【课程笔记】华为 HCIP-AI Solution Architect 人工智能06:并行训练框架MindFormers介绍
目录并行训练框架MindFormers介绍一、MindFormers设计概览二、MindFormers特性介绍三、MindFormers最佳实践1. 预训练2. 微调3. 推理4. 案例(1) 并行注意事项数据并行Data parallel①原理:将计算设备设置为N个计算节点,每个节点(GPU集群)都保存一份完整的模型参数。同时将数据分为N份,每个节点负责处理1份数据。在前向处理完成后,每个节点单
并行训练框架MindFormers介绍
目录
一、MindFormers设计概览
(1) 大模型使能套件:全流程覆盖大模型开发、训练、微调、推理
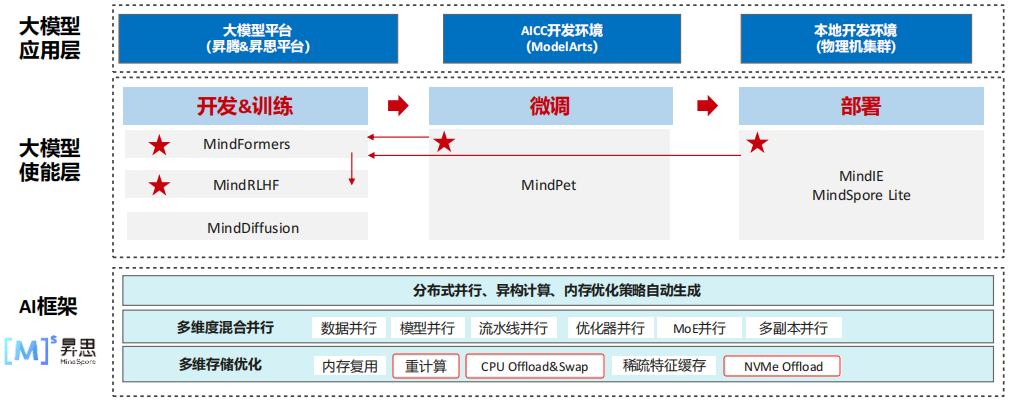
(2) 为什么使用MindFormers
①大模型开发
(1)集成业界主流SOTA大模型结构,提供模块化、配置化开发方式
(2)提供各类高阶API模块,使能用户自定义灵活开发
(3)提供Profile性能分析、MindInsight可视化调优能力,使能大模型调试调优
②大模型训练
(1)提供各领域大模型预训练任务流,训练流程及接口统一化
(2)提供昇思MindSpore多维并行和内存优化配置化开发接口,使能大模型高效并行训练
(3)提供线下物理机集群和人工智能计算中心(AICC)集群训练能力,使能大模型高效稳定训练
③下游任务
(1)提供各领域下游任务微调、评估、推理任务流,使能大模型效果快速验证和推理体验
(2)提供huggingface权重转换(NPU)能力,使能第三方大模型生态无缝衔接
(3)提供各领域预训练及下游任务权重自动加载能力,使能大模型下游任务评测复现
总结
华为开发的一款大模型并行训练、推理、部署的一体式框架
可以应用到GPU、CPU、NPU设备够可以兼容使用。推荐NPU使用,有更好的适配性,可以帮助华为昇腾NPU算力进行加速
框架设计优势
并行策略:
①模型并行(张量并行)、数据并行、流水线并行
②优化器并行:不同阶段的优化器参数存储在不同节点中,在进行参数更新时,再进行通信处理
③MOE并行:Mixture of Expect混合专家。一般是在千亿级以上大模型中常见的架构形式
-
显卡内存优化:
①重计算:激活函数的数值,使用完成后,就从显存中删除,再使用时,再重新进行计算
②offload同DeepSpeed相同
模型训练、微调中,常见的两种编程方式
Trainer组件进行处理:Trainer (填写参数信息).....
pipeline组件进行处理:pipline (参数信息) 无需调用
二、MindFormers特性介绍
(1) 并行注意事项
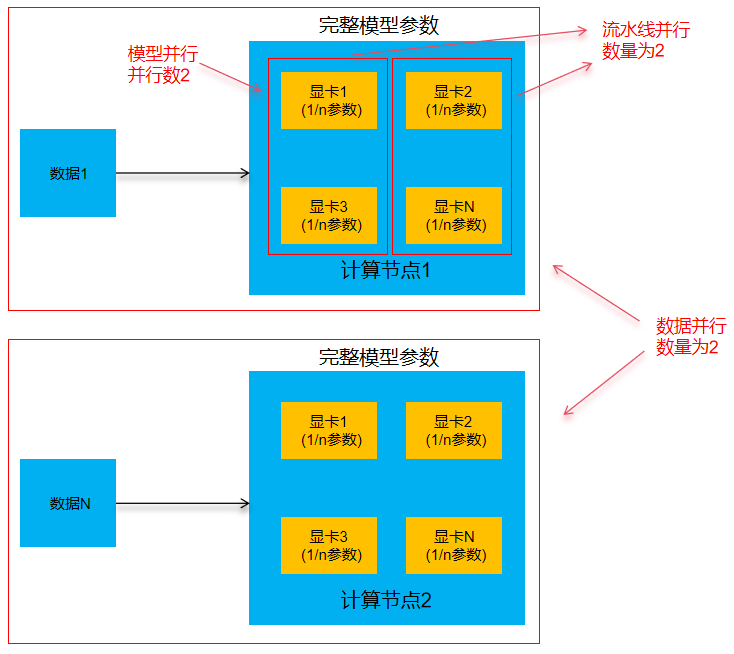
数据并行Data parallel
①原理:将计算设备设置为N个计算节点,每个节点(GPU集群)都保存一份完整的模型参数。同时将数据分为N份,每个节点负责处理1份数据。在前向处理完成后,每个节点单独计算梯度数据。然后使用通信处理,求出梯度平均值,分发给每个节点,进行梯度更新
②使用场景:在计算设备充足的情况下,加速模型的训练时间
③应用的注意事项:每个节点中的数据都是独立的,不包含数据
模型并行(张量并行)Model parallel
①原理:将张量进行拆分,分别放置在不同的芯片中进行计算,然后再将计算结果进行整合,最终得到目标张量结果
②使用场景:模型参数过多,单张AI芯片无法存储当前参数的时候
③应用的注意事项:模型隐藏层中神经元数量与模型并行数能够取余
流水线并行(张量并行)Pipeline parallel
①原理:将模型拆分成多个部分,每个部分使用流水线的方式,依次进行计算
②使用场景:模型参数过多,单张AI芯片无法存储当前参数的时候
③应用的注意事项:模型拆分的数量>=流水线并行的数量
注意:所需AI芯片的数量 = 数据并行数 * 张量并行数 * 流水线并行数
(2) 低参微调
MindPet(Pet:Parameter-Efficient Tuning)是属于MindSpore领域的微调算法套件。目前低参微调针对MindFormers仓库已有的大模型进行统一架构设计,对于LLM类语言模型,我们可以统一调度修改,做到只需要调用接口或者是自定义相关配置文件,即可完成对LLM类模型的低参微调算法的适配
三、MindFormers最佳实践
1. 预训练
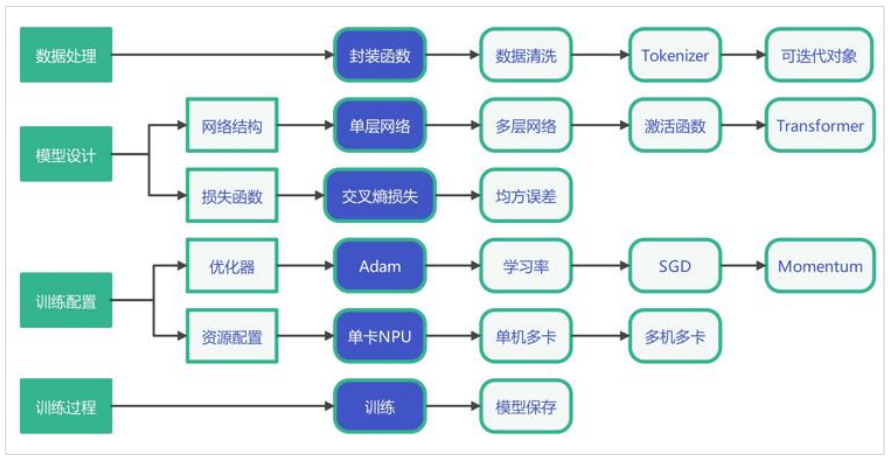
(1) LLM预训练
基本流程:
(2) 数据加载
迭代器,模型可接收对象:
方式一:将数据转成MindRecord数据类型(推荐)
方式二:调用DataLoader完成原生数据向模型可接收数据的转化,如GLM模型AdGen数据集的DataLoader(支持度不高)
方式三:在线数据处理,完成已处理好的文本向模型可接收数据的转化(仅支持Tokenizer处理)
2. 微调
(1) MindPet
MindPet(Pet:Parameter-Efficient Tuning)是属于MindSpore领域的微调算法套件。专注于低参数微调算法的开发,对外提供低参微调算法接口,使能开发者修改自己开发的模型进行低参微调
目前MindPet已提供以下6中低参数微调算法API接口,用户可快速适配原始大模型,提升下游任务微调性能和精度:LoRA,Prefix Tuning,Adapter,LowRankAdapter,BifFit,R_Drop
3. 推理
(1) 增量推理
增量推理基础概念:
①自回归生成过程中,存在重复计算项
②可复用以往的计算结果以节省时间
具体实现:
①在模型各layer中新增parameter,用于记录计算结果
②首次前向,全量推理,记录状态
③后续每次前向仅输入新生成的token,其余状态复用
4. 案例

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 21
21 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)