浅说LLM-RAG(大模型-检索增强生成)
大家好我是木木,自从2022年11月30日OpenAI发布ChatGPT后,大模型迅速火热起来,人工智能作为当下最火的行业之一,2025年春节期间DeepSeek R1模型大火。LLM中有很多的技术,今天我们浅说LLM-RAG检索增强生成技术。
大家好我是木木,自从2022年11月30日OpenAI发布ChatGPT后,大模型迅速火热起来,人工智能作为当下最火的行业之一,2025年春节期间DeepSeek R1模型大火。LLM中有很多的技术,今天我们浅说LLM-RAG检索增强生成技术。
什么是RAG?
RAG(Retrieval-Augmented Generation)是一种信息检索和文本生成结合的技术,提高模型的能力。
简单说:通过外部的数据(一般是向量数据库,存储了一些我们企业的专业知识)+输入的问答信息(向大模型提问的问答信息)融合在一起,让模型能够准确生成我们专业领域或者是更贴近自身企业相关的一些答复信息。
来个故事案例详细了解:一家车企想做一个问答机器人,实现效果是为用户提供自身车企产品的相关问答,比如车辆的价格、优惠活动等信息咨询。
他们本地化部署并训练一个通用模型,但是在测试过程中遇到了一个问题,当输入一些咨询车企产品相关的问答时,问答机器人给出答案结果不是很理想,回答结果跟公司没有任何相关性。
那么现在的问题是:问答机器人给出的结果不准确,要解决这个问题怎么办了?
解决方法:可以通过RAG技术解决。
RAG的三大核心组件
知识库(Knowledge Base)
知识库顾名思义就是存放相关问答信息的。比如上面的案例,车企要做一个产品相关信息问答机器人,那么知识库中我们就存放该车企产品相关信息的数据。
一般将我们清洗完的数据进行文本向量化,将文字转成向量再进行存储,用于后续检索使用。一般都是使用向量数据库进行存储。
检索器(Retriever)
用于从外部知识库(向量数据库)中检索与问题相关的信息。
将输入的问答句子向量化,再去向量数据库进行相似度检索,查找最相近的信息。
生成器(Generator)
根据检索的结果和用户提出的原生问题生成最终回答。
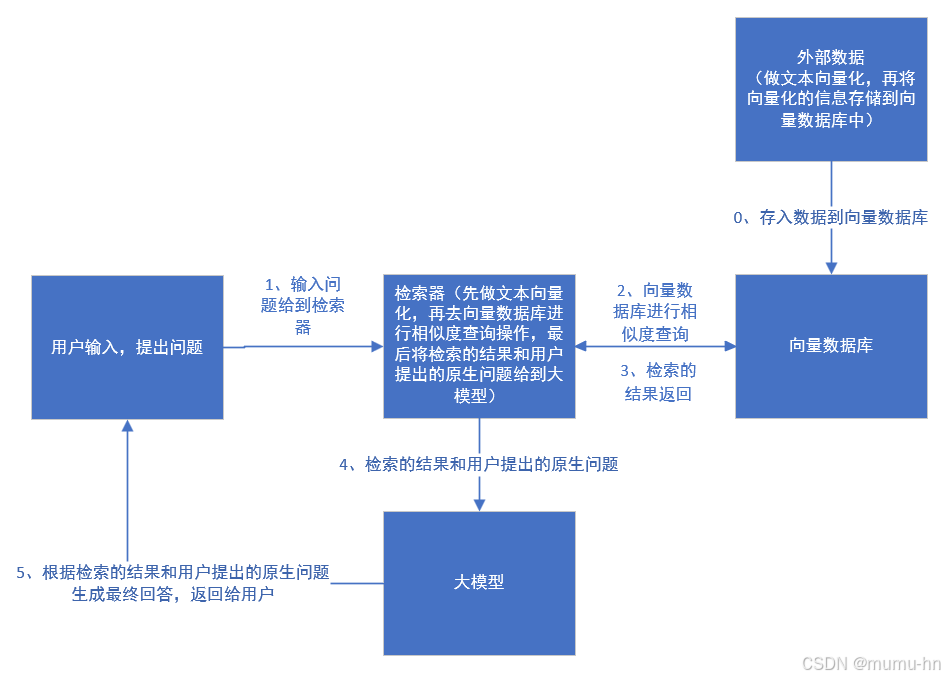
RAG的数据流程
介绍完RAG三大核心组件,我们再讲解下RAG的工作数据流程是怎么样的。
RAG的优缺点
| 优点 | 缺点 |
| 可解释性强,根据检索向量库生成回答,结果真实可靠 | 过于依赖检索能力,如果检索相似度低,结果会不准确 |
| 通过外部的知识可以提升模型专业问答能力 | 对外部知识过于依赖,如果外部知识的质量过差,生成的问答也会下降 |
| 。。。 | 。。。 |
RAG应用
RAG目前应用场景也很多,像我们上面提到的问答机器人、客服机器人、聊天机器人等等,其实现在RAG技术已经应用到我们日常很多的地方,比如现在随便进入一个外卖、电商行业都开始用到RAG技术,提高售后、售前的服务速度。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)