【论文解读】Agent RL Scaling Law:自发掌握工具以解决数学问题
这篇论文完成了一次扎实的探索。它清晰地证明了,LLM 智能体可以通过纯粹的结果导向强化学习,自发地掌握复杂工具的使用,并且这个学习过程遵循可预测的缩放法则。它最大的贡献在于,将“智能体学习使用工具”这个话题从“工程调优”的层面,提升到了一个更接近“科学规律”探索的层面。通过展示工具使用频率、响应长度和任务准确率之间可量化的关系,为我们理解和预测未来更强大智能体的能力涌现提供了坚实的基础。
1st authro
- Xinji Mai [Fudan University]
- Haotian Xu [Xiaohongshu]
code: yyht/openrlhf_async_pipline
5. 总结 (结果先行)
这篇论文完成了一次扎实的探索。它清晰地证明了,LLM 智能体可以通过纯粹的结果导向强化学习,自发地掌握复杂工具的使用,并且这个学习过程遵循可预测的缩放法则。
它最大的贡献在于,将“智能体学习使用工具”这个话题从“工程调优”的层面,提升到了一个更接近“科学规律”探索的层面。通过展示工具使用频率、响应长度和任务准确率之间可量化的关系,为我们理解和预测未来更强大智能体的能力涌现提供了坚实的基础。
未来展望:
- 探索法则的精确数学形式: 论文展示了定性的缩放关系。未来的工作可以尝试拟合出其精确的数学函数形式,类似于 Chinchilla scaling laws,这将使预测更加精准。
- 解除交互限制: 当前实验中仍存在最大调用次数( N m a x N_{max} Nmax)的限制。移除这一限制,在需要进行长时序、多轮工具交互的更复杂任务(如软件工程)中,智能体会演化出何种策略,是一个值得探索的方向。
- 从单一工具到多工具协调: 当前环境只涉及一种工具(代码解释器)。当环境中存在多种工具(如代码、搜索、计算器)时,智能体如何学习选择和组合工具,将是下一个重要的挑战。

1. 思想
这篇论文的核心是探索一个非常根本的问题:我们能否让一个“空白”的大语言模型(Base LLM),在没有任何明确指导或模仿学习的情况下,仅仅通过反复试错和结果好坏的反馈,自发地学会使用像代码解释器这样的外部工具来解决复杂的数学问题。
-
大问题:
- 目前主流的工具使用方法要么依赖于大量的监督微调(SFT) ,即“手把手”教模型如何使用工具;要么依赖于精巧的提示工程(Prompt Engineering) 来强制模型在特定模式下调用工具。
- 这些方法限制了模型的自主探索能力,我们能否找到一种更“第一性原理”的方法,让智能体(Agent)从零开始,通过强化学习(RL) 自主发现工具的价值并掌握使用时机?
-
小问题:
- 当智能体通过 RL 学习使用工具时,其学习过程是否存在可预测的规律(Scaling Law)?例如,训练时间越长,它使用工具的频率、解决问题的能力是否会相应地、可预见地提升?
- 这种自发学会的工具使用方式,与人类精心设计的 SFT 或 Prompt 方法相比,效果如何?能否超越它们?
- 智能体最终会学会什么样的工具使用策略?是频繁地进行简单调用,还是少次但精准地进行复杂调用?
-
核心思想:
- 零样本工具集成推理(ZeroTIR): 这是作者提出的核心方法。从一个通用的基础模型(Base LLM)出发,不提供任何关于如何使用工具的标注数据。训练过程完全依赖于结果导向的强化学习(Outcome-based RL)——只根据最终答案的正确与否给予奖励(reward),而不关心中间过程。
- 验证“智能体强化学习缩放法则”(Agent RL Scaling Law): 通过在 ZeroTIR 训练过程中系统性地追踪关键指标,证明学习过程是可预测的。他们发现,随着训练步数的增加,自发代码执行频率、回答的长度、以及最终任务的准确率都呈现出强正相关性。这为智能体能力的涌现提供了量化证据。
- 构建高效的训练与交互框架: 为了支撑这种需要大量探索的 RL 训练,作者设计了一个解耦的、异步的代码执行环境。这是一个工程上的贡献,它将代码执行服务与 RL 训练主进程分离,大幅提升了训练的稳定性和效率。
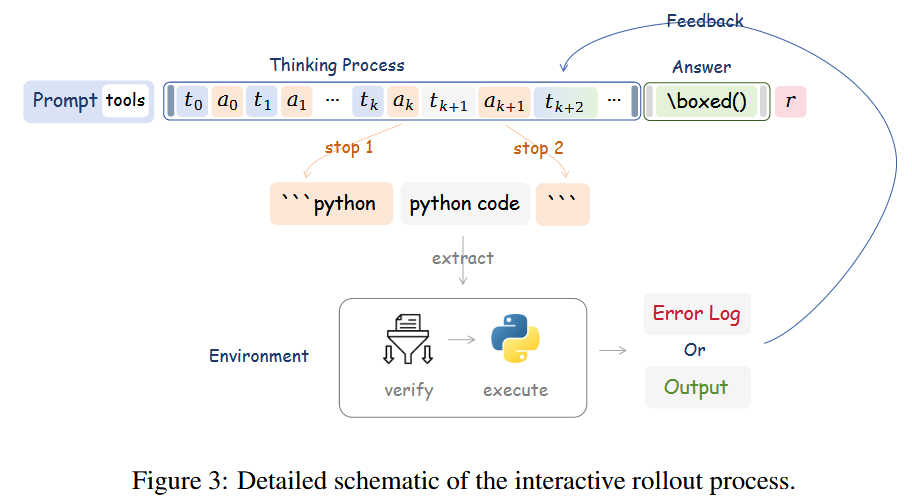
2. 方法
作者将 LLM 智能体的训练构建为一个标准的强化学习问题,并采用策略梯度算法(Policy Gradient)进行优化,核心是让智能体在与环境的交互中最大化期望奖励。
-
RL 范式:带 KL 散度惩罚的 PPO:
智能体的学习目标是最大化一个结合了任务奖励和策略稳定性的目标函数:
max θ E x ∼ D , y ∼ π θ ( ⋅ ∣ x ; E c o d e ) [ R ( x , y ) ] − β D K L [ π θ ( ⋅ ∣ x ; E c o d e ) ∣ ∣ π r e f ( ⋅ ∣ x ; E c o d e ) ] \max_\theta \mathbb{E}_{x \sim D, y \sim \pi_\theta(\cdot|x; \mathcal{E}_{code})} [R(x, y)] - \beta D_{KL}[\pi_\theta(\cdot|x; \mathcal{E}_{code}) || \pi_{ref}(\cdot|x; \mathcal{E}_{code})] θmaxEx∼D,y∼πθ(⋅∣x;Ecode)[R(x,y)]−βDKL[πθ(⋅∣x;Ecode)∣∣πref(⋅∣x;Ecode)]- π θ \pi_\theta πθ: 当前正在训练的智能体策略网络(即 LLM),参数为 θ \theta θ。
- x x x: 输入的问题。
- y y y: 智能体生成的完整轨迹,包括思考过程和与代码环境的交互。
- E c o d e \mathcal{E}_{code} Ecode: 代码执行环境。
- R ( x , y ) R(x, y) R(x,y): 结果导向的奖励函数。如果最终答案正确,则奖励为 +1,否则为 0。这是整个学习过程唯一的外部反馈信号。
- π r e f \pi_{ref} πref: 一个固定的参考模型(通常是训练前的基础模型),用于稳定训练。
- D K L [ ⋅ ∣ ∣ ⋅ ] D_{KL}[\cdot||\cdot] DKL[⋅∣∣⋅]: KL 散度,用于衡量当前策略 π θ \pi_\theta πθ 与参考策略 π r e f \pi_{ref} πref 的差异。
- β \beta β: KL 惩罚项的系数,控制着策略更新的步长,防止模型偏离原始模型太远而导致能力崩溃。
-
互动机制:
智能体与代码环境的互动是一个基于特殊标记(stop tokens)的有限状态机。- 模型开始生成文本(思考过程)。
- 当模型生成一个特殊的代码起始标记(如
```python)时,生成过程暂停。 - 模型切换到“代码生成”模式,继续生成,直到遇到代码结束标记(如 ` ````)。
- 系统提取这段代码,并发送到外部的代码执行环境中运行。
- 代码执行的输出结果(Output)或错误信息(Error Log)被格式化后,注入到当前的生成上下文中。
- 模型继续从注入结果后的位置开始生成文本,这个循环可以重复进行,直到模型输出最终答案。

-
训练稳定性与效率优化:
- 经验回放池过滤(Replay Buffer Filtering): 为了让学习更高效,作者采用了一个巧妙的启发式策略。他们过滤掉那些模型轻易答对(例如,8个样本中对8次)或完全无法解决(例如,8个样本中对0次)的训练数据,专注于那些处于“学习区”的、最具信息量的样本(例如,8个样本中对2-6次)。
- 价值函数掩码(Value Function Masking): 在使用 PPO 这类 Actor-Critic 算法时,价值函数 V ϕ ( s t ) V_\phi(s_t) Vϕ(st) 用于评估状态的优劣。一个关键细节是,价值函数只在模型自己生成的 token 上进行训练,而代码环境返回的 token 会被“掩码”(mask out),因为这些 token 不是模型策略的产物。
- 异步训练架构(Asynchronous Architecture): 将代码执行环境部署为独立的网络服务。RL 训练器(Trainer)和多个数据采样器(Rollout Actors)可以并行和异步地工作,极大地加速了数据收集和模型更新的循环,使得大规模实验成为可能。
3. 优势
与同类工作相比,这篇论文的独特之处在于其视角和方法的纯粹性。
- 自发涌现 vs. 监督学习: 与依赖 SFT 的方法(如 Toolformer 或多数现有的 Code LLMs)不同,ZeroTIR 不预设任何工具使用范式。模型必须自主发现“在数学问题中,写一段 Python 代码来计算比自己瞎想要可靠得多”这一事实。
- 基础模型 vs. 微调模型: 与同期的优秀工作 TORL 相比,一个关键区别是 ZeroTIR 坚持从通用的基础模型开始训练,而不是从一个已经经过数学领域微调的模型开始。这使得他们能够更清晰地观察到“从无到有”的能力习得全过程,而非仅仅是在现有能力上的增强。
- 量化法则 vs. 单点性能: 论文的核心贡献不是简单地报告一个更高的分数,而是揭示了“智能体 RL 缩放法则”这一现象。它提供了一个可复现的框架和一组可量化的关系,为未来研究智能体能力如何随计算投入而演进提供了重要的基准。
4. 实验
- 实验设置:
- 模型: Qwen2.5 7B 和 32B 基础模型。
- 框架: OpenRLHF 和 Open-Reasoner-Zero。
- 算法: PPO 和 Reinforce++。
- 基准: 在 AIME、MATH500 等高难度数学竞赛数据集上进行评测。
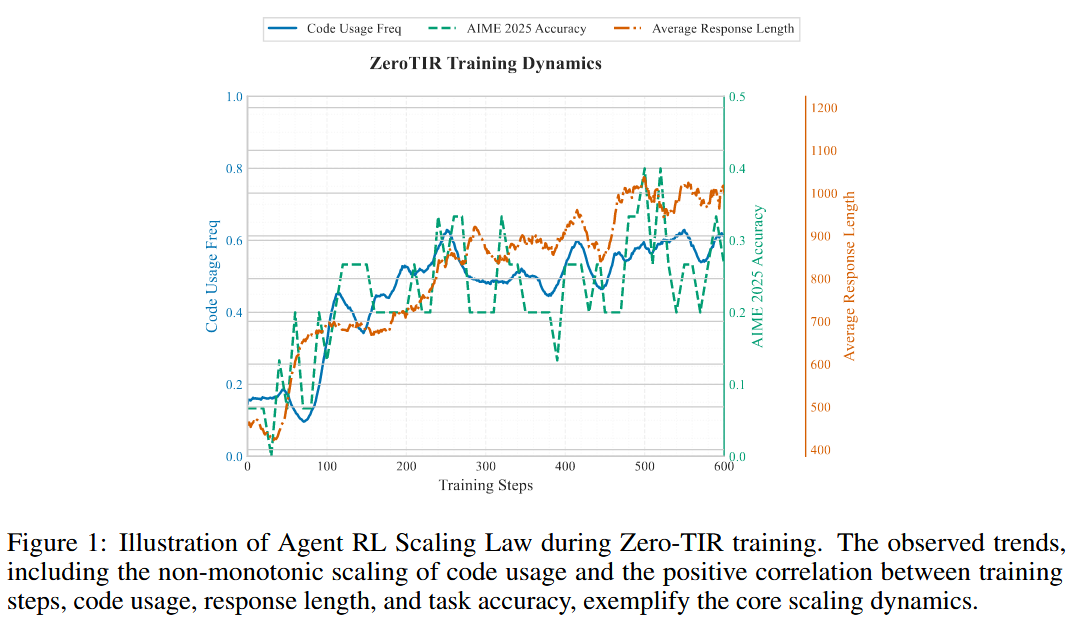
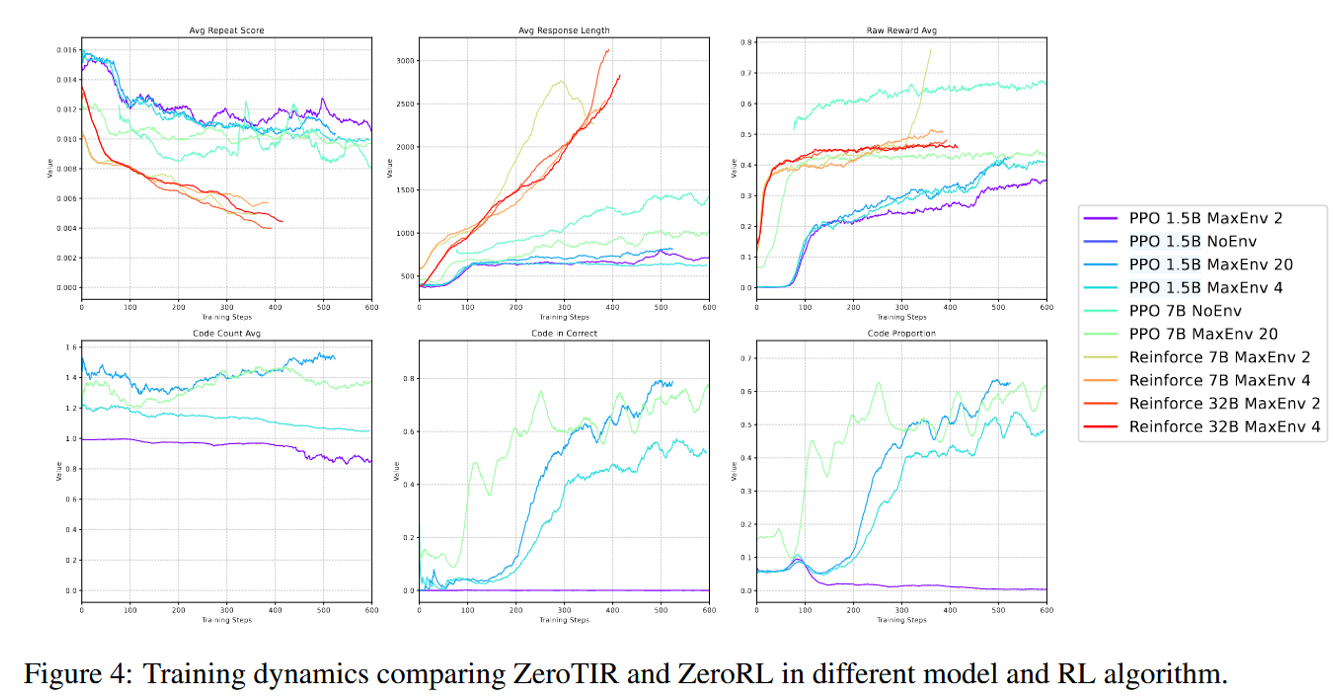
Figure 4 图有点小, 下面表格是上图的标题, 按位置对应:
Avg Repeat Score Avg Response Length Raw Reward Avg Code Count Avg Code in Correct Code Propotion X 是 Training Steps,Y 是 Value。
- 实验结论:
- 性能的显著超越: 在多个数学基准上,7B 参数的 ZTRL 模型(平均分 52.3%)不仅显著优于没有工具的 ZeroRL 基线(39.1%),甚至超越了使用 Prompt 引导的、更专业的 Qwen2.5-Math-Instruct 模型(41.6%)。这证明了自发学习策略的有效性。
- “缩放法则”的清晰证据: 训练曲线图(Figure 1, Figure 4)是论文的亮点。
- 代码使用率:呈现出一个“先下降后急剧上升”的模式。这可能意味着模型在初期尝试不使用工具解决问题,失败后才逐渐认识到工具的价值,并迅速采纳。
- 准确率与代码使用正相关:正确答案中使用代码的比例(Code in Correct)与整体奖励(Raw Reward Avg)同步上升,证明模型学会的是有效的工具使用,而非无效的模仿。
- 收敛到“少而精”的工具使用模式: 尽管实验中允许模型进行多达20次工具调用( N m a x = 20 N_{max}=20 Nmax=20),但分析发现,超过 90% 的成功解题路径只包含 1 次代码执行。这表明模型并没有学会“啰嗦”地与环境交互,而是收敛到了一种 “一击制胜”的高效策略:将复杂计算部分精准地外包给代码解释器。
- 算法与模型规模的影响: 实验表明,Reinforce++ 算法比 PPO 在此任务上收敛更快。同时,模型规模(32B vs 7B)和交互预算( N m a x N_{max} Nmax)的增加,都能带来稳定的性能提升,进一步验证了缩放法则的存在。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 31
31 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)