基于 TensorFlow 和 Gradio 的智能聊天机器人实现
TensorFlow:开源深度学习框架,用于构建和训练神经网络模型Keras:TensorFlow 的高级 API,简化深度学习模型的构建过程Gradio:用于快速创建机器学习模型的交互式 Web 界面:用于数据处理和分析JSON/Re:用于数据加载和文本预处理本项目实现了一个完整的智能聊天机器人系统,通过 TensorFlow 构建深度学习模型进行意图识别,使用 Gradio 创建交互式 Web
在人工智能快速发展的今天,聊天机器人已经成为人机交互的重要方式。本文将介绍如何使用 TensorFlow 构建一个基于深度学习的意图识别模型,并通过 Gradio 实现交互式聊天界面,打造一个功能完整的智能聊天机器人系统。
一、项目背景与目标
随着自然语言处理技术的进步,基于神经网络的模型在文本分类和意图识别任务中表现出优异的性能。本项目旨在开发一个能够理解用户意图并提供相应回复的智能聊天机器人,主要实现以下目标:
- 基于深度学习的文本意图识别
- 智能回复生成系统
- 交互式 Web 聊天界面
- 模型的训练、保存与加载机制
该聊天机器人可以作为 Python 学习助手,解答学习者在编程过程中遇到的常见问题,也可以通过扩展数据集应用于其他领域。
二、技术栈介绍
本项目采用的主要技术栈包括:
- TensorFlow:开源深度学习框架,用于构建和训练神经网络模型
- Keras:TensorFlow 的高级 API,简化深度学习模型的构建过程
- Gradio:用于快速创建机器学习模型的交互式 Web 界面
- Numpy/Pandas:用于数据处理和分析
- JSON/Re:用于数据加载和文本预处理
三、系统设计与实现
1、整体架构设计
聊天机器人系统采用分层架构设计,主要包括:
- 数据处理层:负责数据集加载和文本预处理
- 模型层:构建和训练意图识别神经网络
- 逻辑层:实现意图预测和回复生成
- 接口层:通过 Gradio 提供用户交互界面
2、文本预处理实现
文本预处理是自然语言处理任务的基础,本项目实现了以下预处理步骤:
def preprocess_text(text):
"""清洗和规范化文本"""
text = text.lower() # 转换为小写
text = re.sub(r'[^\w\s]', '', text) # 移除标点符号
text = re.sub(r'\s+', ' ', text).strip() # 处理多余空格
return text
这段代码将文本转换为小写,移除标点符号,并处理多余的空格,使文本格式统一,便于后续处理。
3、数据集加载与处理
系统从 JSON 文件加载对话数据集,并处理成模型训练所需的格式:
def load_dataset(filename='/kaggle/input/chatbot-dataset/chatbot_dataset.json'):
"""从JSON文件加载数据集"""
try:
with open(filename, 'r', encoding='utf-8') as f:
intents = json.load(f)
print(f"成功从 {filename} 加载数据集")
return intents
except FileNotFoundError:
print(f"错误: 文件 {filename} 未找到!请确保数据集文件正确。")
return None
def prepare_training_data(intents):
"""处理数据集,准备训练数据"""
patterns = []
tags = []
for intent in intents["intents"]:
for pattern in intent["patterns"]:
processed_pattern = preprocess_text(pattern)
patterns.append(processed_pattern)
tags.append(intent["tag"])
# 创建DataFrame便于分析
df = pd.DataFrame({
'pattern': patterns,
'tag': tags
})
print(f"数据集大小: {len(df)} 样本")
print(f"类别数量: {len(df['tag'].unique())}")
print("\n各类别样本数量分布:")
print(df['tag'].value_counts())
return patterns, tags, df
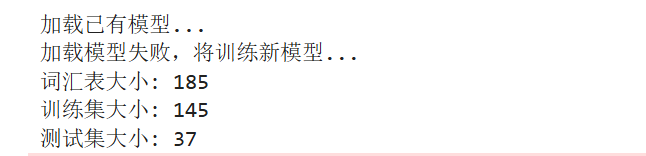
4、神经网络模型构建
本项目使用多层神经网络进行意图识别,模型结构包括词嵌入层、池化层、全连接层和 Dropout 层:
def build_model(vocab_size, embedding_dim, max_length, num_classes):
model = Sequential([
Embedding(vocab_size, embedding_dim, input_length=max_length),
GlobalAveragePooling1D(),
Dense(128, activation='relu'),
Dropout(0.3),
Dense(64, activation='relu'),
Dropout(0.3),
Dense(32, activation='relu'),
Dense(num_classes, activation='softmax')
])
# 明确构建模型
model.build(input_shape=(None, max_length))
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
return model
模型使用词嵌入 (Embedding) 将文本转换为稠密向量表示,通过多层全连接网络提取语义特征,最后使用 softmax 激活函数输出各类别的概率。
5、模型训练与评估
模型训练过程包括数据分割、序列转换和模型拟合:
def train_model(patterns, tags, vocab_size, max_length, embedding_dim, epochs, batch_size):
"""训练意图识别模型"""
# 标签编码
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(tags)
# 文本向量化
tokenizer = Tokenizer(num_words=vocab_size, oov_token='<OOV>')
tokenizer.fit_on_texts(patterns)
X = tokenizer.texts_to_sequences(patterns)
X = pad_sequences(X, maxlen=max_length, padding='post', truncating='post')
# 分割训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 构建模型
num_classes = len(label_encoder.classes_)
model = build_model(vocab_size, embedding_dim, max_length, num_classes)
# 训练模型
history = model.fit(
X_train,
y_train,
validation_data=(X_test, y_test),
epochs=epochs,
batch_size=batch_size,
verbose=1 # 显示训练进度
)
# 评估模型
test_loss, test_acc = model.evaluate(X_test, y_test, verbose=0)
print(f"测试准确率: {test_acc:.4f}")
return model, tokenizer, label_encoder, max_length, history
训练过程中使用了验证集监控模型性能,防止过拟合,并在训练完成后评估模型在测试集上的准确率。
6、模型保存与加载
为了便于模型的复用和部署,系统实现了完整的模型保存和加载功能:
def save_model(model, tokenizer, label_encoder, max_length, model_dir='chatbot_model'):
"""保存训练好的模型和相关组件"""
import os
os.makedirs(model_dir, exist_ok=True)
# 保存模型
model.save(f"{model_dir}/model.h5")
# 保存tokenizer
with open(f"{model_dir}/tokenizer.json", 'w', encoding='utf-8') as f:
f.write(tokenizer.to_json())
# 保存label encoder
np.save(f"{model_dir}/label_encoder.npy", label_encoder.classes_)
# 保存max_length
with open(f"{model_dir}/max_length.txt", 'w') as f:
f.write(str(max_length))
print(f"模型已保存到 {model_dir}")
def load_model(model_dir='chatbot_model'):
"""加载训练好的模型和相关组件"""
from tensorflow.keras.models import load_model
import json
# 加载模型
model = load_model(f"{model_dir}/model.h5")
# 加载tokenizer
with open(f"{model_dir}/tokenizer.json", 'r', encoding='utf-8') as f:
tokenizer_config = json.load(f)
tokenizer = Tokenizer.from_config(tokenizer_config)
# 加载label encoder
label_encoder = LabelEncoder()
label_encoder.classes_ = np.load(f"{model_dir}/label_encoder.npy", allow_pickle=True)
# 加载max_length
with open(f"{model_dir}/max_length.txt", 'r') as f:
max_length = int(f.read())
print(f"模型已从 {model_dir} 加载")
return model, tokenizer, label_encoder, max_length
7.意图预测与回复生成
模型训练完成后,即可用于预测用户输入的意图并生成回复:
def predict_intent(text, model, tokenizer, label_encoder, max_length):
"""预测用户输入的意图"""
# 预处理文本
processed_text = preprocess_text(text)
# 转换为模型输入格式
sequence = tokenizer.texts_to_sequences([processed_text])
padded_sequence = pad_sequences(sequence, maxlen=max_length, padding='post', truncating='post')
# 预测
prediction = model.predict(padded_sequence, verbose=0)
intent_index = np.argmax(prediction)
confidence = prediction[0][intent_index]
# 设置置信度阈值
if confidence < 0.6: # 动态阈值
intent_tag = "unknown"
else:
intent_tag = label_encoder.inverse_transform([intent_index])[0]
return intent_tag, confidence
def get_response(intent_tag, intents):
"""根据意图标签获取回复"""
for intent in intents["intents"]:
if intent["tag"] == intent_tag:
return random.choice(intent["responses"])
return "抱歉,我没明白你的意思。"
系统设置了置信度阈值,当预测置信度低于阈值时,认为意图不明确,返回特殊回复引导用户重新表述问题。
8、Gradio 交互界面实现
最后,使用 Gradio 构建交互式聊天界面,使模型能够以 Web 应用的形式提供服务:
def create_chatbot_interface(model, tokenizer, label_encoder, max_length, intents):
"""创建交互式聊天界面"""
def chatbot_response(message, history):
# 预测意图
intent_tag, confidence = predict_intent(message, model, tokenizer, label_encoder, max_length)
# 获取回复
response = get_response(intent_tag, intents)
# 对于低置信度的预测,可以添加特殊处理
if intent_tag == "unknown":
if "?" in message:
response = "这个问题我不太确定,您可以尝试更详细地描述吗?"
else:
response = "我不太明白您的意思,您是想了解编程、数据科学还是Kaggle相关的内容呢?"
# 将对话添加到历史
history.append((message, response))
return "", history
with gr.Blocks() as demo:
gr.Markdown("# 🤖 Python学习助手聊天机器人")
# 聊天界面
chatbot = gr.Chatbot(height=500)
msg = gr.Textbox(label="输入消息", placeholder="在这里输入您的问题...")
clear = gr.Button("清空对话")
# 交互逻辑
msg.submit(chatbot_response, [msg, chatbot], [msg, chatbot])
clear.click(lambda: None, None, chatbot, queue=False)
return demo
Gradio 提供了简洁的 API,能够快速创建包含聊天历史、消息输入和清空功能的交互界面,无需复杂的 Web 开发知识。
四、运行与测试
1、主函数流程
主函数整合了整个系统的运行流程,包括数据加载、模型训练 (或加载) 和界面启动:
def main():
# 加载数据集
intents = load_dataset()
if intents is None:
return
# 准备训练数据
patterns, tags, df = prepare_training_data(intents)
# 训练模型或加载已有模型
train_new_model = False # 设置为True以训练新模型
if train_new_model:
print("\n开始训练新模型...")
model, tokenizer, label_encoder, max_length, history = train_model(
patterns,
tags,
vocab_size=1000,
max_length=20,
embedding_dim=32,
epochs=100,
batch_size=8
)
# 可视化训练过程
plot_training_history(history)
# 保存模型
save_model(model, tokenizer, label_encoder, max_length)
else:
print("\n加载已有模型...")
try:
model, tokenizer, label_encoder, max_length = load_model()
except:
print("加载模型失败,将训练新模型...")
model, tokenizer, label_encoder, max_length, history = train_model(
patterns,
tags,
vocab_size=1000,
max_length=20,
embedding_dim=32,
epochs=100,
batch_size=8
)
save_model(model, tokenizer, label_encoder, max_length)
# 创建并启动Gradio界面
demo = create_chatbot_interface(model, tokenizer, label_encoder, max_length, intents)
demo.launch(share=True)
if __name__ == "__main__":
main()
2、训练过程可视化
系统提供了训练过程可视化功能,便于观察模型的收敛情况:
def plot_training_history(history):
"""可视化模型训练过程"""
plt.figure(figsize=(12, 4))
# 绘制准确率曲线
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model Accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Validation'], loc='lower right')
# 绘制损失曲线
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model Loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Validation'], loc='upper right')
plt.tight_layout()
plt.show()
五、项目优化与扩展方向
1.现有系统的优化点
①模型优化:
- 可以尝试使用更复杂的模型结构,如 LSTM、GRU 或 Transformer
- 调整超参数以提高模型准确率
- 增加正则化方法减少过拟合
②数据增强:
- 对现有文本进行同义词替换、句式变换等数据增强
- 收集更多领域相关数据扩展知识库
③回复生成:
- 实现基于模板的更灵活的回复生成
- 引入检索式或生成式回复模型提高回复质量
2、功能扩展方向
- 多轮对话支持:实现上下文感知的多轮对话功能
- 实体识别:增加命名实体识别功能,提取用户输入中的关键信息
- 知识库集成:连接外部知识库,提供更丰富的信息查询功能
- 多语言支持:扩展系统以支持多种语言的交互
六、总结
本项目实现了一个完整的智能聊天机器人系统,通过 TensorFlow 构建深度学习模型进行意图识别,使用 Gradio 创建交互式 Web 界面。系统具有以下特点:
- 完整的文本预处理和意图识别流程
- 可复用的模型保存与加载机制
- 简洁友好的用户交互界面
- 可扩展的系统架构设计
该聊天机器人可以作为 Python 学习助手,也可以通过更新数据集应用于客服、教育等其他领域。通过进一步优化模型和扩展功能,能够打造出更智能、更实用的聊天机器人系统。
七、代码仓库与部署
完整的项目代码可以在GitHub 仓库中获取。部署时只需安装所需依赖并运行主程序,系统将自动加载模型或训练新模型并启动 Web 界面。
pip install tensorflow gradio numpy pandas matplotlib
python chatbot.py
通过本项目的实践,我们深入了解了深度学习在自然语言处理中的应用,以及如何将机器学习模型部署为实际可用的应用程序,为进一步开发更复杂的 AI 系统奠定了基础。
八、完整代码
pip install gradio
import numpy as np
import pandas as pd
import json
import re
import random
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, GlobalAveragePooling1D, Dropout
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import gradio as gr
# 文本预处理
def preprocess_text(text):
"""清洗和规范化文本"""
text = text.lower() # 转换为小写
text = re.sub(r'[^\w\s]', '', text) # 移除标点符号
text = re.sub(r'\s+', ' ', text).strip() # 处理多余空格
return text
# 加载数据集
def load_dataset(filename='/kaggle/input/chatbot-dataset/chatbot_dataset.json'):
"""从JSON文件加载数据集"""
try:
with open(filename, 'r', encoding='utf-8') as f:
intents = json.load(f)
print(f"成功从 {filename} 加载数据集")
return intents
except FileNotFoundError:
print(f"错误: 文件 {filename} 未找到!请确保数据集文件正确。")
return None
# 准备训练数据
def prepare_training_data(intents):
"""处理数据集,准备训练数据"""
patterns = []
tags = []
for intent in intents["intents"]:
for pattern in intent["patterns"]:
processed_pattern = preprocess_text(pattern)
patterns.append(processed_pattern)
tags.append(intent["tag"])
# 创建DataFrame便于分析
df = pd.DataFrame({
'pattern': patterns,
'tag': tags
})
print(f"数据集大小: {len(df)} 样本")
print(f"类别数量: {len(df['tag'].unique())}")
print("\n各类别样本数量分布:")
print(df['tag'].value_counts())
return patterns, tags, df
def build_model(vocab_size, embedding_dim, max_length, num_classes):
model = Sequential([
Embedding(vocab_size, embedding_dim, input_length=max_length),
GlobalAveragePooling1D(),
Dense(128, activation='relu'),
Dropout(0.3),
Dense(64, activation='relu'),
Dropout(0.3),
Dense(32, activation='relu'),
Dense(num_classes, activation='softmax')
])
# 明确构建模型
model.build(input_shape=(None, max_length))
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
return model
# 训练模型
history = model.fit(
X_train,
y_train,
validation_data=(X_test, y_test),
epochs=epochs,
batch_size=batch_size,
verbose=1 # 显示训练进度
)
# 评估模型
test_loss, test_acc = model.evaluate(X_test, y_test, verbose=0)
print(f"测试准确率: {test_acc:.4f}")
return model, tokenizer, label_encoder, max_length, history
# 绘制训练历史
def plot_training_history(history):
"""可视化模型训练过程"""
plt.figure(figsize=(12, 4))
# 绘制准确率曲线
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model Accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Validation'], loc='lower right')
# 绘制损失曲线
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model Loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Validation'], loc='upper right')
plt.tight_layout()
plt.show()
# 保存模型
def save_model(model, tokenizer, label_encoder, max_length, model_dir='chatbot_model'):
"""保存训练好的模型和相关组件"""
import os
os.makedirs(model_dir, exist_ok=True)
# 保存模型
model.save(f"{model_dir}/model.h5")
# 保存tokenizer
with open(f"{model_dir}/tokenizer.json", 'w', encoding='utf-8') as f:
f.write(tokenizer.to_json())
# 保存label encoder
np.save(f"{model_dir}/label_encoder.npy", label_encoder.classes_)
# 保存max_length
with open(f"{model_dir}/max_length.txt", 'w') as f:
f.write(str(max_length))
print(f"模型已保存到 {model_dir}")
# 加载模型
def load_model(model_dir='chatbot_model'):
"""加载训练好的模型和相关组件"""
from tensorflow.keras.models import load_model
import json
# 加载模型
model = load_model(f"{model_dir}/model.h5")
# 加载tokenizer
with open(f"{model_dir}/tokenizer.json", 'r', encoding='utf-8') as f:
tokenizer_config = json.load(f)
tokenizer = Tokenizer.from_config(tokenizer_config)
# 加载label encoder
label_encoder = LabelEncoder()
label_encoder.classes_ = np.load(f"{model_dir}/label_encoder.npy", allow_pickle=True)
# 加载max_length
with open(f"{model_dir}/max_length.txt", 'r') as f:
max_length = int(f.read())
print(f"模型已从 {model_dir} 加载")
return model, tokenizer, label_encoder, max_length
# 预测意图
def predict_intent(text, model, tokenizer, label_encoder, max_length):
"""预测用户输入的意图"""
# 预处理文本
processed_text = preprocess_text(text)
# 转换为模型输入格式
sequence = tokenizer.texts_to_sequences([processed_text])
padded_sequence = pad_sequences(sequence, maxlen=max_length, padding='post', truncating='post')
# 预测
prediction = model.predict(padded_sequence, verbose=0)
intent_index = np.argmax(prediction)
confidence = prediction[0][intent_index]
# 设置置信度阈值
if confidence < 0.6: # 动态阈值
intent_tag = "unknown"
else:
intent_tag = label_encoder.inverse_transform([intent_index])[0]
return intent_tag, confidence
# 获取回复
def get_response(intent_tag, intents):
"""根据意图标签获取回复"""
for intent in intents["intents"]:
if intent["tag"] == intent_tag:
return random.choice(intent["responses"])
return "抱歉,我没明白你的意思。"
# 创建Gradio界面
def create_chatbot_interface(model, tokenizer, label_encoder, max_length, intents):
"""创建交互式聊天界面"""
def chatbot_response(message, history):
# 预测意图
intent_tag, confidence = predict_intent(message, model, tokenizer, label_encoder, max_length)
# 获取回复
response = get_response(intent_tag, intents)
# 对于低置信度的预测,可以添加特殊处理
if intent_tag == "unknown":
if "?" in message:
response = "这个问题我不太确定,您可以尝试更详细地描述吗?"
else:
response = "我不太明白您的意思,您是想了解编程、数据科学还是Kaggle相关的内容呢?"
# 将对话添加到历史
history.append((message, response))
return "", history
with gr.Blocks() as demo:
gr.Markdown("# 🤖 Python学习助手聊天机器人")
# 聊天界面
chatbot = gr.Chatbot(height=500)
msg = gr.Textbox(label="输入消息", placeholder="在这里输入您的问题...")
clear = gr.Button("清空对话")
# 交互逻辑
msg.submit(chatbot_response, [msg, chatbot], [msg, chatbot])
clear.click(lambda: None, None, chatbot, queue=False)
return demo
# 主函数
def main():
# 加载数据集
intents = load_dataset()
if intents is None:
return
# 准备训练数据
patterns, tags, df = prepare_training_data(intents)
# 训练模型或加载已有模型
train_new_model = False # 设置为True以训练新模型
if train_new_model:
print("\n开始训练新模型...")
model, tokenizer, label_encoder, max_length, history = train_model(
patterns,
tags,
vocab_size=1000,
max_length=20,
embedding_dim=32,
epochs=100,
batch_size=8
)
# 可视化训练过程
plot_training_history(history)
# 保存模型
save_model(model, tokenizer, label_encoder, max_length)
else:
print("\n加载已有模型...")
try:
model, tokenizer, label_encoder, max_length = load_model()
except:
print("加载模型失败,将训练新模型...")
model, tokenizer, label_encoder, max_length, history = train_model(
patterns,
tags,
vocab_size=1000,
max_length=20,
embedding_dim=32,
epochs=100,
batch_size=8
)
save_model(model, tokenizer, label_encoder, max_length)
# 创建并启动Gradio界面
demo = create_chatbot_interface(model, tokenizer, label_encoder, max_length, intents)
demo.launch(share=True)
if __name__ == "__main__":
main()
脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)