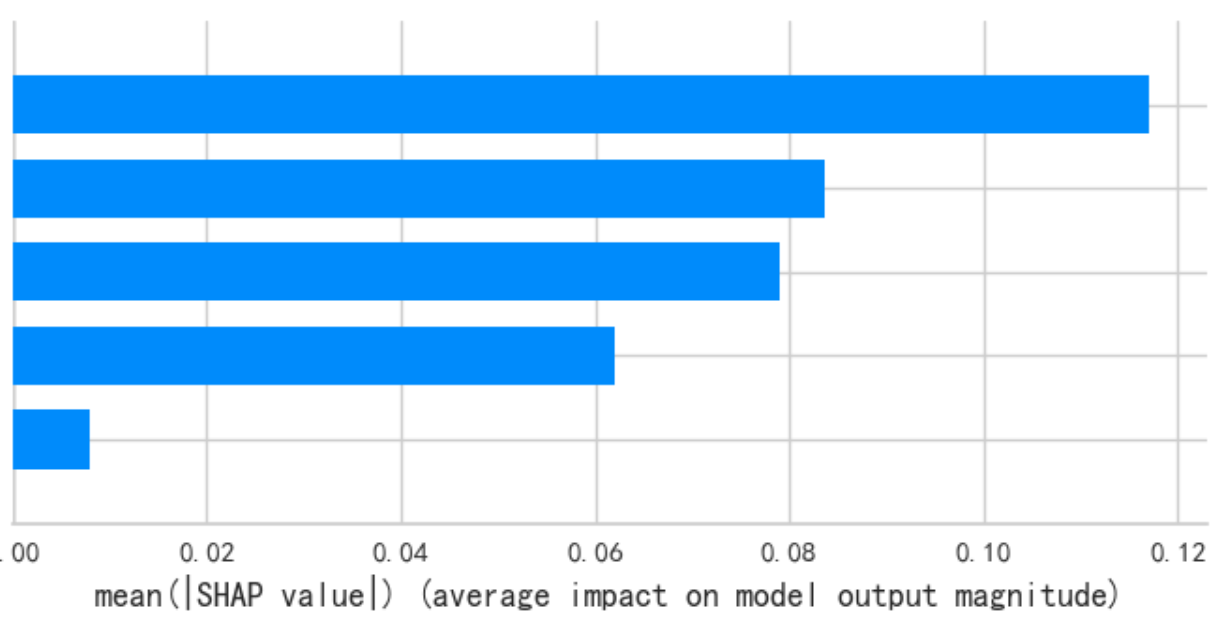
6.1 条形图
# 解释对 "类别1" 的预测
class_index = 1
# 条形图,显示平均绝对影响
print("--- 条形图 ---")
shap.summary_plot(shap_values[class_index], X_test_transformed, plot_type="bar")
6.2 点图 v1
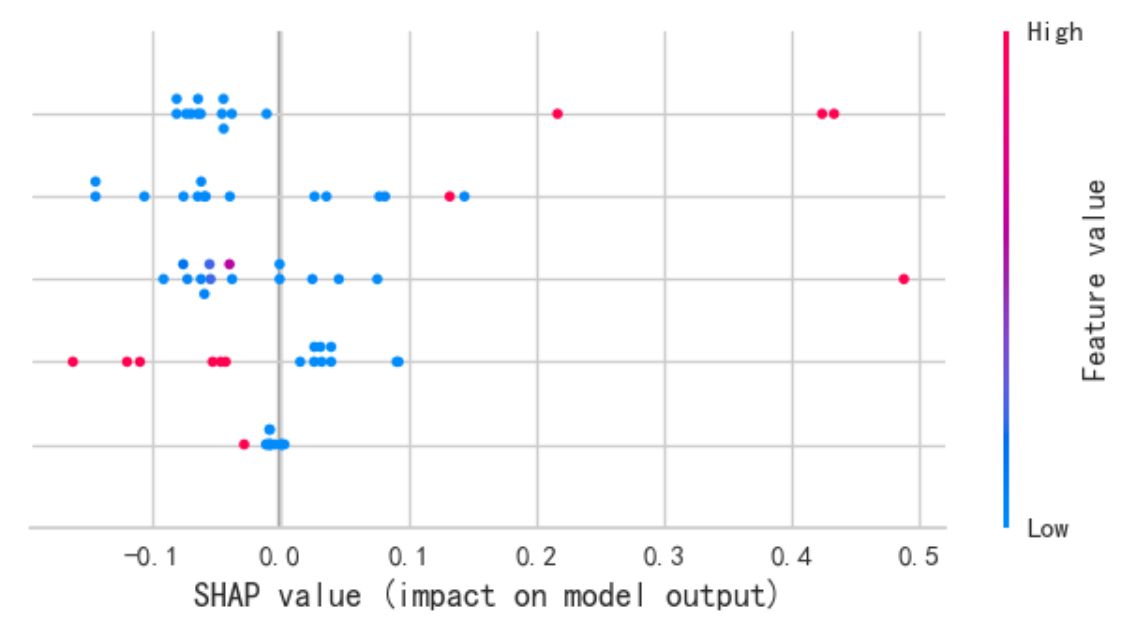
# 点图 每一行代表一个特征,每个点代表一个样本。X轴是SHAP值(正值推高预测,负值拉低预测)。颜色代表特征值本身的大小(红色为高,蓝色为低)。
print("--- 点图 ---")
shap.summary_plot(shap_values[class_index], X_test_transformed, plot_type="dot")
6.2 点图 v2
interpret_model(model_estimator) # shap 特征重要性分析
6.3 力图
# 选择一个样本来解释,例如测试集中的第5个样本
idx = 5
print(f"--- 解释样本 {idx} 的力图 ---")
shap.force_plot(
explainer.expected_value[class_index], # 类别1的基准值
shap_values[class_index][idx,:], # 类别1中样本idx的SHAP值
X_test_transformed.iloc[idx,:] # 样本idx的特征值
)

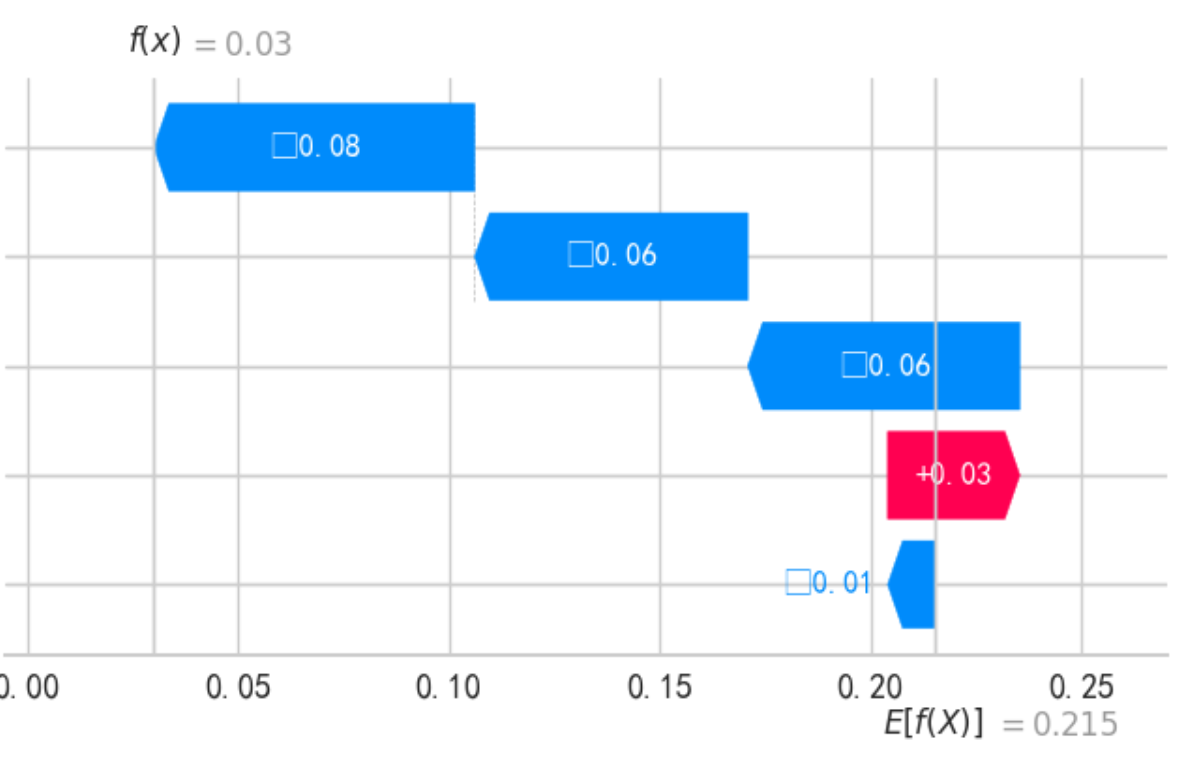
6.4 瀑布图
print(f"--- 解释样本 {idx} 的瀑布图 ---")
shap.waterfall_plot(
shap.Explanation(
values=shap_values[class_index][idx,:],
base_values=explainer.expected_value[class_index],
data=X_test_transformed.iloc[idx,:],
feature_names=X_test_transformed.columns.tolist()
)
)
7. 参考链接
https://zhuanlan.zhihu.com/p/345281527
https://www.cnblogs.com/luohenyueji/p/18225558
https://astrobenhart.medium.com/how-to-use-shap-with-pycaret-dc9a31278621

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)