AI 智能体7种新架构设计模式和代码级落地实现
一个大语言模型(LLM)调用的输出会依次成为下一个 LLM 调用的输入。这种模式将一个任务分解成一系列固定的步骤,每一步都由一个 LLM 调用来处理,它会处理前一个 LLM 调用的输出。这种模式适用于那些可以被清晰地分解成可预测的、按顺序排列的子任务的任务。
1.AI 智能体的架构设计模式和落地实现
架构设计模式一、Workflow: Prompt Chaining
一个大语言模型(LLM)调用的输出会依次成为下一个 LLM 调用的输入。这种模式将一个任务分解成一系列固定的步骤,每一步都由一个 LLM 调用来处理,它会处理前一个 LLM 调用的输出。这种模式适用于那些可以被清晰地分解成可预测的、按顺序排列的子任务的任务。

1、使用场景
-
生成结构化文档:LLM1 创建大纲,LLM2根据标准验证大纲,LLM3根据经过验证的大纲撰写内容。
-
多步骤数据处理:提取信息,转换信息,然后对信息进行总结。
-
基于精选输入生成新闻通讯。
2、落地实现代码
import osfrom google import genai
# Configure the client (ensure GEMINI_API_KEY is set in your environment)client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
# --- Step 1: Summarize Text ---original_text = "Large language models are powerful AI systems trained on vast amounts of text data. They can generate human-like text, translate languages, write different kinds of creative content, and answer your questions in an informative way."prompt1 = f"Summarize the following text in one sentence: {original_text}"
# Use client.models.generate_contentresponse1 = client.models.generate_content( model='gemini-2.0-flash', contents=prompt1)summary = response1.text.strip()print(f"Summary: {summary}")
# --- Step 2: Translate the Summary ---prompt2 = f"Translate the following summary into French, only return the translation, no other text: {summary}"
# Use client.models.generate_contentresponse2 = client.models.generate_content( model='gemini-2.0-flash', contents=prompt2)translation = response2.text.strip()print(f"Translation: {translation}")
架构设计模式二、Workflow: Routing
一开始的时候,有一个大语言模型(LLM)就像一个交通指挥员。它会看看用户说的是啥,然后把用户的话送到最适合处理这个任务的地方,可能是另一个专门的 LLM,也可能是别的任务。这种做法就像是把不同的工作分给不同的人去做,这样就可以针对每个具体的工作,用专门的提示词、不同的模型或者特定的工具来优化。而且,对于简单的任务,可以用小一点的模型来处理,这样能提高效率,还能省点钱。一旦任务被分配出去,被选中的那个“小助手”就会负责把任务完成。
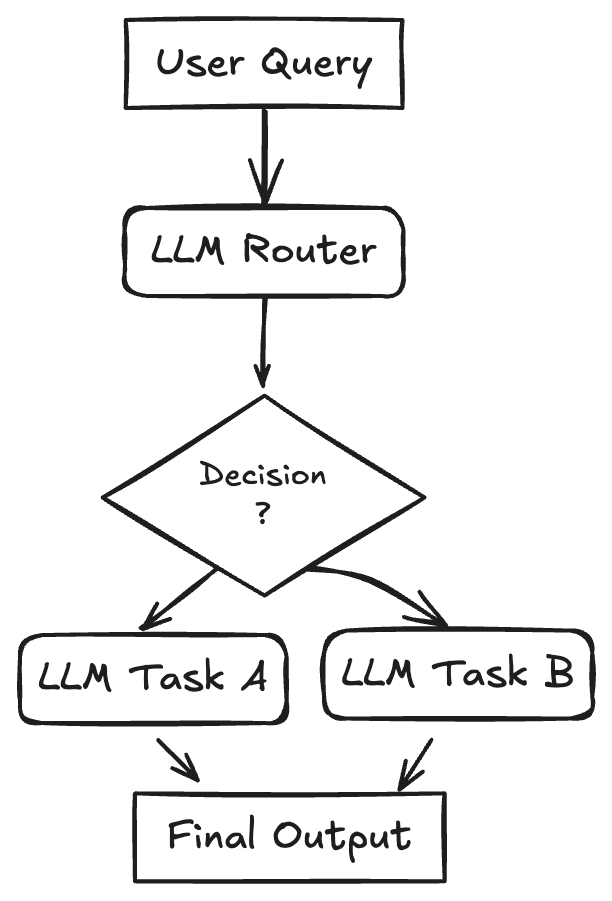
1、使用场景
- 客户支持系统:把客户的问题分给专门处理账单、技术支持或者产品信息的客服人员。
- 分层使用 LLM:把简单的问题交给速度快、成本低的模型(比如:Llama 3.1 8B),把复杂或者不常见的问题交给能力更强的模型(比如:Gemini 1.5 Pro)。
- 内容生成:把写博客文章、社交媒体更新或者广告文案的请求,分给不同的专门的提示词或者模型。
2、落地实现代码
import osimport jsonfrom google import genaifrom pydantic import BaseModelimport enum
# Configure the client (ensure GEMINI_API_KEY is set in your environment)client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
# Define Routing Schemaclass Category(enum.Enum): WEATHER = "weather" SCIENCE = "science" UNKNOWN = "unknown"
class RoutingDecision(BaseModel): category: Category reasoning: str
# Step 1: Route the Queryuser_query = "What's the weather like in Paris?"# user_query = "Explain quantum physics simply."# user_query = "What is the capital of France?"
prompt_router = f"""Analyze the user query below and determine its category.Categories:- weather: For questions about weather conditions.- science: For questions about science.- unknown: If the category is unclear.
Query: {user_query}"""
# Use client.models.generate_content with config for structured outputresponse_router = client.models.generate_content( model= 'gemini-2.0-flash-lite', contents=prompt_router, config={ 'response_mime_type': 'application/json', 'response_schema': RoutingDecision, },)print(f"Routing Decision: Category={response_router.parsed.category}, Reasoning={response_router.parsed.reasoning}")
# Step 2: Handoff based on Routingfinal_response = ""if response_router.parsed.category == Category.WEATHER: weather_prompt = f"Provide a brief weather forecast for the location mentioned in: '{user_query}'" weather_response = client.models.generate_content( model='gemini-2.0-flash', contents=weather_prompt ) final_response = weather_response.textelif response_router.parsed.category == Category.SCIENCE: science_response = client.models.generate_content( model="gemini-2.5-flash-preview-04-17", contents=user_query ) final_response = science_response.textelse: unknown_response = client.models.generate_content( model="gemini-2.0-flash-lite", contents=f"The user query is: {prompt_router}, but could not be answered. Here is the reasoning: {response_router.parsed.reasoning}. Write a helpful response to the user for him to try again." ) final_response = unknown_response.textprint(f"\nFinal Response: {final_response}")
架构设计模式三、Workflow: Parallelization
一个任务被拆成了好几个互不干扰的小任务,这些小任务同时由多个大语言模型(LLM)来处理,最后把它们的结果汇总起来。这种模式就是让任务同时进行。一开始的问题(或者问题的一部分)会同时发给多个 LLM,每个都有自己的提示词或者目标。等所有这些小任务都完成了,就把它们各自的结果收集起来,交给一个最后的汇总 LLM,这个 LLM 把它们合成最终的回答。如果小任务之间没有相互依赖,这样可以减少等待时间,或者通过像多数投票或者生成多种选择这样的方法来提高质量。
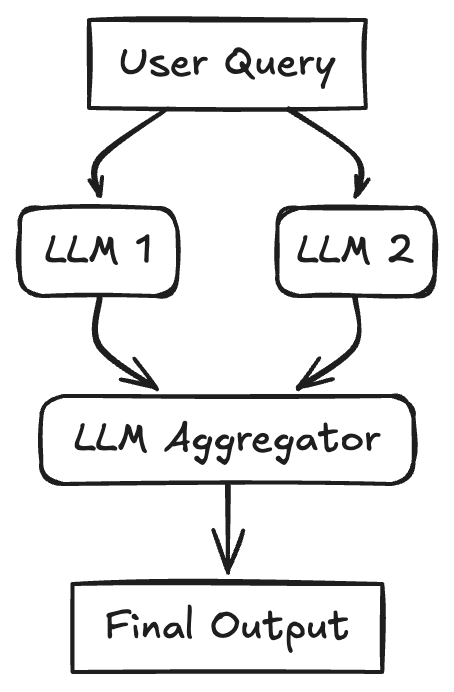
1、使用场景
-
带查询分解的 RAG:把一个复杂的查询分成几个小查询,同时运行每个小查询的检索,然后合成结果。
-
分析大文档:把文档分成几部分,同时总结每部分,然后再把总结合并起来。
-
生成多种视角:用不同的角色提示词问多个 LLM 同一个问题,然后汇总它们的回答。
-
对数据进行类似 MapReduce 的操作。
2、落地实现代码
import osimport asyncioimport timefrom google import genai
# Configure the client (ensure GEMINI_API_KEY is set in your environment)client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
async def generate_content(prompt: str) -> str: response = await client.aio.models.generate_content( model="gemini-2.0-flash", contents=prompt ) return response.text.strip()
async def parallel_tasks(): # Define Parallel Tasks topic = "a friendly robot exploring a jungle" prompts = [ f"Write a short, adventurous story idea about {topic}.", f"Write a short, funny story idea about {topic}.", f"Write a short, mysterious story idea about {topic}." ] # Run tasks concurrently and gather results start_time = time.time() tasks = [generate_content(prompt) for prompt in prompts] results = await asyncio.gather(*tasks) end_time = time.time() print(f"Time taken: {end_time - start_time} seconds")
print("\n--- Individual Results ---") for i, result in enumerate(results): print(f"Result {i+1}: {result}\n")
# Aggregate results and generate final story story_ideas = '\n'.join([f"Idea {i+1}: {result}" for i, result in enumerate(results)]) aggregation_prompt = f"Combine the following three story ideas into a single, cohesive summary paragraph:{story_ideas}" aggregation_response = await client.aio.models.generate_content( model="gemini-2.5-flash-preview-04-17", contents=aggregation_prompt ) return aggregation_response.text
result = await parallel_tasks()print(f"\n--- Aggregated Summary ---\n{result}")
架构设计模式四、Reflection Pattern
想象一下,有一个“小助手”(Agent)在做任务,做完之后,它会自己检查自己的工作,看看哪里做得不好,然后根据这些反馈,一遍又一遍地改进自己的回答。这种模式也被称为“评估者-优化器”,它就像是一个自我纠错的循环。
一开始,一个大语言模型(LLM)生成一个回答或者完成一个任务。然后,第二个 LLM(或者同一个 LLM,但用不同的提示词)就像一个“质检员”,来检查最初的结果,看看它是否符合要求或者达到了期望的质量。这个“质检员”的反馈会再送回去,让 LLM 根据这个反馈来改进输出。这个循环可以一直重复,直到“质检员”确认结果符合要求,或者得到了一个让人满意的结果。

1、使用场景
- 代码生成:先写出代码,运行它,然后用错误信息或者测试结果作为反馈来修复漏洞。
- 写作和润色:先生成一个初稿,思考它的清晰度和语气,然后再进行修改。
- 复杂问题解决:先制定一个计划,评估它的可行性,然后根据评估结果进行改进。
- 信息检索:先搜索信息,然后用一个评估 LLM 来检查是否找到了所有需要的细节,然后再给出答案。
2、落地实现代码
import osimport jsonfrom google import genaifrom pydantic import BaseModelimport enum
# Configure the client (ensure GEMINI_API_KEY is set in your environment)client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
class EvaluationStatus(enum.Enum): PASS = "PASS" FAIL = "FAIL"
class Evaluation(BaseModel): evaluation: EvaluationStatus feedback: str reasoning: str
# --- Initial Generation Function ---def generate_poem(topic: str, feedback: str = None) -> str: prompt = f"Write a short, four-line poem about {topic}." if feedback: prompt += f"\nIncorporate this feedback: {feedback}"
response = client.models.generate_content( model='gemini-2.0-flash', contents=prompt ) poem = response.text.strip() print(f"Generated Poem:\n{poem}") return poem
# --- Evaluation Function ---def evaluate(poem: str) -> Evaluation: print("\n--- Evaluating Poem ---") prompt_critique = f"""Critique the following poem. Does it rhyme well? Is it exactly four lines? Is it creative? Respond with PASS or FAIL and provide feedback.
Poem:{poem}""" response_critique = client.models.generate_content( model='gemini-2.0-flash', contents=prompt_critique, config={ 'response_mime_type': 'application/json', 'response_schema': Evaluation, }, ) critique = response_critique.parsed print(f"Evaluation Status: {critique.evaluation}") print(f"Evaluation Feedback: {critique.feedback}") return critique
# Reflection Loop max_iterations = 3current_iteration = 0topic = "a robot learning to paint"
# simulated poem which will not pass the evaluationcurrent_poem = "With circuits humming, cold and bright,\nA metal hand now holds a brush"
while current_iteration < max_iterations: current_iteration += 1 print(f"\n--- Iteration {current_iteration} ---") evaluation_result = evaluate(current_poem)
if evaluation_result.evaluation == EvaluationStatus.PASS: print("\nFinal Poem:") print(current_poem) break else: current_poem = generate_poem(topic, feedback=evaluation_result.feedback) if current_iteration == max_iterations: print("\nMax iterations reached. Last attempt:") print(current_poem)
架构设计模式五、Tool Use Pattern
大语言模型(LLM)可以调用外部的函数或者 API,这样就能和外面的世界互动,获取信息或者执行操作。这种模式通常被称为“函数调用”,也是大家最熟悉的一种模式。LLM 会得到一些可用工具(比如:函数、API、数据库等)的定义,这些定义包括工具的名字、描述和输入的格式。根据用户的问题,LLM 可以决定调用一个或多个工具,它会生成一个符合所需格式的结构化输出(比如:JSON 格式)。这个输出被用来执行实际的外部工具或函数,然后把结果返回给 LLM。LLM 再用这个结果来形成对用户的最终回答。这就大大扩展了 LLM 的能力,让它能做的事情远远超出了它训练时的数据。
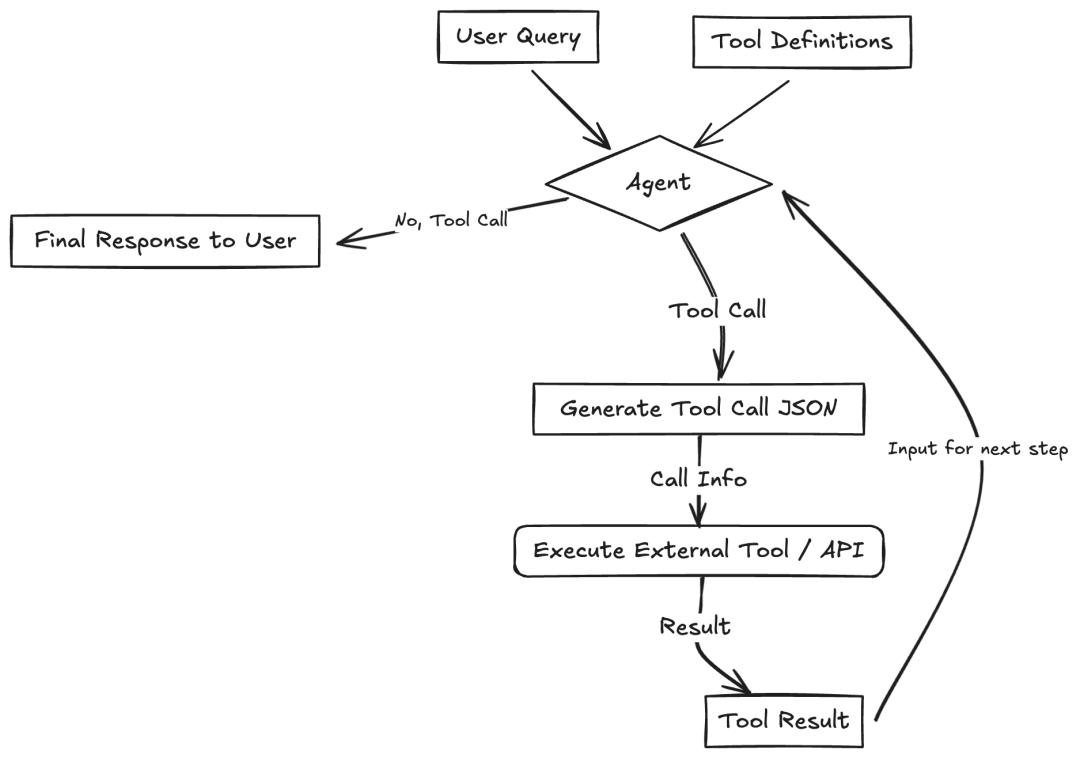
1、使用场景
- 用日历 API 来预约会议。
- 通过金融 API 获取实时股票价格。
- 在向量数据库中搜索相关文档(比如:RAG)。
- 控制智能家居设备。
- 执行代码片段。
2、落地实现代码
import osfrom google import genaifrom google.genai import types
# Configure the client (ensure GEMINI_API_KEY is set in your environment)client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
# Define the function declaration for the modelweather_function = { "name": "get_current_temperature", "description": "Gets the current temperature for a given location.", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city name, e.g. San Francisco", }, }, "required": ["location"], },}
# Placeholder function to simulate API calldef get_current_temperature(location: str) -> dict: return {"temperature": "15", "unit": "Celsius"}
# Create the config object as shown in the user's example# Use client.models.generate_content with model, contents, and configtools = types.Tool(function_declarations=[weather_function])contents = ["What's the temperature in London right now?"]response = client.models.generate_content( model='gemini-2.0-flash', contents=contents, config = types.GenerateContentConfig(tools=[tools]))
# Process the Response (Check for Function Call)response_part = response.candidates[0].content.parts[0]if response_part.function_call: function_call = response_part.function_call print(f"Function to call: {function_call.name}") print(f"Arguments: {dict(function_call.args)}")
# Execute the Function if function_call.name == "get_current_temperature": # Call the actual function api_result = get_current_temperature(*function_call.args) # Append function call and result of the function execution to contents follow_up_contents = [ types.Part(function_call=function_call), types.Part.from_function_response( name="get_current_temperature", response=api_result ) ] # Generate final response response_final = client.models.generate_content( model="gemini-2.0-flash", contents=contents + follow_up_contents, config=types.GenerateContentConfig(tools=[tools]) ) print(response_final.text) else: print(f"Error: Unknown function call requested: {function_call.name}")else: print("No function call found in the response.") print(response.text)
架构设计模式六、Planning Pattern (Orchestrator-Workers)
想象一下,有一个“总指挥官”(中央规划者 LLM),它会把一个复杂的任务拆分成一系列的小任务,然后把这些小任务分派给专门的“工人”(工作 Agent,通常会用到工具调用)去执行。这种模式主要是通过创建一个初始的“计划”来解决需要多步推理的复杂问题。这个计划是根据用户的输入动态生成的。然后,这些小任务会被分配给“工人”去执行,如果条件允许,它们可以同时进行。还有一个“协调者”或者“合成者” LLM,它会收集工人们的结果,看看整体目标是否达成。如果达成了,它就把最终结果整合起来;如果没达成,它可能会重新规划。这种方式可以减轻任何一个 LLM 调用的认知负担,提高推理质量,减少错误,并且能让工作流程动态适应。这和“路由”的关键区别在于,规划者生成的是一个多步骤的计划,而不是选择一个单一的下一步。
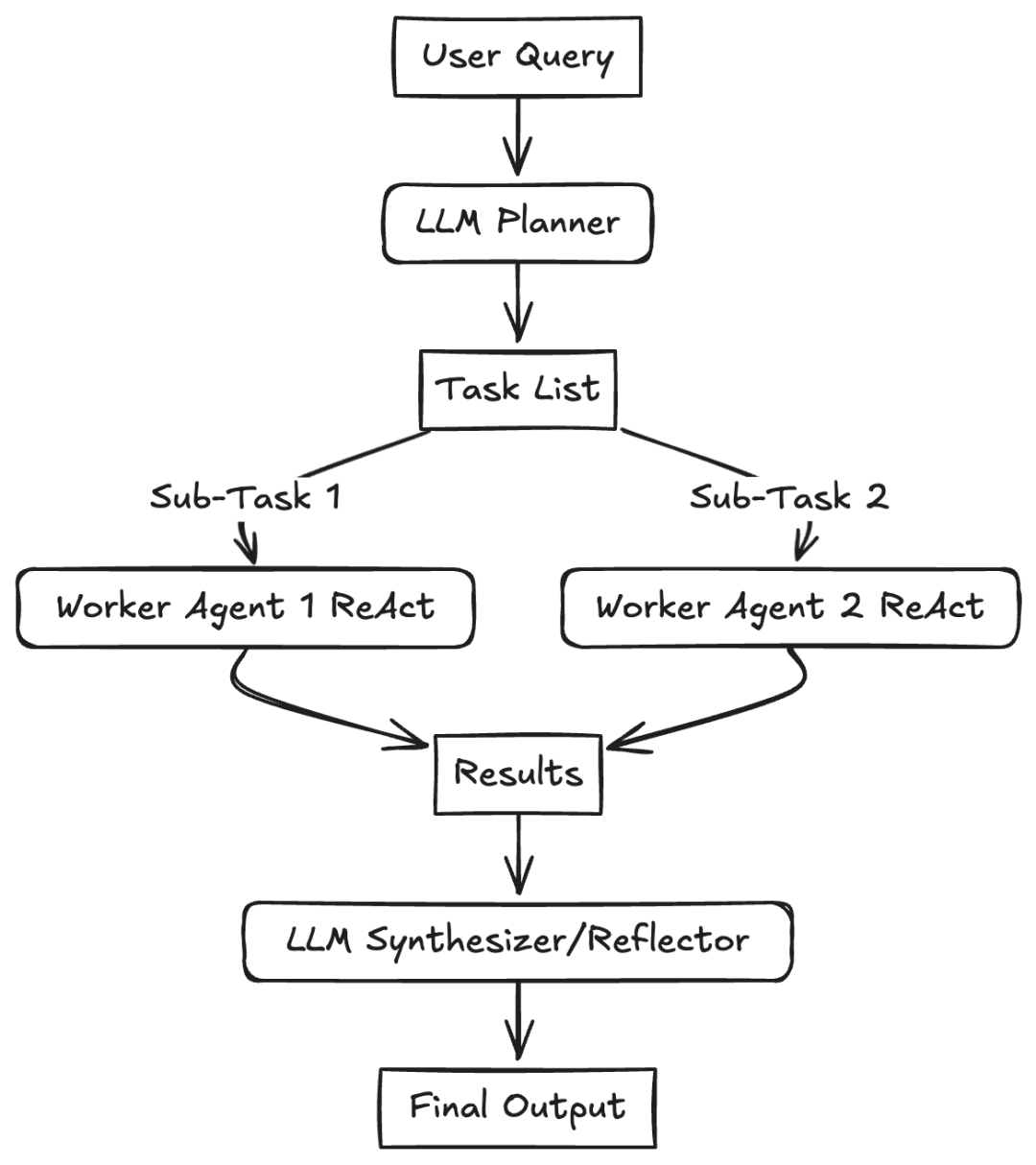
1、使用场景
- 复杂的软件开发任务:把“开发一个功能”拆分成规划、编码、测试和文档编写等子任务。
- 研究和报告生成:规划步骤,比如:文献搜索、数据提取、分析和报告撰写。
- 多模态任务:规划涉及图像生成、文本分析和数据整合的步骤。
- 执行复杂的用户请求,比如“计划一个为期3天的巴黎之旅,预订机票和预算内的酒店”。
2、落地实现代码
import osfrom google import genaifrom pydantic import BaseModel, Fieldfrom typing import List
# Configure the client (ensure GEMINI_API_KEY is set in your environment)client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
# Define the Plan Schemaclass Task(BaseModel): task_id: int description: str assigned_to: str = Field(description="Which worker type should handle this? E.g., Researcher, Writer, Coder")
class Plan(BaseModel): goal: str steps: List[Task]
# Step 1: Generate the Plan (Planner LLM)user_goal = "Write a short blog post about the benefits of AI agents."
prompt_planner = f"""Create a step-by-step plan to achieve the following goal. Assign each step to a hypothetical worker type (Researcher, Writer).
Goal: {user_goal}"""
print(f"Goal: {user_goal}")print("Generating plan...")
# Use a model capable of planning and structured outputresponse_plan = client.models.generate_content( model='gemini-2.5-pro-preview-03-25', contents=prompt_planner, config={ 'response_mime_type': 'application/json', 'response_schema': Plan, },)
# Step 2: Execute the Plan (Orchestrator/Workers - Omitted for brevity) for step in response_plan.parsed.steps: print(f"Step {step.task_id}: {step.description} (Assignee: {step.assigned_to})")
架构设计模式七、Multi-Agent Pattern
多个不同的“小助手”(Agent),每个都有特定的角色、个性或者专长,一起合作来实现一个共同的目标。这种模式使用的是自动或者半自动的智能体。每个智能体可能都有一个独特的角色(比如:项目经理、程序员、测试员、批评者),专门的知识,或者能用到特定的工具。它们会相互交流和合作,通常是由一个中央的“协调者”或者“管理者”代理(就像图里的项目经理)来协调,或者用接力逻辑,一个智能体把控制权交给另一个智能体,两种实现方式如下:
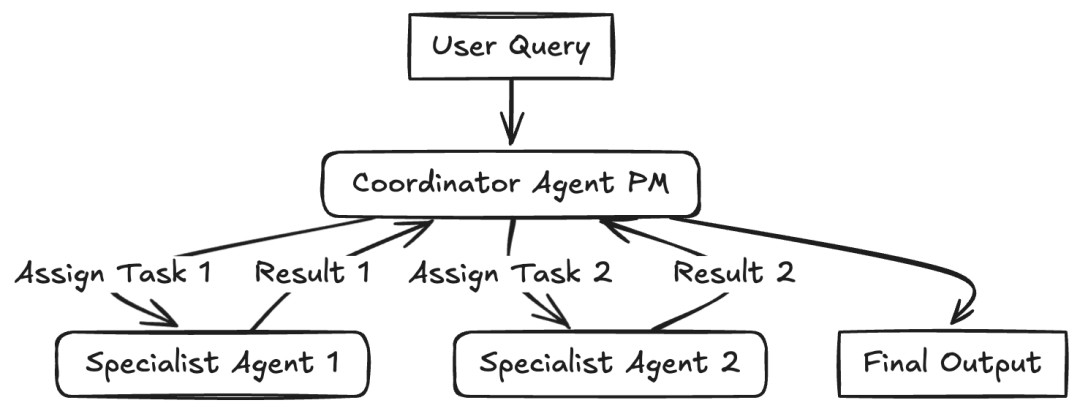
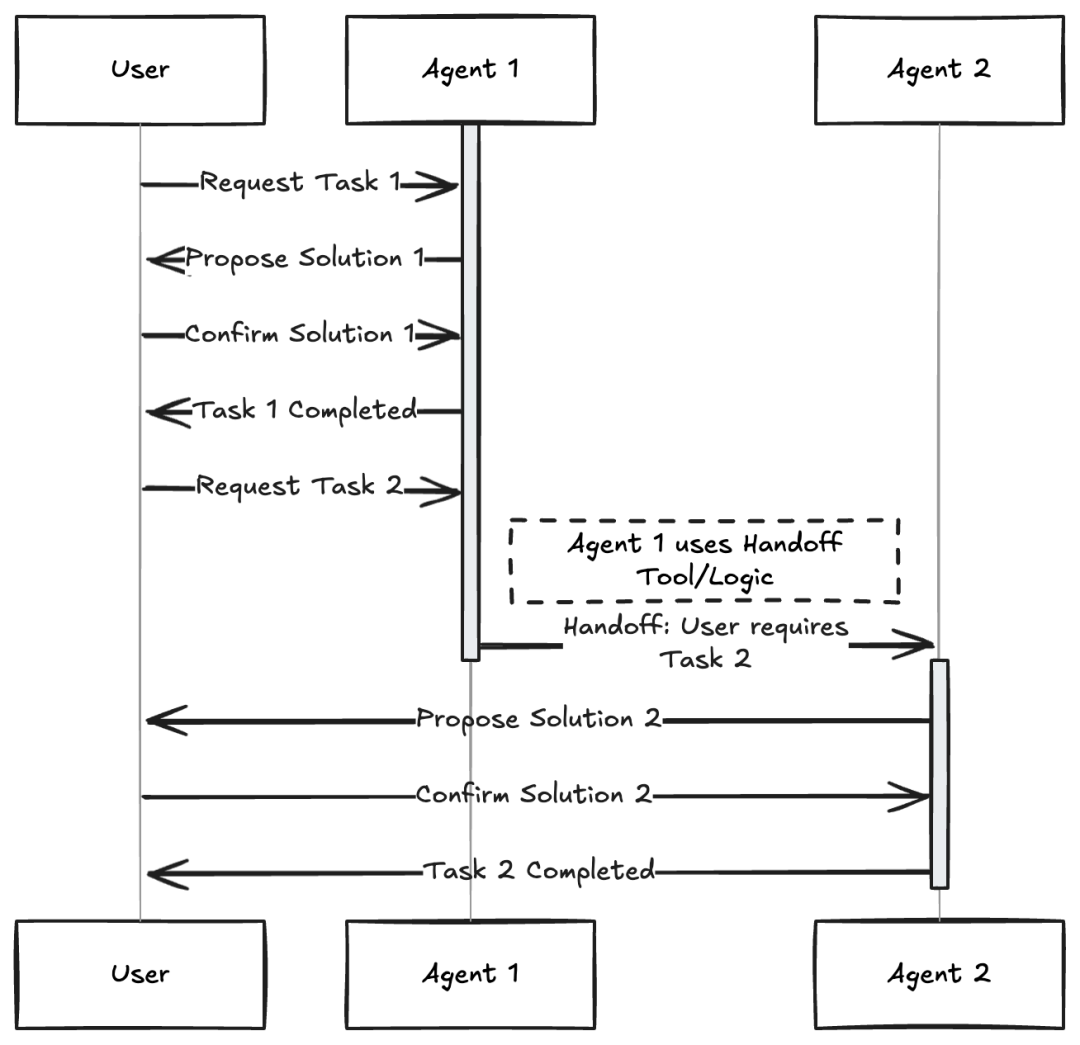
1、使用场景
- 用不同的 AI 角色模拟辩论或者头脑风暴会议。
- 复杂的软件创建,涉及规划、编程、测试和部署的智能体。
- 运行虚拟实验或者模拟,智能体代表不同的参与者。
- 协作写作或者内容创作过程。
2、落地实现代码
*注意*:下面的例子是一个简化的例子,展示如何使用多智能体模式,用接力逻辑和结构化输出。我建议可以看看 LangGraph Multi-Agent Swarm 或者Crew AI。
from google import genaifrom pydantic import BaseModel, Field
# Configure the client (ensure GEMINI_API_KEY is set in your environment)client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
# Define Structured Output Schemasclass Response(BaseModel): handoff: str = Field(default="", description="The name/role of the agent to hand off to. Available agents: 'Restaurant Agent', 'Hotel Agent'") message: str = Field(description="The response message to the user or context for the next agent")
# Agent Functiondef run_agent(agent_name: str, system_prompt: str, prompt: str) -> Response: response = client.models.generate_content( model='gemini-2.0-flash', contents=prompt, config = {'system_instruction': f'You are {agent_name}. {system_prompt}', 'response_mime_type': 'application/json', 'response_schema': Response} ) return response.parsed
# Define System Prompts for the agentshotel_system_prompt = "You are a Hotel Booking Agent. You ONLY handle hotel bookings. If the user asks about restaurants, flights, or anything else, respond with a short handoff message containing the original request and set the 'handoff' field to 'Restaurant Agent'. Otherwise, handle the hotel request and leave 'handoff' empty."restaurant_system_prompt = "You are a Restaurant Booking Agent. You handle restaurant recommendations and bookings based on the user's request provided in the prompt."
# Prompt to be about a restaurantinitial_prompt = "Can you book me a table at an Italian restaurant for 2 people tonight?"print(f"Initial User Request: {initial_prompt}")
# Run the first agent (Hotel Agent) to force handoff logicoutput = run_agent("Hotel Agent", hotel_system_prompt, initial_prompt)
# simulate a user interaction to change the prompt and handoffif output.handoff == "Restaurant Agent": print("Handoff Triggered: Hotel to Restaurant") output = run_agent("Restaurant Agent", restaurant_system_prompt, initial_prompt)elif output.handoff == "Hotel Agent": print("Handoff Triggered: Restaurant to Hotel") output = run_agent("Hotel Agent", hotel_system_prompt, initial_prompt)
print(output.message)
总之,这些模式可不是死板的规则,而是灵活的积木块。在现实世界里的智能体系统,常常会把多种模式的元素组合起来用。比如,一个做规划的智能体可能会用到工具调用,而它的“工人”们可能会用到自我评估。一个有多智能体的系统,可能会在内部用路由来分配任务。
对于任何大语言模型的应用,特别是复杂的智能体系统,成功的关键是要靠实际测试来看效果。得先定好衡量标准,然后去测量性能,找出哪里卡住了或者哪里出错了,接着再改进设计。别把事情搞得过于复杂。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 19
19 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)