NeuralNetwork:入门级Python神经网络库的全面解析
本文还有配套的精品资源,点击获取简介:本篇文章深入探讨了名为"NeuralNetwork"的Python库,专注于其在机器学习领域神经网络构建中的应用。该库以其简洁的接口和适合快速原型开发的特点,被推荐给初学者或小型项目。文章介绍了如何使用NeuralNetwork库创建和训练神经网络模型,包括数据预处理、模型训练与验证、超参数调整、模型保存与加载,以及...

简介:本篇文章深入探讨了名为"NeuralNetwork"的Python库,专注于其在机器学习领域神经网络构建中的应用。该库以其简洁的接口和适合快速原型开发的特点,被推荐给初学者或小型项目。文章介绍了如何使用 NeuralNetwork 库创建和训练神经网络模型,包括数据预处理、模型训练与验证、超参数调整、模型保存与加载,以及应用场景。同时,文章也探讨了该库的文件结构和内容,旨在帮助开发者理解神经网络的基本原理,并有效应用于实际问题中。 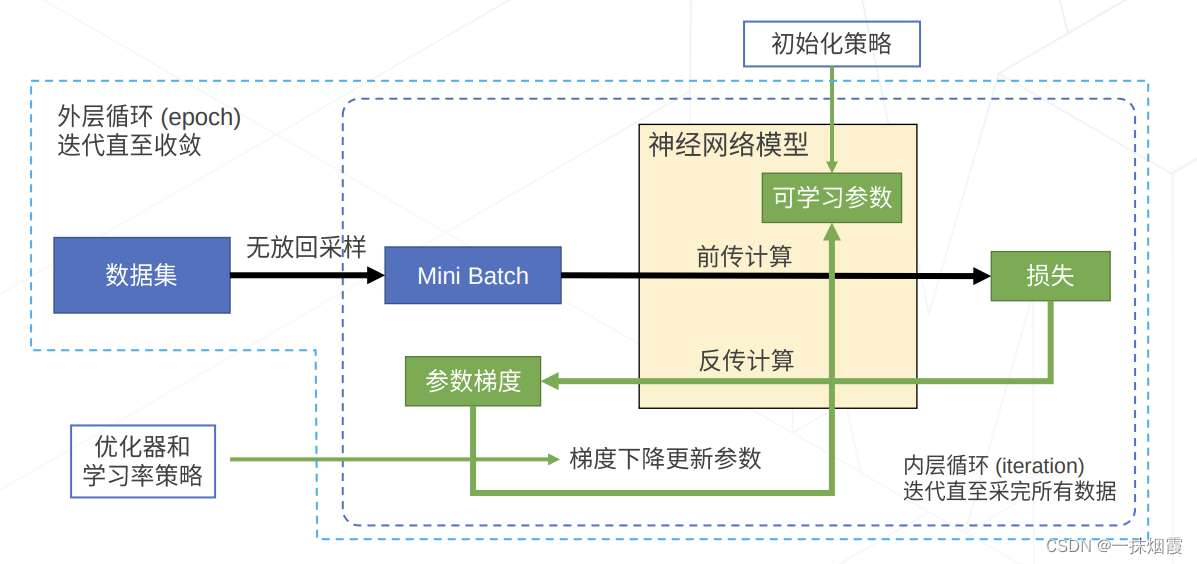
1. 神经网络基本概念与模拟人脑原理
1.1 神经网络的定义与结构
神经网络是一种受生物学启发的计算模型,模拟人脑神经元的连接和处理信息的方式。它由大量相互连接的节点(神经元)组成,节点之间通过带权重的连接(突触)进行通信。每个神经元通常会接收来自其他神经元的输入,经过一个激活函数处理后,再将结果传递给其他神经元。
1.2 模拟人脑的工作原理
在人脑中,神经元通过电脉冲进行信息传递,神经网络通过数学模型来模拟这一过程。基本单元神经元通过加权求和的方式来模拟脉冲的集成,然后通过一个非线性函数(如Sigmoid或ReLU)来模拟脉冲的发射。通过多层网络结构,可以模拟更复杂的逻辑关系,从而执行分类、回归等多种任务。
1.3 神经网络的主要类型
根据网络的拓扑结构和用途,神经网络可以分为多种类型,如前馈神经网络(多层感知机)、卷积神经网络(CNN)、递归神经网络(RNN)、长短期记忆网络(LSTM)等。不同的网络类型适用于不同的问题,如图像识别、自然语言处理、序列预测等。
通过理解这些基本概念,我们可以更深入地探究神经网络如何运作以及如何利用现有的库(例如NeuralNetwork)来实现高效的神经网络开发。
2. NeuralNetwork库介绍及其适合场景
NeuralNetwork库是专为简化神经网络开发而设计的,它封装了一系列深度学习模型的构建块。该库致力于提供易于使用、高度可定制的神经网络工具,以支持不同复杂度的机器学习任务。
2.1 NeuralNetwork库的核心功能与特点
2.1.1 核心功能解析
NeuralNetwork库提供了一系列工具和功能,用于构建、训练和部署神经网络。它的核心功能包括但不限于以下几点:
- 模型构建 :提供多种预定义的层(如全连接层、卷积层、循环层等)以及构建自定义层的工具。
- 训练与验证 :具备高效的训练机制,支持自动化的数据处理与批处理。
- 优化与正则化 :提供多种优化算法,包括SGD、Adam等,以及L1/L2正则化等方法减少过拟合。
- 模型保存与加载 :允许用户保存训练好的模型,并在之后加载进行预测或进一步的训练。
2.1.2 设计理念和应用场景
NeuralNetwork库的设计理念是将复杂深度学习模型的构建过程简化,使得开发者可以更专注于模型结构的设计和业务逻辑的实现。它非常适合以下场景:
- 原型开发 :快速搭建并测试各种神经网络原型。
- 教育与研究 :为教育者和研究人员提供一个易于理解的平台,用于教授和探索不同的神经网络结构。
- 工业应用 :用于构建满足实际工业需求的高效神经网络模型。
2.2 NeuralNetwork库的安装与配置
2.2.1 系统兼容性与安装步骤
NeuralNetwork库支持主流的操作系统,如Windows、Linux和macOS。为了保证最佳的性能和兼容性,建议使用最新版本的Python环境(Python 3.6以上)。
安装步骤如下:
- 打开终端或命令提示符窗口。
- 使用以下命令安装NeuralNetwork库:
pip install neuralnetwork
在安装过程中,可能需要管理员权限,这时可以使用 sudo 命令(在macOS和Linux上)或以管理员身份运行命令提示符(在Windows上)。
2.2.2 常见问题及解决方案
安装过程中可能会遇到的问题和相应的解决方案如下:
- 问题 :依赖缺失或不兼容问题。
-
解决方案 :使用
--force-reinstall参数强制重新安装有问题的依赖包,或使用--no-deps参数避免安装依赖包。 -
问题 :权限不足。
- 解决方案 :以管理员权限运行安装命令,或指定一个用户目录进行安装。
安装成功后,可以通过导入NeuralNetwork库并创建一个简单的模型来检查安装是否正常工作:
import neuralnetwork
# 创建一个简单的序贯模型
model = neuralnetwork.Sequential()
model.add(neuralnetwork.layers.Dense(units=1, input_dim=1))
***pile(loss='mean_squared_error', optimizer='sgd')
# 模型现在可以被训练和使用了
如果在执行上述代码时没有遇到任何错误,那么可以确认NeuralNetwork库已成功安装并可以使用了。
3. Python在神经网络开发中的优势
3.1 Python语言特点与神经网络开发契合度
3.1.1 Python的易用性和灵活性
Python语言以其简洁的语法和强大的功能,成为数据科学和机器学习领域最受欢迎的编程语言之一。Python的易用性主要体现在以下几个方面:
- 简洁的语法 :Python使用英文单词和明确的语法规则,对编程新手非常友好。对于复杂的数据处理和算法实现,Python简洁的语法可以大幅减少开发时间。
python # 示例代码:简单的Python打印语句 print("Hello, Neural Networks!") -
丰富的库支持 :Python拥有庞大的标准库和第三方库,如NumPy、Pandas等,这些库为处理数据提供了高效工具,特别是在数据预处理和分析方面。
-
动态类型系统 :Python是一种动态类型语言,这意味着变量在赋值时不需要声明类型,为快速原型设计提供了便利。
3.1.2 Python在数据科学领域的生态系统
Python的灵活性在于其强大的生态系统,这使得Python在数据科学领域具有巨大优势。数据科学领域的核心库如scikit-learn、TensorFlow、PyTorch等都提供了Python接口。Python的生态系统还包括以下几个方面:
-
数据处理 :Pandas库提供了高效的数据结构DataFrame和时间序列等,非常适合处理大规模数据集。
-
科学计算 :NumPy和SciPy库为高效的数组计算和矩阵运算提供了支持。
-
机器学习 :scikit-learn库提供了大量的机器学习算法,使得Python可以轻松地进行数据挖掘和分析。
-
深度学习 :TensorFlow和PyTorch等库支持构建和训练复杂的神经网络模型,是进行深度学习研究的利器。
-
可视化 :Matplotlib、Seaborn等库提供了丰富的数据可视化工具,帮助开发者更好地理解数据和模型结果。
-
交互式环境 :Jupyter Notebook提供了一个交互式的编程环境,可以方便地进行数据分析和模型实验。
3.2 Python神经网络开发工具对比
3.2.1 主要开发框架简介
目前,Python在神经网络开发中应用最多的框架包括TensorFlow、Keras、PyTorch和MXNet等。下面是这些框架的简介:
-
TensorFlow :由Google开发,支持大量的研究人员和开发者进行深度学习实验。TensorFlow拥有广泛的社区支持和丰富的资源。
-
Keras :最初由François Chollet开发,现在是TensorFlow的一个高级API。Keras设计用于快速实验,使得构建和训练神经网络变得容易。
-
PyTorch :由Facebook开发,以其动态计算图和Python风格的接口受到研究人员的青睐。
-
MXNet :由Apache基金会支持,是一个灵活高效的深度学习框架,支持多种编程语言。
3.2.2 NeuralNetwork与其他框架的对比
NeuralNetwork库是一个相对较新的框架,它在易用性和灵活性方面与现有的深度学习框架相比有其独特之处。下面是一些关键的对比点:
-
易用性 :NeuralNetwork库在API设计上追求简洁,旨在提供更加直观的接口,使得开发者能够更加快速地构建和训练模型。
-
性能 :在性能方面,NeuralNetwork库经过优化,能够提供与TensorFlow和PyTorch相当的性能表现。在某些情况下,针对特定的神经网络结构,NeuralNetwork能够提供更快的训练速度和更优的模型性能。
-
社区和资源 :尽管NeuralNetwork相对年轻,但它的开发者社区正在迅速增长,也逐步有更多教程和文档出现。
-
集成性 :NeuralNetwork可以很好地与现有的Python数据科学生态系统集成,支持NumPy、Pandas等常用数据处理库。
接下来的章节,我们将深入探讨NeuralNetwork库的设计理念和安装配置,以及如何在实际项目中应用该库来构建和优化神经网络模型。
4. ```
第四章:神经网络模型创建步骤详解
4.1 设计网络结构与选择激活函数
网络层类型和选择依据
构建一个神经网络模型时,网络层的类型和层次结构是决定模型性能的关键因素之一。常见的网络层类型包括全连接层(Dense Layer)、卷积层(Convolutional Layer)、循环层(Recurrent Layer)等。
- 全连接层 :适用于处理特征间关系较为独立的数据,如分类问题。
- 卷积层 :通常用于图像数据处理,能够有效提取空间特征。
- 循环层 :如长短时记忆网络(LSTM)和门控循环单元(GRU),适用于序列数据处理,如自然语言处理和时间序列分析。
选择网络层时,应考虑数据的特性及问题的复杂性。例如,对于图像识别问题,卷积层是首选,而对于复杂的序列决策问题,循环层可能更加适合。
激活函数的作用与选择标准
激活函数在神经网络中负责引入非线性因素,使得网络能够学习和表达复杂的函数关系。
- Sigmoid函数 :输出范围为(0,1),早期广泛用于输出层,由于其饱和性,在深层网络中的应用较少。
- Tanh函数 :输出范围为(-1,1),类似于Sigmoid,但其均值为0,通常性能略优于Sigmoid。
- ReLU函数 :输出范围为(0,+∞),由于计算简单且梯度稳定,目前大多数神经网络的隐藏层都选择使用ReLU及其变体。
- Leaky ReLU和PReLU :这些变体解决了ReLU在负区间的死亡问题,即神经元不再激活的情况。
- Softmax函数 :通常用于多分类问题的输出层,可以将输出转化为概率分布。
选择标准包括网络深度、问题类型及梯度消失/爆炸问题。通常推荐在隐藏层使用ReLU或其变体,并在输出层根据问题选择适合的激活函数。
from tensorflow.keras.layers import Dense, ReLU
from tensorflow.keras.models import Sequential
# 一个简单的多层全连接神经网络模型示例
model = Sequential()
model.add(Dense(64, activation='relu', input_shape=(input_dim,)))
model.add(Dense(32, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
在上面的代码中, input_dim 表示输入数据的特征数, num_classes 表示分类任务的类别数。模型中使用了ReLU激活函数,适用于隐藏层,而Softmax则被用于输出层。
4.2 编译模型与设置优化器
损失函数的理解与应用
损失函数(Loss Function)是衡量模型预测值与真实值之间差异的函数,它是神经网络训练过程中优化的核心目标。
- 均方误差(MSE) :常用于回归问题,衡量预测值与真实值的平方差的均值。
- 交叉熵(Cross Entropy) :常用于分类问题,衡量两个概率分布之间的差异。
- Categorical Cross Entropy :适用于多分类问题,它考虑了类别概率分布。
- Binary Cross Entropy :适用于二分类问题,计算预测值与真实值之间概率分布的差异。
选择损失函数时,应结合具体问题类型和数据的特性。
优化器的选择和调整
优化器(Optimizer)负责根据损失函数调整网络权重,以最小化损失。
- 随机梯度下降(SGD) :基于梯度下降的简化版本,适用于小规模数据集。
- Adam :一种自适应学习率的方法,结合了RMSprop和SGD的优势,广泛推荐。
- Adagrad :学习率根据参数的更新频率进行调整。
- RMSprop :调整学习率,特别适用于非稳定梯度的深度神经网络。
- Adadelta :改进了Adagrad的学习率调整方法,减少了学习率单调递减的问题。
在实际应用中,Adam优化器由于其良好的性能和鲁棒性,通常是首选。
from tensorflow.keras.optimizers import Adam
# 编译模型时设置优化器
***pile(optimizer=Adam(), loss='categorical_crossentropy', metrics=['accuracy'])
在本例中, ***pile 函数用于编译模型,指定了优化器、损失函数及性能评估指标。选择Adam优化器,并使用 categorical_crossentropy 作为损失函数,因为这通常用于多分类问题。另外,模型的性能评估指标包括准确率(accuracy)。
5. 数据预处理方法
数据预处理是任何机器学习项目中至关重要的一步,特别是在神经网络的训练中,好的数据预处理可以显著提高模型的性能和收敛速度。在本章节中,我们将详细介绍数据清洗与特征提取、数据归一化与增强等关键步骤。
5.1 数据清洗与特征提取
5.1.1 数据清洗的常用方法
在处理真实世界的数据时,经常遇到噪声和缺失值等问题。数据清洗的目的是提高数据质量,为后续的分析和模型训练提供更可靠的基础。
- 缺失值处理:使用平均值、中位数、众数或预测模型进行填充。
- 异常值处理:通过箱线图、Z-Score等方法识别异常值,并决定是删除还是替换。
- 噪声数据去除:利用滤波算法,如移动平均滤波或中值滤波,来平滑数据。
import pandas as pd
# 示例:处理缺失值
data = pd.DataFrame({
'feature1': [1, 2, 3, None, 5],
'feature2': [None, 2, None, 4, 5]
})
# 使用均值填充缺失值
data_filled = data.fillna(data.mean())
5.1.2 特征工程的基本技巧
特征工程是指从原始数据中提取有用信息,并构造模型可以理解的特征的过程。有效的特征工程可以提高模型的准确性和效率。
- 特征编码:将类别型数据转换为模型可接受的数值型数据。
- 特征构造:基于现有数据构造新的特征,如多项式特征、交互特征等。
- 特征选择:使用特征重要性评估或模型选择方法,确定最有用的特征子集。
from sklearn.preprocessing import OneHotEncoder
# 示例:使用OneHot编码进行类别特征转换
encoder = OneHotEncoder()
data_encoded = encoder.fit_transform(data[['feature2']])
5.2 数据归一化与增强
5.2.1 归一化的意义与方法
数据归一化是将特征缩放到统一的数值范围内,这有助于避免在梯度下降中由于数据尺度差异导致的问题,加快模型训练的收敛速度。
- 最小-最大归一化:将特征缩放到[0, 1]区间。
- Z-Score标准化:将数据转换为均值为0,标准差为1的分布。
from sklearn.preprocessing import MinMaxScaler, StandardScaler
# 示例:最小-最大归一化
scaler = MinMaxScaler()
data_normalized = scaler.fit_transform(data_encoded.toarray())
5.2.2 数据增强的策略和实现
数据增强主要用于增加训练数据的多样性,特别是在图像、语音等领域。它可以帮助模型减少过拟合,提高模型的泛化能力。
- 图像增强:包括旋转、翻转、缩放等操作。
- 特征空间增强:通过添加噪声、进行特征扩展等方式。
import numpy as np
# 示例:简单特征空间增强
data_augmented = np.vstack((data_normalized, data_normalized + np.random.normal(0, 0.1, data_normalized.shape)))
第五章到此结束,我们探讨了数据预处理的关键步骤和方法,下一章将继续深入模型训练与验证流程。
简介:本篇文章深入探讨了名为"NeuralNetwork"的Python库,专注于其在机器学习领域神经网络构建中的应用。该库以其简洁的接口和适合快速原型开发的特点,被推荐给初学者或小型项目。文章介绍了如何使用 NeuralNetwork 库创建和训练神经网络模型,包括数据预处理、模型训练与验证、超参数调整、模型保存与加载,以及应用场景。同时,文章也探讨了该库的文件结构和内容,旨在帮助开发者理解神经网络的基本原理,并有效应用于实际问题中。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐


 19
19 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)