ACM MM2023 | STM | 利用任意风格迁移提高对抗样本的可迁移性
本文 “Improving the Transferability of Adversarial Examples with Arbitrary Style Transfer” 提出了一种基于任意风格迁移的对抗攻击方法(STM),旨在提升对抗样本的可迁移性,应对深度神经网络在对抗攻击下的安全问题。
Improving the Transferability of Adversarial Examples with Arbitrary Style Transfer
本文 “Improving the Transferability of Adversarial Examples with Arbitrary Style Transfer” 提出了一种基于任意风格迁移的对抗攻击方法(STM),旨在提升对抗样本的可迁移性,应对深度神经网络在对抗攻击下的安全问题。
摘要-Abstract
Deep neural networks are vulnerable to adversarial examples crafted by applying human-imperceptible perturbations on clean inputs. Although many attack methods can achieve high success rates in the white-box setting, they also exhibit weak transferability in the black-box setting. Recently, various methods have been proposed to improve adversarial transferability, in which the input transformation is one of the most effective methods. In this work, we notice that existing input transformation-based works mainly adopt the transformed data in the same domain for augmentation. Inspired by domain generalization, we aim to further improve the transferability using the data augmented from different domains. Specifically, a style transfer network can alter the distribution of low-level visual features in an image while preserving semantic content for humans. Hence, we propose a novel attack method named Style Transfer Method (STM) that utilizes a proposed arbitrary style transfer network to transform the images into different domains. To avoid inconsistent semantic information of stylized images for the classification network, we fine-tune the style transfer network and mix up the generated images added by random noise with the original images to maintain semantic consistency and boost input diversity. Extensive experimental results on the ImageNet-compatible dataset show that our proposed method can significantly improve the adversarial transferability on either normally trained models or adversarially trained models than state-of-the-art input transformation-based attacks.
深度神经网络容易受到对抗样本的影响,这些对抗样本是通过在干净的输入上施加人类难以察觉的扰动生成的。尽管许多攻击方法在白盒设置下能够取得较高的成功率,但在黑盒设置下,它们的可迁移性却较弱。最近,人们提出了各种方法来提高对抗样本的可迁移性,其中输入变换是最有效的方法之一。在这项工作中,我们注意到现有的基于输入变换的研究主要采用同一域内的变换数据进行增强。受域泛化的启发,我们旨在利用从不同域增强的数据来进一步提高可迁移性。具体来说,风格迁移网络可以改变图像中低级视觉特征的分布,同时为人类保留语义内容。因此,我们提出了一种名为风格迁移方法(STM)的新型攻击方法,该方法利用一种任意风格迁移网络将图像变换到不同的域。为了避免风格化图像在分类网络中的语义信息不一致,我们对风格迁移网络进行微调,并将添加了随机噪声的生成图像与原始图像混合,以保持语义一致性并增加输入的多样性。在与ImageNet兼容的数据集上进行的大量实验结果表明,与最先进的基于输入变换的攻击方法相比,我们提出的方法在正常训练的模型和对抗训练的模型上都能显著提高对抗样本的可迁移性。
引言-Introduction
这部分主要介绍研究背景和动机,阐述深度神经网络(DNNs)在取得优异性能的同时,易受对抗样本攻击,且现有攻击方法在黑盒攻击场景下存在局限性,由此引出利用不同域数据提升对抗样本迁移性的新方法,具体内容如下:
- 深度神经网络的对抗样本问题:DNNs在图像分类、人脸识别和自动驾驶等计算机视觉任务中表现出色。然而,大量研究表明其易受对抗样本影响,即在干净输入上添加人类难以察觉的扰动就能使模型分类错误。并且,对抗样本具有跨模型迁移性,这给关键安全应用带来严重威胁。了解对抗样本的迁移性有助于提升神经网络应用在现实中的安全性。
- 现有攻击方法的局限性:虽然一些攻击方法在白盒攻击设置下攻击性能良好,但在攻击黑盒模型时,尤其是面对先进防御模型,迁移性较低。为提升对抗样本迁移性,研究人员提出多种方法,如在迭代梯度攻击中引入动量优化、利用源模型集成以及输入变换等。其中,输入变换是通过数据变换提升迁移性的有效方法,但现有基于输入变换的方法主要在同一源域内进行数据增强,可能限制了对抗样本的迁移性。
- 研究动机与创新点:研究发现域偏差会影响模型的泛化能力,类似地,不同模型间也存在域偏差,这限制了对抗样本的迁移性。在域泛化领域,已有研究通过使用不同域的数据训练模型来解决域偏差问题,提升模型泛化能力。受此启发,文章提出利用不同域的数据提升对抗样本迁移性。由于获取不同域数据成本较高,而风格迁移技术的发展为解决这一问题提供了可能。基于此,文章提出一种新的攻击方法——风格迁移方法(STM),通过任意风格迁移网络将数据变换到不同域,以提升对抗样本迁移性。该方法在生成对抗样本时,不是直接使用风格化图像进行攻击,而是利用其梯度信息获取更有效的对抗扰动。同时,通过微调风格迁移网络和混合原始图像与风格化图像,避免风格化图像误导代理模型,确保语义一致性,提高攻击成功率。

图1:各种基于输入变换的攻击方法所生成的两幅变换图像示例。我们的STM方法通过使用风格增强模块生成一些不同域的图像,与现有基于变换的攻击方法相比,这些图像与原始干净图像风格不同,但能保持语义内容不变。
相关工作-Related Work
这部分主要介绍了对抗攻击和基于风格迁移的域泛化的相关研究,为提出的STM方法提供研究背景和思路,具体内容如下:
- 对抗攻击
- 攻击方法发展:自Szegedy等人发现对抗样本后,涌现出许多生成对抗样本的攻击方法。Goodfellow等人提出快速梯度符号法(FGSM),Kurakin等人将其扩展为迭代版本I-FGSM,在白盒设置下攻击成功率较高。黑盒攻击更具实际意义,其中基于查询的攻击效率低,基于迁移的攻击通过在代理模型上生成对抗样本,实用性强,备受关注。
- 提升迁移性的方法:I-FGSM在黑盒攻击中迁移性低,为提升对抗样本迁移性,研究人员提出多种方法。如Liu等人的集成模型攻击,Dong等人将动量集成到I-FGSM中形成MI-FGSM,Lin等人采用Nesterov加速梯度,Wang等人考虑梯度方差或增强动量等。此外,受数据增强策略启发,还出现了多种输入变换方法,如 DIM 通过随机调整大小和填充生成可迁移对抗样本,TIM 利用平移图像优化对抗扰动,SIM 利用DNNs的尺度不变性平均梯度更新对抗样本,Admix 混合不同类别图像生成对抗样本,S 2 ^{2} 2IM 在频域对输入图像进行变换生成对抗样本。
- 基于风格迁移的域泛化
- 域偏差问题及解决方法:DNNs的成功依赖于训练和测试数据同分布的假设,当该假设不成立时,模型性能会下降,即存在域偏差问题。解决域偏差的方法有迁移学习、域适应和域泛化。迁移学习需重用预训练网络架构并谨慎应用层冻结;域适应通过最小化源域和目标域特征域之间的距离,使模型适应特定目标域;域泛化旨在通过学习不同域的数据,提升模型在未见域上的泛化能力。
- 风格迁移在域泛化中的应用:近年来,多种风格增强方法被用于探索域泛化。Wang等人提出风格互补模块生成风格化图像,增强模型在未见目标域上的泛化能力;Jackson等人提出基于数据增强的随机风格迁移,提高卷积神经网络的鲁棒性,增强对域迁移的抵抗能力。受这些研究启发,文章假设引入不同域数据制作对抗样本,也能提升对抗样本的迁移性。
方法-Methodology
预备知识-Preliminaries
这部分内容主要介绍了一些预备知识,包括对抗攻击的基本概念、符号表示,以及两种基于输入变换的攻击方法Admix和S 2 ^{2} 2IM,为后续理解研究内容和方法奠定基础,具体如下:
- 对抗攻击相关概念及符号:给定分类器 f ( x ; θ ) f(x ; \theta) f(x;θ),其中 θ \theta θ 为参数,良性输入图像 x x x 对应真实标签 y y y, J ( x , y ; θ ) J(x, y ; \theta) J(x,y;θ) 表示损失函数(如交叉熵损失)。对抗攻击主要有非针对性攻击和针对性攻击两类。非针对性攻击旨在寻找满足 ∥ x − x a d v ∥ p ≤ ϵ \left\|x - x^{adv}\right\|_{p} \leq \epsilon x−xadv p≤ϵ 的对抗样本 x a d v x^{adv} xadv,使分类器误判( f ( x a d v ; θ ) ≠ y f(x^{adv} ; \theta) \neq y f(xadv;θ)=y );针对性攻击则是让分类器将对抗样本误判为特定标签 y ∗ y^{*} y∗( f ( x a d v ; θ ) = y ∗ f(x^{adv} ; \theta) = y^{*} f(xadv;θ)=y∗ )。这里 ϵ \epsilon ϵ 是最大扰动幅度, y ∗ y^{*} y∗ 是目标标签, p p p 可取 0 0 0、 2 2 2 或 ∞ \infty ∞,本文中 p = ∞ p = \infty p=∞.
- 基于输入变换的攻击方法
- Admix攻击方法:Admix通过混合从其他类别随机采样的一组图像,并保留输入的原始标签来生成更具迁移性的对抗样本。该方法可与SIM方法结合,其平均梯度计算公式为 g ‾ t = 1 m 1 ⋅ m 2 ∑ x ′ ∈ X ′ ∑ i = 0 m 1 − 1 ∇ x t a d v J ( ( x t a d v + η ⋅ x ′ ) / 2 i , y ; θ ) \overline{g}_{t}=\frac{1}{m_{1} \cdot m_{2}} \sum_{x' \in X'} \sum_{i=0}^{m_{1}-1} \nabla_{x_{t}^{adv}} J\left(\left(x_{t}^{adv}+\eta \cdot x'\right) / 2^{i}, y ; \theta\right) gt=m1⋅m21∑x′∈X′∑i=0m1−1∇xtadvJ((xtadv+η⋅x′)/2i,y;θ) 。其中, η \eta η 控制混合图像的强度, m 1 m_{1} m1 是每个 x ′ x' x′ 的混合图像数量, X ′ X' X′ 表示从其他类别随机采样的 m 2 m_{2} m2 个图像的集合。
- S 2 ^{2} 2IM攻击方法:S 2 ^{2} 2IM 对输入数据应用频谱变换,在频域进行模型增强。它基于离散余弦变换( D D D)和逆离散余弦变换( D I D_{I} DI)技术使输入图像多样化。其平均梯度计算公式为 g ‾ t = ∇ x t a d v J ( T ( x t a d v ) , y ; θ ) \overline{g}_{t}=\nabla_{x_{t}^{adv}} J\left(\mathcal{T}\left(x_{t}^{adv}\right), y ; \theta\right) gt=∇xtadvJ(T(xtadv),y;θ) ,其中 T ( x ) = D I ( D ( x + ξ ) ⊙ M ) \mathcal{T}(x)=D_{I}(D(x+\xi) \odot M) T(x)=DI(D(x+ξ)⊙M) , ⊙ \odot ⊙ 是哈达玛积, ξ ∼ N ( 0 , σ 2 ) \xi \sim N(0, \sigma^{2}) ξ∼N(0,σ2) , M M M 的每个元素 M i j ∼ U ( 1 − ρ , 1 + ρ ) M_{ij} \sim U(1 - \rho, 1 + \rho) Mij∼U(1−ρ,1+ρ) ,分别从高斯分布和均匀分布中随机采样。
- 方法集成:上述基于输入变换的攻击方法通常会与MI - FGSM方法集成。在MI - FGSM中, g t + 1 = μ ⋅ g t + g ‾ t ∥ g ‾ t ∥ 1 g_{t + 1}=\mu \cdot g_{t}+\frac{\overline{g}_{t}}{\left\| \overline{g}_{t}\right\| _{1}} gt+1=μ⋅gt+∥gt∥1gt( g 0 = 0 g_{0}=0 g0=0 ),通过 x t + 1 a d v = x t a d v + ϵ ⋅ s i g n ( g t + 1 ) x_{t + 1}^{adv}=x_{t}^{adv}+\epsilon \cdot sign(g_{t + 1}) xt+1adv=xtadv+ϵ⋅sign(gt+1) 生成对抗样本。
动机-Motivation
该部分主要阐述了提出STM方法的原因和思路,具体内容如下:
- 现有提升攻击迁移性方法的角度:Lin等人将对抗样本生成类比于标准神经网络训练,认为对抗样本的迁移性与正常训练模型的泛化性相关。因此,现有提升攻击迁移性的方法主要从优化(如在迭代梯度攻击中引入动量、采用Nesterov加速梯度、考虑梯度方差等)或数据增强(如随机调整大小和填充、平移图像、混合不同类别图像、在频域变换等)的角度出发。
- 域偏差对模型和对抗样本迁移性的影响:本文作者注意到域偏差问题会影响正常训练模型的泛化能力,例如特定数据域训练的模型难以在其他域数据集上良好泛化,即使相同架构的网络在不同域数据集上训练也会导致模型参数差异,进而产生域偏差。在黑盒攻击场景中,由于黑盒模型与源模型的结构差异,域偏差同样存在,这限制了对抗样本的迁移性。
- 提出STM方法的启发与思路:在域泛化领域,有研究通过使用不同域的数据训练模型来解决域偏差问题,提升模型泛化能力。然而,作者发现之前基于输入变换的方法主要在同一源域内进行数据增强,这可能限制了对抗样本的迁移性。受此启发,作者提出利用不同域的数据来提升对抗样本迁移性。得益于风格迁移模型和相关研究的发展,获取不同域数据变得相对容易,基于此,作者提出了风格迁移方法(STM),通过任意风格迁移网络将数据变换到不同域,在生成对抗样本时主要利用风格化图像的梯度信息获取更有效的对抗扰动,以提升对抗样本的迁移性。
风格迁移方法-Style Transfer Method
该部分详细介绍了风格迁移方法(STM),包括任意风格迁移、保持风格化图像语义一致性的措施及算法流程,具体内容如下:
- 任意风格迁移:STM核心组件是风格迁移网络 S T ( − ) ST(-) ST(−),配合风格预测网络 P ( ⋅ ) P(\cdot) P(⋅) 工作。 P ( ⋅ ) P(\cdot) P(⋅) 将风格图像 s s s 映射为风格嵌入 z = P ( s ) z = P(s) z=P(s),通过条件实例归一化影响 S T ( − ) ST(-) ST(−) 生成特定风格图像。为适应对抗样本生成,简化流程,用标准正交分布向量 N ( 0 , 1 ) \mathcal{N}(0, 1) N(0,1) 替代风格嵌入向量 z z z,在对抗样本生成的第 t t t 次迭代时,获取任意风格图像的公式为 x s = S T ( x t a d v , z ) , z = N ( 0 , 1 ) x_{s}=ST\left(x_{t}^{adv}, z\right), z=\mathcal{N}(0,1) xs=ST(xtadv,z),z=N(0,1).
- 保持风格化图像的语义一致性
- 微调风格迁移网络:风格迁移网络虽能保留语义内容,但改变图像低级特征可能导致风格化图像语义标签变化,误导代理模型,影响对抗攻击成功率。因此,使用集成多个分类模型(如Inception-v3、Inception-v4、ResNet-101和ResNet-152)的分类器微调风格迁移网络。定义微调损失函数 L ( x ) = ∑ i = 1 k w k J k ( S T ( x , z ) , y ; θ ) L(x)=\sum_{i=1}^{k} w_{k} J_{k}(ST(x, z), y ; \theta) L(x)=∑i=1kwkJk(ST(x,z),y;θ) ,其中 J k ( ⋅ ) J_{k}(\cdot) Jk(⋅) 是第 k k k 个模型的交叉熵损失, ∑ i = 1 k w k = 1 \sum_{i=1}^{k} w_{k}=1 ∑i=1kwk=1 为集成权重。通过梯度下降最小化损失函数,更新风格迁移网络参数。
- 混合图像与添加噪声:微调后,为进一步避免语义标签不一致产生不精确梯度,将原始图像 x x x 与风格化图像 x s x_{s} xs 按公式 x ‾ = γ ⋅ x + ( 1 − γ ) ⋅ x s \overline{x}=\gamma \cdot x+(1-\gamma) \cdot x_{s} x=γ⋅x+(1−γ)⋅xs 混合( γ ∈ [ 0 , 1 ] \gamma \in[0,1] γ∈[0,1] 为混合比例) 。同时,在混合后的图像上添加随机噪声 r ∼ U [ − ( β ⋅ ϵ ) d , ( β ⋅ ϵ ) d ] r \sim U[-(\beta \cdot \epsilon)^{d},(\beta \cdot \epsilon)^{d}] r∼U[−(β⋅ϵ)d,(β⋅ϵ)d]( β \beta β 为给定参数),增强对抗样本迁移性。
- 算法流程:STM算法输入为干净图像 x x x、代理分类器参数 θ \theta θ 和损失函数 J J J 等;参数包括扰动幅度 ϵ \epsilon ϵ、最大迭代次数 T T T 等。算法通过迭代计算,每次迭代中获取随机风格化图像,与原始图像混合后计算梯度,更新对抗样本,最终输出对抗样本 x a d v x^{adv} xadv 。
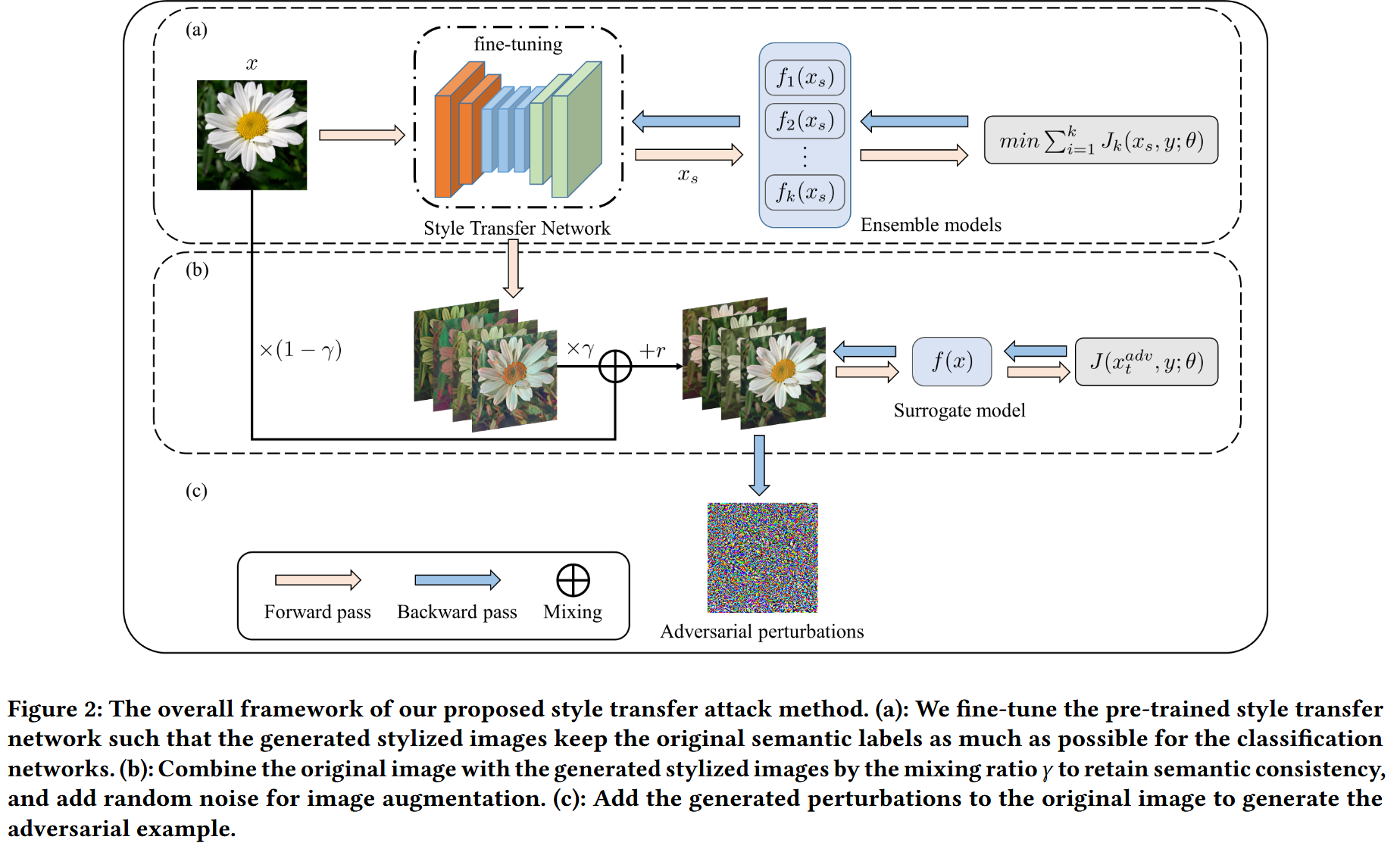
图2:我们所提出的风格迁移攻击方法的整体框架。
( a ):我们对预训练的风格迁移网络进行微调,使得生成的风格化图像在分类网络中尽可能多地保留原始语义标签。
( b ):按照混合比例 γ γ γ 将原始图像与生成的风格化图像进行混合,以保持语义一致性,并添加随机噪声来增强图像多样性。
( c ):将生成的扰动添加到原始图像上,从而生成对抗样本。
与其他方法的不同-Differences with Other Methods
该部分主要对比了STM方法与其他基于输入变换的攻击方法的差异,突出了STM方法的特点,具体内容如下:
- 数据域的使用差异:与DIM、TIM、SIM、Admix和S 2 ^{2} 2IM等方法不同,STM引入从不同域生成的数据来增强对抗样本的迁移性。而上述其他方法主要采用同一域内的变换数据进行增强,这种在相同域内的数据增强方式可能限制了对抗样本的迁移性,STM则突破了这一局限,通过引入不同域数据来提升迁移性。
- 增强方式的差异:STM通过混合原始图像内容来保留部分原始信息,在提升迁移性的同时维持一定的语义一致性。Admix方法是通过混合不同类别的图像来获取图像多样性,与STM的增强方式不同。S 2 ^{2} 2IM是在频域对图像进行变换来实现增强,STM则是基于数据集低级特征的统计差异引入不同域的图像,二者增强途径不同 。
实验-Experiments
这部分主要通过一系列实验验证了STM方法的有效性,包括实验设置、对不同模型的攻击实验以及消融研究,具体内容如下:
-
实验设置
- 数据集:采用广泛应用的ImageNet兼容数据集,包含1,000张尺寸为299×299×3的图像,有真实标签和用于针对性攻击的目标标签。
- 模型:选择多个流行的预训练模型,如Inception-v3(Inc-v3)、ResNet-50、ResNet-152等,还考虑了对抗训练模型,如Inc-v3 e n s 3 _{ens3} ens3、Inc-v3 e n s 4 _{ens4} ens4和IncRes-v2 e n s _{ens} ens ,以此全面测试STM方法的性能。
- 基线方法:选取五种基于输入变换的先进攻击方法DIM、TIM、SIM、Admix、S 2 ^{2} 2IM作为基线,这些方法均与MI-FGSM相结合。
- 超参数设置:对各方法的超参数进行设定,如STM的混合比例 γ = 0.5 \gamma = 0.5 γ=0.5、噪声上限 β = 2.0 \beta = 2.0 β=2.0、风格迁移图像数量 N = 20 N = 20 N=20 等,为实验的公平对比提供保障。
-
攻击实验
-
攻击单个模型:将STM与其他输入变换攻击方法对比,在Inc-v3、Inc-v4、IncRes-v2和Res-101等模型上生成对抗样本并测试攻击成功率。结果显示,STM在黑盒模型上能有效提高攻击成功率,在对抗训练模型上优势更明显,平均攻击成功率比其他方法至少高7.45%。
表1:在单模型设置下,各种基于输入变换的攻击方法的非针对性攻击成功率(%)。对抗样本分别由DIM、TIM、SIM、Admix、(S^{2}IM)和我们的STM攻击方法在Inception-v3(Inc-v3)、Inception-v4(Inc-v4)、Inception-ResNet-v2(IncRes-v2)和ResNet-101上生成。 ∗ * ∗ 表示白盒模型。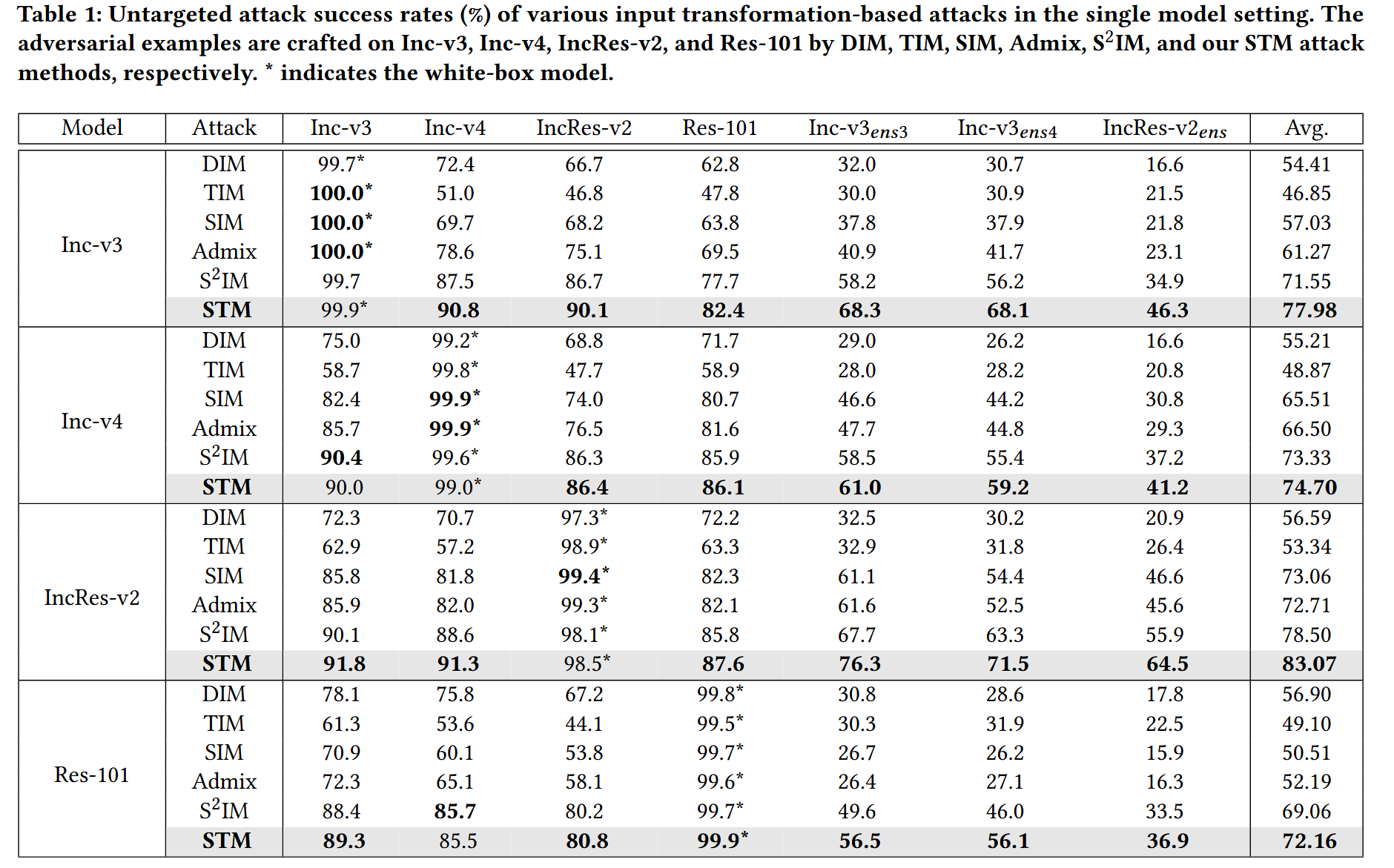
-
攻击集成模型:采用集成模型攻击方式,融合多个模型的logit输出。在集成Inc-v3、Inc-v4和IncRes-v2模型生成对抗样本,并在多个模型上测试迁移性。STM在黑盒设置中攻击成功率最高,平均成功率达90.3%,比S 2 ^{2} 2IM高4.92%,且对所有对抗训练模型的攻击成功率均超80%。
表2:在多模型设置下,各种基于输入变换的攻击方法对黑盒模型的非针对性攻击成功率(%)。对抗样本是在集成模型(即Inc-v3、Inc-v4和IncRes-v2)上生成的。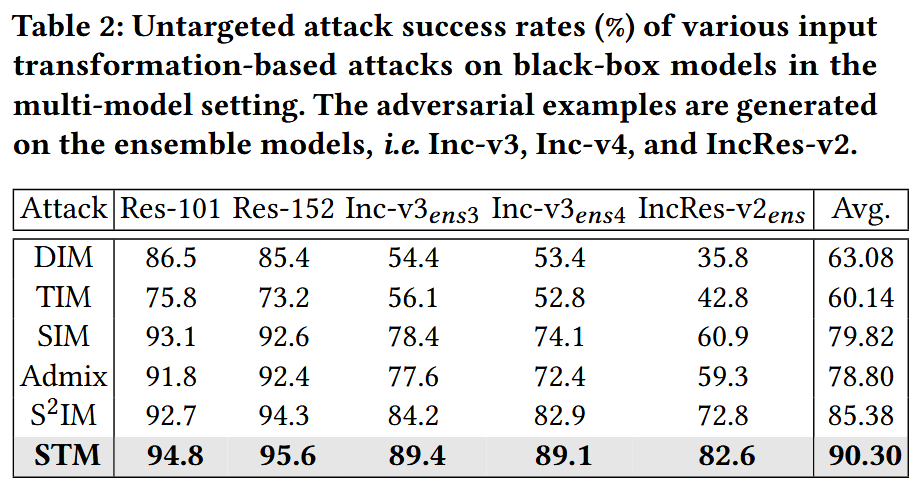
-
与其他输入变换攻击结合:STM可与其他输入变换攻击方法结合提升对抗样本迁移性。将STM和S 2 ^{2} 2IM分别与DIM、TIM、SIM结合,在Inc-v3模型上生成对抗样本并在六个黑盒模型上测试。结果表明,STM结合其他方法时性能更优,平均比S 2 ^{2} 2IM分别高出3.24%、2.6%和3.87%,在对抗训练的集成模型上效果更显著。
表3:S 2 ^{2} 2IM和我们的STM分别与DIM、TIM和SIM相结合时的非针对性攻击成功率(%)。对抗样本在Inc-v3上生成。 ∗ * ∗表示白盒模型。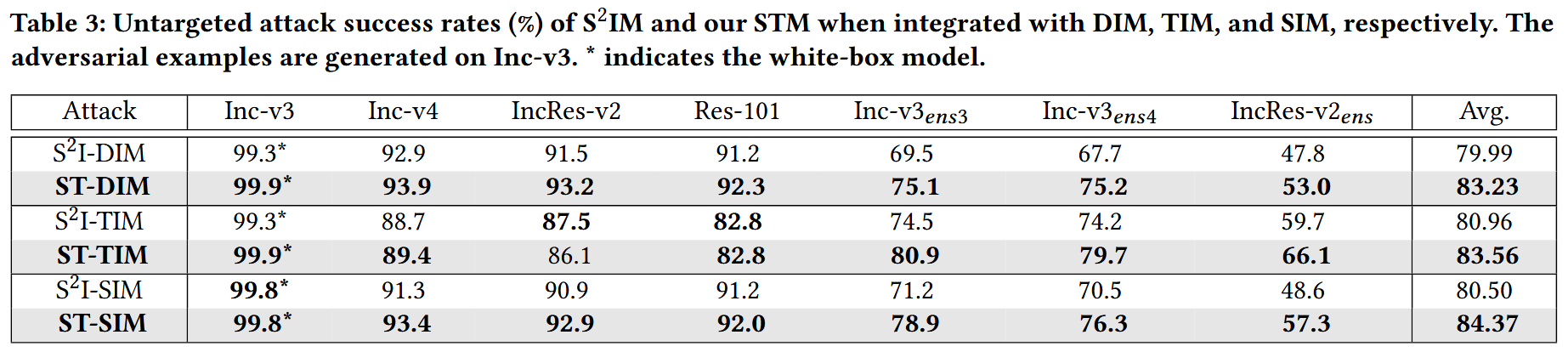
-
攻击防御模型:在包含Bit-Red、ComDefend等多种防御模型上验证STM的有效性。在集成Inc-v3、Inc-v4和IncRes-v2模型生成对抗样本的设置下,STM表现出色,平均成功率比Admix和S 2 ^{2} 2IM分别高17.8%和7.2%,对先进防御模型构成更大威胁。
表4:对六种防御模型的非针对性攻击成功率(%)。对抗样本是在集成模型(即Inception-v3、Inception-v4和Inception-ResNet-v2)上生成的。
-
-
消融研究:针对STM中微调风格迁移网络和混合原始图像这两个关键策略进行消融实验。结果表明,这两个策略均有助于提高对抗样本的迁移性,混合原始图像内容对维持语义一致性、避免产生不精确梯度信息作用显著,结合所有策略时STM性能最佳,验证了STM设计的合理性。
表5:ImageNet兼容数据集在原始图像以及通过不同策略(如图像风格转换、微调模型和混合原始图像内容)变换后的图像上的分类准确率(%)。
表6:在应用图像风格转换、微调模型和混合原始图像内容等不同策略时,对黑盒模型的非针对性攻击成功率(%)。默认情况下,每种策略都会添加随机噪声。对抗样本在Inception-v3模型上生成。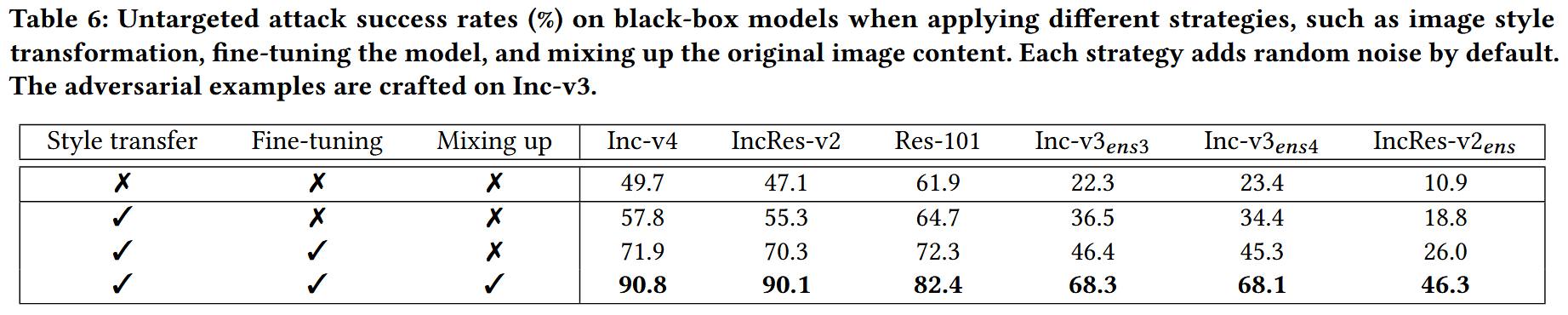
结论-Conslusion
这部分总结了研究的核心内容、创新点及实验成果,阐述了STM方法的优势与意义,具体如下:
- 研究出发点:基于域偏差影响正常训练模型泛化能力这一事实,推测其可能也影响对抗样本的迁移性。研究发现现有基于输入变换的方法主要在同一源域进行数据增强,限制了对抗样本迁移性。
- STM方法概述:提出名为风格迁移方法(STM)的新型攻击方法,利用任意风格迁移网络将数据变换到不同域,以提升对抗样本迁移性。为避免风格化图像误导代理模型,导致迭代过程中梯度不精确,对风格迁移网络进行微调,并将原始图像与风格化图像混合。
- 方法优势与实验验证:STM能与现有基于输入变换的方法有效结合,进一步提升对抗样本迁移性。在ImageNet兼容数据集上的实验结果表明,STM在正常训练模型和对抗训练模型上均能取得更高的攻击成功率,在非针对性和针对性攻击方面的性能均优于当前最先进的基于输入变换的攻击方法。

脑启社区是一个专注类脑智能领域的开发者社区。欢迎加入社区,共建类脑智能生态。社区为开发者提供了丰富的开源类脑工具软件、类脑算法模型及数据集、类脑知识库、类脑技术培训课程以及类脑应用案例等资源。
更多推荐

 15
15 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)