以数据驱动的以太坊价格趋势预测:一种融合机器学习与信号处理的方法
本文提出了一种融合STFT频域分析和ANFIS模糊推理的以太坊价格预测新方法。通过随机森林和ReliefF算法筛选出交易量、A/D振荡器等5个关键特征,采用STFT预处理提取隐藏周期模式,构建ANFIS模型实现76.56%的预测准确率。实验表明,该方法在高波动的加密货币市场表现优于传统机器学习模型,时频特征融合有效提升了预测性能。研究为加密资产分析提供了新思路,但计算效率有待优化以支持实时应用。
Abstract
由于近期加密货币价格的大幅波动,以太坊已被广泛认可为一种投资资产。鉴于其高度波动性,对准确预测的需求十分迫切,以指导投资决策。本文采用一种新颖方法,结合随机森林分类器与ReliefF特征选择,探讨影响以太坊每日价格走势的最重要特征。通过将自适应神经模糊推理系统(ANFIS)与短时傅里叶变换(STFT)相结合,模型在以太坊价格趋势预测中取得了较高的准确率和性能指标。与先前主要基于时间序列分析的研究不同,本方法在时域和频域增强了模式识别能力,从而提升了预测效果。在如加密货币这类高度混沌的市场中,该方法表现出较强的适应性,预测准确率达到76.56%。STFT能揭示以太坊价格的周期性趋势,为ANFIS模型提供有价值的特征,从而实现更精确的预测,弥补了加密货币研究中的显著空白。因此,与文献中常用的梯度提升(Gradient Boosting)、长短期记忆网络(LSTM)、随机森林(Random Forest)和极端梯度提升(XGBoost)等模型相比,所提方法能够适应复杂的数据模式,并捕捉复杂的非线性关系,使其在加密货币预测任务中更具优势。
Introduction
研究背景与动机
随着替代性金融资产兴趣的增长,加密货币因其去中心化、安全性和匿名性而备受关注。区块链技术作为支撑,提供了去中心化、不可篡改和透明的交易记录机制。以太坊通过智能合约进一步扩展了区块链的应用场景,从简单的货币交换拓展到复杂的金融交易和去中心化应用,因其潜在高回报而成为重点研究对象。
现有的研究回顾与不足
早期研究多采用传统计量经济模型(如线性回归、ARIMA),但在捕捉以太坊价格高度波动的非线性动态方面表现有限。随后,研究者引入机器学习方法(如随机森林、SVM、朴素贝叶斯等),并进一步结合元启发式算法(如遗传算法、粒子群优化、Rao算法等)优化神经网络和LSTM模型,提升预测精度。但这些方法往往模型复杂、难以解释,且在处理非线性关系和大规模数据时仍存在挑战。
本文贡献与创新方法
提出将短时傅里叶变换(STFT)与自适应神经模糊推理系统(ANFIS)相结合的预测框架:STFT用于提取价格时间序列的频域特征,揭示潜在周期模式;ANFIS通过融合神经网络学习与模糊逻辑推理,具备良好解释性和非线性建模能力。引入基于随机森林分类器和ReliefF方法的双重特征选择策略,以识别影响价格趋势的关键特征,降低模型复杂度,提高计算效率并增强对噪声和过拟合的鲁棒性。该框架旨在应对加密货币市场的高度波动性,通过丰富输入特征和可解释模型结构,实现更准确的日度价格走势预测,填补现有研究在频域特征利用及可解释性方面的空白。
论文的结构
第2节:研究数据与变量说明;第3节:预测模型设计与方法细节(STFT、ANFIS、特征选择);第4节:实验设计与验证方案;第5节:结果讨论;第6节:结论与未来展望。
Data
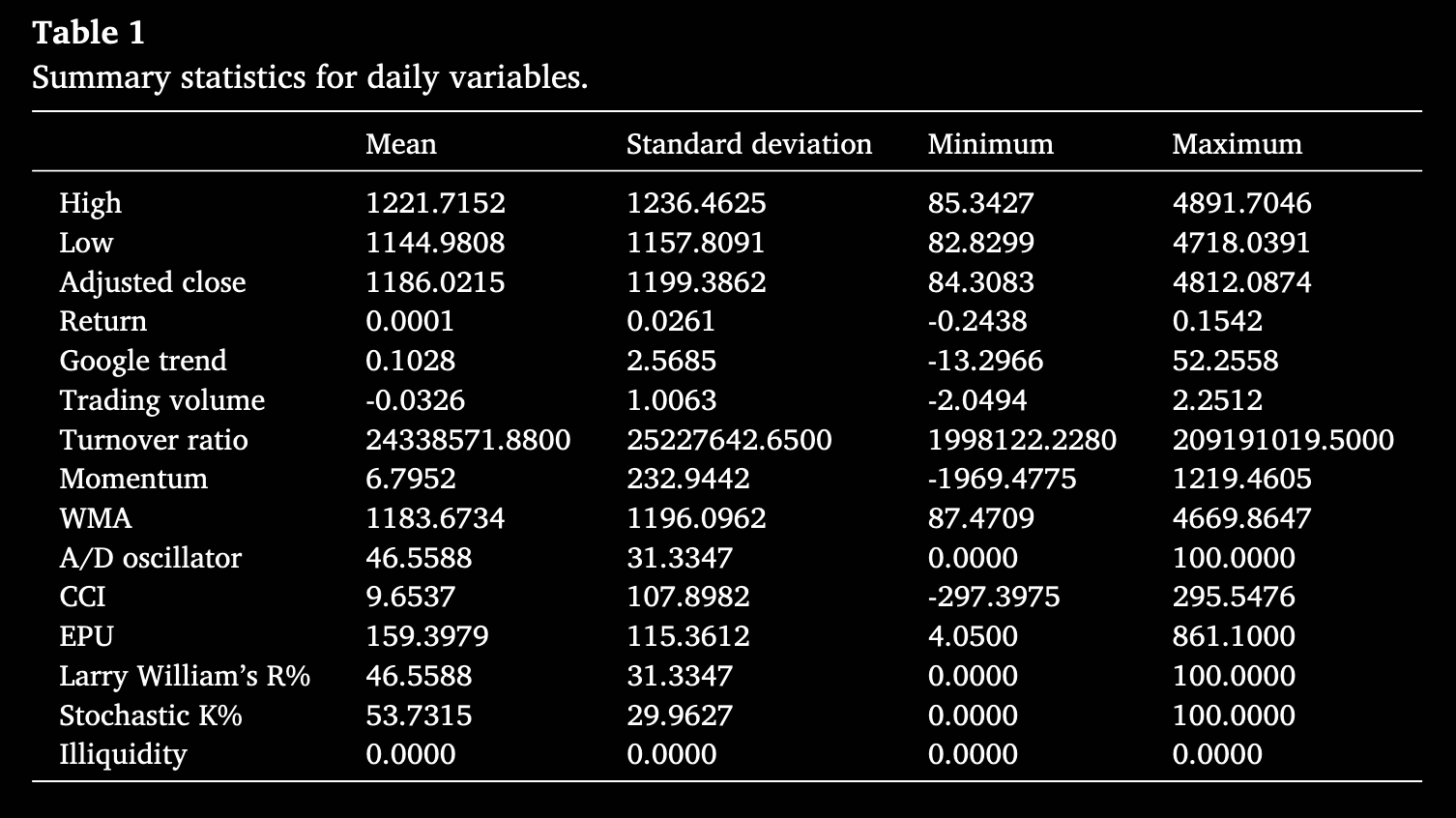
本研究选取了16项指标来预测以太坊价格走势,数据覆盖2018年4月1日至2023年4月9日,来源包括Kaggle上的以太坊历史交易数据(开盘价、最高价、最低价、调整后收盘价、交易量等)、数字金融网站与趋势分析平台(如Google Trends)的搜索频率数据,以及经济政策不确定性(EPU)数据,并在此基础上计算出若干衍生指标。文中提及的Table 1展示了这些指标的摘要统计特征,反映了各变量的均值、波动范围与极值情况,从而为后续的特征选择与模型构建提供基础依据。接下来的小节将对每个变量的定义和计算方法进行详细说明,明确它们在预测框架中的含义与作用。
Variable definitions
Ethereum trading data
Open Price 以太坊的开放价格是指在交易日开始时开始在特定交易所开始交易的价格。
High Price 在交易日,以太坊的高价代表了以太坊交易的最大价值。
Low Price 以太坊的低价表明交易日达到的最低价格点。
Adjusted Close Price 以太坊调整后的关闭价格是对收盘价的修改。它通常反映了调整数据错误后的最终价格,代表了更准确的日期估值。
Volume and trading indicators
交易量(Trading Volume)。Volume 指以太坊的原始交易量,表示在某交易日内以太坊在特定市场上买卖的总单位数量。为了便于更精确的分析,本文采用标准化交易量指标(TradingVolume)。该标准化交易量度量用于归一化每日交易活动,并提供相对的交易强度度量。具体而言,对于某日 t,标准化交易量 TradingVolumeₜ 按如下公式计算:
其中 是第
天的原始交易量,
是前一周(过去7天)交易量的平均值,
是相同时段(前一周)交易量的标准差。
收益率(Return)。以太坊的收益率用于衡量其在特定时期内的盈亏,以对数价格差形式计算。某日 的收益率计算公式为:
该公式计算一天与前一日价格的对数差,反映价格的相对变化,为日度价格波动提供归一化表示。
Google 趋势(Google Trend)。“Ethereum”一词的 Google 搜索频率数据来源于 Google Trends 平台。原始数据记为 ,使用以下公式进行标准化转换:
其中,与
的计算基于前一周的搜索频率数据。
换手率(Turnover Ratio)。换手率通过将以太坊的日交易量除以当日收盘价来计算,提供考虑价格水平后的交易活动归一化度量:
其中 表示第
天的换手率,
是当日交易量,
是当日收盘价。
动量(Momentum)。考虑到以太坊市场的高波动性和快速价格变动,引入短期动量指标。某日 的动量计算为当日收盘价与恰好九天前收盘价之差:
其中 表示第
天的动量,
代表以太坊的收盘价。
流动性缺失(Illiquidity)。以太坊的流动性缺失表示交易成本,定义为绝对收益与资产交易量的比值,可计算为:
其中 是第
天的流动性缺失度量,
是当日收益率的绝对值,
是该日的交易量。
经济政策不确定性(Economic Policy Uncertainty, EPU)。EPU 用于表示一个国家经济政策的不确定程度。
加权 日移动平均(Weighted nnn-day Moving Average, WMA)。WMA 对近期价格赋予更高权重,因此对新信息高度敏感,这在波动剧烈的加密货币市场尤为有用,因为近期价格变化可能更能指示未来趋势。在此,令
,对于10天期,WMA 按下式计算:
其中表示第
天前
天的收盘价,分母 55 是权重和(
。
累积/分配振荡器(Accumulation/Distribution Oscillator, A/D Oscillator)。该指标衡量每日资金流入和流出以太坊市场的累积程度,计算公式如下:
其中是第
天的最高价,
是当日收盘价,
是当日最低价。该公式反映了市场对以太坊的累积或分配程度。
商品通道指数(Commodity Channel Index, CCI)适用于以太坊。CCI 衡量以太坊价格与其统计平均值的偏离程度,提供市场超买或超卖的洞察。CCI 的计算步骤如下:
1、 首先,某日 的典型价格
计算为:
其中 分别为第
天的最高价、最低价和收盘价。
2、 计算 的
日简单移动平均(记为
):
此处 。
3、 计算同一 日期间的平均偏差
:
4、 最终,CCI 计算为:
Larry William’s %R(William’s Percent Range)用于以太坊,作为一种动量指标,反映收盘价相对于高低区间的位置,计算公式为:
其中 是第
天最高价,
是当日收盘价,
是当日最低价。
随机指标 %K(Stochastic %K)用于以太坊,是一种动量指标,将收盘价与特定期间内的价格区间进行比较,计算公式为:
其中 CtC_tCt 是第 天收盘价,
表示过去
天(此处
)内的最低价,
表示过去
天内的最高价。该指标衡量收盘价在过去若干天价格区间中的相对位置。
Descriptive data analysis
描述性统计结果如表1所示,日变量的相关矩阵如图1所示。价格相关变量(最高价、最低价和调整后收盘价)表现出显著的波动性,标准差较高表明其变动幅度较大。收益率的均值较低且范围较小,表明收益较为稳定可靠。Google 趋势和交易量的范围较广,反映了高度的关注度和交易活动波动。换手率的平均值和范围显著偏高,表明交易活动存在大幅波动。动量、加权移动平均(WMA)、累积/分配振荡器(A/D Oscillator)、商品通道指数(CCI)、经济政策不确定性(EPU)、Williams %R 以及随机指标 %K 等指标均表现出显著波动,其中 CCI 和动量出现了负值低点。流动性缺失(Illiquidity)始终保持为零,这表明在样本期内以太坊的市场流动性没有问题。
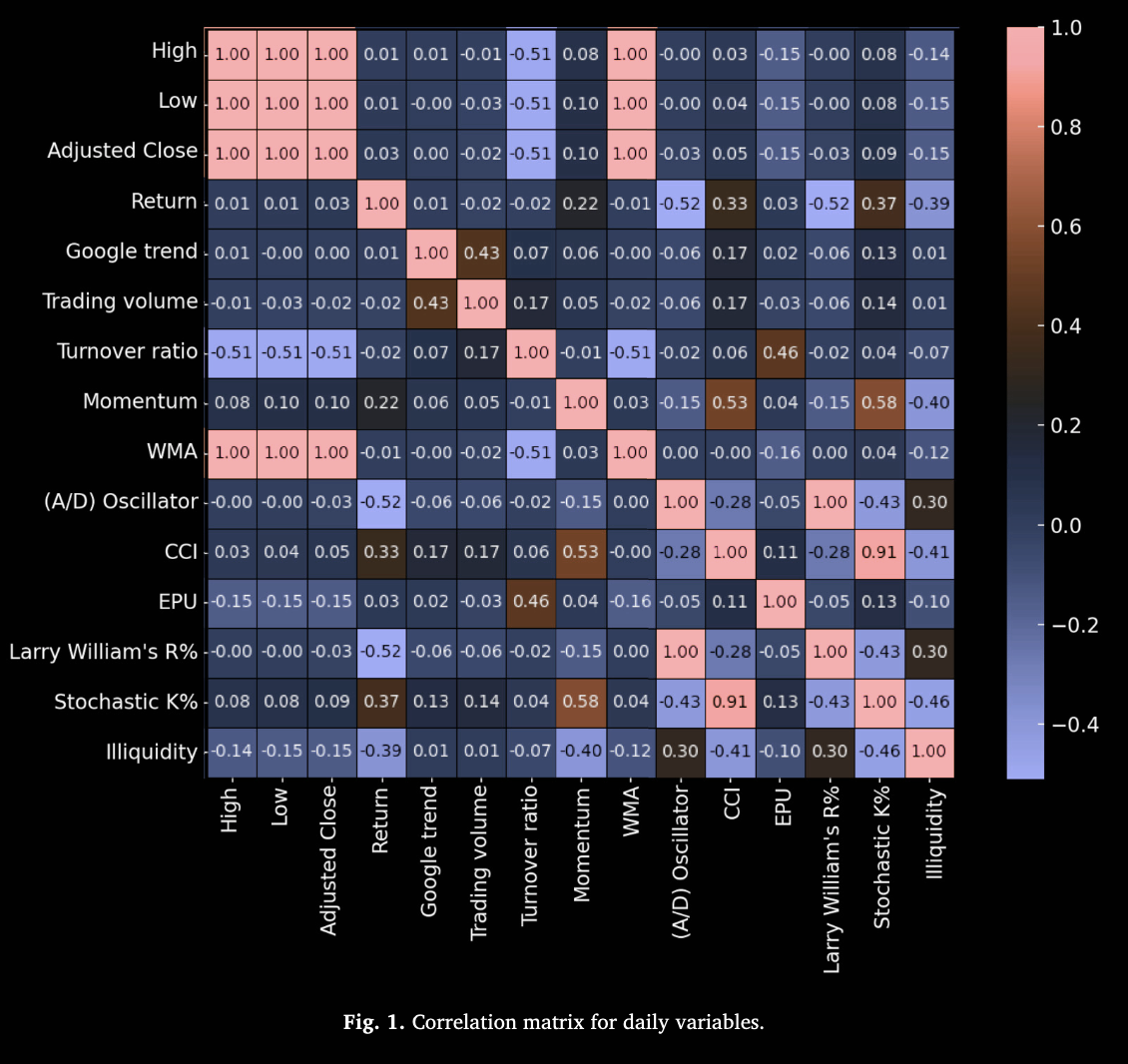
以太坊的最高价、最低价和调整后收盘价之间的相关系数为1,因为这些价格均基于同一天的相同交易数据。最高价和最低价反映了一天内的价格区间,而调整后收盘价是收盘价的函数;由于它们都源自相同的基础数据并按比例变化,因此相关性为完全正相关。交易量与 Google 趋势之间呈中度正相关,表明关注度会影响交易活动。换手率与价格指标之间呈负相关,暗示价格较高时换手率可能下降。动量、WMA、CCI 和 A/D 振荡器等指标与价格存在多样化的关联,其中一些呈较强正相关,表明它们往往与价格走势同步变化。流动性缺失与其他变量大多表现为负相关,但这些相关性总体上较弱。
Method
Feature selection
首先,在分析以太坊价格变动时,已经建立了0.001作为关键阈值。该决定基于多方面的考虑。首先,考虑到收益的平均值约为0.0001,采用0.001阈值使捕获价格波动的捕获与此平均水平显着偏差。这方面至关重要,因为它确保专注于有意义的市场运动。此外,鉴于收益的标准偏差为0.0261,相对于平均值而言,阈值较高,但并非过分,因此有效地减轻了通常由常规市场波动触发的假阳性风险。
随后采用两阶段机器学习方法深入挖掘以太坊价格走势。首先,使用随机森林分类器(Random Forest classifier,因其对复杂数据集的处理能力优秀)作为初步评估器,以识别后续特征选择阶段所需的最优邻居数(nearest neighbors)。对模型性能进行 5 折交叉验证,测试邻居数从 1 到 31。结果表明,当 neighbors = 1 时,交叉验证得分达到 0.7323,表明该参数在加密货币高波动环境下具有较强预测能力。
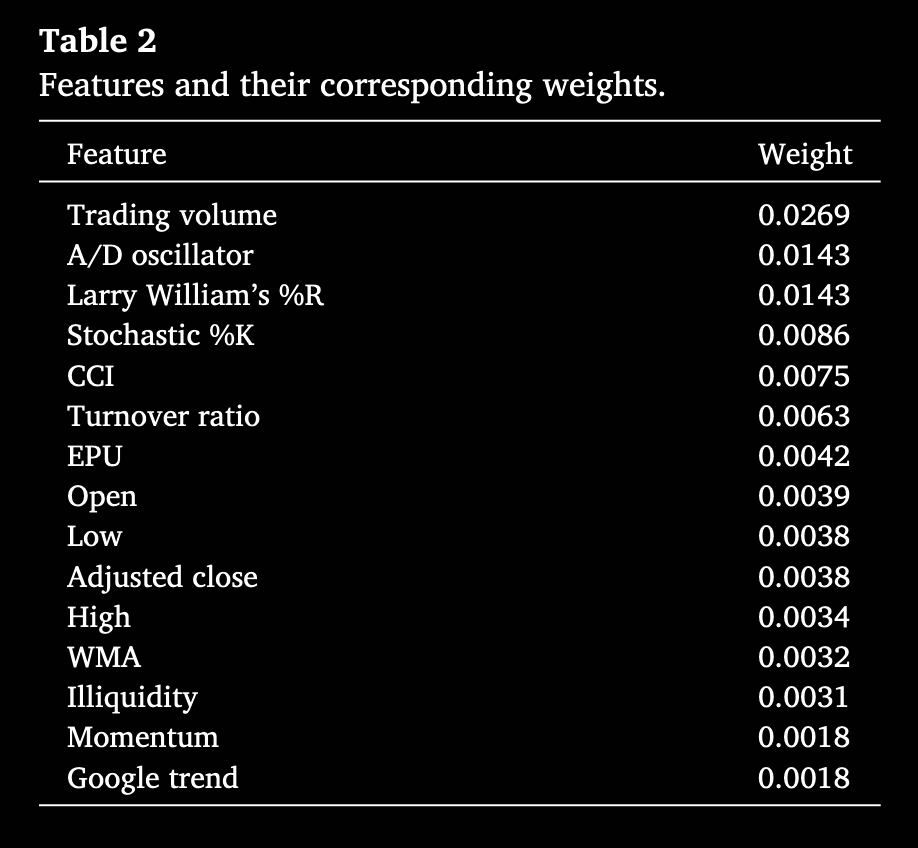
接着基于 ReliefF 算法进行特征加权,确定各特征对预测以太坊日度价格趋势的重要性。使用上述确定的最优邻居数(neighbors = 1),对包括开盘价、高价、低价、调整后收盘价、交易量及若干反映市场情绪与动量的技术指标在内的所有候选特征进行评估。分析结果如表 2 所示,最终识别出前五大最重要特征:交易量、累积/分配振荡器(A/D oscillator)、Williams %R、随机指标 %K(Stochastic %K)和商品通道指数(CCI),各自的权重反映了它们对模型准确性的贡献及解读市场波动的潜力。这些最相关特征将被用于后续 ANFIS 模型构建,以提升预测能力。
Enhanced ANFIS model construction
为确保方法兼容性,需对数据集进行全面预处理后再应用 ANFIS 模型。预处理流程首先包含短时傅里叶变换(STFT)及其逆变换(ISTFT),以丰富 ANFIS 输入:STFT 可提取频域特征并剔除高频噪声,使 ANFIS 获得更清晰、相关性更强的特征。
ANFIS 模型的多层架构(参见图 2)细分如下:
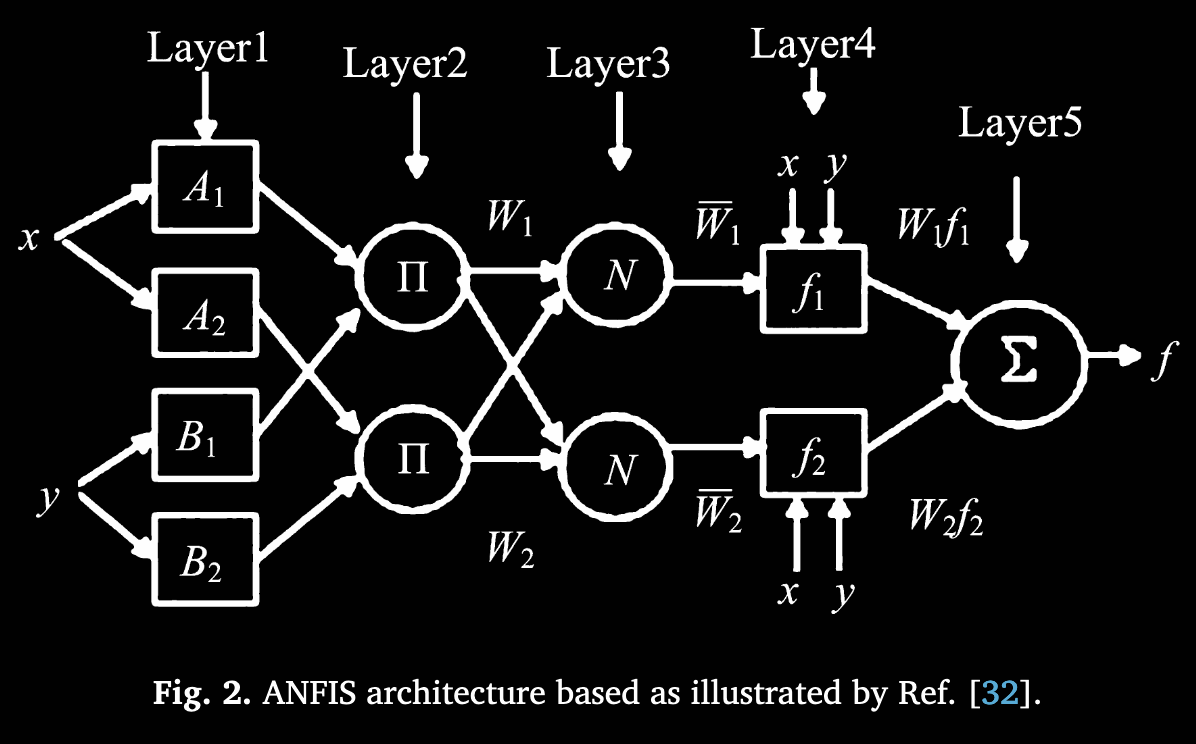
-
输入层(Input Layer):接收标准化后的特征向量
,各维度直接输出
。
-
模糊化层(Fuzzification Layer):将输入特征的精确值转为模糊值,使用 Gaussian 归属函数。共有
个节点(
条模糊规则、
个输入)。对每个输入
计算:
其中
与
是可训练的 Gaussian 函数参数。输出为各输入在每条规则下的隶属度。
-
规则层(Rule Layer):计算每条规则的激活强度(firing strength)。对规则
该乘积代表规则的代数交集。通常可对所有规则激活强度做归一化,但在后续加权时也可直接使用未归一化值或自行归一化方案。
-
去模糊化层(Defuzzification Layer):对每条规则
其中
是该规则对应的线性系数。
-
输出层(Output Layer):聚合所有规则的输出并通过激活函数得到最终二分类概率。先求和:
然后应用 sigmoid 函数:
将结果映射到
之间,以进行二分类(趋势上涨或下跌)。
通过上述层次结构,ANFIS 从输入归一化、隶属度计算、规则激活、线性组合到最终激活函数输出,逐层处理不确定性与非线性。此结构在输入数据具有模糊性或不确定性时尤为有效。
Membership functions
在 ANFIS 模型构建中,模糊化层所用归属函数的选择尤为关键。本文主要采用 Gaussian 归属函数,其定义为:
其中 为均值,
为方差。Gaussian 函数曲线平滑连续,可微性良好,适合在训练过程中进行多次迭代优化;同时其非线性特征使得模型能够更好地刻画输入与输出之间的复杂关系。在具体实现中,对于每个输入特征
及每条规则
,分别计算隶属度值
,并将
、
作为可训练参数,通过训练自动调整,以匹配数据特征。这样,模糊化层可以有效地将精确输入转为反映非线性和不确定性的模糊值,为后续规则推理提供基础。Gaussian 归属函数的可微和非线性属性显著提升了 ANFIS 从复杂数据中学习的能力,从而改善预测性能。
Experiment
Pre-processing
在应用 ANFIS 模型之前,对数据集进行了全面的预处理,以确保与所采用分析方法的最佳兼容性。初始阶段涉及应用短时傅里叶变换(STFT)及其逆变换(ISTFT),这是数据处理工作流的重要组成部分。STFT 是分析信号时变频率和振幅的关键工具,对于捕捉数据的动态特征至关重要343434。实现中,定义了一个自定义函数 stft_transform,用于对数据样本执行 STFT 和 ISTFT。该函数以数据样本为输入,并以以下参数执行 STFT:FFT 点数 设为 256;重叠点数
设为 128,以在保证计算效率的同时获得较好的频率分辨率。STFT 操作将输入数据分解为频率分量
、对应的时间窗口
以及复数 STFT 系数
。此转换能够在时间上观察信号的频谱特性演变,为后续分析提供重要信息。随后,使用相同的 FFT 点数和重叠参数对
应用 ISTFT,以便从频域表示重构时域信号。重构后的信号被截取至与原始输入数据相同的长度,以保持数据维度一致性。
第二阶段的预处理涉及隔离关键特征“William”、“Volume”、“CCI”、“Oscillator”和“Stochastic”。在特征选择之后,使用 sklearn.preprocessing 包中的 StandardScaler 对数据进行标准化处理,使每个特征具有均值为零、标准差为一的分布。这种方差归一化是建模算法的前提条件。然后,利用 sklearn.model_selection 模块中的 train_test_split() 函数将数据集划分为训练集和测试集,采用 80%:20% 的比例划分,并将 random_state 设为 2023,以确保不同实验运行中的数据划分一致,从而保证实验的可重复性和可比性。特征数组和目标数组随后被转换为张量,形成与 PyTorch 神经网络模块兼容的基础数据结构。数据集中无缺失值,保证了后续模型训练和验证阶段的数据完整性。
Experimental setup
实例化 ANFIS 模型时,配置了 10 条模糊规则,以平衡模型的复杂度和泛化能力。数据集中正类(标签“1”)有 879 个样本,负类(标签“0”)有 956 个样本。在对 ANFIS 模型进行微调时,采用带权重的二元交叉熵损失函数(BCEWithLogitsLoss)作为损失准则,以应对类别不平衡问题。正类的权重(pos_weight)按负样本数与正样本数之比计算,得到:
这种做法对较少的正类样本的误分类赋予更高的惩罚,从而防止模型对更多的负类样本产生偏向。模型优化器选用 AdamW,学习率设为 0.001,并使用 L2 正则化以防止过拟合。训练迭代共进行 1000 个 epoch,每个 epoch 记录性能指标,以监控学习进度并在必要时实施提前停止。性能评估在每个 epoch 通过自定义的 evaluate() 函数进行,该函数计算训练集和测试集上的准确率、精确率、召回率和 F1 分数。具体做法是对模型输出的 logits 应用 sigmoid 激活,从而确定预测概率并据此判定类别。数据集规模与模糊规则数量的选择基于初步实验,以在模型表示能力与数据模式复杂度间取得平衡;学习率和训练轮数则通过经验确定,以确保模型权重在训练过程中能够收敛。
Experimental results and discussion
后续符号用于说明评估模型性能的指标:当模型正确预测正向结果(1)时记为真正例(True Positive,TP);当模型错误地将负向(0)预测为正向(1)时记为假正例(False Positive,FP)。当模型错误地将正向(1)预测为负向(0)时记为假反例(False Negative,FN);当模型正确识别负向结果(0)时记为真反例(True Negative,TN)。这些参数在式 (9)–(12) 中定义:
其中,Accuracy 衡量模型在所有预测中正确预测的比例;Precision 衡量模型预测价格上涨(正类)时的准确度;Recall 衡量模型捕捉所有实际价格上涨事件的能力;F1 Score 则是 Precision 与 Recall 的调和平均,提供两者之间的平衡。表 3 给出了模型在训练集和测试集上的性能指标。
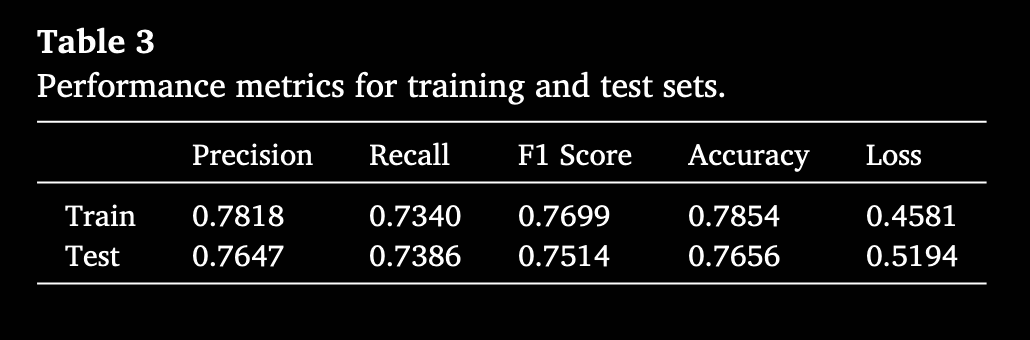
模型在训练集和测试集上的表现如下:训练集 Recall 为 73.40%,测试集 Recall 为 73.86%,表明模型对真正例(价格上涨)的识别能力较好,并且在熟悉数据和新数据上均能保持较稳的敏感度,这一稳定性显示算法具有鲁棒性,不会在未见数据上大幅损失召回能力。训练集 F1 Score 为 76.99%,测试集 F1 Score 为 75.14%,作为 Precision 与 Recall 的调和平均,说明模型在平衡准确预测上涨与捕获上涨事件方面表现良好;训练和测试集之间仅有小幅下降,表明模型对未知数据依然具备可靠性能。
训练集 Accuracy 为 78.54%,测试集 Accuracy 为 76.56%,该指标反映正确分类的比例。高训练准确率表明模型已有效学习数据中的模式;测试集仍维持高准确率,说明模型具备良好泛化能力,能够在未见数据上保持较高的正确分类率。模型 Precision 在训练集为 78.18%,测试集为 76.47%,显示其在识别正类时具有较高精度,从训练到测试集的一致性进一步说明模型没有过度拟合而丧失对正类的识别能力,保持了对正类特征的有效学习。
Loss 指标衡量预测值与真实值之间的差距。训练集 Loss 为 0.4581,表示训练阶段模型预测误差较低,说明模型已较好地学习到训练数据特征。测试集 Loss 略升至 0.5194,常见于模型在测试数据上误差略高,因为测试数据为未见过的数据,但差距不大,说明模型在新数据上依然表现稳定。
图 3 显示了半年时间范围内的真实趋势与预测趋势的时序可视化。真实(实际)与预测线频繁交叉,反映了以太坊价格的高波动性,与加密货币市场已知特征一致。图中红线(预测趋势)大体上与真实趋势吻合,与整合 ANFIS-STFT 模型的 76.56% 测试准确率相符。
Additional insights: performance over several epochs and membership function visualization
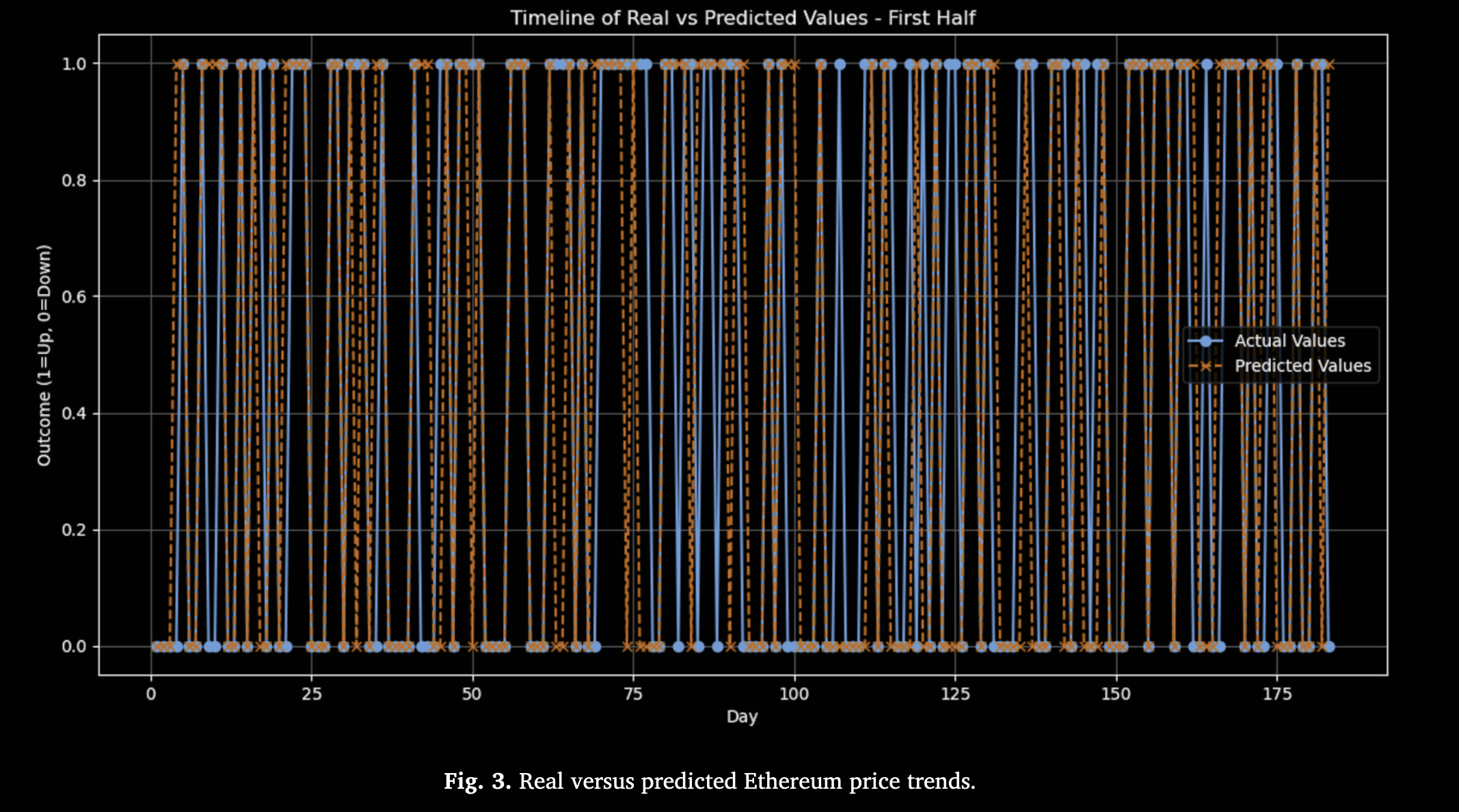
图 4 给出了若干 epoch 下训练集与测试集的损失和性能指标曲线。图中损失快速下降后趋于稳定收敛,测试集损失紧跟训练集损失,说明模型快速适应且无明显过拟合现象。准确率在各轮次均表现较高且稳定,表明泛化能力稳健。Precision 和 Recall 从一开始即较高并保持稳定,这在某些情况下可能与保守预测或类别分布不平衡有关,但也反映模型对正类和负类判断都较可靠。F1 Score 同样从高位开始并保持稳定,体现 Precision 与 Recall 的平衡良好。训练与测试曲线走势几乎平行,表明在从熟悉数据到未知数据的转换中,性能无明显下降,充分展现了模型在处理复杂和高波动数据时的有效性。
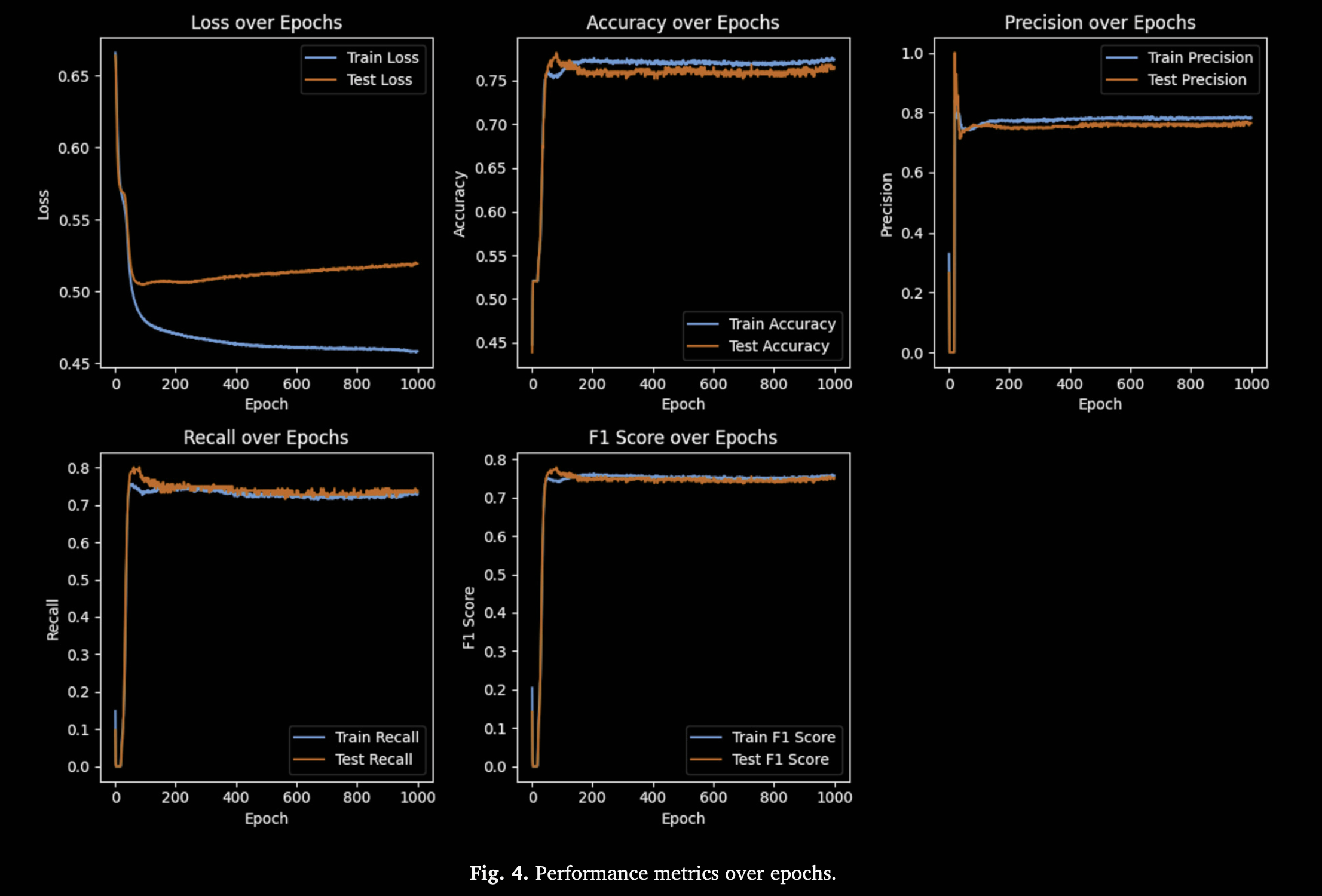
图 5 展示了混淆矩阵和 AUC-ROC 曲线,进一步验证模型优秀性能。混淆矩阵显示无论训练集还是测试集,TP 与 TN 均明显多于 FN 与 FP,表明模型具备较好的预测能力。AUC 值接近 0.76–0.77,虽非完美分类(AUC=1),但对于高度波动的加密货币价格预测而言已属良好区分度。
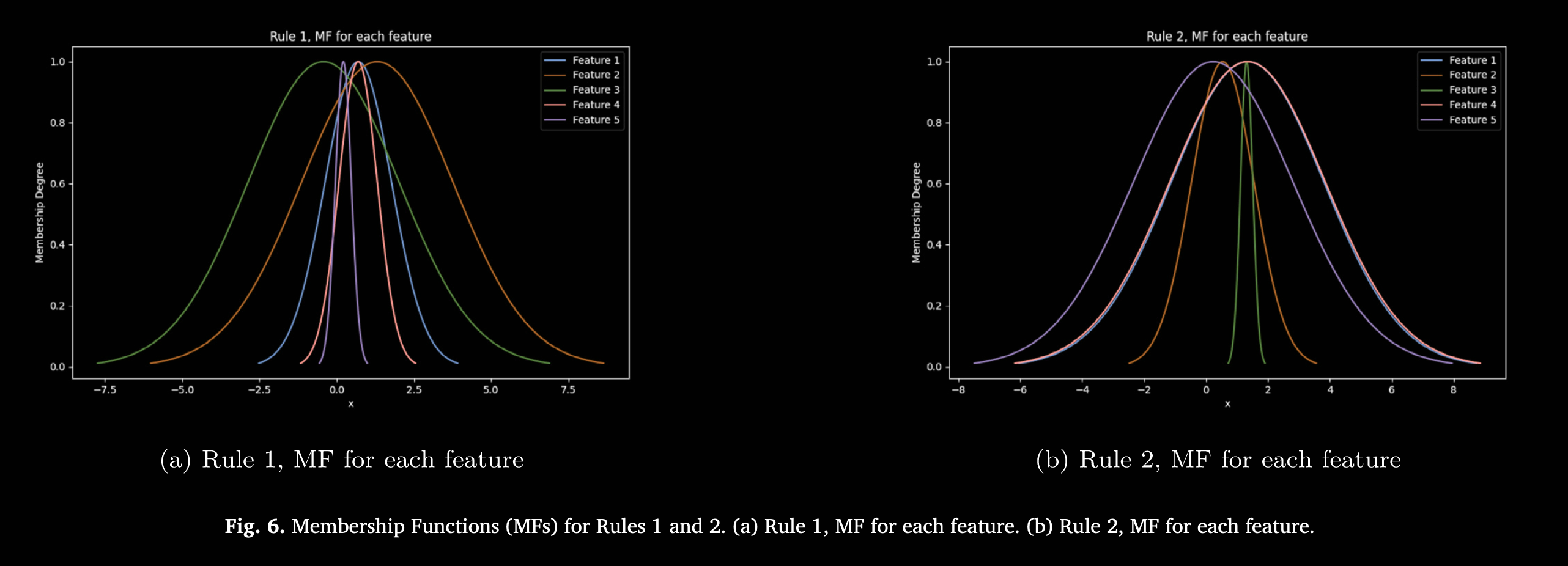
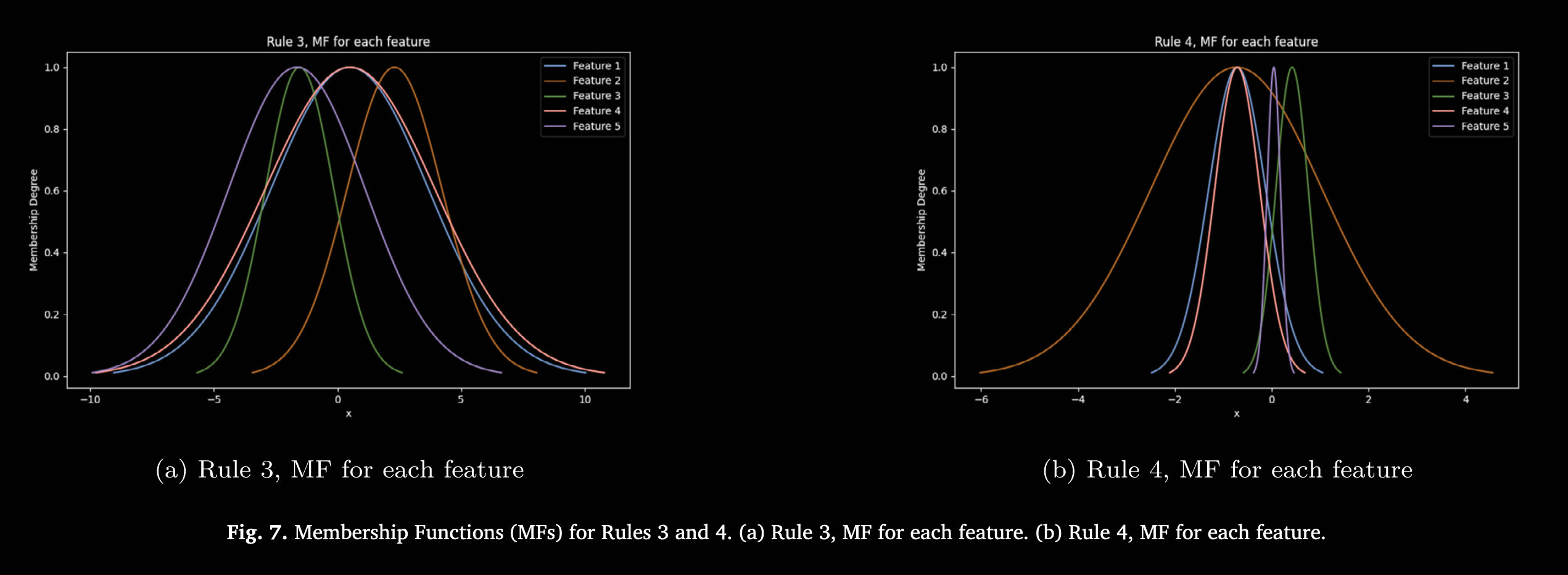
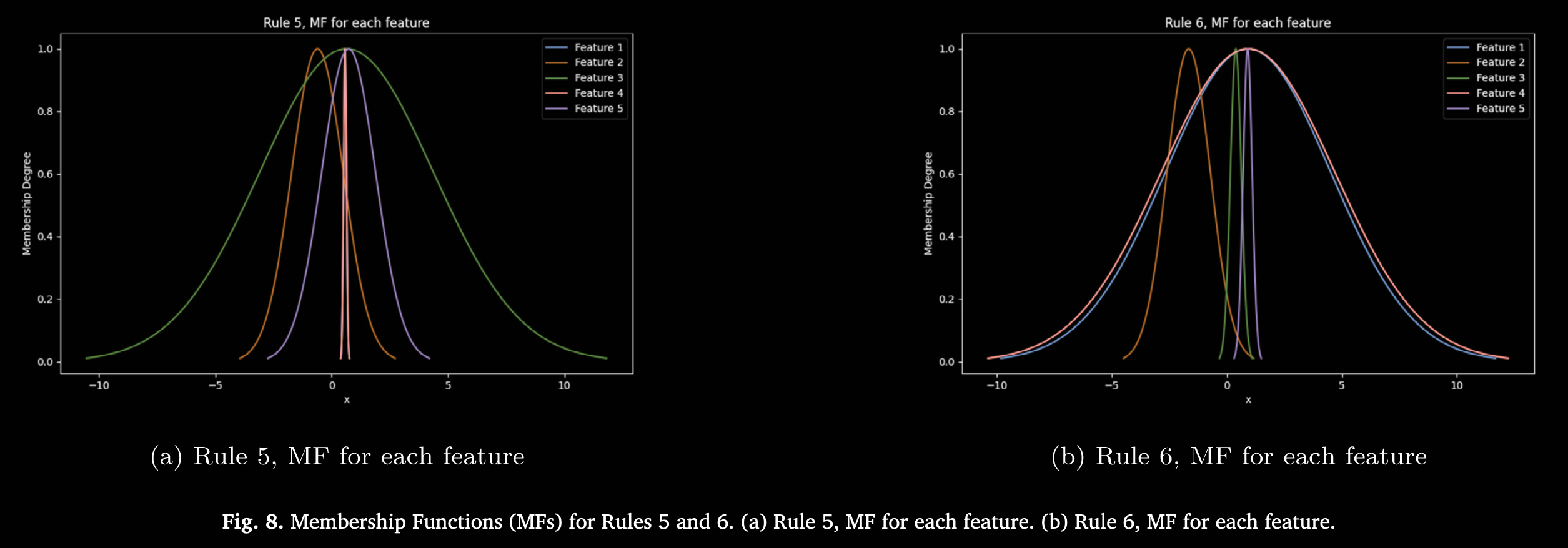
图 6–图 10 则展示了各规则所学习到的隶属函数(Membership Functions, MFs)可视化,体现 ANFIS 模型针对预测以太坊价格走势所适配的细节。每幅图均对应某条或某几条规则下各输入特征的高斯隶属函数曲线。通过训练,ANFIS 自动学习规则及其参数,并动态调整这些高斯曲线的形状和位置,以捕捉市场行为特征。曲线的陡峭或宽度反映模型对该特征变化的敏感度,陡峭表示模型对该特征变化更为敏感,说明其对预测输出影响较大。隶属函数在训练过程中不断优化,形状和位置随之调整,从而更好地契合以太坊市场数据的潜在模式,提升模型性能。
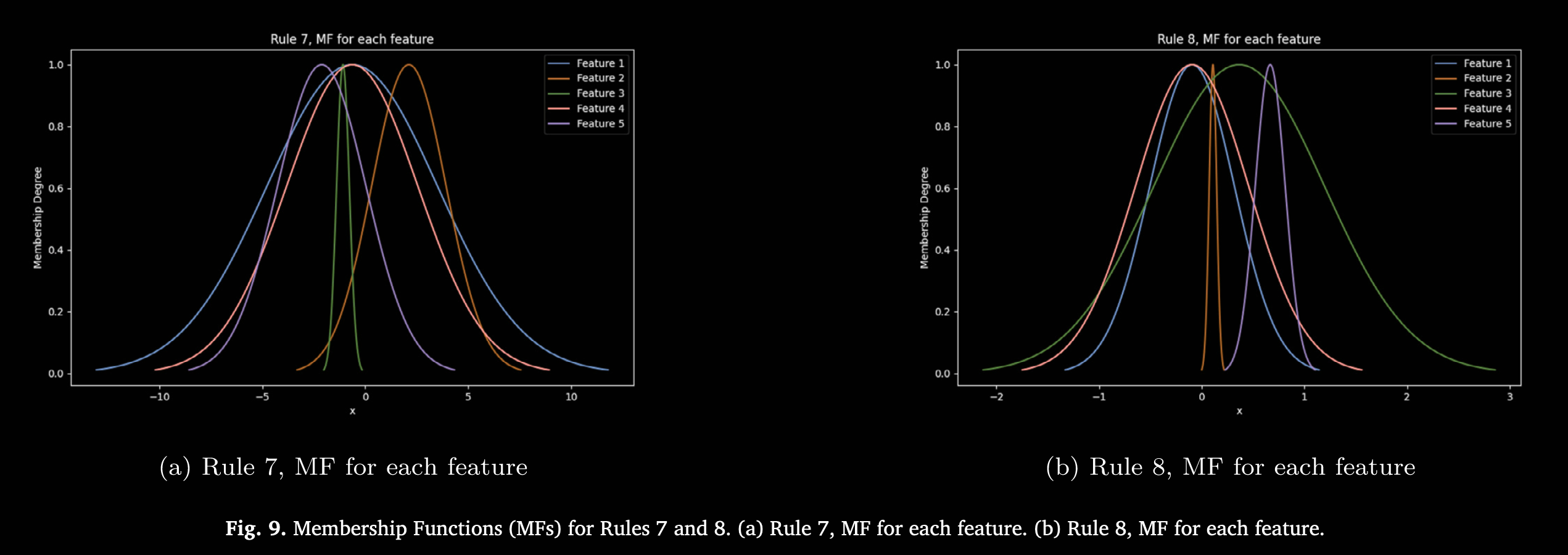
Performance comparison with other models
表 4 给出了多种机器学习和深度学习模型(如 Gradient Boosting、LSTM、Random Forest、XGBoost)在以太坊日度价格趋势预测任务上的性能指标。表中各模型在训练集和测试集上的 Accuracy、Precision、Recall、F1 Score 以及混淆矩阵和 ROC-AUC Score 均有列示。
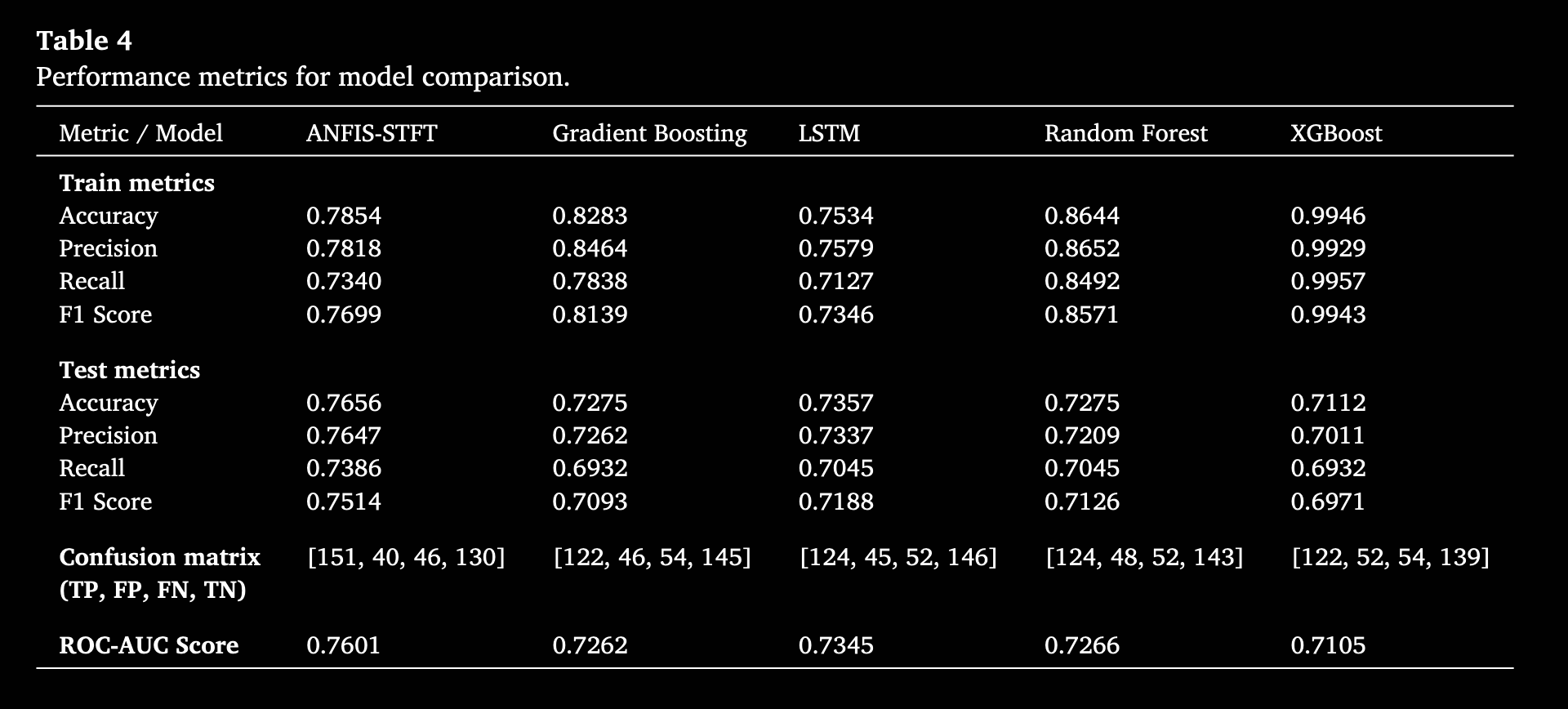
从结果看,XGBoost 在训练集上取得了最高的 Accuracy、Precision 和 F1 Score,但在测试集上性能明显下降,表明其易于在训练集上过拟合。相比之下,ANFIS-STFT 在测试集上的 Accuracy、Precision、Recall 和 F1 Score 表现优异,且对过拟合具有较强抵抗力。ANFIS-STFT 结合了神经网络学习与模糊逻辑推理,这一双重方法显著提升了模型处理非线性关系、发现隐藏周期模式并适应动态市场条件的能力。其在测试集上的 ROC-AUC 为 0.7601,超过 Gradient Boosting(0.7262)和 XGBoost(0.7105),再次凸显其对未知数据的区分能力。ANFIS-STFT 的混淆矩阵在 TP 与 TN 之间保持较为平衡,表明其对正负类别的分类能力均衡且泛化能力强。整体而言,ANFIS-STFT 在训练集和测试集上均表现一致,高 ROC-AUC 及平衡的混淆矩阵体现了其出色的泛化能力和对数据波动的处理能力。此外,该模型融合模糊逻辑提升了可解释性,减轻了复杂机器学习模型常见的过拟合和对噪声敏感等问题。
对比分析强调了在复杂、高波动的加密货币价格预测中,需采用诸如正则化、交叉验证等稳健策略来防止过拟合,并持续探索优化技术以提升模型可靠性和效果。ANFIS-STFT 的成功应用展示了将信号处理(STFT)与可解释性强的模糊推理模型(ANFIS)相结合,在应对市场波动、捕捉复杂模式方面具有优势,为今后进一步改进和扩展预测模型提供了思路。
Conclusion
本研究通过将随机森林分类器与ReliefF方法相结合,识别出显著影响以太坊价格趋势的五大关键特征:交易量、累积/分配振荡器(A/D oscillator)、Larry William’s %R、随机指标(Stochastic %K)和商品通道指数(CCI),在加密货币分析领域取得了重要进展。利用ANFIS模型配合短时傅里叶变换(STFT)技术,对以太坊价格趋势变化进行预测,在训练集和测试集上均获得了高度一致且优异的准确率、精确率、召回率和F1得分,证明了所提模型的有效性。本文创新性地将STFT技术与ANFIS模型相融合,不同于现有研究仅侧重时域分析或传统机器学习方法,该方法能够同时捕捉时域和频域的模式,使模型更好地理解并适应市场的动态变化,从而增强其在多种市场环境和时间范围内的泛化能力。
过往针对以太坊价格预测的研究多集中于使用统计模型或机器学习模型进行时间序列分析,而在预测建模中应用STFT进行金融数据预处理的工作相对较少。通过STFT,将以太坊价格数据转换到频域,可揭示原始时序数据中不易察觉的隐藏周期模式与趋势。ANFIS-STFT模型在以太坊价格预测中的表现包括稳定的召回率(训练集73.40%、测试集73.86%),表明模型在不同数据集上均具备稳健的真正例识别能力;F1得分(训练集76.99%、测试集75.14%)展示了精确率与召回率之间的良好平衡,且在新数据上仅有轻微下降;高准确率(训练集78.54%、测试集76.56%)则体现了模型强大的预测能力与泛化能力;精确率(训练集78.18%、测试集76.47%)凸显了模型在新数据环境下依然能可靠识别正类;损失值(训练集0.4581、测试集0.5194)显示训练阶段有效减少误差,应用于测试集时损失略有上升却在可接受范围内。
研究成果具有重要的实际意义。投资者和金融分析师可以基于所识别的关键特征更深入地理解以太坊市场行为并改进预测策略。例如,交易量与A/D振荡器能洞察市场压力与资金流向,Larry William’s %R与Stochastic %K对于评估市场状态至关重要,而CCI有助于识别新兴或结束中的价格趋势。这些洞见对于制定知情的以太坊投资策略具有重要价值。此外,模型可助力银行和金融机构开发创新金融产品,如基于以太坊的衍生品或投资组合,并使其与市场需求和风险偏好相适应。本研究还为学术界与金融科技开发者提供了一种有价值的工具,用以探究加密货币市场的深层动态,有望激发类似研究在其他金融市场和工具上的应用,从而推动金融科技领域的发展。研究发现不仅为以太坊价格预测作出贡献,还为加密货币分析开辟了新方向,提供了一种能够适应快速市场变化的分析工具。
然而,STFT预处理和ANFIS模型训练的高计算成本限制了本研究在实时交易场景下的可扩展性。未来研究可通过采用更高效的算法、利用并行处理或借助云计算资源来应对大规模数据处理需求,以减轻该限制。此外,还可探索将所提模型应用于其他加密货币和金融市场,以获得关于市场动态和投资者行为的新见解
superx的思考
这篇论文的核心在于提出并验证一种针对以太坊价格趋势预测的混合方法:首先通过随机森林分类器与ReliefF算法相结合的两阶段特征选择流程,从众多潜在指标中筛选出最具预测价值的五大特征(交易量、A/D振荡器、Williams %R、Stochastic %K 和 CCI);然后在此基础上,利用短时傅里叶变换(STFT)对时间序列数据进行频域预处理,提取潜藏的周期模式并去除噪声,再将这些时域与频域特征输入自适应神经模糊推理系统(ANFIS)进行训练与预测。整个流程覆盖从原始数据获取与派生指标计算,到有针对性的特征筛选,再到基于信号处理的预处理与可解释性较强的模糊推理网络建模,旨在捕捉以太坊市场高度波动性下的非线性与时频特征,实现对日度价格涨跌趋势的更准确预测。
这篇文章的创新点主要体现在以下几个方面:第一,将STFT技术引入金融时间序列预处理,在加密货币预测领域较为少见,通过频域分析发现传统时域模型难以捕捉的隐藏周期模式与波动特征;第二,将时域与频域特征有机融合到ANFIS框架中,利用其结合神经网络学习与模糊逻辑推理的能力,既能处理非线性关系,又具备较好的可解释性;第三,设计了一套基于收益率阈值(0.001)定义涨跌标签的策略,并采用随机森林与ReliefF的组合筛选流程,精准找出在高波动市场下最重要的特征,从而降低模型复杂度并提升鲁棒性;第四,在模型训练中针对类别不平衡使用加权二元交叉熵、合理配置模糊规则数量以及超参数(如学习率、训练轮数等),确保稳定收敛并具备良好泛化能力。综合来看,这些创新使得所提ANFIS-STFT方法既能更深入地揭示以太坊价格的时频动态,又在预测性能和解释能力上优于传统机器学习和深度学习方法。
By Superx,written in Chengdu

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)