YOLO-MS:重新思考实时目标检测中的多尺度表征学习(提供源代码)
此外,以前的实时目标检测器大多在不同的编码器阶段采用相同的卷积(即内核大小相同的卷积),但我们认为这并不是提取多尺度语义信息的最佳选择。我们选择的目标分支是基于分支的感受野和阶段,例如,在第二阶段,左边的分支是目标分支,对应小物体。不过,大内核卷积的有效感受野较大,会对更广泛的区域进行编码,从而增加了将小物体外部的干扰信息包含进来的可能性。尽管我们所使用的构建模块在多尺度能力方面有了很大的提升,但
点击蓝字
关注我们
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式
代码和训练好的模型可在https://github.com/FishAndWasabi/YOLO-MS上公开获取,在https://github.com/NK-JittorCV/nk-yolo提供了Jittor版本
计算机视觉研究院专栏
Column of Computer Vision Institute
我们旨在为目标检测领域提供一种高效且性能出色的目标检测器,名为YOLO-MS。其核心设计基于一系列研究,这些研究探究了基础模块的多分支特征以及不同核大小的卷积如何影响不同尺度目标的检测性能。
PART/1
概述
研究结果催生了一种新策略,该策略能够显著增强实时目标检测器的多尺度特征表征能力。为验证我们工作的有效性,我们在MSCOCO数据集上从头开始训练YOLO-MS,不依赖任何其他大规模数据集(如ImageNet)或预训练权重。在不借助花里胡哨技巧的情况下,我们的YOLO-MS优于近期最先进的实时目标检测器,包括YOLO-v7、RTMDet和YOLO-v8。以YOLO-MS的XS版本为例,它在MSCOCO数据集上的平均精度(AP)得分能达到42%以上,比相同模型大小的RTMDet高出约2个百分点。此外,我们的工作还可作为一个即插即用的模块应用于其他YOLO模型。通常情况下,我们的方法能将YOLOv8-N的AP、小目标AP(APl)和大目标AP分别从18%以上、52%以上和37%以上显著提升至20%以上、55%以上和40%以上,且参数和乘加运算量(MACs)更少。
PART/2
背景
以YOLO系列为代表的实时目标检测器,在工业领域,尤其是在无人机和机器人等边缘设备上有着广泛的应用。与以往的目标检测器不同,实时目标检测器旨在追求速度与精度之间的最佳平衡。为此,人们提出了许多方法来开发高效且强大的实时目标检测架构。从第一代DarkNet到CSPNet,再到最近的扩展ELAN,实时目标检测器的架构发生了显著变化,性能也得到了快速提升。尽管这些工作取得了令人瞩目的成绩,但对实时目标检测器来说,识别不同尺度的目标仍然是一个根本性挑战。现有的实时目标检测器主要通过改进宏观结构来增强多尺度特征表示。通常,特征金字塔网络(FPN)、路径聚合网络(PAFPN)和收集-分发机制通过修改模型的颈部结构来改善不同尺度特征的聚合。尽管取得了成功,但这些方法忽视了在基础构建模块中学习多尺度特征表示的重要性。YOLO系列的最新进展引入了多分支结构,这可以看作是一种隐式学习多尺度特征的方法。然而,下图中的可视化和统计分析。

结果表明,它们的分支间特征被同质化了,这反映出可能缺乏多样的多尺度信息。针对上述问题提出的另一种解决方案是Res2Net的模块结构。尽管与上述模块相比,融入Res2Net的分层多分支结构能够丰富分支间特征的多样性,但如上图所示,它引入了与目标物体无关的干扰性空间信息,这可能会对检测性能产生不利影响。
接下来,我们重新思考了如何在多分支构建模块中对多尺度特征表示进行编码。我们认为,对于每个构建模块而言,除了像文献中那样对多尺度特征进行编码之外,动态聚合来自不同分支的不同粒度信息也至关重要。特征金字塔网络(FPN)中每个特征层级的检测头负责检测尺寸在一定范围内的物体,例如,对于边界框的短边来说,范围是从32到64。我们设计了一种全局查询学习(GQL)策略,并提出了一种名为MS-Block的新型构建模块。如图3所示,我们维护一个全局查询,用于存储每个分支的跨阶段空间表示。全局查询学习(GQL)使每个模块能够根据输入和阶段位置,动态平衡每个分支的影响。此外,与之前的实时目标检测器中对所有模块都使用相同的内核大小不同,我们在不同的MS-Block中提出了一种异构内核大小选择(HKS)协议,随着网络层数的加深,该协议会逐渐增大卷积的内核大小。具体来说,我们在浅层使用小内核卷积,以更高效地处理高分辨率特征,而在深层采用大内核卷积,以捕捉高级语义信息,从而更好地识别大物体。基于上述设计原则,我们提出了我们的实时目标检测器,称为YOLO-MS。为了评估我们的YOLO-MS的性能,我们在MSCOCO数据集上进行了全面的实验。我们还提供了与其他最先进方法的定量比较,以展示我们方法的出色性能。
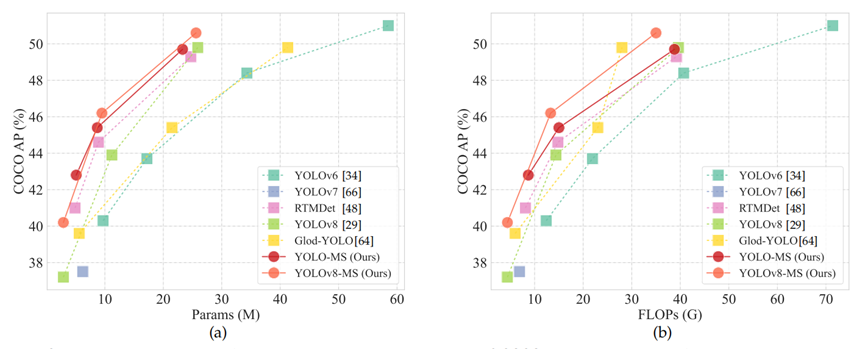
如上图所示,YOLO-MS在计算性能权衡方面优于其他近期的实时目标检测器。具体而言,我们的YOLO-MS-XS在MSCOCO数据集上达到了42.8%的平均精度(AP)分数,仅有510万个可学习参数和87亿次乘加运算(MACs)。此外,YOLO-MS-S和YOLO-MS分别达到了45.4%和52.1%的AP分数,可学习参数分别为870万和5080万,超过了基线模型RTMDet。此外,我们的工作还可以用作即插即用模块,为其他YOLO模型带来性能提升。典型的是,我们的方法将YOLOv8-n的AP从37%以上提升到了40%以上,且参数和乘加运算次数更少。
PART/3
新算法框架解析
作为现代目标检测器的一个关键方面,学习多尺度特征表示对检测性能有着显著影响。在本节中,为了构建一个具有强大多尺度能力的实时目标检测器,我们提出了MS-Block和HKS协议。我们的MS-Block包括一个增强的分层多分支结构,以提高分支间特征的多样性,同时还有全局查询学习(GQL),用于提供跨阶段指导,以减少有害的空间信息并增强多尺度表示。引入HKS协议是为了在实时目标检测器中高效且有效地融入大内核卷积,以实现更好的多尺度能力。下面重新思考基本构建模块中的多尺度特征学习如第1节所述,在两种流行的模块,即CSP和ELAN中,来自不同分支的特征之间存在冗余,这可能会降低多尺度表示能力。为了弥补这一不足,我们重新审视了之前实时目标检测器的基本模块设计,并在我们的MS-Block中采用了分层多分支结构,而不是CSP和ELAN。
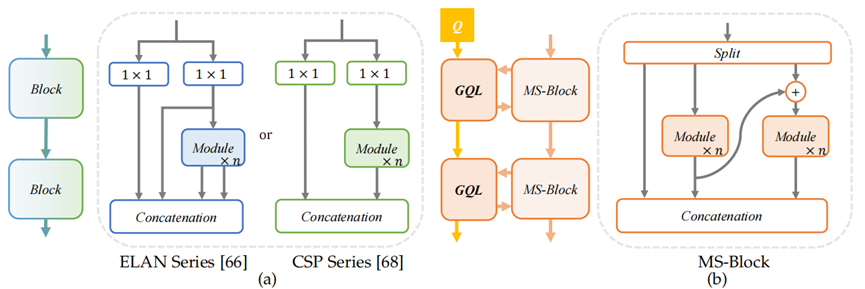
如上图所示,与CSP中的双分支结构和ELAN中类似并行的多分支结构相比,分层多分支结构使基本模块的每个分支都具有不同的感受野。这种分层多分支结构是Res2Net增强构建模块中不同尺度信息丰富度的关键。
全局查询学习
尽管在构建模块中引入上述分层结构能够使目标检测器捕捉到丰富的多尺度特征,但它忽略了对不同尺度物体的多尺度特征进行显式建模的重要性。Transformer中的注意力机制已被证明是一种有效的技术,用于在给定的查询Q和键K之间建立成对关系。受此启发,在本节中,我们提出了一种名为全局查询学习(GQL)的高效策略,旨在为基本模块提供跨阶段指导。如上图(b)所示,我们持有一个轻量级且可学习的全局查询,记为\(Q\in\mathbb{R}^{N\times\frac{c}{2}}\),它在不同阶段传递,将全局空间信息转换到每个模块中,以增加分支之间的多样性。其中\(N\)是分支的数量,\(c\)是\(Q\)的维度大小。它使得当前模块的空间信息\(K\)能够对权重进行索引,该权重用于根据所在阶段以及前一阶段的信息来安排每个分支的影响。请注意,为了在计算成本和有效性之间取得更好的平衡,我们仅在主干网络的第2、第3和第4阶段使用GQL。形式上如前面定义的,给定\(Y\in\mathbb{R}^{H\timesW\timesNC}\),我们的注意力模块的输出\(Y'\in\mathbb{R}^{H\timesW\timesNC}\)可以表示为:
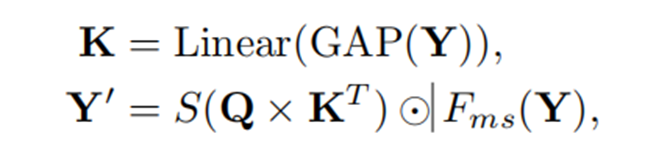
其中\(S\)表示sigmoid函数,\(GAP\)是全局平均池化操作,\(\odot\)是逐元素乘法,\(Linear\)表示用于提取空间信息的线性层。\(F_{ms}\)表示为增强分支间特征多样性而设计的多尺度模块,如上图(b)所示。借助全局平均池化(\(GAP\)),全局查询\(Q\)的计算量较小,使得我们提出的YOLO-MS的计算成本几乎可以忽略不计。

在上图中,我们展示了一些案例的可视化证据,以证明全局查询学习(GQL)有可能减少干扰性空间信息带来的负面影响。
异构内核大小选择协议
除了设计构建模块之外,我们还从宏观架构的角度深入研究了卷积的使用。尽管我们所使用的构建模块在多尺度能力方面有了很大的提升,但它们并没有充分探索不同内核大小的卷积的作用,尤其是对于大内核卷积,大内核卷积在基于卷积神经网络(CNN)的视觉识别任务模型中已被证明是有效的,但却被实时目标检测器所忽视。将大内核卷积融入实时目标检测器的主要障碍是计算开销,尤其是在较低的阶段。

如上表所示,将大内核卷积应用于高分辨率特征的计算成本很高,因此对低分辨率特征采用大内核卷积能更好地大幅降低计算成本。此外,以前的实时目标检测器大多在不同的编码器阶段采用相同的卷积(即内核大小相同的卷积),但我们认为这并不是提取多尺度语义信息的最佳选择。在金字塔架构中,从检测器浅层阶段提取的高分辨率特征通常用于捕捉细粒度的语义信息,这些信息用于检测小物体。相反,较深层阶段的低分辨率特征则用于捕捉高级语义信息,这些信息用于检测大物体。如果我们在所有阶段都采用统一的小内核卷积,那么深层阶段的有效感受野(ERF)就会受到限制,从而影响对大物体的检测性能。在每个阶段都融入大内核卷积有助于解决这一限制。不过,大内核卷积的有效感受野较大,会对更广泛的区域进行编码,从而增加了将小物体外部的干扰信息包含进来的可能性。根据上述分析,我们提出了一种异构内核大小选择(HKS)协议。HKS利用不同阶段的异构卷积来捕捉更丰富的多尺度特征。具体来说,我们从较低阶段到较高阶段逐渐增大内核大小。由于内核大小通常为奇数,我们从\(3×3\)开始,以\(2\)为步长来增大内核大小。根据该协议,从最浅层到最深层,卷积的内核大小分别为\(3\)、\(5\)、\(7\)和\(9\)。与之前的研究不同的是,我们还将这些设置扩展到了路径聚合特征金字塔网络(PAFPN)和检测头部分。
PART/4
新算法框架解析
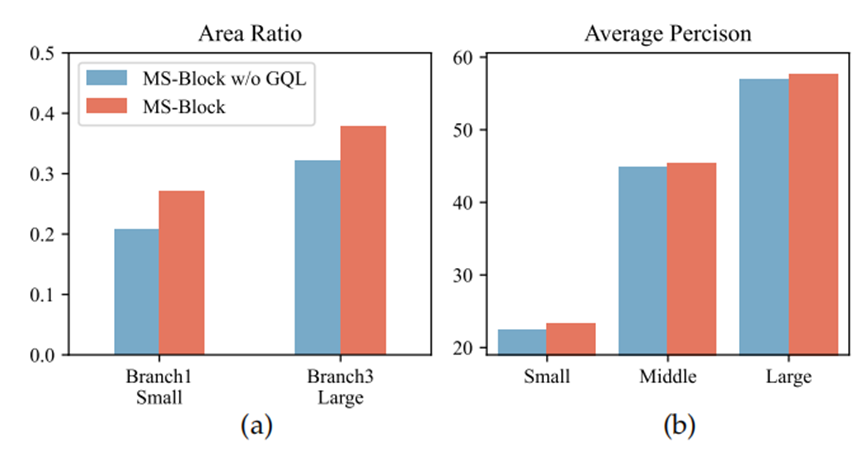
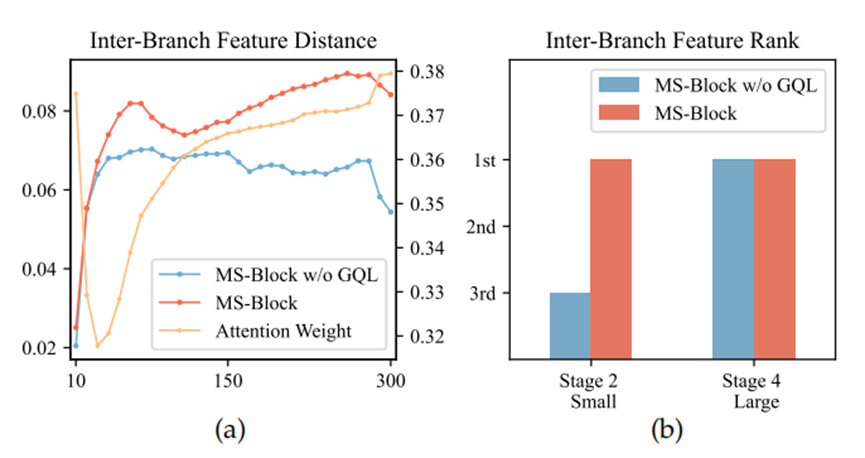
在下图(a)中,我们分别计算了第二阶段中具有最小感受野的第一个分支以及第四阶段中具有最大感受野的最后一个分支,在小物体和大物体的真实框(GTboxes)内高激活特征(值>0.5)的面积比例。下图(a)显示,特征图在与提取该特征图的阶段和分支相对应的物体尺度区域内,具有更多有影响力的激活值。这意味着从特征学习的角度来看,GQL能够使模型更准确地定位不同尺度的物体。在下图(b)中,我们展示了不同物体尺度的平均精度。直观地表明,我们的GQL在多尺度性能方面带来了明显的提升。
此外,在下图(a)中,我们可视化了训练过程中分支间特征距离的趋势以及GQL的注意力权重。为了简化,我们使用目标分支与其他分支之间的平均L1距离来展示变化情况。为了方便起见,我们只可视化目标分支相应权重值的变化趋势,该权重值代表目标分支在模块中的影响力。我们选择的目标分支是基于分支的感受野和阶段,例如,在第二阶段,左边的分支是目标分支,对应小物体。我们取所有阶段的平均结果进行比较。很明显,目标分支的注意力权重与特征距离的变化趋势相同,这进一步证明了GQL的有效性。在下图(b)中,我们比较了不同阶段每个分支之间特征图的平均激活值,并得到了排名值。使用GQL时,在浅层阶段,具有小感受野的左边分支表现出较大的特征激活值,反之亦然。这表明GQL自适应地重新调整了每个分支在相应阶段的作用,以最大化其影响力。
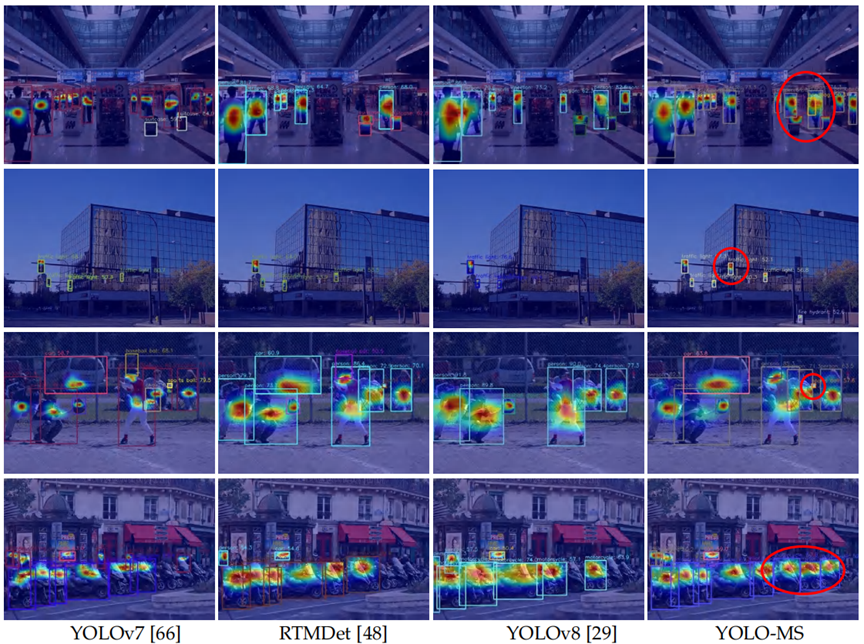
可视化结果如上图所示。YOLOV7-T、RTMDet-T和YOLOV8-N无法检测到小的、密集排列的物体,比如成群的摩托车和人群,并且会忽略其中的一部分。相反,YOLO-MS-XS在类别响应图中对所有物体都表现出强烈的响应,这表明它具有卓越的多尺度特征表示能力。此外,这突出显示了我们的检测器对于不同尺寸的物体以及包含各种密度物体的图像都能实现出色的检测性能。定量比较。在本节中,我们将YOLO-MS与当前最先进的目标检测器进行了比较。很明显,YOLO-MS在速度和准确性之间实现了出色的权衡。与性能第二好的微型检测器,即RTMDet相比,YOLO-MS-XS达到了42.8%的平均精度(AP),比使用ImageNet预训练模型的RTMDet高出1.8%。YOLO-MS-S达到了45.4%的AP,与RTMDet相比,在推理速度更快的情况下,AP提高了0.8%。此外,YOLO-MS的检测性能为49.7%AP,在参数数量和计算复杂度相近的情况下优于基线模型。
总之,YOLO-MS被证明是实时目标检测的一个很有前景的基线模型,它提供了强大的多尺度特征表示能力。在其他YOLO模型上的应用。我们提出的方法可以作为其他YOLO模型的即插即用模块。为了证明我们方法的泛化能力,我们将所提出的方法应用于RTMDet、YOLOv8、YOLOv9和YOLOv10。在MSCOCO数据集上的结果列于表9中。使用我们的方法,所有规模的基线模型的AP分数都能提高,并且参数数量和乘加运算次数(MACs)更少。具体来说,我们的方法将YOLOv8-N、YOLOv8-S和YOLOv8-M的AP分别从37.2%、43.9%和49.8%提高到了40.2%、46.2%和50.6%。此外,我们的方法提高了不同尺度物体的AP,这表明它在增强多尺度能力方面是有效的。
有相关需求的你可以联系我们!


END


转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
往期推荐
🔗

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)