【论文解读】SkyRL-v0: 通过强化学习训练真实世界长时序智能体
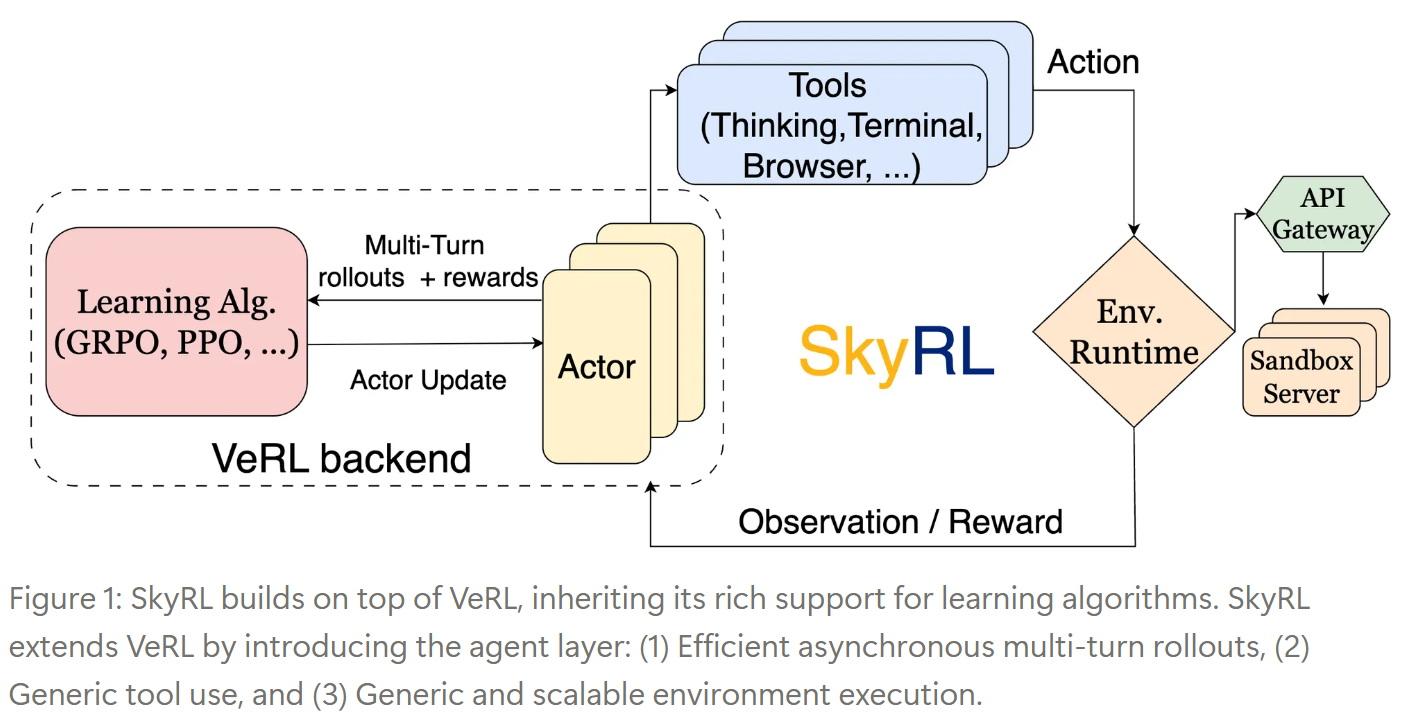
SkyRL-v0 是一个非常务实且有价值的工作。它没有把重点放在提出全新的强化学习算法上,而是通过引入**远程沙箱服务器**来解决环境扩展性问题,并通过**异步 Rollouts 和精巧的三阶段生产者-消费者流水线**来大幅提升 Rollout 效率,SkyRL 为在诸如 SWE-Bench 这样的“硬核”真实世界基准上训练 LLM 智能体铺平了道路。其核心贡献在于提供了一个**高效、可扩展的 R
core contributor
paper: SkyRL-v0: Train Real-World Long-Horizon Agents via Reinforcement Learning | Notion
code: NovaSky-AI/SkyRL: SkyRL-v0: Train Real-World Long-Horizon Agents via Reinforcement Learning
5. 总结 (结果先行)
SkyRL-v0 是一个非常务实且有价值的工作。它没有把重点放在提出全新的强化学习算法上,而是认识到将现有 LLM 智能体应用于真实、复杂、长时序任务时,系统层面的瓶颈才是阻碍 RL 发挥作用的关键。
通过引入远程沙箱服务器来解决环境扩展性问题,并通过异步 Rollouts 和精巧的三阶段生产者-消费者流水线来大幅提升 Rollout 效率,SkyRL 为在诸如 SWE-Bench 这样的“硬核”真实世界基准上训练 LLM 智能体铺平了道路。其核心贡献在于提供了一个高效、可扩展的 RL 训练基础设施。
实验结果清晰地表明,借助 SkyRL 搭建的桥梁,即使是相对简单的 RL 方法(基于结果的奖励 + GRPO 等),也能够让 LLM 智能体在解决复杂软件工程问题上取得切实的进步,超越了单纯的监督微调或零样本提示。
展望未来,SkyRL 的工作为更深入的研究奠定了基础:
- 更复杂的任务: 将 SkyRL 的理念扩展到 WebArena、WebDev 等其他类型的长时序、多工具交互任务中。
- 更精细的奖励设计: 在当前 outcome-based 奖励的基础上,探索更稠密、更能反映中间步骤质量的奖励函数,可能会进一步加速学习过程和提升最终性能。
1. 思想
当前,将大型语言模型 (LLM) 发展为能够主动执行任务的智能体 (Agent) 已成为一个重要研究方向。
-
大问题:
- 多数现有的 RL 框架主要针对无状态、短时序的交互任务进行优化,例如简单的搜索增强推理或代码执行片段。
- 如何让 LLM 智能体在需要长时序规划和复杂环境交互的真实世界任务(如软件开发)中有效工作并通过强化学习持续改进?
-
小问题:
- 如何高效地支持 LLM 智能体与环境进行多轮异步交互并收集训练数据 (rollouts)?
- 如何让智能体能够泛化地使用多种工具 (generic tool use)?
- 如何实现可扩展的环境执行 (scalable environment execution) 以应对复杂任务需求?
- 需要哪些鲁棒的长时序强化学习算法来有效训练这类智能体?(作者仅列出, 没有讨论)
-
核心思想:
- 构建于现有坚实基础之上: 建立在现有框架之上。SkyRL 的创新在于引入了“智能体层 (agent layer)”,专门处理与真实环境的高效交互。
- VeRL 提供了丰富的学习算法支持
- OpenHands 可能贡献了与环境交互或智能体相关的能力。
- 环境执行与训练分离 (Remote Sandbox Server): 为了解决环境扩展性问题,SkyRL 将环境的执行过程与模型的训练过程解耦。通过一个远程沙箱服务器 (Remote Sandbox Server) 来管理和运行大量的环境实例 (Docker 容器),训练器通过 API 与之交互。这使得环境可以独立于训练节点进行扩展,从而满足 LLM 推理引擎对请求速率的要求,避免 GPU 闲置。
- Rollout 过程异步化与流水线化 (Accelerated Rollout Generation): 这是 SkyRL 提高训练效率的关键设计。
- 异步 Rollouts: 利用现代 LLM 服务引擎 (如 SGLang, vLLM) 的
async_generate方法,允许每个智能体的交互轨迹 (trajectory) 独立异步地进行,避免了传统 RL 中常见的全局同步点。 - 三阶段生产者-消费者流水线 (Three-stage Producer-Consumer Pipelining): 进一步将 Rollout 过程细分为三个可以重叠执行的阶段:
- (i) 运行时初始化 (如构建镜像、启动容器)
- (ii) 轨迹生成 (智能体与环境的多轮交互)
- (iii) 奖励计算 (如运行测试用例)。这三个阶段通过队列 (
init_queue,run_queue,eval_queue) 连接,形成流水线,最大化并行度,从而显著提升数据收集的吞吐量 (论文宣称 4-5 倍加速)
- 异步 Rollouts: 利用现代 LLM 服务引擎 (如 SGLang, vLLM) 的
- 构建于现有坚实基础之上: 建立在现有框架之上。SkyRL 的创新在于引入了“智能体层 (agent layer)”,专门处理与真实环境的高效交互。
2. 方法
SkyRL-v0 的方法主要集中在系统设计层面,以支持长时序智能体的强化学习训练。
2.1 系统设计:应对环境扩展性
-
问题: 在 SWE-Bench 这类任务中,每个 rollout (智能体完成一次任务尝试的过程) 都需要在隔离且有状态的环境 (通常是 Docker 容器) 中运行。这些环境资源消耗大 (1+ CPU, ~7GB 存储/每个),当并行 rollout 数量增多时 (例如,batch size 16,每个 instance 跑 8 个 rollout,就需要 128 个环境实例),对计算和存储资源的需求会急剧膨胀。如果环境执行与训练过程耦合在一起,会导致 GPU 利用率低下。
-
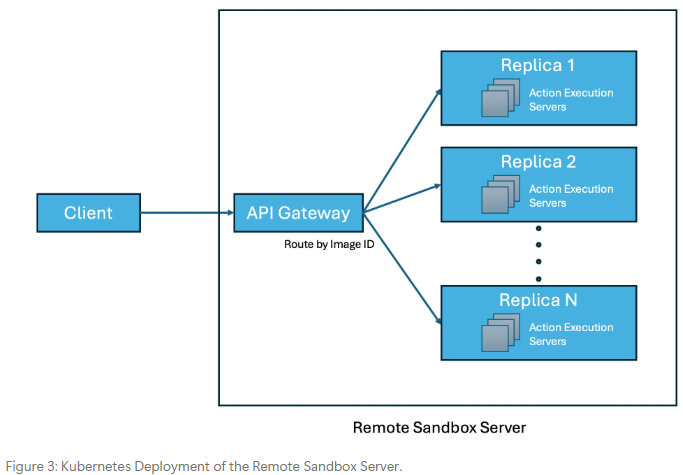
解决方案: 远程沙箱服务器 (Remote Sandbox Server)。
- 核心: 将环境执行从训练节点中分离出来。
- 实现:
- 客户端 (训练器) 将环境执行请求发送到 API 网关。
- API 网关根据镜像 ID 等信息将请求路由到合适的后端 Replica (一组 Action Execution Servers)。
- 每个 Replica 内部署了多个 Action Execution Server,它们负责实际运行 Docker 容器。
- 该服务器部署在 Kubernetes 上,利用存储优化实例缓存容器镜像以加速启动。
- 使用
aidocker和crun容器运行时,以支持轻量级、高性能的容器执行 (据称可在 16-CPU 节点上稳定运行 80-100 个容器)。
- 效果: 实现了环境执行能力的独立扩展,确保了对 LLM 推理引擎有足够的请求压力,从而提高 GPU 在 rollout 阶段的利用率。
2.2 系统设计:应对 Rollout 效率低下
-
问题: 传统的单轮 RL 的 rollout 实现 (如 VeRL 和 OpenRLHF 中的) 在智能体式推理 (agentic-style inference) 这种多轮、每轮耗时不均的场景下效率低下。主要原因是每轮 LLM 生成后的同步障碍,以及对离线批量生成 (offline batch generation) 的依赖,无法充分利用现代 LLM 服务引擎的连续批处理 (continuous batching) 等优化。
-
解决方案:
-
异步 Rollouts (Asynchronous Rollouts):
- 依赖现代 LLM 服务引擎 (如 SGLang, vLLM) 提供的
async_generate方法。 - 使得每个环境中的智能体轨迹可以独立、异步地向前推进,避免了全局同步点。
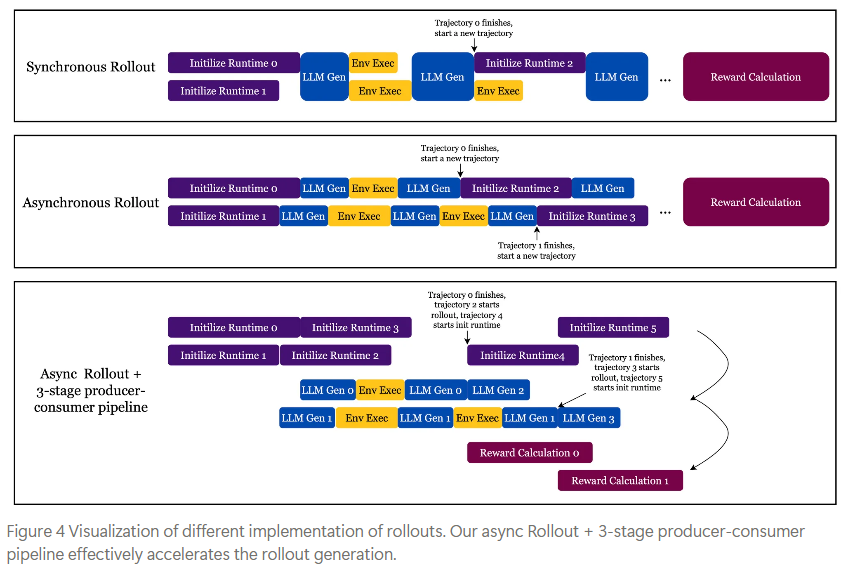
- 如图 4 中部所示,不同 trajectory 的 LLM Gen 和 Env Exec 可以交错进行。
- 依赖现代 LLM 服务引擎 (如 SGLang, vLLM) 提供的
-
三阶段生产者-消费者流水线 (Three-stage Producer-Consumer Pipelining):
- 目标: 进一步减少 GPU 空闲时间,通过解耦和重叠 Rollout 的不同阶段来最大化并行度和系统吞吐量。
- 阶段划分:
- (i) 运行时初始化 (Runtime Initialization): 例如,构建 Docker 镜像、启动和连接容器。此阶段由 Initializer 处理。
- (ii) 轨迹生成 (Trajectory Generation): 智能体与环境进行多轮交互,生成完整的 rollout。此阶段由 Agent Runner 处理。
- (iii) 奖励计算 (Reward Calculation): 例如,发送代码补丁、运行测试用例、评估结果。此阶段由 Evaluator 处理。
- 队列协调:
- Initializer 从
init_queue(初始任务队列) 中拉取任务,准备好环境后,将实例推送到run_queue(待运行轨迹队列)。 - Agent Runner 从
run_queue中拉取已初始化的实例,执行多轮交互生成完整轨迹后,推送到eval_queue(待评估轨迹队列)。 - Evaluator 从
eval_queue中拉取完成的轨迹,计算最终奖励。
- Initializer 从
- 实现细节: 使用
asyncio任务,并根据队列占用情况和剩余工作动态生成任务。有界队列 (bounded queues) 提供了自然的反向压力 (back-pressure),防止系统过载,并有助于在各阶段间实现负载均衡。 - 如图 4 底部所示,初始化、LLM 生成/环境执行、奖励计算在不同轨迹间高度并行和重叠。
-
2.3 框架流程
- Rollout 生成 (Rollout Generation):
- 框架: 采用 OpenHands 的代码脚手架 (scaffold) 和 CodeAct 框架。
- 交互过程: 模型根据当前任务环境进行迭代式提示。在每一轮,模型生成代码和函数调用作为其动作 (action)。
- 可用动作 (Actions):
execute_bash: 在终端执行 bash 命令。finish: 当任务完成或智能体无法继续时,结束交互。str_replace_editor: 一个自定义的编辑工具,用于查看、创建和编辑文件。
- 伪代码流程:
其中:Input: Model M, Environment E, Task description P, Set of available actions A # OpenHands 管理交互历史 history,用任务描述 P 初始化 history = P while not done: # CodeAct 框架用 history 和可用工具 A 来提示模型 M action = M(history, A) # M: 模型, A: 可用动作集合 # action 被发送到环境 E 执行,并获取环境观察 observation # 例如,view_file(file_path) 动作执行后,observation 可能是文件内容 done, observation = E(action) # E: 环境 (例如 SWE-Bench 的一个实例) # OpenHands 追踪历史,追加本轮的 action 和 observation history.append(action) history.append(observation) # 返回模型在交互历史中生成的 git patch patch = E.get_patch() return patchhistory: 代表到目前为止的整个交互历史,包括过去的动作和观察。action: 模型生成的具体操作。observation: 环境执行动作后返回的结果。done: 一个布尔值,指示任务是否结束。patch: 最终由模型行为产生的代码修改。
3. 优势
- 针对长时序真实环境的优化: SkyRL 明确地为如 SWE-Bench 这类需要在有状态、动态环境中进行长时序规划和多轮工具交互的任务设计,填补了现有 RL 框架的空白。
- 高效的 Rollout 生成: 通过异步 Rollouts 和三阶段生产者-消费者流水线,实现了 4-5 倍的 Rollout 生成速度提升 (相比基线实现),显著提高了训练效率。
- 可扩展的环境执行: 远程沙箱服务器的设计允许环境执行与训练过程解耦,使得环境资源可以独立扩展,从而保障了对 LLM 推理引擎的持续请求,提高了 GPU 利用率。
- 模块化和可重用性: 构建在 VeRL 和 OpenHands 之上,可以利用这些框架已有的 RL 算法和智能体交互能力。
- 开源贡献: 提供了系统代码和部署配置,方便其他研究者复现和自托管可扩展的远程沙箱环境。
4. 实验
-
评估设置:
- 智能体: 使用 OpenHands scaffold 和 CodeAct Agent,动作集包括
bash_execute,finish,str_replace_editor。 - 基准: SWE-Bench Verified。
- 评估参数: 最大交互轮次 (turn budget) 50,最大序列长度 32k。
- 温度: 评估时使用温度 0 (如 SWE-Gym 论文建议)。
- 智能体: 使用 OpenHands scaffold 和 CodeAct Agent,动作集包括
-
奖励设计:
- 采用简单的基于最终结果的奖励 (outcome-based reward)。
- 智能体完成交互后,从环境中获取
git patch。 - 将此
patch应用到原始代码库,并针对目标 GitHub Issue 运行测试套件。 - 如果测试通过且问题得到解决,奖励 R = 1 R=1 R=1;否则, R = 0 R=0 R=0。
- 尽管简单,该信号有效地引导模型提高了问题解决率。
- 同时追踪两种常见的失败模式:
- 卡在循环 (Stuck in a loop): 模型连续三次重复相同的动作。
- 没有结束动作 (No finish action): 模型在分配的回合数预算内未能输出
finish动作。
- 实验表明,这种奖励机制有助于减少循环并鼓励及时完成任务。未来将探索更丰富的奖励设计。
-
数据选择:
- 问题源自 SWE-Gym (包含 2438 个真实 Python 任务实例)。
- 这些任务极具挑战性 (即便是 GPT-4o 成功率也不高)。弱模型 (如 7B 级别) 可能无法完成任何成功的 rollout,导致学习信号缺失和训练崩溃。
- 为了缓解此问题,构建了三个经过筛选的数据子集,筛选标准是基于不同强度的模型能否成功生成至少一个 rollout:
SkyRL-v0-80-data(80 instances): SWE-Gym/OpenHands-7B-Agent 模型能在 16 次尝试中至少成功一次。SkyRL-v0-220-data(220 instances): SWE-Gym/OpenHands-32B-Agent 模型能在 16 次尝试中至少成功一次。SkyRL-v0-293-data(293 instances): gpt-4o-2024-08-06 或 claude-3-5-sonnet-20241022 能正确解答 (由 SWE-Gym 提供)。
-
开源模型: 发布了三个不同大小、不同训练算法训练的模型:
- SkyRL-Agent-7B-v0:
- 基础模型: OpenHands-7B-Agent (本身是 Qwen2.5-Coder-7B-Instruct 的 SFT 版本)。
- 训练: 两阶段 outcome-based RL (GRPO 算法),batch size 16,每个 instance 8 rollouts,学习率 1 × 10 − 6 1 \times 10^{-6} 1×10−6,KL 系数 1 × 10 − 3 1 \times 10^{-3} 1×10−3,rollout 温度 0.5,最大轮次 25。
- 数据: SkyRL-v0-80-data (15 steps, 3 epochs, 7h on 8xH100 GPUs) + SkyRL-v0-220-data (15 steps, 1 epoch, 8.5h on 8xH100 GPUs)。
- 结果:
- Qwen2.5-Coder-Instruct (Zero-Shot): 1.8%
- OpenHands-7B-Agent (Supervised Fine-tuning): 11.0%
- SkyRL-Agent-7B-v0 (Outcome based RL): 14.6% (提升 3.6% 绝对值)
- SkyRL-Agent-8B-v0 (Non-Thinking Mode):
- 基础模型: Qwen3-8B (非思考模式,通过在
apply_chat_template中设置enable_thinking=False)。 - 训练: 一阶段 outcome-based RL,batch size 32,每个 instance 8 rollouts,学习率 1 × 10 − 6 1 \times 10^{-6} 1×10−6,KL 系数 1 × 10 − 3 1 \times 10^{-3} 1×10−3,rollout 温度 0.6。
- 数据: SWEGym-293-data (47 steps, 4.7 epochs, 27h on 8xH200)。
- 结果:
- Qwen3-8B (Zero-Shot, Non thinking): 3.6%
- SkyRL-Agent-8B-v0 (Outcome based RL): 9.4% (提升 5.8% 绝对值)
- 基础模型: Qwen3-8B (非思考模式,通过在
- SkyRL-Agent-14B-v0 (Thinking Mode):
- 基础模型: Qwen3-14B (思考模式)。
- 结果:
- Qwen3-14B (thinking-enabled, 可能是 Zero-Shot 或 SFT baseline): 18.0%
- SkyRL-Agent-14B-v0 (Outcome based RL): 21.6% (提升 3.6% 绝对值)
- SkyRL-Agent-7B-v0:
-
实验结论:
- RL 训练有效性: SkyRL 展示了即使使用简单的基于结果的奖励,通过其高效的训练 pipeline 进行强化学习,也能在不同大小的模型和不同基线上持续提升 LLM 智能体在复杂软件工程任务上的表现。
- 系统的重要性: 高效的系统设计 (异步化、流水线化、远程沙箱) 是实现这种提升的关键,因为它使得在资源密集型和长时序任务上进行 RL 训练成为可能。
- 数据选择策略: 对于非常困难的任务,通过逐步使用由更强模型筛选出的“可解”数据子集进行课程学习式的训练,可能是一种有效的策略。
- 行为改善: 奖励设计 (包括对不良行为的隐式惩罚) 有助于引导模型学习更有效的行为模式。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 23
23 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)