自然语言基础——RNN及其变体
RNN(Recurrent Neural Network), 中文称作循环神经网络, 它一般以序列数据为输入, 通过网络内部的结构设计有效捕捉序列之间的关系特征, 一般也是以序列形式进行输出.2.1 建模序列数据的时间依赖关系 2.2 处理变长输入输出2.3实现序列到序列的学习 按照输入和输出的结构进行分类:按照RNN的内部构造进行分类:1. N vs N - RNN: 2. N vs 1 - R
一.RNN模型简介
1.什么是RNN模型
-
RNN(Recurrent Neural Network), 中文称作循环神经网络, 它一般以序列数据为输入, 通过网络内部的结构设计有效捕捉序列之间的关系特征, 一般也是以序列形式进行输出.
- 一般神经网络
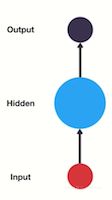
- RNN单层网络结构:
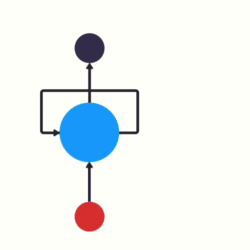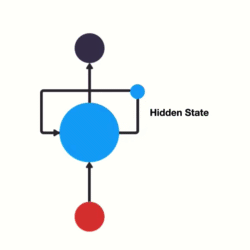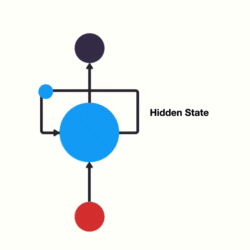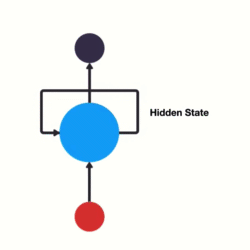
- 以时间步对RNN进行展开后的单层网络结构:

- RNN的循环机制使模型隐层上一时间步产生的结果, 能够作为当下时间步输入的一部分(当下时间步的输入除了正常的输入外还包括上一步的隐层输出)对当下时间步的输出产生影响.
2.RNN模型的作用
2.1 建模序列数据的时间依赖关系
RNN 可以记住前面时刻的信息,并将其用于当前时刻的计算。
这使得它非常适合处理具有前后依赖关系的数据,如语言、语音、股票价格等。
示例:在句子 “我今天吃了一个苹果” 中,理解“苹果”是否指水果还是公司,需要结合前面的上下文。
2.2 处理变长输入输出
与 CNN 不同,RNN 能接受和输出任意长度的序列。
这让它适用于如:
输入不定长文本 → 输出情感分类(Many-to-One)
输入一句话 → 输出翻译后的整句(Many-to-Many)
2.3 实现序列到序列的学习
RNN 可以作为编码器(Encoder)将输入序列压缩为一个上下文向量(context vector),再由解码器(Decoder)生成目标序列。
广泛应用于机器翻译、文本摘要、对话系统等任务。
3.RNN模型的分类
-
按照输入和输出的结构进行分类:
- N vs N - RNN
- N vs 1 - RNN
- 1 vs N - RNN
- N vs M - RNN
-
按照RNN的内部构造进行分类:
- 传统RNN
- LSTM
- Bi-LSTM
- GRU
- Bi-GRU
1. N vs N - RNN:
- 它是RNN最基础的结构形式, 最大的特点就是: 输入和输出序列是等长的. 由于这个限制的存在, 使其适用范围比较小, 可用于生成等长度的合辙诗句.
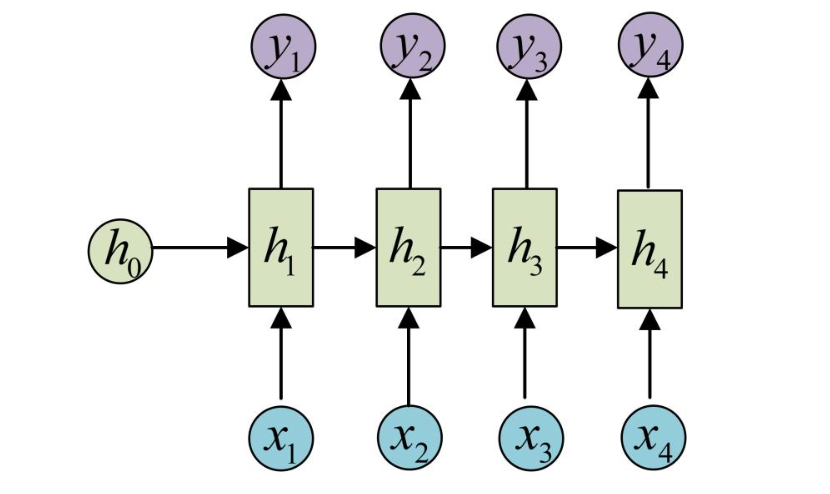
2. N vs 1 - RNN
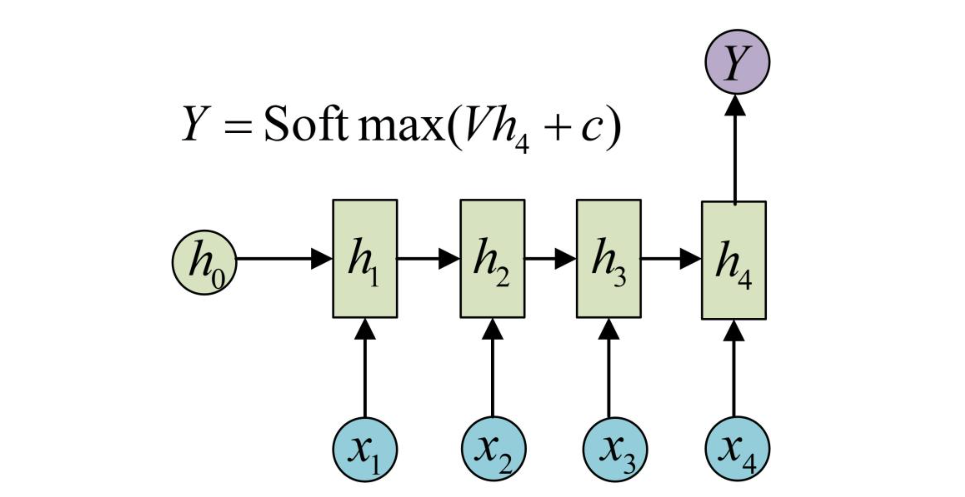
3. 1 vs N - RNN:
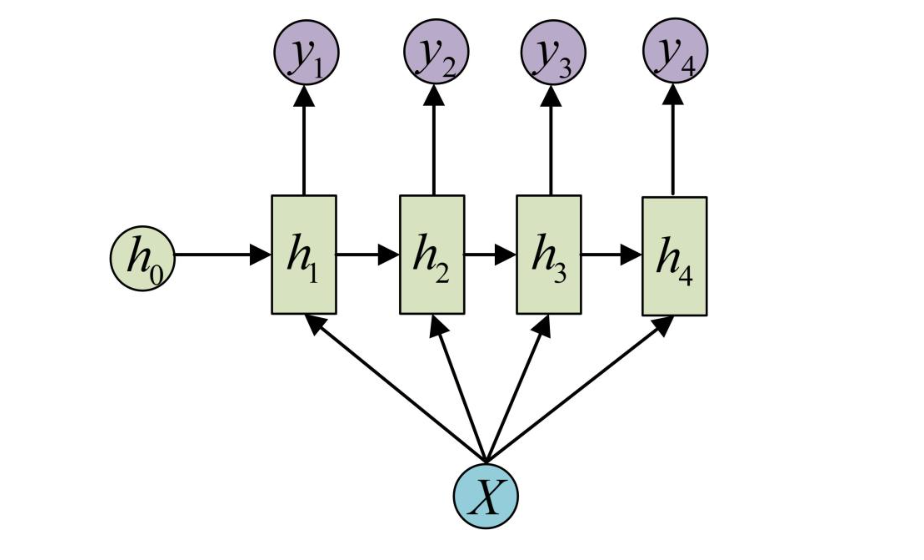
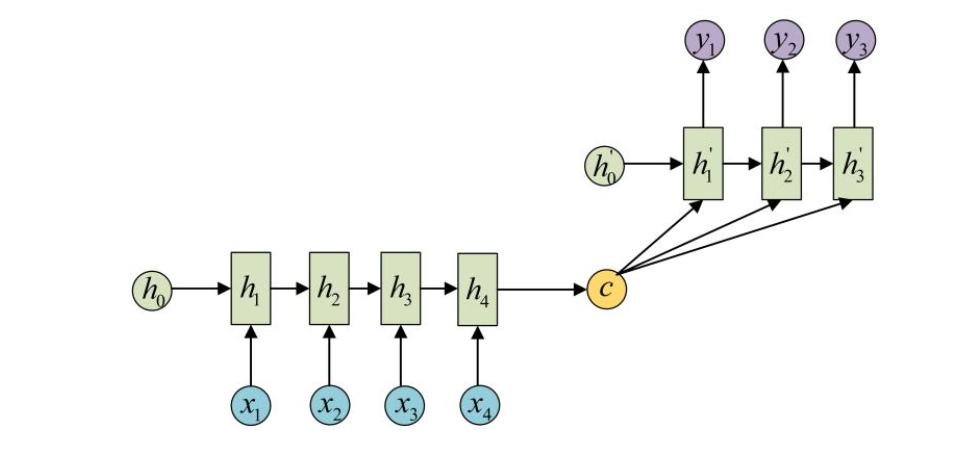
4. N vs M - RNN
这是一种不限输入输出长度的RNN结构, 它由编码器和解码器两部分组成, 两者的内部结构都是某类RNN, 它也被称为seq2seq架构. 输入数据首先通过编码器, 最终输出一个隐含变量c, 之后最常用的做法是使用这个隐含变量c作用在解码器进行解码的每一步上, 以保证输入信息被有效利用.
二.传统的RNN模型
1.传统RNN的内部图
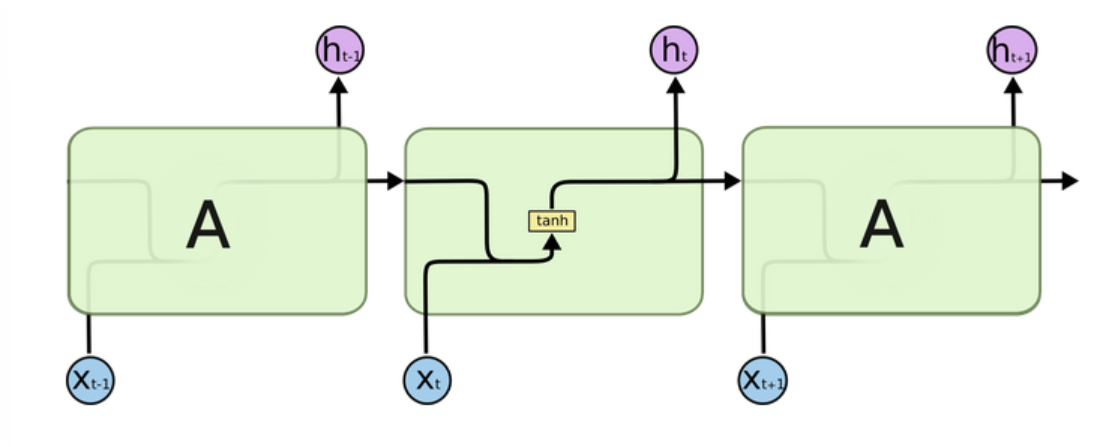
图解:
以中间的部分进行说明:x表示输入,h表示输出,x和h右下角的t代表时间步,t表示当前的时间步,t-1表示上一轮的时间步。
上一步的输出t和当前时间步的输入进行拼接(准确来说是在内部进行加权求和的方式进行结合),然后通过tanh激活函数得到当前的输出h和下一个隐藏层的输入。
内部的公式:
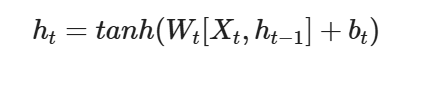
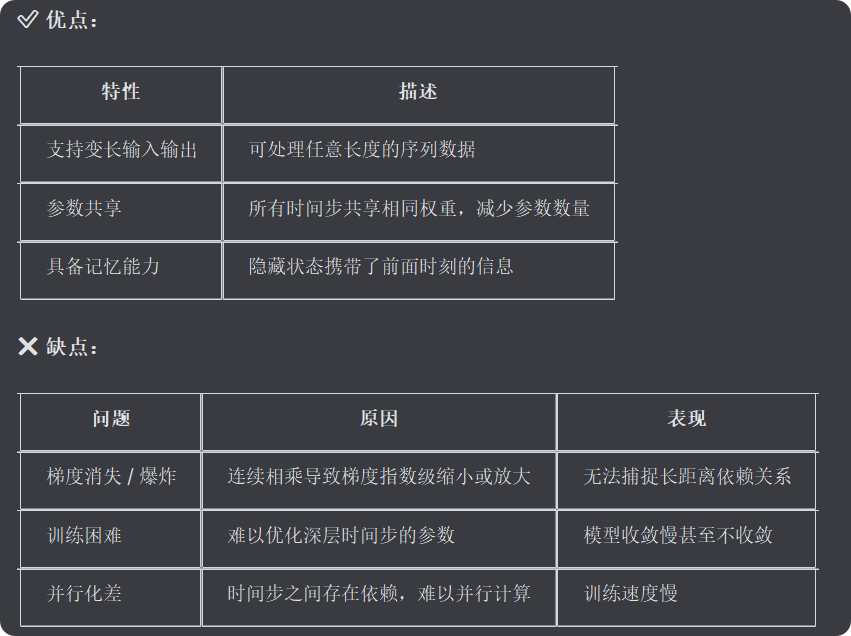
2.传统RNN的优缺点
3. 举例说明
RNN的参数如下图

import torch
import torch.nn as nn
"""
需求:基于torch.nn库,实现一个RNN模型,并进行前向传播
思路步骤:
1. 定义一个RNN模型,传入
第一个参数:input_size(输入张量x的维度)
第二个参数:hidden_size(隐藏层的维度, 隐藏层的神经元个数)
第三个参数:num_layer(隐藏层的数量)
2. 构建输入数据X
第一个参数:batch_size(批次的样本数量)
第二个参数:sequence_length(输入的序列长度)或者说是多少时间步
第三个参数:input_size(输入张量的维度)
3. 初始化隐藏层数据h0
第一个参数:num_layer * num_directions(层数*网络方向)
第二个参数:batch_size(批次的样本数)
第三个参数:hidden_size(隐藏层的维度, 隐藏层神经元的个数)
4. 进行前向传播
rnn(X,h0)
5. 打印输出结果和hn(最后一个时间步的隐藏层数据)
"""
def dm01_rnn():
rnn = nn.RNN(input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True) # 如果为 True,则输入和输出的形状为 (batch, seq, feature),否则为 (seq, batch, feature)
X = torch.randn(batch_size, sequence_length, input_size) # torch.randn(5, 10, 8)
print(X.shape)
h0 = torch.randn(num_layers * num_directions, batch_size, hidden_size) # torch.randn(1, 5, 6)
print(h0.ndim)
print(h0.shape)
# todo 进行前向传播,
# TODO 这里需要注意, 前向传播的结果有两个
# TODO out: 所有时间步hn的拼接
# TODO hn: 最后一个时间步的隐层输出
output, hn = rnn(X, h0)
print(output.shape)
print(hn.shape)
if __name__ == '__main__':
input_size = 8 # 输入张量的维度
hidden_size = 6 # 隐藏层的维度, 隐藏层神经元的个数
num_layers = 1 # 隐藏层的数量
batch_size = 5 # 批次的样本数量
sequence_length = 10 # 输入的序列长度
num_directions = 1 # 网络方向
dm01_rnn()
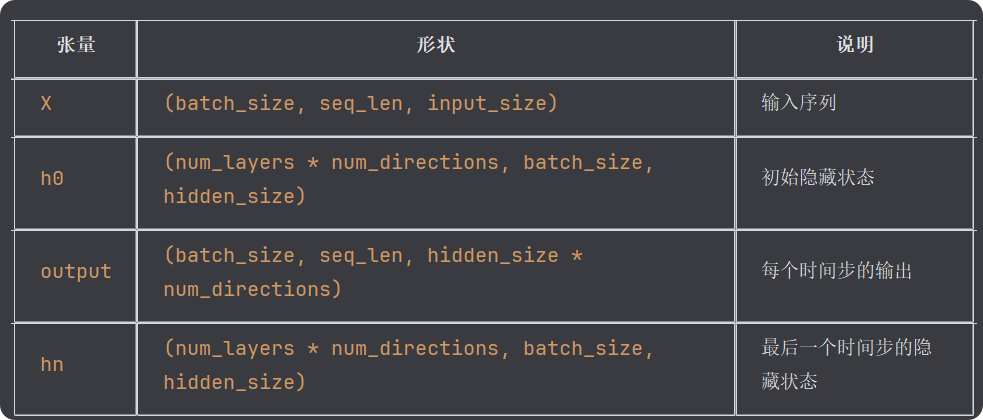
首先初始化rnn中nn.RNN中有一个默认的隐藏参数bidirectional=false,这个参数决定了是否开启双向通道,不开启则num_directions只能等于1,因为rnn的模型结构在初始化的时候就已经确定了,只能接受形状为(num_layers*num_directions, batch_size,hidden_size)的张量,如果bidirectional=Ture,则num_directions只能为2。
输入张量X的形状:(batch_size, seq_len, input_size)
含义:每个 batch 中有 sequence_length 个时间步,每个时间步输入一个长度为 input_size 的向量。
初始化隐藏层的形状:(num_layers * num_directions, batch_size, hidden_size)
含义:每一层每一个方向都需要一个初始隐藏状态;
这里是 1 层 × 1 方向 = 1 个隐藏状态;
每个隐藏状态的形状是 (batch_size, hidden_size);
所以 h0 是一个三维张量。
输出张量 output 的形状:(batch_size, sequence_length, hidden_size * num_directions)
含义:output[i, j] 表示第 i 个样本在第 j 个时间步的输出(即最终的隐藏状态);
因为是单向 RNN,所以每个时间步输出维度是 hidden_size × 1 = 6;
如果是双向 RNN,则每个时间步输出维度是 hidden_size × 2。
隐藏状态 hn 的形状:(num_layers * num_directions, batch_size, hidden_size)
含义:hn 是最后一个时间步的隐藏状态;
它和 h0 的形状完全一致;
你可以把它作为下一层 RNN 的初始隐藏状态使用。
总结:输入和输出的关系
下面代码有助理解RNN的运行,
import torch.nn as nn
import torch
class RNNLayer(nn.Module):
"""
自定义的单层 RNN 模块。
每个时间步使用一个全连接层将输入 x 和上一时刻隐藏状态 h 拼接后进行线性变换,
再通过 tanh 激活函数得到当前时刻的隐藏状态 hn。
"""
def __init__(self, input_size, hidden_size):
"""
初始化 RNN 层。
参数:
- input_size: 输入特征维度
- hidden_size: 隐藏层维度(输出维度)
"""
super(RNNLayer, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# 定义一个线性层,输入是 [x_t + h_{t-1}],输出是 h_t
self.W = nn.Linear(input_size + hidden_size, hidden_size)
# 定义 tanh 激活函数
self.tanh = nn.Tanh()
def forward(self, x, h):
"""
前向传播函数。
参数:
- x: 当前时间步的输入,shape=(batch_size, input_size)
- h: 上一时间步的隐藏状态,shape=(batch_size, hidden_size)
返回:
- hn: 当前时间步的隐藏状态,shape=(batch_size, hidden_size)
"""
# 将当前输入 x 和上一隐藏状态 h 在特征维度拼接
concat = torch.concat((x, h), dim=1) # shape=(batch_size, input_size + hidden_size)
# 经过线性层处理
result_no_tanh = self.W(concat) # shape=(batch_size, hidden_size)
# 应用 tanh 激活函数
hn = self.tanh(result_no_tanh)
return hn
class RNN(nn.Module):
"""
自定义的完整 RNN 网络,支持多时间步序列输入。
使用循环对每个时间步调用 RNNLayer 进行计算。
"""
def __init__(self, input_size, hidden_size):
"""
初始化 RNN 网络。
参数:
- input_size: 输入特征维度
- hidden_size: 隐藏层维度
"""
super(RNN, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# 构建一个 RNN 层(目前只有一层,便于教学演示)
self.layer = RNNLayer(input_size, hidden_size)
def forward(self, X, ht=None):
"""
前向传播函数,处理整个序列输入。
参数:
- X: 输入序列张量,shape=(batch_size, seq_len, input_size)
- ht: 初始隐藏状态,shape=(batch_size, hidden_size),可选
返回:
- out: 所有时间步的输出隐藏状态,shape=(batch_size, seq_len, hidden_size)
- ht: 最后一个时间步的隐藏状态,shape=(batch_size, hidden_size)
"""
batch_size, seq_len, input_size = X.shape
# 如果没有传入初始隐藏状态,则初始化为全零
if ht is None:
ht = torch.zeros(batch_size, self.hidden_size)
ht_list = []
# 循环处理每一个时间步
for t in range(seq_len):
x = X[:, t, :] # 取出第 t 个时间步的输入,shape=(batch_size, input_size)
# 调用 RNN 层计算当前时间步的隐藏状态
ht = self.layer(x, ht)
# 将当前时间步的隐藏状态加入列表
ht_list.append(ht.unsqueeze(1)) # unsqueeze 添加 seq_len 维度,shape=(batch_size, 1, hidden_size)
# 将所有时间步的隐藏状态拼接成一个完整的输出张量
out = torch.cat(ht_list, dim=1) # shape=(batch_size, seq_len, hidden_size)
return out, ht # 返回所有时间步的输出和最后一个时间步的隐藏状态
if __name__ == '__main__':
input_size = 8
hidden_size = 6
batch_size = 5
sequence_length = 20
# 1. 实例化RNN
rnn = RNN(input_size=input_size, hidden_size=hidden_size)
# 2. 构造X
X = torch.randn(batch_size, sequence_length, input_size)
# 3. 初始化h0
h0 = torch.randn(batch_size, hidden_size)
# 4. 前向传播
out, hn = rnn(X, h0)
print(out.shape)
print(hn.shape)三. LSTM模型
简介:LSTM(Long Short-Term Memory)也称长短时记忆结构, 它是传统RNN的变体, 与经典RNN相比能够有效捕捉长序列之间的语义关联, 缓解梯度消失或爆炸现象. 同时LSTM的结构更复杂, 它的核心结构可以分为四个部分去解析:遗忘门、输入门、细胞状态、输出门。
LSTM的结构图如下
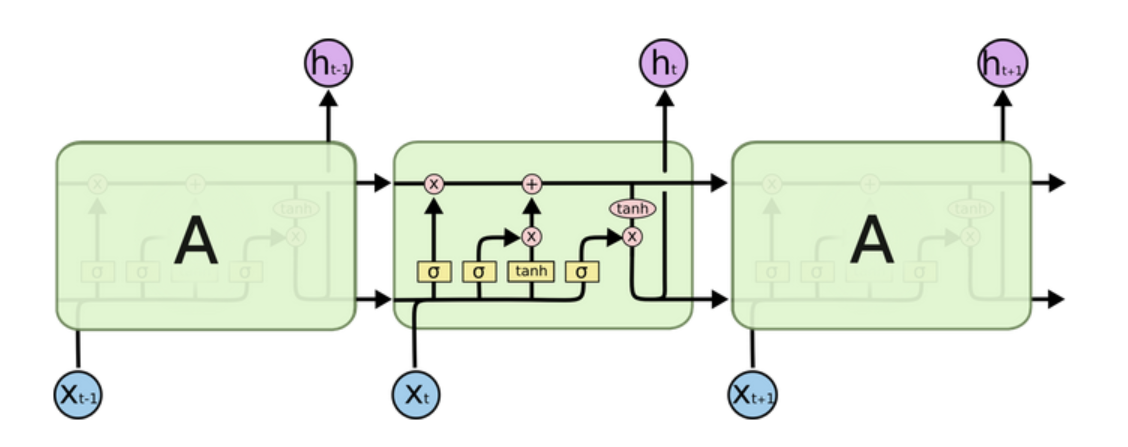
1. 细胞状态
1.1 什么是细胞状态
细胞状态是LSTM中用于长期记忆信息的通道。
它不会像隐藏状态那样每一步都被完全重写;
而是通过门控机制选择性地更新或保留信息;
这使得 LSTM 可以选择性地记住重要信息、遗忘无关信息。
1.2 细胞状态的更新
细胞状态的更新由三个门共同控制
1.遗忘门:决定哪些信息需要从细胞状态中遗忘
2.输入门:决定当前输入中有多少新信息应该被加入到细胞状态中
3.更新细胞状态:由遗忘门和输出门共同决定,将旧信息与新信息融合,得到新的细胞状态
4.输出门:决定当前细胞状态有多少可以输出为隐藏状态
2.遗忘门
2.1 作用
遗忘门通过选择性丢弃细胞状态中的冗余信息,避免无关历史信息干扰当前决策。
2.2 控制机制
采用sigmoid激活函数,实现’软开关‘的效果
输出接近0:完全丢弃对于的信息(如过时的主语,噪声数据)
输出接近1:完整的保留关键信息(如句子主题)
2.3 计算过程

3. 输入门
3.1 作用
1. 控制哪些新信息应该被保存到细胞状态(cell state)中
3.2 计算过程

4. 输出门
4.1 作用
控制当前时刻的细胞状态信息中有多少可以传递到隐藏状态,也就是决定哪些信息可以被输出到下一层
4.2 输出门计算

5. BI-LSTM
Bi-LSTM即双向LSTM, 它没有改变LSTM本身任何的内部结构, 只是将LSTM应用两次且方向不同, 再将两次得到的LSTM结果进行拼接作为最终输出,
LSTM例子:lstm = nn.LSTM(input_size=5, hidden_size=6, num_layers=1)
# 输出形状: (seq_len, batch, hidden_size)BI-LSTM例子:bi_lstm = nn.LSTM(input_size=5, hidden_size=6, num_layers=1, bidirectional=True)
# 输出形状: (seq_len, batch, hidden_size * 2)
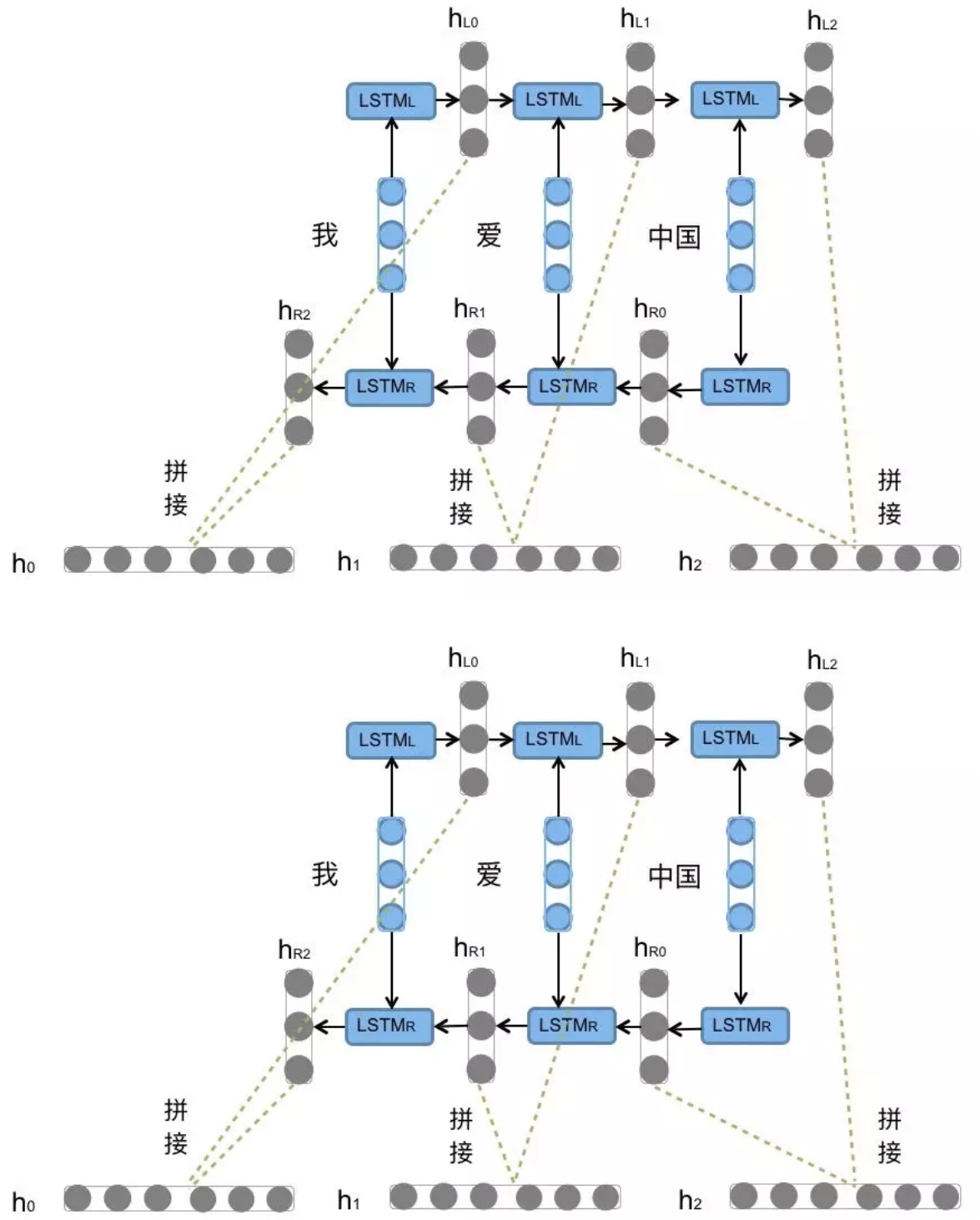
6 举例说明
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
"""
定义 LSTM 层:
nn.LSTM 是 PyTorch 中提供的 LSTM 模块。
参数说明:
1. input_size:输入张量的维度。这里表示每个时间步输入的特征维度为 5。
2. hidden_size:隐藏层的输出维度。LSTM 的每个时间步输出的隐藏状态维度为 6。
3. num_layers:LSTM 层的数量。这里是 1,表示单层 LSTM。
4. batch_first:是否将 batch_size 作为输入的第一个维度。默认为 False,
如果设置为 True,则输入数据的形状应为 (batch_size, sequence_length, input_size),
否则默认是 (sequence_length, batch_size, input_size)。
"""
lstm = nn.LSTM(input_size=5, hidden_size=6, num_layers=1)
"""
构建输入数据 input_x:
input_x 的形状为 (sequence_length, batch_size, input_size)。
根据上面的定义:
- sequence_length = 3(序列长度或时间步数)
- batch_size = 2(批次大小,即一次处理 2 个样本)
- input_size = 5(每个时间步输入的特征维度)
因此,input_x 的形状为 (3, 2, 5)。
"""
input_x = torch.randn(3, 2, 5)
"""
如果 batch_first=True,则输入的形状应为 (batch_size, sequence_length, input_size):
例如:
input_x = torch.randn(2, 3, 5)
"""
"""
初始化初始隐藏状态 h0 和细胞状态 c0:
h0 表示初始隐藏状态,c0 表示初始细胞状态。
它们的形状为 (num_layers * num_directions, batch_size, hidden_size):
- num_layers:LSTM 层的数量,这里是 1。
- num_directions:网络方向数量,默认为 1(单向 LSTM)。
- batch_size:批次大小,这里是 2。
- hidden_size:隐藏层的输出维度,这里是 6。
因此,h0 和 c0 的形状为 (1, 2, 6)。
"""
h0 = torch.randn(1, 2, 6) # 初始隐藏状态
c0 = torch.randn(1, 2, 6) # 初始细胞状态
"""
进行前向传播:
通过调用 lstm(input_x, (h0, c0)) 进行前向传播计算。
返回值:
1. out:所有时间步的隐藏状态拼接而成的张量。
形状为 (sequence_length, batch_size, hidden_size)。
这里 out 的形状为 (3, 2, 6)。
2. hn:最后一个时间步的隐藏状态。
形状为 (num_layers * num_directions, batch_size, hidden_size)。
这里 hn 的形状为 (1, 2, 6)。
3. cn:最后一个时间步的细胞状态。
形状与 hn 相同,这里是 (1, 2, 6)。
"""
out, (hn, cn) = lstm(input_x, (h0, c0))
"""
打印输出结果:
- output:所有时间步的隐藏状态。
- hidden:最后一个时间步的隐藏状态。
- cell:最后一个时间步的细胞状态。
"""
print('output-->', out.shape, '\n', out) # 输出所有时间步的隐藏状态
print('hidden-->', hn.shape, '\n', hn) # 输出最后一个时间步的隐藏状态
print('cell-->', cn.shape, '\n', cn) # 输出最后一个时间步的细胞状态
四.GRU介绍
简介:GRU(Gated Recurrent Unit)也称门控循环单元结构, 它也是传统RNN的变体, 同LSTM一样能够有效捕捉长序列之间的语义关联, 缓解梯度消失或爆炸现象. 同时它的结构和计算要比LSTM更简单, 它的核心结构可以分为两个部分去解析:更新门和重置门。
1.GRU结构分析
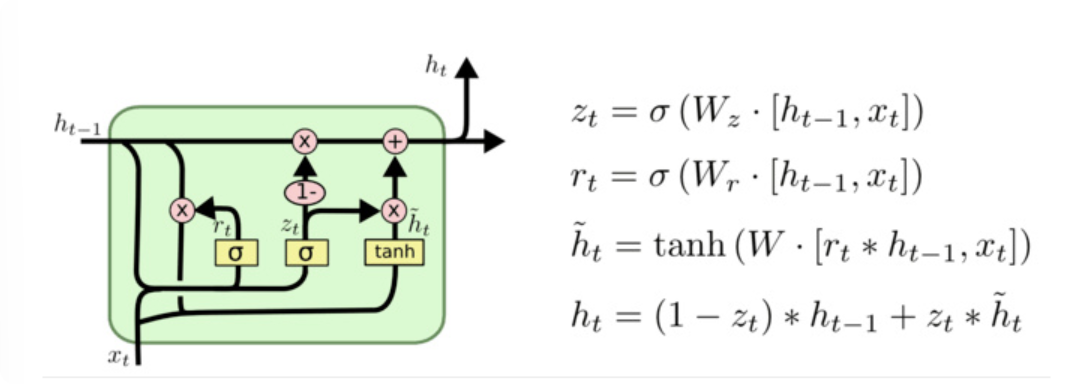
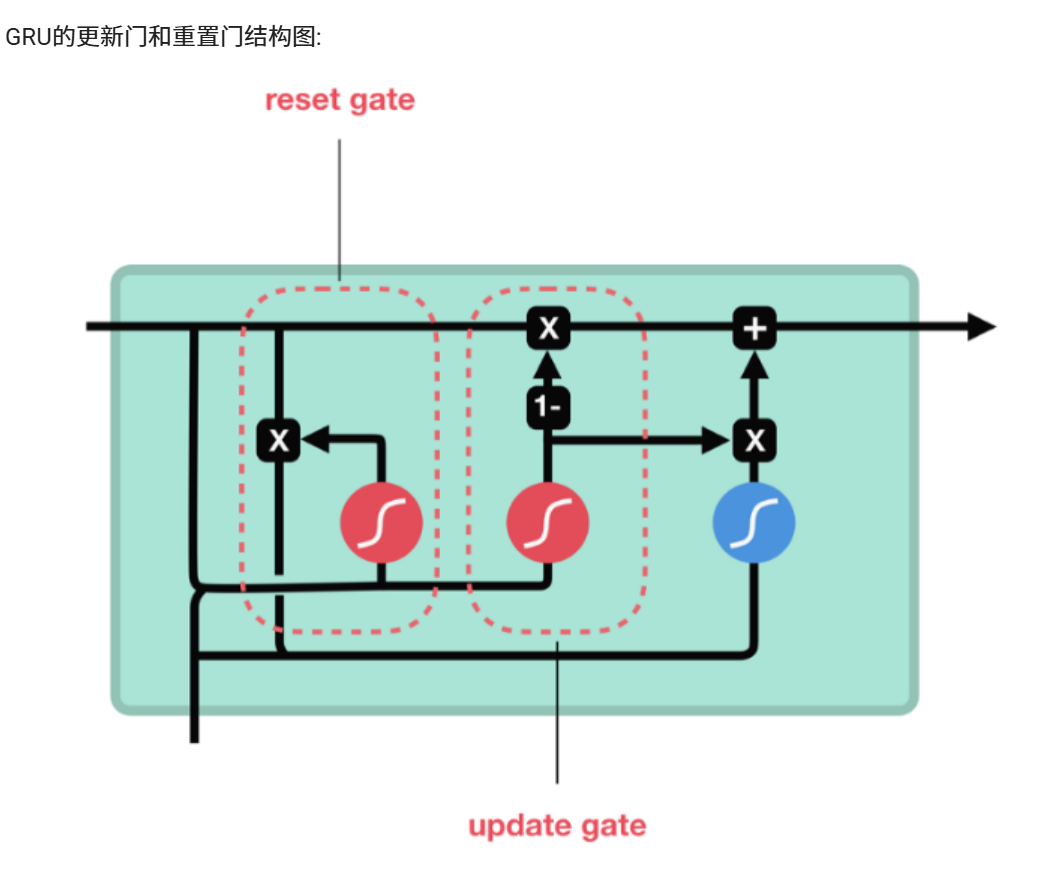
和之前分析过的LSTM中的门控一样, 首先计算更新门和重置门的门值, 分别是z(t)和r(t), 计算方法就是使用X(t)与h(t-1)拼接进行线性变换, 再经过sigmoid激活. 之后重置门门值作用在了h(t-1)上, 代表控制上一时间步传来的信息有多少可以被利用. 接着就是使用这个重置后的h(t-1)进行基本的RNN计算, 即与x(t)拼接进行线性变化, 经过tanh激活, 得到新的h(t). 最后更新门的门值会作用在新的h(t),而1-门值会作用在h(t-1)上, 随后将两者的结果相加, 得到最终的隐含状态输出h(t), 这个过程意味着更新门有能力保留之前的结果, 当门值趋于1时, 输出就是新的h(t), 而当门值趋于0时, 输出就是上一时间步的h(t-1).
2. 更新门
决定有多少过去的信息需要保留,以及当前输入有多少需要更新到隐藏状态中

3.重置门
控制前一时刻隐藏状态对当前候选隐藏状态的影响程度。

4.举例说明
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
"""
定义 GRU 层:
nn.GRU 是 PyTorch 中提供的门控循环单元(Gated Recurrent Unit)模块。
参数说明:
1. input_size:输入张量的维度。这里表示每个时间步输入的特征维度为 5。
2. hidden_size:隐藏层的输出维度。GRU 的每个时间步输出的隐藏状态维度为 6。
3. num_layers:GRU 层数。这里是 1,表示单层 GRU。
4. batch_first:是否将 batch_size 作为输入的第一个维度,默认为 False,
如果设置为 True,则输入数据的形状应为 (batch_size, sequence_length, input_size),
否则默认是 (sequence_length, batch_size, input_size)。
"""
gru = nn.GRU(input_size=5, hidden_size=6, num_layers=1)
"""
构建输入数据 input_x:
input_x 的形状为 (sequence_length, batch_size, input_size)。
根据上面的定义:
- sequence_length = 3(序列长度或时间步数)
- batch_size = 2(批次大小,即一次处理 2 个样本)
- input_size = 5(每个时间步输入的特征维度)
因此,input_x 的形状为 (3, 2, 5)。
"""
input_x = torch.randn(3, 2, 5)
"""
初始化初始隐藏状态 h0:
h0 表示初始隐藏状态。
它的形状为 (num_layers * num_directions, batch_size, hidden_size):
- num_layers:GRU 层数,这里是 1。
- num_directions:网络方向数量,默认为 1(单向 GRU)。
- batch_size:批次大小,这里是 2。
- hidden_size:隐藏层的输出维度,这里是 6。
因此,h0 的形状为 (1, 2, 6)。
"""
h0 = torch.randn(1, 2, 6) # 初始隐藏状态
"""
进行前向传播:
通过调用 gru(input_x, h0) 进行前向传播计算。
返回值:
1. out:所有时间步的隐藏状态拼接而成的张量。
形状为 (sequence_length, batch_size, hidden_size)。
这里 out 的形状为 (3, 2, 6)。
2. hn:最后一个时间步的隐藏状态。
形状为 (num_layers * num_directions, batch_size, hidden_size)。
这里 hn 的形状为 (1, 2, 6)。
"""
out, hn = gru(input_x, h0)
"""
打印输出结果:
- output:所有时间步的隐藏状态。
- hidden:最后一个时间步的隐藏状态。
"""
print('output-->', out.shape, '\n', out) # 输出所有时间步的隐藏状态
print('hidden-->', hn.shape, '\n', hn) # 输出最后一个时间步的隐藏状态
# 下面是输出结果,
"""
output--> torch.Size([3, 2, 6])
tensor([[[-0.5015, -0.7116, -0.1171, 0.2362, -0.6642, 0.0959],
[ 0.0150, -0.1669, 0.2446, 0.1173, -0.1926, -0.5418]],
[[-0.2028, -0.5469, 0.0738, 0.3077, -0.2004, 0.4037],
[-0.1716, 0.1673, 0.1097, 0.2814, -0.2700, -0.1357]],
[[-0.2822, -0.5123, 0.0012, 0.3625, 0.0412, 0.2402],
[-0.2707, -0.1250, 0.2660, 0.2220, 0.3482, 0.5775]]],
grad_fn=<StackBackward0>)
hidden--> torch.Size([1, 2, 6])
tensor([[[-0.2822, -0.5123, 0.0012, 0.3625, 0.0412, 0.2402],
[-0.2707, -0.1250, 0.2660, 0.2220, 0.3482, 0.5775]]],
grad_fn=<StackBackward0>)
"""
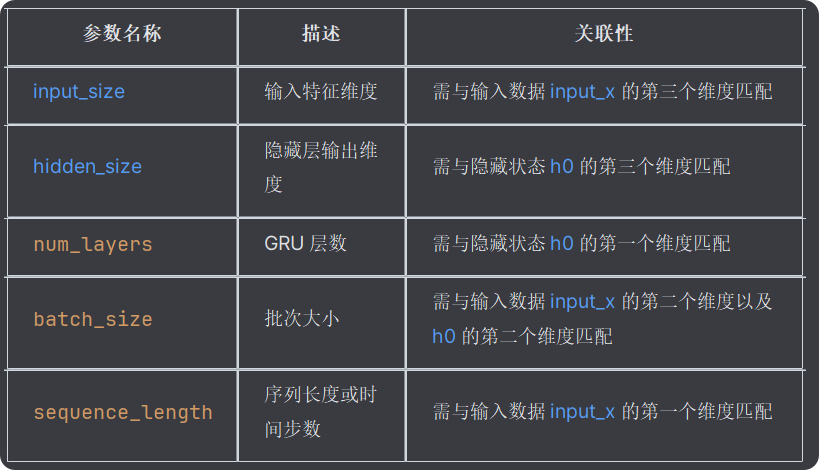
5. 参数关系总结
注意:LSTM的参数关系也和下表一样

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 53
53 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)