Parallel is All You Want:通过并行化 CNN 和 Transformer 编码器来组合语音情感的空间和时间特征表示
在本笔记本中,我将以我的 Intro to Speech Audio Classification 存储库为基础,并使用 Transformer 编码器网络并行构建两个并行卷积神经网络 (CNN) 来对音频数据进行分类。我们正在研究 RAVDESS 数据集,以对 8 类之一的情绪进行分类。我们将 CNN 用于空间特征表示,将 Transformer 用于时间特征表示。我们通过增加数据集的变化来减少
Parallel is All You Want:通过并行化 CNN 和 Transformer 编码器来组合语音情感的空间和时间特征表示
抽象
在本笔记本中,我将以我的 Intro to Speech Audio Classification 存储库为基础,并使用 Transformer 编码器网络并行构建两个并行卷积神经网络 (CNN) 来对音频数据进行分类。我们正在研究 RAVDESS 数据集,以对 8 类之一的情绪进行分类。我们将 CNN 用于空间特征表示,将 Transformer 用于时间特征表示。我们通过增加数据集的变化来减少过度拟合,从而增强训练数据;我们使用加性高斯白噪声 (AWGN) 将 RAVDESS 数据集增强三倍,总共有 4320 个音频样本。
我们通过将 MFCC 图视为灰度图像来利用 CNN 的图像分类和空间特征表示功能;它们的 width 是一个时间尺度,它们的 height 是一个频率尺度。MFCC 中每个像素的值是某个时间步长中特定 mel 频率范围内的音频信号强度。
由于数据的连续性,我们还将使用 Transformer 来尝试尽可能准确地模拟情绪中音高转换之间的时间关系。
此笔记本的灵感来自深度学习和网络架构方面的各种最新进展;特别是,堆叠和并行 CNN 网络与 Transformer 编码器的多头自注意力层相结合。我假设 CNN 滤波器通道维度的扩展和特征图的减少将以最低的计算成本提供最具表现力的特征表示,而 Transformer-Encoder 则与假设网络将学习根据 MFCC 图的全局结构预测不同情绪的频率分布(间接地, mel 频谱图)的凭借 CNN 在空间特征表示方面的优势和 Transformer 在序列编码方面的优势,我设法在 RAVDESS 数据集的维持测试集上实现了 80.44% 的准确率。
目录
附录
介绍
来自我之前的笔记本:“长短期记忆循环神经网络 (LSTM RNN) 和卷积神经网络 (CNN) 是音频数据分类的优秀 DNN 候选者:LSTM RNN 因为它们具有出色的解释顺序数据的能力,例如表示为时间序列的音频波形的特征;CNN,因为基于音频数据设计的特征(例如频谱图)与图像明显相似,而图像 CNN 擅长识别和区分不同的模式。
我将在此基础上再接再厉 - CNN 仍然是当今图像分类的标志,尽管即使在这个领域,Transformer 也开始占据主要舞台:2021 年 ICLR 提交的文件:一张图像值得 16x16 个字:用于大规模图像识别的 Transformer 声称他们已经实现了一种用于图像分类的 Transformer,其性能优于最先进的 CNN, 并且计算复杂度要低得多。
除了从上述内容中汲取灵感外,现在也不再是 2015 年——所以我将实现它的继任者 Transformer 模型,而不是 CNN,以尝试在 RAVDESS 数据集上获得最先进的性能。
此模型架构的其他动机来自过去几年的各种论文。最显著的灵感来源是:
](https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf)用于通过更深的 CNN 网络增加特征图的复杂性,以及通过向自身添加修改后的训练数据版本来增强数据
- VGGNet:用于大规模图像识别的甚深度卷积网络,用于在整个堆叠 CNN 层中使用固定大小的内核
- LeNet:基于梯度的学习应用于 convolution>pool>convolution>pool 范式的文档识别
- Self-Attention: Long Short-Term Memory-Networks for Machine Reading(用于机器读取的长短期记忆网络),用于理解 Transformer 架构
- Dropout 正则化:[Dropout: A Simple Method to Prevent Neural Networks
Overfitting](https://www.cs.toronto.edu/~hinton/absps/JMLRdropout.pdf) 不言自明
- Batch Norm: Batch Normalization: 通过减少内部协变量偏移来加速深度网络训练
让我们开始吧。
设置
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import os, glob
import librosa
import librosa.display
import IPython
from IPython.display import Audio
from IPython.display import Image
import warnings; warnings.filterwarnings('ignore') #matplot lib complains about librosa
#google colab has an old version of librosa with missing mel spectrogram args (for MFCC); upgrade to current
!pip install -U librosa
# needed to import dataset from google drive into colab
from google.colab import drive
drive.mount("/content/gdrive")
Mounted at /content/gdrive
# copy RAVDESS dataset from gdrive and unzip
!cp '/content/gdrive/My Drive/DL/RAVDESS.zip' .
!unzip -q RAVDESS.zip
定义功能
从我的 'sklearn-audio-classification' 存储库中定义此任务的上一个笔记本中的功能。该笔记本解释了 Mel Spectrogram 及其衍生 MFCC 背后的动机,我们将其用作一个功能。简而言之,我们正在寻找可听音高频率的过渡。
在考虑训练注意事项的情况下,仅 MFCC 在此模型中提供了最佳准确性,并且提供与使用色度图 + mel 频谱图 + MFCC 一样好的准确性。我们不希望在像这样的高度参数化的深度神经网络中增加额外的复杂性(除非我们绝对需要它)。
# RAVDESS native sample rate is 48k
sample_rate = 48000
# Mel Spectrograms are not directly used as a feature in this model
# Mel Spectrograms are used in calculating MFCCs, which are a higher-level representation of pitch transition
# MFCCs work better - left the mel spectrogram function here in case anyone wants to experiment
def feature_melspectrogram(
waveform,
sample_rate,
fft = 1024,
winlen = 512,
window='hamming',
hop=256,
mels=128,
):
# Produce the mel spectrogram for all STFT frames and get the mean of each column of the resulting matrix to create a feature array
# Using 8khz as upper frequency bound should be enough for most speech classification tasks
melspectrogram = librosa.feature.melspectrogram(
y=waveform,
sr=sample_rate,
n_fft=fft,
win_length=winlen,
window=window,
hop_length=hop,
n_mels=mels,
fmax=sample_rate/2)
# convert from power (amplitude**2) to decibels
# necessary for network to learn - doesn't converge with raw power spectrograms
melspectrogram = librosa.power_to_db(melspectrogram, ref=np.max)
return melspectrogram
def feature_mfcc(
waveform,
sample_rate,
n_mfcc = 40,
fft = 1024,
winlen = 512,
window='hamming',
#hop=256, # increases # of time steps; was not helpful
mels=128
):
# Compute the MFCCs for all STFT frames
# 40 mel filterbanks (n_mfcc) = 40 coefficients
mfc_coefficients=librosa.feature.mfcc(
y=waveform,
sr=sample_rate,
n_mfcc=n_mfcc,
n_fft=fft,
win_length=winlen,
window=window,
#hop_length=hop,
n_mels=mels,
fmax=sample_rate/2
)
return mfc_coefficients
def get_features(waveforms, features, samplerate):
# initialize counter to track progress
file_count = 0
# process each waveform individually to get its MFCCs
for waveform in waveforms:
mfccs = feature_mfcc(waveform, sample_rate)
features.append(mfccs)
file_count += 1
# print progress
print('\r'+f' Processed {file_count}/{len(waveforms)} waveforms',end='')
# return all features from list of waveforms
return features
def get_waveforms(file):
# load an individual sample audio file
# read the full 3 seconds of the file, cut off the first 0.5s of silence; native sample rate = 48k
# don't need to store the sample rate that librosa.load returns
waveform, _ = librosa.load(file, duration=3, offset=0.5, sr=sample_rate)
# make sure waveform vectors are homogenous by defining explicitly
waveform_homo = np.zeros((int(sample_rate*3,)))
waveform_homo[:len(waveform)] = waveform
# return a single file's waveform
return waveform_homo
# RAVDESS dataset emotions
# shift emotions left to be 0 indexed for PyTorch
emotions_dict ={
'0':'surprised',
'1':'neutral',
'2':'calm',
'3':'happy',
'4':'sad',
'5':'angry',
'6':'fearful',
'7':'disgust'
}
# Additional attributes from RAVDESS to play with
emotion_attributes = {
'01': 'normal',
'02': 'strong'
}
加载数据并提取特征
我们处理数据集中的每个文件并提取其特征。
我们返回波形和标签(来自 RAVDESS 音频样本的文件名)。我们返回原始波形,因为我们要做一些额外的处理。
# path to data for glob
data_path = 'RAVDESS dataset/Actor_*/*.wav'
def load_data():
# features and labels
emotions = []
# raw waveforms to augment later
waveforms = []
# extra labels
intensities, genders = [],[]
# progress counter
file_count = 0
for file in glob.glob(data_path):
# get file name with labels
file_name = os.path.basename(file)
# get emotion label from the sample's file
emotion = int(file_name.split("-")[2])
# move surprise to 0 for cleaner behaviour with PyTorch/0-indexing
if emotion == 8: emotion = 0 # surprise is now at 0 index; other emotion indeces unchanged
# can convert emotion label to emotion string if desired, but
# training on number is better; better convert to emotion string after predictions are ready
# emotion = emotions_dict[str(emotion)]
# get other labels we might want
intensity = emotion_attributes[file_name.split("-")[3]]
# even actors are female, odd are male
if (int((file_name.split("-")[6]).split(".")[0]))%2==0:
gender = 'female'
else:
gender = 'male'
# get waveform from the sample
waveform = get_waveforms(file)
# store waveforms and labels
waveforms.append(waveform)
emotions.append(emotion)
intensities.append(intensity) # store intensity in case we wish to predict
genders.append(gender) # store gender in case we wish to predict
file_count += 1
# keep track of data loader's progress
print('\r'+f' Processed {file_count}/{1440} audio samples',end='')
return waveforms, emotions, intensities, genders
# load data
# init explicitly to prevent data leakage from past sessions, since load_data() appends
waveforms, emotions, intensities, genders = [],[],[],[]
waveforms, emotions, intensities, genders = load_data()
Processed 1440/1440 audio samples
检查提取的音频波形和标签:
print(f'Waveforms set: {len(waveforms)} samples')
# we have 1440 waveforms but we need to know their length too; should be 3 sec * 48k = 144k
print(f'Waveform signal length: {len(waveforms[0])}')
print(f'Emotions set: {len(emotions)} sample labels')
Waveforms set: 1440 samples
Waveform signal length: 144000
Emotions set: 1440 sample labels
看起来不错。总共 1440 个样品和 1440 个标签。
波形长度为 144k,因为 3 秒 * 48k 采样率 = 144k 长度的数组,表示 3 秒的音频片段。
拆分为 Train/Validation/Test Sets
我们将使用 80/10/10 训练/验证/测试拆分来最大化训练数据并保持合理的验证/测试集。
我们正在拆分波形,以便我们可以单独处理训练/验证/测试波形,并避免数据泄漏。
必须注意根据情感按比例分配集合。
是的,我们可以使用 sklearn - 但为了说服自己我已经根除了数据泄漏问题,我手动完成了此作。
# create storage for train, validation, test sets and their indices
train_set,valid_set,test_set = [],[],[]
X_train,X_valid,X_test = [],[],[]
y_train,y_valid,y_test = [],[],[]
# convert waveforms to array for processing
waveforms = np.array(waveforms)
# process each emotion separately to make sure we builf balanced train/valid/test sets
for emotion_num in range(len(emotions_dict)):
# find all indices of a single unique emotion
emotion_indices = [index for index, emotion in enumerate(emotions) if emotion==emotion_num]
# seed for reproducibility
np.random.seed(69)
# shuffle indicies
emotion_indices = np.random.permutation(emotion_indices)
# store dim (length) of the emotion list to make indices
dim = len(emotion_indices)
# store indices of training, validation and test sets in 80/10/10 proportion
# train set is first 80%
train_indices = emotion_indices[:int(0.8*dim)]
# validation set is next 10% (between 80% and 90%)
valid_indices = emotion_indices[int(0.8*dim):int(0.9*dim)]
# test set is last 10% (between 90% - end/100%)
test_indices = emotion_indices[int(0.9*dim):]
# create train waveforms/labels sets
X_train.append(waveforms[train_indices,:])
y_train.append(np.array([emotion_num]*len(train_indices),dtype=np.int32))
# create validation waveforms/labels sets
X_valid.append(waveforms[valid_indices,:])
y_valid.append(np.array([emotion_num]*len(valid_indices),dtype=np.int32))
# create test waveforms/labels sets
X_test.append(waveforms[test_indices,:])
y_test.append(np.array([emotion_num]*len(test_indices),dtype=np.int32))
# store indices for each emotion set to verify uniqueness between sets
train_set.append(train_indices)
valid_set.append(valid_indices)
test_set.append(test_indices)
# concatenate, in order, all waveforms back into one array
X_train = np.concatenate(X_train,axis=0)
X_valid = np.concatenate(X_valid,axis=0)
X_test = np.concatenate(X_test,axis=0)
# concatenate, in order, all emotions back into one array
y_train = np.concatenate(y_train,axis=0)
y_valid = np.concatenate(y_valid,axis=0)
y_test = np.concatenate(y_test,axis=0)
# combine and store indices for all emotions' train, validation, test sets to verify uniqueness of sets
train_set = np.concatenate(train_set,axis=0)
valid_set = np.concatenate(valid_set,axis=0)
test_set = np.concatenate(test_set,axis=0)
# check shape of each set
print(f'Training waveforms:{X_train.shape}, y_train:{y_train.shape}')
print(f'Validation waveforms:{X_valid.shape}, y_valid:{y_valid.shape}')
print(f'Test waveforms:{X_test.shape}, y_test:{y_test.shape}')
# make sure train, validation, test sets have no overlap/are unique
# get all unique indices across all sets and how many times each index appears (count)
uniques, count = np.unique(np.concatenate([train_set,test_set,valid_set],axis=0), return_counts=True)
# if each index appears just once, and we have 1440 such unique indices, then all sets are unique
if sum(count==1) == len(emotions):
print(f'\nSets are unique: {sum(count==1)} samples out of {len(emotions)} are unique')
else:
print(f'\nSets are NOT unique: {sum(count==1)} samples out of {len(emotions)} are unique')
Training waveforms:(1147, 144000), y_train:(1147,)
Validation waveforms:(143, 144000), y_valid:(143,)
Test waveforms:(150, 144000), y_test:(150,)
Sets are unique: 1440 samples out of 1440 are unique
提取特征
首先从未增强波形中提取特征。在下一步中,我们将 augmented waveforms 中的特征附加到这些 “native” 特征中。
# initialize feature arrays
# We extract MFCC features from waveforms and store in respective 'features' array
features_train, features_valid, features_test = [],[],[]
print('Train waveforms:') # get training set features
features_train = get_features(X_train, features_train, sample_rate)
print('\n\nValidation waveforms:') # get validation set features
features_valid = get_features(X_valid, features_valid, sample_rate)
print('\n\nTest waveforms:') # get test set features
features_test = get_features(X_test, features_test, sample_rate)
print(f'\n\nFeatures set: {len(features_train)+len(features_test)+len(features_valid)} total, {len(features_train)} train, {len(features_valid)} validation, {len(features_test)} test samples')
print(f'Features (MFC coefficient matrix) shape: {len(features_train[0])} mel frequency coefficients x {len(features_train[0][1])} time steps')
Train waveforms:
Processed 1147/1147 waveforms
Validation waveforms:
Processed 143/143 waveforms
Test waveforms:
Processed 150/150 waveforms
Features set: 1440 total, 1147 train, 143 validation, 150 test samples
Features (MFC coefficient matrix) shape: 40 mel frequency coefficients x 282 time steps
使用 AWGN 增强数据 - 加性高斯白噪声
赋予动机
由于我们的数据集很小,因此容易出现过拟合 - 尤其是对于高度参数化的深度神经网络模型 例如我们打算在此笔记本中构建的那个。因此,我们将需要增强我们的数据。生成更多真实样本将非常困难。相反,我们可以在音频信号中添加白噪声 - 不仅可以掩盖训练集中存在的随机噪声的影响 - 还可以创建伪新的训练样本并抵消数据集固有噪声的影响。
此外,RAVDESS 数据集非常干净 - 我们可能希望对嘈杂的真实数据进行预测 - 这是增强训练数据的另一个原因。
我们将使用加性高斯白噪声 (AWGN)。它是 Additive (加法),因为我们将其添加到源音频信号中,它是 Gaussian (高斯) 因为噪声矢量将从正态分布中采样,并且时间平均值为零 (零均值),而它是白色的,因为在白化变换后,噪声将在整个频率分布中均匀地为音频信号增加功率。
我们需要一个好的噪声平衡 - 太少将毫无用处,而太多会使网络难以从训练数据中学习。请注意,这只是为了训练 - 我们不需要将 AWGN 添加到我们进行预测的真实数据中(尽管我们可以)。
数学
AWGN 中的关键参数是信噪比 (SNR),它定义了相对于音频信号添加的噪声的大小。我们将 AWGN 参数化为最小值,并最大化 SNR,以便我们可以选择一个随机 SNR 来增强每个样本的波形。
我们需要约束协方差以使其成为真正的 AWGN。我们制作了一个高斯噪声 (np.random.normal) 的零均值向量,该向量在统计上是相关的。我们需要应用白化变换,这是一种线性变换,采用具有已知协方差矩阵的随机正态(高斯)变量向量,并将其映射到协方差是单位矩阵的新向量,即该向量现在与二角醇协方差矩阵完全不相关,每个噪声点都有方差 == stdev == 1。根据定义,白化转换将向量转换为白噪声向量。
我们将 AWGN 增强波形作为新样本添加到我们的数据集中。由于我们生成的 AWGN 对于每个样本都是随机的 - 随机随机噪声 - 我们可以添加噪声增强数据集的倍数。我将添加 2 个额外的相同、随机的噪声数据集,每个数据集有 1440 个样本,以获得一个具有 1440 个原生 + 1440x2 == 4320 个噪声样本的数据集。
def awgn_augmentation(waveform, multiples=2, bits=16, snr_min=15, snr_max=30):
# get length of waveform (should be 3*48k = 144k)
wave_len = len(waveform)
# Generate normally distributed (Gaussian) noises
# one for each waveform and multiple (i.e. wave_len*multiples noises)
noise = np.random.normal(size=(multiples, wave_len))
# Normalize waveform and noise
norm_constant = 2.0**(bits-1)
norm_wave = waveform / norm_constant
norm_noise = noise / norm_constant
# Compute power of waveform and power of noise
signal_power = np.sum(norm_wave ** 2) / wave_len
noise_power = np.sum(norm_noise ** 2, axis=1) / wave_len
# Choose random SNR in decibels in range [15,30]
snr = np.random.randint(snr_min, snr_max)
# Apply whitening transformation: make the Gaussian noise into Gaussian white noise
# Compute the covariance matrix used to whiten each noise
# actual SNR = signal/noise (power)
# actual noise power = 10**(-snr/10)
covariance = np.sqrt((signal_power / noise_power) * 10 ** (- snr / 10))
# Get covariance matrix with dim: (144000, 2) so we can transform 2 noises: dim (2, 144000)
covariance = np.ones((wave_len, multiples)) * covariance
# Since covariance and noise are arrays, * is the haddamard product
# Take Haddamard product of covariance and noise to generate white noise
multiple_augmented_waveforms = waveform + covariance.T * noise
return multiple_augmented_waveforms
def augment_waveforms(waveforms, features, emotions, multiples):
# keep track of how many waveforms we've processed so we can add correct emotion label in the same order
emotion_count = 0
# keep track of how many augmented samples we've added
added_count = 0
# convert emotion array to list for more efficient appending
emotions = emotions.tolist()
for waveform in waveforms:
# Generate 2 augmented multiples of the dataset, i.e. 1440 native + 1440*2 noisy = 4320 samples total
augmented_waveforms = awgn_augmentation(waveform, multiples=multiples)
# compute spectrogram for each of 2 augmented waveforms
for augmented_waveform in augmented_waveforms:
# Compute MFCCs over augmented waveforms
augmented_mfcc = feature_mfcc(augmented_waveform, sample_rate=sample_rate)
# append the augmented spectrogram to the rest of the native data
features.append(augmented_mfcc)
emotions.append(emotions[emotion_count])
# keep track of new augmented samples
added_count += 1
# check progress
print('\r'+f'Processed {emotion_count + 1}/{len(waveforms)} waveforms for {added_count}/{len(waveforms)*multiples} new augmented samples',end='')
# keep track of the emotion labels to append in order
emotion_count += 1
# store augmented waveforms to check their shape
augmented_waveforms_temp.append(augmented_waveforms)
return features, emotions
计算 AWGN 增强的特征并添加到数据集的其余部分
# store augmented waveforms to verify their shape and random-ness
augmented_waveforms_temp = []
# specify multiples of our dataset to add as augmented data
multiples = 2
print('Train waveforms:') # augment waveforms of training set
features_train , y_train = augment_waveforms(X_train, features_train, y_train, multiples)
print('\n\nValidation waveforms:') # augment waveforms of validation set
features_valid, y_valid = augment_waveforms(X_valid, features_valid, y_valid, multiples)
print('\n\nTest waveforms:') # augment waveforms of test set
features_test, y_test = augment_waveforms(X_test, features_test, y_test, multiples)
# Check new shape of extracted features and data:
print(f'\n\nNative + Augmented Features set: {len(features_train)+len(features_test)+len(features_valid)} total, {len(features_train)} train, {len(features_valid)} validation, {len(features_test)} test samples')
print(f'{len(y_train)} training sample labels, {len(y_valid)} validation sample labels, {len(y_test)} test sample labels')
print(f'Features (MFCC matrix) shape: {len(features_train[0])} mel frequency coefficients x {len(features_train[0][1])} time steps')
Train waveforms:
Processed 1147/1147 waveforms for 2294/2294 new augmented samples
Validation waveforms:
Processed 143/143 waveforms for 286/286 new augmented samples
Test waveforms:
Processed 150/150 waveforms for 300/300 new augmented samples
Native + Augmented Features set: 4320 total, 3441 train, 429 validation, 450 test samples
3441 training sample labels, 429 validation sample labels, 450 test sample labels
Features (MFCC matrix) shape: 40 mel frequency coefficients x 282 time steps
检查 Augmented Waveforms(增强波形):
# pick a random waveform, but same one from native and augmented set for easier comparison
plt.figure(figsize=(15,4))
plt.subplot(1, 2, 1)
librosa.display.waveplot(waveforms[12], sr=sample_rate)
plt.title('Native')
plt.subplot(1, 2, 2)
# augmented waveforms are 2D len 1440 list with 2 waveforms in each position
librosa.display.waveplot(augmented_waveforms_temp[0][0], sr=sample_rate)
plt.title('AWGN Augmented')
plt.show()
plt.figure(figsize=(15,4))
plt.subplot(1, 2, 1)
librosa.display.waveplot(augmented_waveforms_temp[2][0], sr=sample_rate)
plt.title('AWGN Augmented')
plt.subplot(1, 2, 2)
librosa.display.waveplot(augmented_waveforms_temp[7][0], sr=sample_rate)
plt.title('AWGN Augmented')
plt.show()
看起来吵还不错。噪声在波形的无声区域中清晰可见。我们可以看到噪声的可变性,其 SNR 应该在 15 到 30 之间。
请注意,只有在将数据拆分为训练集、验证集和测试集后,我们才会进行增强,并且我们单独处理了每个集。
当我们在拆分数据之前对数据进行扩充时,测试和验证数据会泄漏到训练集中,训练后测试准确率达到 97%。
将数据格式化为 Tensor Ready 4D 数组
我们的 MFCC 特征数组中没有暗淡(#samples、#MFC 系数、时间步长)的颜色通道。我们有一个黑白图像的模拟:我们没有 3 个彩色通道,而是 1 个信号强度通道:在时间 t 处 40 个 mel 频率系数中每个系数的幅度。
我们需要一个输入通道 dim 来扩展为使用 CNN 滤波器的输出通道。我们创建一个虚拟通道 dim 以将特征扩展为支持 2D-CNN 的 4D 张量格式:N x C x H x W。
# need to make dummy input channel for CNN input feature tensor
X_train = np.expand_dims(features_train,1)
X_valid = np.expand_dims(features_valid, 1)
X_test = np.expand_dims(features_test,1)
# convert emotion labels from list back to numpy arrays for PyTorch to work with
y_train = np.array(y_train)
y_valid = np.array(y_valid)
y_test = np.array(y_test)
# confiorm that we have tensor-ready 4D data array
# should print (batch, channel, width, height) == (4320, 1, 128, 282) when multiples==2
print(f'Shape of 4D feature array for input tensor: {X_train.shape} train, {X_valid.shape} validation, {X_test.shape} test')
print(f'Shape of emotion labels: {y_train.shape} train, {y_valid.shape} validation, {y_test.shape} test')
Shape of 4D feature array for input tensor: (3441, 1, 40, 282) train, (429, 1, 40, 282) validation, (450, 1, 40, 282) test
Shape of emotion labels: (3441,) train, (429,) validation, (450,) test
# free up some RAM - no longer need full feature set or any waveforms
del features_train, features_valid, features_test, waveforms, augmented_waveforms_temp
特征缩放
缩放将大大减少模型训练到收敛所需的时间 - 它将更容易在较小的量级上执行计算。作为参考,缩放将该模型的收敛时间从大约 500 个纪元减少到 200 个纪元。
Standard Scaling 最有意义,因为我们有一些我们不知道其目标分布的特征。当我使用 MLP 分类器对此数据集执行分类时,标准缩放在各种条件和特征下都是最佳的。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
#### Scale the training data ####
# store shape so we can transform it back
N,C,H,W = X_train.shape
# Reshape to 1D because StandardScaler operates on a 1D array
# tell numpy to infer shape of 1D array with '-1' argument
X_train = np.reshape(X_train, (N,-1))
X_train = scaler.fit_transform(X_train)
# Transform back to NxCxHxW 4D tensor format
X_train = np.reshape(X_train, (N,C,H,W))
##### Scale the validation set ####
N,C,H,W = X_valid.shape
X_valid = np.reshape(X_valid, (N,-1))
X_valid = scaler.transform(X_valid)
X_valid = np.reshape(X_valid, (N,C,H,W))
#### Scale the test set ####
N,C,H,W = X_test.shape
X_test = np.reshape(X_test, (N,-1))
X_test = scaler.transform(X_test)
X_test = np.reshape(X_test, (N,C,H,W))
# check shape of each set again
print(f'X_train scaled:{X_train.shape}, y_train:{y_train.shape}')
print(f'X_valid scaled:{X_valid.shape}, y_valid:{y_valid.shape}')
print(f'X_test scaled:{X_test.shape}, y_test:{y_test.shape}')
X_train scaled:(3441, 1, 40, 282), y_train:(3441,)
X_valid scaled:(429, 1, 40, 282), y_valid:(429,)
X_test scaled:(450, 1, 40, 282), y_test:(450,)
将数据保存和重新加载为 NumPy 数组
我们可以将训练/验证/测试数据保存为 numpy 数组,以便在笔记本内核崩溃/google colab 运行时崩溃/训练数据可能从内存中清除的任何原因时更快地加载。这比加载 1440 个文件并再次计算它们的特征要快得多 - 更不用说增强的特征了。
###### SAVE #########
# choose save file name
filename = 'features+labels.npy'
# open file in write mode and write data
with open(filename, 'wb') as f:
np.save(f, X_train)
np.save(f, X_valid)
np.save(f, X_test)
np.save(f, y_train)
np.save(f, y_valid)
np.save(f, y_test)
print(f'Features and labels saved to {filename}')
Features and labels saved to features+labels.npy
##### LOAD #########
# choose load file name
filename = 'features+labels.npy'
# open file in read mode and read data
with open(filename, 'rb') as f:
X_train = np.load(f)
X_valid = np.load(f)
X_test = np.load(f)
y_train = np.load(f)
y_valid = np.load(f)
y_test = np.load(f)
# Check that we've recovered the right data
print(f'X_train:{X_train.shape}, y_train:{y_train.shape}')
print(f'X_valid:{X_valid.shape}, y_valid:{y_valid.shape}')
print(f'X_test:{X_test.shape}, y_test:{y_test.shape}')
X_train:(3441, 1, 40, 282), y_train:(3441,)
X_valid:(429, 1, 40, 282), y_valid:(429,)
X_test:(450, 1, 40, 282), y_test:(450,)
架构概述

每个 3 层深度的 2D 卷积块都与经典的 LeNet 架构极为相似:Conv->Pool>Conv>Pool>FC。
AlexNet 构成了通过堆叠 CNN 层进行通道扩展而增加特征映射复杂性的基础;Inception 和 GoogLeNet 是并行化 CNN 层的灵感来源,希望使网络学习到的功能多样化。
VGGNet 证明了在整个深度堆叠的 CNN 层中使用固定大小的内核的效率是不合理的;我发现这延伸到了这项任务。具体来说,VGG 主要通过用 3x3 步幅 1 的小内核替换大内核(即 11x11 步幅 5)来获得优于 AlexNet 的改进。VGG 为此引用的动机之一是 3x3 内核是理解空间数据的最小内核大小选择,例如上/下/左/右(尽管 VGG 也使用 1x1 内核)。VGGNet 还激发了 2x2 stride 2 的 maxpool 内核大小,就像我在每个卷积块的第一层使用的那样。
更准确地说,使用小型堆叠滤波器的动机有两个:计算效率和特征表示的表达性。当我们将 3 个 3x3 内核堆叠在一起时,就像在这个架构中一样,第二层是原始输入卷的 5x5 视图,而第 3 层是 7x7 视图。然而,每个较小层之间的非线性传达了更复杂的特征表示,而单个 7x7 层本身只会执行线性变换。此外,如果我们保持各层之间的通道 (C) 一致,那么 3 个 3x3 内核由 (3(C(3x3xC)) = 27C^2 参数参数化,而只有一个 7x7 内核需要 C(7x7xC) = 49C^2 参数。最终,小堆叠内核似乎更强大、更高效——尽管在 Large Kernel Matters 中 - Improve Semantic Segmentation by Global Convolutional Network 一书中,作者得出结论,在语义分割方面,较大的内核优于较小的堆叠内核——然而,由于我们只在做语义部分(分类),而不关心情绪的“位置”——这不应该适用。
最后,2015 年的原始批量归一化 (BN) 论文建议“我们在非线性之前添加 BN 变换”,即在 ReLU 之前;但是,我在 ReLU 之后使用 BN 从这个架构中获得了更好的性能。请参阅 Keras 作者 Francois Chollet 在 GitHub 上关于 BN 订单问题的回应:“我可以保证 Christian [Szegedy] 最近编写的代码在 BN 之前应用 relu”。
Transformer 架构与 Viswani 等人在 2017 年:注意力就是你所需要的完全相同,但我使用了 4 个堆叠编码器,而不是他们论文中的 6 个。有关 Transformer 模块的更多详细信息:附录 B:Transformer 和自我注意(就是你所需要的)
CNN 动机
具有 2D 卷积层的 CNN 是图像处理的黄金标准,除了图像 Transformer 的最新进展。2D 卷积层接受 (N,C,H,W) (批量大小、通道、高度、宽度) 格式的输入特征图。我们有 4320 个 MFCC 图——1440 个原生图和 2880 个噪声增强图——每个 MFCC 图的形状为 40x282,其中 40 个 MFC 系数代表不同的梅尔音高范围,每个 MFC 系数有 282 个时间步长。我们可以将 MFCC 图想象成具有 1 个信号强度通道的黑白图像。因此,我们的 MFCC 输入特征张量在拆分进行训练之前的形状为 (4320, 1, 40, 282)。我将交替引用 input/output feature maps 和 input/output volumes,但它们具有相同的含义。激活函数对特征图进行作后,它会生成激活图。
我在两个 CNN 块的所有 3 层中使用了 3x3 内核。第一层只有一个输入通道,创建一个 1x3x3 滤波器,有 16 个输出通道需要 16 个这样独特的 1x3x3 滤波器,每个滤波器有 1x3x3=9 个权重。下一层有 16 个输入通道和 32 个输出通道,产生 32 个唯一的 16x3x3 滤波器,每个滤波器具有 16x3x3 = 144 个权重。也就是说,第二层将 32 个不同权重的 16x3x3 滤波器应用于 16x20x141 的输入体积(第一层的 2x2 最大池化输出),在 4x4 步幅 4 最大池化后生成 32x5x35 的输出特征图。最后一层有 32 个输入通道,所以一个 32x3x3 的滤波器,还有 64 个输出通道,所以有 64 个唯一的滤波器,每个滤波器有 32x3x3=288 个权重。最后一层在 4x4 步幅 4 最大池化后生成 64x1x8 的输出特征图。我希望滤波器深度/复杂性的同步扩展和特征图体积的减少能够以最低的计算成本提供最具表现力的分层特征表示。
附录 A:剖析卷积神经网络中详细描述了 2D 卷积神经网络的主要动机和作,以解释 CNN 必须完成此任务的动机以及优化 CNN 中每一层的超参数时要考虑的因素。
Transformer-Encoder 动机
我使用 Attention is All You Need 中介绍的 Transformer-Encoder 层,希望网络能够学会根据每种情绪的 MFCC 的全局结构来预测不同情绪的频率分布。我本可以使用 LSTM-RNN 来学习每种情绪的频谱图序列,但网络只会学习根据相邻的时间步长预测频率变化;相比之下,transformer 的多头自注意力层使网络能够在预测下一个时间步长时查看前面的多个时间步。这对我来说是有道理的,因为情绪会影响整个频率序列,而不仅仅是在一个时间步长。
我将输入 MFCC 映射 maxpool 到 transformer 模块,以大幅减少网络需要学习的参数数量。
附录 B:Transformer 中详细描述了 Transformer 架构背后的主要动机和作
构建模型架构并定义前向传递
#change nn.sequential to take dict to make more readable
class parallel_all_you_want(nn.Module):
# Define all layers present in the network
def __init__(self,num_emotions):
super().__init__()
################ TRANSFORMER BLOCK #############################
# maxpool the input feature map/tensor to the transformer
# a rectangular kernel worked better here for the rectangular input spectrogram feature map/tensor
self.transformer_maxpool = nn.MaxPool2d(kernel_size=[1,4], stride=[1,4])
# define single transformer encoder layer
# self-attention + feedforward network from "Attention is All You Need" paper
# 4 multi-head self-attention layers each with 40-->512--->40 feedforward network
transformer_layer = nn.TransformerEncoderLayer(
d_model=40, # input feature (frequency) dim after maxpooling 40*282 -> 40*70 (MFC*time)
nhead=4, # 4 self-attention layers in each multi-head self-attention layer in each encoder block
dim_feedforward=512, # 2 linear layers in each encoder block's feedforward network: dim 40-->512--->40
dropout=0.4,
activation='relu' # ReLU: avoid saturation/tame gradient/reduce compute time
)
# I'm using 4 instead of the 6 identical stacked encoder layrs used in Attention is All You Need paper
# Complete transformer block contains 4 full transformer encoder layers (each w/ multihead self-attention+feedforward)
self.transformer_encoder = nn.TransformerEncoder(transformer_layer, num_layers=4)
############### 1ST PARALLEL 2D CONVOLUTION BLOCK ############
# 3 sequential conv2D layers: (1,40,282) --> (16, 20, 141) -> (32, 5, 35) -> (64, 1, 8)
self.conv2Dblock1 = nn.Sequential(
# 1st 2D convolution layer
nn.Conv2d(
in_channels=1, # input volume depth == input channel dim == 1
out_channels=16, # expand output feature map volume's depth to 16
kernel_size=3, # typical 3*3 stride 1 kernel
stride=1,
padding=1
),
nn.BatchNorm2d(16), # batch normalize the output feature map before activation
nn.ReLU(), # feature map --> activation map
nn.MaxPool2d(kernel_size=2, stride=2), #typical maxpool kernel size
nn.Dropout(p=0.3), #randomly zero 30% of 1st layer's output feature map in training
# 2nd 2D convolution layer identical to last except output dim, maxpool kernel
nn.Conv2d(
in_channels=16,
out_channels=32, # expand output feature map volume's depth to 32
kernel_size=3,
stride=1,
padding=1
),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=4, stride=4), # increase maxpool kernel for subsequent filters
nn.Dropout(p=0.3),
# 3rd 2D convolution layer identical to last except output dim
nn.Conv2d(
in_channels=32,
out_channels=64, # expand output feature map volume's depth to 64
kernel_size=3,
stride=1,
padding=1
),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=4, stride=4),
nn.Dropout(p=0.3),
)
############### 2ND PARALLEL 2D CONVOLUTION BLOCK ############
# 3 sequential conv2D layers: (1,40,282) --> (16, 20, 141) -> (32, 5, 35) -> (64, 1, 8)
self.conv2Dblock2 = nn.Sequential(
# 1st 2D convolution layer
nn.Conv2d(
in_channels=1, # input volume depth == input channel dim == 1
out_channels=16, # expand output feature map volume's depth to 16
kernel_size=3, # typical 3*3 stride 1 kernel
stride=1,
padding=1
),
nn.BatchNorm2d(16), # batch normalize the output feature map before activation
nn.ReLU(), # feature map --> activation map
nn.MaxPool2d(kernel_size=2, stride=2), #typical maxpool kernel size
nn.Dropout(p=0.3), #randomly zero 30% of 1st layer's output feature map in training
# 2nd 2D convolution layer identical to last except output dim, maxpool kernel
nn.Conv2d(
in_channels=16,
out_channels=32, # expand output feature map volume's depth to 32
kernel_size=3,
stride=1,
padding=1
),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=4, stride=4), # increase maxpool kernel for subsequent filters
nn.Dropout(p=0.3),
# 3rd 2D convolution layer identical to last except output dim
nn.Conv2d(
in_channels=32,
out_channels=64, # expand output feature map volume's depth to 64
kernel_size=3,
stride=1,
padding=1
),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=4, stride=4),
nn.Dropout(p=0.3),
)
################# FINAL LINEAR BLOCK ####################
# Linear softmax layer to take final concatenated embedding tensor
# from parallel 2D convolutional and transformer blocks, output 8 logits
# Each full convolution block outputs (64*1*8) embedding flattened to dim 512 1D array
# Full transformer block outputs 40*70 feature map, which we time-avg to dim 40 1D array
# 512*2+40 == 1064 input features --> 8 output emotions
self.fc1_linear = nn.Linear(512*2+40,num_emotions)
### Softmax layer for the 8 output logits from final FC linear layer
self.softmax_out = nn.Softmax(dim=1) # dim==1 is the freq embedding
# define one complete parallel fwd pass of input feature tensor thru 2*conv+1*transformer blocks
def forward(self,x):
############ 1st parallel Conv2D block: 4 Convolutional layers ############################
# create final feature embedding from 1st convolutional layer
# input features pased through 4 sequential 2D convolutional layers
conv2d_embedding1 = self.conv2Dblock1(x) # x == N/batch * channel * freq * time
# flatten final 64*1*8 feature map from convolutional layers to length 512 1D array
# skip the 1st (N/batch) dimension when flattening
conv2d_embedding1 = torch.flatten(conv2d_embedding1, start_dim=1)
############ 2nd parallel Conv2D block: 4 Convolutional layers #############################
# create final feature embedding from 2nd convolutional layer
# input features pased through 4 sequential 2D convolutional layers
conv2d_embedding2 = self.conv2Dblock2(x) # x == N/batch * channel * freq * time
# flatten final 64*1*8 feature map from convolutional layers to length 512 1D array
# skip the 1st (N/batch) dimension when flattening
conv2d_embedding2 = torch.flatten(conv2d_embedding2, start_dim=1)
########## 4-encoder-layer Transformer block w/ 40-->512-->40 feedfwd network ##############
# maxpool input feature map: 1*40*282 w/ 1*4 kernel --> 1*40*70
x_maxpool = self.transformer_maxpool(x)
# remove channel dim: 1*40*70 --> 40*70
x_maxpool_reduced = torch.squeeze(x_maxpool,1)
# convert maxpooled feature map format: batch * freq * time ---> time * batch * freq format
# because transformer encoder layer requires tensor in format: time * batch * embedding (freq)
x = x_maxpool_reduced.permute(2,0,1)
# finally, pass reduced input feature map x into transformer encoder layers
transformer_output = self.transformer_encoder(x)
# create final feature emedding from transformer layer by taking mean in the time dimension (now the 0th dim)
# transformer outputs 2x40 (MFCC embedding*time) feature map, take mean of columns i.e. take time average
transformer_embedding = torch.mean(transformer_output, dim=0) # dim 40x70 --> 40
############# concatenate freq embeddings from convolutional and transformer blocks ######
# concatenate embedding tensors output by parallel 2*conv and 1*transformer blocks
complete_embedding = torch.cat([conv2d_embedding1, conv2d_embedding2,transformer_embedding], dim=1)
######### final FC linear layer, need logits for loss #########################
output_logits = self.fc1_linear(complete_embedding)
######### Final Softmax layer: use logits from FC linear, get softmax for prediction ######
output_softmax = self.softmax_out(output_logits)
# need output logits to compute cross entropy loss, need softmax probabilities to predict class
return output_logits, output_softmax
Analyzing The Flow of Tensors Through the Network
我们将输入特征映射 1 对每个卷积层进行零填充,以从该层返回与我们输入的形状相同的形状张量:零填充 1 将 2 添加到每个 (H, W) 维度,而 3x3、步幅 1 内核从 (H,W) 中的每一个维度中截断(内核 - 步幅 == 2)。Zero-pad 1 --> 3x3 stride 1 内核有效地丢弃了零焊盘,以从每个 conv2D 块获得相同的输入/输出形状。
在每个块的第一个卷积层的末尾,我们有一个大小为 2x2 的 maxpool 内核,步幅为 2,它将在其风度中占用 4 个像素中的 1 个。对于第一个输入特征映射,maxpool 内核将在行上前进 40/2 = 20 次,在列上前进 282/2=141 次,从而生成 20x141 的输出映射。不重叠的 maxpool 内核将每个输出暗淡减少到输入暗淡/内核大小。然后,我们将输出通道扩展到 16,形成 (16x20x141) 的输出特征图。
每个块中接下来的两个卷积层的 maxpool 内核大小为 4x4,步幅为 4。与上述数学相同, maxpool 减少每个 dim/4。第 2 个卷积层需要 (16x20x141) --> (32x5x35)。第 3 个也是最后一个 conv 层需要 (32x5x35) --> (64x1x8)。
请注意,在 (N,C,H,W) 格式中,对于 MFCC H = MFCC(间距),W = 时间步长。
通过每个卷积块 (C,H,W) 的完整流:
Layer 1 ---> 1x40x282 --> PAD-1 --> 1x42x284 --> FILTER 1x3x3 --> 16x40x282 --> MAXPOOL 2x2 stride 2 --> 16x20x141 Layer 2 ---> 16x20x141 --> PAD-1 --> 16x22x143 --> FILTER 16x3x3 --> 32x20x141 --> MAXPOOL 4x4 stride 4 --> 32x5x35 Layer 3 ---> 32x5x35 --> PAD-1 --> 32x7x37 --> FILTER 32x3x3 --> 64x5x35 --> MAXPOOL 4x4 stride 4 --> 64x1x8 Flatten ---> 64x1x8 --> Final convolutional embedding length 512 1D array 完整的流通式变压器编码器模块 (C、H、W):
Maxpool 1x4 stride 1x4 ---> 1x40x282 --> 1x20x70 Drop channel ---> 1x20x70 --> 20x70 (H,W) Change dims ---> 20x70 --> 70x40 (W,H) 4xTransformer encoder ---> 70x40 --> 2x40 (W,H) Time average ---> 2x40 --> 1x40 --> Final transformer embedding length 40 1D array FC 线性网络 (C,H,W):
Concatenate ---> 512+512+40 --> 1064 FC Linear layer ---> 1064 --> Final linear logits output length 8 1D array Softmax layer: 8 ----> 1 predicted emotion / max probability class 我们可以使用出色的 torchsummary 包来确认我们网络的张量形状和流向,该包提供了 Keras 的 model.summary 方法的 PyTorch 实现:
from torchsummary import summary
# need device to instantiate model
device = 'cuda'
# instantiate model for 8 emotions and move to GPU
model = parallel_all_you_want(len(emotions_dict)).to(device)
# include input feature map dims in call to summary()
summary(model, input_size=(1,40,282))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 16, 40, 282] 160
BatchNorm2d-2 [-1, 16, 40, 282] 32
ReLU-3 [-1, 16, 40, 282] 0
MaxPool2d-4 [-1, 16, 20, 141] 0
Dropout-5 [-1, 16, 20, 141] 0
Conv2d-6 [-1, 32, 20, 141] 4,640
BatchNorm2d-7 [-1, 32, 20, 141] 64
ReLU-8 [-1, 32, 20, 141] 0
MaxPool2d-9 [-1, 32, 5, 35] 0
Dropout-10 [-1, 32, 5, 35] 0
Conv2d-11 [-1, 64, 5, 35] 18,496
BatchNorm2d-12 [-1, 64, 5, 35] 128
ReLU-13 [-1, 64, 5, 35] 0
MaxPool2d-14 [-1, 64, 1, 8] 0
Dropout-15 [-1, 64, 1, 8] 0
Conv2d-16 [-1, 16, 40, 282] 160
BatchNorm2d-17 [-1, 16, 40, 282] 32
ReLU-18 [-1, 16, 40, 282] 0
MaxPool2d-19 [-1, 16, 20, 141] 0
Dropout-20 [-1, 16, 20, 141] 0
Conv2d-21 [-1, 32, 20, 141] 4,640
BatchNorm2d-22 [-1, 32, 20, 141] 64
ReLU-23 [-1, 32, 20, 141] 0
MaxPool2d-24 [-1, 32, 5, 35] 0
Dropout-25 [-1, 32, 5, 35] 0
Conv2d-26 [-1, 64, 5, 35] 18,496
BatchNorm2d-27 [-1, 64, 5, 35] 128
ReLU-28 [-1, 64, 5, 35] 0
MaxPool2d-29 [-1, 64, 1, 8] 0
Dropout-30 [-1, 64, 1, 8] 0
MaxPool2d-31 [-1, 1, 40, 70] 0
MultiheadAttention-32 [[-1, 2, 40], [-1, 70, 70]] 0
Dropout-33 [-1, 2, 40] 0
LayerNorm-34 [-1, 2, 40] 80
Linear-35 [-1, 2, 512] 20,992
Dropout-36 [-1, 2, 512] 0
Linear-37 [-1, 2, 40] 20,520
Dropout-38 [-1, 2, 40] 0
LayerNorm-39 [-1, 2, 40] 80
TransformerEncoderLayer-40 [-1, 2, 40] 0
MultiheadAttention-41 [[-1, 2, 40], [-1, 70, 70]] 0
Dropout-42 [-1, 2, 40] 0
LayerNorm-43 [-1, 2, 40] 80
Linear-44 [-1, 2, 512] 20,992
Dropout-45 [-1, 2, 512] 0
Linear-46 [-1, 2, 40] 20,520
Dropout-47 [-1, 2, 40] 0
LayerNorm-48 [-1, 2, 40] 80
TransformerEncoderLayer-49 [-1, 2, 40] 0
MultiheadAttention-50 [[-1, 2, 40], [-1, 70, 70]] 0
Dropout-51 [-1, 2, 40] 0
LayerNorm-52 [-1, 2, 40] 80
Linear-53 [-1, 2, 512] 20,992
Dropout-54 [-1, 2, 512] 0
Linear-55 [-1, 2, 40] 20,520
Dropout-56 [-1, 2, 40] 0
LayerNorm-57 [-1, 2, 40] 80
TransformerEncoderLayer-58 [-1, 2, 40] 0
MultiheadAttention-59 [[-1, 2, 40], [-1, 70, 70]] 0
Dropout-60 [-1, 2, 40] 0
LayerNorm-61 [-1, 2, 40] 80
Linear-62 [-1, 2, 512] 20,992
Dropout-63 [-1, 2, 512] 0
Linear-64 [-1, 2, 40] 20,520
Dropout-65 [-1, 2, 40] 0
LayerNorm-66 [-1, 2, 40] 80
TransformerEncoderLayer-67 [-1, 2, 40] 0
TransformerEncoder-68 [-1, 2, 40] 0
Linear-69 [-1, 8] 8,520
Softmax-70 [-1, 8] 0
================================================================
Total params: 222,248
Trainable params: 222,248
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.04
Forward/backward pass size (MB): 2.61
Params size (MB): 0.85
Estimated Total Size (MB): 3.50
----------------------------------------------------------------
定义损失/标准
我们必须为每次训练迭代的向后传递定义损失函数(每个 PyTorch 表示法的标准)。由于我们的类是 balanced 的,因此我们不需要指定 class-weight 参数(来平衡类)。
PyTorch nn.CrossEntropyLoss() 实现对数 softmax 和负对数似然损失 (nn.NLLoss() --> nn.对数软max()) 我们使用 log softmax 来获得计算优势和更快的梯度优化。Log softmax 在无法预测正确的类时会对模型进行严重惩罚。
# define loss function; CrossEntropyLoss() fairly standard for multiclass problems
def criterion(predictions, targets):
return nn.CrossEntropyLoss()(input=predictions, target=targets)
选择 Optimizer (优化器)
我使用 Adam 来训练 MLP,因为它的计算和收敛速度更快。Adam 很棒,通常与默认值配合得很好。
然而,许多 2018-2020 年的论文仍然使用 SGD。在我看来,原因是 SGD 具有适当调整的动量有时(经常)会收敛到具有足够训练的较低损失。
引用 Wilson 等人,2017 年:
“We observe that the solutions found by adaptive methods generalize worse (often significantly worse) than SGD, even when these solutions have better training performance. These results suggest that practitioners should reconsider the use of adaptive methods to train neural networks." “适应性方法”指的是像亚当这样的人。
我充分利用了普通的旧 SGD,使用了导致收敛的最高动量,再加上大量的长训练时间。
optimizer = torch.optim.SGD(model.parameters(),lr=0.01, weight_decay=1e-3, momentum=0.8)
定义训练步骤
我们定义了一个函数来返回一个定义模型迭代的单个训练步骤。
Forward pass output logits and softmax probabilities. Record the softmax probabilities to track accuracy. Pass output logits to loss function to compute loss. Call backwards pass with loss function (backpropogate errors). Tell optimizer to apply one update step to network parameters. Zero the accumulated gradient in the optimizer for next iteration. # define function to create a single step of the training phase
def make_train_step(model, criterion, optimizer):
# define the training step of the training phase
def train_step(X,Y):
# forward pass
output_logits, output_softmax = model(X)
predictions = torch.argmax(output_softmax,dim=1)
accuracy = torch.sum(Y==predictions)/float(len(Y))
# compute loss on logits because nn.CrossEntropyLoss implements log softmax
loss = criterion(output_logits, Y)
# compute gradients for the optimizer to use
loss.backward()
# update network parameters based on gradient stored (by calling loss.backward())
optimizer.step()
# zero out gradients for next pass
# pytorch accumulates gradients from backwards passes (convenient for RNNs)
optimizer.zero_grad()
return loss.item(), accuracy*100
return train_step
定义验证步骤
定义一个函数,在 10% X,y 张量对上返回单个验证步骤,以了解模型在训练时的泛化性,以便我们知道是否以及何时停止它并调整超参数。通过将 model 设置为 validation mode,确保我们在验证期间不更新网络参数。不要通过设置 torch.no_grad() 在验证阶段浪费资源来计算梯度。
def make_validate_fnc(model,criterion):
def validate(X,Y):
# don't want to update any network parameters on validation passes: don't need gradient
# wrap in torch.no_grad to save memory and compute in validation phase:
with torch.no_grad():
# set model to validation phase i.e. turn off dropout and batchnorm layers
model.eval()
# get the model's predictions on the validation set
output_logits, output_softmax = model(X)
predictions = torch.argmax(output_softmax,dim=1)
# calculate the mean accuracy over the entire validation set
accuracy = torch.sum(Y==predictions)/float(len(Y))
# compute error from logits (nn.crossentropy implements softmax)
loss = criterion(output_logits,Y)
return loss.item(), accuracy*100, predictions
return validate
Make Checkpoint 函数
最好在每个 epoch 之后保存模型状态的检查点。然后,当对模型的性能感到满意时,我们将中断训练并加载适当的模型二进制文件。
- 如果硬件/软件出现故障,则恢复训练
- 优化后通过从 checkpoint 进行训练来节省计算重新训练
- 通过保留最高性能版本的模型快照,轻松实现提前停止
- Google Colab 最终会限制 GPU 的使用;不能无限期地从头开始重新训练
def make_save_checkpoint():
def save_checkpoint(optimizer, model, epoch, filename):
checkpoint_dict = {
'optimizer': optimizer.state_dict(),
'model': model.state_dict(),
'epoch': epoch
}
torch.save(checkpoint_dict, filename)
return save_checkpoint
def load_checkpoint(optimizer, model, filename):
checkpoint_dict = torch.load(filename)
epoch = checkpoint_dict['epoch']
model.load_state_dict(checkpoint_dict['model'])
if optimizer is not None:
optimizer.load_state_dict(checkpoint_dict['optimizer'])
return epoch
构建训练循环
使用训练和验证步骤函数构建完整的训练循环。
这个模型在 CPU 上训练是不合理的,但它是检查模型是否编译成功的好方法。我正在使用 Google Colab 的免费 GPU(K80 - 24GB RAM ~2.9 TFLOPs)。这个模型相当大(如果我正确检查了数学运算,则需要学习 383,688 个参数),但在 K80 上可以在 ~10 分钟内训练收敛。
选择要使用的纪元数(所有训练样本的完成通过)高于合理值,以便模型不会在收敛之前终止 - 我在收敛时手动停止了它。
小批量大小:来自 Yann LeCun 的 twitter(附加了 LeCun 的 facebook 评论)引用了这篇 2018 年的小批量论文:
"Training with large minibatches is bad for your health. More importantly, it's bad for your test error. Friends dont let friends use minibatches larger than 32. Let's face it: the only people have switched to minibatch sizes larger than one since 2012 is because GPUs are inefficient for batch sizes smaller than 32. That's a terrible reason. It just means our hardware sucks." 这就是逻辑。以下是完整的训练循环:
--Setup-- Instantiate model. Instantiate training and validation steps with model, loss function, and optimizer. Move model to GPU. --Epoch-- Set model to train mode after each post-epoch validation phase completes. Shuffle the training set for each epoch, reset epoch loss and accuracy. --Iteration-- Create X_train, y_train minibatch tensors for each iteration and move tensors to GPU. Take 1 train step with X_train, y_train minibatch tensors. Aggregate accuracy and loss from each iteration, but only record after each epoch. --Epoch-- Compute and record validation accuracy for the entire epoch to keep track of learning progress. Print training metrics after each epoch. # get training set size to calculate # iterations and minibatch indices
train_size = X_train.shape[0]
# pick minibatch size (of 32... always)
minibatch = 32
# set device to GPU
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f'{device} selected')
# instantiate model and move to GPU for training
model = parallel_all_you_want(num_emotions=len(emotions_dict)).to(device)
print('Number of trainable params: ',sum(p.numel() for p in model.parameters()) )
# encountered bugs in google colab only, unless I explicitly defined optimizer in this cell...
optimizer = torch.optim.SGD(model.parameters(),lr=0.01, weight_decay=1e-3, momentum=0.8)
# instantiate the checkpoint save function
save_checkpoint = make_save_checkpoint()
# instantiate the training step function
train_step = make_train_step(model, criterion, optimizer=optimizer)
# instantiate the validation loop function
validate = make_validate_fnc(model,criterion)
# instantiate lists to hold scalar performance metrics to plot later
train_losses=[]
valid_losses = []
# create training loop for one complete epoch (entire training set)
def train(optimizer, model, num_epochs, X_train, Y_train, X_valid, Y_valid):
for epoch in range(num_epochs):
# set model to train phase
model.train()
# shuffle entire training set in each epoch to randomize minibatch order
train_indices = np.random.permutation(train_size)
# shuffle the training set for each epoch:
X_train = X_train[train_indices,:,:,:]
Y_train = Y_train[train_indices]
# instantiate scalar values to keep track of progress after each epoch so we can stop training when appropriate
epoch_acc = 0
epoch_loss = 0
num_iterations = int(train_size / minibatch)
# create a loop for each minibatch of 32 samples:
for i in range(num_iterations):
# we have to track and update minibatch position for the current minibatch
# if we take a random batch position from a set, we almost certainly will skip some of the data in that set
# track minibatch position based on iteration number:
batch_start = i * minibatch
# ensure we don't go out of the bounds of our training set:
batch_end = min(batch_start + minibatch, train_size)
# ensure we don't have an index error
actual_batch_size = batch_end-batch_start
# get training minibatch with all channnels and 2D feature dims
X = X_train[batch_start:batch_end,:,:,:]
# get training minibatch labels
Y = Y_train[batch_start:batch_end]
# instantiate training tensors
X_tensor = torch.tensor(X, device=device).float()
Y_tensor = torch.tensor(Y, dtype=torch.long,device=device)
# Pass input tensors thru 1 training step (fwd+backwards pass)
loss, acc = train_step(X_tensor,Y_tensor)
# aggregate batch accuracy to measure progress of entire epoch
epoch_acc += acc * actual_batch_size / train_size
epoch_loss += loss * actual_batch_size / train_size
# keep track of the iteration to see if the model's too slow
print('\r'+f'Epoch {epoch}: iteration {i}/{num_iterations}',end='')
# create tensors from validation set
X_valid_tensor = torch.tensor(X_valid,device=device).float()
Y_valid_tensor = torch.tensor(Y_valid,dtype=torch.long,device=device)
# calculate validation metrics to keep track of progress; don't need predictions now
valid_loss, valid_acc, _ = validate(X_valid_tensor,Y_valid_tensor)
# accumulate scalar performance metrics at each epoch to track and plot later
train_losses.append(epoch_loss)
valid_losses.append(valid_loss)
# Save checkpoint of the model
checkpoint_filename = '/content/gdrive/My Drive/DL/models/checkpoints/parallel_all_you_wantFINAL-{:03d}.pkl'.format(epoch)
save_checkpoint(optimizer, model, epoch, checkpoint_filename)
# keep track of each epoch's progress
print(f'\nEpoch {epoch} --- loss:{epoch_loss:.3f}, Epoch accuracy:{epoch_acc:.2f}%, Validation loss:{valid_loss:.3f}, Validation accuracy:{valid_acc:.2f}%')
cuda selected
Number of trainable params: 248488
训练模型
# choose number of epochs higher than reasonable so we can manually stop training
num_epochs = 500
# train it!
train(optimizer, model, num_epochs, X_train, y_train, X_valid, y_valid)
Epoch 0: iteration 106/107
Epoch 0 --- loss:3.199, Epoch accuracy:22.55%, Validation loss:2.501, Validation accuracy:13.75%
Epoch 1: iteration 106/107
Epoch 1 --- loss:1.804, Epoch accuracy:31.10%, Validation loss:2.059, Validation accuracy:23.31%
Epoch 2: iteration 106/107
Epoch 2 --- loss:1.727, Epoch accuracy:34.09%, Validation loss:2.031, Validation accuracy:27.04%
Epoch 3: iteration 106/107
Epoch 3 --- loss:1.658, Epoch accuracy:37.11%, Validation loss:1.962, Validation accuracy:26.34%
Epoch 4: iteration 106/107
Epoch 4 --- loss:1.542, Epoch accuracy:41.88%, Validation loss:1.722, Validation accuracy:38.00%
Epoch 5: iteration 106/107
Epoch 5 --- loss:1.485, Epoch accuracy:44.61%, Validation loss:1.616, Validation accuracy:42.89%
Epoch 6: iteration 106/107
Epoch 6 --- loss:1.406, Epoch accuracy:47.40%, Validation loss:1.482, Validation accuracy:47.32%
Epoch 7: iteration 106/107
Epoch 7 --- loss:1.337, Epoch accuracy:49.43%, Validation loss:1.474, Validation accuracy:51.52%
Epoch 8: iteration 106/107
Epoch 8 --- loss:1.293, Epoch accuracy:50.77%, Validation loss:1.488, Validation accuracy:46.85%
Epoch 9: iteration 106/107
Epoch 9 --- loss:1.226, Epoch accuracy:53.73%, Validation loss:1.390, Validation accuracy:51.98%
Epoch 10: iteration 106/107
Epoch 10 --- loss:1.184, Epoch accuracy:56.67%, Validation loss:1.251, Validation accuracy:55.24%
Epoch 11: iteration 106/107
Epoch 11 --- loss:1.161, Epoch accuracy:57.40%, Validation loss:1.193, Validation accuracy:53.61%
Epoch 12: iteration 106/107
Epoch 12 --- loss:1.094, Epoch accuracy:59.20%, Validation loss:1.195, Validation accuracy:53.61%
Epoch 13: iteration 106/107
Epoch 13 --- loss:1.079, Epoch accuracy:60.22%, Validation loss:1.241, Validation accuracy:56.18%
Epoch 14: iteration 106/107
Epoch 14 --- loss:1.047, Epoch accuracy:61.99%, Validation loss:1.205, Validation accuracy:55.48%
Epoch 15: iteration 106/107
Epoch 15 --- loss:1.002, Epoch accuracy:62.89%, Validation loss:1.189, Validation accuracy:58.04%
Epoch 16: iteration 106/107
Epoch 16 --- loss:0.963, Epoch accuracy:64.49%, Validation loss:1.096, Validation accuracy:61.31%
Epoch 17: iteration 106/107
Epoch 17 --- loss:0.946, Epoch accuracy:65.21%, Validation loss:1.188, Validation accuracy:55.71%
Epoch 18: iteration 106/107
Epoch 18 --- loss:0.911, Epoch accuracy:66.41%, Validation loss:1.046, Validation accuracy:62.94%
Epoch 19: iteration 106/107
Epoch 19 --- loss:0.901, Epoch accuracy:66.41%, Validation loss:1.174, Validation accuracy:56.41%
Epoch 20: iteration 106/107
Epoch 20 --- loss:0.891, Epoch accuracy:67.63%, Validation loss:1.051, Validation accuracy:60.84%
Epoch 21: iteration 106/107
Epoch 21 --- loss:0.850, Epoch accuracy:68.61%, Validation loss:1.233, Validation accuracy:57.81%
Epoch 22: iteration 106/107 Epoch 22 --- loss:0.829, Epoch accuracy:69.14%, Validation loss:1.065, Validation accuracy:64.57%
Epoch 23: iteration 106/107
Epoch 23 --- loss:0.807, Epoch accuracy:71.20%, Validation loss:0.965, Validation accuracy:65.97%
Epoch 24: iteration 106/107
Epoch 24 --- loss:0.788, Epoch accuracy:71.37%, Validation loss:1.015, Validation accuracy:65.03%
Epoch 25: iteration 106/107
Epoch 25 --- loss:0.772, Epoch accuracy:71.78%, Validation loss:1.028, Validation accuracy:64.34%
Epoch 26: iteration 106/107
Epoch 26 --- loss:0.766, Epoch accuracy:72.80%, Validation loss:1.022, Validation accuracy:64.57%
Epoch 27: iteration 106/107
Epoch 27 --- loss:0.730, Epoch accuracy:72.83%, Validation loss:1.058, Validation accuracy:61.54%
Epoch 28: iteration 106/107
Epoch 28 --- loss:0.704, Epoch accuracy:74.11%, Validation loss:1.004, Validation accuracy:64.57%
Epoch 29: iteration 106/107
Epoch 29 --- loss:0.687, Epoch accuracy:74.51%, Validation loss:0.956, Validation accuracy:65.27%
Epoch 30: iteration 106/107
Epoch 30 --- loss:0.659, Epoch accuracy:76.05%, Validation loss:0.949, Validation accuracy:67.37%
Epoch 31: iteration 106/107
Epoch 31 --- loss:0.644, Epoch accuracy:76.75%, Validation loss:0.967, Validation accuracy:68.07%
Epoch 32: iteration 106/107
Epoch 32 --- loss:0.641, Epoch accuracy:76.69%, Validation loss:0.914, Validation accuracy:64.80%
Epoch 33: iteration 106/107
Epoch 33 --- loss:0.623, Epoch accuracy:78.29%, Validation loss:0.991, Validation accuracy:65.27%
Epoch 34: iteration 106/107
Epoch 34 --- loss:0.609, Epoch accuracy:77.68%, Validation loss:0.909, Validation accuracy:66.67%
Epoch 35: iteration 106/107
Epoch 35 --- loss:0.591, Epoch accuracy:78.44%, Validation loss:1.072, Validation accuracy:65.50%
Epoch 36: iteration 106/107
Epoch 36 --- loss:0.593, Epoch accuracy:78.81%, Validation loss:0.950, Validation accuracy:64.80%
Epoch 37: iteration 106/107
Epoch 37 --- loss:0.552, Epoch accuracy:80.59%, Validation loss:0.899, Validation accuracy:67.13%
Epoch 38: iteration 106/107
Epoch 38 --- loss:0.553, Epoch accuracy:80.73%, Validation loss:0.871, Validation accuracy:68.07%
Epoch 39: iteration 106/107
Epoch 39 --- loss:0.542, Epoch accuracy:80.30%, Validation loss:0.892, Validation accuracy:68.53%
Epoch 40: iteration 106/107
Epoch 40 --- loss:0.522, Epoch accuracy:81.58%, Validation loss:0.848, Validation accuracy:68.30%
Epoch 41: iteration 106/107
Epoch 41 --- loss:0.520, Epoch accuracy:81.26%, Validation loss:0.920, Validation accuracy:67.83%
Epoch 42: iteration 106/107
Epoch 42 --- loss:0.513, Epoch accuracy:81.02%, Validation loss:0.862, Validation accuracy:66.20%
Epoch 43: iteration 106/107
Epoch 43 --- loss:0.477, Epoch accuracy:83.17%, Validation loss:0.881, Validation accuracy:69.00%
Epoch 44: iteration 106/107
Epoch 44 --- loss:0.481, Epoch accuracy:82.80%, Validation loss:0.977, Validation accuracy:66.67%
Epoch 45: iteration 106/107
Epoch 45 --- loss:0.486, Epoch accuracy:82.59%, Validation loss:0.959, Validation accuracy:65.27%
Epoch 46: iteration 106/107
Epoch 46 --- loss:0.461, Epoch accuracy:82.91%, Validation loss:0.830, Validation accuracy:66.90%
Epoch 47: iteration 106/107
Epoch 47 --- loss:0.441, Epoch accuracy:83.38%, Validation loss:0.926, Validation accuracy:69.00%
Epoch 48: iteration 106/107
Epoch 48 --- loss:0.441, Epoch accuracy:84.37%, Validation loss:1.104, Validation accuracy:62.70%
Epoch 49: iteration 106/107
Epoch 49 --- loss:0.442, Epoch accuracy:84.10%, Validation loss:0.810, Validation accuracy:70.40%
Epoch 50: iteration 106/107
Epoch 50 --- loss:0.434, Epoch accuracy:84.66%, Validation loss:0.861, Validation accuracy:68.53%
Epoch 51: iteration 106/107
Epoch 51 --- loss:0.436, Epoch accuracy:84.22%, Validation loss:0.826, Validation accuracy:69.70%
Epoch 52: iteration 106/107
Epoch 52 --- loss:0.446, Epoch accuracy:84.28%, Validation loss:0.859, Validation accuracy:69.23%
Epoch 53: iteration 106/107
Epoch 53 --- loss:0.415, Epoch accuracy:85.56%, Validation loss:0.855, Validation accuracy:67.13%
Epoch 54: iteration 106/107
Epoch 54 --- loss:0.385, Epoch accuracy:86.37%, Validation loss:0.912, Validation accuracy:66.20%
Epoch 55: iteration 106/107
Epoch 55 --- loss:0.387, Epoch accuracy:86.98%, Validation loss:0.848, Validation accuracy:66.90%
Epoch 56: iteration 106/107
Epoch 56 --- loss:0.386, Epoch accuracy:86.37%, Validation loss:0.868, Validation accuracy:69.93%
Epoch 57: iteration 106/107
Epoch 57 --- loss:0.371, Epoch accuracy:87.01%, Validation loss:0.807, Validation accuracy:71.79%
Epoch 58: iteration 106/107
Epoch 58 --- loss:0.367, Epoch accuracy:87.04%, Validation loss:0.888, Validation accuracy:69.00%
Epoch 59: iteration 106/107
Epoch 59 --- loss:0.356, Epoch accuracy:87.59%, Validation loss:0.886, Validation accuracy:68.53%
Epoch 60: iteration 106/107
Epoch 60 --- loss:0.341, Epoch accuracy:88.14%, Validation loss:0.880, Validation accuracy:70.40%
Epoch 61: iteration 106/107
Epoch 61 --- loss:0.337, Epoch accuracy:88.32%, Validation loss:0.844, Validation accuracy:71.10%
Epoch 62: iteration 106/107
Epoch 62 --- loss:0.346, Epoch accuracy:88.11%, Validation loss:0.846, Validation accuracy:71.56%
Epoch 63: iteration 106/107
Epoch 63 --- loss:0.332, Epoch accuracy:88.58%, Validation loss:0.897, Validation accuracy:68.30%
Epoch 64: iteration 106/107
Epoch 64 --- loss:0.342, Epoch accuracy:88.20%, Validation loss:0.808, Validation accuracy:69.23%
Epoch 65: iteration 106/107
Epoch 65 --- loss:0.326, Epoch accuracy:88.40%, Validation loss:0.825, Validation accuracy:68.53%
Epoch 66: iteration 106/107
Epoch 66 --- loss:0.338, Epoch accuracy:88.26%, Validation loss:0.831, Validation accuracy:69.70%
Epoch 67: iteration 106/107
Epoch 67 --- loss:0.322, Epoch accuracy:88.32%, Validation loss:0.860, Validation accuracy:69.93%
Epoch 68: iteration 106/107
Epoch 68 --- loss:0.315, Epoch accuracy:89.48%, Validation loss:0.810, Validation accuracy:70.40%
Epoch 69: iteration 106/107
Epoch 69 --- loss:0.313, Epoch accuracy:89.07%, Validation loss:0.810, Validation accuracy:72.03%
Epoch 70: iteration 106/107
Epoch 70 --- loss:0.336, Epoch accuracy:88.17%, Validation loss:0.822, Validation accuracy:72.49%
Epoch 71: iteration 106/107
Epoch 71 --- loss:0.310, Epoch accuracy:88.96%, Validation loss:0.812, Validation accuracy:69.93%
Epoch 72: iteration 106/107
Epoch 72 --- loss:0.308, Epoch accuracy:89.60%, Validation loss:0.793, Validation accuracy:70.16%
Epoch 73: iteration 106/107
Epoch 73 --- loss:0.305, Epoch accuracy:89.77%, Validation loss:0.818, Validation accuracy:70.86%
Epoch 74: iteration 106/107
Epoch 74 --- loss:0.293, Epoch accuracy:89.63%, Validation loss:0.830, Validation accuracy:69.46%
Epoch 75: iteration 106/107
Epoch 75 --- loss:0.277, Epoch accuracy:90.26%, Validation loss:0.797, Validation accuracy:71.79%
Epoch 76: iteration 106/107
Epoch 76 --- loss:0.290, Epoch accuracy:90.00%, Validation loss:0.782, Validation accuracy:70.86%
Epoch 77: iteration 106/107
Epoch 77 --- loss:0.294, Epoch accuracy:89.19%, Validation loss:0.750, Validation accuracy:74.13%
Epoch 78: iteration 106/107
Epoch 78 --- loss:0.304, Epoch accuracy:89.19%, Validation loss:0.803, Validation accuracy:73.43%
Epoch 79: iteration 106/107
Epoch 79 --- loss:0.278, Epoch accuracy:90.29%, Validation loss:0.800, Validation accuracy:71.10%
Epoch 80: iteration 106/107
Epoch 80 --- loss:0.263, Epoch accuracy:90.73%, Validation loss:0.739, Validation accuracy:74.59%
Epoch 81: iteration 106/107
Epoch 81 --- loss:0.298, Epoch accuracy:89.60%, Validation loss:0.826, Validation accuracy:72.26%
Epoch 82: iteration 106/107
Epoch 82 --- loss:0.268, Epoch accuracy:90.85%, Validation loss:0.780, Validation accuracy:72.03%
Epoch 83: iteration 106/107
Epoch 83 --- loss:0.263, Epoch accuracy:91.17%, Validation loss:0.824, Validation accuracy:71.33%
Epoch 84: iteration 106/107
Epoch 84 --- loss:0.269, Epoch accuracy:90.53%, Validation loss:0.738, Validation accuracy:73.89%
Epoch 85: iteration 106/107
Epoch 85 --- loss:0.259, Epoch accuracy:91.46%, Validation loss:0.798, Validation accuracy:73.43%
Epoch 86: iteration 106/107
Epoch 86 --- loss:0.257, Epoch accuracy:90.87%, Validation loss:0.747, Validation accuracy:71.79%
Epoch 87: iteration 106/107
Epoch 87 --- loss:0.271, Epoch accuracy:90.29%, Validation loss:0.739, Validation accuracy:72.49%
Epoch 88: iteration 106/107
Epoch 88 --- loss:0.278, Epoch accuracy:90.24%, Validation loss:0.856, Validation accuracy:72.49%
Epoch 89: iteration 106/107
Epoch 89 --- loss:0.259, Epoch accuracy:91.25%, Validation loss:0.757, Validation accuracy:71.79%
Epoch 90: iteration 106/107
Epoch 90 --- loss:0.238, Epoch accuracy:91.95%, Validation loss:0.767, Validation accuracy:72.26%
Epoch 91: iteration 106/107
Epoch 91 --- loss:0.245, Epoch accuracy:91.49%, Validation loss:0.759, Validation accuracy:73.89%
Epoch 92: iteration 106/107
Epoch 92 --- loss:0.249, Epoch accuracy:91.46%, Validation loss:0.754, Validation accuracy:73.43%
Epoch 93: iteration 106/107
Epoch 93 --- loss:0.273, Epoch accuracy:89.94%, Validation loss:0.765, Validation accuracy:72.73%
Epoch 94: iteration 106/107
Epoch 94 --- loss:0.253, Epoch accuracy:91.89%, Validation loss:0.731, Validation accuracy:72.49%
Epoch 95: iteration 106/107
Epoch 95 --- loss:0.240, Epoch accuracy:91.60%, Validation loss:0.756, Validation accuracy:73.89%
Epoch 96: iteration 106/107
Epoch 96 --- loss:0.258, Epoch accuracy:91.22%, Validation loss:0.772, Validation accuracy:71.79%
Epoch 97: iteration 106/107
Epoch 97 --- loss:0.250, Epoch accuracy:91.46%, Validation loss:0.767, Validation accuracy:73.43%
Epoch 98: iteration 106/107
Epoch 98 --- loss:0.242, Epoch accuracy:91.86%, Validation loss:0.842, Validation accuracy:71.56%
Epoch 99: iteration 106/107
Epoch 99 --- loss:0.227, Epoch accuracy:92.18%, Validation loss:0.732, Validation accuracy:72.49%
Epoch 100: iteration 106/107
Epoch 100 --- loss:0.232, Epoch accuracy:91.98%, Validation loss:0.773, Validation accuracy:72.03%
Epoch 101: iteration 106/107
Epoch 101 --- loss:0.237, Epoch accuracy:91.80%, Validation loss:0.754, Validation accuracy:71.56%
Epoch 102: iteration 106/107
Epoch 102 --- loss:0.236, Epoch accuracy:92.10%, Validation loss:0.804, Validation accuracy:72.96%
Epoch 103: iteration 106/107
Epoch 103 --- loss:0.221, Epoch accuracy:92.56%, Validation loss:0.754, Validation accuracy:73.89%
Epoch 104: iteration 106/107
Epoch 104 --- loss:0.222, Epoch accuracy:92.44%, Validation loss:0.769, Validation accuracy:72.03%
Epoch 105: iteration 106/107
Epoch 105 --- loss:0.229, Epoch accuracy:92.21%, Validation loss:0.839, Validation accuracy:70.16%
Epoch 106: iteration 106/107
Epoch 106 --- loss:0.225, Epoch accuracy:91.95%, Validation loss:0.793, Validation accuracy:72.26%
Epoch 107: iteration 106/107
Epoch 107 --- loss:0.230, Epoch accuracy:92.39%, Validation loss:0.756, Validation accuracy:72.49%
Epoch 108: iteration 106/107
Epoch 108 --- loss:0.211, Epoch accuracy:93.23%, Validation loss:0.747, Validation accuracy:72.26%
Epoch 109: iteration 106/107
Epoch 109 --- loss:0.218, Epoch accuracy:92.36%, Validation loss:0.770, Validation accuracy:74.13%
Epoch 110: iteration 106/107
Epoch 110 --- loss:0.226, Epoch accuracy:92.71%, Validation loss:0.759, Validation accuracy:70.86%
Epoch 111: iteration 106/107
Epoch 111 --- loss:0.224, Epoch accuracy:92.07%, Validation loss:0.808, Validation accuracy:71.56%
Epoch 112: iteration 106/107
Epoch 112 --- loss:0.218, Epoch accuracy:92.65%, Validation loss:0.813, Validation accuracy:70.86%
Epoch 113: iteration 106/107
Epoch 113 --- loss:0.228, Epoch accuracy:91.78%, Validation loss:0.794, Validation accuracy:71.33%
Epoch 114: iteration 106/107
Epoch 114 --- loss:0.212, Epoch accuracy:93.00%, Validation loss:0.814, Validation accuracy:71.33%
Epoch 115: iteration 106/107
Epoch 115 --- loss:0.217, Epoch accuracy:92.42%, Validation loss:0.797, Validation accuracy:71.79%
Epoch 116: iteration 106/107
Epoch 116 --- loss:0.186, Epoch accuracy:93.66%, Validation loss:0.750, Validation accuracy:71.79%
Epoch 117: iteration 106/107
Epoch 117 --- loss:0.210, Epoch accuracy:92.88%, Validation loss:0.743, Validation accuracy:72.03%
Epoch 118: iteration 106/107
Epoch 118 --- loss:0.233, Epoch accuracy:91.63%, Validation loss:0.847, Validation accuracy:69.93%
Epoch 119: iteration 106/107
Epoch 119 --- loss:0.211, Epoch accuracy:92.94%, Validation loss:0.763, Validation accuracy:71.10%
Epoch 120: iteration 106/107
Epoch 120 --- loss:0.207, Epoch accuracy:93.08%, Validation loss:0.795, Validation accuracy:70.40%
Epoch 121: iteration 106/107
Epoch 121 --- loss:0.192, Epoch accuracy:93.84%, Validation loss:0.819, Validation accuracy:72.26%
Epoch 122: iteration 106/107
Epoch 122 --- loss:0.220, Epoch accuracy:92.44%, Validation loss:0.809, Validation accuracy:70.86%
Epoch 123: iteration 106/107
Epoch 123 --- loss:0.211, Epoch accuracy:92.53%, Validation loss:0.806, Validation accuracy:70.63%
Epoch 124: iteration 106/107
Epoch 124 --- loss:0.210, Epoch accuracy:92.53%, Validation loss:0.763, Validation accuracy:72.73%
Epoch 125: iteration 106/107
Epoch 125 --- loss:0.197, Epoch accuracy:93.58%, Validation loss:0.750, Validation accuracy:70.40%
Epoch 126: iteration 106/107
Epoch 126 --- loss:0.197, Epoch accuracy:93.29%, Validation loss:0.781, Validation accuracy:71.79%
Epoch 127: iteration 106/107
Epoch 127 --- loss:0.205, Epoch accuracy:93.11%, Validation loss:0.834, Validation accuracy:71.33%
Epoch 128: iteration 106/107
Epoch 128 --- loss:0.200, Epoch accuracy:93.17%, Validation loss:0.763, Validation accuracy:72.49%
Epoch 129: iteration 106/107
Epoch 129 --- loss:0.207, Epoch accuracy:93.32%, Validation loss:0.798, Validation accuracy:72.26%
Epoch 130: iteration 106/107
Epoch 130 --- loss:0.225, Epoch accuracy:92.62%, Validation loss:0.752, Validation accuracy:74.59%
Epoch 131: iteration 106/107
Epoch 131 --- loss:0.203, Epoch accuracy:93.40%, Validation loss:0.782, Validation accuracy:73.66%
Epoch 132: iteration 106/107
Epoch 132 --- loss:0.209, Epoch accuracy:93.20%, Validation loss:0.792, Validation accuracy:70.86%
Epoch 133: iteration 106/107
Epoch 133 --- loss:0.198, Epoch accuracy:93.58%, Validation loss:0.763, Validation accuracy:69.00%
Epoch 134: iteration 106/107
Epoch 134 --- loss:0.212, Epoch accuracy:93.20%, Validation loss:0.798, Validation accuracy:71.10%
Epoch 135: iteration 106/107
Epoch 135 --- loss:0.197, Epoch accuracy:93.26%, Validation loss:0.798, Validation accuracy:70.40%
Epoch 136: iteration 106/107
Epoch 136 --- loss:0.186, Epoch accuracy:93.72%, Validation loss:0.800, Validation accuracy:70.40%
Epoch 137: iteration 106/107
Epoch 137 --- loss:0.203, Epoch accuracy:92.85%, Validation loss:0.814, Validation accuracy:71.33%
Epoch 138: iteration 106/107
Epoch 138 --- loss:0.201, Epoch accuracy:92.97%, Validation loss:0.798, Validation accuracy:68.76%
Epoch 139: iteration 106/107
Epoch 139 --- loss:0.188, Epoch accuracy:93.55%, Validation loss:0.771, Validation accuracy:71.10%
Epoch 140: iteration 106/107
Epoch 140 --- loss:0.213, Epoch accuracy:92.04%, Validation loss:0.845, Validation accuracy:71.33%
Epoch 141: iteration 106/107
Epoch 141 --- loss:0.184, Epoch accuracy:94.01%, Validation loss:0.772, Validation accuracy:70.63%
Epoch 142: iteration 106/107
Epoch 142 --- loss:0.204, Epoch accuracy:92.91%, Validation loss:0.764, Validation accuracy:71.33%
Epoch 143: iteration 106/107
Epoch 143 --- loss:0.201, Epoch accuracy:92.85%, Validation loss:0.811, Validation accuracy:69.00%
Epoch 144: iteration 106/107
Epoch 144 --- loss:0.192, Epoch accuracy:93.35%, Validation loss:0.754, Validation accuracy:69.93%
Epoch 145: iteration 106/107
Epoch 145 --- loss:0.190, Epoch accuracy:93.93%, Validation loss:0.743, Validation accuracy:72.73%
Epoch 146: iteration 106/107
Epoch 146 --- loss:0.195, Epoch accuracy:93.64%, Validation loss:0.766, Validation accuracy:71.79%
Epoch 147: iteration 106/107
Epoch 147 --- loss:0.186, Epoch accuracy:94.04%, Validation loss:0.744, Validation accuracy:71.33%
Epoch 148: iteration 106/107
Epoch 148 --- loss:0.196, Epoch accuracy:93.46%, Validation loss:0.801, Validation accuracy:68.53%
Epoch 149: iteration 106/107
Epoch 149 --- loss:0.176, Epoch accuracy:93.98%, Validation loss:0.713, Validation accuracy:72.49%
Epoch 150: iteration 106/107
Epoch 150 --- loss:0.189, Epoch accuracy:93.78%, Validation loss:0.751, Validation accuracy:71.33%
Epoch 151: iteration 106/107
Epoch 151 --- loss:0.169, Epoch accuracy:94.71%, Validation loss:0.831, Validation accuracy:70.86%
Epoch 152: iteration 106/107
Epoch 152 --- loss:0.196, Epoch accuracy:93.17%, Validation loss:0.812, Validation accuracy:71.33%
Epoch 153: iteration 106/107
Epoch 153 --- loss:0.193, Epoch accuracy:93.72%, Validation loss:0.798, Validation accuracy:71.33%
Epoch 154: iteration 106/107
Epoch 154 --- loss:0.197, Epoch accuracy:93.49%, Validation loss:0.760, Validation accuracy:72.96%
Epoch 155: iteration 106/107
Epoch 155 --- loss:0.175, Epoch accuracy:94.59%, Validation loss:0.760, Validation accuracy:74.13%
Epoch 156: iteration 106/107
Epoch 156 --- loss:0.189, Epoch accuracy:93.72%, Validation loss:0.828, Validation accuracy:71.79%
Epoch 157: iteration 106/107
Epoch 157 --- loss:0.187, Epoch accuracy:93.72%, Validation loss:0.745, Validation accuracy:73.19%
Epoch 158: iteration 106/107
Epoch 158 --- loss:0.191, Epoch accuracy:93.37%, Validation loss:0.711, Validation accuracy:74.59%
Epoch 159: iteration 106/107
Epoch 159 --- loss:0.183, Epoch accuracy:94.10%, Validation loss:0.809, Validation accuracy:71.10%
Epoch 160: iteration 106/107
Epoch 160 --- loss:0.179, Epoch accuracy:93.87%, Validation loss:0.798, Validation accuracy:72.96%
Epoch 161: iteration 106/107
Epoch 161 --- loss:0.181, Epoch accuracy:94.07%, Validation loss:0.750, Validation accuracy:73.43%
Epoch 162: iteration 106/107
Epoch 162 --- loss:0.186, Epoch accuracy:93.78%, Validation loss:0.837, Validation accuracy:71.79%
Epoch 163: iteration 106/107
Epoch 163 --- loss:0.205, Epoch accuracy:93.43%, Validation loss:0.762, Validation accuracy:73.66%
Epoch 164: iteration 106/107
Epoch 164 --- loss:0.180, Epoch accuracy:94.16%, Validation loss:0.830, Validation accuracy:71.79%
Epoch 165: iteration 106/107
Epoch 165 --- loss:0.188, Epoch accuracy:93.84%, Validation loss:0.772, Validation accuracy:74.36%
Epoch 166: iteration 106/107
Epoch 166 --- loss:0.175, Epoch accuracy:94.04%, Validation loss:0.728, Validation accuracy:75.52%
Epoch 167: iteration 106/107
Epoch 167 --- loss:0.174, Epoch accuracy:94.45%, Validation loss:0.837, Validation accuracy:72.49%
Epoch 168: iteration 106/107
Epoch 168 --- loss:0.161, Epoch accuracy:94.77%, Validation loss:0.764, Validation accuracy:74.13%
Epoch 169: iteration 106/107
Epoch 169 --- loss:0.168, Epoch accuracy:94.13%, Validation loss:0.827, Validation accuracy:73.43%
Epoch 170: iteration 106/107
Epoch 170 --- loss:0.175, Epoch accuracy:94.45%, Validation loss:0.753, Validation accuracy:73.89%
Epoch 171: iteration 106/107
Epoch 171 --- loss:0.176, Epoch accuracy:94.22%, Validation loss:0.756, Validation accuracy:73.89%
Epoch 172: iteration 106/107
Epoch 172 --- loss:0.180, Epoch accuracy:93.93%, Validation loss:0.755, Validation accuracy:73.19%
Epoch 173: iteration 106/107
Epoch 173 --- loss:0.189, Epoch accuracy:93.87%, Validation loss:0.765, Validation accuracy:75.06%
Epoch 174: iteration 106/107
Epoch 174 --- loss:0.161, Epoch accuracy:94.94%, Validation loss:0.716, Validation accuracy:73.43%
Epoch 175: iteration 106/107
Epoch 175 --- loss:0.174, Epoch accuracy:93.75%, Validation loss:0.782, Validation accuracy:72.73%
Epoch 176: iteration 106/107
Epoch 176 --- loss:0.158, Epoch accuracy:95.09%, Validation loss:0.728, Validation accuracy:74.59%
Epoch 177: iteration 106/107
Epoch 177 --- loss:0.181, Epoch accuracy:94.25%, Validation loss:0.705, Validation accuracy:74.59%
Epoch 178: iteration 106/107
Epoch 178 --- loss:0.182, Epoch accuracy:93.87%, Validation loss:0.757, Validation accuracy:73.19%
Epoch 179: iteration 106/107
Epoch 179 --- loss:0.183, Epoch accuracy:93.98%, Validation loss:0.759, Validation accuracy:74.36%
Epoch 180: iteration 106/107
Epoch 180 --- loss:0.185, Epoch accuracy:94.13%, Validation loss:0.787, Validation accuracy:72.73%
Epoch 181: iteration 106/107
Epoch 181 --- loss:0.182, Epoch accuracy:93.81%, Validation loss:0.772, Validation accuracy:72.96%
Epoch 182: iteration 106/107
Epoch 182 --- loss:0.186, Epoch accuracy:94.10%, Validation loss:0.825, Validation accuracy:72.49%
Epoch 183: iteration 106/107
Epoch 183 --- loss:0.194, Epoch accuracy:93.14%, Validation loss:0.795, Validation accuracy:70.16%
Epoch 184: iteration 106/107
Epoch 184 --- loss:0.173, Epoch accuracy:94.22%, Validation loss:0.761, Validation accuracy:75.06%
Epoch 185: iteration 106/107
Epoch 185 --- loss:0.183, Epoch accuracy:94.39%, Validation loss:0.710, Validation accuracy:75.06%
Epoch 186: iteration 106/107
Epoch 186 --- loss:0.167, Epoch accuracy:94.45%, Validation loss:0.729, Validation accuracy:73.19%
Epoch 187: iteration 106/107
Epoch 187 --- loss:0.160, Epoch accuracy:94.94%, Validation loss:0.746, Validation accuracy:76.22%
Epoch 188: iteration 106/107
Epoch 188 --- loss:0.176, Epoch accuracy:94.25%, Validation loss:0.811, Validation accuracy:73.66%
Epoch 189: iteration 106/107
Epoch 189 --- loss:0.155, Epoch accuracy:95.38%, Validation loss:0.798, Validation accuracy:73.19%
Epoch 190: iteration 106/107
Epoch 190 --- loss:0.170, Epoch accuracy:94.25%, Validation loss:0.712, Validation accuracy:75.06%
Epoch 191: iteration 106/107
Epoch 191 --- loss:0.183, Epoch accuracy:93.84%, Validation loss:0.747, Validation accuracy:73.66%
Epoch 192: iteration 106/107
Epoch 192 --- loss:0.163, Epoch accuracy:94.86%, Validation loss:0.774, Validation accuracy:73.89%
Epoch 193: iteration 106/107
Epoch 193 --- loss:0.168, Epoch accuracy:94.42%, Validation loss:0.802, Validation accuracy:73.66%
Epoch 194: iteration 106/107
Epoch 194 --- loss:0.165, Epoch accuracy:94.48%, Validation loss:0.736, Validation accuracy:76.69%
Epoch 195: iteration 106/107
Epoch 195 --- loss:0.172, Epoch accuracy:94.19%, Validation loss:0.784, Validation accuracy:71.56%
Epoch 196: iteration 106/107
Epoch 196 --- loss:0.166, Epoch accuracy:94.65%, Validation loss:0.776, Validation accuracy:72.96%
Epoch 197: iteration 106/107
Epoch 197 --- loss:0.166, Epoch accuracy:94.48%, Validation loss:0.795, Validation accuracy:72.49%
Epoch 198: iteration 106/107
Epoch 198 --- loss:0.177, Epoch accuracy:93.98%, Validation loss:0.730, Validation accuracy:73.43%
Epoch 199: iteration 106/107
Epoch 199 --- loss:0.164, Epoch accuracy:94.80%, Validation loss:0.726, Validation accuracy:73.19%
Epoch 200: iteration 106/107
Epoch 200 --- loss:0.183, Epoch accuracy:94.13%, Validation loss:0.731, Validation accuracy:73.66%
Epoch 201: iteration 106/107
Epoch 201 --- loss:0.160, Epoch accuracy:94.65%, Validation loss:0.718, Validation accuracy:73.43%
Epoch 202: iteration 106/107
Epoch 202 --- loss:0.169, Epoch accuracy:94.33%, Validation loss:0.731, Validation accuracy:73.66%
Epoch 203: iteration 106/107
Epoch 203 --- loss:0.175, Epoch accuracy:94.33%, Validation loss:0.708, Validation accuracy:76.46%
Epoch 204: iteration 106/107
Epoch 204 --- loss:0.162, Epoch accuracy:94.48%, Validation loss:0.759, Validation accuracy:75.06%
Epoch 205: iteration 106/107
Epoch 205 --- loss:0.151, Epoch accuracy:95.18%, Validation loss:0.688, Validation accuracy:75.76%
Epoch 206: iteration 106/107
Epoch 206 --- loss:0.164, Epoch accuracy:94.22%, Validation loss:0.737, Validation accuracy:72.73%
Epoch 207: iteration 106/107
Epoch 207 --- loss:0.170, Epoch accuracy:94.51%, Validation loss:0.724, Validation accuracy:73.19%
Epoch 208: iteration 106/107
Epoch 208 --- loss:0.168, Epoch accuracy:94.36%, Validation loss:0.748, Validation accuracy:74.13%
Epoch 209: iteration 106/107
Epoch 209 --- loss:0.168, Epoch accuracy:94.42%, Validation loss:0.712, Validation accuracy:75.76%
Epoch 210: iteration 106/107
Epoch 210 --- loss:0.167, Epoch accuracy:94.39%, Validation loss:0.750, Validation accuracy:75.52%
Epoch 211: iteration 106/107
Epoch 211 --- loss:0.168, Epoch accuracy:94.39%, Validation loss:0.720, Validation accuracy:75.29%
Epoch 212: iteration 106/107
Epoch 212 --- loss:0.162, Epoch accuracy:94.80%, Validation loss:0.712, Validation accuracy:75.29%
Epoch 213: iteration 106/107
Epoch 213 --- loss:0.160, Epoch accuracy:94.57%, Validation loss:0.728, Validation accuracy:72.96%
Epoch 214: iteration 106/107
Epoch 214 --- loss:0.157, Epoch accuracy:95.00%, Validation loss:0.716, Validation accuracy:74.36%
Epoch 215: iteration 106/107
Epoch 215 --- loss:0.168, Epoch accuracy:94.36%, Validation loss:0.760, Validation accuracy:73.43%
Epoch 216: iteration 106/107
Epoch 216 --- loss:0.164, Epoch accuracy:94.45%, Validation loss:0.714, Validation accuracy:75.29%
Epoch 217: iteration 106/107
Epoch 217 --- loss:0.154, Epoch accuracy:94.97%, Validation loss:0.719, Validation accuracy:76.92%
Epoch 218: iteration 106/107
Epoch 218 --- loss:0.165, Epoch accuracy:94.65%, Validation loss:0.753, Validation accuracy:70.86%
Epoch 219: iteration 106/107
Epoch 219 --- loss:0.168, Epoch accuracy:94.36%, Validation loss:0.649, Validation accuracy:77.16%
Epoch 220: iteration 106/107
Epoch 220 --- loss:0.167, Epoch accuracy:94.22%, Validation loss:0.665, Validation accuracy:77.62%
Epoch 221: iteration 106/107
Epoch 221 --- loss:0.162, Epoch accuracy:94.77%, Validation loss:0.735, Validation accuracy:72.96%
Epoch 222: iteration 106/107
Epoch 222 --- loss:0.176, Epoch accuracy:93.75%, Validation loss:0.720, Validation accuracy:73.89%
Epoch 223: iteration 106/107
Epoch 223 --- loss:0.172, Epoch accuracy:94.42%, Validation loss:0.728, Validation accuracy:74.13%
Epoch 224: iteration 106/107
Epoch 224 --- loss:0.173, Epoch accuracy:94.01%, Validation loss:0.663, Validation accuracy:77.16%
Epoch 225: iteration 106/107
Epoch 225 --- loss:0.179, Epoch accuracy:94.04%, Validation loss:0.734, Validation accuracy:75.29%
Epoch 226: iteration 106/107
Epoch 226 --- loss:0.163, Epoch accuracy:94.57%, Validation loss:0.737, Validation accuracy:72.73%
Epoch 227: iteration 106/107
Epoch 227 --- loss:0.173, Epoch accuracy:94.07%, Validation loss:0.739, Validation accuracy:74.83%
Epoch 228: iteration 106/107
Epoch 228 --- loss:0.166, Epoch accuracy:94.27%, Validation loss:0.672, Validation accuracy:74.36%
Epoch 229: iteration 106/107
Epoch 229 --- loss:0.148, Epoch accuracy:95.00%, Validation loss:0.677, Validation accuracy:77.39%
Epoch 230: iteration 106/107
Epoch 230 --- loss:0.160, Epoch accuracy:94.59%, Validation loss:0.683, Validation accuracy:78.32%
Epoch 231: iteration 106/107
Epoch 231 --- loss:0.162, Epoch accuracy:94.57%, Validation loss:0.706, Validation accuracy:75.99%
Epoch 232: iteration 106/107
Epoch 232 --- loss:0.162, Epoch accuracy:94.65%, Validation loss:0.660, Validation accuracy:76.22%
Epoch 233: iteration 106/107
Epoch 233 --- loss:0.168, Epoch accuracy:94.42%, Validation loss:0.693, Validation accuracy:75.29%
Epoch 234: iteration 106/107
Epoch 234 --- loss:0.164, Epoch accuracy:94.77%, Validation loss:0.760, Validation accuracy:75.06%
Epoch 235: iteration 106/107
Epoch 235 --- loss:0.167, Epoch accuracy:94.59%, Validation loss:0.672, Validation accuracy:75.29%
Epoch 236: iteration 106/107
Epoch 236 --- loss:0.157, Epoch accuracy:94.54%, Validation loss:0.702, Validation accuracy:75.52%
Epoch 237: iteration 106/107
Epoch 237 --- loss:0.158, Epoch accuracy:95.00%, Validation loss:0.714, Validation accuracy:73.66%
Epoch 238: iteration 106/107
Epoch 238 --- loss:0.149, Epoch accuracy:95.12%, Validation loss:0.703, Validation accuracy:75.06%
Epoch 239: iteration 106/107
Epoch 239 --- loss:0.165, Epoch accuracy:94.57%, Validation loss:0.742, Validation accuracy:73.43%
Epoch 240: iteration 106/107
Epoch 240 --- loss:0.145, Epoch accuracy:94.68%, Validation loss:0.658, Validation accuracy:76.92%
Epoch 241: iteration 106/107
Epoch 241 --- loss:0.159, Epoch accuracy:95.03%, Validation loss:0.707, Validation accuracy:75.76%
Epoch 242: iteration 106/107
Epoch 242 --- loss:0.151, Epoch accuracy:95.18%, Validation loss:0.728, Validation accuracy:73.43%
Epoch 243: iteration 106/107
Epoch 243 --- loss:0.164, Epoch accuracy:94.22%, Validation loss:0.754, Validation accuracy:75.29%
Epoch 244: iteration 106/107
Epoch 244 --- loss:0.151, Epoch accuracy:95.09%, Validation loss:0.721, Validation accuracy:75.52%
Epoch 245: iteration 106/107
Epoch 245 --- loss:0.153, Epoch accuracy:94.89%, Validation loss:0.688, Validation accuracy:74.83%
Epoch 246: iteration 106/107
Epoch 246 --- loss:0.160, Epoch accuracy:94.74%, Validation loss:0.686, Validation accuracy:73.89%
Epoch 247: iteration 106/107
Epoch 247 --- loss:0.156, Epoch accuracy:94.97%, Validation loss:0.719, Validation accuracy:74.59%
Epoch 248: iteration 106/107
Epoch 248 --- loss:0.162, Epoch accuracy:94.91%, Validation loss:0.693, Validation accuracy:76.92%
Epoch 249: iteration 106/107
Epoch 249 --- loss:0.167, Epoch accuracy:94.19%, Validation loss:0.682, Validation accuracy:75.76%
Epoch 250: iteration 106/107
Epoch 250 --- loss:0.155, Epoch accuracy:94.62%, Validation loss:0.694, Validation accuracy:73.43%
Epoch 251: iteration 106/107
Epoch 251 --- loss:0.150, Epoch accuracy:94.74%, Validation loss:0.730, Validation accuracy:74.59%
Epoch 252: iteration 106/107
Epoch 252 --- loss:0.145, Epoch accuracy:95.38%, Validation loss:0.715, Validation accuracy:74.36%
Epoch 253: iteration 106/107
Epoch 253 --- loss:0.172, Epoch accuracy:94.33%, Validation loss:0.705, Validation accuracy:72.49%
Epoch 254: iteration 106/107
Epoch 254 --- loss:0.164, Epoch accuracy:94.39%, Validation loss:0.693, Validation accuracy:73.66%
Epoch 255: iteration 106/107
Epoch 255 --- loss:0.160, Epoch accuracy:94.77%, Validation loss:0.705, Validation accuracy:75.29%
Epoch 256: iteration 106/107
Epoch 256 --- loss:0.158, Epoch accuracy:94.80%, Validation loss:0.722, Validation accuracy:74.59%
Epoch 257: iteration 106/107
Epoch 257 --- loss:0.155, Epoch accuracy:94.80%, Validation loss:0.692, Validation accuracy:74.83%
Epoch 258: iteration 106/107
Epoch 258 --- loss:0.152, Epoch accuracy:95.15%, Validation loss:0.644, Validation accuracy:76.46%
Epoch 259: iteration 106/107
Epoch 259 --- loss:0.157, Epoch accuracy:94.71%, Validation loss:0.687, Validation accuracy:75.29%
Epoch 260: iteration 106/107
Epoch 260 --- loss:0.170, Epoch accuracy:94.42%, Validation loss:0.694, Validation accuracy:75.29%
Epoch 261: iteration 106/107
Epoch 261 --- loss:0.148, Epoch accuracy:95.32%, Validation loss:0.673, Validation accuracy:76.69%
Epoch 262: iteration 106/107
Epoch 262 --- loss:0.157, Epoch accuracy:94.97%, Validation loss:0.757, Validation accuracy:73.19%
Epoch 263: iteration 106/107
Epoch 263 --- loss:0.159, Epoch accuracy:94.74%, Validation loss:0.766, Validation accuracy:72.73%
Epoch 264: iteration 106/107
Epoch 264 --- loss:0.168, Epoch accuracy:94.10%, Validation loss:0.763, Validation accuracy:72.96%
Epoch 265: iteration 106/107
Epoch 265 --- loss:0.147, Epoch accuracy:95.32%, Validation loss:0.675, Validation accuracy:73.89%
Epoch 266: iteration 106/107
Epoch 266 --- loss:0.153, Epoch accuracy:95.06%, Validation loss:0.744, Validation accuracy:75.06%
Epoch 267: iteration 106/107
Epoch 267 --- loss:0.147, Epoch accuracy:95.00%, Validation loss:0.720, Validation accuracy:72.96%
Epoch 268: iteration 106/107
Epoch 268 --- loss:0.164, Epoch accuracy:94.54%, Validation loss:0.704, Validation accuracy:74.36%
Epoch 269: iteration 106/107
Epoch 269 --- loss:0.177, Epoch accuracy:94.04%, Validation loss:0.683, Validation accuracy:74.59%
Epoch 270: iteration 106/107
Epoch 270 --- loss:0.152, Epoch accuracy:95.12%, Validation loss:0.700, Validation accuracy:75.06%
Epoch 271: iteration 106/107
Epoch 271 --- loss:0.170, Epoch accuracy:94.01%, Validation loss:0.798, Validation accuracy:71.10%
Epoch 272: iteration 106/107
Epoch 272 --- loss:0.140, Epoch accuracy:95.58%, Validation loss:0.690, Validation accuracy:76.22%
Epoch 273: iteration 106/107
Epoch 273 --- loss:0.152, Epoch accuracy:94.65%, Validation loss:0.776, Validation accuracy:72.96%
Epoch 274: iteration 106/107
Epoch 274 --- loss:0.155, Epoch accuracy:94.83%, Validation loss:0.691, Validation accuracy:75.52%
Epoch 275: iteration 106/107
Epoch 275 --- loss:0.148, Epoch accuracy:95.23%, Validation loss:0.718, Validation accuracy:75.76%
Epoch 276: iteration 106/107
Epoch 276 --- loss:0.158, Epoch accuracy:94.74%, Validation loss:0.697, Validation accuracy:75.99%
Epoch 277: iteration 106/107
Epoch 277 --- loss:0.166, Epoch accuracy:94.59%, Validation loss:0.702, Validation accuracy:77.16%
Epoch 278: iteration 106/107
Epoch 278 --- loss:0.163, Epoch accuracy:94.36%, Validation loss:0.693, Validation accuracy:74.13%
Epoch 279: iteration 106/107
Epoch 279 --- loss:0.164, Epoch accuracy:94.86%, Validation loss:0.700, Validation accuracy:76.92%
Epoch 280: iteration 106/107
Epoch 280 --- loss:0.147, Epoch accuracy:95.44%, Validation loss:0.695, Validation accuracy:75.29%
Epoch 281: iteration 106/107
Epoch 281 --- loss:0.143, Epoch accuracy:95.20%, Validation loss:0.690, Validation accuracy:75.52%
Epoch 282: iteration 106/107
Epoch 282 --- loss:0.135, Epoch accuracy:95.73%, Validation loss:0.697, Validation accuracy:75.76%
Epoch 283: iteration 106/107
Epoch 283 --- loss:0.137, Epoch accuracy:95.47%, Validation loss:0.662, Validation accuracy:76.46%
Epoch 284: iteration 106/107
Epoch 284 --- loss:0.153, Epoch accuracy:94.71%, Validation loss:0.733, Validation accuracy:75.06%
Epoch 285: iteration 106/107
Epoch 285 --- loss:0.140, Epoch accuracy:95.06%, Validation loss:0.708, Validation accuracy:75.06%
Epoch 286: iteration 106/107
Epoch 286 --- loss:0.145, Epoch accuracy:95.41%, Validation loss:0.899, Validation accuracy:67.83%
Epoch 287: iteration 106/107
Epoch 287 --- loss:0.164, Epoch accuracy:94.30%, Validation loss:0.759, Validation accuracy:72.73%
Epoch 288: iteration 106/107
Epoch 288 --- loss:0.151, Epoch accuracy:95.06%, Validation loss:0.687, Validation accuracy:75.52%
Epoch 289: iteration 106/107
Epoch 289 --- loss:0.156, Epoch accuracy:94.74%, Validation loss:0.720, Validation accuracy:76.46%
Epoch 290: iteration 106/107
Epoch 290 --- loss:0.150, Epoch accuracy:94.97%, Validation loss:0.755, Validation accuracy:72.73%
Epoch 291: iteration 106/107
Epoch 291 --- loss:0.169, Epoch accuracy:94.45%, Validation loss:0.700, Validation accuracy:76.46%
Epoch 292: iteration 106/107
Epoch 292 --- loss:0.162, Epoch accuracy:94.57%, Validation loss:0.676, Validation accuracy:77.86%
Epoch 293: iteration 106/107
Epoch 293 --- loss:0.154, Epoch accuracy:94.89%, Validation loss:0.723, Validation accuracy:72.96%
Epoch 294: iteration 106/107
Epoch 294 --- loss:0.156, Epoch accuracy:95.12%, Validation loss:0.723, Validation accuracy:75.52%
Epoch 295: iteration 106/107
Epoch 295 --- loss:0.160, Epoch accuracy:94.97%, Validation loss:0.674, Validation accuracy:75.99%
Epoch 296: iteration 106/107
Epoch 296 --- loss:0.165, Epoch accuracy:94.10%, Validation loss:0.733, Validation accuracy:74.83%
Epoch 297: iteration 106/107
Epoch 297 --- loss:0.145, Epoch accuracy:95.64%, Validation loss:0.707, Validation accuracy:75.06%
Epoch 298: iteration 106/107
Epoch 298 --- loss:0.155, Epoch accuracy:94.94%, Validation loss:0.720, Validation accuracy:74.83%
Epoch 299: iteration 106/107
Epoch 299 --- loss:0.150, Epoch accuracy:95.18%, Validation loss:0.748, Validation accuracy:72.49%
Epoch 300: iteration 106/107
Epoch 300 --- loss:0.148, Epoch accuracy:94.74%, Validation loss:0.714, Validation accuracy:74.59%
Epoch 301: iteration 106/107
Epoch 301 --- loss:0.137, Epoch accuracy:95.52%, Validation loss:0.694, Validation accuracy:73.89%
Epoch 302: iteration 106/107
Epoch 302 --- loss:0.149, Epoch accuracy:94.62%, Validation loss:0.667, Validation accuracy:74.59%
Epoch 303: iteration 106/107
Epoch 303 --- loss:0.151, Epoch accuracy:94.89%, Validation loss:0.645, Validation accuracy:77.39%
Epoch 304: iteration 106/107
Epoch 304 --- loss:0.142, Epoch accuracy:95.09%, Validation loss:0.658, Validation accuracy:75.76%
Epoch 305: iteration 106/107
Epoch 305 --- loss:0.147, Epoch accuracy:95.15%, Validation loss:0.649, Validation accuracy:75.29%
Epoch 306: iteration 106/107
Epoch 306 --- loss:0.140, Epoch accuracy:95.50%, Validation loss:0.659, Validation accuracy:76.22%
Epoch 307: iteration 106/107
Epoch 307 --- loss:0.169, Epoch accuracy:93.98%, Validation loss:0.709, Validation accuracy:76.92%
Epoch 308: iteration 106/107
Epoch 308 --- loss:0.150, Epoch accuracy:95.03%, Validation loss:0.728, Validation accuracy:73.89%
Epoch 309: iteration 106/107
Epoch 309 --- loss:0.160, Epoch accuracy:94.62%, Validation loss:0.704, Validation accuracy:75.76%
Epoch 310: iteration 106/107
Epoch 310 --- loss:0.158, Epoch accuracy:94.77%, Validation loss:0.684, Validation accuracy:76.22%
Epoch 311: iteration 106/107
Epoch 311 --- loss:0.141, Epoch accuracy:95.67%, Validation loss:0.656, Validation accuracy:76.92%
Epoch 312: iteration 106/107
Epoch 312 --- loss:0.151, Epoch accuracy:95.12%, Validation loss:0.692, Validation accuracy:77.39%
Epoch 313: iteration 106/107
Epoch 313 --- loss:0.157, Epoch accuracy:94.65%, Validation loss:0.708, Validation accuracy:75.52%
Epoch 314: iteration 106/107
Epoch 314 --- loss:0.139, Epoch accuracy:95.18%, Validation loss:0.671, Validation accuracy:76.92%
Epoch 315: iteration 106/107
Epoch 315 --- loss:0.146, Epoch accuracy:95.23%, Validation loss:0.749, Validation accuracy:72.26%
Epoch 316: iteration 106/107
Epoch 316 --- loss:0.145, Epoch accuracy:95.15%, Validation loss:0.666, Validation accuracy:77.62%
Epoch 317: iteration 106/107
Epoch 317 --- loss:0.149, Epoch accuracy:94.71%, Validation loss:0.688, Validation accuracy:78.09%
Epoch 318: iteration 106/107
Epoch 318 --- loss:0.160, Epoch accuracy:94.86%, Validation loss:0.664, Validation accuracy:75.52%
Epoch 319: iteration 106/107
Epoch 319 --- loss:0.150, Epoch accuracy:94.91%, Validation loss:0.709, Validation accuracy:75.29%
Epoch 320: iteration 106/107
Epoch 320 --- loss:0.144, Epoch accuracy:95.06%, Validation loss:0.709, Validation accuracy:75.29%
Epoch 321: iteration 106/107
Epoch 321 --- loss:0.161, Epoch accuracy:94.89%, Validation loss:0.711, Validation accuracy:72.96%
Epoch 322: iteration 106/107
Epoch 322 --- loss:0.159, Epoch accuracy:94.65%, Validation loss:0.707, Validation accuracy:73.43%
Epoch 323: iteration 106/107
Epoch 323 --- loss:0.145, Epoch accuracy:95.67%, Validation loss:0.767, Validation accuracy:74.13%
Epoch 324: iteration 106/107
Epoch 324 --- loss:0.148, Epoch accuracy:94.74%, Validation loss:0.680, Validation accuracy:76.46%
Epoch 325: iteration 106/107
Epoch 325 --- loss:0.143, Epoch accuracy:95.76%, Validation loss:0.711, Validation accuracy:74.59%
Epoch 326: iteration 106/107
Epoch 326 --- loss:0.165, Epoch accuracy:94.27%, Validation loss:0.767, Validation accuracy:75.29%
Epoch 327: iteration 106/107
Epoch 327 --- loss:0.156, Epoch accuracy:94.77%, Validation loss:0.789, Validation accuracy:73.19%
Epoch 328: iteration 106/107
Epoch 328 --- loss:0.145, Epoch accuracy:95.38%, Validation loss:0.718, Validation accuracy:77.39%
Epoch 329: iteration 106/107
Epoch 329 --- loss:0.146, Epoch accuracy:95.03%, Validation loss:0.792, Validation accuracy:74.59%
Epoch 330: iteration 106/107
Epoch 330 --- loss:0.161, Epoch accuracy:95.03%, Validation loss:0.675, Validation accuracy:77.62%
Epoch 331: iteration 106/107
Epoch 331 --- loss:0.138, Epoch accuracy:95.58%, Validation loss:0.716, Validation accuracy:74.13%
Epoch 332: iteration 106/107
Epoch 332 --- loss:0.144, Epoch accuracy:95.44%, Validation loss:0.674, Validation accuracy:76.69%
Epoch 333: iteration 106/107
Epoch 333 --- loss:0.133, Epoch accuracy:95.67%, Validation loss:0.722, Validation accuracy:73.19%
Epoch 334: iteration 106/107
Epoch 334 --- loss:0.146, Epoch accuracy:95.26%, Validation loss:0.773, Validation accuracy:74.59%
Epoch 335: iteration 106/107
Epoch 335 --- loss:0.129, Epoch accuracy:95.67%, Validation loss:0.718, Validation accuracy:74.59%
Epoch 336: iteration 106/107
Epoch 336 --- loss:0.139, Epoch accuracy:95.26%, Validation loss:0.723, Validation accuracy:75.99%
Epoch 337: iteration 106/107
Epoch 337 --- loss:0.153, Epoch accuracy:94.89%, Validation loss:0.684, Validation accuracy:73.89%
Epoch 338: iteration 106/107
Epoch 338 --- loss:0.148, Epoch accuracy:95.06%, Validation loss:0.666, Validation accuracy:76.92%
Epoch 339: iteration 106/107
Epoch 339 --- loss:0.129, Epoch accuracy:95.52%, Validation loss:0.641, Validation accuracy:76.92%
Epoch 340: iteration 106/107
Epoch 340 --- loss:0.141, Epoch accuracy:95.41%, Validation loss:0.747, Validation accuracy:73.66%
Epoch 341: iteration 106/107
Epoch 341 --- loss:0.162, Epoch accuracy:94.89%, Validation loss:0.670, Validation accuracy:76.46%
Epoch 342: iteration 106/107
Epoch 342 --- loss:0.163, Epoch accuracy:94.36%, Validation loss:0.647, Validation accuracy:77.16%
Epoch 343: iteration 106/107
Epoch 343 --- loss:0.143, Epoch accuracy:95.52%, Validation loss:0.693, Validation accuracy:75.06%
Epoch 344: iteration 106/107
Epoch 344 --- loss:0.151, Epoch accuracy:94.83%, Validation loss:0.662, Validation accuracy:77.16%
Epoch 345: iteration 106/107
Epoch 345 --- loss:0.156, Epoch accuracy:95.00%, Validation loss:0.687, Validation accuracy:77.16%
Epoch 346: iteration 106/107
Epoch 346 --- loss:0.164, Epoch accuracy:94.33%, Validation loss:0.696, Validation accuracy:75.76%
Epoch 347: iteration 106/107
Epoch 347 --- loss:0.133, Epoch accuracy:95.73%, Validation loss:0.643, Validation accuracy:76.69%
Epoch 348: iteration 106/107
Epoch 348 --- loss:0.135, Epoch accuracy:95.61%, Validation loss:0.674, Validation accuracy:75.99%
Epoch 349: iteration 106/107
Epoch 349 --- loss:0.148, Epoch accuracy:95.09%, Validation loss:0.674, Validation accuracy:75.29%
Epoch 350: iteration 106/107
Epoch 350 --- loss:0.142, Epoch accuracy:94.91%, Validation loss:0.690, Validation accuracy:75.52%
Epoch 351: iteration 106/107
Epoch 351 --- loss:0.154, Epoch accuracy:94.94%, Validation loss:0.660, Validation accuracy:75.29%
Epoch 352: iteration 106/107
Epoch 352 --- loss:0.139, Epoch accuracy:95.64%, Validation loss:0.665, Validation accuracy:74.83%
Epoch 353: iteration 106/107
Epoch 353 --- loss:0.146, Epoch accuracy:95.35%, Validation loss:0.673, Validation accuracy:75.06%
Epoch 354: iteration 106/107
Epoch 354 --- loss:0.150, Epoch accuracy:94.77%, Validation loss:0.665, Validation accuracy:75.76%
Epoch 355: iteration 106/107
Epoch 355 --- loss:0.134, Epoch accuracy:95.55%, Validation loss:0.653, Validation accuracy:77.16%
Epoch 356: iteration 106/107
Epoch 356 --- loss:0.149, Epoch accuracy:94.86%, Validation loss:0.645, Validation accuracy:75.06%
Epoch 357: iteration 106/107
Epoch 357 --- loss:0.136, Epoch accuracy:95.47%, Validation loss:0.724, Validation accuracy:74.59%
Epoch 358: iteration 106/107
Epoch 358 --- loss:0.144, Epoch accuracy:95.06%, Validation loss:0.759, Validation accuracy:71.79%
Epoch 359: iteration 106/107
Epoch 359 --- loss:0.142, Epoch accuracy:95.15%, Validation loss:0.707, Validation accuracy:75.76%
Epoch 360: iteration 106/107
Epoch 360 --- loss:0.153, Epoch accuracy:94.97%, Validation loss:0.746, Validation accuracy:75.06%
Epoch 361: iteration 106/107
Epoch 361 --- loss:0.144, Epoch accuracy:95.00%, Validation loss:0.697, Validation accuracy:74.59%
Epoch 362: iteration 106/107
Epoch 362 --- loss:0.141, Epoch accuracy:95.58%, Validation loss:0.698, Validation accuracy:73.89%
Epoch 363: iteration 106/107
Epoch 363 --- loss:0.133, Epoch accuracy:95.76%, Validation loss:0.659, Validation accuracy:73.66%
Epoch 364: iteration 106/107
Epoch 364 --- loss:0.142, Epoch accuracy:95.29%, Validation loss:0.672, Validation accuracy:76.46%
Epoch 365: iteration 106/107
Epoch 365 --- loss:0.143, Epoch accuracy:95.26%, Validation loss:0.684, Validation accuracy:75.52%
Epoch 366: iteration 106/107
Epoch 366 --- loss:0.148, Epoch accuracy:95.12%, Validation loss:0.673, Validation accuracy:77.39%
Epoch 367: iteration 106/107
Epoch 367 --- loss:0.147, Epoch accuracy:94.86%, Validation loss:0.685, Validation accuracy:75.99%
Epoch 368: iteration 106/107
Epoch 368 --- loss:0.142, Epoch accuracy:95.50%, Validation loss:0.641, Validation accuracy:78.79%
Epoch 369: iteration 106/107
Epoch 369 --- loss:0.141, Epoch accuracy:95.26%, Validation loss:0.671, Validation accuracy:76.92%
Epoch 370: iteration 106/107
Epoch 370 --- loss:0.132, Epoch accuracy:95.70%, Validation loss:0.669, Validation accuracy:76.69%
Epoch 371: iteration 106/107
Epoch 371 --- loss:0.141, Epoch accuracy:95.26%, Validation loss:0.666, Validation accuracy:76.22%
Epoch 372: iteration 106/107
Epoch 372 --- loss:0.141, Epoch accuracy:95.50%, Validation loss:0.652, Validation accuracy:77.86%
Epoch 373: iteration 106/107
Epoch 373 --- loss:0.131, Epoch accuracy:95.41%, Validation loss:0.646, Validation accuracy:76.92%
Epoch 374: iteration 106/107
Epoch 374 --- loss:0.144, Epoch accuracy:95.03%, Validation loss:0.688, Validation accuracy:77.62%
Epoch 375: iteration 106/107
Epoch 375 --- loss:0.144, Epoch accuracy:95.52%, Validation loss:0.665, Validation accuracy:78.32%
Epoch 376: iteration 106/107
Epoch 376 --- loss:0.156, Epoch accuracy:94.89%, Validation loss:0.707, Validation accuracy:74.83%
Epoch 377: iteration 106/107
Epoch 377 --- loss:0.159, Epoch accuracy:94.13%, Validation loss:0.743, Validation accuracy:72.49%
Epoch 378: iteration 106/107
Epoch 378 --- loss:0.154, Epoch accuracy:95.18%, Validation loss:0.716, Validation accuracy:75.52%
Epoch 379: iteration 106/107
Epoch 379 --- loss:0.141, Epoch accuracy:95.44%, Validation loss:0.690, Validation accuracy:73.89%
Epoch 380: iteration 106/107
Epoch 380 --- loss:0.143, Epoch accuracy:95.20%, Validation loss:0.677, Validation accuracy:75.52%
Epoch 381: iteration 106/107
Epoch 381 --- loss:0.140, Epoch accuracy:95.32%, Validation loss:0.700, Validation accuracy:73.43%
Epoch 382: iteration 106/107
Epoch 382 --- loss:0.127, Epoch accuracy:96.08%, Validation loss:0.660, Validation accuracy:76.22%
Epoch 383: iteration 106/107
Epoch 383 --- loss:0.137, Epoch accuracy:95.15%, Validation loss:0.686, Validation accuracy:75.06%
Epoch 384: iteration 106/107
Epoch 384 --- loss:0.140, Epoch accuracy:95.12%, Validation loss:0.697, Validation accuracy:74.59%
Epoch 385: iteration 106/107
Epoch 385 --- loss:0.145, Epoch accuracy:95.32%, Validation loss:0.705, Validation accuracy:75.29%
Epoch 386: iteration 106/107
Epoch 386 --- loss:0.146, Epoch accuracy:94.77%, Validation loss:0.692, Validation accuracy:75.76%
Epoch 387: iteration 106/107
Epoch 387 --- loss:0.133, Epoch accuracy:95.61%, Validation loss:0.721, Validation accuracy:75.76%
Epoch 388: iteration 106/107
Epoch 388 --- loss:0.147, Epoch accuracy:95.12%, Validation loss:0.707, Validation accuracy:75.29%
Epoch 389: iteration 106/107
Epoch 389 --- loss:0.139, Epoch accuracy:95.18%, Validation loss:0.691, Validation accuracy:73.89%
Epoch 390: iteration 106/107
Epoch 390 --- loss:0.148, Epoch accuracy:94.89%, Validation loss:0.730, Validation accuracy:73.19%
Epoch 391: iteration 106/107
Epoch 391 --- loss:0.130, Epoch accuracy:95.96%, Validation loss:0.660, Validation accuracy:76.46%
Epoch 392: iteration 106/107
Epoch 392 --- loss:0.138, Epoch accuracy:95.35%, Validation loss:0.694, Validation accuracy:74.36%
Epoch 393: iteration 106/107
Epoch 393 --- loss:0.143, Epoch accuracy:95.12%, Validation loss:0.695, Validation accuracy:74.36%
Epoch 394: iteration 106/107
Epoch 394 --- loss:0.147, Epoch accuracy:95.15%, Validation loss:0.731, Validation accuracy:74.13%
Epoch 395: iteration 106/107
Epoch 395 --- loss:0.136, Epoch accuracy:95.58%, Validation loss:0.663, Validation accuracy:76.46%
Epoch 396: iteration 106/107
Epoch 396 --- loss:0.134, Epoch accuracy:95.67%, Validation loss:0.671, Validation accuracy:75.52%
Epoch 397: iteration 106/107
Epoch 397 --- loss:0.151, Epoch accuracy:94.91%, Validation loss:0.647, Validation accuracy:77.62%
Epoch 398: iteration 106/107
Epoch 398 --- loss:0.147, Epoch accuracy:95.41%, Validation loss:0.725, Validation accuracy:76.69%
Epoch 399: iteration 106/107
Epoch 399 --- loss:0.126, Epoch accuracy:95.90%, Validation loss:0.655, Validation accuracy:77.39%
Epoch 400: iteration 106/107
Epoch 400 --- loss:0.143, Epoch accuracy:95.03%, Validation loss:0.694, Validation accuracy:73.89%
Epoch 401: iteration 106/107
Epoch 401 --- loss:0.140, Epoch accuracy:95.67%, Validation loss:0.707, Validation accuracy:75.76%
Epoch 402: iteration 106/107
Epoch 402 --- loss:0.141, Epoch accuracy:95.52%, Validation loss:0.724, Validation accuracy:75.29%
Epoch 403: iteration 106/107
Epoch 403 --- loss:0.141, Epoch accuracy:95.23%, Validation loss:0.734, Validation accuracy:75.52%
Epoch 404: iteration 106/107
Epoch 404 --- loss:0.140, Epoch accuracy:95.41%, Validation loss:0.643, Validation accuracy:77.16%
Epoch 405: iteration 106/107
Epoch 405 --- loss:0.136, Epoch accuracy:95.47%, Validation loss:0.696, Validation accuracy:75.76%
Epoch 406: iteration 106/107
Epoch 406 --- loss:0.145, Epoch accuracy:95.41%, Validation loss:0.718, Validation accuracy:73.19%
Epoch 407: iteration 106/107
Epoch 407 --- loss:0.138, Epoch accuracy:95.58%, Validation loss:0.645, Validation accuracy:78.09%
Epoch 408: iteration 106/107
Epoch 408 --- loss:0.135, Epoch accuracy:95.50%, Validation loss:0.717, Validation accuracy:75.52%
Epoch 409: iteration 106/107
Epoch 409 --- loss:0.150, Epoch accuracy:95.12%, Validation loss:0.700, Validation accuracy:75.06%
Epoch 410: iteration 106/107
Epoch 410 --- loss:0.148, Epoch accuracy:95.23%, Validation loss:0.693, Validation accuracy:76.22%
Epoch 411: iteration 106/107
Epoch 411 --- loss:0.149, Epoch accuracy:95.20%, Validation loss:0.691, Validation accuracy:74.36%
Epoch 412: iteration 106/107
Epoch 412 --- loss:0.142, Epoch accuracy:95.32%, Validation loss:0.664, Validation accuracy:75.99%
Epoch 413: iteration 106/107
Epoch 413 --- loss:0.135, Epoch accuracy:95.73%, Validation loss:0.631, Validation accuracy:77.62%
Epoch 414: iteration 106/107
Epoch 414 --- loss:0.137, Epoch accuracy:95.26%, Validation loss:0.700, Validation accuracy:76.22%
Epoch 415: iteration 106/107
Epoch 415 --- loss:0.136, Epoch accuracy:95.58%, Validation loss:0.622, Validation accuracy:76.69%
Epoch 416: iteration 106/107
Epoch 416 --- loss:0.141, Epoch accuracy:95.23%, Validation loss:0.706, Validation accuracy:75.99%
Epoch 417: iteration 106/107
Epoch 417 --- loss:0.127, Epoch accuracy:96.08%, Validation loss:0.708, Validation accuracy:77.16%
Epoch 418: iteration 106/107
Epoch 418 --- loss:0.133, Epoch accuracy:95.70%, Validation loss:0.703, Validation accuracy:74.59%
Epoch 419: iteration 106/107
Epoch 419 --- loss:0.129, Epoch accuracy:95.67%, Validation loss:0.664, Validation accuracy:78.09%
Epoch 420: iteration 106/107
Epoch 420 --- loss:0.135, Epoch accuracy:95.52%, Validation loss:0.660, Validation accuracy:76.92%
Epoch 421: iteration 106/107
Epoch 421 --- loss:0.140, Epoch accuracy:95.15%, Validation loss:0.818, Validation accuracy:73.89%
Epoch 422: iteration 106/107
Epoch 422 --- loss:0.149, Epoch accuracy:95.00%, Validation loss:0.682, Validation accuracy:76.69%
Epoch 423: iteration 106/107
Epoch 423 --- loss:0.154, Epoch accuracy:95.20%, Validation loss:0.701, Validation accuracy:76.69%
Epoch 424: iteration 106/107
Epoch 424 --- loss:0.144, Epoch accuracy:95.47%, Validation loss:0.707, Validation accuracy:77.39%
Epoch 425: iteration 106/107
Epoch 425 --- loss:0.151, Epoch accuracy:94.91%, Validation loss:0.674, Validation accuracy:76.69%
Epoch 426: iteration 106/107
Epoch 426 --- loss:0.129, Epoch accuracy:95.58%, Validation loss:0.693, Validation accuracy:76.46%
Epoch 427: iteration 106/107
Epoch 427 --- loss:0.134, Epoch accuracy:95.52%, Validation loss:0.672, Validation accuracy:76.46%
Epoch 428: iteration 106/107
Epoch 428 --- loss:0.127, Epoch accuracy:95.84%, Validation loss:0.660, Validation accuracy:75.29%
Epoch 429: iteration 106/107
Epoch 429 --- loss:0.146, Epoch accuracy:94.94%, Validation loss:0.661, Validation accuracy:79.72%
Epoch 430: iteration 106/107
Epoch 430 --- loss:0.143, Epoch accuracy:95.52%, Validation loss:0.677, Validation accuracy:77.16%
Epoch 431: iteration 106/107
Epoch 431 --- loss:0.153, Epoch accuracy:95.47%, Validation loss:0.705, Validation accuracy:75.29%
Epoch 432: iteration 106/107
Epoch 432 --- loss:0.123, Epoch accuracy:96.05%, Validation loss:0.686, Validation accuracy:78.55%
Epoch 433: iteration 106/107
Epoch 433 --- loss:0.152, Epoch accuracy:95.03%, Validation loss:0.690, Validation accuracy:76.69%
Epoch 434: iteration 106/107
Epoch 434 --- loss:0.133, Epoch accuracy:95.61%, Validation loss:0.648, Validation accuracy:79.95%
Epoch 435: iteration 106/107
Epoch 435 --- loss:0.137, Epoch accuracy:96.02%, Validation loss:0.719, Validation accuracy:75.99%
Epoch 436: iteration 106/107
Epoch 436 --- loss:0.150, Epoch accuracy:95.00%, Validation loss:0.727, Validation accuracy:76.69%
Epoch 437: iteration 106/107
Epoch 437 --- loss:0.136, Epoch accuracy:95.64%, Validation loss:0.685, Validation accuracy:77.39%
Epoch 438: iteration 106/107
Epoch 438 --- loss:0.150, Epoch accuracy:94.51%, Validation loss:0.709, Validation accuracy:75.52%
Epoch 439: iteration 106/107
Epoch 439 --- loss:0.151, Epoch accuracy:95.03%, Validation loss:0.660, Validation accuracy:78.79%
Epoch 440: iteration 106/107
Epoch 440 --- loss:0.139, Epoch accuracy:95.44%, Validation loss:0.679, Validation accuracy:79.02%
Epoch 441: iteration 106/107
Epoch 441 --- loss:0.142, Epoch accuracy:95.52%, Validation loss:0.709, Validation accuracy:76.69%
Epoch 442: iteration 106/107
Epoch 442 --- loss:0.120, Epoch accuracy:96.16%, Validation loss:0.754, Validation accuracy:76.46%
Epoch 443: iteration 106/107
Epoch 443 --- loss:0.144, Epoch accuracy:95.32%, Validation loss:0.721, Validation accuracy:73.43%
Epoch 444: iteration 106/107
Epoch 444 --- loss:0.148, Epoch accuracy:94.91%, Validation loss:0.676, Validation accuracy:75.99%
Epoch 445: iteration 106/107
Epoch 445 --- loss:0.146, Epoch accuracy:95.15%, Validation loss:0.706, Validation accuracy:76.69%
Epoch 446: iteration 106/107
Epoch 446 --- loss:0.149, Epoch accuracy:95.20%, Validation loss:0.633, Validation accuracy:78.55%
Epoch 447: iteration 48/107
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
<ipython-input-23-d14eb4f1b628> in <module>()
3
4 # train it!
----> 5 train(optimizer, model, num_epochs, X_train, y_train, X_valid, y_valid)
<ipython-input-22-3b155e61bacc> in train(optimizer, model, num_epochs, X_train, Y_train, X_valid, Y_valid)
72
73 # Pass input tensors thru 1 training step (fwd+backwards pass)
---> 74 loss, acc = train_step(X_tensor,Y_tensor)
75
76 # aggregate batch accuracy to measure progress of entire epoch
<ipython-input-19-72eaed1e66fd> in train_step(X, Y)
6
7 # forward pass
----> 8 output_logits, output_softmax = model(X)
9 predictions = torch.argmax(output_softmax,dim=1)
10 accuracy = torch.sum(Y==predictions)/float(len(Y))
/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
<ipython-input-15-3e7c192fbfc0> in forward(self, x)
130 # create final feature embedding from 1st convolutional layer
131 # input features pased through 4 sequential 2D convolutional layers
--> 132 conv2d_embedding1 = self.conv2Dblock1(x) # x == N/batch * channel * freq * time
133
134 # flatten final 64*1*4 feature map from convolutional layers to length 256 1D array
/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
/usr/local/lib/python3.6/dist-packages/torch/nn/modules/container.py in forward(self, input)
115 def forward(self, input):
116 for module in self:
--> 117 input = module(input)
118 return input
119
/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
720 result = self._slow_forward(*input, **kwargs)
721 else:
--> 722 result = self.forward(*input, **kwargs)
723 for hook in itertools.chain(
724 _global_forward_hooks.values(),
/usr/local/lib/python3.6/dist-packages/torch/nn/modules/batchnorm.py in forward(self, input)
134 self.running_mean if not self.training or self.track_running_stats else None,
135 self.running_var if not self.training or self.track_running_stats else None,
--> 136 self.weight, self.bias, bn_training, exponential_average_factor, self.eps)
137
138
/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py in __getattr__(self, name)
756 self._load_state_dict_pre_hooks = OrderedDict()
757
--> 758 def __getattr__(self, name: str) -> Union[Tensor, 'Module']:
759 if '_parameters' in self.__dict__:
760 _parameters = self.__dict__['_parameters']
KeyboardInterrupt:
检查 Loss Curve 的行为
让我们看看我们在训练过程中是否遗漏了什么令人震惊的事情。请注意,验证集实现了 78-82% 的准确率,具体取决于数据的随机拆分(调整后检查;在调整模型时,在拆分数据之前指定了随机种子)。
plt.title('Loss Curve for Parallel is All You Want Model')
plt.ylabel('Loss', fontsize=16)
plt.xlabel('Epoch', fontsize=16)
plt.plot(train_losses[:],'b')
plt.plot(valid_losses[:],'r')
plt.legend(['Training loss','Validation loss'])
plt.show()
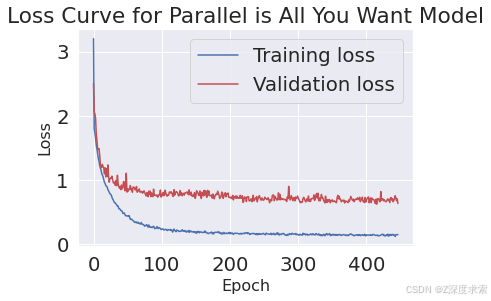
看起来不错。验证准确率超过约 78% 时,模型开始在训练集上过拟合。请注意,我运行最终模型的时间超过了必要的时间(500 个 epoch/20 分钟,而在 Google Colab 的 K80 上训练收敛需要 200 个 epoch/8 分钟)。
从 Checkpoint 加载经过训练的模型以进行评估
# pick load folder
load_folder = '/content/gdrive/My Drive/DL/models/checkpoints'
# pick the epoch to load
epoch = '429'
model_name = f'parallel_all_you_wantFINAL-{epoch}.pkl'
# make full load path
load_path = os.path.join(load_folder, model_name)
## instantiate empty model and populate with params from binary
model = parallel_all_you_want(len(emotions_dict))
load_checkpoint(optimizer, model, load_path)
print(f'Loaded model from {load_path}')
Loaded model from /content/gdrive/My Drive/DL/models/checkpoints/parallel_all_you_wantFINAL-429.pkl
在保持测试集上评估模型
手指交叉以概括性。
# reinitialize validation function with model from chosen checkpoint
validate = make_validate_fnc(model,criterion)
# Convert 4D test feature set array to tensor and move to GPU
X_test_tensor = torch.tensor(X_test,device=device).float()
# Convert 4D test label set array to tensor and move to GPU
y_test_tensor = torch.tensor(y_test,dtype=torch.long,device=device)
# Get the model's performance metrics using the validation function we defined
test_loss, test_acc, predicted_emotions = validate(X_test_tensor,y_test_tensor)
print(f'Test accuracy is {test_acc:.2f}%')
Test accuracy is 80.44%
不算太寒酸。超过 epoch 200,测试准确率在 75-80% 之间;超过 epoch 400,测试准确率在 77-80% 之间;最后几个 epochs 的测试准确率在 78-80% 之间 - 因此在最后进行少量的学习。
一些参考点:2020 年 5 月的一篇论文声称在 RAVDESS 语音音频上实现了 “新 SOTA”,在 8 种情绪上取得了 71.61% 的准确率,而 2020 年 5 月的另一篇论文声称在 8 种情绪上取得了 90% 的 F1 分数。两者都使用 CNN 架构。但是,报告了 90% F1 分数的论文因对训练样本的测试而被夸大了:请参阅本文的 GitHub 问题。
来自得分为 90% 的作者:“此外,这项工作的先前版本使用了从 RAVDESS 数据集的视频中提取的音频特征。管道的这一特定部分已被删除,因为它在训练集和测试集中对非常相似的文件进行随机排序,从而提高了模型的准确性(过拟合)。
作者用从 RAVDESS 的视频数据中提取的语音增强了 RAVDESS 语音音频数据集——因此准确率为 90% 的数据集在被分成训练集和测试集之前包含重复样本,导致测试样本泄漏到训练集中。作为参考,当我在拆分数据之前用重复的语音音频类似地扩充数据集时,我的模型实现了 97% 的准确率。我通过在拆分为训练集/验证集/测试集后才增加数据来纠正这个数据泄漏问题。
这是 “if it's too good to be true” 的一个很好的例子。在我看来,更保守的估计更有可能具有可重复性。
分析测试集的性能
from sklearn.metrics import confusion_matrix
import seaborn as sn
# because model tested on GPU, move prediction tensor to CPU then convert to array
predicted_emotions = predicted_emotions.cpu().numpy()
# use labels from test set
emotions_groundtruth = y_test
# build confusion matrix and normalized confusion matrix
conf_matrix = confusion_matrix(emotions_groundtruth, predicted_emotions)
conf_matrix_norm = confusion_matrix(emotions_groundtruth, predicted_emotions,normalize='true')
# set labels for matrix axes from emotions
emotion_names = [emotion for emotion in emotions_dict.values()]
# make a confusion matrix with labels using a DataFrame
confmatrix_df = pd.DataFrame(conf_matrix, index=emotion_names, columns=emotion_names)
confmatrix_df_norm = pd.DataFrame(conf_matrix_norm, index=emotion_names, columns=emotion_names)
# plot confusion matrices
plt.figure(figsize=(16,6))
sn.set(font_scale=1.8) # emotion label and title size
plt.subplot(1,2,1)
plt.title('Confusion Matrix')
sn.heatmap(confmatrix_df, annot=True, annot_kws={"size": 18}) #annot_kws is value font
plt.subplot(1,2,2)
plt.title('Normalized Confusion Matrix')
sn.heatmap(confmatrix_df_norm, annot=True, annot_kws={"size": 13}) #annot_kws is value font
plt.show()
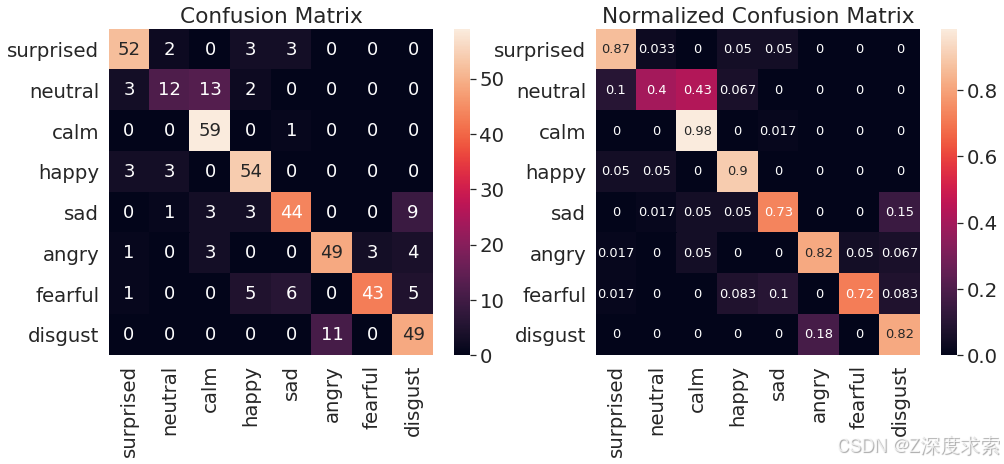
结果并不令人惊讶 - 该模型难以区分 “中立” 和 “冷静”,以及 “厌恶 ”和 “愤怒”。
如果让一个人区分厌恶和愤怒,那么 49/60 的正确和 11/60 的错误不会太糟糕(这些是上述矩阵中“厌恶”的分数)。
其他可预测的结果包括将 “sad” 与 “disgust” 混淆。也许令人惊讶的是,“恐惧”与“快乐”的混淆与“悲伤”或“厌恶”的次数一样多——也许是因为恐惧是一种真正多方面的情绪。
基于此,我会更详细地比较困惑情绪的特征,看看是否有任何差异 - 以及如何捕捉它们。对于真实世界的数据,对翻译成文本的口语单词进行情感分析会更有效率,并在我们的最终评估中考虑这一点。
结论
过去 5 年涉及自动编码器方案升级的进步导致了 RNN、升级的 LSTM-RNN、双向 LSTM-RNN,并最终导致了带有注意力层的 LSTM-RNN,为顺序编码数据的潜在空间提供了深刻的时间表达性。Transformer 在此基础上利用并行化的自我注意层来提供几乎真正的顺序数据的全局时间表示。
今天,在这些块上构建经过深思熟虑的架构可以带来合理的训练时间和出色的泛化性。我们将用于空间特征表示的 CNN 和用于时间特征表示的 Transformer 相结合,并通过增加训练数据集的变化来减少过度拟合来增强训练数据。
CNN 仍然是空间数据表示的编码标准。CNN 过滤器的内核大小对性能和准确性都很重要,特别是考虑到最近使用较小 maxpool 内核的范例,例如 VGGNet 中的 3x3 跨步 1 内核,与 AlexNet 论文中的 11x11 跨步 4 内核形成鲜明对比。
当我们在此处使用的之外添加卷积层和转换器层时,这实际上降低了测试精度。只有泛化性所需的复杂性才得到保证。尽管 CNN 适用于图像,而转换器适用于顺序数据,但最近出现的范式(例如本笔记本中的)表明,如果仔细考虑,这些网络是完全交叉适用的。
CNN 很强大。变压器工作得很好。他们在一起会更好。LSTM-RNN 的时代已经一去不复返了。
如果您走到了这一步,我衷心感谢您抽出时间这样做。如果您有任何反馈或问题,请随时向 ilzenkov@gmail.com 给我留言。
引用
-
Ba et al, 2016. Layer Normalization. https://arxiv.org/abs/1607.06450
-
Bahdanau et al, 2015. https://arxiv.org/pdf/1409.0473.pdf
-
Cheng et al, 2016. Long Short-Term Memory-Networks for Machine Reading. https://arxiv.org/pdf/1601.06733.pdf
-
He et al, 2015. Deep Residual Learning for Image Recognition. https://arxiv.org/abs/1512.03385
-
Ioffe, Szegedy, 2015. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. https://arxiv.org/abs/1502.03167
-
Krizhevsky et al, 2017. ImageNet Classification with Deep Convolutional Neural Networks. https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
-
LeCunn et al, 1998. Gradient-Based Learning Applied to Document Recognition. http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
-
Li et al, 2018. Visualizing the Loss Landscape of Neural Nets. https://papers.nips.cc/paper/7875-visualizing-the-loss-landscape-of-neural-nets.pdf
-
Masters and Luschi, 2018. Revisiting Small Batch Training for Deep Neural Networks. [1804.07612] Revisiting Small Batch Training for Deep Neural Networks
-
Peng et al, 2017. Large Kernel Matters —— Improve Semantic Segmentation by Global Convolutional Network. https://arxiv.org/pdf/1703.02719.pdf
-
Santurkar et al, 2019. How Does Batch Normalization Help Optimization? https://arxiv.org/pdf/1805.11604.pdf
-
Simonyan and Zisserman, 2015. Very Deep Convolutional Networks for Large-Scale Image Recognition. https://arxiv.org/pdf/1409.1556.pdf
-
Srivastava et al, 2014. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. https://www.cs.toronto.edu/~hinton/absps/JMLRdropout.pdf
-
Ulyanov et al, 2017. Instance Normalization: The Missing Ingredient for Fast Stylization. https://arxiv.org/pdf/1607.08022.pdf
-
Vaswani et al, 2017. Attention Is All You Need. [1706.03762] Attention Is All You Need
-
Wilson et al, 2017. The Marginal Value of Adaptive Gradient Methods in Machine Learning. https://arxiv.org/abs/1705.08292
-
Christopher Olah's Blog; Neural Networks, Types, and Functional Programming: http://colah.github.io/posts/2015-09-NN-Types-FP/
-
Lilian Weng's blog on Attention Mechanisms: Attention Attention
-
Stanford Autoencoder tutorial: Unsupervised Feature Learning and Deep Learning Tutorial
-
Stanford CNN Tutorial: Unsupervised Feature Learning and Deep Learning Tutorial
-
Stanford's CS231n: CS231n Deep Learning for Computer Vision
-
U of T CSC2515, Optimization: https://www.cs.toronto.edu/~hinton/csc2515/notes/lec6tutorial.pdf
附录 A - 剖析的卷积神经网络
返回主要部分: CNN 动机
内核和过滤器
每个卷积层行为的核心是其内核。每个卷积层都由一定数量的 2D 内核组成,我们指定其维度。层中的 2D 内核堆栈创建 3D 滤波器,定义该层在其输入特征图(张量)上的作。每个过滤器都包含与其大小相等的权重数量(即深度 x 高度 x 宽度)。内核的大小是卷积层的超参数;内核的感受野。之所以这样命名,是因为内核的大小决定了它在每个卷积子期间看到的输入特征映射的维度。
尽管完整的 CNN 滤波器是 3D 的,但它们仅在 H x W 维度上按其步幅移动,并且包含它们所作的特征图的整个深度 - 因此卷积实际上是 2D 的,因此命名法。
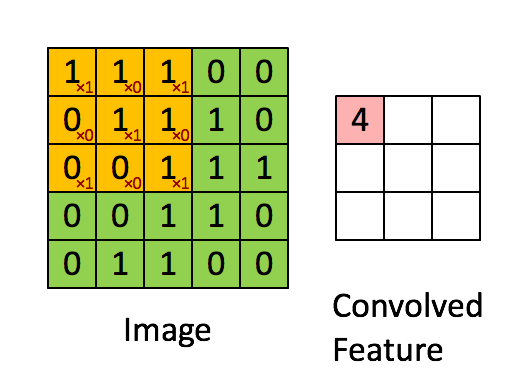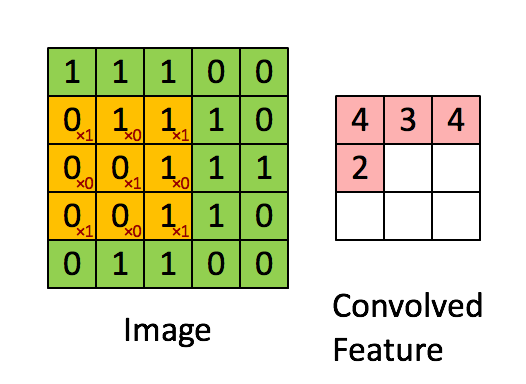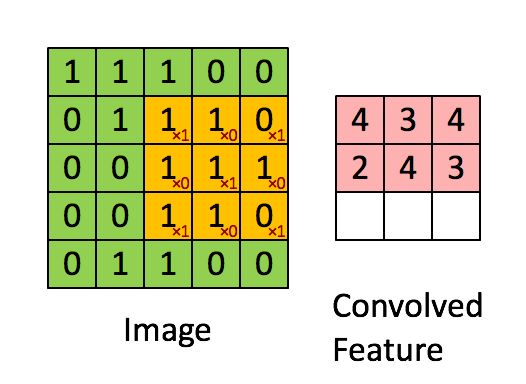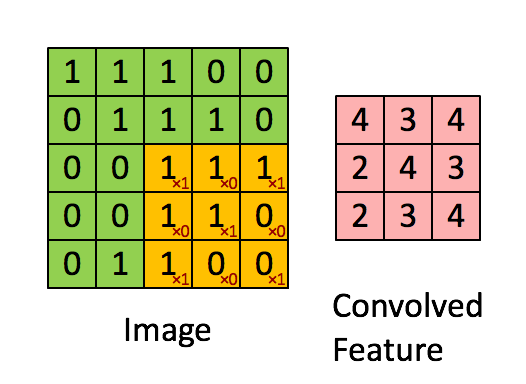
使用 5x5 特征映射可视化单个 3x3 步幅 1 内核的卷积。来自 Stanford Deep Learning 教程的图:http://ufldl.stanford.edu/tutorial/supervised/FeatureExtractionUsingConvolution/
在执行卷积时,我们将内核权重的乘积与输入特征图的值相加,然后将它们相加,以在输出特征图中创建单个条目。在这个任务中,初始输入特征图具有描述像素亮度的值 - 在我们的例子中,我们有 40x282 个“MFCC 像素”,每个像素代表 40 个 MFC 系数中每个系数在 282 个时间点中每个时间点的强度(以分贝为单位) - 换句话说,我们有一个 40x282 灰度图像映射,只有一个亮度通道, 这就是为什么 CNN 是这项任务的首选模型。构成卷积层滤波器的每个内核都会创建一个 2D 特征图,因此更多的内核 = 更大的滤波器 = 更多的 2D 特征图 = 更高的复杂性(深度)3D 特征图,其中内核的 # 由层的输入通道指定。如果我们的输入特征图有 1 个通道和 2D 尺寸 H x W,并且我们需要 16 个输出通道,那么我们将在该层的过滤器中有 1 个 2D 内核,并生成 16 个 H x W 的 2D 特征图,或整个层的单个 3D 16 x H x W 特征图。输出通道维度越高,创建的输出特征图数量就越多。根据任务的不同,这可能是有益的也可能有害的 w.r.t. 过拟合。
对于每个 input channel,我们都有一个 2D 内核,因此当我们有多个 input 通道时,我们有一个 2D 内核的集合组成一个 3D 滤波器。每个 2D 内核为每个输出通道创建一个 2D 贡献 - 因此整个 3D 滤波器创建一个完整的 3D 输出通道。在这种架构中,作为堆叠 CNN 的标准,我们在保持其 H x W 维度不变的同时,扩展了通道/深度维度中输入特征映射的复杂性。对于每个完整的输出通道,每个 3D 滤波器都会在输入特征图上传递一次。输入通道的数量决定了 2D 内核的数量,因此决定了层中所有 3D 滤波器的大小,而输出通道的数量决定了通过输入特征图传递的 3D 滤波器数量 - 所有输入特征图与唯一 3D 滤波器的卷积将创建一个唯一的输出通道。
总而言之,输入通道尺寸决定了该图层中所有 3D 滤镜的大小,而输出通道尺寸决定了该图层中唯一 3D 滤镜的数量。每个筛选条件都由一组唯一的权重定义,并且每个筛选条件都有自己的偏差项。
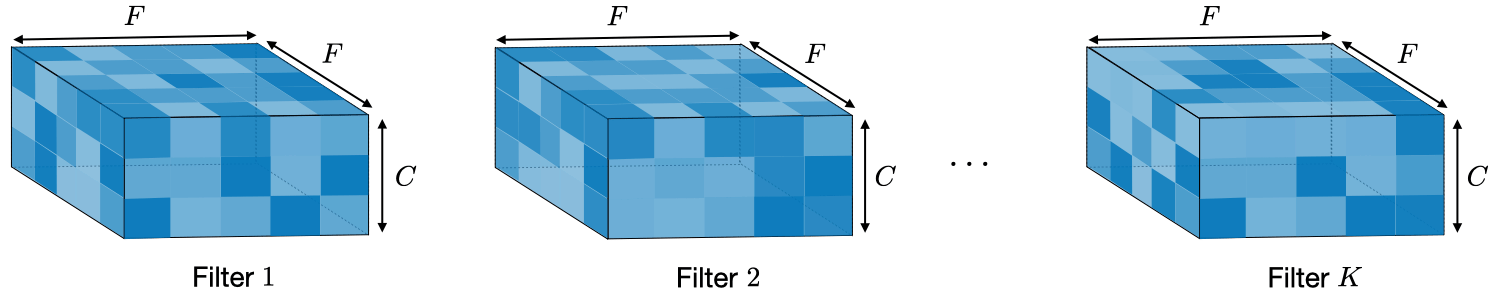
一组 2D 内核构成了一个 conolutional Layer 的 3D 滤波器:每个滤波器都有一组唯一的权重,如下所示。内核大小为 FxF,深度为 C(通道维度)。来自斯坦福大学 CS230 的图:https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-convolutional-neural-networks
3 通道 (RGB) 3D 滤波器体积在 3 通道 3D 输入体积上运行以产生输出 3D 体积的视觉效果 - 深度取决于卷积层的滤波器/输出通道的数量。
层中的每个滤波器在遇到它已学会表示的特征时,都会学习产生高幅度的激活(在 ReLU 之后)。每个筛选条件输出都会创建一个唯一的特征图。在高性能 CNN 中,每个卷积层中的滤波器可能会以分层方式学习一组不同的高级特征,随着我们扩展通道维度,每个后续卷积层的复杂性都会增加。这种范式背后的想法是创建类似于人类识别图像方式的高阶特征表示。
谈到 CNN 的神经元表示,3D 输出体积的每个元素都可以看作是神经元的激活,该神经元查看输入体积中的一个小区域。过滤器中的每个神经元在空间上都与其左侧和右侧的所有神经元共享参数,因为这些神经元的参数是通过应用相同的过滤器来更新的。通过这种方式,与完全连接的“密集”层相比,CNN 的神经元仅局部连接。
简洁:CNN 层将 3D 输入体积转换为神经元激活的 3D 输出体积。分类本身仅由后续的非卷积层完成,通常具有完全连接的线性层。
零填充
我们在每个卷积块的开头对输入特征图进行零填充,即在特征图的 (H,W) 维度的每一侧添加一列和一行零。如果我们在每个卷积层之前不进行零填充,那么输入特征图只会产生带有滤波器的“有效”卷积;在每次完全卷积之后,输出特征图的大小会小幅减少:边界处的信息会逐渐被侵蚀。如果内核的下一个步幅将其设置为超出特征图的 (H,W) 维度的最后一列的边界,则该卷积将无效;内核将继续 (采取 length==stride 的步骤) 到下一行。如果我们的 kernel 大小> 1,步长为 > 1,这意味着我们将完全丢失特征图右边缘和下边缘的特征。对于大小> 1 的内核,零填充是卷积层的标准,即使步幅为 1 也是如此 - 如果在这种情况下不填充,角像素(特征)将只使用一次。因为这个网络中的所有卷积核都是 3x3 步幅 1;I 零填充 1 以保留每个卷积层特征图的输入维度,即“相同”的零填充。
最大池化
这就是真正的奇迹发生的地方。Maxpool 内核在特征图上运行,这与卷积内核非常相似;但是,它们不执行乘法或加法,而是执行简单的 argmax 运算,采用 Maxpool 内核感受野中最高值的特征;通过这种方式,maxpool 层减小了它们所作的特征图(卷)的维度。Maxpooling 可以等效地被视为特征空间的降维或下采样技术。最终,maxpooling 大大减少了网络必须学习的参数数量;后续层之间的连接比没有 MaxPooling 时要少得多。Maxpooling 正是 CNN 的实用性。
直观地说,maxpooling 输出一个特征图,该特征图仅包含输入特征图每个区域中最重要的特征,并将这些特征放在它们相对于其他最重要特征的位置上下文中。这是一个非常合适的类比,与幕后发生的事情相去不远:靠近鼻子的眼睛靠近嘴巴可能意味着一张脸——眼睛的位置无关紧要,重要的是它与鼻子相邻,鼻子与嘴巴相邻。由于这种范式,CNN 即使在旋转或移动时也能非常擅长识别图像:也就是说,CNN 是特征和尺度不变的。但请注意,CNN 学习的特征本身并不是比例或旋转不变的。同样,也许以这种方式,maxpooling 是 CNN 的绝对核心。
斯坦福大学 CS230 中 maxpool 图层的可视化:https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-convolutional-neural-networks
将上述内容扩展到此应用程序:从一个 mel 频段到另一个 mel 频段的尖锐音高过渡可能代表愤怒的声音,过渡发生在哪个时间点并不重要(移位不变性)。这正是我们获得我们想要的泛化性所需要的。
在这个架构中,我使用不重叠的 maxpool 内核,通过内核大小减少输入卷:使用 2x2 maxpool 内核在其感受野中占用 1/4 像素,因此它将其输出卷中包含的信息量减少了 75%。第一个图层的输入体积为 40x282 = 11,280 像素;在 2x2 MaxPool 之后,这将变为 20x141 输出体积 = 2,820 像素。2,820/11,280 = 1/4。虽然卷的维度会随着内核的维度而减小,但卷中的信息总量会因内核的大小而减小。
在堆叠架构(如 AlexNet 和 GoogLeNet)中,第一卷积层上的典型 maxpool 内核是 2x2,步幅为 1。较高的步幅长度会丢弃更多的信息,而较小的步幅长度会保留更多信息,因为它们会在 Importing Volume 上采取更少或更多的步数,具体取决于它们的步幅,而根据它们的大小,则更少。一些著名的网络(AlexNet、GoogLeNet)使用步幅长度为 2 的 3x3 内核作为其最大池层。
我优化了内核大小和步幅,其原则是在网络每一层的特征保留和特征减少之间找到完美的平衡,以使模型在计算上合理。我发现在输入层上需要一个 2x2 跨步 2 非重叠的 maxpool 内核(减少 1/4 特征图),以保持通过后续卷积层的特征的良好平衡,但此后非重叠的 8x8、stride 8 内核(减少 1/16 特征图)在接下来的 2 层上提供了出色的计算提升,而准确性几乎没有妥协。
在实践中,我的最终网络架构最终是 VGGNet 的网络架构:3x3 跨步 1 卷积内核与 2x2 跨步 2 maxpool 内核 - 出于计算需要,在第一个卷积层之后有 4x4 跨步 4 maxpool 内核的区别 - 我:)负担不起 138M 参数。
使用 Dropout 进行正则化和关于修剪的说明
3D 激活图中的每个条目都类似于神经元的激活。当通过 dropout 层传递激活映射时,我们只需停用其中的一些神经元(激活);要丢弃的神经元是从伯努利分布中选择的,概率 p 为零(停用。在这个网络中,在最大化 ReLU 转换的激活图后,我们在每个 2D 卷积层的末尾实现了 30% 的特征丢弃。与随机失学论文的第 5.2 节一样,在训练中学到的权重必须按系数 1/(1-p) 进行缩放,以便保留的那些激活的权重不会膨胀;这是必要的,这样同一网络才能在测试数据上保持性能而不会丢失。从本质上讲,当使用 dropout 时,我们保持权重之和相同,因此我们产生相同的激活预期值,而与 dropout 概率无关 - 否则来自保留神经元的激活会导致学习到不正确的权重。Dropout 适用于各种神经网络架构。把它想象成你的网络的一种 “减肥”,双关语 - 不仅可以加快训练速度,还可以减少所学特征之间的相互依赖。请注意,在验证和测试期间,我们会关闭 dropout (即我们保留所有学习的神经元)。
CNN 的 Dropout from https://arxiv.org/ftp/arxiv/papers/1512/1512.00242.pdf
如果我们真的在验证和训练期间关闭了某些神经元,那将不再被视为 dropout - 那将是修剪,我们寻找并删除与 “死” 神经元的所有连接 - 那些对网络贡献很小或没有其他不良贡献的神经元。当我们在网络上执行修剪时,我们将删除某些神经元簇 - 特征表示,即 CNN 中的过滤器。CNN 修剪领域最近取得了一些进展,取得了一些非常令人兴奋的结果——例如,网络参数减少了 60%,准确率损失了 0.6%。我实现了非常合理的训练时间(~10 分钟),所以我花在调优上的时间比修剪的时间多。
批量归一化和优化 Landsape
随着网络的训练,每个卷积层的激活映射输入的分布会发生变化,因为前一层的输出会随着其参数的调整而变化——批量归一化论文的作者将这种称为“内部协变量偏移”。非饱和非线性(例如 ReLU)受较高幅度权重的高度影响,而饱和非线性(sigmoid、tanh)可能会使模型的训练速度变慢。因为超过 +-1 的输出的饱和非线性激活的差分接近 0,所以这些输出之间的误差差也接近于零,这意味着这种输出的反向传播没有变化——即我们遇到了饱和非线性激活的消失梯度问题的变化。批量归一化会重新居中数据,使激活图更有可能在整个训练过程中属于相似的分布。更具体地说,批量归一化鼓励每一层的神经元产生更接近其激活的线性区域的输出,即尝试将激活居中。
随着激活映射分布的变化,优化器的损失表面变得更加不稳定;损失表面是为权重设置定义的,这些权重将在不稳定的激活贴图上以不可预测的方式更新。因此,通常需要较低的学习率来确保权重朝着更稳定的负梯度方向移动,否则优化器更有可能在学习适当的模型参数之前收敛到次优解。尽管输入特征图最初可以缩放为零均值和单位方差,但一旦它们作为后续隐藏层的激活输出,不同的特征集可能会转换为属于不同的分布。为避免次优收敛,考虑适当的参数初始化也很重要。
批量归一化最终通过引导模型避免陷入梯度消失的饱和学习机制,从而实现更快的收敛。批量归一化还鼓励以这种方式进行正则化权重,从而阻止梯度爆炸和过度拟合。这种规范化是作为模型架构的一个方面在内部实现的,因此每个训练小批量的输出在每一层都进行了规范化。由于这缓解了内部协变量偏移的问题,因此可以使用更广泛的参数和更高的学习率来初始化网络,并且仍然实现最佳收敛。
该论文表明 BN 是凭经验而不是通过数学证明来工作的——这也许就是为什么有些人不同意 BN 背后的推理:在批量归一化如何帮助优化?中,作者认为内部协变量偏移的稳定并不是 BN 成功背后的主要因素,而是优化器损失函数景观的平滑化提高了性能.更平滑的损失表面在每个训练步骤之间创建更稳定的梯度差方向,即朝着良好的最小值移动;TE 梯度更具可预测性,从而加快训练速度,因为当梯度可预测地朝着全局最小值的方向移动时,我们可以使用更高的学习率。否则,我们将需要更频繁地重新计算区域中的梯度,以确保我们在正确的方向上移动。
简而言之,batch norm 的默认行为以及它在 pytorch 中实现时,本质上是将标准缩放(零均值、单位方差)应用于张量的小批量(H,W)维度。
虽然 BN 最初不用于验证和测试,但截至 2019 年,BN 的改编版本在训练和测试时都应用,从而提高了性能:实例规范化: 快速风格化缺失的要素
ReLU - 非饱和激活更健康 [对于 CNN]
我们使用 ReLU 进行激活,这是 CNN 中的标准,以避免权重饱和 - 大权重不会被压缩,因此我们进一步阻止梯度消失。这个模型用 tanh/sigmoid 训练需要更长的时间,性能差异可以忽略不计。由于该模型的深度适中,这一点尤其重要,因为在饱和非线性激活的情况下,我们训练后续层的难度将增加。我们希望有相当数量的层来学习特征的更高表示,例如,不仅仅是频率转换,还有这些转换的形状和幅度。如果用 ReLU 激活神经元,梯度通常很高,从而在网络中产生有效的连续梯度,而 sigmoid 和 tanh 激活则为非常高幅度的输入产生接近零的梯度。总而言之,ReLU 将导致更快的收敛,并且对于这项任务,可以产生出色的结果。
使用全连接层将特征图转换为概率
如前所述,CNN 无法自行执行分类。常规隐藏层仅对 1D 数组进行作,而卷积层生成 3D 激活图。因此,3D 激活图的整个体积被展平为 1D 数组,因此它可以连接到下一个全连接 (FC) 层中的所有输入神经元,因此称为 FC。在卷积层的末尾使用全连接层来启用分类是一种标准架构。
在这个网络中,我们有一个来自每个卷积块的输出嵌入 (64x1x8 = 512),以及来自一个 1x40 的 Transformer 块的输出嵌入。因此,我们最终的扁平化嵌入将包含 512x2 + 40 == 1064 个激活,在完全连接的线性层中需要 1064 个输入神经元。
FC 层根据网络其余部分生成的串联 1D 激活映射生成 8 个激活 logit。我们需要 FC 层,以便将卷积滤波器的最终结果和 transformer 编码器嵌入学习的高级特征结合起来,以便网络可以构建频谱图的全局表示。虽然不同类别中可能存在高级特征,但这些特征的特定组合可以自信地代表一种情绪。另一种查看方式是 FC 层评估卷积滤波器学习的哪些高阶特征存在于当前样本中。
Appendix B - The Transformer
返回主要部分: Transformer-Encoder 动机
自我关注
在 Bahdanau 等人于 2015 年提出最初的注意力机制后,自我注意于 2016 年首次作为机器阅读的长短期记忆网络中的注意力内引入。我们可以从 Transformer 论文中学到关于自我关注所需的一切。滚动过文本墙,查看带有图像的 Transformer 的逐块细分。
Transformer,在 Vaswani 等人于 2017 年在 Attention is All you Need 中引入,Transformer 模型通过引入现在使用的自我注意机制,用上述 in-attention 取代了 seq2seq LSTM-RNN 模型。Transformer 没有使用带有注意力层对齐上下文向量的 LSTM-RNN,而是实现了多种自我注意机制,并完全取消了 seq2seq 任务的 LSMT-RNN。方法如下:
Transformer 架构将输入序列的上下文向量编码为一组 (K, V) 键值对,其维度与输入序列长度相同。现在,键 (inputs) 和值 (inputs' hidden state) 都构成了编码器的隐藏状态。解码器在前一个时间步预测的输出被计算成一个 “查询”,解码器输出序列中的下一个项是 key-val 对加查询的映射:(Q,K,V) 解码器的每个输出项都是来自 (K,V) 输入的 (K,V) 编码表示的所有值的加权和 - 所以, 就像一个常规的注意力机制 它解码隐藏状态的加权和,但 self-attention 将 (对齐) 权重分配给每个值 (隐藏状态) 作为具有所有键的查询的序列长度缩放点积。也就是说,所有 inputs的隐藏状态的加权和是相对于输出序列中的前(最后一个)项和整个 input 序列计算的。这就是 Transformer 的全局注意力能力的来源。
试图澄清一下:最终输出序列中的每个项都取决于输入序列中的所有项和输出序列中的前一项:因此,自我注意。
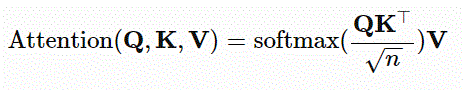
自我注意机制背后的方程式。来自 Vaswani 等人,2017 年。一个极其有效的想法的极其简单的表示。缩放的点积只是按源隐藏状态的维度 _n_ 进行缩放,以便在时间步 _t_ 处输出序列。
结果如下所示:

自我注意捕获的全局时间关系的可视化,用于文本预测。来自 Cheng 等人,2016 年。

又一次自我关注的可视化,这次是翻译。来自 Bahdanau 等人,2015 年。
Multi-Head Self-Attention
有了自我注意,我们现在可以应用多种自我注意机制:根据 “Attention is All you Need” ,缩放的点积自我注意力 (Q, K, V) 是在多个 “表示子空间” 上计算的 - 因此每个查询、键和值都有自己的关联权重矩阵。通过这种方式,多头(多层)自我注意可以根据输入序列的区域(子空间)计算输出序列中的一项,其权重不同。直觉上:在句子 “I like sour green ___” 中,一个注意力头将更密集地学习输入序列中术语 “sour” 的权重,而另一个注意力头将更密集地学习 “green” 的权重。多头自注意力中的每个注意力头仍然计算整个 (K,V) 编码输入上的缩放点积,只是对输入值的加权不同。
所有注意力头的输出都与权重矩阵连接并相乘,该权重矩阵将编码状态的维度放回单个注意力头的维度;然后,无论注意力头的数量如何,单个前馈层都可以对编码的潜在空间进行作,并且根据多头注意力架构中所有层的加权和计算出 softmax 预测。多头注意力层是变压器的肉。

多头自我注意机制背后的方程式。来自 Vaswani 等人,2017 年。单头自注意力机制的近乎直观的延伸。
Transformer 架构
2017 年在“Attention is All You Need”中实施的完整架构:
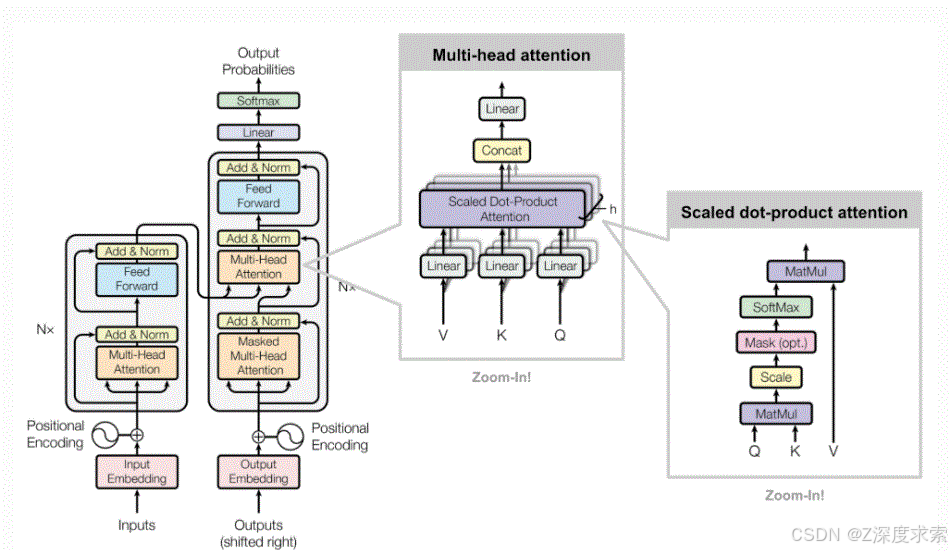
来自 Vaswani 等人,2017 年。每个 encoder/decoder block 在原始 implementation中堆叠 6 次。
各组成部分说明:
输入
- 输入嵌入是根据 Importing 序列计算的。
- 输出嵌入是当输入嵌入向右移动一个时间步 (t+1) 时给出的。
- 提供给 transformer 的输入嵌入生成 (K,V) 对,而输出嵌入提供最后一个预测词,即查询 (Q)。
- 图中的位置编码是指嵌入的(正弦)转换,它保留 input/output sequence 嵌入中项目的相对位置。
编码器
A 是 6 个相同区块的堆栈,每个区块由以下部分组成:
- 一个多头自注意力层 + 一个全连接前馈层。
- 多头自我注意之后的残差 (skip-connection) 和归一化层。
- 前馈层之后的残差连接和归一化。
- 残差连接将原始嵌入与多头自注意力层输出的嵌入添加。
- 归一化层类似于批量归一化 (BN),但适用于顺序输入,与 BN 不同的是,范数层也在测试时使用。范数层应用于残差连接的组合嵌入。
译码器
一堆 6 个相同的区块,每个区块由以下部分组成:
- 两个多头自注意力层 + 一个全连接前馈层。
- 给解码器的输出嵌入是屏蔽的(输入嵌入转移到 t+1),因此我们不会将任何未来的项从输入序列(即 t+2)传递到多头自注意力层。
- 每个多头自注意力层之后和前馈层之后的残差连接和归一化层。
输出
- 最终的 linear 和 softmax 层被添加到 decoder 块的最终输出上。
总而言之,这是 Transformer:
- 通过完全避开 RNN 来消除 RNN 中有问题的误差梯度的优化问题,因为它利用了注意力机制。
- 使用注意力机制为输入序列的每个隐藏状态分配权重,并在输出序列的每个时间步生成隐藏状态加权输出。
- 使用自注意力机制,该机制使用输入序列、它们的所有编码隐藏状态和输出序列中的前(最后一个)预测词 - (Q,K,V) - 在输出序列的每个时间步生成输入隐藏状态查询加权输出。
- 集成自注意力机制以创建多头自注意力机制,能够为输入序列的每个 (Q, K, V) 集分配多个权重
- 生成一个输出,该输出是多个自注意力层的加权和的 softmax。
- 花里胡哨的功能,如 6 个堆叠编码器/解码器模块、层归一化和残差连接
附录 C - 从自动编码器到 LSTM 再到 Attention
自动编码器
了解自动编码器 - Transformer 取代的 RNN 和 seq2seq 模型的基础,将有助于更好地理解 Transformer 架构背后的动机和作。
自动编码器本质上试图学习一个函数 F(weight, bias, X) = X。它尝试输出类似于 one input 的序列。当我们将此任务交给受有限数量隐藏神经元约束的网络时,这就变得困难了 - 也就是说, 对于 X 中的每个数据点,编码器中没有一个神经元。因此,编码器需要学习它所训练的 inputs 的压缩表示。例如,使用 50 个隐藏神经元重建 100 像素的 10x10 图像。 为了使自动编码器有效,我们希望使用自动编码器处理的数据点之间必须存在结构 - 相关性。要求编码器学习压缩表示的约束也称为 '瓶颈'。
Standard/Vanilla Autoencoder,图 Deepak Birla:https://medium.com/@birla.deepak26/autoencoders-76bb49ae6a8f
自动编码器实际上与 PCA 非常相似,PCA 在某种程度上,通过计算协方差矩阵的特征向量来编码它所作的数据结构,这样沿主成分轴的投影点就会产生编码最大量方差(信息)的向量,维度比输入数据中可用的维度少。与自动编码器相反,PCA 生成的组件是原始数据的线性组合。这样做的优点是可以产生快速且可解释的变换,但缺点是无法编码特征之间的非线性关系。**从这个意义上说,自动编码器是一种升级的 PCA - 它也可以执行维度重构,但增加了学习特征非线性表示的能力 - 以牺牲可解释性和计算效率为代价。
稀疏自动编码器
稀疏自动编码器将编码的约束扩展到隐藏神经元的数量之外 - 我们可能会选择比输入数据点更多的隐藏神经元,而不是施加稀疏约束,为我们的损失函数添加一个额外的惩罚项。对于 ReLU 和 sigmoid 激活,我们使用接近 0 的稀疏参数来参数化惩罚项,对于 tanh 接近 -1:即非活动。我在这里将 0 称为非活动神经元。稀疏自动编码的目标是强制所有隐藏神经元的平均激活率低于稀疏性参数:隐藏层中的大多数神经元不会针对任何给定的特征集进行激活。
稀疏性约束或惩罚项,无论我们以何种方式称呼它,都是 Kullback-Leibler (KL) 散度:一个函数 它计算两个伯努利随机变量之间的散度,即 0 或 1 的分布。当特定层中隐藏神经元的平均激活量不接近惩罚约束 p 时,KL 散度惩罚(自动编码器的正则化项)就会爆炸 - 因此隐藏层的平均激活被迫既不是 0 也不是 1,而是接近 p=~0,例如 0.05。
稀疏自动编码器的解码器层使用损失函数(“重建项”)进行训练,该函数优化了输入的精确重建,通常具有均方 (MSE) 损失。最终,结果是,除非神经元对一组特定输入特征的激活严重破坏了结果重建的损失,否则该神经元将被参数化以将其对该输入的激活降低到 0。稀疏自动编码器的神经元只有在对模型的准确性至关重要时,才会学习输入特征集上的高激活。因此,模型受益于稀疏自动编码,因为当且仅当它被作为输入提供它已经学会表示的精确特征时,隐藏层的每个神经元才会激活。这具有严厉惩罚过拟合模型的固有好处。
变分自动编码器、解码器和潜在空间
原版自动编码器计算一种称为潜在空间的特征表示,类似于 PCA 的主成分。一旦输入特征集被编码到潜在空间中,另一个称为解码层的隐藏层的目标是从编码的潜在空间重建输入特征集。
由于自动编码器寻求产生与其输入相似的输出,因此自动编码器是生成模型的一种风味 - 尽管原版自动编码器无法生成它们从未见过的输出。变分自动编码器 (VAE) 更适合该任务。与普通自动编码器编码的潜在空间中的单个点相反,VAE 计算的是其输入的潜在空间的分布。然后,我们可以从输入的潜在空间分布中采样点,以真正生成新的输出数据。
变分自动编码器,图由 Katsunori Ohnishi 绘制:http://katsunoriohnishi.github.io/
与稀疏自动编码器类似,我们在潜在(编码)层中有 KL 散度, 现在将潜在表示约束为接近标准正态分布,并且解码层上的重建项最小化了重建和输入之间的距离(直观地说,信息丢失),其中重建现在是通过从输入的潜在空间分布中随机采样来计算的——这就是为什么我们首先需要一个正态分布的潜在空间。
如果我们没有对 VAE 的编码器层施加正则化项,它最终会通过简单地编码接近零方差和/或非常不同的方式的分布(本质上是潜在空间中的编码点)来最小化解码器层的重建项,并且 VAE 退化为普通的自动编码器。强制执行标准正态分布的潜在空间会正则化编码潜在空间中分布的均值和协方差矩阵,避免像 vanilla 自动编码器训练的那样过度拟合输入。
RNN、Seq2Seq 和梯度问题
编码器-解码器范式在实践中被实现为递归神经网络 (RNN),通常使用长短期记忆 (LSTM) 单元来处理梯度消失/爆炸问题 - 这就是现代 squence-to-sequence (seq2seq) 模型。seq2seq 模型通常使用 LSTM-RNN 网络将可变长度的输入序列编码为向量潜在空间表示,并使用 LSTM-RNN 将该向量解码为可变长度的输出序列。
RNN 为给定序列的每个输入编码一个隐藏状态。RNN 中的节点(或神经元)获取序列中的每个输入,将其添加到根据之前的输入计算的隐藏状态中,并通过激活函数(如 tanh)计算新的隐藏状态。对于给定序列的所有时间步,此过程将重复,因此每个时间步的隐藏状态都是根据之前输入的聚合隐藏状态计算的。只有最后一个神经元的聚合隐藏状态才会传递给解码网络。
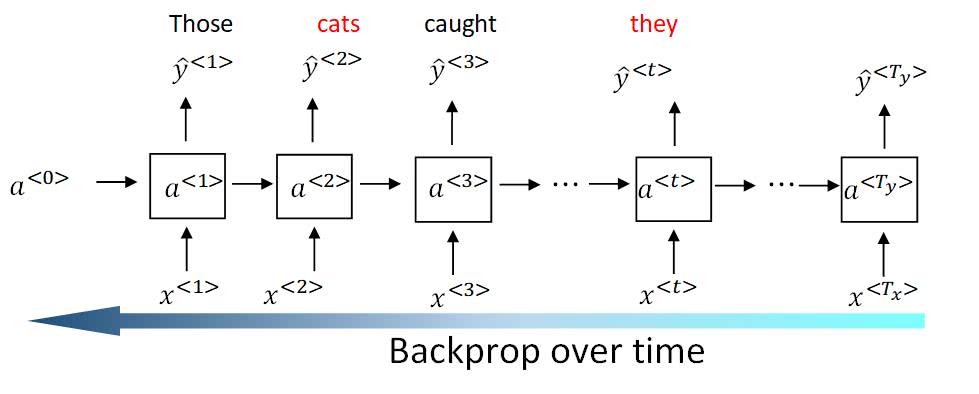
随时间的反向传播构成了 RNN 的梯度问题。图由 Chengwei: https://www.dlology.com/blog/how-to-deal-with-vanishingexploding-gradients-in-keras/
这种结构的问题在于,我们只能计算最终神经元输出的误差 - 所以每个神经元的误差都取决于它之前所有时间步的神经元。最后一个神经元的 ID 必须反向传播到同一层中的所有神经元,而不仅仅是前一层的神经元。如果最后一个神经元的误差很小 (<1),它将变得越来越小并“消失”,因为它在每个时间步长都以乘法方式反向繁殖。同样,对于大误差 (>1),它将变得越来越大并 “爆炸”。RNN 网络要么不会学习,要么需要很长时间来学习 - 或者并非所有权重都会更新。
LSTM 单元
缓解 RNN 梯度问题的一种机制是长短期记忆 (LSTM) 单元。直观地说,LSTM 细胞被添加到 RNN 的每个节点/神经元/时间步长,并“忘记”或“记住”隐藏状态 - 本质上,在一系列时间步长中绕过某些神经元。LSTM 单元归结为每个神经元上的开关门的组合 - 允许 RNN 中的节点删除或向节点添加信息,但通常允许信息原封不动地流过。
LSTM 单元的内部工作原理。来源: https://blog.floydhub.com/long-short-term-memory-from-zero-to-hero-with-pytorch/
在上图中,输入 x 流经 5 个门:1 个忘记门、2 个输入门和 2 个输出门。请注意,每个门都有通过反向传播学习的权重:每个 LSTM 单元都学习自己的权重矩阵。每个 LSTM 信元都作为输入 CT-1、前一个细胞的长期记忆和 HT-1、前一个细胞的短期记忆(经典 RNN 隐藏状态)。每个 LSTM 单元输出长期记忆 Ct和 短期记忆 Ht.
-
1 个遗忘门(左,sigmoid):决定丢弃长期记忆中的哪些信息。从以前的 LSTM 单元 C 中获取长期记忆的乘积T-1替换为 forget 向量;当当前输入 xt和上一个单元格的隐藏状态 HT-1(短期记忆)被添加并通过 sigmoid 激活门传递:
- f向量= σ(W忘记⋅(Ht−1,xt) + 偏置忘记)
- Ct= Ct−1∗f忘记+我输入:计算新的长期记忆 Ct.
-
2 个输入门(中间,sigmoid+tanh):将新信息编码到 LSTM 单元运行的长期记忆中。上一个单元格 H 的隐藏状态T-1(短期记忆)和当前单元格 x 的输入t通过两个门:
- 我1= σ(Wi1⋅(Ht−1,xt) + 偏置i1):一个 sigmoid 激活门将不重要的特征映射到 0,丢弃它们,并计算 i1:
- 我2= tanh(Wi2⋅(Ht−1,xt) + 偏置i2): tanh 激活门对先前的短期记忆 H 起作用T-1和电流输入 Xt要计算 i2.
- 我输入= 我1∗i2: 产品 i输入被添加到 LSTM 单元的长期记忆 C 中t由 Output Gate 指定。
-
2 个输出门(右,sigmoid+tanh):对新的短期记忆(隐藏状态)进行编码。
- O1= σ(W输出 1⋅(Ht−1,xt)+偏置输出 1):Sigmoid 门从前一个单元格 H 中获取隐藏状态T-1(短期记忆)和当前单元格 x 的输入t.
- O2= tanh(W输出 2⋅Ct+偏置输出 2):tanh gate 采用该单元的 input gate 计算的新长期记忆。
- Ht,Ot= O1∗O2:新的短期记忆,即当前单元的输出,是 O 的乘积1和 O2.
上述 LSTM 细胞结构被添加到传统 RNN 中的所有节点/神经元中。上述过程在每个 LSTM 单元中重复。长期记忆 Ct是贯穿所有细胞的矩阵,而短期记忆 Ht是每个时间步的编码隐藏状态输出。
双向 RNN
LSTM-RNN 之上的另一种优化是使其双向化:我们将两个 RNN 堆叠在一起,其中输入序列通过一个 RNN 向前流动,通过另一个 RNN 向后流动。RNN 中的每个节点/神经元都对应一个 LSTM 单元。在每个时间步,输入同时提供给两个彼此相反方向运行的 RNN 神经元。每个 RNN 聚合自己的隐藏状态,一个正向,一个反向。隐藏状态不在双向 RNN 的两个网络之间共享,而是在整个输入序列被消耗后,正向和反向 RNN 的最终隐藏状态被组合起来,然后传递给解码器网络。
来自 Christopher Olah 博客的双向 RNN:https://colah.github.io/
然而,我们仍然有一系列神经元,我们必须对错误进行反向传播。进入 Attention 机制:
注意力机制
由 Bahdanau 等人在 2015 年的论文《通过联合学习对齐和翻译的神经机器翻译》中介绍。注意力机制使用注意力层(一个简单的前馈网络)在编码器 RNN 的所有隐藏状态和原始输入序列之间引入权重。注意力层使用 “对齐权重” 来计算每个输入的隐藏状态对最终隐藏状态(在注意力机制中也称为上下文向量)的贡献,然后将其传递给解码器网络。对于解码器为输出序列预测的每个术语,注意力层计算输入的所有隐藏状态的概率分布。换句话说,输出序列中的每个术语都是从注意力层计算的分布中的唯一上下文向量计算得出的。每个上下文向量都是 LSTM-RNN 从输入序列计算的隐藏状态的比对加权和。
注意力层与常规的编码器-解码器 RNN 对相反,后者只使用一个隐藏状态来生成解码器的整个输出序列,只使用一个隐藏状态来反向传播错误。注意力层使用所有隐藏状态同时向编码器-解码器 RNN 的所有神经元传播错误。
来自 Bahdanau 等人,2015 年。完整的注意力机制:双精度 RNN 编码器-解码器对,中间有自注意力层,用于计算所有隐藏状态的加权上下文向量。
从某种意义上说,注意力机制有点像 ResNet 的跳过连接:相反,我们跳过了 RNN 层中神经元的贡献。注意力层中的跳过或快捷方式连接是各个隐藏状态和最终上下文向量之间的连接。
附录 D - 补充说明
更多 CNN 内核/滤波器数学运算
我将在这里将特征图互换地称为输入/输出体积。我们将每个内核生成的 2D 体积连接起来,以创建由这些内核组成的滤波器生成的 3D 体积。让我们忽略 maxpooling 来了解通道维度的影响:在这个网络的第一层,一个 1x40x282 的输入卷变成了一个 16x40x282 的输出卷,它被馈送到下一个具有 32 核滤波器的卷积层,产生一个 32x40x282 的输出卷。第 3 层也是最后一层具有一个 64 内核的过滤器,并产生 64x40x282 的输出卷。每个内核都学习其生成的卷积的权重,因此每个过滤器都是一组深度 x 高度 x 宽度权重 - 例如,最后一层包含 32 个内核过滤器,它生成 64 个这样的过滤器来满足其 64x40x282 的输出体积。
每层中的 2D 内核总数 = input_channel x output_channels。在此架构中,每个卷积块有 3 层:第一层具有 1x16=16 个 2D 内核,第二层具有 16x32 = 512 个 2D 内核,第 3 层具有 32x64 = 2048 个 2D 内核。在此架构中,两个卷积块中所有层中所有内核的大小均为 3x3,步幅为 1。
平滑优化表面
除了批量归一化之外,其他驯服优化表面的方法包括跳过连接,其中一层的输出跳过其一些后续层 - 由非常成功的 ResNet(住宅网络)架构实现 - 从大脑皮层中的某些细胞中汲取灵感。如果跳过多个非线性层,则此类跳过连接需要自己的权重矩阵才能有效。比全局最小值更差的局部最小值变得更浅,即它们的深度减小,这消除了损失景观中的“坏”局部最小值。
损失 landsacpe 由训练样本和训练权重的损失函数形成。由于神经网络的高度参数化,如果不进行转换,损失景观的视觉表示不是很直观。为此,有一些特定的技术可用于损失 landsacpe 可视化。
来自 Li 等人,2018 年。不守规矩(左)和驯服(右)优化景观的可视化效果。
平滑优化表面:损失函数的深度最终决定了权重因梯度而发生的变化程度。更深的损失表面为模型提供了更大的灵活性 - 对于 CNN 来说,这意味着能够学习基于前几层输出构建的更高级别的特征,但与此同时,高深度优化环境鼓励对噪声进行过拟合。相比之下,width 平滑了优化环境并消除了许多不良的局部最小值。我们寻求在优化表面的宽度和深度之间找到平衡,并最终使其尽可能接近凸函数。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 20
20 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)