微分中值定理与积分中值定理:机器学习中的数学基石
本文对比积分与微分中值定理,解析二者在研究对象(积分均值/导数变化率)、条件(连续/可导)及应用场景(整体估计/局部分析)的差异,阐述其互为补充的中值定理框架体系。
前言
本文隶属于专栏《机器学习数学通关指南》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见《机器学习数学通关指南》
正文
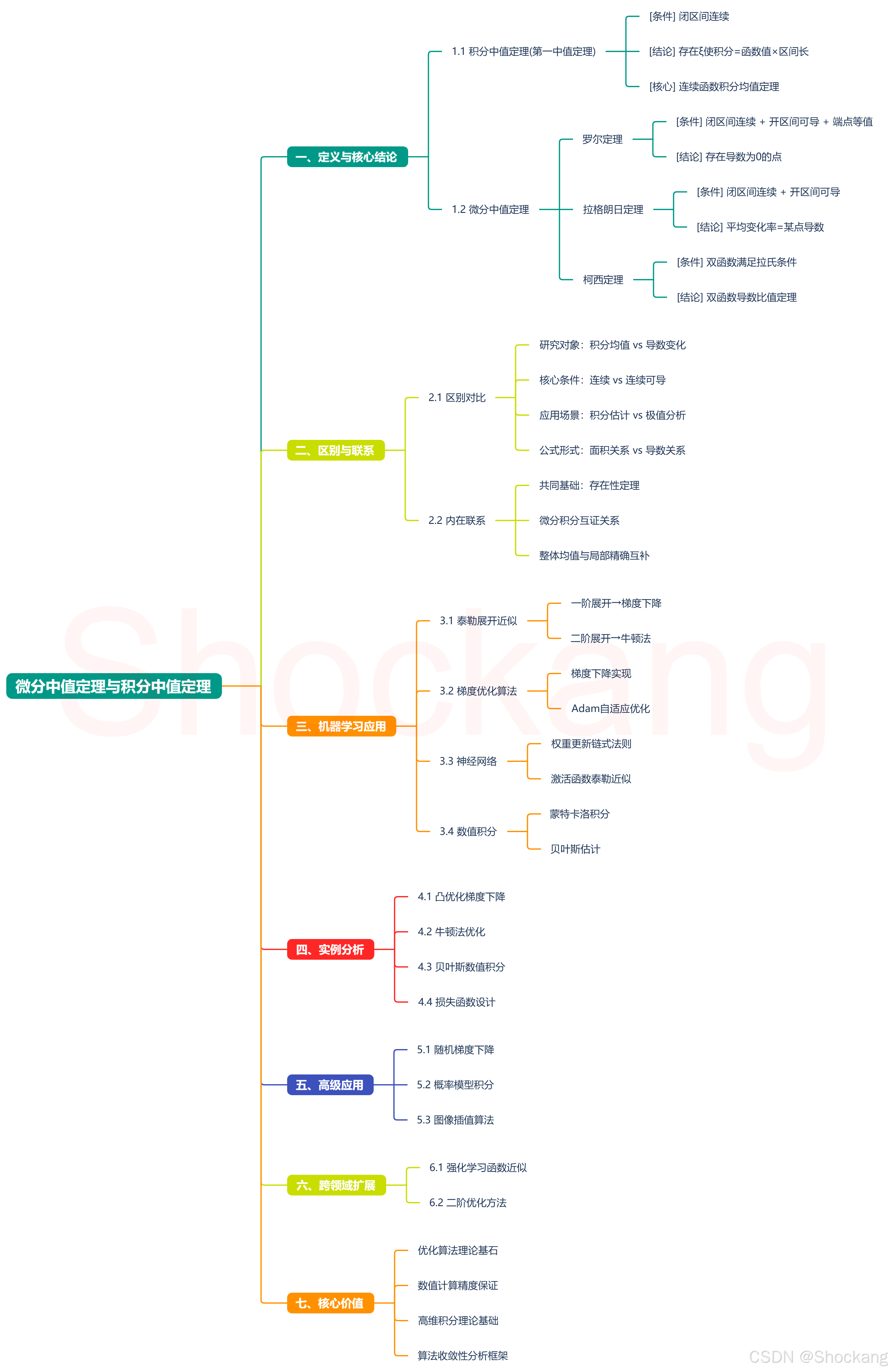
📚 一、定义与核心结论
📊 积分中值定理(第一中值定理)
- 条件:函数 f ( x ) f(x) f(x) 在闭区间 [ a , b ] [a, b] [a,b] 上连续。
- 结论:存在至少一点 ξ ∈ [ a , b ] \xi \in [a, b] ξ∈[a,b],使得:
∫ a b f ( x ) d x = f ( ξ ) ( b − a ) . \int_a^b f(x) \, dx = f(\xi)(b - a). ∫abf(x)dx=f(ξ)(b−a). - 核心思想:连续函数在区间上的定积分等于某点的函数值与区间长度的乘积。
📈 微分中值定理
包含多个子定理,关键的区别如下:
-
罗尔定理
- 条件: f ( x ) f(x) f(x) 在 [ a , b ] [a, b] [a,b] 连续、开区间可导,且 f ( a ) = f ( b ) f(a) = f(b) f(a)=f(b)。
- 结论:存在 ξ ∈ ( a , b ) \xi \in (a, b) ξ∈(a,b),使得 f ′ ( ξ ) = 0 f'(\xi) = 0 f′(ξ)=0。
-
拉格朗日中值定理
- 条件: f ( x ) f(x) f(x) 在 [ a , b ] [a, b] [a,b] 连续、开区间可导。
- 结论:存在 ξ ∈ ( a , b ) \xi \in (a, b) ξ∈(a,b),使得:
f ( b ) − f ( a ) = f ′ ( ξ ) ( b − a ) . f(b) - f(a) = f'(\xi)(b - a). f(b)−f(a)=f′(ξ)(b−a).
-
柯西中值定理
- 条件: f ( x ) f(x) f(x)、 F ( x ) F(x) F(x) 满足拉格朗日中值定理的条件,且 F ′ ( x ) ≠ 0 F'(x) \neq 0 F′(x)=0。
- 结论:存在 ξ ∈ ( a , b ) \xi \in (a, b) ξ∈(a,b),使得:
f ( b ) − f ( a ) F ( b ) − F ( a ) = f ′ ( ξ ) F ′ ( ξ ) . \frac{f(b) - f(a)}{F(b) - F(a)} = \frac{f'(\xi)}{F'(\xi)}. F(b)−F(a)f(b)−f(a)=F′(ξ)f′(ξ).
🧩 二、区别与联系
🔄 区别对比
| 方面 | 积分中值定理 | 微分中值定理 |
|---|---|---|
| 研究对象 | 函数在区间上的积分均值 | 函数在区间内的导数或变化率 |
| 核心条件 | 连续性(无需可导) | 连续且可导(对导数的要求不同) |
| 应用场景 | 定积分的估计、物理量的平均作用 | 分析极值、证明函数性质(如单调性、等式) |
| 公式形式 | 积分等于某点函数值的面积形式 | 导数与平均变化率的关系 |
🔗 联系
-
基础框架的一致性
两个定理均属于中值定理,核心是利用连续性或可导性证明"存在某点满足特定条件"。 -
微分与积分的关系
积分中值定理的证明常借助罗尔定理或拉格朗日中值定理(通过构造辅助函数)。例如,积分上限函数的导数即为被积函数,结合微分中值定理可得积分均值。 -
互为补充
- 积分中值定理:关注整体性质的均值。
- 微分中值定理:关注局部变化的精确点。
例如,拉格朗日中值定理可视为积分中值定理在导数领域的对应形式。
💻 三、在机器学习中的应用
🔬 1. 泰勒展开与函数近似
泰勒展开是拉格朗日中值定理在高阶可微函数上的推广,在机器学习中有广泛应用:
- 一阶泰勒展开: f ( x ) ≈ f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) f(x) \approx f(x_0) + f'(x_0)(x - x_0) f(x)≈f(x0)+f′(x0)(x−x0)
- 二阶泰勒展开: f ( x ) ≈ f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) + 1 2 f ′ ′ ( x 0 ) ( x − x 0 ) 2 f(x) \approx f(x_0) + f'(x_0)(x - x_0) + \frac{1}{2}f''(x_0)(x - x_0)^2 f(x)≈f(x0)+f′(x0)(x−x0)+21f′′(x0)(x−x0)2
在实际的机器学习算法中:
- 一阶泰勒展开用于梯度下降算法中,通过线性近似寻找函数的局部最优解。
- 二阶泰勒展开用于牛顿法和拟牛顿法,提供更精确的函数近似,加速收敛。
🧮 2. 梯度下降优化算法
机器学习中最常用的优化算法——梯度下降,其理论基础就来自拉格朗日中值定理:
# 梯度下降算法的简单实现
def gradient_descent(f, df, x0, learning_rate=0.01, epsilon=1e-6, max_iterations=1000):
"""
f: 目标函数
df: 目标函数的梯度
x0: 初始点
learning_rate: 学习率
epsilon: 收敛阈值
max_iterations: 最大迭代次数
"""
x = x0
iterations = 0
while iterations < max_iterations:
gradient = df(x)
if np.linalg.norm(gradient) < epsilon:
break
# 根据中值定理,在某点的梯度方向是函数值下降最快的方向
x = x - learning_rate * gradient
iterations += 1
return x, f(x), iterations
利用了拉格朗日中值定理中梯度方向表示函数变化最快方向的性质。
🧠 3. 神经网络中的权重更新
神经网络训练过程中,权重更新依赖于误差函数对权重的梯度。根据链式法则(微分中值定理的推广):
∂ E ∂ w i j = ∂ E ∂ o j ⋅ ∂ o j ∂ n e t j ⋅ ∂ n e t j ∂ w i j \frac{\partial E}{\partial w_{ij}} = \frac{\partial E}{\partial o_j} \cdot \frac{\partial o_j}{\partial net_j} \cdot \frac{\partial net_j}{\partial w_{ij}} ∂wij∂E=∂oj∂E⋅∂netj∂oj⋅∂wij∂netj
其中:
- E E E 是误差函数
- o j o_j oj 是输出值
- n e t j net_j netj 是神经元输入加权和
- w i j w_{ij} wij 是权重
📉 4. 积分中值定理在数值积分中的应用
在处理大规模数据集的积分计算(如期望值估计)时:
def monte_carlo_integration(f, a, b, n=1000):
"""使用蒙特卡洛方法估计定积分"""
# 根据积分中值定理,用随机采样点来近似
x = np.random.uniform(a, b, n)
fx = np.vectorize(f)(x)
integral = (b - a) * np.mean(fx) # 积分中值定理的应用
return integral
该方法基于积分中值定理,用区间内的随机点函数值的平均来近似积分值。
🛠️ 四、实例分析:机器学习中的具体应用
📊 1. 凸优化与梯度下降
在凸优化问题中,微分中值定理保证了梯度方向是函数下降最快的方向:
# 二次函数的梯度下降示例
def quadratic(x):
return x**2
def dquadratic(x):
return 2*x
x_history = []
x = 10.0 # 起始点
learning_rate = 0.1
epochs = 20
for i in range(epochs):
x_history.append(x)
x = x - learning_rate * dquadratic(x) # 中值定理的应用
通过每一步沿梯度方向更新,我们能够逐步接近函数的最小值点。
🔎 2. 泰勒展开在神经网络训练中的应用
泰勒展开用于神经网络中的损失函数近似和优化算法:
- 一阶展开:标准梯度下降法
- 二阶展开:考虑Hessian矩阵的Newton法和拟Newton法
# 使用二阶泰勒展开的优化(简化版Newton法)
def newton_optimization(f, df, ddf, x0, epsilon=1e-6, max_iter=100):
x = x0
for i in range(max_iter):
grad = df(x)
hessian = ddf(x)
if abs(grad) < epsilon:
break
# 利用二阶泰勒展开寻找最优点
x = x - grad / hessian
return x
这里的牛顿法本质上是利用二阶泰勒展开构建函数的二次近似。
🧪 3. 数值积分在机器学习中的应用
在贝叶斯学习中,经常需要计算后验分布的期望,这涉及到复杂积分:
# 使用积分中值定理的思想实现贝叶斯估计
def bayesian_integration(likelihood, prior, data, theta_range, n_samples=1000):
"""
likelihood: 似然函数
prior: 先验分布
data: 观测数据
theta_range: 参数范围 [min, max]
n_samples: 采样数量
"""
a, b = theta_range
# 生成参数空间中的均匀采样点
thetas = np.linspace(a, b, n_samples)
# 计算未标准化的后验概率
posterior = np.array([likelihood(theta, data) * prior(theta) for theta in thetas])
# 使用积分中值定理计算期望值
normalizing_constant = np.trapz(posterior, thetas) # 通过积分获取标准化常数
posterior_normalized = posterior / normalizing_constant
# 计算参数的后验期望
expected_theta = np.trapz(thetas * posterior_normalized, thetas)
return expected_theta, posterior_normalized
这里的数值积分方法(梯形法则)就是基于积分中值定理的思想实现的。
📱 4. 改进的损失函数设计
在处理特殊的损失函数时,比如对数函数 ln ( 1 + x ) \ln(1+x) ln(1+x) 在 x x x 接近零时的数值稳定性问题,可以使用泰勒展开:
def log1p(x):
"""数值稳定的ln(1+x)实现"""
if abs(x) < 1e-4:
# 使用泰勒展开提高小x值的精度
return x - x**2/2 + x**3/3 - x**4/4
else:
return np.log(1 + x)
这种实现在 x x x 很小时避免了浮点运算的精度问题,广泛应用于机器学习中的各种损失函数计算。
📝 五、总结与启示
🌟 理论与实践的桥梁
微分中值定理和积分中值定理不仅是数学理论中的重要定理,也是连接机器学习理论与实践的重要桥梁:
- 微分中值定理为梯度下降、函数逼近等优化方法提供理论基础
- 积分中值定理为期望计算、概率密度函数处理提供理论保障
💡 编程实现中的启示
在机器学习算法的实现中,这些定理启示我们:
- 局部信息的利用:梯度包含了函数局部变化的重要信息,是优化的关键
- 渐进逼近的思想:通过泰勒展开实现函数的多阶近似,权衡精度和计算成本
- 数值计算的稳定性:利用泰勒展开处理边界情况,提高计算精度
- 采样与积分:积分中值定理为蒙特卡洛积分和其他数值积分方法提供了理论基础,尤其在处理高维积分时显得尤为重要
- 误差分析:中值定理帮助我们理解算法的收敛性和误差界限,为算法性能的理论分析提供工具
🔬 六、高级应用场景
🔄 1. 随机梯度下降与批量更新
SGD(随机梯度下降)的理论基础也来自于微分中值定理的扩展:
# 随机梯度下降实现
def sgd_optimizer(X, y, model, learning_rate=0.01, epochs=100, batch_size=32):
n_samples = len(X)
losses = []
for epoch in range(epochs):
# 随机打乱数据
indices = np.random.permutation(n_samples)
X_shuffled = X[indices]
y_shuffled = y[indices]
for i in range(0, n_samples, batch_size):
X_batch = X_shuffled[i:i+batch_size]
y_batch = y_shuffled[i:i+batch_size]
# 计算当前批次的梯度
grads = model.compute_gradients(X_batch, y_batch)
# 基于微分中值定理的梯度更新
model.update_parameters(grads, learning_rate)
# 计算并记录本轮损失
loss = model.compute_loss(X, y)
losses.append(loss)
SGD通过小批量样本估计真实梯度,依据微分中值定理仍能保证向最优解收敛。
📊 2. 自适应学习率算法
AdaGrad、RMSProp和Adam等自适应学习率算法,都是基于微分中值定理的进一步优化:
# Adam优化器简化实现
def adam_optimizer(params, grads, learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-8):
# 初始化动量和二阶矩估计
if 'm' not in params:
params['m'] = {k: np.zeros_like(v) for k, v in grads.items()}
params['v'] = {k: np.zeros_like(v) for k, v in grads.items()}
params['t'] = 0
params['t'] += 1
# 更新规则(基于拉格朗日中值定理的梯度修正)
for k, grad in grads.items():
# 计算偏置修正的动量和二阶矩
params['m'][k] = beta1 * params['m'][k] + (1 - beta1) * grad
params['v'][k] = beta2 * params['v'][k] + (1 - beta2) * (grad ** 2)
m_corrected = params['m'][k] / (1 - beta1 ** params['t'])
v_corrected = params['v'][k] / (1 - beta2 ** params['t'])
# 自适应学习率更新
params[k] -= learning_rate * m_corrected / (np.sqrt(v_corrected) + epsilon)
这些算法通过历史梯度信息来调整每个参数的学习率,本质上是对中值定理的深度应用。
🧠 3. 神经网络中的激活函数及其泰勒近似
常见的激活函数如Sigmoid、tanh等,在计算过程中常使用泰勒展开进行近似:
def sigmoid_with_taylor(x):
"""带有泰勒近似的Sigmoid函数"""
if x < -5:
# 大负值区域使用泰勒展开
return np.exp(x) # 使用一阶近似
elif x > 5:
# 大正值区域使用泰勒展开
return 1 - np.exp(-x) # 使用一阶近似
else:
# 一般区域使用标准公式
return 1 / (1 + np.exp(-x))
这种优化能有效避免激活函数在极端输入值下的数值不稳定问题。
📐 4. 积分中值定理在概率模型中的应用
贝叶斯推断和概率图模型中的积分计算:
# 使用重要性采样计算期望值(基于积分中值定理)
def importance_sampling(target_pdf, proposal_pdf, proposal_sampler, n_samples=1000):
"""
target_pdf: 目标概率密度函数(可能难以直接采样)
proposal_pdf: 建议分布的概率密度函数
proposal_sampler: 从建议分布采样的函数
"""
# 生成采样点
samples = proposal_sampler(n_samples)
# 计算重要性权重
weights = np.array([target_pdf(s) / proposal_pdf(s) for s in samples])
normalized_weights = weights / np.sum(weights)
# 使用积分中值定理的思想,以加权平均估计期望
expectation = np.sum(normalized_weights * samples)
return expectation
这里利用了积分中值定理的思想,通过有权重的采样点来逼近积分值。
🌟 七、跨领域应用
🎯 1. 强化学习中的函数近似
在强化学习中,Q-learning和策略梯度方法都依赖于价值函数的近似:
# 使用泰勒展开思想的函数近似Q-learning
def q_learning_with_function_approximation(state, action, reward, next_state, model, learning_rate=0.1, gamma=0.99):
# 当前状态-动作对的预测Q值
current_q = model.predict(state, action)
# 下一状态的最大Q值
next_max_q = np.max([model.predict(next_state, a) for a in possible_actions])
# TD目标(基于贝尔曼方程)
td_target = reward + gamma * next_max_q
# TD误差
td_error = td_target - current_q
# 基于梯度方向更新(微分中值定理)
gradients = model.compute_gradients(state, action)
model.update_weights(gradients, learning_rate * td_error)
强化学习中的策略梯度方法直接利用了微分中值定理,通过梯度方向更新策略参数。
🧪 2. 深度学习中的二阶优化
Hessian矩阵和二阶优化方法,如Newton-CG等,直接利用了泰勒展开的二阶近似:
# 简化的二阶优化算法
def newton_cg_optimization(model, X, y, max_iter=100):
params = model.get_params()
for iteration in range(max_iter):
# 计算梯度
grad = model.compute_gradient(X, y)
# 计算Hessian矩阵(或其近似)
hessian = model.compute_hessian(X, y)
# 使用共轭梯度法求解线性系统 Hx = -g
update = conjugate_gradient(hessian, -grad)
# 线搜索确定步长
alpha = line_search(model, params, update, X, y)
# 更新参数(基于二阶泰勒展开)
model.update_params(alpha * update)
这些二阶方法通过利用曲率信息(Hessian矩阵),实现了更高效的优化过程。
📈 3. 积分中值定理在数据增强中的应用
在图像处理和数据增强中,积分中值定理的思想被用于插值算法:
# 使用积分中值定理思想的图像插值
def interpolate_image(image, scale_factor):
height, width = image.shape[:2]
new_height = int(height * scale_factor)
new_width = int(width * scale_factor)
# 创建新图像
new_image = np.zeros((new_height, new_width, image.shape if len(image.shape) > 2 else 1))
# 双线性插值(基于积分中值定理的思想)
for i in range(new_height):
for j in range(new_width):
# 找到对应的源图像坐标
src_i = i / scale_factor
src_j = j / scale_factor
# 计算最近的四个点
i0 = int(src_i)
j0 = int(src_j)
i1 = min(i0 + 1, height - 1)
j1 = min(j0 + 1, width - 1)
# 插值权重
di = src_i - i0
dj = src_j - j0
# 双线性插值(积分中值定理的应用)
if len(image.shape) > 2:
for c in range(image.shape):
new_image[i, j, c] = (1-di)*(1-dj)*image[i0, j0, c] + \
di*(1-dj)*image[i1, j0, c] + \
(1-di)*dj*image[i0, j1, c] + \
di*dj*image[i1, j1, c]
else:
new_image[i, j, 0] = (1-di)*(1-dj)*image[i0, j0] + \
di*(1-dj)*image[i1, j0] + \
(1-di)*dj*image[i0, j1] + \
di*dj*image[i1, j1]
return new_image.squeeze()
图像插值算法基于积分中值定理的思想,通过邻近像素的加权平均来估计中间位置的像素值。
🔍 八、结语:中值定理在机器学习中的价值
微分中值定理和积分中值定理是机器学习算法的理论基石,它们不仅为算法提供了数学保证,也启发了众多算法的设计思路:
-
优化算法的理论依据:各类梯度下降算法都建立在微分中值定理的基础上,保证了"沿梯度方向移动"能不断接近最优解。
-
函数近似的精度保证:泰勒展开为各种函数近似技术提供了误差界限,使我们能够在精度和计算效率之间做出合理权衡。
-
数值积分的理论基础:在概率模型和贝叶斯推断中,积分中值定理为蒙特卡洛方法等数值积分技术提供了理论支持。
-
算法收敛性分析:利用中值定理,我们能够分析各种机器学习算法的收敛性和稳定性,指导算法参数的选择。
理解这些数学基础对于机器学习从业者不仅有助于应用现有算法,更能启发新算法的设计和现有算法的改进。无论是传统机器学习还是深度学习,微分中值定理和积分中值定理都是构建整个理论体系的重要支柱。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 18
18 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)