基于对抗生成网络的短时长SSVEP数据拓展算法
摘要:本文提出了一种基于生成对抗网络的TEGAN算法,用于解决短时长SSVEP信号在脑机接口应用中的数据不足问题。与传统方法仅增加数据数量不同,TEGAN创新性地通过U-Net生成器架构和辅助分类器,实现了信号从短时长到长时长的转换。该模型采用两阶段训练策略和正则化技术,显著提升了多种频率识别方法在有限校准数据下的性能,并缩小了不同方法间的分类差距。实验结果表明,TEGAN能有效缓解短数据导致的特
基于对抗生成网络的短时长SSVEP数据拓展算法
导读
在脑机接口(BCI)技术的研究与应用中,稳态视觉诱发电位(SSVEP)信号因具有高信噪比和易于检测的特点,成为实现人机交互的重要数据基础。然而,实际应用中短时间窗内采集的 SSVEP 信号数据量有限,制约了传统频率识别方法和深度学习模型的性能。为突破这一瓶颈,张杨松教授团队联合电子科技大学尧德中教授团队提出了一种基于生成对抗网络的端到端信号变换网络 ——TEGAN(Time-Extension Generative Adversarial Network)。该网络通过创新性地融合 U 型网络生成器架构与辅助分类器,结合两阶段训练策略及勒卡姆散度正则化项,能够将短长度的 SSVEP 信号转换为长时人工信号。在公开数据集上的实验结果表明,TEGAN 不仅显著提升了多种频率识别方法在有限校准数据下的性能,还缩小了不同方法间的分类差距,充分验证了其在扩展数据长度方面的可行性。这一成果为高性能 BCI 系统的开发提供了新方向,同时也展现出基于生成对抗网络的技术在缩短校准时间、降低 BCI 实际应用成本上的巨大潜力。TEGAN的研究相关成果发表在Cognitive Neurodynamics上,目前引用量已接近20次。
代码链接: https://github.com/YuDongPan/TEGAN
1. 研究背景
要理解 TEGAN 的价值,需先明确 SSVEP-BCI 技术的核心优势与现实痛点,以及现有解决方案的局限。
1.1 SSVEP-BCI 的核心优势与应用潜力
稳态视觉诱发电位(SSVEP)是大脑枕叶区域对特定频率闪烁 / 反转的视觉刺激产生的周期性脑电信号,其频率与刺激频率一致(含基频及谐波)。基于 SSVEP 的 BCI 系统之所以成为研究热点,核心原因在于两点:
- 高信息传输率(ITR):相比运动想象(Motor Imagery, MI)、P300 等范式,SSVEP 能支持更快的人机交互(如高速拼写器、无人机控制);
- 多目标支持:可同时设计多个不同频率的刺激目标,满足复杂场景需求(如智能家居多设备控制)。
目前,SSVEP-BCI 已应用于仿生机械腿1、无人飞行器2、智能拨号界面3等场景,但这些应用的落地始终受限于数据采集环节,包括但不限于SSVEP信号解码算法对校准数据的需求量,数据分析时长等方面。
1.2 核心痛点:数据长度与校准成本的制约
SSVEP 频率识别的性能高度依赖数据长度和用户校准数据量:
- 数据长度不足:短时长信号(如 0.5-1s)的时域 / 频域特征不明显,易受自发脑电(EEG)噪声干扰,导致传统方法(如 CCA4、TRCA5)准确率骤降;
- 校准成本过高:现有高性能方法(如 ITCCA6、TRCA5、EEGNet7)需要大量用户专属训练数据(即 “校准数据”),而采集过程耗时费力(通常需 30 分钟以上),还可能引发用户疲劳,进一步降低信号质量。
1.3 现有技术的局限:“扩数量” 而非 “扩长度”
为解决数据短缺问题,研究界已尝试两类方案,但均存在明显不足:
(1)传统与深度学习方法的瓶颈
- 传统方法:如 CCA (Canonical Correlation Analysis)4、TRCA (Task-Related Component Analysis (TRCA)5,虽无需训练或训练量小,但短数据下抗干扰能力差;个体模板 CCA(Individual Templete CCA)虽引入用户数据,但仍依赖足够校准样本。
- 深度学习方法:如 EEGNet(Compact-CNN)7、C-CNN(Complex CNN)8,能提取如导联组合模式特征、时域局部特征或频域局部通用特征以减少校准依赖,但短时长信号的特征稀缺性仍会导致模型欠拟合,性能难以突破。
(2)现有 GAN 方法的局限
- 近年来,生成对抗网络(GAN)被用于合成 EEG 数据以扩大训练集(如 EEG-GAN9、SIS-GAN10),但这些方法仅能增加数据数量,无法解决 “数据长度不足” 的核心问题。而多项研究通过大量实验验证:相同条件下,更长的 SSVEP 信号能带来更显著的准确率提升(如 1.0s 信号比 0.5s 信号准确率高 20%+)。
- 因此,TEGAN 的核心创新在于:
首次通过 GAN 实现 SSVEP 信号 “长度扩展”,而非仅扩展数据数量,从根本上缓解短数据的特征稀缺问题。
2. TEGAN模型架构
TEGAN 的设计围绕 “稳定生成高质量长时 SSVEP 信号” 展开,整体分为三大模块:生成器(负责 “短→长” 信号转换)、判别器(负责 “真伪 + 类别” 双任务判别),以及针对 GAN 训练不稳定性的正则化策略。其核心逻辑是通过生成器与判别器的 “零和博弈”,学习短信号到长信号的精准映射。
2.1 整体框架:端到端信号转换流程
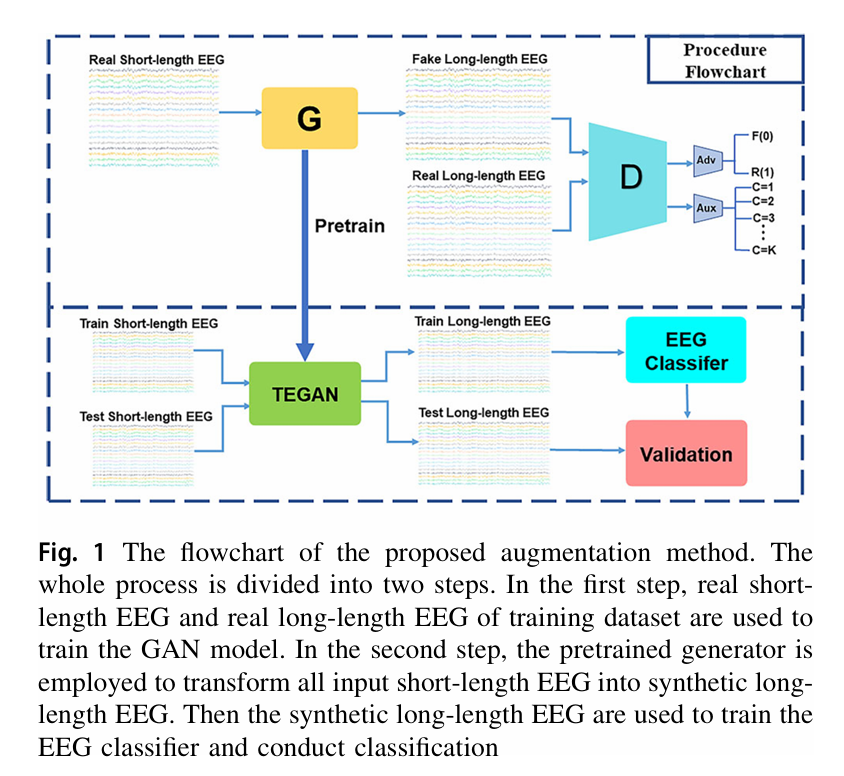
TEGAN 的工作流程分为两步,本质是 “先训模型、再转信号”:
- 模型训练阶段:基于辅助分类器 GAN(ACGAN)范式,让生成器(G)和判别器(D)对抗训练 ——
生成器输入短时长 SSVEP 信号,输出长时长人工信号;判别器则需同时区分 “信号是真实长信号还是生成的长信号”,并识别信号对应的刺激类别;
L S = E x ∼ p x l [ log ( D ( x ) ) ] + E x ∼ p x s [ log ( 1 − D ( G ( x ) ) ) ] (1) L_S = \underset{x \sim p_{xl}}{\mathbb{E}} \left[ \log(D(x)) \right] + \underset{x \sim p_{xs}}{\mathbb{E}} \left[ \log(1 - D(G(x))) \right] \tag{1} LS=x∼pxlE[log(D(x))]+x∼pxsE[log(1−D(G(x)))](1)
L C = E x ∼ p x l [ log ( D ( x ∈ C ) ) ] + E x ∼ p x s [ log ( D ( G ( x ) ∈ C ) ) ] (2) L_C = \underset{x \sim p_{xl}}{\mathbb{E}} \left[ \log(D(x \in C)) \right] + \underset{x \sim p_{xs}}{\mathbb{E}} \left[ \log(D(G(x) \in C)) \right] \tag{2} LC=x∼pxlE[log(D(x∈C))]+x∼pxsE[log(D(G(x)∈C))](2)
其中, p x s p_{xs} pxs 和 p x l p_{xl} pxl 分别是训练数据中短时长脑电(EEG)数据和长时长脑电(EEG)数据的分布。符号 D ( x ∈ C ) D(x∈C) D(x∈C) 表示类别标签被正确识别的概率。令 V ( G ) V(G) V(G)和 V ( D ) V(D) V(D) 分别表示生成器
G G G和判别器 D D D的训练目标,则 TEGAN 的训练可大致表示为:
min G V G = L S − L C (3) \min_G V_G = L_S - L_C \tag{3} GminVG=LS−LC(3)
max D V D = L S + L C (4) \max_D V_D = L_S + L_C \tag{4} DmaxVD=LS+LC(4)
- 信号转换阶段:用训练好的生成器,将所有短时长 SSVEP 信号(包括训练集和测试集)转换为长时长信号,再用转换后的信号训练分类器并完成识别。
ζ ( x s ) = G ( x s ∣ θ = θ G ∗ ) = x l (5) \zeta(x_s) = G(x_s|\theta = \theta_G^*) = x_l \tag{5} ζ(xs)=G(xs∣θ=θG∗)=xl(5)
- 为加速训练收敛,团队还采用了 “hinge 损失” 计算判别器损失,避免传统损失函数在训练后期梯度消失的问题。
2.2 生成器:基于 U-Net 的 “短→长” 映射
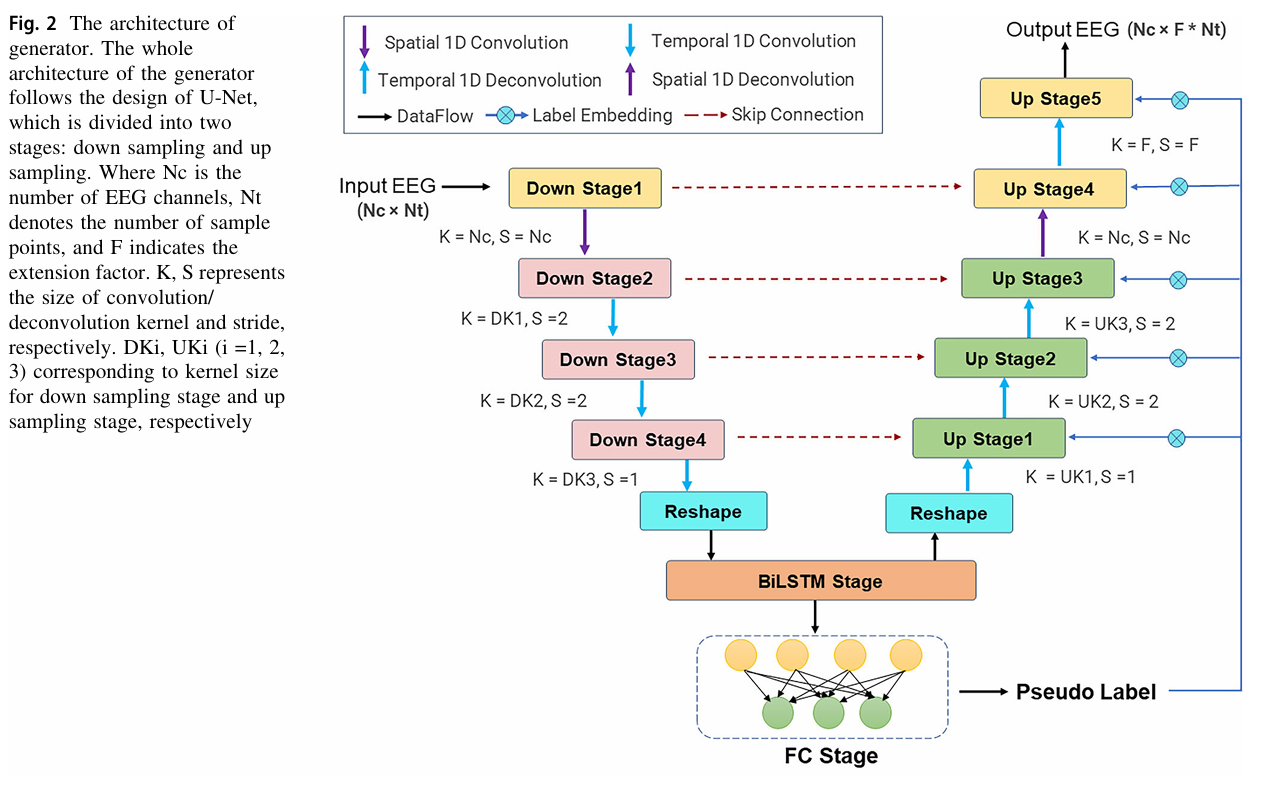
生成器是 TEGAN 实现 “短信号拉长” 的核心,其架构借鉴了 U-Net(常用于医学图像分割),通过 “下采样提取特征→上采样重构信号” 的流程,实现短信号到长信号的精准转换,关键设计包括三点:
- U 型双阶段结构:补全信号信息
生成器分为 下采样阶段 和 上采样阶段:- 下采样:通过 3 个 1D 卷积模块,逐步压缩短信号的时间维度、提取关键特征(如基频信息、导联间关联),同时用 “谱归一化(SN)” 防止过拟合;
- 上采样:通过 5 个 1D 反卷积模块,逐步恢复时间维度、重构长信号,同时通过 “跳跃连接”(Skip Connection),将下采样阶段的细节特征(如局部时域波动)传递到上采样阶段,减少信号信息丢失。
- Bi-LSTM 编码:连接时空特征
- 考虑到 SSVEP 信号的 “时空关联性”(不同时间点的信号特征存在依赖,不同导联的信号也相互关联),生成器在上下采样之间加入 双向长短期记忆网络(Bi-LSTM):
作用是编码下采样提取的特征,建立 “时间维度” 和 “空间维度” 的关联(例如,某一导联在 0.3s 的特征与另一导联在 0.4s 的特征的联系),让重构的长信号更符合真实 SSVEP 的时空规律。
- 考虑到 SSVEP 信号的 “时空关联性”(不同时间点的信号特征存在依赖,不同导联的信号也相互关联),生成器在上下采样之间加入 双向长短期记忆网络(Bi-LSTM):
- 伪标签生成:增强类别一致性
- 由于生成器输入无标签信息,团队设计了 伪标签生成模块:通过全连接层对下采样特征进行分类,生成 “高置信度伪标签”(如判断输入短信号对应 8Hz 刺激),再结合伪标签优化生成器 —— 确保生成的长信号与原短信号的 “类别属性” 一致(不会把 8Hz 的短信号生成为 12Hz 的长信号)。
min G L G = V G − ∑ c = 1 K y c log p c (6) \min_G L_G = V_G - \sum_{c=1}^K y_c \log p_c \tag{6} GminLG=VG−c=1∑Kyclogpc(6)
2.3 判别器:“真伪 + 类别” 双任务约束
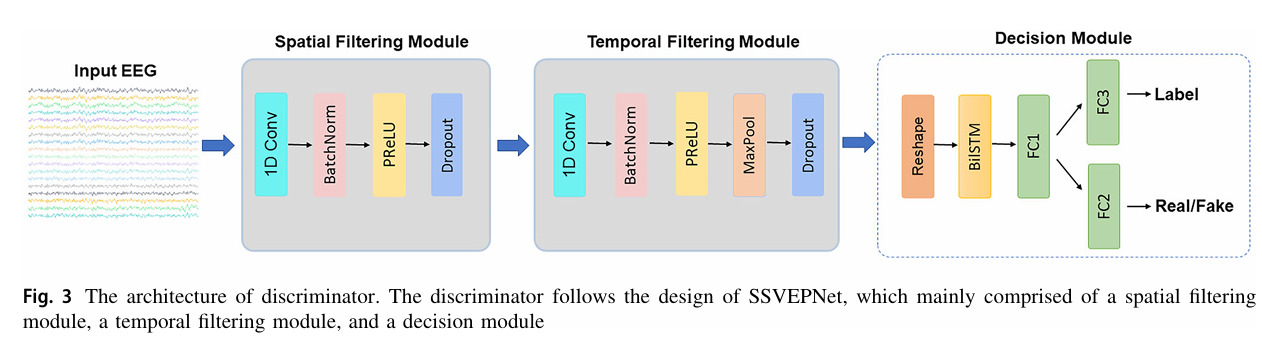
判别器的核心是 “给生成器提反馈”,但 TEGAN 对其做了两点优化,避免传统 GAN 常见的 “模式崩溃”(生成信号单一化)问题:
- 三模块架构:精准区分信号
判别器基于团队此前提出的 SSVEPNet11 改进,分为三个模块:- 空间滤波模块:用 1D 卷积融合不同导联的信号(如整合枕叶区域 10 个导联的信息),提取空间特征;
- 时间滤波模块:用 1D 卷积 + 最大池化,提取信号的时间特征(如不同时间点的频率波动)
- 决策模块:用 Bi-LSTM 学习时空特征的依赖关系,再通过全连接层完成 “真伪判别”(是真实长信号还是生成的)和 “类别判别”(对应哪个刺激频率)。
- 辅助分类器:抑制模式崩溃
在判别器的最后一层加入 辅助分类器(ACGAN 的核心设计):- 判别器不仅关注 “信号真伪”,还需关注 “信号类别”,迫使生成器在生成长信号时,既要模仿真实信号的特征,又要保持类别一致性;
- 尤其当数据集类别较多时(如 12 类的 Dial 数据集),辅助分类器能有效避免生成器 “混淆类别”—— 例如,不会把 6.67Hz 的信号生成为 8.57Hz 的信号。
2.4 正则化策略:解决 GAN 训练不稳定性
GAN 训练易受数据量影响(尤其是小样本时),TEGAN 引入两种正则化策略,确保训练稳定且生成信号高质量:
- 基于微调的两阶段训练策略
采用 “先训通用模型、再微调专属模型” 的思路:- 第一阶段(源模型训练):用 N-1 个受试者的 SSVEP 数据(源数据),训练通用的生成器(Gₛ)和判别器(Dₛ),学习 SSVEP 信号的通用规律(如枕叶信号的频率响应模式);
- 第二阶段(目标模型微调):将 Gₛ 和 Dₛ 的参数复制到目标模型(Gₜ、Dₜ),冻结 Dₜ 除全连接层外的参数,用少量目标受试者的数据(如仅 20% 的校准数据)微调 Gₜ 和 Dₜ,让模型适配目标用户的信号特点;
- 优势:减少目标用户的校准数据需求 —— 例如,仅用 20% 的校准数据,就能达到用 80% 数据训练的相近效果。
- LeCam 散度正则化
在判别器的训练目标中加入 LeCam 散度正则化项:- 不让判别器 “过度区分” 真实信号和生成信号,而是通过约束让两者的预测分布更接近(例如,让判别器对真实信号的预测值和生成信号的预测值差异缩小);
- 具体做法:通过指数移动平均(EMA)跟踪判别器的预测值,用正则化项引导判别器 “温和判别”,避免生成器为了骗过判别器而生成极端信号(如仅保留基频、丢失谐波)。
min D L D = − V D + λ R L C ( D ) (7) \min_D L_D = -V_D + \lambda R_{LC}(D) \tag{7} DminLD=−VD+λRLC(D)(7)
其中 λ \lambda λ 表示正则化权重,勒卡姆正则化项 R L C ( D ) R_{LC}(D) RLC(D) 表示为:
R L C ( D ) = E x ∼ p x l [ ∥ D ( x ) − α F ∥ 2 ] − E x ∼ p x s [ ∥ D ( G ( x ) ) − α R ∥ 2 ] (8) R_{LC}(D) = \underset{x \sim p_{xl}}{\mathbb{E}} \left[ \| D(x) - \alpha_F \|^2 \right] - \underset{x \sim p_{xs}}{\mathbb{E}} \left[ \| D(G(x)) - \alpha_R \|^2 \right] \tag{8} RLC(D)=x∼pxlE[∥D(x)−αF∥2]−x∼pxsE[∥D(G(x))−αR∥2](8)
其中 α F \alpha_F αF 和 α R \alpha_R αR 是由指数移动平均变量得到的锚点,旨在跟踪判别器的预测。 R L C ( D ) R_{LC}(D) RLC(D) 促使判别器混合真实脑电(EEG)和生成脑电(EEG)的预测,而非对它们进行区分。这种违反直觉的效果可通过为优化更鲁棒的目标提供有意义的约束来发挥正则化作用。 假设总训练轮次为 T E TE TE,则 α F \alpha_F αF 和 α R \alpha_R αR 可通过以下公式计算:
{ α F ( i + 1 ) = γ D ( G ( x s ) ) + ( 1 − γ ) α F ( i ) α R ( i + 1 ) = γ D ( x l ) + ( 1 − γ ) α R ( i ) , S E ≤ i ≤ T E (9) \begin{cases} \alpha_F(i+1) = \gamma D(G(x_s)) + (1-\gamma) \alpha_F(i) \\ \alpha_R(i+1) = \gamma D(x_l) + (1-\gamma) \alpha_R(i) \end{cases}, \quad SE \leq i \leq TE \tag{9} {αF(i+1)=γD(G(xs))+(1−γ)αF(i)αR(i+1)=γD(xl)+(1−γ)αR(i),SE≤i≤TE(9)
这里, γ \gamma γ 是衰减系数, S E SE SE 表示开始实施勒卡姆正则化项的轮次,这有助于避免在训练初期模型欠拟合时出现过度正则化的情况。
3. 实验结果与分析讨论
3.1 数据集与参数配置
实验采用的两个数据集在刺激设计、数据采集参数上存在差异,可覆盖不同复杂度的 SSVEP-BCI 场景,具体信息如下表所示:
| 数据集 | 刺激类别数 | 被试数量 | 采样率(原始 / 下采样后) | 电极选择 | 信号处理 | 训练数据划分(小 / 中 / 大规模) |
|---|---|---|---|---|---|---|
| Direction | 4(5.45/6.67/8.57/12 Hz) | 54 人(25 女,24-35 岁) | 1000 Hz / 100 Hz | 枕叶 10 电极(P7/P3/Pz 等) | 4-40 Hz Butterworth 带通滤波 | 20%/50%/80% 训练,80%/50%/20% 测试 |
| Dial | 12(9.25 Hz 为基频,Δf=0.5 Hz) | 10 人(1 女,平均 28 岁) | 2048 Hz / 256 Hz | 枕叶 8 电极(PO7/PO3/POZ 等) | 6-80 Hz Butterworth 带通滤波,剔除刺激后 135ms 视觉潜伏期 | 20%/50%/80% 训练,80%/50%/20% 测试 |
TEGAN 训练与分类器参数遵循统一标准:
- 第一阶段(跨被试预训练):使用 Adam 优化器(β1=0.9,β2=0.999),学习率 0.001,批大小 64(Direction)/24(Dial),迭代 200 轮;
- 第二阶段(目标被试微调):采用 Cosine Annealing 学习率调度(初始 0.01),批大小 20(Direction)/24(Dial),迭代 500 轮;LeCam 正则化权重 λ=0.6,起始生效轮次 SE=50,衰减系数 γ=0.9。
3.2 评估指标与基线方法
实验以分类准确率和信息传输率(ITR) 作为核心指标,其中 ITR 计算需考虑 0.5s 视线转移时间(即T=T+0.5,公式如下),同时采用配对 t 检验(p<0.05 为显著差异)验证结果可靠性:
I T R ( P , T ) = ( log 2 N + P log 2 P + ( 1 − P ) log 2 ( 1 − P ) ( N − 1 ) ) × 60 T (10) ITR(P,T)=\left(\log_2 N + P\log_2 P + (1-P)\log_2 \frac{(1-P)}{(N-1)}\right) × \frac{60}{T} \tag{10} ITR(P,T)=(log2N+Plog2P+(1−P)log2(N−1)(1−P))×T60(10)
式中,P 为分类准确率,T 为信号时间窗口长度(s),N 为刺激类别数。
基线方法涵盖传统频率识别与深度学习两类,共 4 种主流算法:
- 传统方法:IT-CCA(个体模板 canonical correlation analysis)、TRCA(task-related component analysis);
- 深度学习方法:EEGNet(紧凑卷积神经网络)、C-CNN(复频谱卷积神经网络)。
3.3 信号时间窗口长度对性能的影响
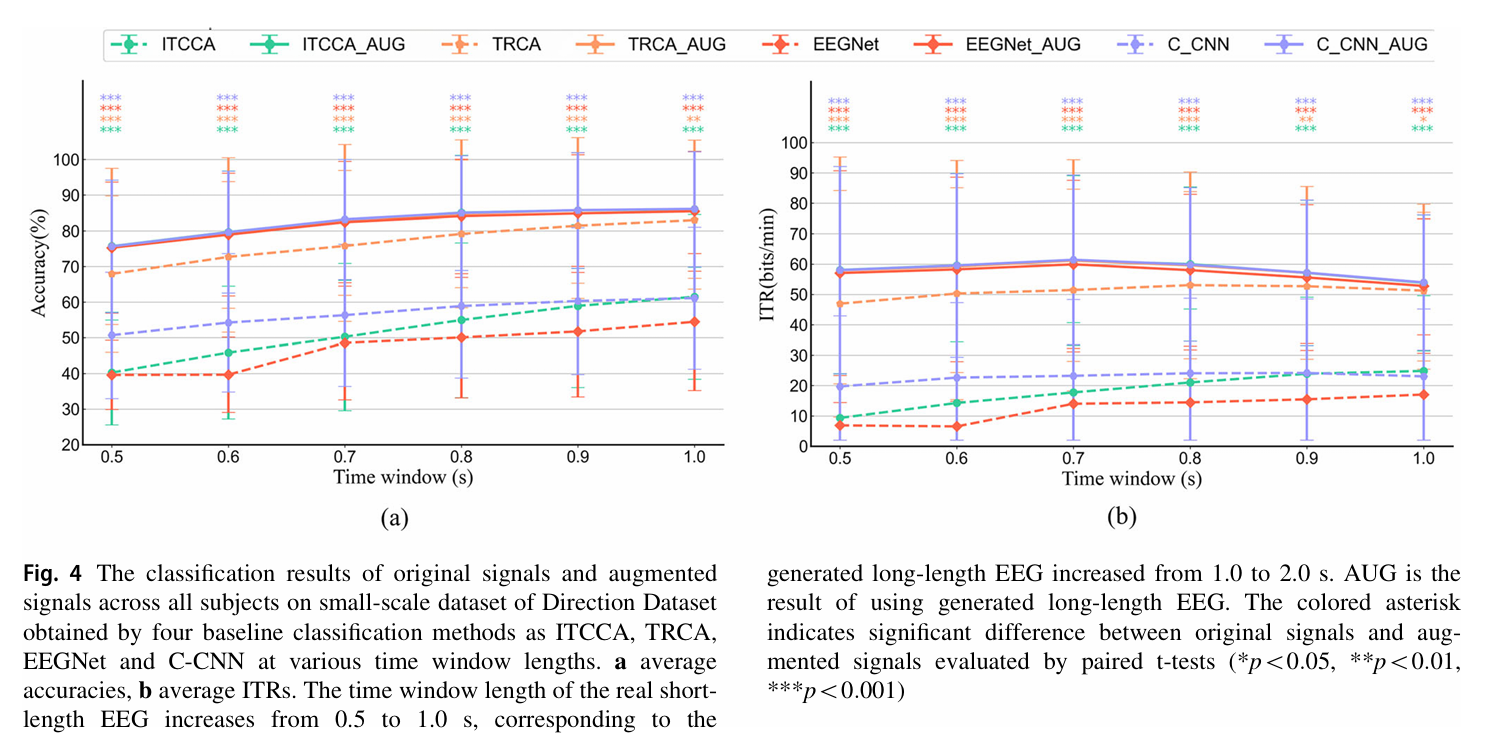
将原始信号长度从 0.5s 逐步增加至 1.0s(步长 0.1s),对应拓展后信号长度从 1.0s 增加至 2.0s(步长 0.2s),结果如下两图所示(以小规模训练集为例)。
- 所有基线方法均受益于 TEGAN 拓展:在 Direction 数据集上,IT-CCA、EEGNet、C-CNN 的准确率提升幅度均超过 20%(如 EEGNet 在 0.5s 原始信号时准确率仅 39.60%,拓展后达 75.27%,提升 35.67%);即使是对信号长度不敏感的 TRCA,也有 3%-7% 的准确率提升(0.5s 时从 67.92% 提升至 75.63%)。
- ITR 翻倍效应:Direction 数据集上,IT-CCA、EEGNet、C-CNN 的 ITR 在拓展后接近翻倍(如 IT-CCA 在 0.7s 窗口时,原始信号 ITR 仅 24.83 bits/min,拓展后达 61.19 bits/min);且所有方法的最优 ITR 均集中在 0.7s 拓展窗口(原始 0.35s),解决了传统方法最优窗口分散的问题。
- 类别数增加时仍有效:Dial 数据集(12 类)中,除 TRCA 在 0.7s 后无显著提升外,其余方法在全窗口长度下均有显著提升(IT-CCA 在 0.5s 时准确率从 42.44% 提升至 73.24%,提升 30.8%),且最优 ITR 集中在 0.5s 拓展窗口(原始 0.25s),验证了 TEGAN 在多类别场景的适配性。
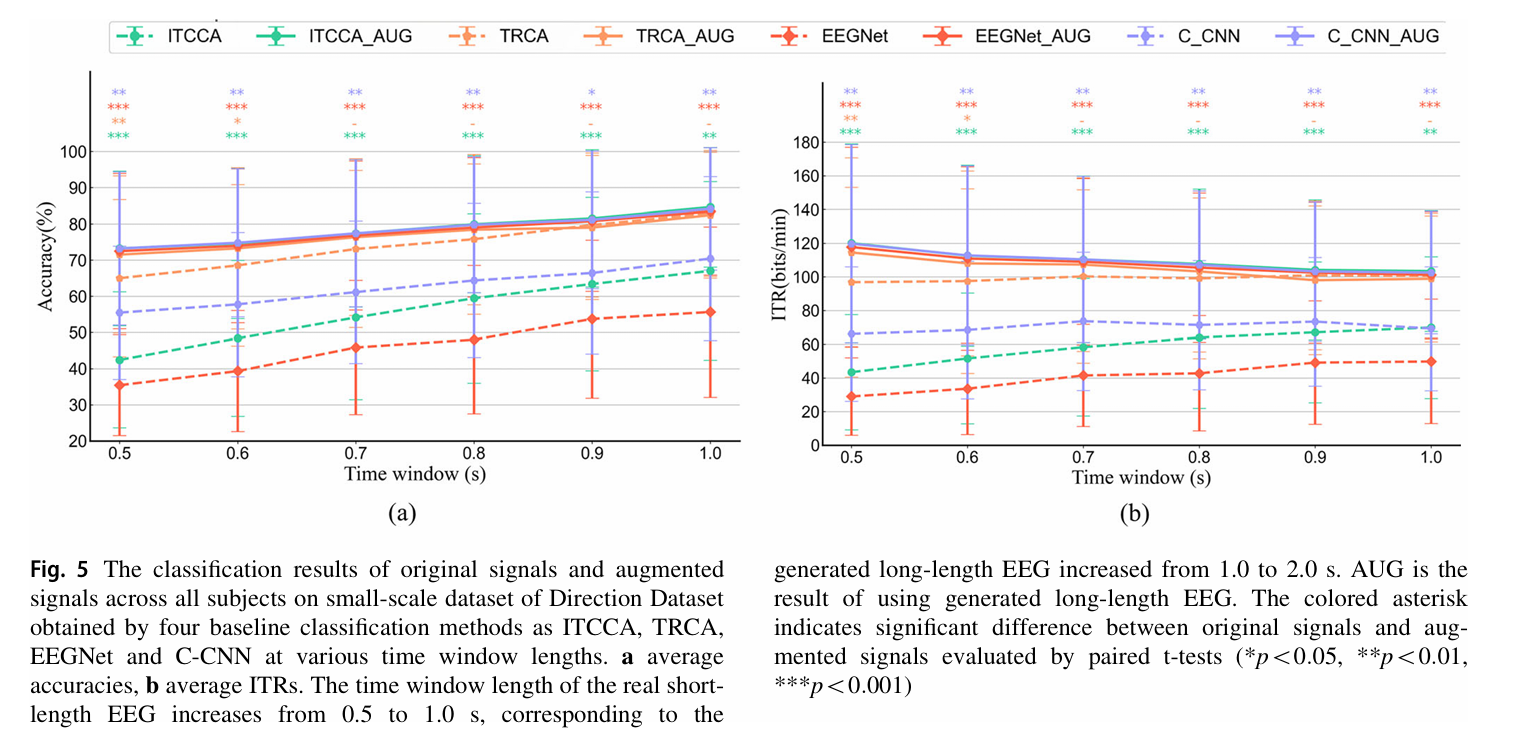
短时长 SSVEP 信号的频率 / 相位特征被自发脑电噪声掩盖,TEGAN 通过学习 “短 - 长信号” 映射关系,补充了与刺激频率锁定的周期性成分。
3.4 训练数据规模对性能的影响
为验证 TEGAN 在 “有限校准数据” 场景的价值,实验设置小(20% 训练)、中(50% 训练)、大(80% 训练)三种数据规模,固定原始信号长度 1.0s(拓展后 2.0s),结果如下图所示。
- 小规模数据下提升最显著:Direction 数据集小规模场景中,IT-CCA、EEGNet、C-CNN 的准确率提升分别达 24.54%、31.00%、24.97%;而大规模场景中,提升幅度降至 22.63%、9.04%、6.34%,说明 TEGAN 能有效缓解 “数据稀缺” 问题。
- 多类别场景依赖 TEGAN:Dial 数据集(12 类)中,即使是大规模训练数据,IT-CCA、EEGNet 仍需 TEGAN 提升 17% 以上准确率(原始数据准确率约 53%-65%,拓展后达 71%-73%),因多类别场景下分类器更难通过少量数据学习类别边界。
- TRCA 的特殊性:仅在 Direction 数据集小规模场景中,TRCA 有显著提升(3.05%),中大规模场景无显著差异,进一步证明其对数据量敏感度低,但在多类别场景(Dial)仍需 TEGAN 补充特征。
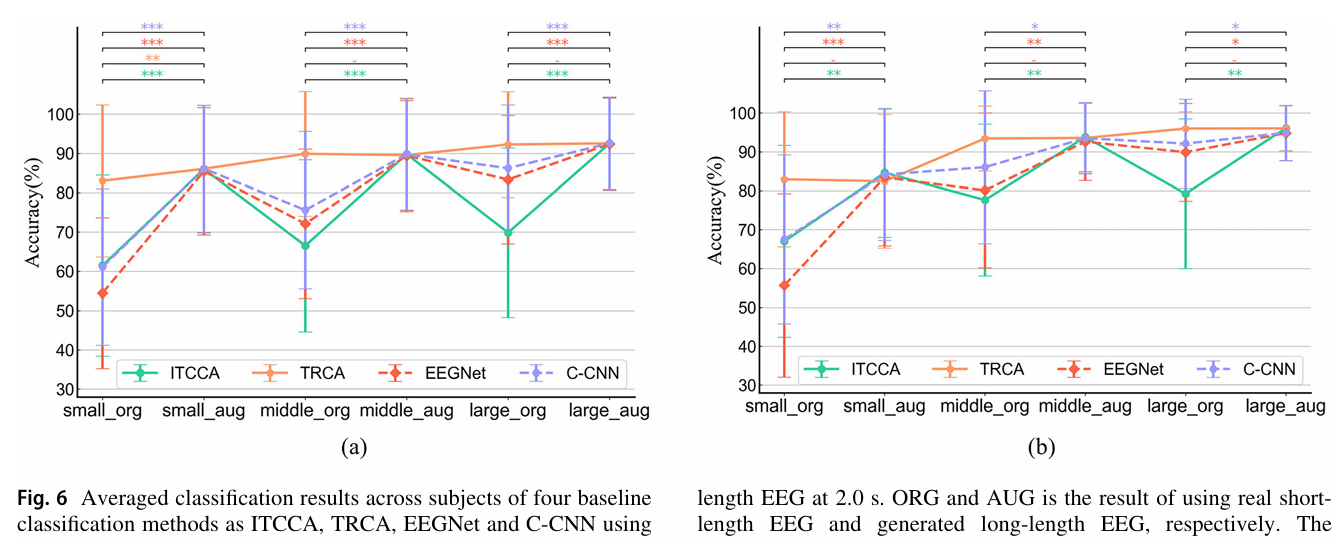
SSVEP-BCI 的实际应用中,用户校准时间越长越易疲劳(导致信号质量下降)。TEGAN 可在 “仅 20% 校准数据” 下实现接近全量数据的性能,将校准时间缩短 80%,大幅提升用户体验。
3.5 个体差异性适配分析
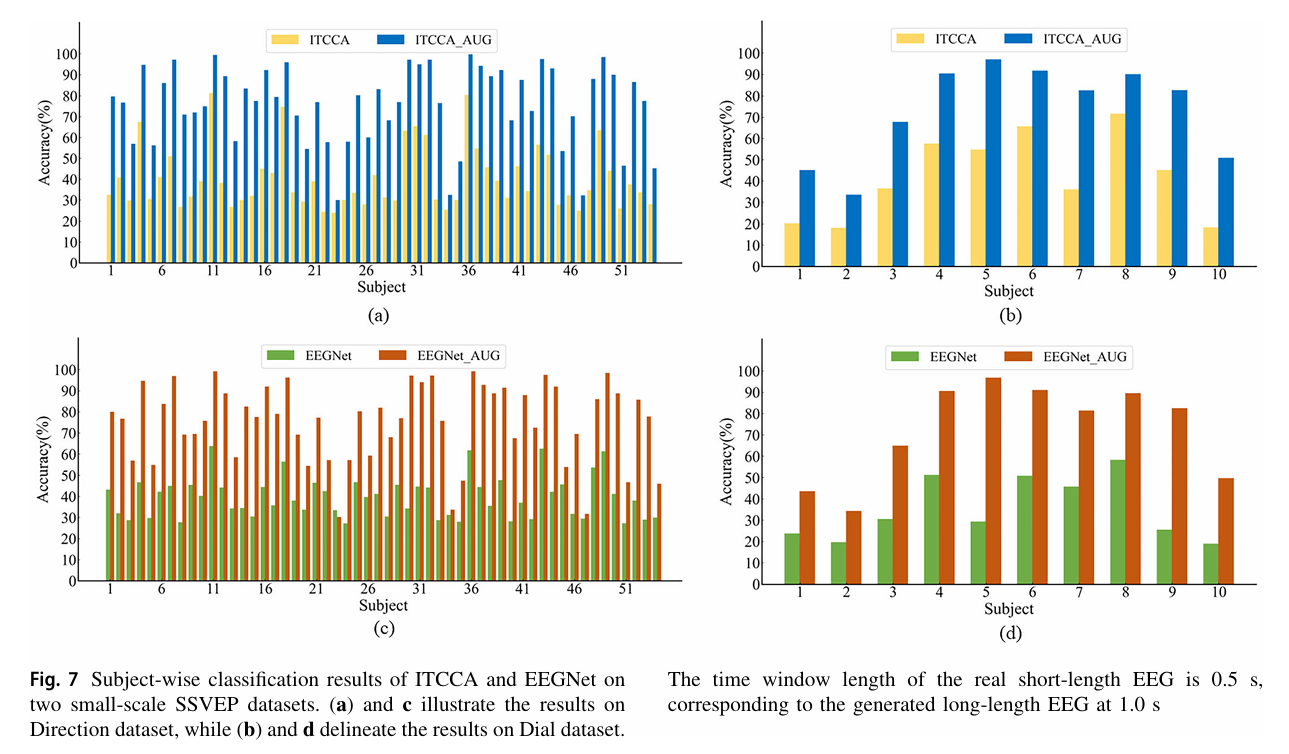
EEG 信号具有强个体特异性(如头发生长、视觉潜伏期差异),实验通过 “被试级分类结果” 验证 TEGAN 的个体适配性,以 0.5s 原始信号(拓展后 1.0s)为例,结果如下图所示。
- 绝大多数被试性能提升:Direction 数据集 54 名被试中,53 名被试的 IT-CCA/EEGNet 性能提升,其中被试 39 的 IT-CCA 准确率从 39.25% 提升至 92.25%(提升 53 个百分点);Dial 数据集 10 名被试全部提升,被试 5 的 EEGNet 准确率从 29.40% 提升至 96.87%(提升 67.47 个百分点)。
- 极少数被试性能下降:仅 Direction 数据集被试 32 的 EEGNet 准确率从 33.50% 降至 30.25%(下降 3.25 个百分点),推测因该被试的 SSVEP 谐波成分特殊(TEGAN 暂未充分学习谐波特征,如图 10 所示,拓展信号高频谐波缺失),导致生成信号与真实信号偏差较大。
未来可在 TEGAN 中加入 “谐波注意力机制”,通过强化学习或多尺度频谱约束,让生成器更关注 SSVEP 的谐波成分(如 6.67Hz刺激的 13.34Hz、20.01Hz 谐波),进一步提升个体适配性。
3.6 消融实验
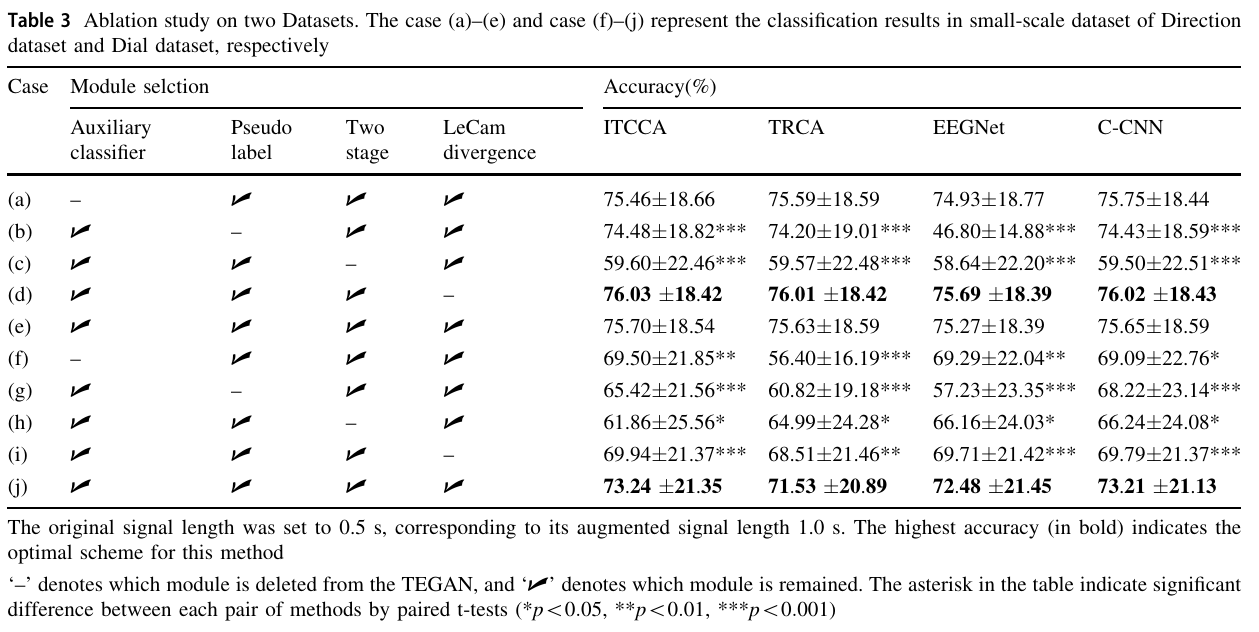
在小规模数据集上通过消融验证(删除某模块后对比性能),明确 TEGAN 中 “辅助分类器、伪标签生成、两阶段训练、LeCam 正则化” 四大模块的作用,结果如表 3 所示:
- 两阶段训练(最关键):删除后,Direction 数据集各方法准确率降 16-19 个百分点,Dial 数据集降 7-12 个百分点;因该模块通过 “跨被试预训练学通用特征 + 目标被试微调学个体特征”,解决 GAN 小数据下模式崩溃问题,是 TEGAN 泛化核心。
- 伪标签生成:删除后,Direction 数据集 EEGNet 准确率骤降 28.47 个百分点,Dial 数据集各方法降 5-15 个百分点;因生成器借全连接层生成 “高置信伪标签”(公式 6),引导生成信号与真实类别对齐,为深度学习分类器补充类别先验以提升特征判别性。
- 辅助分类器与 LeCam 正则化(多类别专属):Direction 数据集(4 类)删除后性能无显著变化,Dial 数据集(12 类)删除后各方法准确率降 3-8 个百分点;因多类别场景 GAN 易因类别分布复杂模式崩溃,二者分别助力判别器区分 “真实 / 伪造 + 类别”、约束判别器预测分布(公式 9)以提升生成数据类别覆盖度。
模块组合最优策略:Dial 数据集(多类别)需全模块保留,Direction 数据集(少类别)可省略 “辅助分类器 + LeCam 正则化”
降成本;少类别(≤5 类)用 “两阶段训练 + 伪标签生成”,多类别(≥10 类)全模块保留。
3.7 缩减分类性能差异的附加价值
实验发现,TEGAN 不仅提升单一分类器性能,还能缩小不同分类器的性能差距。以 Dial 数据集被试 5 为例:
-
原始信号(1.0s):IT-CCA 与 TRCA 的相关系数差距达 0.15(目标 10 的相关系数分别为 0.74 和 0.89),特征重叠严重(图 8a);
-
拓展信号(2.0s):IT-CCA 的目标 10 相关系数提升至 0.92,非目标相关系数降至 0.5 以下,与 TRCA 的差距缩小至 0.05(图 8b);
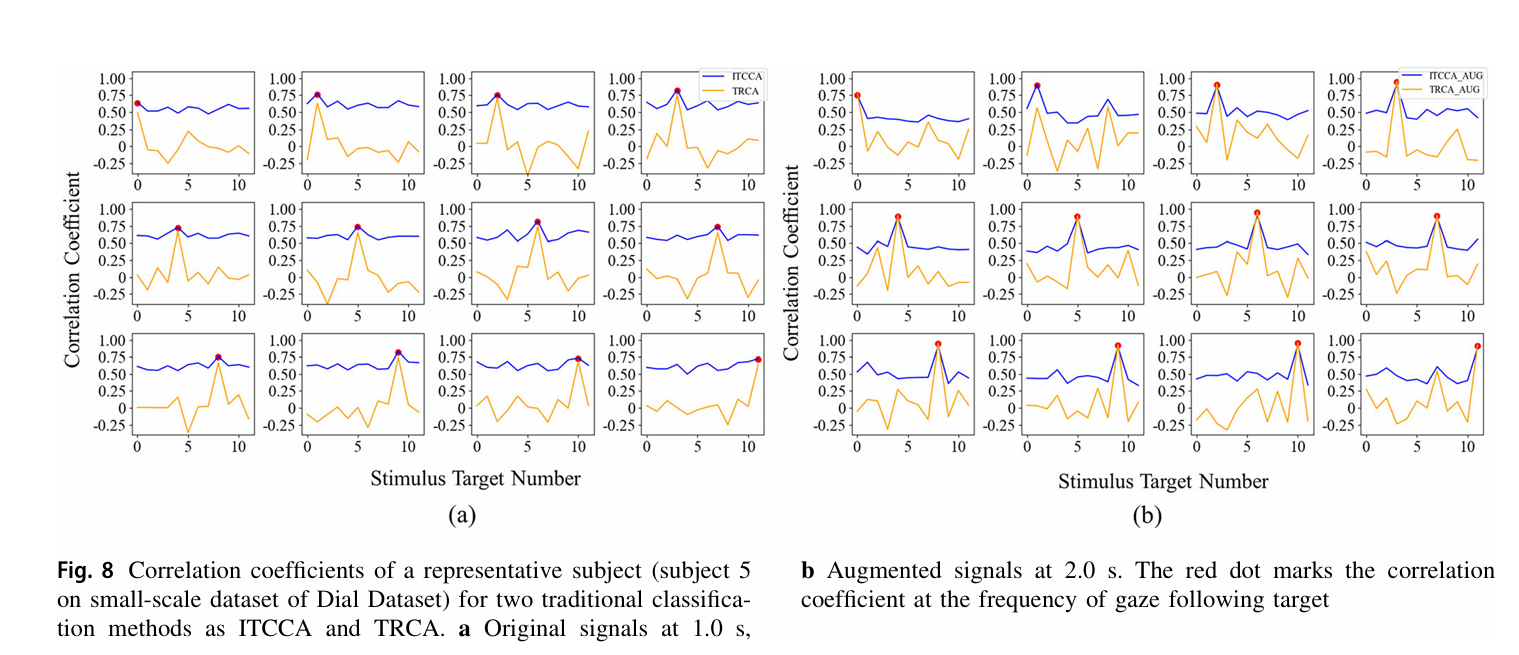
-
深度学习方法:EEGNet 在原始信号下特征聚类混乱(图 9a),拓展后类内距离缩小、类间距离扩大(图 9b),
与 C-CNN 的准确率差距从 18 个百分点缩小至 1 个百分点。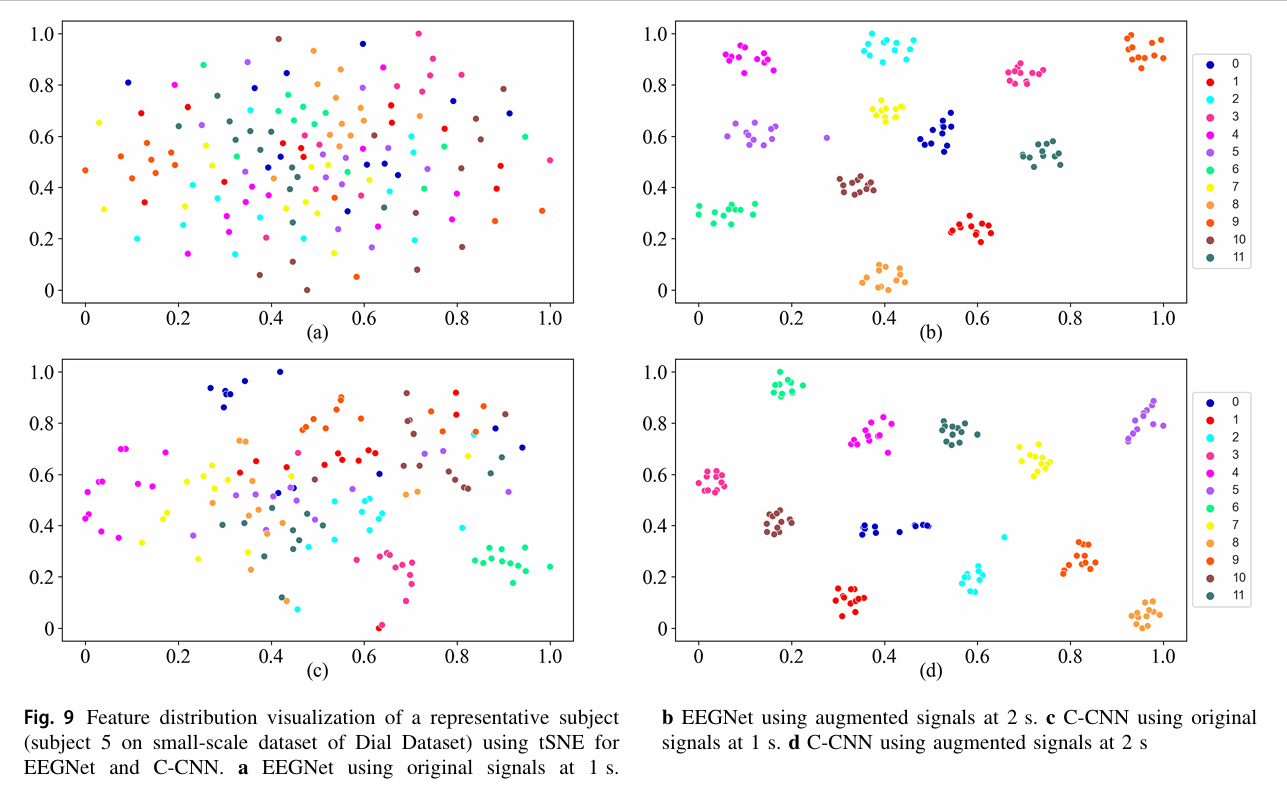
传统 SSVEP-BCI 需根据场景选择 “复杂但高性能” 的分类器(如 TRCA、C-CNN),增加部署成本;TEGAN 可让 “简单分类器(如 IT-CCA)” 达到接近复杂方法的性能,降低实际应用的算法复杂度与计算成本。
3.8 生成数据的信号质量评估
通过对比 “真实长信号” 与 “TEGAN 生成信号” 的时频域特征(如下图 10),验证了生成数据的信号质量:
- 时间域:二者相关系数 ρ_t 达 0.64-0.69,生成信号能复现真实信号的周期性波动;
- 频率域:生成信号在基频(如 6.67Hz、12.0Hz)处有显著峰值,与真实信号的频率域相关系数 ρ_f 达 0.80-0.86;
可以观察到,生成信号难以复现高频谐波(如 6.67Hz 的 20Hz 以上谐波),且存在少量伪峰值,导致其单独用于训练时准确率比真实长信号低 5-10 个百分点(表 5)。
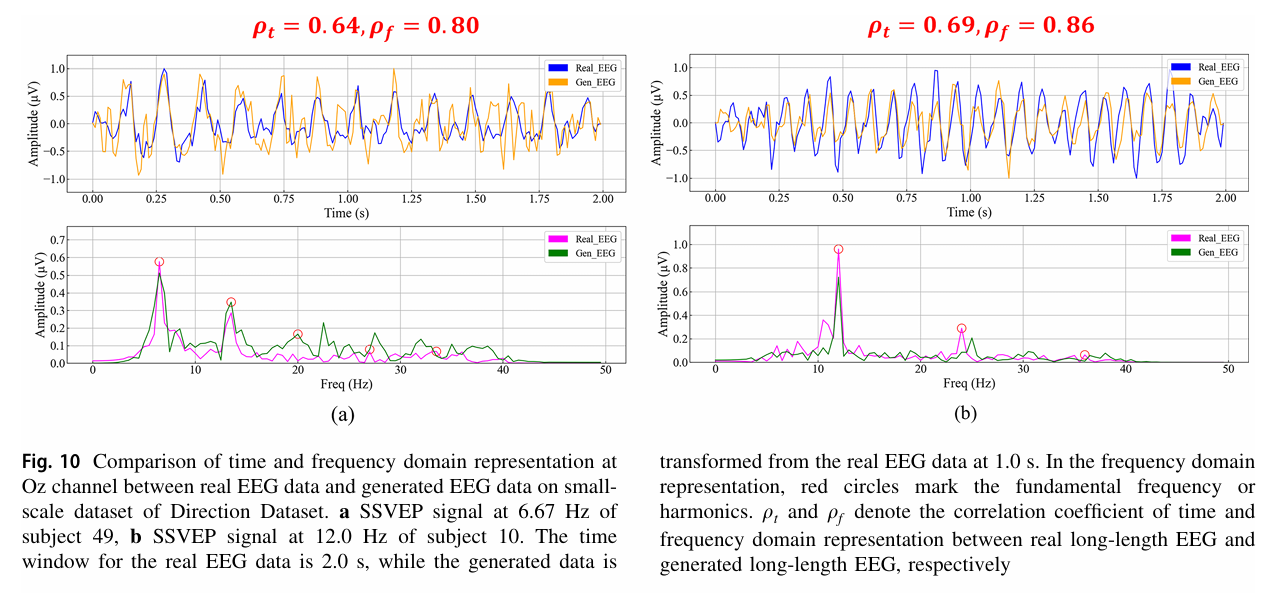
后续可在 TEGAN 的生成器损失函数中加入 “谐波相似度约束”(如计算生成信号与真实信号在谐波频率处的功率比),强制生成器学习谐波特征,进一步提升数据真实性。
3.9 TEGAN计算开销
实验在 NVIDIA GeForce GTX 3090 GPU 上测试 TEGAN 的计算开销,结果如表 7 所示:
- 训练成本:Direction 数据集两阶段共需 514.86s(约 8.6 分钟),Dial 数据集需 199.11s(约 3.3 分钟),均在可接受范围内;
- 在线生成成本:生成单条 1.0s 拓展信号仅需 0.36ms(Direction)-0.47ms(Dial),可实时用于在线 BCI 系统;
参数规模:生成器参数约 0.47-0.68M,判别器约 0.20-0.81M,轻量化设计适配嵌入式设备(如脑电帽配套的边缘计算模块)。

TEGAN 的训练可在离线阶段完成,在线测试时仅需毫秒级生成时间,不会影响 SSVEP-BCI 的实时响应(通常要求延迟 < 100ms)。
4. 结论与展望
4.1 研究结论
TEGAN 作为首个实现 SSVEP 信号 “长度扩展” 的 GAN 模型,其核心贡献可总结为三点:
- 突破数据长度瓶颈:
首次通过 GAN 实现短信号到长信号的端到端转换,无需增加校准数据量,即可提升分类性能 —— 在有限校准数据下,传统方法和深度学习方法的准确率平均提升 20% 以上,ITR 接近翻倍; - 降低应用成本:通过两阶段训练减少校准时间(如从 30 分钟缩短到 5 分钟以内),同时缩小不同分类方法的性能差距 —— 简单方法(如 ITCCA)也能达到复杂方法(如 TRCA)的性能,降低 BCI 系统的开发成本;
- 验证技术可行性:在 4 类和 12 类数据集上充分验证,证明生成对抗网络在 SSVEP 信号长度扩展上的潜力,为后续研究提供新范式。
4.2 未来展望
基于现有研究的局限,未来可从以下方向进行优化TEGAN模型:
- 支持更多类别:目前仅验证 12 类信号,未来计划在更大类别数据集(如 40 类的 Benchmark 数据集)上测试,解决多类别场景下的模式崩溃问题;
- 提升谐波还原能力:引入 “滤波器组技术”,增强对高次谐波的还原,进一步提升生成信号的真实性;
- 实现零校准:结合更先进的迁移学习技术(如改进两阶段训练),无需目标用户的校准数据,即可生成专属长信号,推动 BCI 系统的 “即插即用”;
- 拓展应用场景:将 TEGAN 应用于运动想象、P300 等其他 BCI 范式,解决更多 “短数据” 相关问题。
5. 参考文献
-
Kwak N S, Müller K R, Lee S W. A convolutional neural network for steady state visual evoked potential classification under ambulatory environment[J]. PloS one, 2017, 12(2): e0172578. https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0172578 ↩︎
-
Dang W, Li M, Lv D, et al. MHLCNN: Multi-harmonic linkage CNN model for SSVEP and SSMVEP signal classification[J]. IEEE Transactions on Circuits and Systems II: Express Briefs, 2021, 69(1): 244-248.https://ieeexplore.ieee.org/abstract/document/9465221 ↩︎
-
Nakanishi M, Wang Y, Wang Y T, et al. A comparison study of canonical correlation analysis based methods for detecting steady-state visual evoked potentials[J]. PloS one, 2015, 10(10): e0140703.https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0140703 ↩︎
-
Lin Z, Zhang C, Wu W, et al. Frequency recognition based on canonical correlation analysis for SSVEP-based BCIs[J]. IEEE transactions on biomedical engineering, 2006, 53(12): 2610-2614. https://ieeexplore.ieee.org/abstract/document/4015614/ ↩︎ ↩︎
-
Nakanishi M, Wang Y, Chen X, et al. Enhancing detection of SSVEPs for a high-speed brain speller using task-related component analysis[J]. IEEE Transactions on Biomedical Engineering, 2017, 65(1): 104-112. https://ieeexplore.ieee.org/abstract/document/7904641 ↩︎ ↩︎ ↩︎
-
Wang Y, Nakanishi M, Wang Y T, et al. Enhancing detection of steady-state visual evoked potentials using individual training data[C]//2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society. Ieee, 2014: 3037-3040. https://ieeexplore.ieee.org/abstract/document/6944263 ↩︎
-
Waytowich N, Lawhern V J, Garcia J O, et al. Compact convolutional neural networks for classification of asynchronous steady-state visual evoked potentials[J]. Journal of neural engineering, 2018, 15(6): 066031. https://iopscience.iop.org/article/10.1088/1741-2552/aae5d8/meta ↩︎ ↩︎
-
Ravi A, Beni N H, Manuel J, et al. Comparing user-dependent and user-independent training of CNN for SSVEP BCI[J]. Journal of neural engineering, 2020, 17(2): 026028. https://iopscience.iop.org/article/10.1088/1741-2552/ab6a67/meta ↩︎
-
Hartmann K G, Schirrmeister R T, Ball T. EEG-GAN: Generative adversarial networks for electroencephalograhic (EEG) brain signals[J]. arXiv preprint arXiv:1806.01875, 2018.https://arxiv.org/abs/1806.01875 ↩︎
-
Aznan N K N, Atapour-Abarghouei A, Bonner S, et al. Leveraging synthetic subject invariant EEG signals for zero calibration BCI[C]//2020 25th International Conference on Pattern Recognition (ICPR). IEEE, 2021: 10418-10425.https://ieeenew.66557.net/abstract/document/9411994 ↩︎
-
Pan Y, Chen J, Zhang Y, et al. An efficient CNN-LSTM network with spectral normalization and label smoothing technologies for SSVEP frequency recognition[J]. Journal of Neural Engineering, 2022, 19(5): 056014. https://iopscience.iop.org/article/10.1088/1741-2552/ac8dc5/meta ↩︎

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)