基于深度学习的视听情感融合算法研究
本文提出了一种基于深度学习的视听情感融合算法,通过结合音频和视觉信息实现更准确的情感识别。研究首先介绍了双通道理论、互补性和冗余性原理作为理论基础,然后详细阐述了音频特征(MFCC、韵律特征)和视觉特征(面部动作单元、深度特征)的提取方法,以及时序特征的LSTM处理。在模型架构方面,采用了2D-CNN、3D-CNN和注意力融合策略,并提供了MATLAB实现代码。实验结果表明,该多模态融合方法能够有
目录
视听情感融合算法是一种多模态学习方法,它结合语音和面部表情信息来识别更准确的人类情感状态。人类情感表达通常通过多种渠道传达,单一模态可能受到环境噪声或个体表达习惯的影响,而多模态融合能够利用不同模态之间的互补性,提高情感识别的准确率和鲁棒性。
1.基于深度学习的视听情感融合算法
情感计算是人工智能领域的一个重要研究方向,旨在让计算机能够识别、解释、处理和模拟人类情感。视听情感融合作为情感计算的关键技术,主要基于以下理论基础:
双通道理论:人类通过听觉和视觉两个主要通道接收信息,这两个通道在大脑中协同工作,形成对外部世界的综合感知。
互补性原理:音频和视觉信息在情感表达中具有互补性。例如,语音中的语调变化能反映情感强度,而面部表情则更直观地传达情感类型。
冗余性原理:不同模态可能包含部分重叠信息,利用这些冗余信息可以提高系统的鲁棒性。
2.视听情感特征提取
特征提取是视听情感融合的第一步,其目的是从原始信号中提取出能够有效表征情感信息的特征向量。
2.1 音频特征提取
音频信号中的情感信息主要体现在声学特征的变化上,常见的音频特征包括:
声学特征:如音高 (Pitch)、音长 (Duration)、音强 (Intensity) 等,这些特征直接反映了语音的基本属性。
频谱特征:如梅尔频率倒谱系数 (MFCC)、线性预测倒谱系数 (LPCC) 等,这些特征描述了语音的频谱特性。
韵律特征:如语速、语调、停顿等,这些特征与情感表达密切相关。
数学上,音频特征提取过程可以表示为:
A=fa(xa;θa)
其中,xa是原始音频信号,θa是特征提取参数,fa是特征提取函数,A是提取的音频特征向量。
音频一般使用RNN/LSTM处理时序信息,或使用CNN提取频谱特征。
2.2 视觉特征提取
视觉信息中的情感线索主要来自面部表情、身体姿态和动作等。常见的视觉特征包括:
面部特征:如面部关键点 (landmarks)、表情动作单元 (Action Units, AU) 等。
纹理特征:如局部二值模式 (LBP)、Gabor 滤波器等提取的纹理特征。
深度特征:利用卷积神经网络 (CNN) 提取的高级语义特征。
视觉特征提取过程可以表示为:
V=fv(xv;θv)
其中,xv是原始视频序列,θv是特征提取参数,fv是特征提取函数,V是提取的视觉特征向量。
视频一般使用3D-CNN处理时空信息,或2D-CNN处理面部特征。
2.3 时序特征处理
由于音频和视频信号都具有时序特性,通常需要使用循环神经网络(RNN)或其变体(LSTM、GRU)来处理时序信息:
ht=g(ht−1,xt;θg)
其中,xt是时刻t的输入特征,ht−1是上一时刻的隐藏状态,θg是网络参数,ht是当前时刻的隐藏状态。
3. 深度学习模型在视听情感分析中的应用
深度学习模型因其强大的特征表达能力,已成为视听情感分析的主流方法。其结构如下图所示:
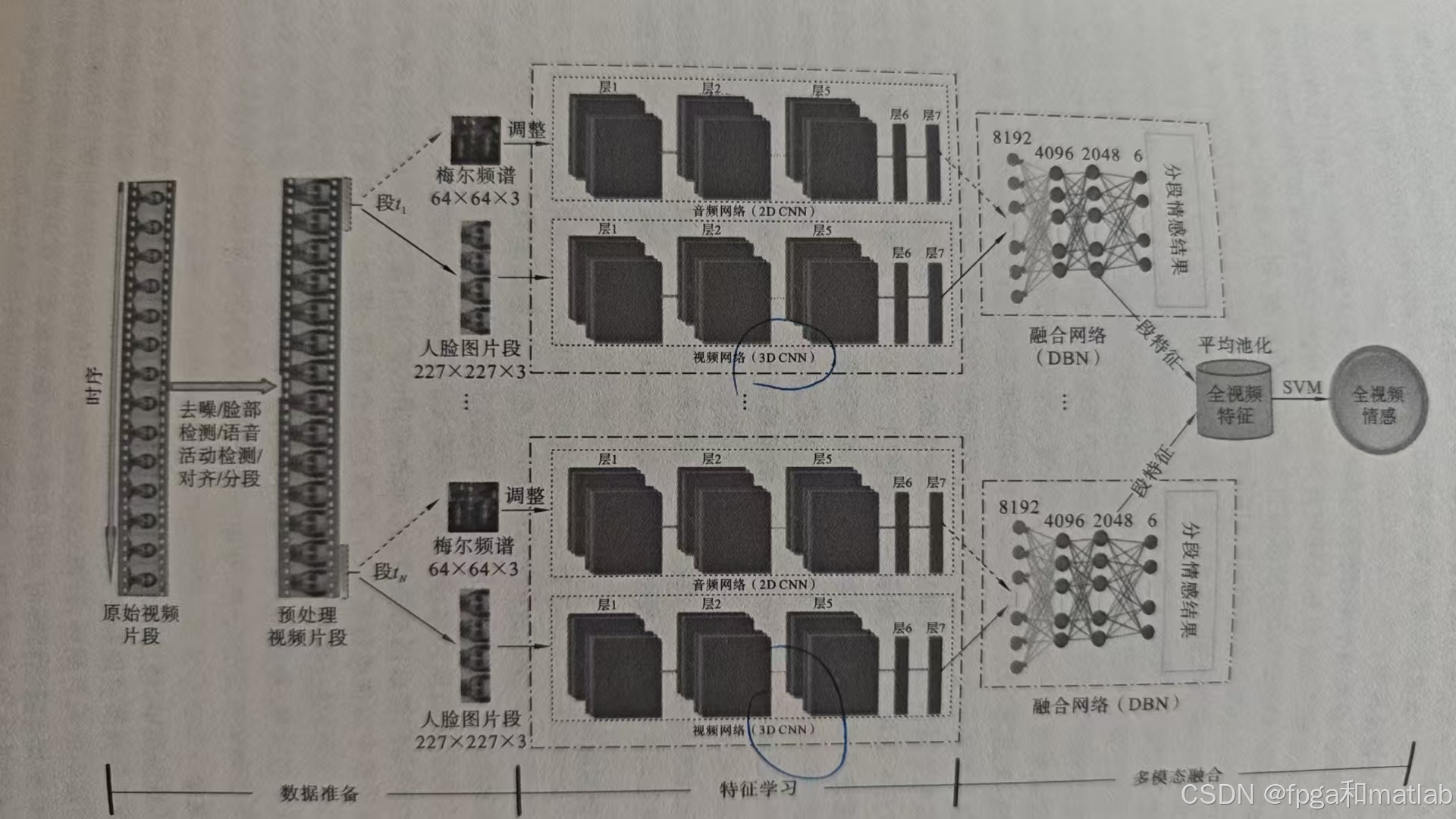
3.1 卷积神经网络(2D-CNN)
CNN特别适合处理具有网格结构的数据如图像和音频频谱图。在视觉情感分析中,CNN可以自动学习到面部表情的空间特征:
y=σ(W⋅ReLU(Wl−1⋅ReLU(⋯W1⋅x+b1)+⋯)+bl)
其中,x是输入数据,Wi和bi是第i层的权重和偏置,σ是激活函数,y是输出特征。
3.2 3D-CNN网络模型
3D卷积神经网络(3D Convolutional Neural Network, 3D-CNN)是传统2D-CNN的扩展,专门设计用于处理具有三维结构的数据,如视频、体积医学图像、点云等。与2D-CNN相比,3D-CNN能够同时捕获空间和时间维度上的特征,在视频分析、动作识别、医学图像处理等领域取得了显著的成果。3D-CNN通过引入三维卷积核,能够同时在空间和时间维度上进行特征提取,从而更自然地处理时序数据。
3D卷积操作与2D卷积类似,但卷积核是三维的,同时在空间和时间维度上滑动。给定一个输入体积X∈RT×H×W×Cin,其中T是时间维度,H和W是高度和宽度,Cin是输入通道数,3D卷积操作可以表示为:

3.3 视听情感融合策略
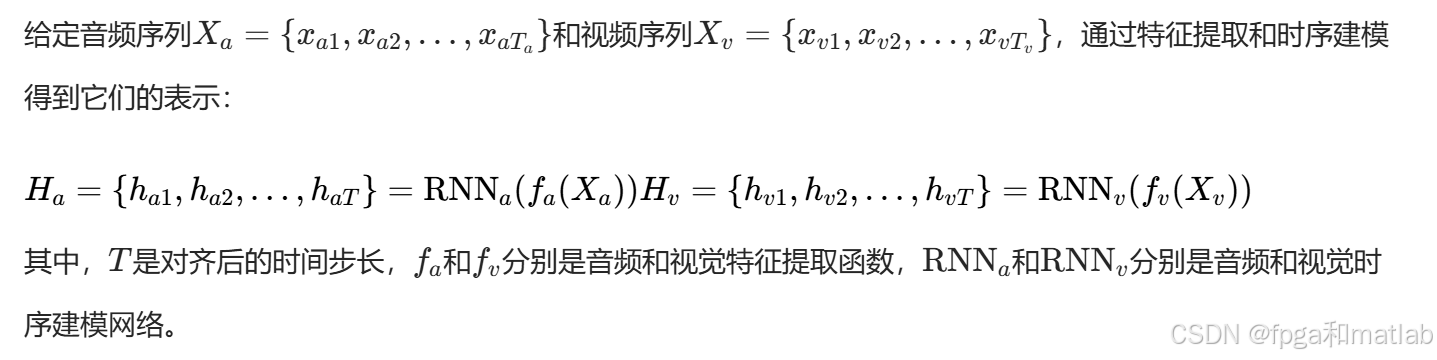
为了捕获模态间的依赖关系,可以引入模态间注意力机制:

使用注意力加权后的特征进行融合:
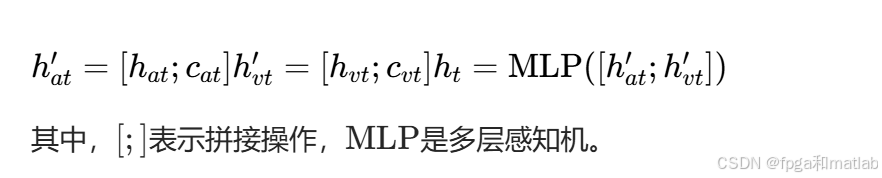
3.4 视听情感分类
基于融合特征进行情感分类:
p(y∣Xa,Xv)=softmax(Wh⋅h+bh)
其中,h是融合后的全局特征,Wh和bh是分类器参数,p(y∣Xa,Xv)是给定视听输入的情感类别概率分布。
4. MATLAB测试
MATLAB主体代码大概如下:
% 基于深度学习的视听情感融合算法主函数
% 参数设置
params.audioFeatureType = 'MFCC'; % 音频特征类型:MFCC, Spectral
params.visualFeatureType = 'CNN'; % 视觉特征类型:HOG, CNN
params.fusionType = 'attention'; % 融合类型:early, middle, late, attention
params.useAttention = true; % 是否使用注意力机制
params.numClasses = 6; % 情感类别数:生气、厌恶、恐惧、快乐、悲伤、中性
params.numEpochs = 50; % 训练轮数
params.batchSize = 64; % 批次大小
params.learningRate = 0.001; % 学习率
params.valRatio = 0.2; % 验证集比例
% 加载数据
fprintf('加载视听情感数据集...\n');
[audioFeatures, visualFeatures, labels] = loadAVEmotionDataset(params);
% 数据预处理
fprintf('数据预处理...\n');
[audioFeatures, visualFeatures, labels] = preprocessData(audioFeatures, visualFeatures, labels);
% 划分训练集、验证集和测试集
fprintf('划分训练集、验证集和测试集...\n');
[trainIdx, valIdx, testIdx] = partitionData(size(audioFeatures, 1), params.valRatio);
% 创建深度学习网络
fprintf('创建深度学习网络...\n');
[audioNet, visualNet, fusionNet] = createDeepLearningNetworks(params);
% 训练模型
fprintf('开始训练视听情感融合模型...\n');
trainedModel = trainAVEmotionModel(audioFeatures, visualFeatures, labels, trainIdx, valIdx, ...
audioNet, visualNet, fusionNet, params);
% 测试模型
fprintf('测试模型性能...\n');
[accuracy, confusionMat, classReport] = testAVEmotionModel(trainedModel, audioFeatures, visualFeatures, labels, testIdx);
% 显示结果
displayResults(accuracy, confusionMat, classReport);其中深度学习模型如下
function [audioNet, visualNet, fusionNet] = createDeepLearningNetworks(params)
% 创建深度学习网络架构
% 音频网络
if strcmpi(params.audioFeatureType, 'MFCC')
% 创建处理MFCC特征的网络
audioLayers = [
sequenceInputLayer([13 100], 'Name', 'audioInput')
% 卷积层
convolution2dLayer([3 3], 16, 'Padding', 'same', 'Name', 'audioConv1')
batchNormalizationLayer('Name', 'audioBN1')
reluLayer('Name', 'audioRelu1')
maxPooling2dLayer([2 2], 'Stride', [2 2], 'Name', 'audioPool1')
convolution2dLayer([3 3], 32, 'Padding', 'same', 'Name', 'audioConv2')
batchNormalizationLayer('Name', 'audioBN2')
reluLayer('Name', 'audioRelu2')
maxPooling2dLayer([2 2], 'Stride', [2 2], 'Name', 'audioPool2')
% 循环层
depthToSequenceLayer('Name', 'audioDepthToSeq')
lstmLayer(64, 'OutputMode', 'last', 'Name', 'audioLSTM')
fullyConnectedLayer(128, 'Name', 'audioFC')
dropoutLayer(0.5, 'Name', 'audioDropout')
featureExtractionLayer('Name', 'audioFeatures')
];
end
% 视觉网络
if strcmpi(params.visualFeatureType, 'CNN')
% 创建处理视觉特征的网络
visualLayers = [
imageInputLayer([224 224 3], 'Normalization', 'none', 'Name', 'visualInput')
% 使用预训练的ResNet-18
resnet18('Weights', 'none')
% 移除最后几层,添加自定义层
fullyConnectedLayer(512, 'Name', 'visualFC1')
reluLayer('Name', 'visualRelu1')
dropoutLayer(0.5, 'Name', 'visualDropout1')
fullyConnectedLayer(256, 'Name', 'visualFC2')
dropoutLayer(0.5, 'Name', 'visualDropout2')
featureExtractionLayer('Name', 'visualFeatures')
];
end
% 融合网络
if strcmpi(params.fusionType, 'attention')
% 注意力融合网络
fusionLayers = [
featureInputLayer(128, 'Name', 'audioInput')
featureInputLayer(256, 'Name', 'visualInput')
% 音频注意力
fullyConnectedLayer(64, 'Name', 'audioAttFC1')
reluLayer('Name', 'audioAttRelu')
fullyConnectedLayer(1, 'Name', 'audioAttFC2')
% 视觉注意力
fullyConnectedLayer(64, 'Name', 'visualAttFC1')
reluLayer('Name', 'visualAttRelu')
fullyConnectedLayer(1, 'Name', 'visualAttFC2')
% 计算注意力权重
concatLayer(2, 'Name', 'attentionConcat')
softmaxLayer('Name', 'attentionSoftmax')
% 注意力加权融合
elementwiseProductLayer(2, 'Name', 'audioWeighted')
elementwiseProductLayer(2, 'Name', 'visualWeighted')
additionLayer(2, 'Name', 'fusionAdd')
fullyConnectedLayer(256, 'Name', 'fusionFC1')
batchNormalizationLayer('Name', 'fusionBN')
reluLayer('Name', 'fusionRelu')
dropoutLayer(0.5, 'Name', 'fusionDropout')
fullyConnectedLayer(params.numClasses, 'Name', 'fusionOutput')
softmaxLayer('Name', 'softmax')
classificationLayer('Name', 'classoutput')
];
elseif strcmpi(params.fusionType, 'late')
% 后期融合网络(决策级融合)
fusionLayers = [
featureInputLayer(128, 'Name', 'audioInput')
featureInputLayer(256, 'Name', 'visualInput')
% 音频分类分支
fullyConnectedLayer(params.numClasses, 'Name', 'audioClassFC')
softmaxLayer('Name', 'audioSoftmax')
% 视觉分类分支
fullyConnectedLayer(params.numClasses, 'Name', 'visualClassFC')
softmaxLayer('Name', 'visualSoftmax')
% 权重融合
fullyConnectedLayer(params.numClasses, 'Name', 'fusionWeights')
softmaxLayer('Name', 'fusionSoftmax')
% 加权组合
weightedSumLayer(3, 'Name', 'finalOutput')
classificationLayer('Name', 'classoutput')
];
end
% 创建网络
audioNet = layerGraph(audioLayers);
visualNet = layerGraph(visualLayers);
fusionNet = layerGraph(fusionLayers);
end 测试模型如下:
function [accuracy, confusionMat, classReport] = testAVEmotionModel(trainedModel, audioFeatures, visualFeatures, labels, testIdx)
% 测试视听情感融合模型
% 准备测试数据
audioTest = audioFeatures(testIdx, :, :);
visualTest = visualFeatures(testIdx, :);
labelsTest = labels(testIdx, :);
% 转换为表格形式
testTable = table(audioTest', visualTest', labelsTest', ...
'VariableNames', {'audio', 'visual', 'labels'});
% 预测
predictedLabels = classify(trainedModel, testTable);
% 计算准确率
accuracy = mean(predictedLabels == labelsTest);
% 计算混淆矩阵
confusionMat = confusionmat(labelsTest, predictedLabels);
% 生成分类报告
classReport = generateClassificationReport(labelsTest, predictedLabels);
end
function report = generateClassificationReport(actualLabels, predictedLabels)
% 生成分类报告,包括精确率、召回率和F1分数
% 获取类别
classes = unique([actualLabels; predictedLabels]);
numClasses = length(classes);
% 初始化报告
report = struct('Class', {}, 'Precision', {}, 'Recall', {}, 'F1Score', {}, 'Support', {});
% 计算每个类别的指标
for i = 1:numClasses
class = classes(i);
% 真正例(TP)
TP = sum(actualLabels == class & predictedLabels == class);
% 假正例(FP)
FP = sum(actualLabels ~= class & predictedLabels == class);
% 假负例(FN)
FN = sum(actualLabels == class & predictedLabels ~= class);
% 支持度(Support)
support = sum(actualLabels == class);
% 计算精确率
precision = TP / (TP + FP);
if isnan(precision)
precision = 0;
end
% 计算召回率
recall = TP / (TP + FN);
if isnan(recall)
recall = 0;
end
% 计算F1分数
f1 = 2 * (precision * recall) / (precision + recall);
if isnan(f1)
f1 = 0;
end
% 添加到报告
report(i).Class = class;
report(i).Precision = precision;
report(i).Recall = recall;
report(i).F1Score = f1;
report(i).Support = support;
end
% 计算宏平均和加权平均
macroPrecision = mean([report.Precision]);
macroRecall = mean([report.Recall]);
macroF1 = mean([report.F1Score]);
totalSupport = sum([report.Support]);
weightedPrecision = sum([report.Precision] .* [report.Support]) / totalSupport;
weightedRecall = sum([report.Recall] .* [report.Support]) / totalSupport;
weightedF1 = sum([report.F1Score] .* [report.Support]) / totalSupport;
% 添加平均值到报告
report(numClasses+1).Class = 'Macro Average';
report(numClasses+1).Precision = macroPrecision;
report(numClasses+1).Recall = macroRecall;
report(numClasses+1).F1Score = macroF1;
report(numClasses+1).Support = totalSupport;
report(numClasses+2).Class = 'Weighted Average';
report(numClasses+2).Precision = weightedPrecision;
report(numClasses+2).Recall = weightedRecall;
report(numClasses+2).F1Score = weightedF1;
report(numClasses+2).Support = totalSupport;
end 
脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 19
19 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)